
مع ظهور الكاميرات عالية الجودة في الهواتف المحمولة ، نقوم بالتصوير أكثر فأكثر ، ونقوم بتصوير مقاطع فيديو لحظات مشرقة وهامة في حياتنا. لدى الكثير منا محفوظات للصور يعود تاريخها إلى عشرات السنين والآلاف من الصور الفوتوغرافية ، حيث أصبح التنقل فيها أكثر صعوبة. تذكر المدة التي استغرقتها للعثور على الصورة الصحيحة منذ عدة سنوات.
أحد أهداف Mail.ru Cloud هو توفير الوصول الأكثر ملاءمة والبحث في أرشيف الصور والفيديو الخاص بك. للقيام بذلك ، قمنا نحن ، فريق رؤية الجهاز Mail.ru ، بإنشاء وتنفيذ أنظمة معالجة الصور الذكية: البحث عن طريق الكائنات ، والمشاهد ، والوجوه ، وما إلى ذلك. واليوم سأتحدث عن الطريقة التي حلنا بها هذه المشكلة بمساعدة التعلم العميق.
تخيل الموقف: ذهبت في عطلة وأحضرت مجموعة من الصور. وفي محادثة مع الأصدقاء ، طلبوا منك أن توضح كيف زرت القصر ، القلعة ، الهرم ، المعبد ، البحيرة ، الشلال ، الجبل ، إلخ. تبدأ في التمرير بشكل محموم عبر المجلد مع الصور ، في محاولة للعثور على المجلد الصحيح. على الأرجح ، لا تجده بين مئات الصور ، ويقول إنك ستظهر لاحقًا.
نحن نحل هذه المشكلة من خلال تجميع الصور المخصصة في ألبومات. هذا يجعل من السهل العثور على الصور المناسبة في بضع نقرات. الآن لدينا ألبومات على الوجوه والأشياء والمشاهد ، وكذلك على مناطق الجذب السياحي.
تعد الصور ذات المعالم مهمة لأنها تعرض غالبًا لحظات مهمة من حياتنا (على سبيل المثال ، السفر). يمكن أن تكون هذه صور فوتوغرافية في خلفية بعض البنية المعمارية أو زاوية من الطبيعة لم يمسها الإنسان. لذلك ، نحتاج إلى العثور على هذه الصور ومنح المستخدمين وصولاً سهلاً وسريعًا إليها.
ميزة الاعتراف
ولكن هناك فارق بسيط: لا يمكنك فقط تدريب وتدريب بعض النماذج للتعرف على المعالم السياحية ، فهناك الكثير من الصعوبات.
- أولاً ، لا يمكننا وصف ماهية "المعلم" بوضوح. لا يمكننا تحديد سبب كون أحد المباني علامة فارقة ، والوقوف بجانبه ليس كذلك. هذا ليس مفهومًا رسميًا ، مما يعقد صياغة مشكلة الاعتراف.
- ثانيا ، المشاهد متنوعة للغاية. يمكن أن تكون المباني التاريخية أو الثقافية - المعابد والقصور والقلاع. هذه يمكن أن تكون الآثار الأكثر تنوعا. يمكن أن يكون أشياء طبيعية - البحيرات والأودية والشلالات. ويجب أن يكون هناك نموذج واحد قادر على العثور على كل هذه المعالم.
- ثالثًا ، هناك عدد قليل جدًا من الصور ذات مشاهد ، وفقًا لحساباتنا ، فهي موجودة فقط في 1-3٪ من صور المستخدم. لذلك ، لا يمكننا أن نسمح لأنفسنا بالأخطاء في التقدير ، لأنه إذا عرضنا على شخص صورة دون نقطة اهتمام ، فستكون ملحوظة على الفور وستسبب حيرة ورد فعل سلبي. أو ، على العكس من ذلك ، أظهرنا للشخص صورة مع معلم في نيويورك ، ولم يذهب إلى أمريكا مطلقًا. لذلك يجب أن يحتوي نموذج التعرف على معدل FPR منخفض (معدل إيجابي خاطئ).
- رابعًا ، يقوم حوالي 50٪ من المستخدمين ، أو أكثر ، بإيقاف تشغيل تخزين المعلومات الجغرافية عند التصوير. نحتاج إلى أخذ هذا في الاعتبار وتحديد المكان فقط من الصورة. معظم الخدمات التي تعمل اليوم بطريقة أو بأخرى للعمل مع أماكن الاهتمام تقوم بذلك بفضل البيانات الجغرافية. كانت متطلباتنا الأولية أكثر صرامة.
سأعرض الآن مع الأمثلة.
فيما يلي أشياء مشابهة ، ثلاثة كاتدرائيات قوطية فرنسية. اليسار هو كاتدرائية آميان ، في منتصف كاتدرائية ريمس ، على اليمين نوتردام دي باريس.

حتى الشخص يحتاج إلى بعض الوقت للنظر إليه وفهم أن هذه كاتدرائيات مختلفة ، ويجب أن يكون الجهاز قادرًا أيضًا على التعامل معها وأسرع من شخص.
