اختبار مقارن للذاكرة المؤقتة متعددة مؤشرات الترابط التي يتم تنفيذها في C / C ++ ووصف لكيفية ترتيب ذاكرة التخزين المؤقت LRU / MRU لسلسلة ذاكرة التخزين المؤقت O (n) ** RU
على مر العقود ، تم تطوير العديد من خوارزميات التخزين المؤقت: LRU ، MRU ، ARC ، وغيرها. ومع ذلك ، عندما كانت هناك حاجة إلى ذاكرة التخزين المؤقت للعمل متعدد الخيوط ، أعطت google في هذا الموضوع خيارًا واحدًا ونصف ، وظل السؤال على StackOverflow بدون إجابة بشكل عام. لقد وجدت حلاً من Facebook يعتمد على حاويات آمنة للخيوط من مستودع Intel TBB . لدى الأخير أيضًا ذاكرة تخزين مؤقت LRU متعددة مؤشرات الترابط لا يزال قيد الاختبار التجريبي ، وبالتالي ، لاستخدامه ، يجب تحديد صراحة في المشروع:
#define TBB_PREVIEW_CONCURRENT_LRU_CACHE true
وإلا ، فسوف يعرض المترجم خطأ نظرًا لوجود فحص في رمز Intel TBB:
#if ! TBB_PREVIEW_CONCURRENT_LRU_CACHE #error Set TBB_PREVIEW_CONCURRENT_LRU_CACHE to include concurrent_lru_cache.h #endif
أردت أن أقارن بطريقة أو بأخرى أداء ذاكرات التخزين المؤقت - أيها تختار؟ أو اكتب بنفسك؟ في وقت سابق ، عندما كنت أقارن بين ذاكرة التخزين المؤقت ذات الارتباط المفرد ( الرابط ) ، تلقيت عروضًا لتجربة شروط أخرى مع مفاتيح أخرى وأدركت أن هناك حاجة إلى اختبار اختبار أكثر قابلية للتوسعة. لجعله أكثر ملاءمة لإضافة خوارزميات منافسة للاختبارات ، قررت لفها في الواجهة القياسية:
class IAlgorithmTester { public: IAlgorithmTester() = default; virtual ~IAlgorithmTester() { } virtual void onStart(std::shared_ptr<IConfig> &cfg) = 0; virtual void onStop() = 0; virtual void insert(void *elem) = 0; virtual bool exist(void *elem) = 0; virtual const char * get_algorithm_name() = 0; private: IAlgorithmTester(const IAlgorithmTester&) = delete; IAlgorithmTester& operator=(const IAlgorithmTester&) = delete; };
وبالمثل ، يتم التفاف الواجهات: العمل مع نظام التشغيل ، والحصول على الإعدادات ، وحالات الاختبار ، إلخ. يتم وضع المصادر في المستودع . هناك حالتان للاختبار في الحامل: إدراج / بحث ما يصل إلى 1،000،000 عنصر باستخدام مفتاح من الأرقام التي تم إنشاؤها عشوائيًا وحتى 100000 عنصر باستخدام مفتاح سلسلة (مأخوذ من 10 ميغابايت من خطوط wiki.train.tokens). لتقدير وقت التشغيل ، يتم تسخين كل ذاكرة تخزين مؤقت