نبدأ سلسلة من المقالات التي تصف المواقف المختلفة التي أدى فيها استخدام أدوات Intel للمطورين إلى زيادة كبيرة في سرعة البرنامج وتحسين نوعيته.
حدث قصتنا الأولى في جامعة نوفوسيبيرسك ، حيث طور الباحثون أداة برمجية لمحاكاة عددي ديناميكيات مشاكل المغنطيسية الديناميكية أثناء تأين الهيدروجين. تم تنفيذ هذا العمل كجزء من المشروع العالمي لنمذجة الكائنات الفيزيائية الفلكية
AstroPhi ؛ تم استخدام معالجات
Intel Xeon Phi كنظام أساسي للأجهزة. نتيجة لاستخدام
Intel Advisor و
Intel Trace Analyzer and Collector ، زاد أداء الحوسبة 3 مرات ، وانخفضت سرعة حل مشكلة واحدة من أسبوع إلى يومين.
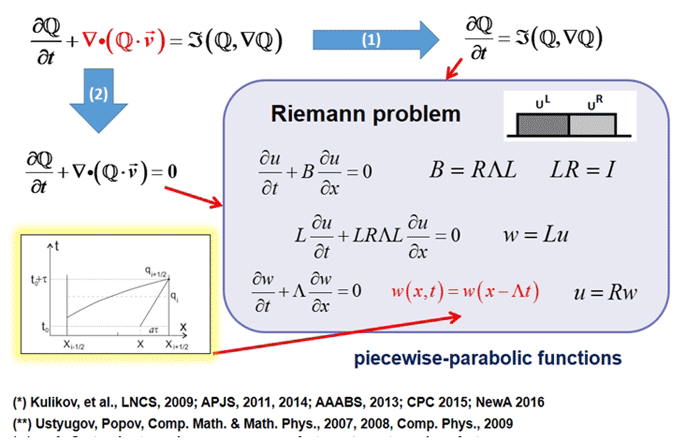
وصف المهمة
تلعب النماذج الرياضية دورا هاما في الفيزياء الفلكية الحديثة ، كما هو الحال في أي علم. هذه أداة عالمية لدراسة العمليات التطورية غير الخطية في الكون. تتطلب النماذج عالية الدقة للعمليات الفلكية الفيزيائية المعقدة موارد حسابية ضخمة. يقوم مشروع AstroPhi NSU بتطوير رمز البرنامج الفيزيائي الفائق لأجهزة الكمبيوتر العملاقة استنادًا إلى معالجات Intel Xeon Phi. يتعلم الطلاب كتابة برامج المحاكاة لوقت تشغيل متوازي للغاية ، واكتساب معرفة مهمة سيحتاجون إليها عند العمل مع الحواسيب الفائقة الأخرى.
كان لطريقة النمذجة العددية المستخدمة في المشروع عدد من المزايا المهمة:
- نقص اللزوجة الصناعية ،
- الثقل الجليلي ،
- ضمان عدم الحد من الانتروبيا ،
- موازاة بسيطة
- القابلية للتوسعة لانهائية.
العوامل الثلاثة الأولى هي مفتاح النمذجة الواقعية للآثار الجسدية الهامة في مشاكل الفيزياء الفلكية.
ابتكر فريق البحث أداة النمذجة الجديدة للهياكل متعددة الموازي القائمة على Intel Xeon Phi. كانت مهمتها الرئيسية هي تجنب الاختناقات في تبادل البيانات بين العقد وتبسيط عملية تحسين الكود قدر الإمكان. يستخدم حل الموازاة MPI ، وللتوجيه ، تضيف إرشادات Intel Advanced Vector Extensions 512 (Intel AVX-512) دعمًا لبطاقة SIM ذات 512 بت وتسمح للبرنامج بتعبئة 8 أرقام ذات فاصلة عائمة مزدوجة الدقة أو 16 رقمًا أحادي الدقة (32 بت) ) إلى المتجهات 512 بت طويل. وبالتالي ، يتم معالجة ضعف عدد عناصر البيانات لكل تعليمة من عند استخدام AVX / AVX2 وأربعة أضعاف عند استخدام SSE.
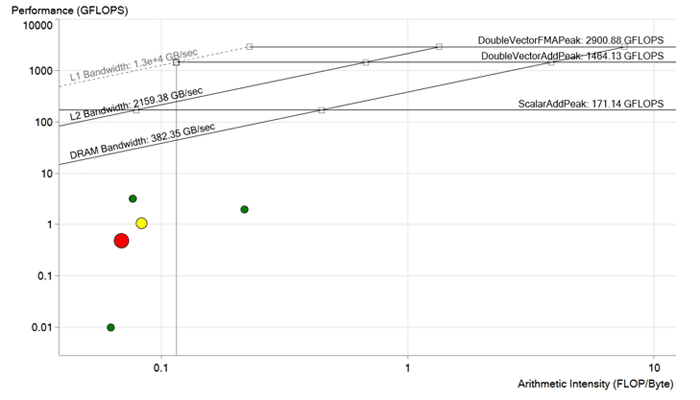 الصورة قبل التحسين. كل نقطة هي دورة المعالجة. كلما كانت النقطة أكبر وأكثر احمرارًا ، كلما طالت الدورة ، وكلما زاد تأثيرها ، كان تأثير تحسينها أكثر. تقع النقطة الحمراء أقل بكثير من الحد الأقصى لعرض النطاق الترددي DRAM ويتم حسابها بأداء أقل من 1 GFLOP. لديها إمكانات كبيرة جدا للتحسين.