وإليك مثال على صعوبة أخرى: الصور الثلاث الموجودة على الشريحة هي نوتردام دي باريس ، مأخوذة من زوايا مختلفة. تبين أن الصور مختلفة تمامًا ، لكن يجب التعرف عليها جميعًا والعثور عليها.

الكائنات الطبيعية مختلفة تماما عن تلك المعمارية. على اليسار توجد قيصرية في إسرائيل ، على اليمين توجد الحديقة الإنجليزية في ميونيخ.

في هذه الصور ، هناك القليل من التفاصيل المميزة التي يمكن للنموذج "اللحاق بها".
طريقتنا
تعتمد طريقة عملنا تمامًا على الشبكات العصبية التلافيفية العميقة. كنهج للتعلم ، اختاروا ما يسمى تعلم المناهج - التعلم في عدة مراحل. من أجل العمل بشكل أكثر كفاءة في وجود البيانات الجغرافية وفي غيابها ، قمنا باستنتاج خاص (استنتاج). سوف أخبركم بكل مرحلة من المراحل بمزيد من التفصيل.
بيانات
الوقود للتعلم الآلة هو البيانات. وأولا وقبل كل شيء ، كنا بحاجة لجمع مجموعة بيانات للتدريب النموذجي.
قسمنا العالم إلى 4 مناطق ، يتم استخدام كل منها في مراحل مختلفة من التدريب. بعد ذلك ، تم التقاط البلدان في كل منطقة ، وتم تجميع قائمة بالمدن لكل دولة ، وتم تجميع قاعدة بيانات بالصور عن مناطق الجذب فيها. يتم تقديم أمثلة على البيانات أدناه.

أولاً ، حاولنا تدريب نموذجنا على القاعدة الناتجة. النتائج كانت سيئة. لقد بدأوا في التحليل ، واتضح أن البيانات "قذرة للغاية". كل جاذبية لديها كمية كبيرة من القمامة. ما يجب القيام به إن مراجعة كمية البيانات الضخمة بأكملها يدويًا باهظة الثمن ، كئيبة وليست ذكية جدًا. لذلك ، قمنا بتنظيف القاعدة تلقائيًا ، حيث يتم استخدام المعالجة اليدوية فقط في خطوة واحدة: لكل نقطة جذب ، اخترنا يدويًا 3-5 صور مرجعية تحتوي بدقة على الجذب المطلوب في منظور أكثر أو أقل دقة. اتضح بسرعة كبيرة ، لأن حجم هذه البيانات المرجعية صغير بالنسبة إلى قاعدة البيانات بأكملها. ثم ، التنظيف التلقائي على أساس الشبكات العصبية التلافيفية العميقة يتم بالفعل.
علاوة على ذلك ، سأستخدم مصطلح "التضمين" ، الذي سوف أفهم ما يلي. لدينا شبكة عصبية تلافيفية ، قمنا بتدريبها على التصنيف ، وقطعنا طبقة التصنيف الأخيرة ، والتقطنا بعض الصور ، قادنا عبر الشبكة وحصلنا على ناقل رقمي في المخرجات. سأسميها التضمين.
كما قلت ، تم تنفيذ التدريب لدينا على عدة مراحل ، المقابلة لأجزاء من قاعدة البيانات الخاصة بنا. لذلك ، أولاً نأخذ إما شبكة عصبية من المرحلة السابقة ، أو شبكة تهيئة.
سنقوم بتشغيل صور المعالم السياحية عبر الشبكة والحصول على العديد من الزخارف. الآن يمكنك تنظيف القاعدة. نلتقط جميع الصور من مجموعة البيانات لهذا الجذب ، ونقود أيضًا كل صورة عبر الشبكة. نحصل على مجموعة من حفلات الزفاف ولكل واحد منهم نعتبر المسافات إلى تضمين المعايير. ثم نحسب متوسط المسافة ، وإذا كان أكثر من عتبة معينة ، وهي معلمة الخوارزمية ، فإننا نعتبر أن هذه ليست نقطة جذب سياحية. إذا كان متوسط المسافة أقل من العتبة ، فإننا نترك هذه الصورة.
