الذكاء الاصطناعى اليوم "ضعيف" من الناحية الفنية - ومع ذلك ، فهو معقد ويمكن أن يؤثر بشكل كبير على المجتمع
 لست بحاجة إلى أن تكون سايروس دولي لتعرف إلى أي مدى يمكن أن تصبح مخيفة الذكاء [ممثلًا أمريكيًا قام بدور رائد الفضاء ديف بومان في فيلم "Space Odyssey 2001" / تقريبًا. العابرة.]
لست بحاجة إلى أن تكون سايروس دولي لتعرف إلى أي مدى يمكن أن تصبح مخيفة الذكاء [ممثلًا أمريكيًا قام بدور رائد الفضاء ديف بومان في فيلم "Space Odyssey 2001" / تقريبًا. العابرة.]الذكاء الاصطناعي ، أو الذكاء الاصطناعي ، هو الآن واحد من أهم مجالات المعرفة. يتم حل المشكلات "غير القابلة للحل" ، ويتم استثمار مليارات الدولارات ،
وتوظف Microsoft أيضًا أمرًا
مشتركًا لتخبرنا في هدوء شعري ، ما هذا الشيء الرائع - AI. هذا صحيح.
وكما هو الحال مع أي تقنية جديدة ، قد يكون من الصعب تجاوز كل هذه الضجة. لقد أجريت أبحاثًا في مجال الطائرات بدون طيار ومنظمة العفو الدولية منذ سنوات ، ولكن حتى قد يكون من الصعب علي مواكبة كل هذا. في السنوات الأخيرة ، قضيت الكثير من الوقت في البحث عن إجابات لأسهل الأسئلة مثل:
- ماذا يعني الناس بقول "AI"؟
- ما هو الفرق بين الذكاء الاصطناعي والتعلم الآلي والتعلم العميق؟
- ما هو عظيم جدا حول التعلم العميق؟
- ما هي المهام الصعبة السابقة التي يسهل حلها الآن ، وما الذي لا يزال من الصعب؟
أعلم أن لا أحد يهتم بمثل هذه الأمور. لذلك ، إذا كنت مهتمًا بما ترتبط به كل هذه الحماسات حول الذكاء الاصطناعي على أبسط المستويات ، فقد حان الوقت للنظر وراء الكواليس. إذا كنت خبيرًا في الذكاء الاصطناعى وقرأت تقارير من مؤتمر معالجة المعلومات العصبية (NIPS) من أجل المتعة ، فلن تكون هذه المقالة جديدة بالنسبة لك - ومع ذلك ، فإننا نتوقع توضيحات وتصحيحات منك في التعليقات.
ما هو الذكاء الاصطناعى؟
هناك مثل هذه النكتة القديمة في علوم الكمبيوتر: ما هو الفرق بين الذكاء الاصطناعي والأتمتة؟ الأتمتة هي شيء يمكن القيام به باستخدام الكمبيوتر ، و AI شيء نود أن نكون قادرين على القيام به. بمجرد أن نتعلم كيفية القيام بشيء ما ، ينتقل من مجال الذكاء الاصطناعي إلى فئة الأتمتة.
هذه النكتة صالحة اليوم ، نظرًا لأن الذكاء الاصطناعي لم يتم تعريفه بوضوح كاف. الذكاء الاصطناعي هو ببساطة ليس مصطلح تقني. إذا صعدت إلى ويكيبيديا ، فهذا يعني أن الذكاء الاصطناعي هو "الذكاء الذي أظهرته الآلات ، على عكس الذكاء الطبيعي الذي أظهره الناس والحيوانات الأخرى." لا يمكنك قول أقل وضوحا.
بشكل عام ، هناك نوعان من الذكاء الاصطناعي: قوي وضعيف. يتخيل معظم الناس الذكاء الاصطناعى القوي عندما يسمعون عن الذكاء الاصطناعى - إنه نوع من الفكر الشبيه بالله الذي يشبه الله مثل سكاينيت أو هال 9000 ، وهو قادر على التفكير وقابل للمقارنة بالبشر ، مع تجاوز قدراته.
الذكاء الاصطناعى الضعيف عبارة عن خوارزميات متخصصة للغاية مصممة للإجابة على أسئلة مفيدة محددة في مناطق محددة بدقة. على سبيل المثال ، يندرج ضمن هذه الفئة برنامج جيد للشطرنج. يمكن قول الشيء نفسه عن البرامج التي تقوم بضبط مدفوعات التأمين بدقة شديدة. في مجال عملهم ، تحقق مثل هذه الأدوات نتائج رائعة ، ولكن بشكل عام محدودة للغاية.
باستثناء معارضة هوليود ، لم نقترب اليوم من منظمة العفو الدولية القوية. حتى الآن ، أي الذكاء الاصطناعى ضعيف ، ويتفق معظم الباحثين في هذا المجال على أن التقنيات التي اخترعناها لإنشاء الذكاء الاصطناعى الضعيف الكبير من غير المرجح أن تقربنا من إنشاء الذكاء الاصطناعى القوي.
لذا ، فإن الذكاء الاصطناعي اليوم هو مصطلح تسويقي أكثر منه مصطلح تقني. السبب الذي يجعل الشركات تعلن عن الذكاء الاصطناعي الخاص بها بدلاً من الأتمتة هو أنها تريد إدخال هوليوود الذكاء الاصطناعي في أذهان الجمهور. ومع ذلك ، هذا ليس سيئا للغاية. إذا لم يتم أخذ هذا بصرامة شديدة ، فإن الشركات لا ترغب إلا في القول إنه على الرغم من أننا لا نزال بعيدين عن الذكاء الاصطناعي القوي ، فإن الذكاء الاصطناعي الضعيف اليوم هو أكثر قدرة مما كان عليه الحال قبل عدة سنوات.
وإذا كنت تصرف الانتباه عن التسويق ، فهذا هو الحال. في مناطق معينة ، زادت إمكانات الآلات بشكل كبير ، ويعود الفضل في ذلك إلى جملتين أخريين أصبحتا الآن رائعتين: التعلم الآلي والتعلم العميق.
 تم تصويره من مقطع فيديو قصير من مهندسي Facebook يوضح كيف يتعرف الذكاء الاصطناعي في الوقت الفعلي على القطط (وهي مهمة تعرف أيضًا باسم الكأس المقدسة للإنترنت)
تم تصويره من مقطع فيديو قصير من مهندسي Facebook يوضح كيف يتعرف الذكاء الاصطناعي في الوقت الفعلي على القطط (وهي مهمة تعرف أيضًا باسم الكأس المقدسة للإنترنت)تعلم الآلة
MO هي طريقة خاصة لإنشاء ذكاء الجهاز. لنفترض أنك تريد إطلاق صاروخ ، وتوقع إلى أين سيذهب. بشكل عام ، ليس الأمر صعبًا: فالجاذبية مدروسة جيدًا ، يمكنك كتابة المعادلات وحساب أين ستذهب ، استنادًا إلى العديد من المتغيرات - مثل السرعة والموضع الأولي.
ومع ذلك ، يصبح هذا النهج محرجًا إذا انتقلنا إلى منطقة ليست قواعدها معروفة تمامًا وواضحة. افترض أنك تريد أن يخبرك الكمبيوتر إذا كانت هناك أي قطط في بعض الصور. كيف يمكنك كتابة القواعد التي تصف طريقة العرض في جميع وجهات النظر الممكنة على جميع المجموعات الممكنة من الشارب والأذنين؟
اليوم ، أسلوب MO معروف جيدًا: بدلاً من محاولة تدوين جميع القواعد ، يمكنك إنشاء نظام يمكنه اشتقاق مجموعة من القواعد الداخلية بشكل مستقل بعد دراسة عدد كبير من الأمثلة. بدلاً من وصف القطط ، يمكنك ببساطة عرض الذكاء الاصطناعي الخاص بك على مجموعة من صور القطط ، والسماح له بأن يفهم بمفرده ما هو القط وما هو ليس كذلك.
واليوم هو النهج المثالي. يمكن تحسين نظام التعلم الذاتي القائم على البيانات ببساطة عن طريق إضافة البيانات. وإذا كان بإمكان جنسنا أن يفعل شيئًا جيدًا ، فهو توليد وتخزين وإدارة البيانات. تريد أن تتعلم كيفية التعرف بشكل أفضل القطط؟ تولد الإنترنت ملايين الأمثلة في هذه اللحظة.