الصورة قبل التحسين. كل نقطة هي دورة المعالجة. كلما كانت النقطة أكبر وأكثر احمرارًا ، كلما طالت الدورة ، وكلما زاد تأثيرها ، كان تأثير تحسينها أكثر. تقع النقطة الحمراء أقل بكثير من الحد الأقصى لعرض النطاق الترددي DRAM ويتم حسابها بأداء أقل من 1 GFLOP. لديها إمكانات كبيرة جدا للتحسين.رمز التحسين
قبل التحسين ، كان للرمز مشاكل معينة في التبعيات وأحجام المتجهات. كان هدف التحسين هو إزالة تبعيات المتجهات وتحسين عمليات تحميل البيانات في الذاكرة باستخدام الحجم الأمثل للمتجهات والمصفوفات لـ Xeon Phi. من أجل التحسين ، استخدمنا
Intel Advisor و
Intel Trace Analyzer and Collector ، وهما أداتان من
Intel Parallel Studio XE .
يعد Intel Advisor ، كما يوحي اسمه ، مستشارًا - أداة برمجية تقيم درجة التحسين - الاتجاه (باستخدام تعليمات AVX أو SIMD) والموازنة لتحقيق أقصى أداء. باستخدام هذه الأداة ، تمكن الفريق من إجراء تحليل عام للدورات ، مع تسليط الضوء على ذوي الإنتاجية المنخفضة ، مما يشير إلى إمكانية التحسين وتحديد ما يمكن تحسينه وما إذا كانت اللعبة تستحق كل هذا العناء. قام Intel Advisor بفرز الدورات حسب الإمكانات ، وأضاف الرسائل إلى المصدر من أجل تحسين قراءة تقرير برنامج التحويل البرمجي. كما قدم معلومات مهمة مثل أوقات الدورات ، واعتمادات البيانات ، وأنماط الوصول إلى الذاكرة من أجل ناقل آمن وفعال.
يعد Intel Trace Analyzer and Collector طريقة أخرى لتحسين الكود. ويتضمن تشكيل وظائف الاتصالات وتحليل MPI لتحسين التدرج الضعيف والقوي. ساعدت هذه الأداة الرسومية الفريق على فهم سلوك MPI للتطبيق ، والعثور بسرعة على الاختناقات ، والأهم من ذلك ، زيادة الأداء على بنية Intel.
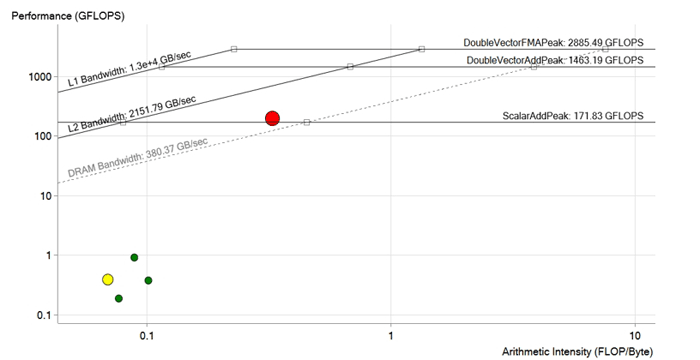 الصورة بعد التحسين. أثناء تحسين حلقة حمراء ، تمت إزالة تبعيات ناقل البيانات ، وتم تحسين عمليات التحميل في الذاكرة ، وتم تكييف أحجام المتجهات والمصفوفات لتعليمات Intel Xeon Phi و AVX-512. زاد الأداء إلى 190 GFLOPS ، أي حوالي 200 مرة. الآن هو فوق الحد DRAM وعلى الأرجح محدودة بخصائص ذاكرة التخزين المؤقت L2
الصورة بعد التحسين. أثناء تحسين حلقة حمراء ، تمت إزالة تبعيات ناقل البيانات ، وتم تحسين عمليات التحميل في الذاكرة ، وتم تكييف أحجام المتجهات والمصفوفات لتعليمات Intel Xeon Phi و AVX-512. زاد الأداء إلى 190 GFLOPS ، أي حوالي 200 مرة. الآن هو فوق الحد DRAM وعلى الأرجح محدودة بخصائص ذاكرة التخزين المؤقت L2يؤدي
لذلك ، بعد كل التحسينات والتحسينات ، حقق الفريق 190 أداء GFLOPS بكثافة حسابية قدرها 0.3 FLOP / b ، واستخدام 100 ٪ وعرض النطاق الترددي للذاكرة 573 GB / s.
 مقتطف الشفرة الأمثل
مقتطف الشفرة الأمثل