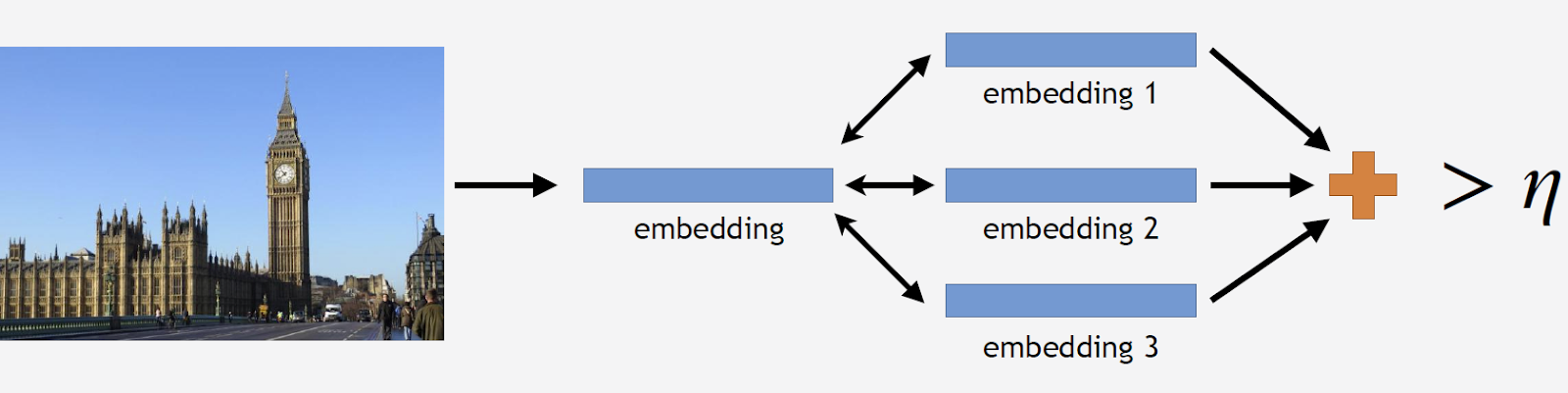
نتيجة لذلك ، حصلنا على قاعدة بيانات تحتوي على أكثر من 11 ألف من مناطق الجذب السياحي من أكثر من 500 مدينة في 70 دولة حول العالم - أكثر من 2.3 مليون صورة. حان الوقت الآن لتتذكر أن معظم الصور لا تحتوي على عوامل جذب على الإطلاق. يجب مشاركة هذه المعلومات بطريقة أو بأخرى مع نماذجنا. لذلك ، أضفنا 900 ألف صورة بدون مشاهد إلى قاعدة البيانات الخاصة بنا ، وقمنا بتدريب نموذجنا على مجموعة البيانات الناتجة.
لقياس جودة التدريب ، قدمنا اختبارًا غير متصل بالإنترنت. استنادًا إلى حقيقة أن المعالم السياحية موجودة فقط في حوالي 1-3٪ من الصور الفوتوغرافية ، جمعنا يدويًا مجموعة من 290 صورة تعرض مشاهد. هذه صور مختلفة ومعقدة للغاية مع عدد كبير من الأشياء المأخوذة من زوايا مختلفة ، بحيث يكون الاختبار صعباً للغاية بالنسبة للنموذج. وفقًا للمبدأ نفسه ، اخترنا 11 ألف صورة بدون مشاهد ، وهي أيضًا معقدة للغاية ، وحاولنا العثور على كائنات تشبه المعالم السياحية المتوفرة في قاعدة البيانات الخاصة بنا.
لتقييم جودة التدريب ، نقيس دقة نموذجنا من الصور الفوتوغرافية مع وبدون مشاهد. هذه هي مقاييسنا الرئيسية.
النهج الحالية
هناك القليل من المعلومات حول التعرف على البصر في الأدبيات العلمية. تعتمد معظم الحلول على الميزات المحلية. والفكرة هي أن لدينا صورة طلب معين وصورة من قاعدة البيانات. في هذه الصور ، نجد علامات محلية - نقاط أساسية ، ومقارنتها. إذا كان عدد المباريات كبيرًا بما يكفي ، نعتقد أننا وجدنا نقطة اهتمام.
حتى الآن ، فإن أفضل طريقة هي طريقة Google المقترحة ، DELF (الميزات المحلية العميقة) ، حيث يتم دمج مقارنة الميزات المحلية مع التعلم العميق. من خلال تشغيل صورة الإدخال من خلال شبكة الالتفاف ، نحصل على بعض علامات DELF.

كيف يتم الاعتراف الجذب السياحي؟ لدينا قاعدة بيانات للصور وصورة إدخال ، ونريد أن نفهم ما إذا كان هناك جاذبية سياحية عليها أم لا. نقوم بتشغيل جميع الصور من خلال DELF ، ونحصل على العلامات المقابلة للقاعدة ولصورة الإدخال. بعد ذلك ، نقوم بإجراء بحث باستخدام طريقة أقرب الجيران وفي الإخراج نحصل على صور مرشح بها علامات. قارنا هذه العلامات بمساعدة التحقق الهندسي: إذا نجحت في اجتيازها ، فإننا نعتقد أن هناك نقطة اهتمام في الصورة.
الشبكة العصبية التلافيفية
للتعلم العميق ، التدريب المسبق أمر بالغ الأهمية. لذلك ، أخذنا قاعدة المشاهد ودربنا عليها شبكتنا العصبية. لماذا هكذا؟ المشهد هو كائن معقد يتضمن عددًا كبيرًا من الكائنات الأخرى. والجذب هو حالة خاصة للمشهد. كنموذج تمهيدي للتدريب على هذا الأساس ، يمكننا إعطاء النموذج فكرة عن بعض الميزات ذات المستوى المنخفض والتي يمكن تعميمها من أجل الاعتراف الناجح بمعالم الجذب.