يعد التدفق المتزايد باستمرار للبيانات أحد أسباب النمو الهائل لخوارزميات MO في الآونة الأخيرة. وترتبط أسباب أخرى لاستخدام هذه البيانات.
بالإضافة إلى البيانات ، هناك مسألتان أخريان تتعلقان بهذا في منطقة موسكو:
- كيف أتذكر ما تعلمته؟ كيفية تخزين وتقديم الاتصالات والقواعد التي استنتجتها من جهاز الكمبيوتر؟
- كيف اتعلم؟ كيفية تغيير التمثيل المخزن استجابة لأمثلة جديدة ، وتحسين؟
بمعنى آخر ، ما الذي يتم تدريبه بالضبط على أساس كل هذه البيانات؟
في MO ، يمثل التمثيل الحسابي للتدريب الذي نخزنه نموذجًا. نوع النموذج المستخدم مهم للغاية: فهو يحدد كيفية تعلم الذكاء الاصطناعى الخاص بك والبيانات التي يمكن أن تتعلم منها والأسئلة التي يمكنك طرحها.
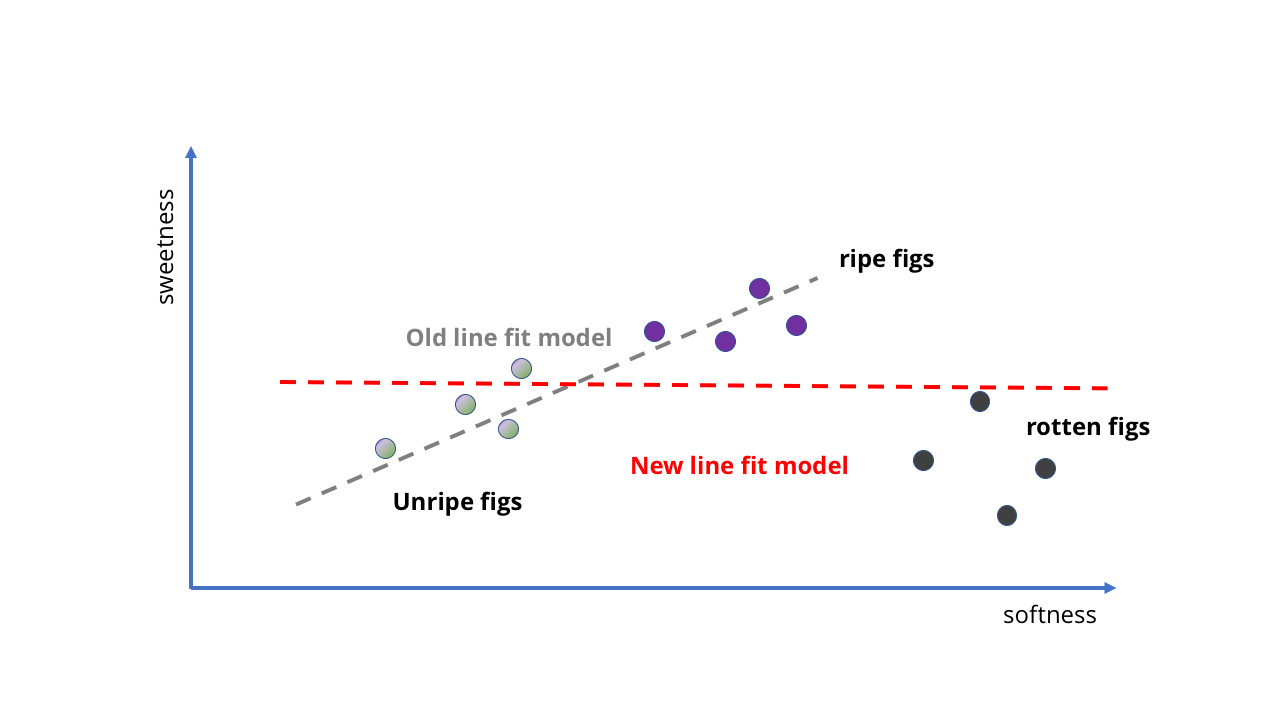
دعونا ننظر إلى مثال بسيط للغاية. لنفترض أننا نشتري التين من متجر البقالة ونريد أن نصنع AI مع MO من شأنه أن يخبرنا ما إذا كان قد حان. يجب أن يكون ذلك سهلاً ، لأنه في حالة التين ، يكون ليونة أحلى.
يمكننا أن نأخذ عدة عينات من التين الناضج وغير الناضج ، ونرى مدى جمالها ، ثم نضعها على الرسم البياني ونضبط الخط المستقيم لها. هذا الخط سيكون نموذجنا.
 الجنين AI في شكل "ليونة أحلى"
الجنين AI في شكل "ليونة أحلى" مع إضافة بيانات جديدة ، تصبح المهمة أكثر تعقيدًا.
مع إضافة بيانات جديدة ، تصبح المهمة أكثر تعقيدًا.ألقِ نظرة! يتبع الخط المستقيم ضمنيًا الفكرة القائلة "ليونة ، أحلى" ، ولم يكن علينا حتى كتابة أي شيء. لا يعرف جنين AI أي شيء عن محتوى السكر أو الثمار الناضجة ، ولكن يمكنه التنبؤ بحلاوة الثمرة عن طريق عصرها.
كيفية تدريب نموذج لجعله أفضل؟ يمكننا جمع المزيد من العينات ورسم خط مستقيم آخر للحصول على تنبؤات أكثر دقة (كما في الصورة الثانية أعلاه). ومع ذلك ، فإن المشاكل تصبح واضحة على الفور. حتى الآن ، قمنا بتدريب التين AI على التوت عالي الجودة - ماذا لو أخذنا البيانات من البستان؟ فجأة ، ليس لدينا نضج فحسب ، بل ثمار فاسدة أيضًا. أنها لينة جدا ، ولكن بالتأكيد ليست مناسبة لتناول الطعام.
ماذا نفعل؟ حسنًا ، نظرًا لأن هذا نموذج MO ، يمكننا فقط تزويدها بمزيد من البيانات ، أليس كذلك؟
كما تظهر الصورة الأولى أدناه ، في هذه الحالة ، سنحصل على نتائج لا معنى لها تمامًا. الخط ببساطة غير مناسب لوصف ما يحدث عندما تصبح الثمرة ناضجة جدًا. نموذجنا لم يعد يناسب هيكل البيانات.
بدلاً من ذلك ، يتعين علينا تغييره ، واستخدام نموذج أفضل وأكثر تعقيدًا - ربما قطع مكافئ أو شيء مشابه. هذا التغيير يعقد التعلم لأن منحنيات الرسم تتطلب رياضيات أكثر تطوراً من رسم خط مستقيم.
