سارت الأخطاء والبرامج جنبًا إلى جنب منذ بداية عصر برمجة الكمبيوتر. مع مرور الوقت ، طور المطورون مجموعة من الممارسات لاختبار برامج تصحيح الأخطاء قبل نشرها ، لكن هذه الممارسات لم تعد مناسبة للأنظمة الحديثة ذات التعليم العميق. اليوم ، يمكن تسمية الممارسة الرئيسية في مجال التعلم الآلي بالتدريب على مجموعة بيانات معينة ، يليها التحقق في مجموعة أخرى. وبهذه الطريقة ، يمكنك حساب متوسط كفاءة النماذج ، ولكن من المهم أيضًا ضمان الموثوقية ، أي الكفاءة المقبولة في أسوأ الحالات. في هذه المقالة ، وصفنا ثلاثة أساليب لتحديد الأخطاء والقضاء عليها بدقة في النماذج التنبؤية المدربة: اختبار الخصومة ، والتعلم القوي ،
والتحقق الرسمي .
الأنظمة مع MOs ، بحكم التعريف ، ليست مستقرة. حتى الأنظمة التي تفوز على شخص في منطقة معينة قد لا تكون قادرة على مواجهة حل المشاكل البسيطة عند إجراء اختلافات دقيقة. على سبيل المثال ، ضع في اعتبارك مشكلة الصور المزعجة: يمكن بسهولة إنشاء شبكة عصبية يمكنها تصنيف الصور بشكل أفضل من الأشخاص للاعتقاد بأن الكسل عبارة عن سيارة سباق ، مما يضيف جزءًا صغيرًا من الضوضاء المحسوبة بعناية إلى الصورة.
 قد يؤدي الخلط بين المدخلات المنافسة عند تداخلها على صورة عادية إلى إرباك الذكاء الاصطناعي. تختلف صورتان متطرفتان بما لا يزيد عن 0.0078 لكل بكسل. يتم تصنيف الأول ككسل ، مع احتمال 99 ٪. والثاني هو مثل سيارة سباق مع احتمال 99 ٪.
قد يؤدي الخلط بين المدخلات المنافسة عند تداخلها على صورة عادية إلى إرباك الذكاء الاصطناعي. تختلف صورتان متطرفتان بما لا يزيد عن 0.0078 لكل بكسل. يتم تصنيف الأول ككسل ، مع احتمال 99 ٪. والثاني هو مثل سيارة سباق مع احتمال 99 ٪.هذه المشكلة ليست جديدة. كانت البرامج دائمًا بها أخطاء. منذ عقود ، يكتسب المبرمجون مجموعة رائعة من التقنيات ، من اختبار الوحدة إلى التحقق الرسمي. في البرامج التقليدية ، تعمل هذه الطرق بشكل جيد ، لكن تكييف هذه الأساليب للاختبار الدقيق لنماذج MO أمر بالغ الصعوبة بسبب الحجم والافتقار إلى البنية في النماذج التي يمكن أن تحتوي على مئات الملايين من المعلمات. هذا يشير إلى الحاجة إلى تطوير أساليب جديدة لضمان موثوقية أنظمة MO.
من وجهة نظر المبرمج ، فإن الخلل هو أي سلوك لا يلبي المواصفات ، أي الوظيفة المخططة للنظام. كجزء من بحثنا حول الذكاء الاصطناعى ، ندرس تقنيات لتقييم ما إذا كانت أنظمة MO تفي بالمتطلبات ، ليس فقط على مجموعات التدريب والاختبار ، ولكن أيضًا في قائمة المواصفات التي تصف الخصائص المطلوبة للنظام. من بين هذه الخصائص قد تكون هناك مقاومة للتغييرات الصغيرة بما فيه الكفاية في بيانات الإدخال ، أو قيود السلامة التي تمنع الإخفاقات الكارثية ، أو الامتثال للتنبؤات بقوانين الفيزياء.
في هذه المقالة ، سنناقش ثلاث مشكلات فنية مهمة يواجهها مجتمع MO في العمل لجعل أنظمة MO قوية ومتوافقة بشكل موثوق مع المواصفات المطلوبة:
- التحقق الفعال من الامتثال للمواصفات. نحن ندرس طرقًا فعالة للتحقق من أن أنظمة MO تتوافق مع خصائصها (على سبيل المثال ، الاستقرار والثبات) المطلوبة منها بواسطة المطور والمستخدمين. تتمثل إحدى الطرق للعثور على الحالات التي يمكن للنموذج من خلالها الابتعاد عن هذه الخصائص في البحث المنهجي عن أسوأ نتائج العمل.
