تعد السجلات جزءًا مهمًا من النظام ، حيث تتيح لك فهم أنه يعمل (أو لا يعمل) ، كما هو متوقع. في ظروف بنية microservice ، يصبح العمل مع سجلات الانضباط منفصلة لأولمبياد خاص. تحتاج إلى حل مجموعة من الأسئلة على الفور:
- كيفية كتابة سجلات من التطبيق ؛
- أين تكتب السجلات ؛
- كيفية تسليم سجلات للتخزين والمعالجة ؛
- كيفية معالجة وتخزين السجلات.
يضيف استخدام تقنيات تعبئة الحاويات ، الذي أصبح شائعًا الآن ، الرمال على قمة أشعل النار إلى مجال خيارات حل المشكلة.
فقط حول فك شفرة تقرير يوري بوشميليف "خريطة أشعل النار في مجال جمع وتسليم سجلات"
من يهتم ، من فضلك ، تحت القط.
اسمي يوري بوشميليف. أنا أعمل في لازادا. سأتحدث اليوم عن كيفية قيامنا بعمل سجلاتنا ، وكيف جمعناها ، وما نكتبه هناك.

من اين نحن؟ من نحن؟ Lazada هو المتجر الأول على الإنترنت في ست دول في جنوب شرق آسيا. يتم توزيع جميع هذه البلدان من قبل مراكز البيانات. هناك الآن مراكز بيانات 4. لماذا هذا مهم؟ لأن بعض القرارات كانت بسبب وجود رابط ضعيف للغاية بين المراكز. لدينا بنية microservice. لقد فوجئت عندما وجدت أن لدينا بالفعل 80 خدمة ميكروية. عندما بدأت المهمة مع سجلات ، كان هناك فقط 20. بالإضافة إلى ذلك ، هناك قطعة كبيرة من إرث PHP ، والتي يجب عليك أيضًا التعايش معها وتحملها. كل هذا يولد لنا في الوقت الحالي أكثر من 6 ملايين رسالة في الدقيقة في جميع أنحاء النظام ككل. علاوة على ذلك ، سأوضح كيف نحاول التعايش معها ، ولماذا هذا هو الحال.

نحن بحاجة إلى العيش بطريقة ما مع هذه الرسائل البالغ عددها 6 ملايين رسالة. ماذا يجب أن نفعل معهم؟ 6 ملايين رسالة تحتاجها:
- إرسال من التطبيق
- قبول للتسليم
- تقديم للتحليل والتخزين.
- لتحليل
- متجر بطريقة أو بأخرى.

عندما ظهرت ثلاثة ملايين رسالة ، كان لدي نفس المظهر. لأننا بدأنا مع بعض سنتا. من الواضح أن سجلات التطبيق مكتوبة هناك. على سبيل المثال ، لم أستطع الاتصال بقاعدة البيانات ، وكنت قادراً على الاتصال بقاعدة البيانات ، لكنني لم أستطع قراءة شيء ما. ولكن إلى جانب ذلك ، تكتب كل واحدة من خدماتنا الميكروية أيضًا سجل وصول. كل طلب يصل إلى microservice يقع في السجل. لماذا نفعل هذا؟ المطورين يريدون أن يكونوا قادرين على تتبع. في كل سجل وصول ، يوجد حقل traceid ، حيث تعمل الواجهة الخاصة على زيادة إرخاء السلسلة بأكملها وتعرض التتبع بشكل جميل. تتبع يوضح كيف ذهب الطلب ، وهذا يساعد المطورين لدينا للتعامل بسرعة مع أي القمامة مجهولة الهوية.

كيف نعيش معها؟ الآن سوف أصف بإيجاز مجال الخيارات - كيف يتم حل هذه المشكلة بشكل عام. كيفية حل مشكلة جمع السجلات ونقلها وتخزينها.

كيف تكتب من التطبيق؟ من الواضح أن هناك طرقًا مختلفة. على وجه الخصوص ، هناك أفضل الممارسات ، كما يخبرنا الرفاق المألوف. هناك مدرسة قديمة في شكلين ، كما قال الأجداد. هناك طرق أخرى.

مع مجموعة من السجلات عن نفس الوضع. لا توجد خيارات كثيرة لحل هذا الجزء بالذات. هناك بالفعل المزيد ، ولكن ليس الكثير.

ولكن مع التسليم والتحليل اللاحق - يبدأ عدد الاختلافات في الانفجار. لن أصف كل خيار الآن. أعتقد أن الخيارات الرئيسية يسمعها كل شخص مهتم بالموضوع.

سأبين كيف فعلنا ذلك في لازادا ، وكيف بدأ كل شيء بالفعل.