 حسنًا ، ربما لم تكن فكرة استخدام خط مستقيم للحصول على الذكاء الاصطناعي المعقد ناجحة جدًا
حسنًا ، ربما لم تكن فكرة استخدام خط مستقيم للحصول على الذكاء الاصطناعي المعقد ناجحة جدًا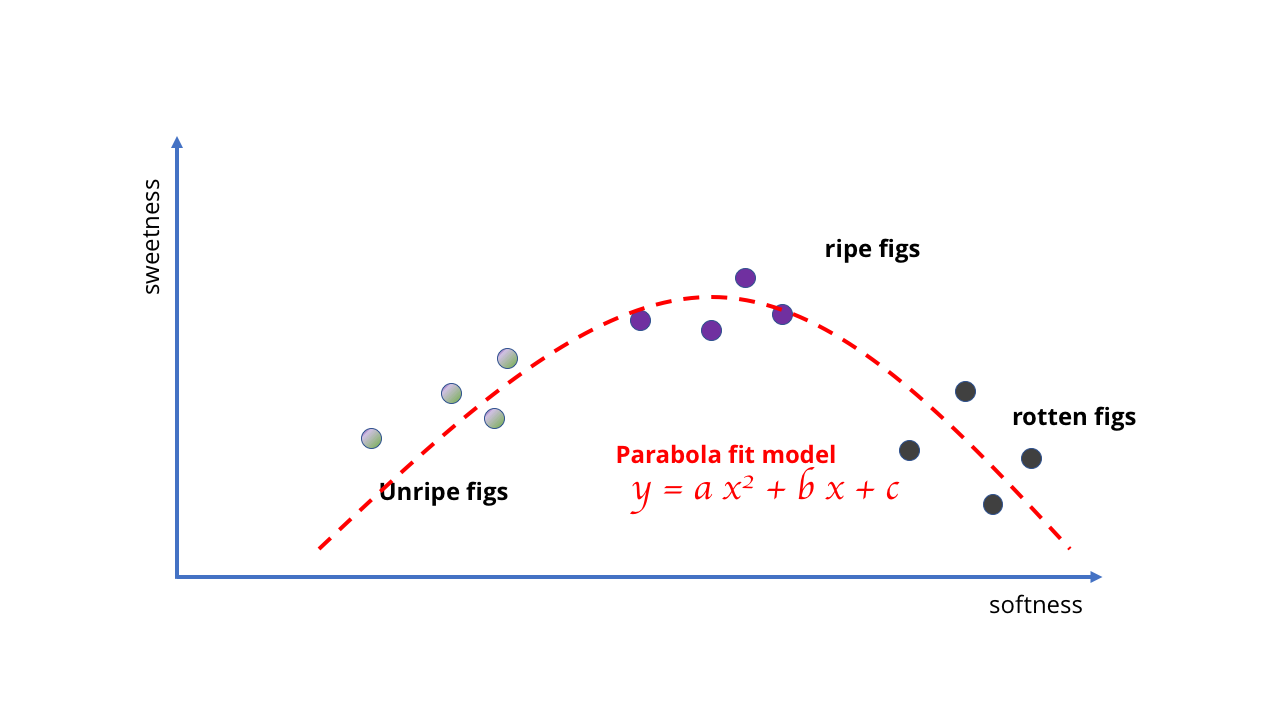 الرياضيات أكثر تعقيدا المطلوبة
الرياضيات أكثر تعقيدا المطلوبةالمثال غبي إلى حد ما ، لكنه يوضح أن اختيار النموذج يحدد فرص التعلم. في حالة التين ، تكون البيانات بسيطة ، ويمكن أن تكون النماذج بسيطة. ولكن إذا كنت تحاول معرفة شيء أكثر تعقيدًا ، فهناك نماذج أكثر تعقيدًا مطلوبة. تمامًا مثل عدم وجود كمية من البيانات تجعل النموذج الخطي يعكس سلوك التوت الفاسد ، فمن المستحيل تحديد منحنى بسيط يتوافق مع مجموعة من الصور لإنشاء خوارزمية رؤية الكمبيوتر.
لذلك ، تكمن صعوبة MO في إنشاء النماذج المناسبة للمهام المقابلة وتحديدها. نحتاج إلى نموذج معقد بما فيه الكفاية لوصف العلاقات والهياكل المعقدة حقًا ، ولكنه بسيط بما يكفي حتى تتمكن من العمل معها وتدريبها. لذلك ، على الرغم من أن الإنترنت والهواتف الذكية وما إلى ذلك قد خلقت جبال لا تصدق من البيانات للتعلم منها ، ما زلنا بحاجة إلى النماذج الصحيحة للاستفادة من هذه البيانات.
هذا هو المكان الذي يأتي دور التعلم العميق.

التعلم العميق
التعلم العميق هو التعلم الآلي الذي يستخدم نوعًا معينًا من النماذج: الشبكات العصبية العميقة.
الشبكات العصبية هي نوع من نموذج MO يستخدم بنية تشبه الخلايا العصبية في الدماغ لإجراء العمليات الحسابية والتنبؤات. يتم تنظيم الخلايا العصبية في الشبكات العصبية في طبقات: كل طبقة تنفذ مجموعة من العمليات الحسابية البسيطة وتمرير الجواب إلى التالي.
يسمح نموذج الطبقات لإجراء عمليات حسابية أكثر تعقيدًا. شبكة بسيطة تحتوي على عدد صغير من طبقات الخلايا العصبية كافية لإعادة إنتاج الخط المستقيم أو القطع المكافئ الذي استخدمناه أعلاه. الشبكات العصبية العميقة هي شبكات عصبية بها عدد كبير من الطبقات ، مع العشرات ، أو حتى المئات ؛ وبالتالي اسمهم. مع العديد من الطبقات ، يمكنك إنشاء نماذج قوية بشكل لا يصدق.
هذه الفرصة هي واحدة من الأسباب الرئيسية لشعبية كبيرة من الشبكات العصبية العميقة في الآونة الأخيرة. يمكنهم تعلم العديد من الأشياء المعقدة دون إجبار باحث بشري على تحديد أي قواعد ، وهذا سمح لنا بإنشاء خوارزميات يمكنها حل مجموعة متنوعة من المشكلات التي لم تتمكن أجهزة الكمبيوتر من معالجتها من قبل.
ومع ذلك ، ساهم جانب آخر في نجاح الشبكات العصبية: التدريب.
"ذاكرة" النموذج عبارة عن مجموعة من المعلمات العددية التي تحدد كيفية تقديم إجابات للأسئلة المطروحة. لتدريب نموذج يعني صقل هذه المعلمات بحيث يعطي النموذج أفضل الإجابات الممكنة.
في نموذجنا مع التين ، بحثنا عن معادلة الخط. هذه مهمة انحدار بسيطة ، وهناك صيغ تعطيك الإجابة في خطوة واحدة.
 شبكة عصبية بسيطة وشبكة عصبية عميقة
شبكة عصبية بسيطة وشبكة عصبية عميقةمع النماذج الأكثر تعقيدًا ، الأمور ليست بهذه البساطة. يمكن بسهولة تمثيل خط مستقيم ومكافئ بعدة أرقام ، ولكن يمكن أن تحتوي الشبكة العصبية العميقة على ملايين المعلمات ، كما يمكن أن تتكون البيانات المخصصة للتدريب من ملايين الأمثلة. الحل التحليلي في خطوة واحدة غير موجود.
لحسن الحظ ، هناك خدعة غريبة واحدة: يمكنك البدء بشبكة عصبية سيئة ، ثم تحسينها بتعديل تدريجي.
تعلم نموذج MO بهذه الطريقة يشبه اختبار الطالب باستخدام الاختبارات. في كل مرة نحصل على تقييم من خلال مقارنة الإجابات التي يجب أن تكون في رأي النموذج مع الإجابات "الصحيحة" في بيانات التدريب. ثم نجري تحسنا ونجري الاختبار مرة أخرى.
كيف نعرف المعلمات التي يجب ضبطها ، وكم؟ تتمتع الشبكات العصبية بمثل هذه الميزة الرائعة عندما لا تتمكن من الحصول على تقييم في الاختبار للعديد من أنواع التدريب فحسب ، بل يمكنك أيضًا حساب مقدار ما سيتغير استجابةً للتغيير في كل معلمة. من الناحية الرياضية ، التقدير عبارة عن دالة ذات قيمة ، وبالنسبة لمعظم هذه الوظائف يمكننا بسهولة حساب تدرج هذه الوظيفة فيما يتعلق بمساحة المعلمة.
الآن نحن نعرف بالضبط الطريقة التي نحتاج بها لضبط المعلمات لزيادة النتيجة ، ويمكننا ضبط الشبكة من خلال خطوات متتالية في كل "أفضل" وأفضل "الاتجاهات" ، حتى تصل إلى نقطة حيث لا يمكن تحسين أي شيء. يُشار إلى هذا غالبًا على أنه تسلق التل ، لأنه يشبه فعلًا رفع أعلى التل: إذا كنت تتحرك باستمرار للأعلى ، فسوف ينتهي بك الأمر في المقدمة.
 هل رأيت أعلى!
هل رأيت أعلى!بفضل هذا ، من السهل تحسين الشبكة العصبية. إذا كانت شبكتك تتمتع ببنية جيدة ، وقد استلمت بيانات جديدة ، فلن تحتاج إلى البدء من نقطة الصفر. يمكنك البدء بالمعلمات المتاحة وإعادة التعلم من البيانات الجديدة. سوف تتحسن شبكتك تدريجيا. إن أبرز أدوات الذكاء الاصطناعي اليوم - بدءًا من التعرف على القطط على Facebook وحتى التقنيات التي تستخدمها Amazon (على الأرجح) في المتاجر دون البائعين - مبنية على هذه الحقيقة البسيطة.