- مو نماذج التدريب للمواصفات. حتى في حالة وجود كمية كبيرة من بيانات التدريب ، يمكن لخوارزميات MO القياسية إنتاج نماذج تنبؤية لا تفي عمليتها بالمواصفات المطلوبة. نحن مطالبون بمراجعة خوارزميات التدريب بحيث لا تعمل فقط بشكل جيد على بيانات التدريب ، ولكن أيضًا تفي بالمواصفات المطلوبة.
- دليل رسمي على تطابق نماذج MO مع المواصفات المطلوبة. يجب تطوير الخوارزميات للتأكد من أن النموذج يلبي المواصفات المطلوبة لجميع بيانات الإدخال الممكنة. على الرغم من أن مجال التحقق الرسمي قد درس هذه الخوارزميات لعدة عقود ، على الرغم من التقدم المثير للإعجاب ، إلا أنه ليس من السهل توسيع نطاقه ليشمل أنظمة MO الحديثة.
تحقق من توافق النموذج مع المواصفات المطلوبة
مقاومة الأمثلة التنافسية هي مشكلة مدنية إلى حد ما في الدفاع المدني. أحد الاستنتاجات الرئيسية التي تم التوصل إليها هي أهمية تقييم تصرفات الشبكة نتيجة لهجمات قوية ، وتطوير نماذج شفافة يمكن تحليلها بشكل فعال. لقد وجدنا مع باحثين آخرين أن العديد من النماذج أثبتت مقاومتها ضد الأمثلة التنافسية الضعيفة. ومع ذلك ، فإنها توفر دقة 0٪ تقريبًا للحصول على أمثلة تنافسية أقوى (
Athalye et al.، 2018 ،
Uesato et al.، 2018 ،
Carlini and Wagner، 2017 ).
على الرغم من أن معظم العمل يركز على حالات الفشل النادرة في سياق التدريس مع المعلم (وهذا هو تصنيف الصور بشكل أساسي) ، إلا أن هناك حاجة لتوسيع نطاق تطبيق هذه الأفكار لتشمل مجالات أخرى. في عمل حديث باستخدام منهج تنافسي لإيجاد حالات فشل فادحة ، نطبق هذه الأفكار على شبكات اختبار مدربة على التعزيز ومصممة لاستخدامها في الأماكن ذات المتطلبات الأمنية العالية. أحد التحديات التي تواجه تطوير نظم الحكم الذاتي هو أنه نظرًا لأن خطأ واحد يمكن أن يكون له عواقب وخيمة ، فلا يُعتبر حتى احتمال حدوث الفشل بسيطًا.
هدفنا هو تصميم "منافس" من شأنه أن يساعد على التعرف على مثل هذه الأخطاء مسبقًا (في بيئة يتم التحكم فيها). إذا كان بإمكان الخصم تحديد بفعالية أسوأ بيانات إدخال لنموذج معين ، فسيسمح لنا ذلك بالتقاط حالات نادرة من حالات الفشل قبل نشرها. كما هو الحال مع مصنفات الصور ، يمنحك تقييم كيفية العمل مع خصم ضعيف شعورا زائفا بالأمان أثناء النشر. يشبه هذا النهج تطوير البرمجيات بمساعدة "الفريق الأحمر" [red teaming - الذي يضم فريق تطوير تابع لجهة خارجية يتولى دور المهاجمين من أجل اكتشاف نقاط الضعف / التقريب. الترجمة.] ، ومع ذلك ، فإنه يتجاوز البحث عن حالات الفشل التي تسببها الدخلاء ، ويتضمن أيضًا الأخطاء التي تحدث بشكل طبيعي ، على سبيل المثال ، بسبب التعميم غير الكافي.
لقد طورنا نهجين متكاملين للاختبار التنافسي لشبكات التعلم المعززة. في البداية ، نستخدم التحسين الخالي من المشتقات لتقليل المكافأة المتوقعة بشكل مباشر. في الحالة الثانية ، نتعلم دالة للقيمة التعددية ، والتي تتنبأ في التجربة بالحالات التي قد تفشل فيها الشبكة. ثم نستخدم هذه الوظيفة المستفادة لتحسين الأداء ، مع التركيز على تقييم أكثر بيانات المدخلات إشكالية. تشكل هذه الأساليب جزءًا صغيرًا فقط من المساحة الغنية والمتنامية للخوارزميات المحتملة ، ونحن مهتمون جدًا بالتطوير المستقبلي لهذا المجال.