كنموذج ، استخدمنا شبكة عصبية من عائلة شبكة المتبقية. الميزة الرئيسية هي أنها تستخدم كتلة متبقية ، والتي تتضمن اتصال تخطي ، والذي يسمح للإشارة بالمرور بحرية دون الدخول في طبقات ذات أوزان. مع هذه البنية ، يمكنك تدريب شبكات عميقة نوعًا والتعامل مع تأثير طمس التدرج ، وهو أمر مهم جدًا عند التعلم.
نموذجنا هو Wide ResNet 50-2 ، وهو تعديل لـ ResNet 50 ، حيث يتضاعف عدد التلفيفات في كتلة عنق الزجاجة الداخلية.

الشبكة فعالة جدا. لقد أجرينا اختبارات على قاعدة بيانات المشهد لدينا وهذا ما حصلنا عليه:
تحولت شبكة ResNet الواسعة إلى ضعف سرعة شبكة ResNet 200 الكبيرة تقريبًا ، كما أن سرعة التشغيل مهمة جدًا للتشغيل. استنادًا إلى إجمالي هذه الظروف ، اتخذنا Wide ResNet 50-2 كشبكة عصبية رئيسية لدينا.
تدريب
لتدريب الشبكة ، نحتاج إلى الخسارة (وظيفة الخسارة). لتحديده ، قررنا استخدام نهج التعلم المتري: يتم تدريب شبكة عصبية بحيث يتم تجميع ممثلي نفس الفصل في مجموعة واحدة. في الوقت نفسه ، يجب أن تكون المجموعات لفئات مختلفة متباعدة قدر الإمكان. بالنسبة للجذب السياحي ، استخدمنا خسارة المركز ، التي تجمع نقاطًا من نفس الفئة معًا في مركز معين. من السمات المهمة لهذا النهج أنه لا يتطلب أخذ عينات سلبية ، والتي في المراحل الأخيرة من التدريب هي إجراء صعب إلى حد ما.
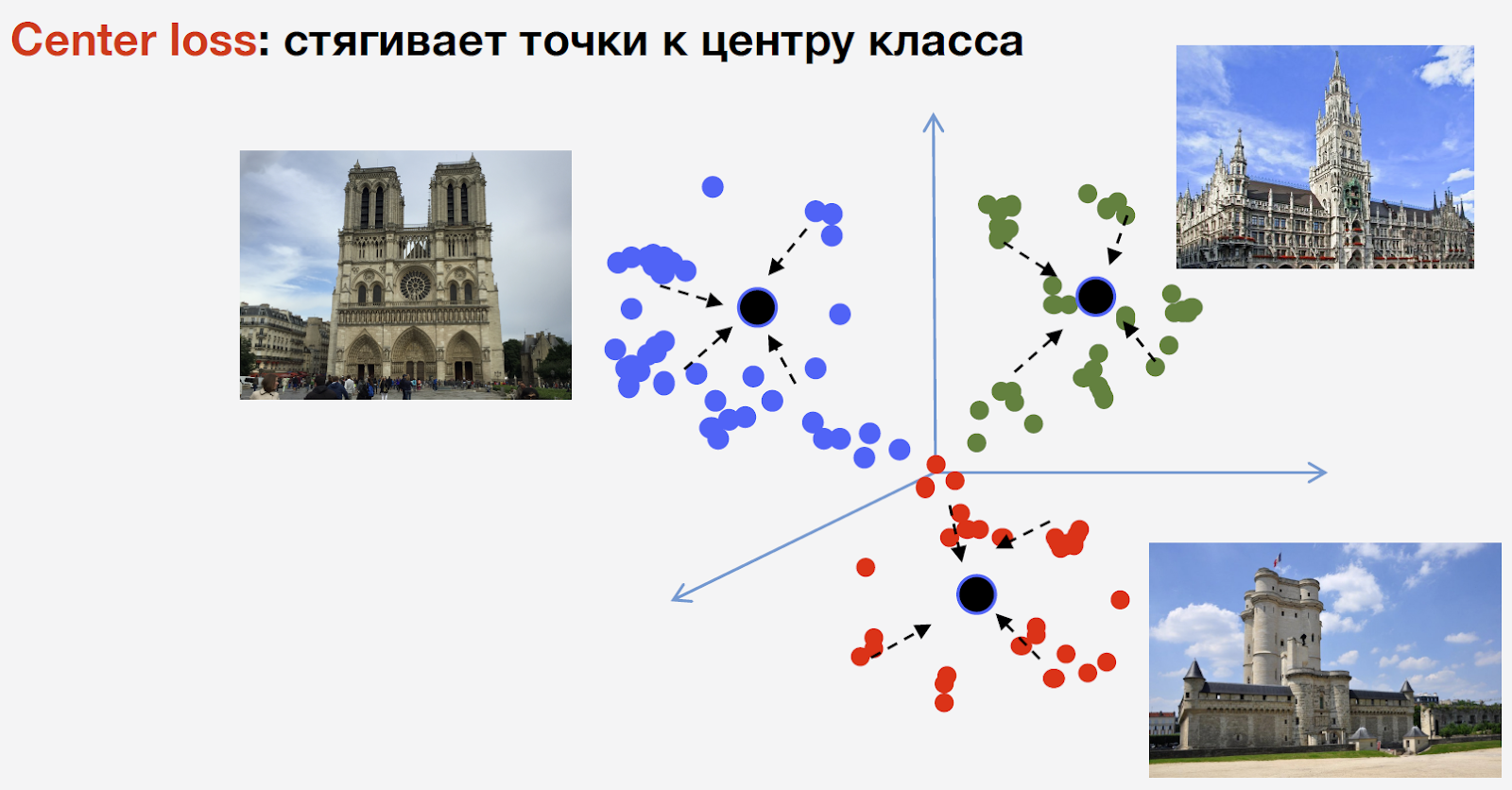
واسمحوا لي أن أذكركم بأن لدينا فئات ن من عوامل الجذب وفئة أخرى من "لا معالم الجذب" ، لا يتم استخدام خسارة المركز لذلك. نعني أن معلمًا واحدًا ونفس الشيء ، وهناك بنية فيه ، لذلك فمن المستحسن التفكير في مركز له. ولكن لا يمكن أن يكون أي معلم سياحي أي شيء ، واعتبار المركز بالنسبة له أمر غير معقول.