هذا هو المفتاح لسبب آخر لانتشار الدفاع المدني بهذه السرعة وعلى نطاق واسع: تسلق التل يسمح لك بأخذ شبكة عصبية مدربة على بعض المهام وإعادة تدريبها لأداء أخرى ، ولكن مماثلة. إذا كنت قد دربت منظمة العفو الدولية على التعرف على القطط جيدًا ، يمكن استخدام هذه الشبكة لتدريب الذكاء الاصطناعي الذي يتعرف على الكلاب أو الزرافات دون الحاجة إلى البدء من نقطة الصفر. ابدأ باستخدام الذكاء الاصطناعي للقطط ، وقم بتقييمه من خلال جودة التعرف على الكلاب ، ثم تسلق التل ، مما يحسن الشبكة!
لذلك ، في السنوات 5-6 الماضية ، كان هناك تحسن حاد في قدرات الذكاء الاصطناعي. اجتمعت عدة أجزاء من اللغز بطريقة تآزرية: أنتجت الإنترنت كمية هائلة من البيانات للتعلم منها. جعلت الحسابات ، وخاصة الحسابات الموازية على وحدات معالجة الرسومات ، من الممكن معالجة هذه المجموعات الضخمة. أخيرًا ، أتاحت الشبكات العصبية العميقة الاستفادة من هذه المجموعات وإنشاء نماذج MO قوية بشكل لا يصدق.
وكل هذا يعني أن بعض الأشياء التي كانت صعبة للغاية في السابق أصبحت سهلة للغاية الآن.
وماذا يمكننا أن نفعل الآن؟ التعرف على الأنماط
ربما كان الأعمق (آسف للتورية) والتأثير المبكر للتعلم العميق كان في مجال رؤية الكمبيوتر - على وجه الخصوص ، على التعرف على الأشياء في الصور الفوتوغرافية. قبل بضع سنوات ، وصف هذا الكوميديا xkcd تمامًا المتطورة في علوم الكمبيوتر:

اليوم ، يعد التعرف على الطيور وحتى أنواع معينة من الطيور مهمة تافهة يستطيع حلها طالب ثانوي ذو دوافع صحيحة. ما الذي تغير؟
من السهل وصف فكرة التعرف المرئي على الكائنات ، ولكن يصعب تنفيذها: تتكون الكائنات المعقدة من مجموعات من العناصر الأبسط ، والتي تتكون بدورها من أشكال وخطوط أبسط. تتكون الوجوه من عيون وأنف وفم ، وتتكون الوجوه من دوائر وخطوط ، وهكذا.
لذلك ، يصبح التعرف على الوجوه مسألة التعرف على الأنماط التي تقع فيها العينين والفم ، والتي قد تتطلب التعرف على شكل العين والفم من الخطوط والدوائر.
تسمى هذه الأنماط بالميزات ، وقبل التعلم العميق للتعرف عليها ، كان من الضروري وصف جميع الميزات يدويًا وبرمجة الكمبيوتر للعثور عليها. على سبيل المثال ، هناك خوارزمية للتعرف على الوجوه الشهيرة
Viola-Jones ، استنادًا إلى حقيقة أن الحواجب والأنف عادة ما تكون أخف وزناً من مآخذ العين ، بحيث تشكل شكل T مشرق مع نقطتين مظلمتين. الخوارزمية ، في الواقع ، تبحث عن أشكال T مماثلة.
طريقة فيولا جونز تعمل بشكل جيد وسريع بشكل مدهش ، وهي بمثابة أساس للتعرف على الوجوه في الكاميرات الرخيصة ، إلخ. لكن من الواضح أن كل شيء تحتاج إلى إدراكه يفسر مثل هذا التبسيط ، وقد توصل الناس إلى أنماط متزايدة التعقيد ومنخفضة المستوى. لكي تعمل الخوارزميات بشكل صحيح ، كان مطلوبًا من فريق من أطباء العلوم ، كانوا حساسين جدًا وعرضة للفشل.
جاء الاختراق الكبير بفضل الدفاع المدني ، وخاصةً لنوع معين من الشبكات العصبية تسمى الشبكة العصبية التلافيفية. الشبكات العصبية التلافيفية ، SNS هي شبكات عميقة ذات بنية معينة ، مستوحاة من بنية القشرة البصرية للدماغ الثدييات. تتيح هذه البنية لنظام الحسابات القومية أن يتعلم بشكل مستقل التسلسل الهرمي للخطوط والأنماط للتعرف على الأشياء ، بدلاً من انتظار الأطباء لقضاء سنوات في البحث عن الميزات الأكثر ملاءمة لذلك.
على سبيل المثال ، سوف يتعلم نظام الحسابات القومية ، المدربين على الوجوه ، تمثيله الداخلي للخطوط والدوائر التي تتشكل في العيون والأذنين والأنوف ، وما إلى ذلك.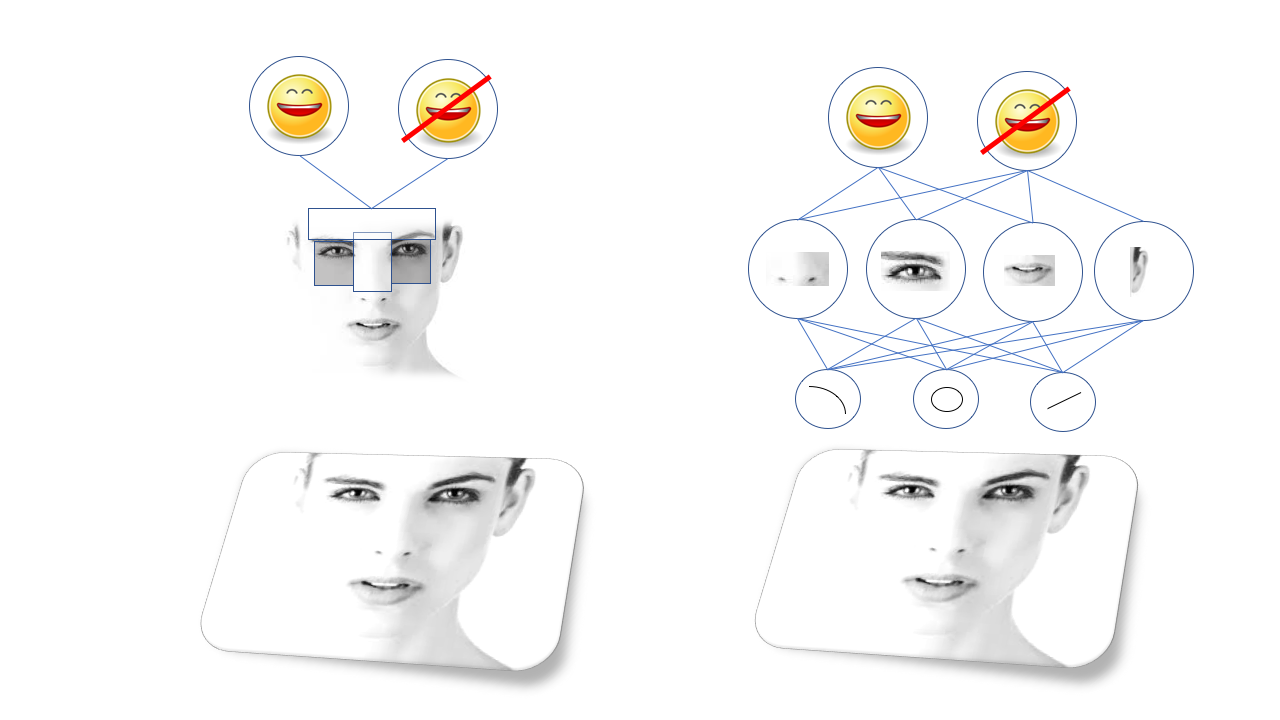 تعتمد الخوارزميات المرئية القديمة (طريقة Viola-Jones ، على اليسار) على الميزات المحددة يدويًا ، والشبكات العصبية العميقة (على اليمين) على التسلسل الهرمي الخاص بها من الميزات الأكثر تعقيدًا المكونة منأنظمة الحسابات القومية أبسط كانت جيدة بشكل مذهل لرؤية الكمبيوتر ، وقريبا تمكن الباحثون من تدريبهم على أداء جميع أنواع المهام للتعرف البصري ، من العثور على القطط في الصورة إلى تحديد المشاة الذين يتم القبض عليهم في كاميرا سيارة آلية.كل هذا رائع ، ولكن هناك سبب آخر لمثل هذا الانتشار السريع والواسع النطاق لنظام الحسابات القومية - وهذا هو مدى سهولة التكيف. تذكر تسلق التل؟ إذا أراد طالب مدرستنا الثانوية التعرف على طائر معين ، فيمكنه أن يأخذ أيًا من الشبكات المرئية العديدة برمز مفتوح ، ويدربها على مجموعة البيانات الخاصة به ، حتى دون فهم كيفية عمل الرياضيات التي تقوم عليها.بطبيعة الحال ، يمكن توسيع هذا أبعد من ذلك.