قبل عام ، جئت إلى Lazada ، وأرسلوني إلى مشروع حول سجلات. كان مثل هذا. تمت كتابة السجل من التطبيق إلى stdout و stderr. لقد فعلوا كل شيء بطريقة عصرية. ولكن بعد ذلك قام المطورون بإخراجها من التدفقات القياسية ، وبعد ذلك سيقوم أخصائيو البنية التحتية بترتيبها بطريقة ما. بين المتخصصين في البنية التحتية والمطورين ، هناك أيضًا إصدارات تقول: "حسنًا ... حسنًا ، فلنلفها في ملف به غلاف ، هذا كل شيء." وبما أن كل هذا موجود في الحاوية ، فقد قاموا بلفها في الحاوية نفسها ، وقاموا بتنزيل الكتالوج داخلها ووضعها هناك. أعتقد أنه من الواضح تقريبًا للجميع ما جاء منه.

دعونا نرى بعيدا قليلا. كيف نقدم هذه السجلات. اختار شخص ما td-agent ، وهو في الواقع fluentd ، ولكن ليس fluentd تماما. ما زلت لم أفهم العلاقة بين هذين المشروعين ، لكن يبدو أنهما نفس الشيء. وهذا الطلاقة ، المكتوب بلغة روبي ، يقرأ ملفات السجل ، ويقوم بتحليلها في JSON لبعض الفترات العادية. ثم أرسلهم إلى كافكا. وفي كافكا لكل API كان لدينا 4 مواضيع منفصلة. لماذا 4؟ لأن هناك حية ، وهناك انطلاق ، ولأن هناك stdout و stderr. المطورين يلدونهم ، ويجب على مهندسي البنية التحتية خلقهم في كافكا. علاوة على ذلك ، كانت كافكا تحت سيطرة قسم آخر. لذلك ، كان من الضروري إنشاء تذكرة بحيث تنشئ 4 موضوعات لكل api هناك. الجميع نسي ذلك. بشكل عام ، كان هناك القمامة والأبخرة.
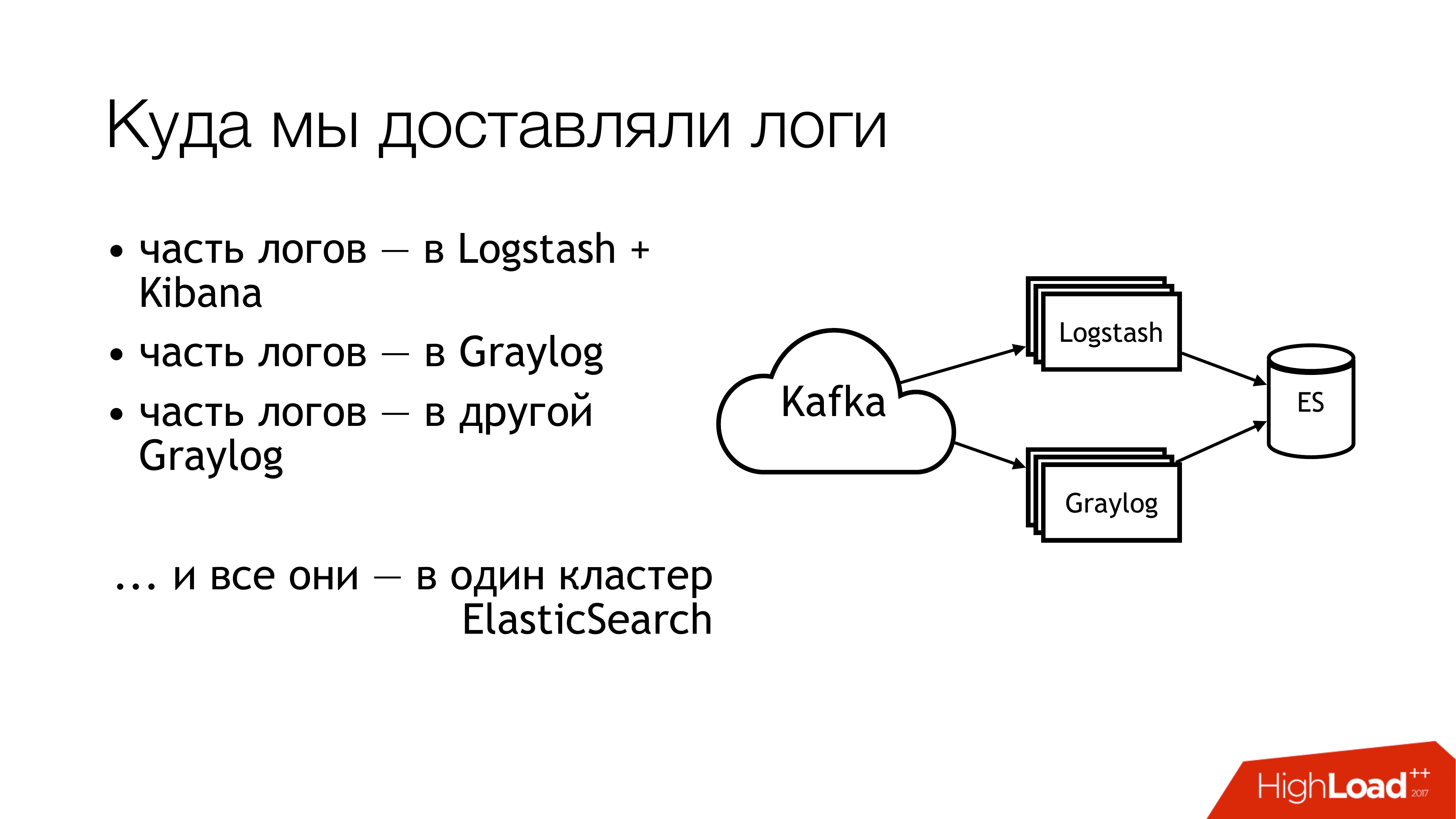
ماذا فعلنا بعد ذلك؟ أرسلناها إلى الكافكا. أبعد من كافكا ، طار نصف السجلات إلى لوغستاش. تمت مشاركة النصف الآخر من السجلات. طار جزء إلى Graylog واحد ، جزء - إلى Graylog آخر. ونتيجة لذلك ، طار كل هذا في مجموعة Elasticsearch واحدة. وهذا هو ، هذه الفوضى كلها وقعت في نهاية المطاف هناك. ليس عليك القيام بذلك!

