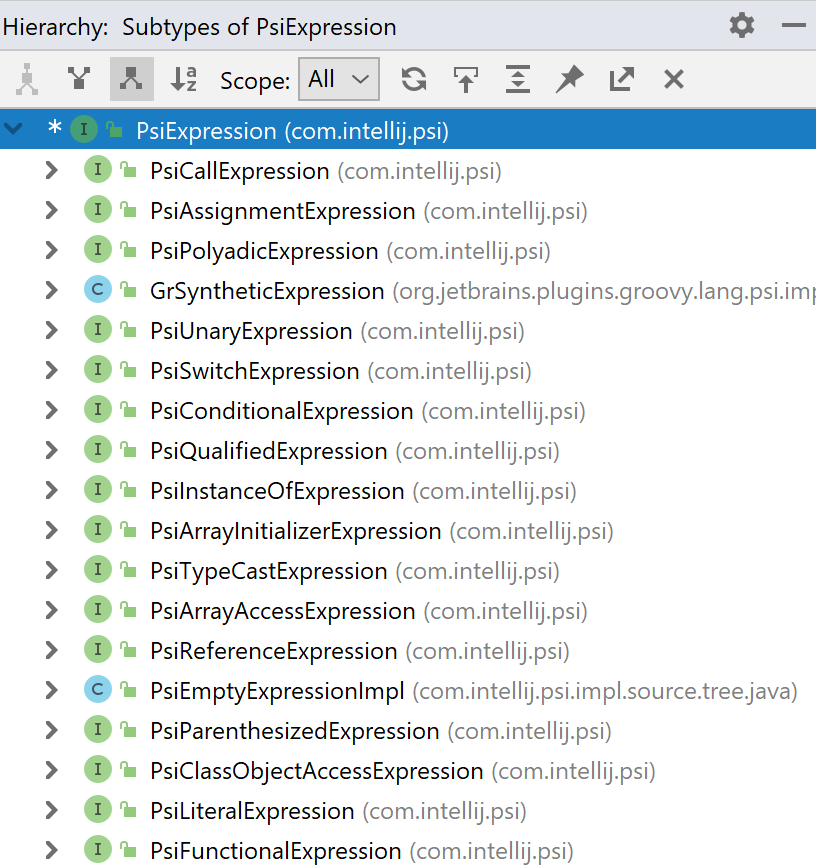
 يعد البحث عن التعليمات البرمجية والتنقل ميزات مهمة لأي IDE. في Java ، أحد خيارات البحث الشائعة الاستخدام هو البحث عن جميع تطبيقات الواجهة. تسمى هذه الميزة غالبًا Type Hierarchy ، ويبدو تمامًا مثل الصورة الموجودة على اليمين.
يعد البحث عن التعليمات البرمجية والتنقل ميزات مهمة لأي IDE. في Java ، أحد خيارات البحث الشائعة الاستخدام هو البحث عن جميع تطبيقات الواجهة. تسمى هذه الميزة غالبًا Type Hierarchy ، ويبدو تمامًا مثل الصورة الموجودة على اليمين.
من غير الفعال التكرار في جميع فئات المشروع عندما يتم استدعاء هذه الميزة. يتمثل أحد الخيارات في حفظ التسلسل الهرمي للفئة الكاملة في الفهرس أثناء التحويل البرمجي نظرًا لأن المترجم يقوم بإنشائه على أي حال. نقوم بذلك عندما يتم تشغيل التحويل البرمجي بواسطة IDE ولا يتم تفويضه ، على سبيل المثال ، إلى Gradle. ولكن هذا لا يعمل إلا إذا لم يتغير شيء في الوحدة النمطية بعد التحويل البرمجي. بشكل عام ، الكود المصدري هو أكثر مزود معلومات محدّثًا ، وتستند الفهارس إلى الكود المصدري.
