لسوء الحظ ، يتم الآن تقليل دور المتخصصين في ضبط الأداء واستكشاف الأخطاء وإصلاحها في قواعد البيانات إلى آخرها فقط - استكشاف الأخطاء وإصلاحها: إنهم دائمًا ما يتحولون إلى متخصصين فقط عندما تصل المشكلات بالفعل إلى نقطة حرجة ، ويجب حلها "بالأمس". وحتى مع ذلك ، من الجيد أن يتم تشغيلها ، ولا تؤجل المشكلة عن طريق شراء أجهزة أكثر تكلفة وأقوى بدون مراجعة أداء واختبارات إجهاد مفصلة. في الواقع ، غالبًا ما تكون الإحباطات كافية: لقد اشتروا معدات بقيمة 2-5 مرات أكثر تكلفة ، وفازوا في الأداء بنسبة 30-40٪ فقط ، وتؤكل الزيادة بأكملها في غضون بضعة أشهر إما عن طريق زيادة عدد المستخدمين ، أو بزيادة هائلة في البيانات ، إلى جانب تعقيد المنطق.
والآن ، في الوقت الذي ينمو فيه عدد المهندسين المعماريين والمختبرين ومهندسي DevOps بشكل سريع ، يعمل مطورو Java Core على تحسين العمل حتى
مع السلاسل ، ببطء ولكن بثبات حان الوقت لمحسّن قاعدة البيانات. أصبحت نظم إدارة قواعد البيانات (DBMS) مع كل إصدار أكثر ذكاءً وتعقيدًا بحيث تتطلب دراسة الفروق الدقيقة الموثقة وغير الموثقة والتحسينات وقتًا كبيرًا. يتم نشر عدد كبير من المقالات شهريًا وتعقد مؤتمرات رئيسية مخصصة لـ Oracle. نأسف لهذا التشبيه المألوف ، ولكن في هذه الحالة ، عندما يصبح مسؤولو قواعد البيانات مشابهين للطيارين في الطائرة مع عدد لا يحصى من مفاتيح التبديل والأزرار والأضواء والشاشات ، فمن غير المناسب بالفعل تحميلها مع التفاصيل الدقيقة لتحسين الأداء.
بالطبع ، يمكن لـ DBA ، مثل الطيارين ، في معظم الحالات حل المشكلات الواضحة والبسيطة بسهولة عندما يتم تشخيصها أو ملاحظتها بسهولة في "قمم" مختلفة (أهم الأحداث ، أعلى SQL ، القطاعات العليا ...). والتي يسهل العثور عليها على MOS أو Google ، حتى لو كانوا لا يعرفون الحل. يكون الأمر أكثر تعقيدًا حتى عندما يتم إخفاء الأعراض خلف تعقيد النظام وتحتاج إلى اكتشافها بين الكم الهائل من المعلومات التشخيصية التي يتم جمعها بواسطة Oracle DBMS نفسها.
أحد الأمثلة الأكثر بساطة والأكثر لفتا للنظر في هذا هو تحليل عوامل التصفية والوصول: في الأنظمة الكبيرة والمحملة ، يحدث غالبًا أن يتم التغاضي عن هذه المشكلة بسهولة ، لأن يتم توزيع الحمل بشكل متساوٍ إلى حد ما على طلبات مختلفة (مع وصلات لجداول مختلفة ، مع وجود اختلافات طفيفة في الظروف ، وما إلى ذلك) ، ولا تظهر الأجزاء العليا أي شيء خاص ، ويقولون "حسنًا ، نعم ، غالبًا ما تكون البيانات مطلوبة من هذه الجداول وهناك المزيد" . في مثل هذه الحالات ، يمكنك بدء التحليل بإحصائيات من SYS.COL_USAGE $:
col_usage.sqlcol owner format a30 col oname format a30 heading "Object name" col cname format a30 heading "Column name" accept owner_mask prompt "Enter owner mask: "; accept tab_name prompt "Enter tab_name mask: "; accept col_name prompt "Enter col_name mask: "; SELECT a.username as owner ,o.name as oname ,c.name as cname ,u.equality_preds as equality_preds ,u.equijoin_preds as equijoin_preds ,u.nonequijoin_preds as nonequijoin_preds ,u.range_preds as range_preds ,u.like_preds as like_preds ,u.null_preds as null_preds ,to_char(u.timestamp, 'yyyy-mm-dd hh24:mi:ss') when FROM sys.col_usage$ u , sys.obj$ o , sys.col$ c , all_users a WHERE a.user_id = o.owner