هذه هي الطريقة التي تبدو بها إذا نظرت من بعيد. لا تفعل هذا! هنا ، تشير الأرقام على الفور إلى مناطق المشكلة. يوجد الكثير منهم في الواقع ، لكن 6 منهم يمثلون مشكلة كبيرة للغاية ، والتي تحتاج إلى القيام بشيء ما. سأتحدث عنها بشكل منفصل الآن.

هنا (1،2،3) نكتب الملفات ، وبالتالي ، هناك ثلاثة مكابس في وقت واحد.
الأول (1) هو أننا نحتاج إلى كتابتها في مكان ما. لا أريد دائمًا إعطاء واجهة برمجة التطبيقات (API) القدرة على الكتابة مباشرةً إلى ملف. من المرغوب فيه عزل واجهة برمجة التطبيقات في الحاوية ، بل والأفضل ، أن تكون للقراءة فقط. أنا مسؤول النظام ، لذلك لدي وجهة نظر بديلة بعض الشيء لهذه الأشياء.
النقطة الثانية (2،3) - لدينا الكثير من الطلبات التي تصل إلى API. يكتب API الكثير من البيانات إلى ملف. الملفات تنمو. نحن بحاجة إلى تدويرها. لأنه خلاف ذلك لا توجد وسيلة للحصول على أي أقراص. يعد تدويرها أمرًا سيئًا لأنه يتم إعادة توجيهها من خلال shell إلى دليل. لا يمكننا نقله بأي شكل من الأشكال. لا يمكن إخبار أحد التطبيقات بإعادة اكتشاف الواصفات. لأن المطورين سوف ينظرون إليك مثل أحمق: "ما هي الواصفات؟ نكتب عموما إلى stdout ". قام مهندسو البنية التحتية بعمل نسخة طبق الأصل في logrotate ، مما يجعل مجرد نسخة من الملف و trankeytit الأصلي. وفقًا لذلك ، بين عمليات النسخ هذه ، عادة ما تنتهي مساحة القرص.
(4) لدينا تنسيقات مختلفة وكان لدينا واجهات برمجة تطبيقات مختلفة. كانت مختلفة بعض الشيء ، ولكن يجب إعادة كتابة regexp بشكل مختلف. منذ أن تم التحكم في كل هذا من قبل الدمى ، كان هناك مجموعة كبيرة من الطبقات مع الصراصير الخاصة بهم. بالإضافة إلى ذلك ، يمكن لل td-agent في معظم الأحيان أن يأكل الذاكرة ، غبي ، يمكن أن يدعي أنه يعمل ، ولا يفعل شيئًا. في الخارج ، كان من المستحيل أن نفهم أنه لم يفعل شيئًا. في أحسن الأحوال ، سوف يسقط ، وسيقوم شخص ما بالتقاطه لاحقًا. بتعبير أدق ، سوف تصل حالة التأهب ، وسيذهب شخص ما بأيديهم.

(6) ومعظم القمامة والنفايات - كان elasticsearch. لأنه كان نسخة قديمة. لأنه لم يكن لدينا سادة متخصصون في ذلك الوقت. كان لدينا سجلات غير متجانسة يمكن أن تتقاطع فيها الحقول. يمكن كتابة سجلات مختلفة للتطبيقات المختلفة بأسماء الحقول نفسها ، ولكن في نفس الوقت قد تكون هناك بيانات مختلفة من الداخل. وهذا هو ، سجل واحد يأتي مع عدد صحيح في الحقل ، على سبيل المثال ، المستوى. سجل آخر يأتي مع سلسلة في حقل المستوى. في حالة عدم وجود خرائط ثابتة ، يتم الحصول على مثل هذا الشيء الرائع. إذا وصلت الرسالة الأولى بسلسلة ، بعد تدوير الفهرس في elasticsearch ، فإننا نعيش بشكل طبيعي. وإذا وصلت أولاً مع Integer ، فسيتم ببساطة تجاهل جميع الرسائل اللاحقة التي وصلت مع String. لأن نوع الحقل غير متطابق.