العثور على الأطفال المباشرين مهمة بسيطة إذا لم نتعامل مع واجهة وظيفية. عند البحث عن تطبيقات واجهة Foo ، نحتاج إلى العثور على جميع الفئات التي implements Foo والواجهات التي extends Foo ، بالإضافة إلى فصول مجهولة new Foo(...) {...} . للقيام بذلك ، يكفي إنشاء شجرة بناء جملة لكل ملف مشروع مسبقًا ، والعثور على الإنشاءات المقابلة ، وإضافتها إلى فهرس. ومع ذلك ، هناك تعقيد هنا: قد تبحث عن واجهة com.example.goodcompany.Foo ، بينما يتم استخدام org.example.evilcompany.Foo فعليًا. هل يمكننا وضع الاسم الكامل للواجهة الأصل في الفهرس مقدمًا؟ يمكن أن يكون خادعا. على سبيل المثال ، قد يبدو الملف الذي تستخدم فيه الواجهة كما يلي:
من خلال النظر إلى الملف وحده ، من المستحيل معرفة ما هو اسم Foo المؤهل بالكامل الفعلي. سيتعين علينا النظر في محتوى العديد من الحزم. ويمكن تعريف كل حزمة في عدة أماكن في المشروع (على سبيل المثال ، في العديد من ملفات JAR). إذا قمنا بإجراء تحليل مناسب للرمز عند تحليل هذا الملف ، فستستغرق عملية الفهرسة الكثير من الوقت. لكن المشكلة الرئيسية هي أن الفهرس المبني على MyFoo.java سيعتمد على الملفات الأخرى أيضًا. يمكننا نقل إعلان واجهة Foo ، على سبيل المثال ، من حزمة org.example.foo إلى حزمة org.example.bar ، دون تغيير أي شيء في ملف MyFoo.java ، ولكن سيتم تغيير اسم Foo المؤهل بالكامل.
في IntelliJ IDEA ، تعتمد الفهارس فقط على محتوى ملف واحد. من ناحية ، هو مناسب للغاية: يصبح الفهرس المرتبط بملف معين غير صالح عند تغيير الملف. من ناحية أخرى ، يفرض قيودًا كبيرة على ما يمكن وضعه في الفهرس. على سبيل المثال ، لا يسمح بحفظ الأسماء المؤهلة بالكامل للفئات الرئيسية بشكل موثوق في الفهرس. لكن بشكل عام ، هذا ليس بالأمر السيء. عند طلب تسلسل هرمي للكتابة ، يمكننا العثور على كل ما يطابق طلبنا باسم قصير ، ثم تنفيذ دقة الرمز المناسبة لهذه الملفات وتحديد ما إذا كان هذا هو ما نبحث عنه. في معظم الحالات ، لن يكون هناك الكثير من الرموز الزائدة ولن يستغرق التحقق وقتًا طويلاً.
 ومع ذلك ، تتغير الأمور عندما يكون الفصل الذي نبحث عن أطفاله هو واجهة وظيفية. ثم ، بالإضافة إلى الفئات الفرعية الصريحة والمجهولة ، ستكون هناك تعبيرات lambda ومراجع الطريقة. ماذا نضعه في الفهرس الآن ، وما الذي يجب تقييمه أثناء البحث؟
ومع ذلك ، تتغير الأمور عندما يكون الفصل الذي نبحث عن أطفاله هو واجهة وظيفية. ثم ، بالإضافة إلى الفئات الفرعية الصريحة والمجهولة ، ستكون هناك تعبيرات lambda ومراجع الطريقة. ماذا نضعه في الفهرس الآن ، وما الذي يجب تقييمه أثناء البحث؟
لنفترض أن لدينا واجهة وظيفية:
@FunctionalInterface public interface StringConsumer { void consume(String s); }
الكود يحتوي على تعبيرات لامدا مختلفة. على سبيل المثال:
() -> {}
هذا يعني أنه يمكننا تصفية بسرعة lambdas التي تحتوي على عدد غير مناسب من المعلمات أو نوع الإرجاع غير مناسب بشكل واضح ، على سبيل المثال ، الفراغ بدلاً من عدم الفراغ. عادة ما يكون من المستحيل تحديد نوع الإرجاع بدقة أكبر. على سبيل المثال ، في s -> list.add(s) سيتعين عليك حل list add ، وربما ، تشغيل إجراء منتظم لاستنتاج الكتابة. يستغرق وقتًا ويعتمد على محتوى الملفات الأخرى.