ثم وضعناها جميعًا معًا وحصلنا على نموذج للتدريب. يتكون من ثلاثة أجزاء رئيسية:
- شبكة عصبية تلافيفية واسعة ResNet 50-2 ، مدربة مسبقًا على أساس المشاهد ؛
- أجزاء من التضمين تتكون من طبقة متصلة بالكامل وطبقة قاعدة الدُفعات ؛
- جهاز تصنيف ، وهو عبارة عن طبقة متصلة تمامًا ، يتبعه زوج من خسائر Softmax وفقدان المركز.

كما تتذكر ، قاعدتنا مقسمة إلى 4 أجزاء حسب المنطقة من العالم. نستخدم هذه الأجزاء الأربعة كجزء من نموذج تعلم المناهج. في كل مرحلة ، لدينا مجموعة البيانات الحالية ، نضيف جزءًا آخر من العالم إليها ونحصل على مجموعة بيانات تدريب جديدة.
يتكون النموذج من ثلاثة أجزاء ، ولكل واحد منهم نستخدم معدل التعلم الخاص بنا في التدريب. يعد ذلك ضروريًا حتى لا تتمكن الشبكة من معرفة المعالم من الجزء الجديد من مجموعة البيانات التي أضفناها فحسب ، بل لا تنسى أيضًا البيانات التي تم تعلمها بالفعل. بعد العديد من التجارب ، تبين أن هذا النهج هو الأكثر فعالية.
لذلك ، قمنا بتدريب النموذج. تحتاج إلى فهم كيف يعمل. دعنا نستخدم خريطة تنشيط الفصل لمعرفة أي جزء من الصورة هو الأكثر استجابة لشبكتنا العصبية. في الصورة أدناه ، في الصف الأول ، الصور المدخلة ، وفي الثانية ، يتم تنشيط خريطة تنشيط الفصل من الشبكة ، والتي قمنا بتدريبها في الخطوة السابقة.

تُظهر خريطة الحرارة الأجزاء التي توليها الشبكة مزيدًا من الاهتمام للصورة. من خريطة تفعيل الفصل ، يمكن أن نرى أن شبكتنا العصبية قد تعلمت بنجاح مفهوم الجاذبية.
استدلال
الآن تحتاج إلى استخدام هذه المعرفة بطريقة أو بأخرى للحصول على النتيجة. نظرًا لأننا استخدمنا خسارة المركز للتدريب ، فإنه يبدو من المنطقي تمامًا الاستدلال لحساب تسيروتويد للجذب السياحي.
لهذا ، نأخذ جزءًا من الصور من مجموعة التدريب لنوع من الجاذبية ، على سبيل المثال ، لفارس الخيول البرونزي. نقوم بتشغيلها من خلال الشبكة ، الحصول على حفلات الزفاف ، متوسط والحصول على centroid.