تعتمد الخوارزميات المرئية القديمة (طريقة Viola-Jones ، على اليسار) على الميزات المحددة يدويًا ، والشبكات العصبية العميقة (على اليمين) على التسلسل الهرمي الخاص بها من الميزات الأكثر تعقيدًا المكونة منأنظمة الحسابات القومية أبسط كانت جيدة بشكل مذهل لرؤية الكمبيوتر ، وقريبا تمكن الباحثون من تدريبهم على أداء جميع أنواع المهام للتعرف البصري ، من العثور على القطط في الصورة إلى تحديد المشاة الذين يتم القبض عليهم في كاميرا سيارة آلية.كل هذا رائع ، ولكن هناك سبب آخر لمثل هذا الانتشار السريع والواسع النطاق لنظام الحسابات القومية - وهذا هو مدى سهولة التكيف. تذكر تسلق التل؟ إذا أراد طالب مدرستنا الثانوية التعرف على طائر معين ، فيمكنه أن يأخذ أيًا من الشبكات المرئية العديدة برمز مفتوح ، ويدربها على مجموعة البيانات الخاصة به ، حتى دون فهم كيفية عمل الرياضيات التي تقوم عليها.بطبيعة الحال ، يمكن توسيع هذا أبعد من ذلك.من هناك؟ (التعرف على الوجوه)
لنفترض أنك تريد تدريب شبكة لا تتعرف فقط على الوجوه ، ولكن على وجه معين. يمكنك تدريب الشبكة على التعرف على شخص معين ، ثم شخص آخر ، وهلم جرا. ومع ذلك ، فإن تدريب الشبكات يستغرق وقتًا ، وهذا يعني أنه بالنسبة لكل شخص جديد ، سيكون من الضروري إعادة تدريب الشبكة. لا حقا.بدلاً من ذلك ، يمكننا أن نبدأ بشبكة مدربة للتعرف على الوجوه بشكل عام. يتم تكوين الخلايا العصبية لها للتعرف على جميع الهياكل الوجه: العينين والأذنين والفم ، وهلم جرا. ثم تقوم فقط بتغيير الإخراج: بدلاً من إجبارها على التعرف على الوجوه المعينة ، فإنك تطلب منها إعطاء وصف للوجه في شكل مئات الأرقام التي تصف انحناء الأنف أو شكل العينين ، وهكذا. يمكن للشبكة القيام بذلك لأنها "تعرف" بالفعل المكونات التي يتكون منها الوجه.بالطبع ، أنت لا تحدد كل هذا مباشرة. بدلاً من ذلك ، تقوم بتدريب الشبكة من خلال إظهار مجموعة من الوجوه ، ثم مقارنة الإخراج. أنت تعلمها أيضًا حتى تعطي وصفًا مشابهًا لبعضها البعض للشخص نفسه ، وتختلف تمامًا عن الأوصاف الأخرى لأشخاص مختلفين. من الناحية الرياضية ، تقوم بتدريب شبكة لإنشاء مراسلات لصور وجوه نقطة ما في مساحة من الميزات ، حيث يمكن استخدام المسافة الديكارتية بين النقاط لتحديد تشابهها. يتطلب تغيير الشبكة العصبية من التعرف على الوجوه (على اليسار) إلى وصف الوجوه (على اليمين) تغيير تنسيق بيانات المخرجات فقط ، دون تغيير أساسها.
يتطلب تغيير الشبكة العصبية من التعرف على الوجوه (على اليسار) إلى وصف الوجوه (على اليمين) تغيير تنسيق بيانات المخرجات فقط ، دون تغيير أساسها. الآن يمكنك التعرف على الوجوه من خلال مقارنة أوصاف كل الوجوه التي أنشأتها الشبكة العصبية.بعد تدريب الشبكة ، يمكنك التعرف بسهولة على الوجوه. كنت تأخذ الشخص الأصلي والحصول على وصفه. ثم خذ وجهًا جديدًا وقارن الوصف الذي توفره الشبكة مع الأصل. إذا كانت قريبة بما فيه الكفاية ، فأنت تقول أنه شخص واحد. والآن انتقلت من شبكة قادرة على التعرف على وجه واحد إلى ما يمكن استخدامه للتعرف على أي وجه!هذه المرونة الهيكلية هي سبب آخر لفائدة الشبكات العصبية العميقة. لقد تم بالفعل تطوير عدد كبير من نماذج MO المختلفة لرؤية الكمبيوتر ، وعلى الرغم من أنها تتطور في اتجاهات مختلفة تمامًا ، فإن الهيكل الأساسي للعديد منها يعتمد على حسابات مبكرة مثل Alexnet و Resnet.لقد سمعت قصصًا عن أشخاص يستخدمون الشبكات العصبية المرئية للعمل مع بيانات السلاسل الزمنية أو قياسات أجهزة الاستشعار. بدلاً من إنشاء شبكة خاصة لتحليل تدفق البيانات ، قاموا بتدريب شبكة عصبية مفتوحة المصدر مصممة لرؤية الكمبيوتر من أجل النظر حرفيًا في أشكال الرسوم البيانية الخطية.هذه المرونة هي شيء جيد ، ولكن ليس لانهائي. لحل بعض المشكلات الأخرى ، تحتاج إلى استخدام أنواع أخرى من الشبكات.