نحن محظوظون إذا كانت الواجهة الوظيفية تأخذ خمس حجج. ولكن إذا استغرق الأمر واحدًا فقط ، فسيحتفظ المرشح بعدد كبير من اللمبات غير الضرورية. الأمر أسوأ عندما يتعلق الأمر بمراجع الأسلوب. بالمناسبة ، لا يستطيع المرء معرفة ما إذا كان مرجع الطريقة مناسب أم لا.
للحصول على الأمور في نصابها الصحيح ، قد يكون من المفيد النظر إلى ما يحيط لامدا. في بعض الأحيان ، كان يعمل. على سبيل المثال:
في جميع هذه الحالات ، يمكن تحديد الاسم المختصر للواجهة الوظيفية المقابلة من الملف الحالي ويمكن وضعه في الفهرس بجانب التعبير الوظيفي ، سواء كان لامدا أو مرجعًا للطريقة. لسوء الحظ ، في هذه المشروعات الواقعية ، تغطي هذه الحالات نسبة مئوية صغيرة جدًا من جميع اللمبات. في معظم الحالات ، يتم استخدام lambdas كوسائط طريقة:
list.stream() .filter(s -> StringUtil.isNonEmpty(s)) .map(s -> s.trim()) .forEach(s -> list.add(s));
أي من لامدا الثلاثة يمكن أن تحتوي على StringConsumer ؟ من الواضح ، لا شيء. هنا لدينا سلسلة Stream API التي تحتوي فقط على واجهات وظيفية من المكتبة القياسية ، ولا يمكن أن يكون لها النوع المخصص.
ومع ذلك ، يجب أن يكون IDE قادراً على رؤية الحيلة ومنحنا إجابة دقيقة. ماذا لو كانت list ليست java.util.List بالضبط ، و list.stream() تُرجع شيئًا مختلفًا عن java.util.stream.Stream ؟ بعد ذلك ، سيتعين علينا حل list التي ، كما نعلم ، لا يمكن القيام بها بشكل موثوق استنادًا إلى محتوى الملف الحالي فقط. وحتى لو فعلنا ذلك ، يجب ألا يعتمد البحث على تنفيذ المكتبة القياسية. ماذا لو قمنا في هذا المشروع بالذات باستبدال java.util.List بفئة خاصة بنا؟ يجب أن يأخذ البحث هذا في الاعتبار. وبطبيعة الحال ، يتم استخدام لامدا ليس فقط في التدفقات القياسية: هناك العديد من الطرق الأخرى التي يتم تمريرها.
نتيجة لذلك ، يمكننا الاستعلام عن الفهرس للحصول على قائمة بجميع ملفات Java التي تستخدم lambdas مع العدد المطلوب من المعلمات ونوع الإرجاع صالح (في الواقع ، نحن نبحث فقط عن أربعة خيارات: باطلة ، غير خالية ، منطقية ، و وجدت). وماذا بعد؟ هل نحن بحاجة إلى إنشاء شجرة PSI كاملة (نوع من شجرة التحليل مع دقة الرمز ، والاستدلال على الكتابة ، والميزات الذكية الأخرى) لكل من هذه الملفات وتنفيذ استدلال مناسب للكتابة على lambdas؟ بالنسبة لمشروع كبير ، سيستغرق الأمر الأعمار للحصول على قائمة بجميع تطبيقات الواجهة ، حتى لو كان هناك اثنان منها فقط.
