
- هذه المرة تم تحديد لعبة "الأفعى".
- تم إنشاء مكتبة لشبكة Go.
- تم العثور على مبدأ التعلم ، اعتمادا على "عمق" الذاكرة.
- خادم مكتوب للعبة بين المطورين.
جوهر اللعبة
ربما يتذكر الكثير من الناس لعبة "Snake" ، والتي كانت تطبيقًا قياسيًا على هواتف نوكيا. جوهرها هو: ثعبان يتحرك في جميع أنحاء الميدان ، مما يقلل إذا لم يجد الطعام ، أو زاد إذا وجد. إذا اصطدم ثعبان بعائق ، فإنه يموت.
لقد غيرت القواعد قليلاً: الثعبان لا يموت إذا تعطل ، لكنه توقف ببساطة ، واستمر في الانخفاض. بالإضافة إلى ذلك ، يمكن تقسيم الثعبان إلى النصف. إذا كان لدى الأفعى خلية واحدة في الجسم ولم تتمكن من العثور على الطعام في 10 حركات ، فماتت وتتحول إلى طعام.
سنقوم بتدريب الروبوت الذي يتحكم في الثعبان. إذا انشققت الأفعى ، فسيحصل الروبوت على ثعبان آخر ، والذي بدوره يمكن أن ينقسم.
تعتبر تجربة ثعابين عالم الأحياء الإلكتروني ميخائيل تساركوف بمثابة الأساس.
الشبكة العصبية
كجزء من المهمة ، تمت كتابة مكتبة للشبكة العصبية بلغة Go. أدرس عمل الشبكة العصبية ، وأنا استخدم مذكرات الفيديو
foo52ru وكتاب طارق راشد - إنشاء شبكة عصبية.
CreateLayer(L []int) الدالة
CreateLayer(L []int) شبكة عصبية مع العدد المطلوب من الطبقات وحجمها. في كل طبقة ، ما عدا الأخيرة ، تتم إضافة الخلايا العصبية للإزاحة. نقوم بتغذية البيانات إلى الطبقة الأولى ، ونحصل على النتيجة من الطبقة الأخيرة.
مثال:
CreateLayer([]int{9, 57, 3, 1})
هنا أنشأنا شبكة عصبية مع تسعة مدخلات. طبقتان مخفيتان من 57 و 3 من الخلايا العصبية وخلية واحدة للحصول على النتيجة. تتم إضافة الخلايا العصبية الإزاحة تلقائيًا بواسطة علامة الجمع إلى تلك التي نضعها.
تسمح لك المكتبة بما يلي:
- إرسال البيانات إلى إدخال الشبكة.
- احصل على النتيجة عن طريق الوصول إلى الطبقة الأخيرة.
- اسأل الإجابات الصحيحة وقم بإجراء التدريب من خلال ضبط أوزان الروابط.
يتم إعطاء أوزان السندات الأولية بقيم عشوائية قريبة من الصفر. للتنشيط ، استخدمنا الوظيفة اللوجستية.
بوت التدريب
يستقبل الروبوت حقل 9x9 مربعا عند المدخل ، وفي منتصفه رأس ثعبان. وفقا لذلك ، سيكون لدينا شبكة العصبية 81 المدخلات. لا يهم ترتيب الخلايا التي تغذيها المدخلات. أثناء التدريب ، "ستكتشف الشبكة" نفسها ، حيث يوجد ما يوجد.
للإشارة إلى العقبات والأفاعي الأخرى ، استخدمت القيم من 1 إلى 0 (غير شاملة). تم تعيين خلايا فارغة بقيمة 0.01 ، والغذاء 0.99.
عند إخراج الشبكة العصبية ، تم استخدام 5 خلايا عصبية للقيام بالإجراءات:
- تحرك يسارا على طول المحور X ؛
- إلى اليمين ؛
- حتى المحور y ؛
- إلى أسفل؛
- انقسام في النصف.
تم تحديد حركة الروبوت بواسطة الخلايا العصبية التي لها أكبر قيمة في الخرج.
الخطوة 0. Randomizer
أولا ، تم إنشاء العشوائية بوت. لذلك أدعو روبوت يسير بشكل عشوائي. من الضروري التحقق من فعالية الشبكة العصبية. مع التدريب المناسب ، يجب على الشبكة العصبية التغلب عليها بسهولة.
الخطوة 1. التعلم دون ذاكرة
بعد كل خطوة ، نقوم بضبط أوزان الروابط للخلايا العصبية الناتجة والتي تشير إلى أعلى قيمة. نحن لا نلمس الخلايا العصبية الإخراج الأخرى.