الآن يمكنك التعرف على الوجوه من خلال مقارنة أوصاف كل الوجوه التي أنشأتها الشبكة العصبية.بعد تدريب الشبكة ، يمكنك التعرف بسهولة على الوجوه. كنت تأخذ الشخص الأصلي والحصول على وصفه. ثم خذ وجهًا جديدًا وقارن الوصف الذي توفره الشبكة مع الأصل. إذا كانت قريبة بما فيه الكفاية ، فأنت تقول أنه شخص واحد. والآن انتقلت من شبكة قادرة على التعرف على وجه واحد إلى ما يمكن استخدامه للتعرف على أي وجه!هذه المرونة الهيكلية هي سبب آخر لفائدة الشبكات العصبية العميقة. لقد تم بالفعل تطوير عدد كبير من نماذج MO المختلفة لرؤية الكمبيوتر ، وعلى الرغم من أنها تتطور في اتجاهات مختلفة تمامًا ، فإن الهيكل الأساسي للعديد منها يعتمد على حسابات مبكرة مثل Alexnet و Resnet.لقد سمعت قصصًا عن أشخاص يستخدمون الشبكات العصبية المرئية للعمل مع بيانات السلاسل الزمنية أو قياسات أجهزة الاستشعار. بدلاً من إنشاء شبكة خاصة لتحليل تدفق البيانات ، قاموا بتدريب شبكة عصبية مفتوحة المصدر مصممة لرؤية الكمبيوتر من أجل النظر حرفيًا في أشكال الرسوم البيانية الخطية.هذه المرونة هي شيء جيد ، ولكن ليس لانهائي. لحل بعض المشكلات الأخرى ، تحتاج إلى استخدام أنواع أخرى من الشبكات. وحتى إلى هذه النقطة ، استغرق المساعدين الظاهري وقتا طويلا جدا
وحتى إلى هذه النقطة ، استغرق المساعدين الظاهري وقتا طويلا جداماذا قلت؟ (التعرف على الكلام)
فهرسة الصور ورؤية الكمبيوتر ليستا المجاالت الوحيدة لظهور الذكاء الاصطناعى. المجال الآخر الذي قطعت فيه أجهزة الكمبيوتر بعيدًا هو التعرف على الكلام ، وخاصة في ترجمة الكلام إلى الكتابة.تتشابه الفكرة الأساسية في التعرف على الكلام مع مبدأ رؤية الكمبيوتر: التعرف على الأشياء المعقدة في شكل مجموعات أبسط منها. في حالة الكلام ، يعتمد التعرف على الجمل والعبارات على التعرف على الكلمات ، والذي يستند إلى التعرف على المقاطع الصوتية ، أو ، على نحو أكثر دقة ، الصوتيات. لذلك عندما يقول شخص ما "بوند ، جيمس بوند" ، نسمع فعلاً BON + DUH + JAY + MMS + BON + DUH.في الرؤية ، يتم تنظيم الميزات مكانيًا ، ويقوم نظام الحسابات القومية بمعالجة هذا الهيكل. في الشائعات ، يتم تنظيم هذه الميزات في الوقت المناسب. يمكن للناس التحدث بسرعة أو ببطء ، دون بداية واضحة ونهاية الكلام. نحتاج إلى نموذج قادر على إدراك الأصوات فور وصولها ، كشخص ، بدلاً من الانتظار والبحث عن جمل كاملة فيها. لا يمكننا ، كما في الفيزياء ، أن نقول إن المكان والزمان متماثلان.من السهل إلى حد ما التعرف على المقاطع الفردية ، لكن يصعب عزلها. على سبيل المثال ، قد يبدو "Hello there" مثل "hell no they're" ... لذلك بالنسبة لأي تسلسل للأصوات ، عادةً ما توجد عدة مجموعات من المقاطع المنطوقة بالفعل.لفهم كل هذا ، نحتاج إلى فرصة لدراسة التسلسل في سياق معين. إذا سمعت صوتًا ، فمن الأرجح أن يكون الشخص قد قال "مرحباً يا عزيزي" أو "لا بحق الجحيم إنهم الغزلان؟" هنا مرة أخرى ، يأتي التعلم الآلي في عملية الإنقاذ. مع مجموعة كبيرة بما فيه الكفاية من أنماط الكلمات المنطوقة ، يمكنك تعلم العبارات الأكثر احتمالا. والمزيد من الأمثلة لديك ، كلما كان ذلك أفضل.لهذا ، يستخدم الناس الشبكات العصبية المتكررة ، RNS. في معظم أنواع الشبكات العصبية ، مثل نظام الحسابات القومية المشترك في رؤية الكمبيوتر ، تعمل الاتصالات بين الخلايا العصبية في اتجاه واحد ، من المدخلات إلى المخرجات (من الناحية الرياضية ، يتم توجيه هذه الرسوم البيانية الحلقية). في RNS ، يمكن إعادة توجيه إخراج الخلايا العصبية إلى الخلايا العصبية من نفس المستوى ، لأنفسهم أو إلى أبعد من ذلك. يتيح ذلك لـ RNS امتلاك ذاكرتها الخاصة (إذا كنت معتادًا على المنطق الثنائي ، فهذا الموقف يشبه تشغيل المشغلات).يعمل نظام الحسابات القومية على نهج واحد: نحن نطعمها صورة ، وهي تقدم بعض الوصف. تحتفظ RNS بالذاكرة الداخلية لما تم تقديمه لها سابقًا ، وتقدم إجابات بناءً على ما شاهدته بالفعل ، بالإضافة إلى ما تراه الآن.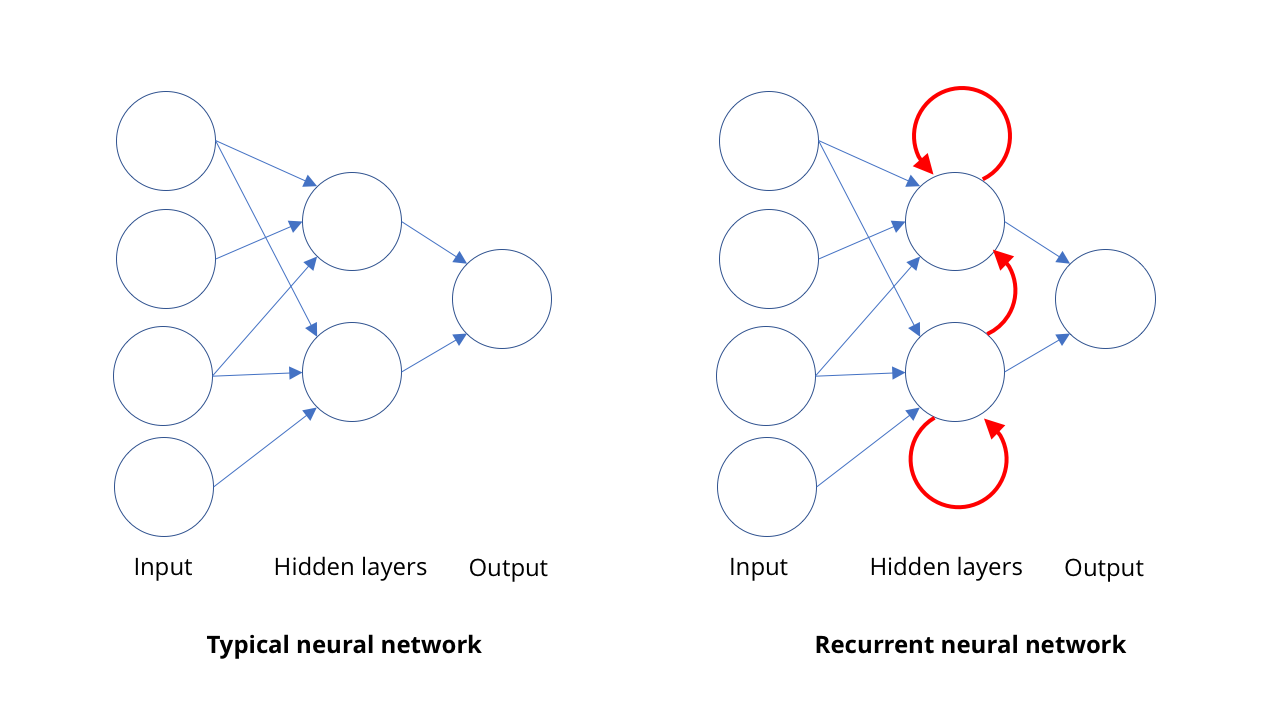 لا تسمح لهم خاصية الذاكرة هذه في RNS "بالاستماع" فقط إلى المقاطع الصوتية التي تأتي إليها واحدة تلو الأخرى. يتيح ذلك للشبكة معرفة المقاطع الصوتية التي تتشكل معًا لتكوين كلمة ، ومدى احتمال وجود تسلسلات معينة.باستخدام RNS ، من الممكن الحصول على نسخ جيد جدًا للكلام البشري - لدرجة أن أجهزة الكمبيوتر يمكنها الآن أن تتفوق على البشر في بعض قياسات دقة النسخ. بالطبع ، الأصوات ليست المنطقة الوحيدة التي تظهر فيها المتتاليات. اليوم ، يتم استخدام RNS أيضًا لتحديد تسلسل الحركات للتعرف على الإجراءات على الفيديو.