كلا النهجين تظهر بالفعل تحسينات كبيرة على اختبار عشوائي. باستخدام أسلوبنا ، فمن الممكن في غضون دقائق قليلة اكتشاف العيوب التي كان يجب البحث عنها مسبقًا طوال اليوم ، أو ربما لا يمكن العثور عليها على الإطلاق (
Uesato et al. ، 2018b ). لقد وجدنا أيضًا أن الاختبار التنافسي يمكن أن يكشف عن سلوك مختلف نوعيًا للشبكات مقارنةً بما يمكن توقعه من التقييم على مجموعة اختبار عشوائية. على وجه الخصوص ، باستخدام طريقتنا ، وجدنا أن الشبكات التي قامت بمهمة التوجيه على خريطة ثلاثية الأبعاد ، وعادة ما تتعامل مع ذلك على المستوى الإنساني ، لا يمكنها العثور على الهدف في متاهات بسيطة بشكل غير متوقع (
Ruderman et al.، 2018 ). يؤكد عملنا أيضًا على الحاجة إلى تصميم أنظمة آمنة ضد الإخفاقات الطبيعية ، وليس فقط المنافسين.
 عند إجراء اختبارات على عينات عشوائية ، فإننا لا نرى أبدًا بطاقات ذات احتمال كبير بالفشل ، ولكن الاختبار التنافسي يدل على وجود مثل هذه البطاقات. لا يزال احتمال الفشل كبيرًا حتى بعد إزالة العديد من الجدران ، أي تبسيط الخرائط مقارنة بالخرائط الأصلية.
عند إجراء اختبارات على عينات عشوائية ، فإننا لا نرى أبدًا بطاقات ذات احتمال كبير بالفشل ، ولكن الاختبار التنافسي يدل على وجود مثل هذه البطاقات. لا يزال احتمال الفشل كبيرًا حتى بعد إزالة العديد من الجدران ، أي تبسيط الخرائط مقارنة بالخرائط الأصلية.المواصفات نموذج التدريب
يحاول الاختبار التنافسي إيجاد مثال مضاد يخالف المواصفات. غالبًا ما يبالغ في تقدير تناسق النماذج مع هذه المواصفات. من وجهة نظر رياضية ، المواصفات هي نوع من العلاقة التي يجب الحفاظ عليها بين بيانات الإدخال والإخراج للشبكة. يمكن أن يأخذ شكل الحد العلوي والسفلي أو بعض معلمات الإدخال والإخراج الرئيسية.
مستوحاة من هذه الملاحظة ، قام العديد من الباحثين (
Raghunathan et al.، 2018 ؛
Wong et al.، 2018 ؛
Mirman et al.، 2018 ؛
Wang et al.، 2018 )، بما في ذلك فريقنا من DeepMind (
Dvijotham et al.، 2018 ؛
عمل غوال وآخرون ، 2018 ) على الخوارزميات الثابتة للاختبار التنافسي. يمكن وصف ذلك هندسيًا - يمكننا تقييد (
Ehlers 2017 ،
Katz et al. 2017 ،
Mirman et al.، 2018 ) أسوأ انتهاك للمواصفات ، مما يحد من مساحة بيانات المخرجات بناءً على مجموعة من المدخلات. إذا كان هذا الحد مختلفًا عن طريق معلمات الشبكة ويمكن حسابه بسرعة ، فيمكن استخدامه أثناء التدريب. بعد ذلك ، يمكن أن تنتشر الحدود الأصلية من خلال كل طبقة من الشبكة.