لذلك ، نحن بحاجة إلى اتخاذ الخطوات التالية:
- اسأل مؤشر (غير مكلف)
- بناء PSI (مكلف)
- استنتج نوع لامدا (مكلف للغاية)
بالنسبة لنظام التشغيل Java 8 والإصدارات الأحدث ، تعد عملية الاستدلال عملية مكلفة للغاية. في سلسلة نداء معقدة ، قد يكون هناك العديد من المعلمات العامة البديلة ، والتي يجب تحديد قيمها باستخدام إجراء الضرب الثابت الموصوف في الفصل 18 من المواصفات. بالنسبة للملف الحالي ، يمكن القيام بذلك في الخلفية ، ولكن معالجة الآلاف من الملفات غير المفتوحة بهذه الطريقة ستكون مهمة مكلفة.
ومع ذلك ، من الممكن هنا خفض الزوايا قليلاً: في معظم الحالات ، لا نحتاج إلى النوع الملموس. ما لم تقبل الطريقة معلمة عامة حيث يتم تمرير lambda إليها ، يمكن تجنب خطوة استبدال المعلمة النهائية. إذا استنتجنا نوع java.util.function.Function<T, R> lambda ، فلن يتعين علينا تقييم قيم المعلمات البديلة T و R : من الواضح بالفعل ما إذا كان يجب تضمين lambda في نتائج البحث أم لا. لا. ومع ذلك ، لن تنجح هذه الطريقة مثل:
static <T> void doSmth(Class<T> aClass, T value) {}
يمكن استدعاء هذه الطريقة باستخدام doSmth(Runnable.class, () -> {}) . ثم سيتم الاستدلال على نوع lambda كـ T ، لا يزال الاستبدال مطلوبًا. ومع ذلك ، هذه هي حالة نادرة. يمكننا بالفعل توفير بعض الوقت لوحدة المعالجة المركزية هنا ، ولكن حوالي 10٪ فقط ، لذلك هذا لا يحل المشكلة في جوهرها.
بدلاً من ذلك ، عندما يكون الاستدلال النوعي الدقيق معقدًا للغاية ، فيمكن تقريبه. على عكس المواصفات المقترحة ، دعها تعمل فقط على أنواع الفئات المحوّة ولا تخفض من مجموعة القيود ، لكن ببساطة اتبع سلسلة الاتصال. طالما أن النوع الذي تم مسحه لا يتضمن معلمات عامة ، فكل شيء على ما يرام. دعونا ننظر في الدفق من المثال أعلاه وتحديد ما إذا كان lambda الأخير ينفذ StringConsumer :
list متغير -> java.util.List نوعList.stream() طريقة → java.util.stream.Stream النوعStream.filter(...) -> java.util.stream.Stream type ، لسنا Stream.filter(...) للنظر في وسيطات filter- وبالمثل ،
Stream.map(...) → نوع java.util.stream.Stream Stream.forEach(...) طريقة → مثل هذه الطريقة موجودة ، المعلمة لديها نوع Consumer ، والذي من الواضح أنه ليس StringConsumer .
وهذه هي الطريقة التي يمكننا القيام بها دون الاستدلال النوعي العادي. مع هذا النهج البسيط ، مع ذلك ، من السهل الدخول في طرق مثقلة. إذا لم نقم بإجراء الاستنتاج الصحيح للكتابة ، فلن نتمكن من اختيار الطريقة المثقلة بشكل صحيح. في بعض الأحيان يكون ذلك ممكنًا: إذا كان للطرق عدد مختلف من المعلمات. على سبيل المثال:
CompletableFuture.supplyAsync(Foo::bar, myExecutor).thenRunAsync(s -> list.add(s));
هنا يمكننا أن نرى ما يلي:
- هناك طريقتان
CompletableFuture.supplyAsync ؛ الأولى تأخذ حجة واحدة والثانية تأخذ اثنين ، لذلك نختار الثانية. تقوم بإرجاع CompletableFuture . - هناك طريقتان
thenRunAsync أيضًا ، ويمكننا بالمثل اختيار الطريقة التي تأخذ وسيطة واحدة. المعلمة المقابلة لها نوع Runnable ، مما يعني أنها ليست StringConsumer .
