مقدمة
بالإضافة إلى مقالتي الأخيرة ، أود أيضًا أن أتحدث عن موضوع MIM ( M ulti U ser) MIMO. لقد سبق أن ذكرت مقالًا شهيرًا جدًا للأستاذ هاردت ، حيث يقترح ، مع زملائه ، خوارزمية لفصل المستخدمين في رابط لأسفل استنادًا إلى طرق خطية ، وهي Block Diagonalization للقناة. تحتوي المقالة على عدد كبير من الاستشهادات ، وهي أيضًا منشور أساسي لأحد واجبات الاختبار. لذلك ، لماذا لا تصنع أساسيات الخوارزمية المقترحة؟
بيان المشكلة
أولاً ، لنقرر في أي مجال في موضوع MIMO سنعمل الآن.
تقليديًا ، يمكن تقسيم جميع أساليب النقل في إطار تقنية MIMO إلى مجموعتين رئيسيتين:
الهدف الرئيسي هو زيادة مناعة الضوضاء في ناقل الحركة. القنوات المكانية ، إذا كانت مبسطة ، تكرر بعضها البعض ، ونحصل على أفضل جودة نقل.
الأمثلة على ذلك:
- رموز الكتل (على سبيل المثال ، مخطط ألاموتي ) ؛
- رموز تستند إلى خوارزمية Viterbi.
الهدف الرئيسي هو زيادة سرعة النقل. لقد ناقشنا بالفعل في مقال سابق أنه في ظل ظروف معينة ، يمكن اعتبار قناة MIMO كسلسلة من قنوات SISO المتوازية. في الواقع ، هذه هي الفكرة المركزية لتعدد الإرسال المكاني: لتحقيق الحد الأقصى لعدد تدفقات المعلومات المستقلة. المشكلة الرئيسية في هذه الحالة هي قمع التداخل بين القنوات (التداخل بين القنوات) ، والذي توجد فيه عدة فئات من الحلول:
- فصل القناة الأفقية ؛
- عمودي (على سبيل المثال ، خوارزمية V-BLAST) ؛
- قطري (على سبيل المثال ، خوارزمية D-BLAST).
لكن هذا ، بالطبع ، ليس كل شيء.
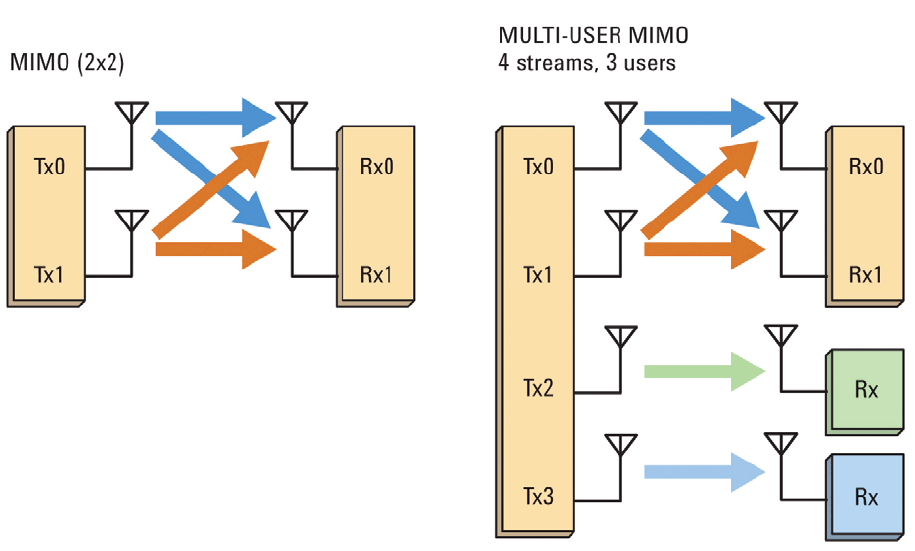
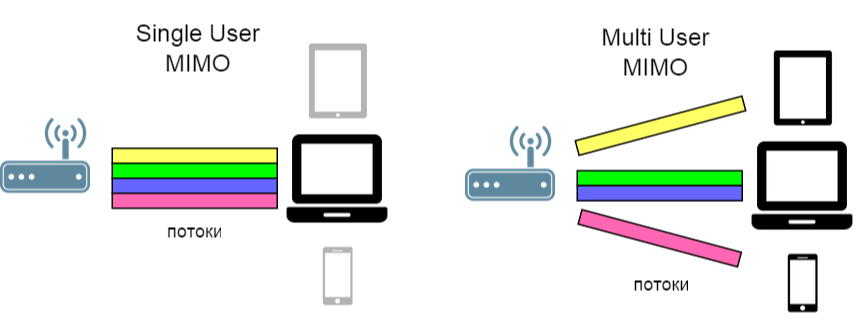
يمكن توسيع فكرة تعدد الإرسال المكاني: لتقسيم ليس فقط القنوات ، ولكن أيضًا المستخدمين (SDMA - Space Division Multi Access).
( رابط لمصدر التوضيح )
وبالتالي ، في هذه الحالة ، من الضروري بالفعل مكافحة التداخل بين المستخدمين . لهذا الغرض ، تم اقتراح خوارزمية تدعى Block diagonalization Zero-Forcing ، والتي ندرسها اليوم.
وصف رياضي
لنبدأ ، كما كان من قبل ، بنموذج الإشارة المستلمة. بتعبير أدق ، نعرض على الرسم البياني ما الذي يأتي وماذا يأتي من:

تحتوي مصفوفة القناة في هذه الحالة على الشكل:
مع إجمالي عدد هوائيات الإرسال  ، والعدد الإجمالي للهوائيات المستقبلة
، والعدد الإجمالي للهوائيات المستقبلة  .
.
مهم :
لا يمكن تطبيق هذه الخوارزمية إلا بشرط أن يكون عدد هوائيات الإرسال أكبر من أو يساوي إجمالي عدد هوائيات الاستقبال:
هذا الشرط يؤثر مباشرة على خصائص قطري.
لذلك ، يمكن كتابة نموذج الرموز المستقبلة (الإشارات) في شكل متجه على النحو التالي:
ومع ذلك ، من المثير أن ننظر إلى الصيغة لمستخدم معين:
في الواقع:
 - الضوضاء المضافة.
- الضوضاء المضافة.
لذلك نأتي إلى صياغة المهمة الرئيسية:
يمكنك العثور على هذه المصفوفات  بحيث يذهب جزء التدخل إلى الصفر!
بحيث يذهب جزء التدخل إلى الصفر!
هذا هو ما سنفعله.
وصف الخوارزمية
سنقوم بتنفيذ الوصف مع مثال ، وكتوضيح ، سأقدم لقطات شاشة مباشرة ، وأعلق عليها قليلاً.
النظر في المستخدم الأول:

دعنا نتحدث عن الخطوات الرئيسية:
- نصنع بعض المصفوفة
 من مصفوفات القناة لجميع المستخدمين الآخرين.
من مصفوفات القناة لجميع المستخدمين الآخرين.
المضي قدما:

وبالتالي سيتم تكرار هذا الإجراء لكل مستخدم. أليس هذا هو سحر الرياضيات: باستخدام أساليب الجبر الخطي ، فإننا نحل المشاكل الفنية تمامًا!
لاحظ أنه في الممارسة العملية ، لا يتم استخدام مصفوفات التشفير المسبق التي تم الحصول عليها فحسب ، بل يتم أيضًا استخدام مصفوفات ما بعد المعالجة ومصفوفة القيم الفردية (انظر الشرائح ). هذا الأخير ، على سبيل المثال ، لموازنة الطاقة وفقًا لخوارزمية صب الماء المعروفة بالفعل.
نحن نموذج الخوارزمية
أعتقد أنه لن يكون من الضروري إجراء محاكاة صغيرة لتعزيز النتيجة. للقيام بذلك ، سوف نستخدم بيثون 3 ، وهي:
import numpy as np
للحسابات الأساسية ، و:
import pandas as pd
لعرض النتيجة.
حتى لا تتراكم ، سأضع المصدر هنا class ZeroForcingBD: def __init__(self, H, Mrs_arr): Mr, Mt = np.shape(H) self.Mr = Mr self.Mt = Mt self.H = H self.Mrs_arr = Mrs_arr def __routines(self, H, mr, shift):
لنفترض أن لدينا 8 هوائيات إرسال و 3 مستخدمين لديهم 3 و 2 و 3 هوائيات استقبال ، على التوالي:
Mrs_arr = [3,2,3]
نحن نهيئ صفنا ونطبق الأساليب المناسبة:
BD = ZeroForcingBD(H, Mrs_arr) F, D, Hs = BD.process() FF = BD.obtain_matrices()
نأتي إلى شكل مقروء:
df = pd.DataFrame(np.dot(H, FF)) df[abs(df).lt(1e-14)] = 0
ودعنا نأخذ قليلاً من أجل الوضوح (على الرغم من أنه يمكنك بدون ذلك):
print(pd.DataFrame(np.round(np.real(df),100)))
يجب أن تحصل على شيء مثل هذا:

في الواقع ، ها هم الكتل ، ها هو والتقطير. وتقليل التدخل.
مثل هذه الأشياء.
أدب
- سبنسر ، كوينتين هـ ، أ. لي سويندلهرست ، ومارتن هارت. "طرق التأثير الصفري لتعدد الإرسال المكاني للوصلة الهابطة في قنوات MIMO متعددة المستخدمين." معاملات IEEE على معالجة الإشارات 52.2 (2004): 461-471.
- مارتن هارد " معالجة الإرسال القوية لأنظمة MIMO متعددة المستخدمين "
PS
لأعضاء هيئة التدريس والطلاب الأخوة في مهنتي الأم أقول مرحباً!