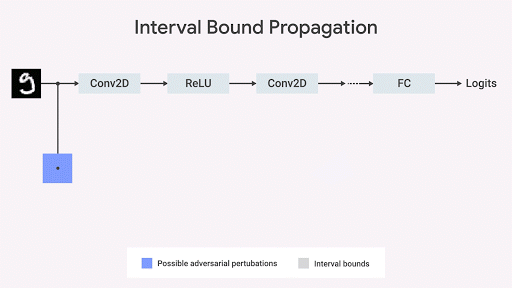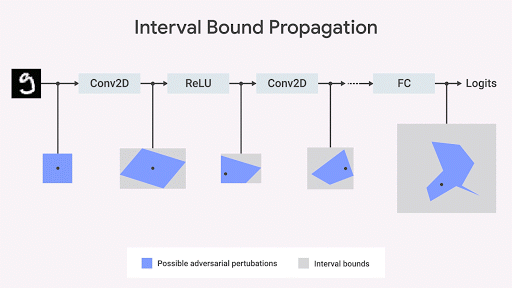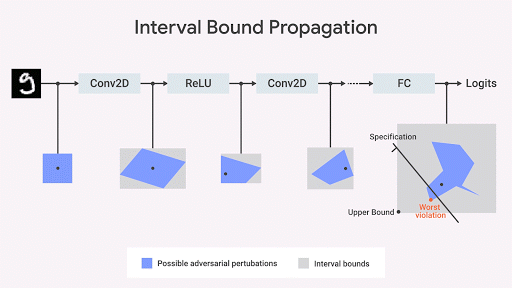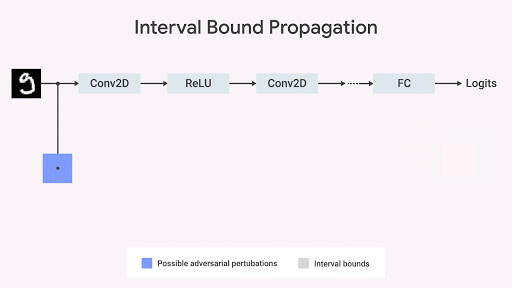
نظهر أن انتشار حدود الفاصل الزمني سريع وفعال ، وعلى عكس ما كان يعتقد سابقًا ، فإنه يعطي نتائج جيدة (
Gowal et al. ، 2018 ). على وجه الخصوص ، نظهر أنه يمكن تقليل عدد الأخطاء (أي الحد الأقصى لعدد الأخطاء التي يمكن أن يسببها أي منافس) مقارنة بأكثر مصنفات الصور تقدمًا على مجموعات من قواعد بيانات MNIST و CIFAR-10.
سيكون الهدف التالي هو دراسة التجريدات الهندسية الصحيحة لحساب التقديرات المفرطة لمساحة الإخراج. نريد أيضًا تدريب الشبكات بحيث تعمل بشكل موثوق مع مواصفات أكثر تعقيدًا تصف السلوك المطلوب ، مثل الثقل المذكور سابقًا والامتثال للقوانين الفيزيائية.
التحقق الرسمي
يمكن أن يكون الاختبار الشامل والتدريب مفيدًا للغاية في إنشاء أنظمة MO موثوقة. ومع ذلك ، لا يمكن أن يضمن الاختبار الضخم بشكل تعسفي رسميًا أن سلوك النظام يطابق رغباتنا. في النماذج واسعة النطاق ، يبدو من الصعب تنفيذ جميع خيارات الإخراج المحتملة لمجموعة معينة من المدخلات (على سبيل المثال ، تغييرات طفيفة في الصورة) بسبب العدد الفلكي للتغيرات المحتملة في الصورة. ومع ذلك ، كما في حالة التدريب ، يمكن للمرء أن يجد أساليب أكثر فعالية لوضع قيود هندسية على مجموعة بيانات المخرجات. التحقق الرسمي هو موضوع البحث المستمر في DeepMind.
طور مجتمع MO بعض الأفكار المثيرة للاهتمام لحساب الحدود الهندسية الدقيقة لمساحة إخراج الشبكة (Katz et al. 2017،
Weng et al.، 2018 ؛
Singh et al.، 2018 ).
يتكون منهجنا (
Dvijotham et al. ، 2018 ) ، استنادًا إلى التحسين والازدواجية ، من صياغة مشكلة التحقق من حيث التحسين ، والتي تحاول العثور على أكبر انتهاك للعقار الذي يتم اختباره. تصبح المهمة قابلة للحساب إذا تم استخدام الأفكار من الازدواجية في التحسين. نتيجة لذلك ، نحصل على قيود إضافية تحدد الحدود المحسوبة عند نقل الحد الفاصل [انتشار الفاصل الزمني] باستخدام ما يسمى طائرات القطع. هذا نهج موثوق به ولكنه غير مكتمل: قد تكون هناك حالات عندما تكون الخاصية التي تهمنا مقتنعة ، لكن الحدود المحسوبة بواسطة هذه الخوارزمية ليست صارمة بما فيه الكفاية بحيث يمكن إثبات وجود هذه الخاصية بشكل رسمي. ومع ذلك ، بعد استلامنا للحدود ، حصلنا على ضمان رسمي بعدم وجود انتهاكات لهذه الممتلكات. في التين. تحت هذا النهج يتضح بيانيا.