لا تسمح لهم خاصية الذاكرة هذه في RNS "بالاستماع" فقط إلى المقاطع الصوتية التي تأتي إليها واحدة تلو الأخرى. يتيح ذلك للشبكة معرفة المقاطع الصوتية التي تتشكل معًا لتكوين كلمة ، ومدى احتمال وجود تسلسلات معينة.باستخدام RNS ، من الممكن الحصول على نسخ جيد جدًا للكلام البشري - لدرجة أن أجهزة الكمبيوتر يمكنها الآن أن تتفوق على البشر في بعض قياسات دقة النسخ. بالطبع ، الأصوات ليست المنطقة الوحيدة التي تظهر فيها المتتاليات. اليوم ، يتم استخدام RNS أيضًا لتحديد تسلسل الحركات للتعرف على الإجراءات على الفيديو.أرني كيف يمكنك التحرك (المزيفة العميقة والشبكات التوليدية)
حتى الآن ، كنا نتحدث عن نماذج MO المصممة للاعتراف بها: أخبرني بما يظهر في الصورة ، أخبرني بما قاله الشخص. لكن هذه النماذج قادرة على المزيد - يمكن أيضًا استخدام طرازات GO اليوم لإنشاء محتوى.هذا هو عندما يتحدث الناس عن deepfake - مقاطع فيديو وصور واقعية وهمية بشكل لا يصدق تم إنشاؤها باستخدام GO. منذ بعض الوقت ، أثار مسؤول تلفزيوني ألماني نقاشًا سياسيًا مكثفًا عن طريق إنشاء فيديو مزيفالذي أظهر وزير المالية اليوناني ألمانيا الاصبع الوسطى. لإنشاء هذا الفيديو ، كنا بحاجة إلى فريق من المحررين الذين عملوا لإنشاء برنامج تلفزيوني ، ولكن في العالم الحديث ، يمكن القيام به في غضون دقائق قليلة بواسطة أي شخص يمكنه الوصول إلى كمبيوتر ألعاب متوسط الحجم.كل هذا محزن إلى حد ما ، ولكنه ليس قاتمًا جدًا في هذا المجال - يتم عرض مقطع الفيديو المفضل لدي حول موضوع هذه التقنية في الأعلى.ابتكر هذا الفريق نموذجًا قادرًا على معالجة مقطع فيديو بحركات الرقص لأحد الأشخاص وإنشاء مقطع فيديو مع شخص آخر يكرر هذه الحركات ويؤديها بطريقة سحرية على مستوى الخبراء. من الممتع أيضًا قراءة العمل العلمي المصاحب .يمكن للمرء أن يتخيل أنه ، باستخدام كل التقنيات التي ناقشناها ، من الممكن تدريب شبكة تتلقى صورة راقصة وتحدد مكان ذراعيه وساقيه. وفي هذه الحالة ، من الواضح ، على مستوى ما ، أن الشبكة تعلمت كيفية توصيل وحدات البكسل في الصورة مع موقع الأطراف البشرية. نظرًا لأن الشبكة العصبية هي مجرد بيانات مخزنة على جهاز كمبيوتر ، وليس دماغًا بيولوجيًا ، يجب أن يكون من الممكن أخذ هذه البيانات والانتقال في الاتجاه المعاكس - للحصول على وحدات بكسل مقابلة لموقع الأطراف.ابدأ بشبكة تستخرج من صور الأشخاص.
تسمى نماذج MO التي يمكنها القيام بذلك بالنماذج التوليفية. توليد - توليد ، إنتاج ، إنشاء / تقريبا. العابرة.]. جميع النماذج السابقة التي اعتبرناها تسمى تمييزية [م. التمييز - للتمييز / تقريبا. العابرة.]. يمكن تصور الفرق بينهما على النحو التالي: نموذج تمييزي للقطط ينظر إلى الصور ويميز بين الصور التي تحتوي على القطط والصور التي لا توجد فيها. يخلق النموذج التوليدي صورًا للقطط استنادًا إلى وصف لما يجب أن يكون عليه القط. يتم إنشاء النماذج العامة التي "ترسم" صور الكائنات باستخدام نفس هياكل SNA مثل النماذج المستخدمة للتعرف على هذه الكائنات. ويمكن تدريب هذه النماذج بنفس طريقة تدريب موديلات MO الأخرى.ومع ذلك ، فإن الحيلة هي التوصل إلى "تقييم" لتدريبهم. عند تدريب نموذج تمييزي ، هناك طريقة بسيطة لتقييم صحة وخطأ الإجابة - مثل ما إذا كانت الشبكة قد ميزت الكلب بشكل صحيح عن القط. ومع ذلك ، كيف يمكن تقييم جودة صورة القط الناتجة ، أو دقتها؟وهنا بالنسبة لشخص يحب نظريات المؤامرة ويعتقد أن كلنا محكوم عليهم ، يصبح الوضع مخيفًا بعض الشيء. كما ترون ، فإن أفضل طريقة اخترعناها لتعلم شبكات الجيل هي عدم القيام بذلك بنفسك. لهذا ، نحن ببساطة استخدام شبكة عصبية مختلفة.وتسمى هذه التكنولوجيا شبكة الخصومة التوليدية ، أو GSS. يمكنك إجبار شبكتين عصبيتين على التنافس مع بعضهما البعض: تحاول إحدى الشبكات إنشاء مزيفة ، على سبيل المثال ، عن طريق رسم راقصة جديدة تعتمد على المواقف القديمة. يتم تدريب شبكة أخرى للعثور على الفرق بين الأمثلة الحقيقية والمزيفة باستخدام مجموعة من الأمثلة الراقصة الحقيقية.وهاتان الشبكتان تلعبان لعبة تنافسية. ومن هنا جاءت كلمة "الخصومة" في العنوان. تحاول الشبكة التوليدية مزيفة مقنعة ، وتحاول الشبكة التمييزية أن تفهم مكان تزييفها وأين يوجد الشيء الحقيقي.في حالة مقطع فيديو به راقصة ، تم إنشاء شبكة تمييزية منفصلة أثناء عملية التدريب ، مما يوفر إجابات بنعم / لا بسيطة. نظرت إلى صورة الشخص ووصف موقف أطرافه ، وقررت ما إذا كانت الصورة هي صورة حقيقية أو صورة مرسومة من نموذج ابتكاري.
يتم إنشاء النماذج العامة التي "ترسم" صور الكائنات باستخدام نفس هياكل SNA مثل النماذج المستخدمة للتعرف على هذه الكائنات. ويمكن تدريب هذه النماذج بنفس طريقة تدريب موديلات MO الأخرى.ومع ذلك ، فإن الحيلة هي التوصل إلى "تقييم" لتدريبهم. عند تدريب نموذج تمييزي ، هناك طريقة بسيطة لتقييم صحة وخطأ الإجابة - مثل ما إذا كانت الشبكة قد ميزت الكلب بشكل صحيح عن القط. ومع ذلك ، كيف يمكن تقييم جودة صورة القط الناتجة ، أو دقتها؟وهنا بالنسبة لشخص يحب نظريات المؤامرة ويعتقد أن كلنا محكوم عليهم ، يصبح الوضع مخيفًا بعض الشيء. كما ترون ، فإن أفضل طريقة اخترعناها لتعلم شبكات الجيل هي عدم القيام بذلك بنفسك. لهذا ، نحن ببساطة استخدام شبكة عصبية مختلفة.