المادة في السؤال.
مقدمة
تقتصر أنظمة التعرف الحديثة على تصنيفها في عدد صغير نسبيًا من الطبقات غير المرتبطة ارتباطًا وثيقًا. يتيح جذب المعلومات النصية ، حتى غير المتعلقة بالصور ، إثراء النموذج وإلى حد ما حل المشكلات التالية:
- إذا ارتكب نموذج التعرف خطأً ، فغالبًا ما يكون هذا الخطأ غير قريب من الفئة الصحيحة ؛
- لا توجد وسيلة للتنبؤ بشيء ينتمي إلى فصل جديد لم يتم تمثيله في مجموعة البيانات التدريبية.
يقترح النهج المقترح عرض الصور في فضاء دلالي غني حيث تكون التسميات ذات الطبقات المتشابهة أقرب إلى بعضها البعض من التسميات ذات الطبقات الأقل تشابهًا. نتيجةً لذلك ، يعطي النموذج أقل بُعدًا بشكل واضح عن الفئة الحقيقية للتنبؤات. علاوة على ذلك ، يمكن للنموذج ، مع مراعاة القرب المرئي والدلالي ، تصنيف الصور المرتبطة بفصل لم يتم تمثيله في مجموعة بيانات التدريب بشكل صحيح.
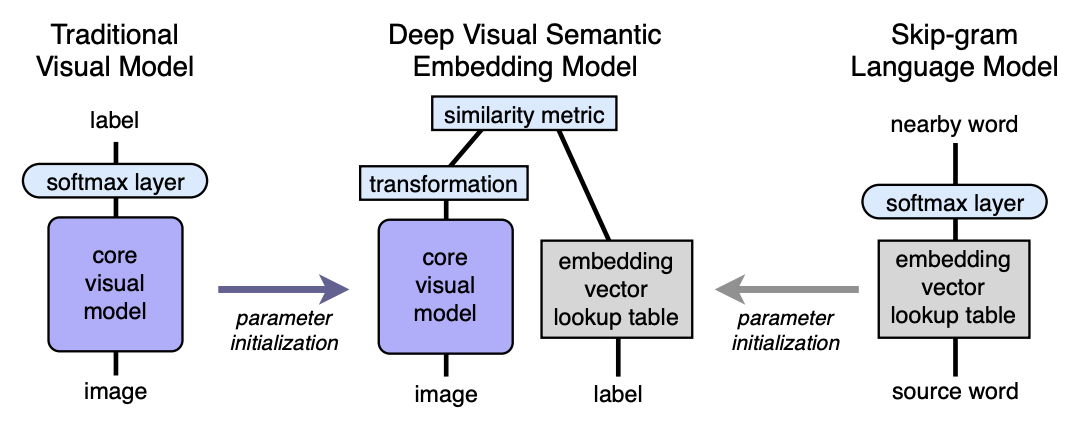
الخوارزمية. هندسة معمارية
- نقوم بتدريب نموذج اللغة مسبقًا ، والذي يوفر زخارف جيدة ذات مغزى معاني. البعد من الفضاء هو ن. بعد ذلك ، سيتم أخذ n يساوي 500 أو 1000.
- نقوم بتدريب النموذج المرئي مسبقًا ، والذي يصنف الكائنات جيدًا إلى 1000 فئة.
- لقد قمنا بقص طبقة softmax الأخيرة من النموذج البصري المُدرَّب مسبقًا ونضيف طبقة متصلة بالكامل من 4096 إلى n. نقوم بتدريب النموذج الناتج لكل صورة للتنبؤ بالتضمين المقابل لتسمية الصورة.
دعونا شرح بمساعدة من التعيينات. اجعل LM نموذج لغة ، VM كنموذج مرئي مع softmax مقطوع وطبقة متصلة بالكامل ، I - صورة ، L - تسمية للصورة ، LM (L) - تتضمن التسمية في الفضاء الدلالي. ثم في الخطوة الثالثة نقوم بتدريب جهاز VM بحيث:
العمارة:
نموذج اللغة
لمعرفة نموذج اللغة ، تم استخدام نموذج skip-gram ، وهو عبارة عن مجموعة من 5.4 مليار كلمة مأخوذة من wikipedia.org. استخدم النموذج طبقة softmax ذات التسلسل الهرمي للتنبؤ بالمفاهيم ذات الصلة ، نافذة - 20 كلمة ، عدد مرات المرور عبر الجسم - 1. لقد ثبت تجريبياً أن حجم التضمين من الأفضل أن يأخذ 500-1000.
تُظهر صورة ترتيب الطبقات في الفضاء أن النموذج قد تعلم بنية دلالة نوعية وغنية. على سبيل المثال ، بالنسبة لأنواع معينة من أسماك القرش في الفضاء الدلالي الناتج ، فإن 9 من الجيران الأقربين هم الأنواع التسعة الأخرى من أسماك القرش.
نموذج بصري
الهندسة المعمارية التي فازت بمنافسة ILSVRC 2012 كانت بمثابة نموذج بصري. تمت إزالة Softmax فيه وتمت إضافة طبقة متصلة بالكامل للحصول على حجم التضمين المطلوب في الإخراج.