تم إعطاء القيم التالية للتدريب:
- العثور على الغذاء: 0.99
- قام بحركة في أي اتجاه: 0.5
- فقدت خلية جسدية دون العثور على الطعام (يتم إعطاء 10 حركات لهذا): 0.2
- لا يزال قائما (ضرب عقبة أو عالقة): 0.1
- لا يزال قائما ، وجود خلية واحدة من الجسم: 0.01
بعد هذا التدريب ، سرعان ما بدأت الروبوتات تغلب على العشوائية ، وقمت بتعيين المهمة: لإنشاء روبوتات من شأنها التغلب عليها.
اختبار A / B
لإنجاز هذه المهمة ، تم إنشاء برنامج يقسم الثعابين إلى جزأين ، اعتمادًا على تكوين الشبكة العصبية. في الحقل ، تم إنتاج 20 ثعبان من كل التكوين.
جميع الثعابين التي يسيطر عليها بوت واحد لديه نفس الشبكة العصبية. كلما زاد عدد الثعابين في إدارته ، وفي كثير من الأحيان واجهوا مهام مختلفة ، حدث التدريب الأسرع. على سبيل المثال ، إذا تعلمت ثعبان واحد تجنب الجمود أو الانقسام إلى نصفين عندما وصلت إلى طريق مسدود ، عندها اكتسبت جميع الثعابين في هذا الروبوت هذه المهارات تلقائيًا.
من خلال تغيير تكوين الشبكة العصبية ، يمكنك الحصول على نتائج جيدة ، لكن هذا لا يكفي. لتحسين الخوارزمية ، قررت استخدام الذاكرة لعدة حركات.
الخطوة 2. التعلم مع الذاكرة
لكل روبوت ، أنا خلقت ذاكرة لمدة 8 التحركات. تم تسجيل حالة الحقل والتحرك الذي اقترحه الروبوت في الذاكرة. بعد ذلك ، قمت بإجراء تعديلات على الأوزان لجميع الولايات الثمان التي سبقت هذه الخطوة. لهذا ، استخدمت عامل تصحيح واحد ، بغض النظر عن عمق السفر. وبالتالي ، أدت كل خطوة إلى تعديل الأوزان ليس مرة واحدة ، ولكن ثمانية.
كما هو متوقع ، بدأت روبوتات الذاكرة تتغلب بسرعة على الروبوتات التي تم تدريبها بدون ذاكرة.
الخطوة 3. انخفاض في معامل التصحيح اعتمادا على عمق الذاكرة
بعد ذلك ، حاولت تقليل عامل التصحيح ، اعتمادًا على عمق الذاكرة. بالنسبة إلى الخطوة الأخيرة التي تمت ، تم إنشاء أكبر معامل لضبط الأوزان. في الدورة التي سبقته ، انخفض عامل التصحيح وهلم جرا في جميع أنحاء الذاكرة.
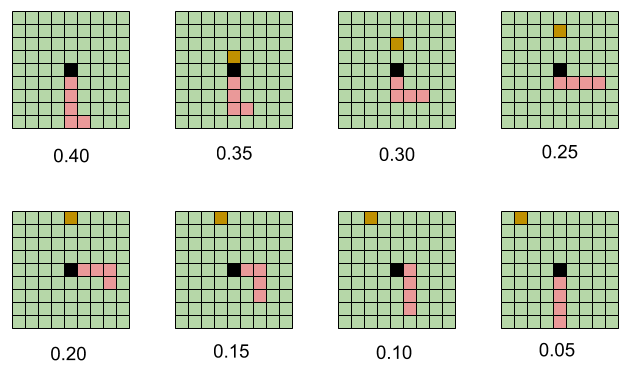
أدى الانخفاض الخطي في معامل التصحيح اعتمادًا على عمق الذاكرة إلى حقيقة أن برامج الروبوت الجديدة بدأت في التغلب على أولئك الذين استخدموا معاملًا واحدًا.
بعد ذلك ، حاولت استخدام الاختصار اللوغاريتمي لعامل التصحيح. انخفض المعامل بمقدار النصف ، وهذا يتوقف على عمق الذاكرة لكل حركة. وبالتالي ، فإن التحركات التي تم إجراؤها "منذ فترة طويلة" كان لها تأثير أقل بكثير على التعلم من التحركات "الجديدة".