وتسمى هذه التكنولوجيا شبكة الخصومة التوليدية ، أو GSS. يمكنك إجبار شبكتين عصبيتين على التنافس مع بعضهما البعض: تحاول إحدى الشبكات إنشاء مزيفة ، على سبيل المثال ، عن طريق رسم راقصة جديدة تعتمد على المواقف القديمة. يتم تدريب شبكة أخرى للعثور على الفرق بين الأمثلة الحقيقية والمزيفة باستخدام مجموعة من الأمثلة الراقصة الحقيقية.وهاتان الشبكتان تلعبان لعبة تنافسية. ومن هنا جاءت كلمة "الخصومة" في العنوان. تحاول الشبكة التوليدية مزيفة مقنعة ، وتحاول الشبكة التمييزية أن تفهم مكان تزييفها وأين يوجد الشيء الحقيقي.في حالة مقطع فيديو به راقصة ، تم إنشاء شبكة تمييزية منفصلة أثناء عملية التدريب ، مما يوفر إجابات بنعم / لا بسيطة. نظرت إلى صورة الشخص ووصف موقف أطرافه ، وقررت ما إذا كانت الصورة هي صورة حقيقية أو صورة مرسومة من نموذج ابتكاري. يجبر GSS شبكتين على التنافس مع بعضهما البعض: الأولى تنتج المنتجات المقلدة ، والآخر يحاول التمييز بين الصورة المقلدة والنسخة الأصلية.في
يجبر GSS شبكتين على التنافس مع بعضهما البعض: الأولى تنتج المنتجات المقلدة ، والآخر يحاول التمييز بين الصورة المقلدة والنسخة الأصلية.في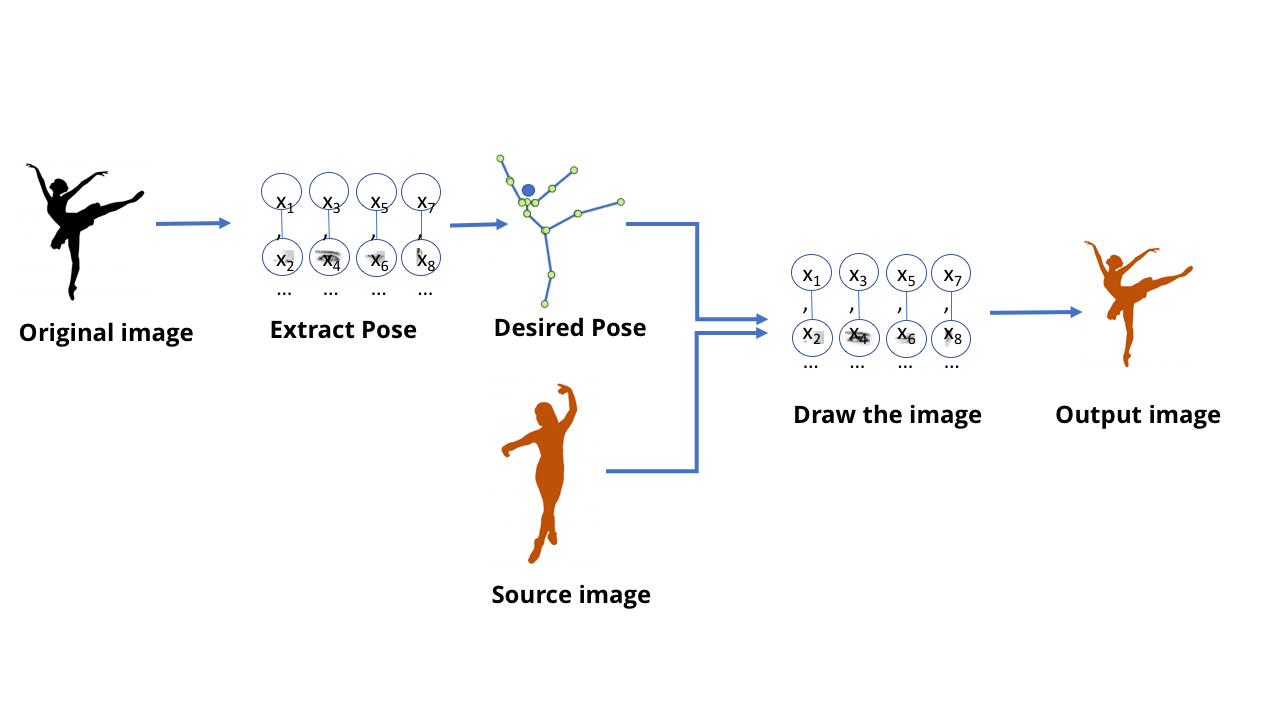 سير العمل النهائي ، يتم استخدام نموذج بديل فقط لإنشاء الصور الضروريةخلال جولات التدريب المتكررة ، أصبحت النماذج أفضل وأفضل. هذا مشابه للمنافسة بين خبير المجوهرات وخبير التقييم - التنافس مع خصم قوي ، كل منهم يصبح أقوى وأكثر ذكاءً. أخيرًا ، عندما تعمل النماذج جيدًا بما فيه الكفاية ، يمكنك أن تأخذ نموذجًا عامًا وتستخدمه بشكل منفصل.يمكن أن تكون النماذج التجريبية اللاحقة للتدريب مفيدة للغاية لإنشاء المحتوى. على سبيل المثال ، يمكنهم إنشاء صور لوجوه (والتي يمكن استخدامها لتدريب برامج التعرف على الوجوه) ، أو خلفيات لألعاب الفيديو.لكي يعمل كل هذا بشكل صحيح ، يلزم القيام بالكثير من العمل بشأن التعديلات والتصحيحات ، ولكن في الأساس يعمل الشخص هنا كمحكّم. إنها منظمة العفو الدولية التي تعمل ضد بعضها البعض ، مما يجعل تحسينات كبيرة.
سير العمل النهائي ، يتم استخدام نموذج بديل فقط لإنشاء الصور الضروريةخلال جولات التدريب المتكررة ، أصبحت النماذج أفضل وأفضل. هذا مشابه للمنافسة بين خبير المجوهرات وخبير التقييم - التنافس مع خصم قوي ، كل منهم يصبح أقوى وأكثر ذكاءً. أخيرًا ، عندما تعمل النماذج جيدًا بما فيه الكفاية ، يمكنك أن تأخذ نموذجًا عامًا وتستخدمه بشكل منفصل.يمكن أن تكون النماذج التجريبية اللاحقة للتدريب مفيدة للغاية لإنشاء المحتوى. على سبيل المثال ، يمكنهم إنشاء صور لوجوه (والتي يمكن استخدامها لتدريب برامج التعرف على الوجوه) ، أو خلفيات لألعاب الفيديو.لكي يعمل كل هذا بشكل صحيح ، يلزم القيام بالكثير من العمل بشأن التعديلات والتصحيحات ، ولكن في الأساس يعمل الشخص هنا كمحكّم. إنها منظمة العفو الدولية التي تعمل ضد بعضها البعض ، مما يجعل تحسينات كبيرة.لذا ، هل نتوقع ظهور Skynet و Hal 9000 في المستقبل القريب؟
في كل فيلم وثائقي عن الطبيعة في النهاية ، هناك حلقة يتحدث فيها المؤلفون عن كيف سيختفي كل هذا الجمال الفخم قريبًا نظرًا لضعف الناس. أعتقد أنه بنفس الروح ، يجب أن تتضمن كل مناقشة مسؤولة بشأن الذكاء الاصطناعى قسمًا عن حدوده وعواقبه الاجتماعية.
أولاً ، دعنا نؤكد مرة أخرى القيود الحالية على الذكاء الاصطناعى: الفكرة الرئيسية التي آمل أن تكون قد تعلمتها من قراءة هذا المقال هي أن نجاح MO أو AI يعتمد اعتمادًا كبيرًا على نماذج التدريب التي اخترناها. إذا كان الأشخاص لا ينظمون الشبكة بشكل جيد أو يستخدمون مواد غير مناسبة للتدريب ، فقد تكون هذه التشوهات واضحة للجميع.
تتميز الشبكات العصبية العميقة بالمرونة والقوة بشكل لا يصدق ، ولكن ليس لها خصائص سحرية. على الرغم من حقيقة أنك تستخدم شبكات عصبية عميقة لـ RNS و SNA ، فإن هيكلها مختلف تمامًا ، وبالتالي ، يجب على الناس تحديده على أي حال. لذلك حتى إذا كان يمكنك استخدام نظام الحسابات القومية للسيارات وإعادة تدريبه للتعرف على الطيور ، فلا يمكنك استخدام هذا النموذج وإعادة تدريبه للتعرف على الكلام.
إذا وصفناها من الناحية الإنسانية ، فكل شيء يبدو كما لو أننا فهمنا كيف تعمل القشرة البصرية والقشرة السمعية ، لكن ليس لدينا أي فكرة عن كيفية عمل القشرة الدماغية ، وأين يمكننا البدء في تناولها.
هذا يعني أنه في المستقبل القريب ، ربما لن نشاهد الذكاء الاصطناعي الذي يشبه إله هوليوود. لكن هذا لا يعني أنه في شكله الحالي ، لا يمكن أن يكون لمنظمة العفو الدولية تأثير خطير على المجتمع.
كثيرا ما نتخيل كيف "يحل الذكاء الاصطناعي" محلنا ، أي كيف تؤدي الروبوتات عملنا حرفيًا ، ولكن هذا لن يحدث في الواقع. ألقِ نظرة على الأشعة ، على سبيل المثال: في بعض الأحيان ، يقول الناس ، الذين ينظرون إلى نجاح رؤية الكمبيوتر ، إن الذكاء الاصطناعي سيحل محل أخصائيي الأشعة. ربما لن نصل إلى النقطة التي لن يكون لدينا فيها اختصاصي أشعة بشري واحد على الإطلاق. لكن المستقبل ممكن تمامًا ، حيث سيسمح الذكاء الاصطناعى ، بالنسبة لمئات من أخصائيي الأشعة اليوم ، بخمسة إلى عشرة منهم للقيام بعمل كل شخص آخر. إذا تحقق مثل هذا السيناريو ، فأين يذهب 90 طبيبا المتبقية؟
حتى إذا كان الجيل الحديث من الذكاء الاصطناعي لا يرقى إلى مستوى آمال مؤيديه الأكثر تفاؤلاً ، فسيظل يؤدي إلى عواقب وخيمة للغاية. وسيتعين علينا حل هذه المشكلات ، لذلك ربما تكون البداية الجيدة هي إتقان أساسيات هذا المجال.