بدأنا في طرح هذه الأسئلة. قررنا عدم البحث عن المذنبين.

ولكن هناك شيء يجب القيام به! الشيء الواضح هو وضع المعايير. كان لدينا بالفعل بعض المعايير. بعض وصلنا في وقت لاحق قليلا. لحسن الحظ ، تمت الموافقة بالفعل على تنسيق سجل موحد لجميع واجهات برمجة التطبيقات في ذلك الوقت. هو مكتوب مباشرة في معايير تفاعل الخدمات. وفقًا لذلك ، يجب على أولئك الذين يرغبون في الحصول على سجلات كتابتها بهذا التنسيق. إذا كان شخص ما لا يكتب سجلات في هذا الشكل ، فإننا لا نضمن أي شيء.
علاوة على ذلك ، أود أن أضع معيارًا واحدًا لطرق تسجيل السجلات وتسليمها وجمعها. في الواقع ، أين تكتبها ، وكيفية إيصالها. الموقف المثالي هو عندما تستخدم المشاريع نفس المكتبة. فيما يلي مكتبة تسجيل منفصلة لـ Go ، وهناك مكتبة منفصلة لـ PHP. الجميع لدينا - يجب على الجميع استخدامها. في الوقت الحالي ، أود أن أقول إننا حصلنا عليه بنسبة 80 في المائة. لكن البعض يواصل أكل الصبار.
وهناك (على الشريحة) بالكاد ظهر "SLA لتسليم السجل". لم يصل إلى هناك بعد ، لكننا نعمل عليه. نظرًا لأنه مناسب جدًا عندما تقول المعلومات الواردة أدناه ، إذا كتبت بتنسيق كذا وكذا لمثل هذا المكان وما لا يزيد عن N رسائل في الثانية الواحدة ، فمن المحتمل أن نسلم مثل هذه الأشياء وكذا هناك. هذا يخفف من مجموعة من الصداع. إذا كان هناك جيش تحرير السودان ، فهذا أمر رائع!

كيف بدأنا في حل المشكلة؟ وكان أشعل النار الرئيسي مع وكيل TD. لم يكن من الواضح إلى أين تذهب السجلات. هل تم تسليمها؟ هل سيذهبون؟ أين هم على الإطلاق؟ لذلك ، تقرر العنصر الأول ليحل محل td- وكيل. رسمت لفترة وجيزة الخيارات لما يمكن استبداله به.
Fluentd. أولاً ، صادفته في وظيفة سابقة ، وسقط هناك أيضًا بشكل دوري. ثانيا ، هذا هو نفسه ، فقط في الملف الشخصي.
Filebeat. كيف كانت مريحة بالنسبة لنا؟ حقيقة أنه على الذهاب ، ولدينا الكثير من الخبرة في الذهاب. وفقا لذلك ، إذا كان الأمر كذلك ، يمكننا أن نضيفها بطريقة أو بأخرى لأنفسنا. لذلك ، لم نأخذها. حتى أنه لم يكن هناك أي إغراء للبدء في إعادة كتابته بنفسك.
الحل الواضح لـ sysadmin هو كل syslogs في هذا المبلغ (syslog-ng / rsyslog / nxlog).
أو اكتب شيئًا خاصًا بنا ، لكننا أسقطناه ، كما فعل ملف. إذا كتبت شيئًا ما ، فمن الأفضل أن تكتب شيئًا مفيدًا للعمل. لتسليم السجلات ، من الأفضل أن تأخذ شيئًا جاهزًا.
لذلك ، جاء الاختيار بالفعل إلى الاختيار بين syslog-ng و rsyslog. لقد اتجه نحو rsyslog ببساطة لأن لدينا بالفعل دروسًا في rsyslog في Puppet ، ولم أجد أي فرق واضح بينهما. ما هو سيسلوغ ، ما هو سيسلوغ. نعم ، شخص ما لديه وثائق أسوأ ، شخص لديه أفضل. إنه يعرف كيف ، وهو - بطريقة مختلفة.

وقليلا عن rsyslog. أولاً ، إنه رائع لأنه يحتوي على الكثير من الوحدات. أنه يحتوي على راينرسكريبت القابلة للقراءة البشرية (لغة تكوين حديثة). المكافأة الرائعة هي أننا نستطيع محاكاة سلوك td-agent باستخدام وسائله المعتادة ، ولم يتغير شيء للتطبيقات. أي أننا نغير td-agent إلى rsyslog ، لكننا لا نلمس أي شيء آخر. وعلى الفور نحصل على تسليم العمل. التالي ، mmnormalize هو شيء رائع في rsyslog. يسمح لك بتحليل السجلات ، ولكن لا تستخدم Grok و regexp. انها تجعل شجرة بناء الجملة مجردة. يقوم بتوزيع السجلات تقريبًا ، حيث يقوم المترجم بتوزيع أكواد المصدر. يتيح لك ذلك العمل بسرعة كبيرة ، وتناول القليل من وحدة المعالجة المركزية ، وبشكل عام ، إنه أمر رائع للغاية. هناك الكثير من المكافآت الأخرى. لن أتوقف عنهم.