وظيفة الخسارة
اتضح أن اختيار وظيفة الخسارة هو المهم. تم استخدام مزيج من التشابه جيب التمام وفقدان رتبة المفصلي. شجّعت وظيفة الفقدان منتجًا عدديًا أكبر بين متجه النتيجة في الشبكة المرئية وتضمين الملصق المطابق ، وتغريمه لمنتج عددي كبير بين نتيجة الشبكة المرئية وتضمينات تسميات عشوائية محتملة للصور. لم يتم تحديد عدد الملصقات العشوائية التعسفية ، ولكن كان محددًا بالشرط الذي أصبح بموجبه مجموع المنتجات العددية ذات الملصقات الكاذبة أكثر من مجرد منتج عددي ذو ملصق صالح مطروحًا بهامش ثابت (ثابت يساوي 0.1). بالطبع ، تم التطبيع المسبق لجميع المتجهات.
![خسارة $ (I، L) = \ sum_ {j} {max [0، margin - (L، VM (I)) + (wrongL_j، VM (I))]} $](https://habrastorage.org/getpro/habr/formulas/5a2/327/384/5a232738434707dcfd35ab20cfe59460.svg)
عملية التدريب
في البداية ، تم تدريب آخر طبقة متصلة بالكامل تم إضافتها ، ولم تقم بقية الشبكة بتحديث الوزن. في هذه الحالة ، تم استخدام طريقة تحسين SGD. بعد ذلك ، تم إذابة الشبكة المرئية بالكامل وتدريبها باستخدام مُحسِّن Adagrad بحيث يتم التدرج اللوني أثناء الانتشار الخلفي على طبقات مختلفة من الشبكة بشكل صحيح.
تنبؤ
أثناء التنبؤ ، من الصورة باستخدام الشبكة المرئية ، نحصل على بعض المتجهات في الفضاء الدلالي لدينا. بعد ذلك ، نجد أقرب الجيران ، أي بعض الملصقات الممكنة وبصورة خاصة نعرضهم مرة أخرى في مجموعات بيانات ImageNet للتسجيل. إن إجراء العرض الأخير ليس بهذه البساطة ، لأن التصنيفات الموجودة في ImageNet هي مجموعة من المرادفات وليست مجرد تسمية واحدة. إذا كان القارئ مهتمًا بمعرفة التفاصيل ، فإنني أوصي بالمقال الأصلي (الملحق 2).
النتائج
تمت مقارنة نتائج نموذج DEVISE بطرازين:
- نموذج Softmax الأساسي - نموذج رؤية حديث (SOTA - في وقت النشر)
- نموذج التضمين العشوائي هو نسخة من نموذج DEVISE الموصوف ، حيث لا يتم تعلم حفلات الزفاف عن طريق نموذج اللغة ، ولكن يتم التهيئة بشكل تعسفي.
لتقييم الجودة ، تم استخدام مقاييس "مسطح" للضغط على @ k ودقة القياس الهرمي @ k. يعد قياس "مسطح" hit @ k هو النسبة المئوية لصور الاختبار التي توجد التسمية الصحيحة لها من بين الخيارات الأولى المتوقعة من k. تم استخدام مقياس الدقة الهرمية @ k لتقييم جودة المراسلات الدلالية. يستند هذا المقياس إلى التسلسل الهرمي للتسمية في ImageNet. لكل تسمية حقيقية وثابتة ك ، المجموعة
التسميات الصحيحة بشكل واضح - قائمة حقائق الأرض. الحصول على التنبؤ (أقرب الجيران) كانت نسبة التقاطع مع قائمة الحقيقة الأساسية.

توقع الباحثون أن يُظهر نموذج softmax أفضل النتائج على القياس المسطح نظرًا لأنه يقلل من الخسائر الناتجة عن الانتروبيا ، وهو مناسب جدًا لمقاييس ضربات التشغيل "مسطحة" @ k. فوجئ المؤلفون بمدى قرب نموذج DEVISE من طراز softmax ، ووصوله إلى التكافؤ عند k الكبيرة وحتى التجاوز عند k = 20.
على المقياس الهرمي ، يظهر نموذج DEVISE نفسه بكل مجده ويتفوق على بيسبول softmax بنسبة 3٪ مقابل k = 5 و 7٪ لـ k = 20.
التعلم بدون طلقة
تتمثل إحدى الميزات الخاصة لنموذج DEVISE في القدرة على توفير تنبؤات كافية للصور التي لم تشهدها علامات الشبكة مطلقًا أثناء التدريب. على سبيل المثال ، أثناء التدريب ، شاهدت الشبكة صورًا تحمل علامات وسمك قرش النمر وسمك القرش الثور وسمك القرش الأزرق ولم تلتق مطلقًا بسمك القرش. نظرًا لأن نموذج اللغة له تمثيل لسمك القرش في الفضاء الدلالي وقريبًا من حفلات أنواع مختلفة من سمك القرش ، فمن المحتمل جدًا أن يقدم النموذج تنبؤًا مناسبًا. وهذا ما يسمى القدرة على التعميم - التعميم.
دعنا نوضح بعض الأمثلة على تنبؤات Zero-Shot:

لاحظ أن طراز DEVISE ، حتى في افتراضاته الخاطئة ، أقرب إلى الإجابة الصحيحة من الافتراضات الخاطئة لنموذج softmax.
لذلك ، فإن النموذج المقدم يفقد قليلاً إلى softmax إلى خط الأساس على المقاييس المسطحة ، لكنه يفوز بشكل كبير في القياس الهرمي @ k المتري. يتمتع هذا النموذج بالقدرة على التعميم ، مما ينتج عنه تنبؤات كافية للصور التي لم تحقق الشبكة لها علامات (التعلم بدون أية صور).
يمكن تنفيذ النهج الموضح بسهولة ، لأنه يعتمد على نموذجين تم تدريبهما مسبقًا - اللغة والبصرية.