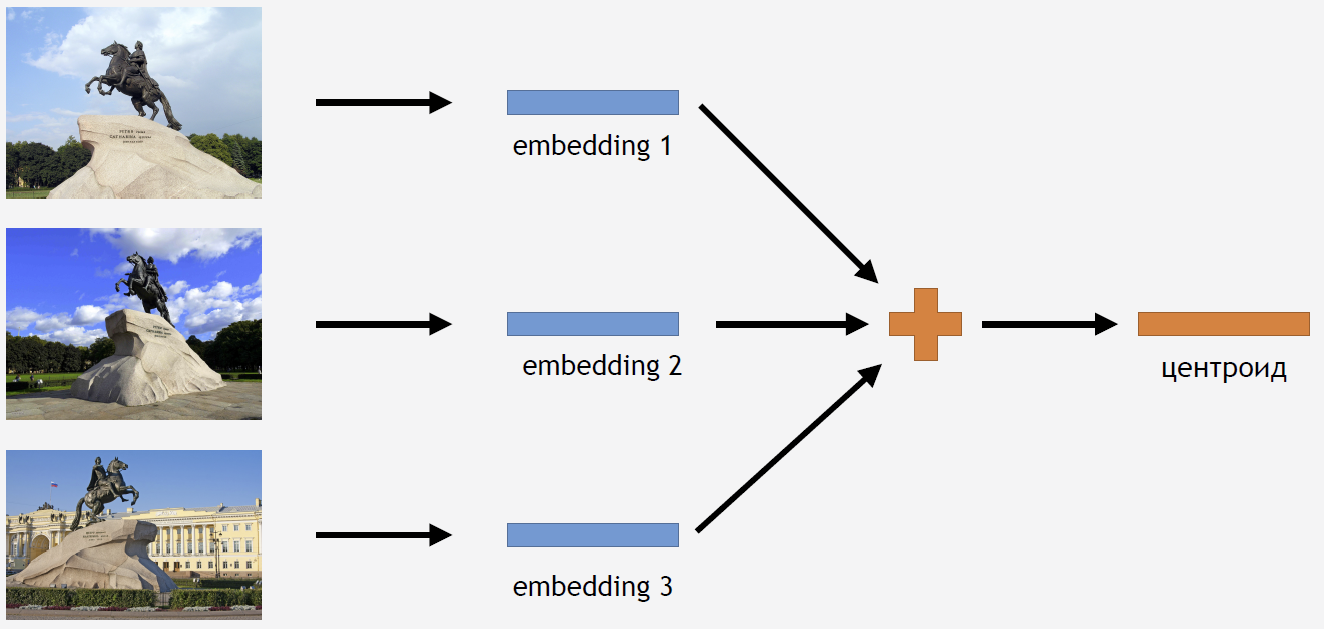
ولكن السؤال الذي يطرح نفسه هو: كم عدد النقط الوسطى لجاذبية واحدة لا معنى لحساب؟ في البداية ، يبدو الجواب واضحًا ومنطقيًا: نقطة واحدة. ولكن تبين أن هذا ليس كذلك. في البداية ، قررنا أيضًا جعل centroid واحد وحصلنا على نتيجة جيدة. فلماذا تحتاج إلى اتخاذ عدد قليل من centroids؟
أولاً ، بياناتنا ليست نظيفة تمامًا. على الرغم من أننا قمنا بتنظيف مجموعة البيانات ، إلا أننا أزلنا القمامة المباشرة فقط. ويمكن أن يكون لدينا صور لا يمكن اعتبارها قمامة ، ولكنها تزيد من سوءًا النتيجة.
على سبيل المثال ، لدي فصل دراسي لقصر الشتاء. أريد أن أحسب النقطه الوسطى له. لكن المجموعة تضمنت عددًا من الصور الفوتوغرافية مع ميدان القصر وقوس مبنى هيئة الأركان العامة. إذا أخذنا في الاعتبار أن النقطه الوسطى في كل الصور ، فسوف يتحول ذلك إلى ثبات. من الضروري تجميع حفلاتهم بطريقة أو بأخرى ، والتي يتم الحصول عليها من الشبكة المعتادة ، وأخذ فقط النقطه الوسطى المسؤولة عن قصر الشتاء ، وحساب المتوسط وفقا لهذه البيانات.

ثانياً ، يمكن التقاط الصور من زوايا مختلفة.
سأستشهد ببرج بيلفورت بيل في بروج كتوضيح لهذا السلوك. يتم حساب اثنين من النقط الوسطى لها. في الصف العلوي من الصورة توجد تلك الصور الأقرب إلى النقطه الوسطى الأولى ، وفي الصف الثاني - الصور الأقرب إلى النقطه الوسطى الثانيه:

يعد أول مركز مركزي مسؤولاً عن الصور "الأكثر ذكاء" عن قرب التي تم التقاطها من ميدان سوق بروج. وال centroid الثاني هو المسؤول عن الصور التي التقطت من بعيد ، من الشوارع المجاورة.
اتضح أنه من خلال حساب العديد من النقط الوسطى لكل فئة من نقاط الاهتمام ، يمكننا عرض زوايا مختلفة من هذه النقطة المثيرة للاهتمام في الاستدلال.
لذا ، كيف نجد هذه المجموعات لحساب النقط الوسطى؟ نحن نطبق المجموعات الهرمية على مجموعات البيانات لكل نقطة اهتمام - رابط كامل. بمساعدتها ، نجد مجموعات صالحة سنعمل على حساب النقط الوسطى. نعني بالمجموعات الصحيحة تلك التي تحتوي على 50 صورة على الأقل نتيجة للتكتل. يتم تجاهل المجموعات المتبقية. ونتيجة لذلك ، تبين أن حوالي 20 ٪ من المعالم السياحية لديها أكثر من واحد النقطه الوسطى.