Rsyslog لا يزال لديه مجموعة من العيوب. هم تقريبا نفس المكافآت. المشاكل الرئيسية - يجب أن تكون قادرًا على طهيها ، وتحتاج إلى تحديد الإصدار.
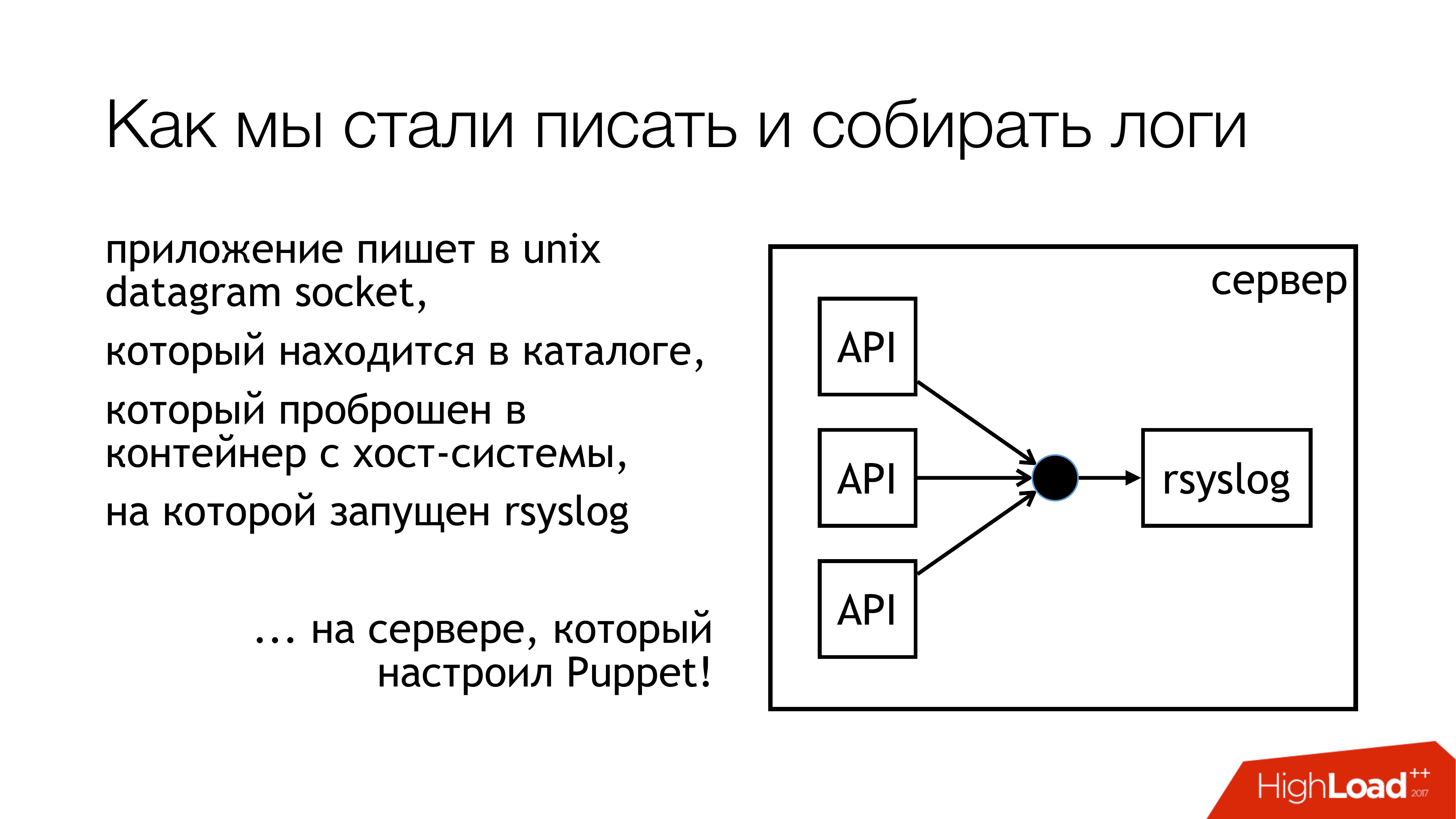
قررنا أن نكتب سجلات إلى مأخذ يونكس. وليس في / dev / log ، لأنه يوجد لدينا عصيدة من سجلات النظام ، يوجد دفتر يومية في خط الأنابيب هذا. لذلك دعونا نكتب إلى مقبس مخصص. نعلقها على مجموعة منفصلة. لن نتدخل. كل شيء سيكون شفافا وواضحا. لذلك فعلنا في الواقع. يتم توحيد الدليل مع هذه المقابس وإعادة توجيهه إلى كافة الحاويات. يمكن للحاويات رؤية المقبس الذي يحتاجونه ، وفتحه وكتابته.
لماذا لا ملف؟ لأن الجميع قرأ مقالًا عن Badushechka الذي حاول إعادة توجيه الملف إلى عامل الإرساء ، واتضح أنه بعد إعادة تشغيل rsyslog ، يتغير واصف الملف ، ويفقد عامل الإرساء هذا الملف. إنه يحتفظ بشيء آخر ، ولكن ليس نفس المقبس حيث يكتبون. قررنا أن نتجاوز هذه المشكلة ، وفي الوقت نفسه ، سنتجاوز مشكلة الحجب.