ومع ذلك ، لتحليل كامل لهذه المعلومات ليست كافية ، لأنه أنها لا تظهر مجموعات من المسندات. في هذه الحالة ، يمكن أن يساعدنا تحليل v $ active_session_history و v $ sql_plan:
with ash as ( select sql_id ,plan_hash_value ,table_name ,alias ,ACCESS_PREDICATES ,FILTER_PREDICATES ,count(*) cnt from ( select h.sql_id ,h.SQL_PLAN_HASH_VALUE plan_hash_value ,decode(p.OPERATION ,'TABLE ACCESS',p.OBJECT_OWNER||'.'||p.OBJECT_NAME ,(select i.TABLE_OWNER||'.'||i.TABLE_NAME from dba_indexes i where i.OWNER=p.OBJECT_OWNER and i.index_name=p.OBJECT_NAME) ) table_name ,OBJECT_ALIAS ALIAS ,p.ACCESS_PREDICATES ,p.FILTER_PREDICATES
كما ترون من الاستعلام نفسه ، فإنه يعرض أفضل 50 عمود بحث ويتوقع أنفسهم بعدد مرات ظهور ASH في الساعات الثلاث الأخيرة. على الرغم من حقيقة أن ASH تقوم بتخزين اللقطات فقط كل ثانية ، إلا أن أخذ العينات في القواعد المحمّلة يمثل تمثيليًا كبيرًا. يمكن أن يوضح عدة نقاط:
- يعرض حقل cols - أعمدة البحث نفسها ، و total_by_cols - مجموع الإدخالات في سياق هذه الأعمدة.
- أعتقد أنه من الواضح أن هذه المعلومات في حد ذاتها ليست علامة كافية على المشكلة ، لأنه على سبيل المثال ، يمكن للعديد من عمليات المسح الكامل لمرة واحدة أن تدمر الإحصائيات بسهولة ، لذلك سيكون عليك بالتأكيد التفكير في الاستعلامات نفسها وتواترها (v $ sqlstats ، dba_hist_sqlstat)
- التجميع حسب OBJECT_ALIAS داخل SQL_ID ، plan_hash_value مهم لدمج تقديرات الجدول والجدول بحسب الكائن ، لأن عند الوصول إلى الجدول من خلال الفهرس ، سيتم تقسيم المسند إلى خطوط مختلفة من الخطة:
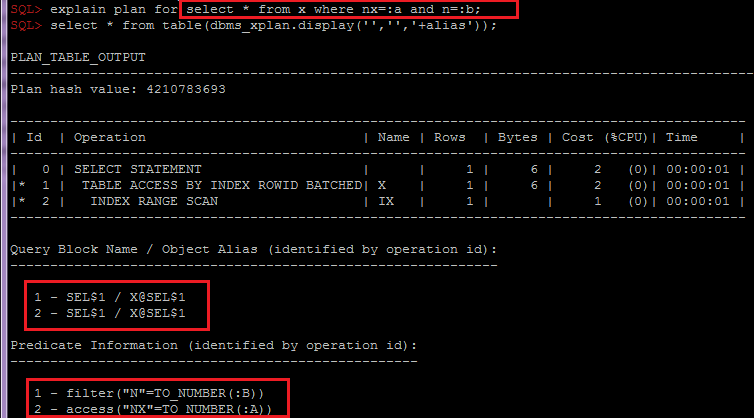
حسب الحاجة ، يمكن تعديل هذا البرنامج النصي بسهولة لجمع معلومات إضافية في أقسام أخرى ، على سبيل المثال ، مع مراعاة التقسيم أو التوقعات. وبعد تحليل هذه المعلومات بالفعل ، إلى جانب تحليل إحصائيات الجدول وفهارسه ، ونظام البيانات العام ومنطق الأعمال ، يمكنك تمرير توصيات للمطورين أو المهندسين المعماريين لاختيار حل ، على سبيل المثال: خيارات لإزالة الطابع أو تغيير مخطط التقسيم أو فهارسه.
غالبًا ما يتم نسيان تحليل حركة مرور SQL * net ، وهناك أيضًا العديد من التفاصيل الدقيقة ، على سبيل المثال: fetch-size ، SQLNET.COMPRESSION ، وأنواع البيانات الموسعة ، التي تسمح بتقليل عدد رحلات Roundtripes ، وما إلى ذلك ، ولكن هذا موضوع لمقال منفصل.
في الختام ، أود أن أقول إنه بعد أن أصبح المستخدمون أقل تسامحًا مع التأخير ، أصبح تحسين الأداء ميزة تنافسية.