يسمح لنا هذا النهج بتوسيع إمكانية تطبيق خوارزميات التحقق على شبكات متعددة الأغراض (وظائف المنشط ، والبنى) ، والمواصفات العامة ونماذج GO الأكثر تعقيدًا (النماذج التوليفية ، والعمليات العصبية ، إلخ) والمواصفات التي تتجاوز الموثوقية التنافسية (
Qin ، 2018 ).
آفاق
ينطوي نشر أوامر الإدارة في المواقف الشديدة الخطورة على تحديات وصعوبات فريدة خاصة به ، وهذا يتطلب تطوير تقنيات التقييم المضمونة لاكتشاف الأخطاء المحتملة. نعتقد أن التدريب المتسق على المواصفات يمكن أن يحسن الأداء مقارنةً بالحالات التي تنشأ فيها المواصفات ضمنيًا من بيانات التدريب. نتطلع إلى نتائج دراسات التقييم التنافسي المستمرة ونماذج التدريب القوية والتحقق من المواصفات الرسمية.
ستكون هناك حاجة إلى المزيد من العمل حتى نتمكن من إنشاء أدوات آلية تضمن أن أنظمة الذكاء الاصطناعي في العالم الحقيقي "ستعمل كل شيء بشكل صحيح". على وجه الخصوص ، نحن سعداء جدًا للتقدم في المجالات التالية:
- التدريب على التقييم والتحقق التنافسي. مع التوسع والتطور في أنظمة الذكاء الاصطناعي ، أصبح من الصعب على نحو متزايد تصميم خوارزميات التقييم والتحقق التنافسي التي يتم تكييفها بما يكفي لنموذج الذكاء الاصطناعي. إذا استطعنا استخدام القوة الكاملة لمنظمة العفو الدولية للتقييم والتحقق ، فيمكن قياس هذه العملية.
- تطوير الأدوات المتاحة للجمهور للتقييم والتحقق التنافسي: من المهم تزويد المهندسين وغيرهم من الأشخاص الذين يستخدمون الذكاء الاصطناعى بأدوات سهلة الاستخدام تسلط الضوء على الأنماط المحتملة لفشل نظام الذكاء الاصطناعي قبل أن يؤدي هذا الفشل إلى عواقب سلبية واسعة النطاق. سيتطلب ذلك بعض التوحيد القياسي للتقييمات التنافسية وخوارزميات التحقق.
- توسيع نطاق الأمثلة التنافسية. حتى الآن ، ركز الكثير من العمل على الأمثلة التنافسية على ثبات النماذج في التغييرات الصغيرة ، عادة في منطقة الصورة. لقد أصبح هذا مجالًا ممتازًا للاختبار لتطوير أساليب التقييم التنافسية والتدريب والتحقق الموثوقين. لقد بدأنا في دراسة مواصفات مختلفة للخصائص المرتبطة مباشرة بالعالم الحقيقي ، ونتطلع إلى نتائج البحوث المستقبلية في هذا الاتجاه.
- مواصفات التدريب. غالبًا ما يصعب صياغة المواصفات التي تصف السلوك "الصحيح" لأنظمة الذكاء الاصطناعي. نظرًا لأننا نقوم بإنشاء أنظمة أكثر ذكاءً قادرة على السلوك المعقد والعمل في بيئة غير منظمة ، فسوف نحتاج إلى معرفة كيفية إنشاء أنظمة يمكنها استخدام المواصفات المعدة جزئيًا ، والحصول على مزيد من المواصفات من الملاحظات.
تلتزم DeepMind بالتأثير الإيجابي على المجتمع من خلال التطوير المسؤول لنظم MO ونشرها. للتأكد من أن مساهمة المطورين مضمونة لتكون إيجابية ، نحتاج إلى التعامل مع العديد من العوائق الفنية. نعتزم المساهمة في هذا المجال ، ويسعدنا العمل مع المجتمع لحل هذه المشكلات.