بدأت السير مع انخفاض لوغاريتمي في معامل التصحيح لهزيمة الروبوتات مع علاقة خطية.
خادم لبوتات
كما اتضح ، يمكن أن يكون تحسين مستوى روبوتات "الضخ" غير محدود. وقررت إنشاء خادم حيث يمكن للمطورين التنافس مع بعضهم البعض (بغض النظر عن لغة البرمجة) في كتابة خوارزمية فعالة لـ Snakes.
بروتوكول
للحصول على إذن ، تحتاج إلى إرسال طلب GET إلى دليل "اللعبة" وتحديد اسم مستخدم ، على سبيل المثال:
.../game/?user=masterdak
بدلاً من "..." تحتاج إلى تحديد عنوان الموقع والمنفذ الذي يتم فيه نشر الخادم.
بعد ذلك ، سيصدر الخادم ردًا بتنسيق JSON للإشارة إلى الجلسة:
{"answer":"Hellow, masterdak!","session":"f4f559d1d2ed97e0616023fb4a84f984"}
بعد ذلك ، يمكنك طلب خريطة وإحداثيات الثعبان في الحقل ، وإضافة جلسة إلى الطلب:
.../game/?user=masterdak&session=f4f559d1d2ed97e0616023fb4a84f984
سيعرض الخادم شيئًا مثل هذا:
{ "answer": "Sent game data.", "data": { "area": [ ["... ..."] ], "snakes": [ { "num": 0, "body": [ { "x": 19, "y": 24 }, { "x": 19, "y": 24 }, { "x": 19, "y": 24 } ], "energe": 4, "dead": false } ] } }
سيشير حقل
المساحة إلى حالة الملعب بالقيم التالية:
0
وسيتبع ذلك مجموعة من الثعابين الموجودة في التحكم الخاصة بك.
جسد الثعبان في مجموعة
الجسم . كما ترون جسم الثعبان بأكمله (بما في ذلك الرأس - الخلية الأولى) في البداية في نفس الموضع "x": 19 ، "y": 24. هذا يرجع إلى حقيقة أن الثعابين في بداية اللعبة تخرج من الحفرة ، والتي يتم تحديدها بواسطة خلية واحدة في الحقل . علاوة على ذلك ، فإن إحداثيات الجسم والرأس تكون مختلفة.
تحدد الهياكل التالية (مثال في Go) جميع خيارات استجابة الخادم:
type respData struct { Answer string Session string Data struct { Area [][]int Snakes []struct { Num int Body []Cell Energe int Dead bool } } } type Cell struct { X int Y int }
بعد ذلك ، تحتاج إلى إرسال الخطوة التي يقوم بها الثعبان عن طريق إضافة
نقل إلى طلب GET ، على سبيل المثال:
...&move=u
يو يعني القيادة
د - أسفل ؛
ل - إلى اليسار ؛
ص - إلى اليمين ؛
/ - النصف.
سيبدو الأمر بالنسبة للعديد من الثعابين (على سبيل المثال ، لمدة سبعة) كما يلي:
...&move=ud/urld
شخصية واحدة - فريق واحد. يجب أن تحتوي الإجابة على أمر لجميع الثعابين الموجودة تحت سيطرتك. خلاف ذلك ، قد لا تتلقى بعض الثعابين أمر وسوف تستمر في العمل القديم.
يتم تحديث الحقل على فترات من 150 مللي ثانية. إذا لم يتم تلقي أي أمر خلال 60 ثانية ، فسيغلق الخادم الاتصال.
مراجع
لتفادي التحرّك ، بالنسبة إلى أولئك الذين يرغبون في رؤيتهم ، أرسلوا لي رسالة. رداً على ذلك ، سأرسل عنوان IP لخادمتي. أو يمكنك نشر الخادم الخاص بك باستخدام الكود المصدري للبرنامج.
أنا لست متخصصًا في البرمجة ولا في الشبكات العصبية. لذلك ، يمكنني أن أجعل الأخطاء. أنا نشر الرمز "كما هو". سأكون سعيدًا إذا أظهر مطورون أكثر خبرة الأخطاء التي ارتكبت.
- مكتبة للشبكة العصبية مع لعبة "Tic Tac Toe"
- ثعبان ماجستير - خادم
- ثعبان ماجستير - بوت
- SnakeWorld2
UPDقم بتحميل
عنوان IP الخاص بالخادم مؤقتًا. الآن فقط واحد عشوائي بوت (SnakeBot0) يتم إطلاق هناك. آمل أن يتعطل الخادم بسرعة.