للاختبار لأول مرة إلى الحجم المستهدف دون قياسات الوقت ، ثم تقوم الإشارة بإطلاق التدفقات من السلسلة لإضافة البيانات والبحث عنها. يتم تعيين عدد مؤشرات الترابط وإعدادات حالة الاختبار في الأصول / settings.json . يتم توضيح إرشادات التجميع خطوة بخطوة ووصف إعدادات JSON في مستودع WiKi . يتم تعقب الوقت من اللحظة التي يتم فيها إطلاق الإشارة حتى تتوقف السلسلة الأخيرة. إليك ما حدث:
حالة الاختبار 1 - مفتاح في شكل مجموعة من الأرقام العشوائية uint64_t keyArray [3]:
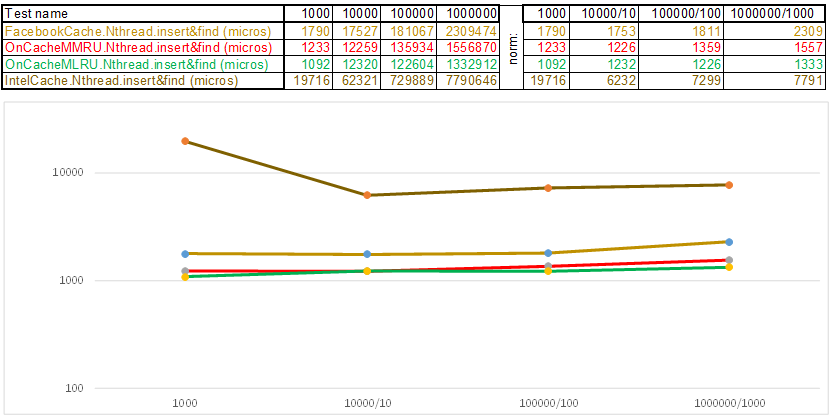
اختبار الحالة 2 - المفتاح كسلسلة:
يرجى ملاحظة أن حجم البيانات المدرجة / البحث في كل خطوة من حالة الاختبار يزيد 10 مرات. بعد ذلك ، في الوقت الذي تم إنفاقه في معالجة المجلد التالي ، أقسم على 10 ، 100 ، 1000 ، على التوالي ... إذا تصرفت الخوارزمية مثل O (n) في تعقيد الوقت ، فسيظل الجدول الزمني موازيًا تقريبًا لمحور X. بعد ذلك ، سأكشف عن المعرفة المقدسة ، حيث تمكنت من احصل على تفوق 3-5 مرات على ذاكرة التخزين المؤقت على Facebook في خوارزميات O (n) Cache ** RU عند العمل باستخدام مفتاح سلسلة:
- دالة التجزئة ، بدلاً من قراءة كل حرف في السلسلة ، تقوم ببساطة بإلقاء مؤشر على بيانات السلسلة إلى uint64_t keyArray [3] وتحسب مجموع الأعداد الصحيحة. وهذا يعني أنه يعمل مثل برنامج "Guess the Melody" - وأعتقد أن اللحن بـ 3 ملاحظات ... 3 * 8 = 24 حرفًا إذا كانت لاتينية ، وهذا يسمح لك بالفعل بتشتيت الخطوط جيدًا في سلال التجزئة. نعم ، يمكن جمع الكثير من الخطوط في سلة تجزئة ، وهنا تبدأ الخوارزمية في التسارع:
- تتيح لك قائمة القفز في كل سلة القفز بسرعة أولاً في تجزئة مختلفة (معرف السلة = عدد التجزئة٪ من السلال ، بحيث يمكن ظهور تجزئة مختلفة في سلة واحدة) ، ثم داخل نفس التجزئة على طول الرؤوس:
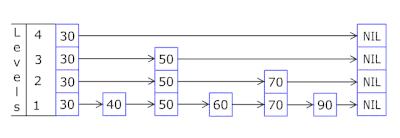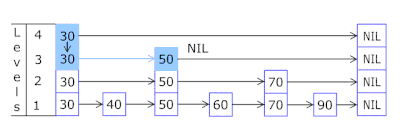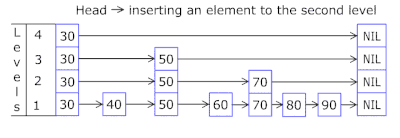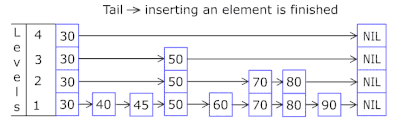
- يتم أخذ العقد التي يتم تخزين المفاتيح والبيانات فيها من مجموعة العقد المخصصة مسبقًا ، ويتزامن عدد العقد مع سعة التخزين المؤقت. يشير المعرف الذري إلى العقدة التي يجب اتخاذها بعد ذلك - إذا وصل إلى نهاية تجمع العقدة ، يبدأ بـ 0 = لذلك يذهب المُخصص في دائرة الكتابة فوق العقد القديمة ( ذاكرة التخزين المؤقت LRU في OnCacheMLRU ).