تقوم Rsyslog بالإجراءات المشار إليها على الشريحة وترسل السجلات إما إلى التتابع أو إلى Kafka. كافكا يطابق الطريقة القديمة. ترحيل - حاولت استخدام rsyslog الخالص لتسليم السجلات. بدون قائمة انتظار الرسائل ، أدوات rsyslog القياسية. في الأساس ، كان يعمل.

ولكن هناك فروق دقيقة حول كيفية حشرها لاحقًا في هذا الجزء (Logstash / Graylog / ES). يستخدم هذا الجزء (rsyslog-rsyslog) بين مراكز البيانات. فيما يلي رابط tcp مضغوط ، يسمح لك بحفظ عرض النطاق الترددي ، وبالتالي ، يزيد بطريقة ما من احتمال أن نتلقى بعض السجلات من مركز بيانات آخر في الحالات التي تكون فيها القناة ممتلئة. لأن لدينا إندونيسيا ، حيث كل شيء سيء. هذا هو المكان هذه المشكلة المستمرة.

فكرنا في كيفية مراقبتنا فعليًا ، ما هو احتمال وصول السجلات التي سجلناها من التطبيق إلى هذه الغاية؟ قررنا الحصول على المقاييس. لدى Rsyslog وحدة تجميع الإحصاءات الخاصة بها ، والتي تحتوي على نوع من العدادات. على سبيل المثال ، يمكن أن يوضح لك حجم قائمة الانتظار ، أو عدد الرسائل التي جاءت في مثل هذا الإجراء. يمكن بالفعل أن تؤخذ شيئا منها. بالإضافة إلى ذلك ، يحتوي على عدادات مخصصة يمكن تهيئتها ، وسوف يعرض لك ، على سبيل المثال ، عدد الرسائل التي كتبتها بعض API. بعد ذلك ، كتبت rsyslog_exporter في بيثون ، وأرسلناها كلها إلى بروميثيوس ورسمناها. تريد مقاييس Graylog حقًا ، لكن حتى الآن لم يكن لدينا وقت لتكوينها.

ما هي المشاكل؟ نشأت مشاكل مع حقيقة أننا اكتشفنا (SUDDENLY!) أن واجهات برمجة التطبيقات المباشرة الخاصة بنا تكتب 50 ألف رسالة في الثانية. هذه ليست سوى واجهة برمجة تطبيقات حية دون تنظيم. ويظهر لنا Graylog فقط 12 ألف رسالة في الثانية. ونشأ سؤال معقول ، ولكن أين هي بقايا الطعام؟ من الذي استنتجنا أن Graylog فقط لا يمكن التعامل معها. لقد نظروا ، وبالفعل لم يتقن Graylog مع Elasticsearch هذا الدفق.
علاوة على ذلك ، الاكتشافات الأخرى التي حققناها في هذه العملية.
تم حظر الكتابة على المقبس. كيف حدث هذا؟ عندما استعملت rsyslog للتسليم ، في وقت من الأوقات ، انفصلت قناتنا بين مراكز البيانات. استيقظ التسليم في مكان واحد ، واستيقظ التسليم في مكان آخر. كل هذا قد وصل إلى جهاز مع واجهات برمجة التطبيقات التي تكتب إلى مقبس rsyslog. كان هناك طابور. ثم تم ملء قائمة الانتظار للكتابة على مأخذ يونكس ، والذي يصل إلى 128 حزمة. ويتم حظر الكتابة التالية () في التطبيق. عندما نظرنا إلى المكتبة التي نستخدمها في التطبيقات على Go ، فقد كتب هناك أن الكتابة إلى المقبس تحدث في وضع عدم الحظر. كنا متأكدين أن لا شيء يحجب. لأننا قرأنا مقالاً عن Badushechka الذي كتب عنه. ولكن هناك لحظة. حول هذه المكالمة لا تزال هناك حلقة لا نهاية لها حيث تم إجراء محاولة باستمرار لدفع الرسالة إلى المقبس. لم نلاحظ ذلك. اضطررت إلى إعادة كتابة المكتبة. منذ ذلك الحين ، تغيرت عدة مرات ، لكننا تخلصنا الآن من الأقفال في جميع النظم الفرعية. لذلك ، يمكنك إيقاف rsyslog ولن يسقط أي شيء.
من الضروري مراقبة حجم قوائم الانتظار ، مما يساعد على عدم خطوة على هذا أشعل النار. أولاً ، يمكننا أن نراقب عندما نبدأ في فقدان الرسائل. ثانيا ، يمكننا مراقبة ذلك من حيث المبدأ لدينا مشاكل التسليم.
ولحظة أخرى غير سارة - التضخيم 10 مرات في هندسة الخدمات المصغرة - إنها سهلة للغاية. ليس لدينا العديد من الطلبات الواردة ، ولكن بسبب الرسم البياني الذي تعمل به هذه الرسائل ، بسبب سجلات الوصول ، نزيد فعليًا الحمل على السجلات مرة واحدة كل عشرة. لسوء الحظ ، لم يكن لدي وقت لحساب الأرقام الدقيقة ، ولكن الخدمات الدقيقة - هم. هذا يجب أن يؤخذ في الاعتبار. اتضح أنه في الوقت الحالي ، يُعد النظام الفرعي لجمع السجلات هو الأكثر تحميلًا في Lazada.