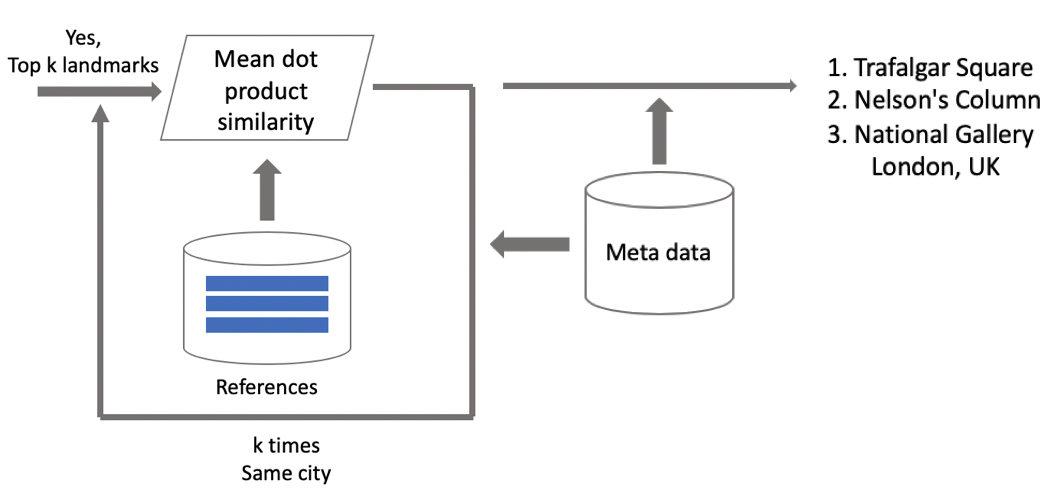
الآن الاستدلال. نقوم بحسابها على مرحلتين: أولاً ، نقوم بتشغيل صورة الإدخال من خلال شبكتنا العصبية التلافيفية والحصول على التضمين ، ثم باستخدام منتج العددية الذي نقارن التضمين مع النقطتين الوسطى. إذا كانت الصور تحتوي على بيانات جغرافية ، فنحن نقصر البحث على النقط الوسطى ، والتي تتعلق بمناطق الجذب الموجودة في مربع واحد لكل كيلومتر واحد من موقع التصوير. يسمح لك ذلك بالبحث بدقة أكبر ، واختيار حد أدنى للمقارنة اللاحقة. إذا كانت المسافة التي تم الحصول عليها أكبر من العتبة ، وهي معلمة من الخوارزمية ، فإننا نقول أنه في الصورة هناك نقطة اهتمام مع أقصى قيمة للمنتج القياسي. إذا كان أقل ، فهذا ليس عامل جذب سياحي.
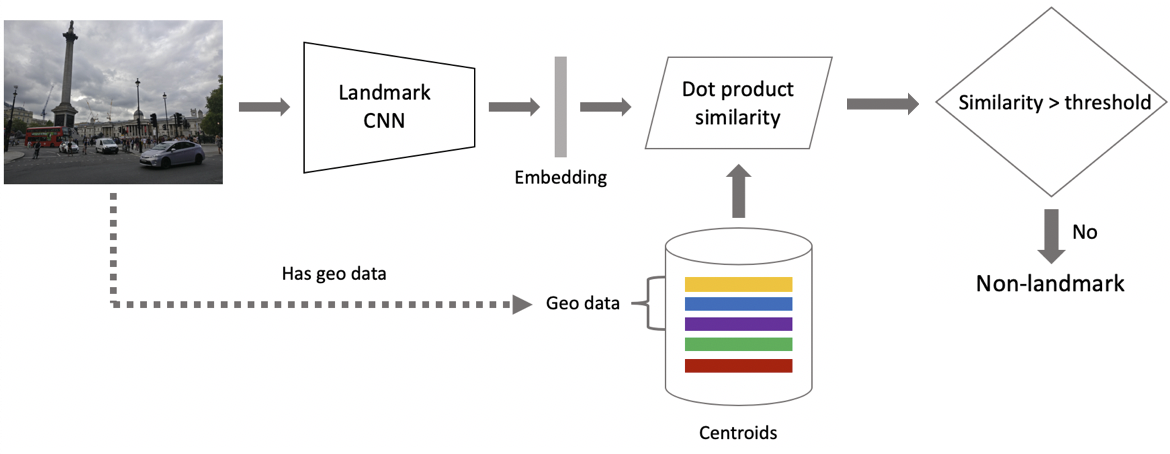
افترض أن الصورة تحتوي على معلم. إذا كان لدينا بيانات جغرافية ، فإننا نستخدمها ونعرض الإجابة. إذا لم يكن هناك بيانات جغرافية ، فنحن نقوم بفحص إضافي. عندما قمنا بتنظيف مجموعة البيانات ، قمنا بعمل مجموعة من الصور المرجعية لكل فئة من مناطق الجذب. بالنسبة لهم ، يمكننا حساب التضمينات ، ثم نحسب متوسط المسافة منها لتضمين صورة الطلب. إذا كان أكثر من بعض العتبة ، ثم يتم تمرير التحقق ، فإننا نضمّن البيانات الوصفية ونعرض النتيجة. من المهم ملاحظة أنه يمكننا القيام بمثل هذا الإجراء للعديد من عوامل الجذب التي تم العثور عليها في الصورة.