إذا كانت هناك عدة طرق تأخذ نفس عدد المعلمات أو تحتوي على عدد متغير من المعلمات ولكنها تبدو مناسبة ، فسوف يتعين علينا البحث في جميع الخيارات. غالبًا ما لا يكون ذلك مخيفًا:
new StringBuilder().append(foo).append(bar).chars().forEach(s -> list.add(s));
new StringBuilder() الواضح أن new StringBuilder() ينشئ java.lang.StringBuilder . بالنسبة للمنشئين ، ما زلنا نحدد المرجع ، لكن الاستدلال النوعي المعقد غير مطلوب هنا. حتى لو كان هناك new Foo<>(x, y, z) ، فلن نستنتج قيم معلمات الكتابة لأن Foo فقط هي التي تهمنا.- هناك الكثير من أساليب
StringBuilder.append التي تأخذ وسيطة واحدة ، ولكنها جميعًا تُرجع نوع java.lang.StringBuilder ، لذلك نحن لا نهتم بأنواع foo و bar . - هناك طريقة
StringBuilder.chars واحدة ، وتقوم بإرجاع java.util.stream.IntStream . - هناك طريقة واحدة
IntStream.forEach ، ويستغرق نوع IntConsumer .
حتى إذا بقيت عدة خيارات ، فلا يزال بإمكانك تتبعها جميعًا. على سبيل المثال ، قد يكون نوع lambda الذي تم تمريره إلى ForkJoinPool.getInstance().submit(...) قد يكون ForkJoinPool.getInstance().submit(...) Runnable أو Runnable ، وإذا كنا نبحث عن خيار آخر ، فلا يزال بإمكاننا تجاهل هذا lambda.
الأمور تزداد سوءًا عندما تُرجع الطريقة معلمة عامة. ثم يفشل الإجراء وعليك القيام باستنتاج الكتابة الصحيح. ومع ذلك ، لقد دعمنا حالة واحدة. يتم عرضها بشكل جيد في مكتبة StreamEx الخاصة بي ، والتي تحتوي على AbstractStreamEx<T, S extends AbstractStreamEx<T, S>> فئة الملخص الذي يحتوي على أساليب مثل S filter(Predicate<? super T> predicate) . عادةً ما يعمل الأشخاص باستخدام StreamEx<T> extends AbstractStreamEx<T, StreamEx<T>> ملموسة StreamEx<T> extends AbstractStreamEx<T, StreamEx<T>> فئة. في هذه الحالة ، يمكنك استبدال معلمة الكتابة ومعرفة ذلك S = StreamEx .
هكذا تخلصنا من الاستدلال المكلف للكثير من الحالات. لكننا لم نفعل أي شيء مع بناء PSI. من المخيب للآمال أن يتم تحليل ملف يحتوي على 500 سطر من التعليمات البرمجية فقط لمعرفة أن lambda على السطر 480 لا يطابق استعلامنا. دعنا نعود إلى ساحة مشاركاتنا:
list.stream() .filter(s -> StringUtil.isNonEmpty(s)) .map(s -> s.trim()) .forEach(s -> list.add(s));
إذا كانت list عبارة عن متغير محلي ، أو معلمة أسلوب ، أو حقل في الفصل الحالي ، بالفعل في مرحلة الفهرسة ، يمكننا أن نجد إعلانها ونثبت أن اسم النوع المختصر هو List . وفقًا لذلك ، يمكننا وضع المعلومات التالية في فهرس آخر لامدا:
هذا النوع من lambda هو نوع معلمة من أساليب forEach يأخذ وسيطة واحدة ، تسمى نتيجة طريقة map تأخذ وسيطة واحدة ، تسمى نتيجة طريقة filter تأخذ وسيطة واحدة ، تسمى نتيجة طريقة stream الذي يأخذ وسيطات الصفر ، ودعا على كائن List .