كيفية حل مشكلة elasticsearch؟ إذا كنت بحاجة إلى الحصول بسرعة على السجلات في مكان واحد ، حتى لا تعمل عبر جميع الأجهزة ، ولا تجمعها هناك ، استخدم تخزين الملفات. هذا مضمون للعمل. وهي مصنوعة من أي خادم. تحتاج فقط إلى عصا الأقراص هناك ووضع سيسلوغ. بعد ذلك ، يضمن لك الحصول على جميع السجلات في مكان واحد. علاوة على ذلك ، سيكون من الممكن بالفعل ضبط ببطء elasticsearch ، graylog ، شيء آخر. ولكن سيكون لديك بالفعل جميع السجلات ، وعلاوة على ذلك ، يمكنك تخزينها بقدر ما يكفي من صفائف القرص.

في وقت تقريري ، بدأت الدائرة تبدو هكذا. لقد توقفنا عملياً عن الكتابة إلى الملف. الآن ، على الأرجح ، سوف نطفئ بقايا الطعام. على الأجهزة المحلية التي تشغل API ، سنتوقف عن الكتابة إلى الملفات. أولاً ، يوجد تخزين ملفات يعمل بشكل جيد للغاية. ثانياً ، نفاد مكان هذه الآلات باستمرار ، من الضروري مراقبتها باستمرار.
هذا الجزء مع Logstash و Graylog ، إنه يرتفع حقًا. لذلك ، يجب أن نتخلص منه. عليك أن تختار شيئا واحدا.

قررنا رمي Logstash و Kibana. لأن لدينا قسم الأمن. ما هو الاتصال؟ الاتصال هو أن Kibana بدون X-Pack وبدون Shield لا يسمح بالتمييز بين حقوق الوصول والسجلات. لذلك ، أخذوا Graylog. لديه كل شيء. أنا لا أحبه ، لكنه يعمل. اشترينا حديدًا جديدًا ونضع Graylog الطازجة هناك ونقلنا جميع السجلات بتنسيقات صارمة إلى Graylog منفصل. لقد حللنا المشكلة مع أنواع مختلفة من الحقول المتطابقة تنظيميا.

بالضبط ما هو مدرج في Graylog الجديد. سجلنا فقط كل شيء في عامل الميناء. أخذنا مجموعة من الخوادم ، وتم طرح ثلاث حالات من تطبيق Kafka ، و 7 من خوادم Graylog الإصدار 2.3 (لأنني أردت إصدار Elasticsearch 5). كل هذا على غارات من الأقراص الصلبة التي أثيرت. لقد رأينا معدل فهرسة يصل إلى 100 ألف رسالة في الثانية. رأينا أن الرقم 140 تيرابايت من البيانات في الأسبوع.

ومرة أخرى أشعل النار! اثنين من المبيعات قادمون. لقد انتقلنا ل 6 ملايين رسالة. في الولايات المتحدة ، ليس لدى Graylog وقت لمضغه. بطريقة ما علينا البقاء على قيد الحياة مرة أخرى.

لقد نجينا من هذا القبيل. أضفنا المزيد من الخوادم ومحركات أقراص الحالة الثابتة. في هذه اللحظة ، نحن نعيش بهذه الطريقة. الآن نحن مضغ بالفعل رسائل 160K في الثانية الواحدة. لم نصل بعد إلى الحد الأقصى ، لذلك لم يتضح بعد مقدار ما يمكننا فعلاً الخروج منه.

هذه هي خططنا للمستقبل. من هذه ، حقا ، الأهم هو توافر عالية ربما. ليس لدينا بعد. يتم تكوين العديد من السيارات على النحو نفسه ، ولكن حتى الآن كل شيء يمر سيارة واحدة. , failover .
Graylog.
rate limit , API, bandwidth .
, - SLA c , . , .
.