نتائج الاختبار
قمنا بمقارنة نموذجنا مع DELF ، حيث أخذنا المعايير التي أظهر بها أفضل النتائج في اختبارنا. وكانت النتائج هي نفسها تقريبا.
: ( 100 ), 87 % , . : 85,3 %. 46 %, — .
/B- . 10 %, 3 %, 13 %.
DELF. GPU DELF 7 , 7 , 1 . CPU DELF . CPU 15 . , .
:
. .
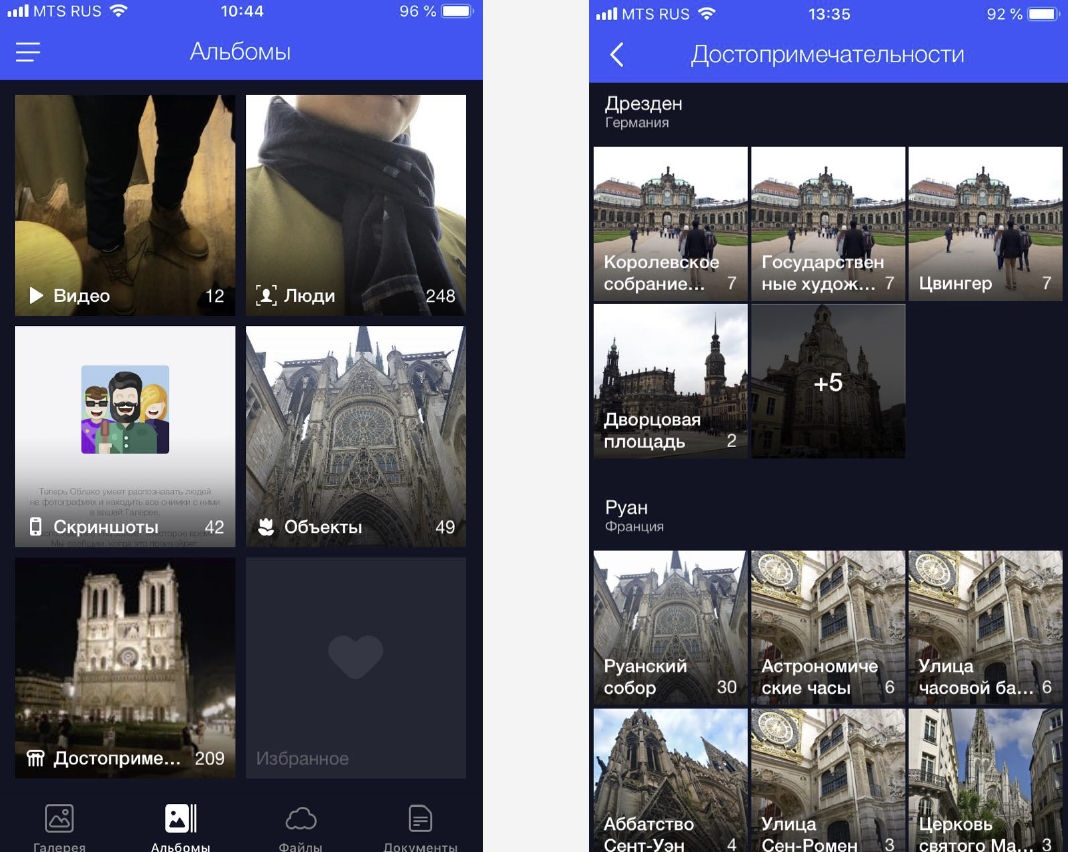
, . «», «», «». , . , .
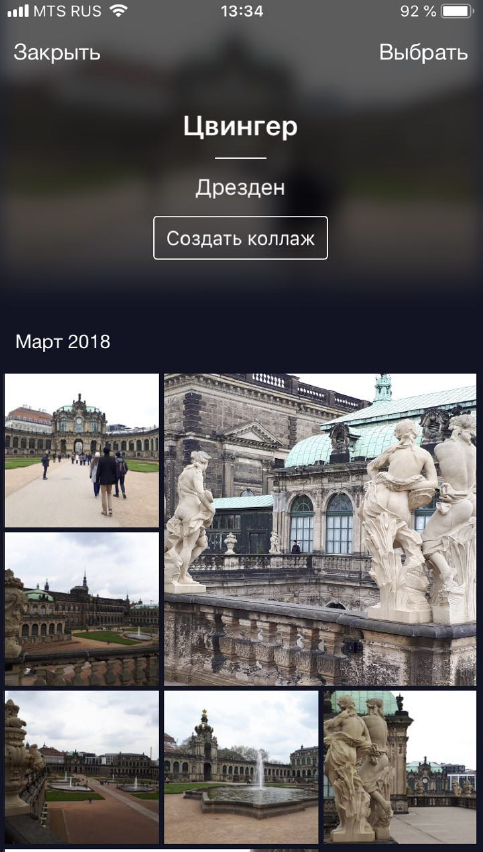
: , , . Instagram , , — .
.
- . , . .
- deep metric learning, .
- curriculum learning — . . inference , .
, — . , , . - . !