للحالة عندما يكون من الضروري تخزين العناصر الأكثر شيوعًا في استعلامات البحث في ذاكرة التخزين المؤقت ، يتم إنشاء فئة OnCacheMMRU الثانية ، تكون الخوارزمية كما يلي: بالإضافة إلى سعة ذاكرة التخزين المؤقت ، يقوم مُنشئ الفئة أيضًا بتمرير المعلمة الثانية uint32_t بلا فائدة ، والحد المسموح به هو إذا كانت عدد طلبات البحث التي تتمنى استخدام العقدة الحالية أقل إذا كانت الحدود عديمة الفائدة ، فسيتم إعادة استخدام العقدة لعملية الإدراج التالية (سيتم إخلاؤها). إذا كانت شعبية العقدة (std :: atomic <uint32_t> المستخدمة {0}) في هذه الدائرة مرتفعة ، في لحظة طلب التخصيص من التجمع الدوري ، ستتمكن العقدة من البقاء على قيد الحياة ، ولكن سيتم إعادة تعيين عداد الشعبية إلى 0. لذلك ستكون هناك دائرة أخرى من تمرير التخصيص على مجموعة من العقد وستحصل على فرصة لاستعادة الشعبية من أجل الاستمرار في الوجود. بمعنى أنه مزيج من خوارزميات MRU (حيث يتم تعليق الخوارزميات الأكثر شيوعًا في ذاكرة التخزين المؤقت للأبد) و MQ (حيث يتم تتبع العمر). يتم تحديث ذاكرة التخزين المؤقت باستمرار وفي نفس الوقت يعمل بسرعة كبيرة - بدلاً من 10 خوادم يمكنك وضع 1 ..
بشكل عام ، تقضي خوارزمية التخزين المؤقت الوقت على ما يلي:
- الحفاظ على البنية التحتية لذاكرة التخزين المؤقت (الحاويات والمخصصات وتتبع العمر وشعبية العناصر)
- حساب التجزئة وعمليات المقارنة الرئيسية عند إضافة / البحث عن البيانات
- خوارزميات البحث: شجرة Red-Black ، جدول التجزئة ، قائمة التخطي ، ...
كان من الضروري فقط تقليل وقت تشغيل كل عنصر من هذه العناصر ، بالنظر إلى أن أبسط الخوارزمية معقدة من الناحية الزمنية وغالبًا ما تكون أكثر كفاءة ، نظرًا لأن أي منطق يأخذ دورات CPU. هذا ، بغض النظر عن ما تكتبه ، هذه عمليات يجب أن تؤتي ثمارها في الوقت المناسب مقارنةً بأسلوب التعداد البسيط: بينما تسمى الوظيفة التالية ، سيتعين على التعداد أن يمر عبر مائة أو عقدتين آخرتين. في ضوء ذلك ، ستلعب التخزين المؤقت متعدد الخيوط دائمًا ترابطًا فرديًا ، نظرًا لأن حماية السلال من خلال std :: shared_mutex والعُقد من خلال std :: atomic_flag in_use ليست مجانية. لذلك ، للإصدار على الخادم ، أستخدم ذاكرة التخزين المؤقت المفردة الترابط OnCacheSMRU في مؤشر ترابط خادم Epoll الرئيسي (العمليات الطويلة فقط على العمل مع DBMS ، القرص ، تشفير يتم إخراجها في سير العمل المتوازي). لإجراء تقييم مقارن ، يتم استخدام نسخة واحدة من حالات الاختبار:
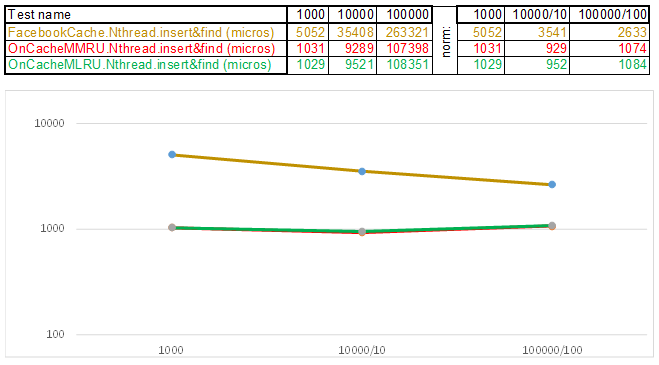
حالة الاختبار 1 - مفتاح في شكل مجموعة من الأرقام العشوائية uint64_t keyArray [3]:

اختبار الحالة 2 - المفتاح كسلسلة:
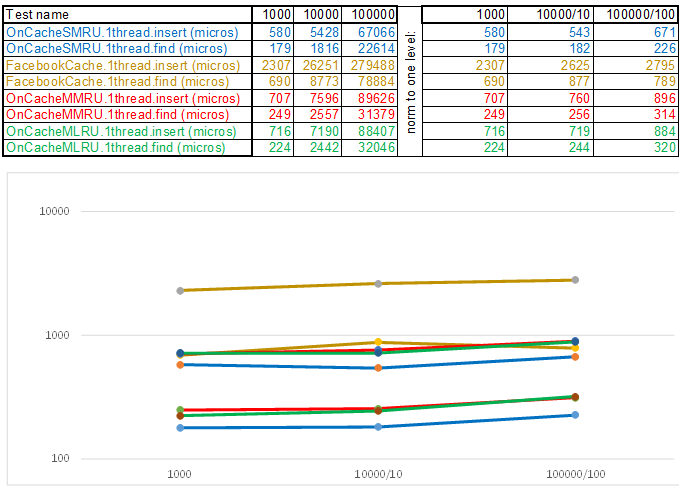
في الختام ، أريد أن أخبركم عن الأشياء المهمة الأخرى التي يمكن استخلاصها من مصادر طاولة الاختبار:
- مكتبة تحليل JSON ، التي تتألف من ملف specjson.h واحد ، هي خوارزمية بسيطة بسيطة لأولئك الذين لا يريدون سحب بضع ميغا بايت من رمز شخص آخر في مشروعهم من أجل تحليل ملف الإعدادات أو JSON الوارد بتنسيق معروف.
- منهج مع حقن تنفيذ العمليات الخاصة بالنظام الأساسي في النموذج (فئة LinuxSystem: public ISystem {...}) بدلاً من التقليدي (#ifdef _WIN32). إنها أكثر ملاءمة للالتفاف ، على سبيل المثال ، الإشارات ، والعمل مع المكتبات والخدمات المتصلة ديناميكيًا - في الفصول الدراسية يوجد فقط رمز ورؤوس من نظام تشغيل معين. إذا كنت بحاجة إلى نظام تشغيل آخر ، فأنت تقوم بحقن تطبيق آخر (فئة WindowsSystem: public ISystem {...}).
- سيتجه الحامل إلى CMake - من المناسب فتح مشروع CMakeLists.txt في Qt Creator أو Microsoft Visual Studio 2017. يتيح لك العمل مع المشروع من خلال CmakeLists.txt أتمتة بعض العمليات التحضيرية - على سبيل المثال ، نسخ ملفات حالة الاختبار وملفات التكوين إلى دليل التثبيت:
- بالنسبة لأولئك الذين يتقنون الميزات الجديدة لـ C ++ 17 ، هذا مثال على العمل مع std :: shared_mutex ، std :: customator <std :: shared_mutex> ، thread_local ثابت في القوالب (هناك فروق دقيقة - أين يمكن تخصيصها؟) ، إطلاق عدد كبير من الاختبارات في المواضيع بطرق مختلفة مع قياس وقت التنفيذ:
- إرشادات خطوة بخطوة حول كيفية تجميع وتكوين وتشغيل منصة الاختبار هذه - WiKi .
إذا لم يكن لديك حتى الآن إرشادات خطوة بخطوة لنظام تشغيل مناسب ، سأكون ممتنًا للمساهمة في المستودع الخاص بتطبيق ISystem وتعليمات التجميع خطوة بخطوة (لـ WiKi) ... أو فقط اكتب لي - سأحاول إيجاد الوقت لرفع الجهاز الظاهري ووصف خطوات التجميع.