, , . -, . -, syslog — . -, rsyslog , . .
.
: - … (filebeat?)
: . . API , , . pipe. : « , , »? , , : « , ».
: HDFS?
: . , , , , long term solution.
: .
: . "" .
: rsyslog. TCP, UDP. UDP, ?
: . , , . , : « , - , - », «! , , , .» . , ? , ? best effort. , 100% . . .
: API - , , ? - .
: , . . , . , API . rsyslog . API , , timestamp . Graylog, timestamp. .
: Timestamp .
: Timestamp API. , , . NTP. API timestamp . rsyslog .
: . , . ? ?
: . - . , . . Log Relay. Rsyslog . . . . . . , (), Graylog. storage. , , . . .
: ?
: ( ) .
: , ?
: , . . , Go API, . , socket. . . socket. , . . , . prometheus, Grafana . . , .
: elasticsearch . ?
: .
: ?
: . .
: rsyslog - ?
: unix socket. 128 . . . , 128 . , , , , . , . .
c : JSON?
: JSON relay, . Graylog, JSON . , , rsyslog. issue, .
c : Kafka? RabbitMQ? Graylog ?
: Graylog . Graylog . . . , , . rsyslog elasticsearch Kibana. . , Graylog Kibana. Logstash . , rsyslog. elasticsearch. Graylog - . . .
Kafka. . , , . . , , . RabbitMQ… c RabbitMQ. RabbitMQ . , . , . . . Graylog AMQP 0.9, rsyslog AMQP 1.0. , , . . Kafka. . omkafka rsyslog, , , rsyslog. .
سؤال : هل تستخدم كافكا لأنه كان لديك؟ لا تستخدم لأي غرض آخر؟
الإجابة : كافكا ، والذي تم استخدامه من قبل فريق Data Siness. هذا هو مشروع منفصل تماما ، والذي ، للأسف ، لا أستطيع أن أقول أي شيء. لا اعرف كانت تدار من قبل فريق علوم البيانات. عندما بدأت السجلات ، قرروا استخدامها ، حتى لا يضعوا سجلاتهم الخاصة. لقد قمنا الآن بتحديث Graylog ، وفقدنا التوافق ، لأن هناك نسخة قديمة من Kafka. كان لدينا للحصول على منطقتنا. في الوقت نفسه ، تخلصنا من هذه الموضوعات الأربعة لكل واجهة برمجة التطبيقات. لقد صنعنا موضوعًا واحدًا واسعًا للجميع مباشرًا ، وموضوعًا واسعًا واحدًا لكل التدريج وفقط كل شيء هناك. Graylog أشعل كل هذا بالتوازي.
السؤال : لماذا هذه الشامانية مع مآخذ ضرورية؟ هل حاولت استخدام برنامج تشغيل سجل syslog للحاويات؟
الإجابة : في تلك اللحظة عندما طرحنا هذا السؤال ، كانت لدينا علاقة متوترة مع عامل الميناء. كان عامل الميناء 1.0 أو 0.9. عامل الميناء نفسه كان غريب. ثانياً ، إذا قمت أيضًا بإدخال سجلات الدخول إليها ... لدي شكوك لم يتم التحقق منها أنه يمر بجميع السجلات من خلال نفسه ، من خلال البرنامج الخفي لرسو السفن. إذا كان لدينا واجهة برمجة تطبيقات واحدة تصبح مجنونة ، فإن بقية واجهات برمجة التطبيقات عالقة في حقيقة أنها لا تستطيع إرسال stdout و stderr. أنا لا أعرف من أين سيؤدي هذا. لديّ شكوك على مستوى الشعور بأنك لست بحاجة إلى استخدام برنامج تشغيل syslog لرسو السفن في هذا المكان. قسم الاختبار الوظيفي لدينا لديه مجموعة Graylog الخاصة بها مع سجلات. يستخدمون برامج تشغيل سجل الإرساء ويبدو أن كل شيء على ما يرام هناك. لكنهم يكتبون على الفور GELF إلى Graylog. نحن في تلك اللحظة عندما كان كل هذا متروكًا ، كنا بحاجة إلى العمل. ربما في وقت لاحق ، عندما يأتي شخص ما ويقول إنه كان يعمل بشكل طبيعي منذ مائة عام ، سنحاول.
سؤال : أنت تقوم بالتوصيل بين مراكز البيانات على rsyslog. لماذا لا في كافكا؟
الجواب : نحن نفعل كلا ، وذلك في الواقع. لسببين. إذا كانت القناة ميتة تمامًا ، فلدينا جميع السجلات ، حتى في شكل مضغوط ، لن نزحف إليها. و kafka يسمح لهم ببساطة أن تضيع في هذه العملية. بهذه الطريقة نتخلص من لصق هذه السجلات. نحن فقط استخدام كافكا في هذه الحالة مباشرة. إذا كانت لدينا قناة جيدة وتريد تحريرها ، فإننا نستخدم rsyslog الخاص بهم. ولكن في الواقع ، يمكنك تكوينه بحيث يسقط هو نفسه ما لم يزحف. في الوقت الحالي ، نحن فقط نستخدم تسليم rsyslog مباشرةً ، في مكان كافكا.