كل هذه المعلومات متاحة من الملف الحالي ، وبالتالي ، يمكن وضعها في الفهرس. أثناء البحث ، نطلب مثل هذه المعلومات حول جميع lambdas من الفهرس ونحاول استعادة نوع lambda دون إنشاء PSI. أولاً ، سيتعين علينا إجراء بحث عالمي للفصول الدراسية باستخدام اسم List القصيرة. من الواضح ، لن نجد java.util.List فقط ولكن أيضًا java.awt.List أو شيء من رمز المشروع. بعد ذلك ، ستخضع كل هذه الفئات لنفس الإجراء التقريبي لاستدلال النوع الذي استخدمناه من قبل. غالبًا ما يتم تصفية الطبقات الزائدة بسرعة. على سبيل المثال ، java.awt.List لا يحتوي على طريقة stream ، لذلك سيتم استبعادها. ولكن حتى لو بقي شيء زائدًا ووجدنا العديد من المرشحين لنوع lambda ، فليس من المحتمل أن يطابق أي منهم استعلام البحث ، وسنستمر في تجنب بناء PSI كامل.
قد يكون البحث الشامل مكلفًا للغاية (عندما يحتوي المشروع على عدد كبير جدًا من فئات List ) ، أو لا يمكن حل بداية السلسلة في سياق ملف واحد (على سبيل المثال ، إنه حقل لفئة الأصل) ، أو سلسلة يمكن كسر كما إرجاع الأسلوب معلمة عامة. لن نستسلم وسوف نحاول البدء من جديد بالبحث العالمي عن الطريقة التالية للسلسلة. على سبيل المثال ، بالنسبة إلى map.get(key).updateAndGet(a -> a * 2) ، ينتقل التعليمة التالية إلى الفهرس:
هذا النوع من lambda هو نوع المعلمة updateAndGet لطريقة updateAndGet ، والتي تسمى نتيجة لطريقة get مع معلمة واحدة ، تسمى على كائن Map .
تخيل أننا محظوظون ، والمشروع به نوع Map واحد فقط - java.util.Map . يحتوي على طريقة get(Object) ، لكن لسوء الحظ ، تقوم بإرجاع معلمة عامة V بعد ذلك updateAndGet السلسلة ونبحث عن طريقة updateAndGet مع معلمة واحدة على مستوى العالم (باستخدام الفهرس ، بالطبع). ويسعدنا أن نكتشف أن هناك ثلاث طرق فقط في المشروع: في AtomicInteger AtomicLong و AtomicReference و AtomicReference مع أنواع المعلمات IntUnaryOperator و LongUnaryOperator و UnaryOperator ، على التوالي. إذا كنا نبحث عن أي نوع آخر ، فقد اكتشفنا بالفعل أن هذا لامدا لا يتطابق مع الطلب ، وليس لدينا لبناء PSI.
والمثير للدهشة ، هذا مثال جيد على ميزة تعمل بشكل أبطأ مع مرور الوقت. على سبيل المثال ، عندما تبحث عن تطبيقات للواجهة الوظيفية ولديك ثلاثة منها فقط في مشروعك ، يستغرق IntelliJ IDEA عشر ثوانٍ للعثور عليها. تتذكر أنه منذ ثلاث سنوات كان عددهم هو نفسه ، لكن IDE زودك بنتائج البحث في ثانيتين فقط على نفس الجهاز. وعلى الرغم من أن مشروعك ضخم ، إلا أنه نما بنسبة خمسة بالمائة فقط خلال هذه السنوات. من المعقول أن نبدأ في التذمر بشأن ما فعله مطورو IDE بشكل خاطئ لجعله بطيئًا بشكل رهيب.
في حين أننا ربما لم نغير شيئًا على الإطلاق. البحث يعمل تماما كما كان قبل ثلاث سنوات. الشيء هو أنه قبل ثلاث سنوات ، قمت فقط بالتبديل إلى Java 8 ولم يكن لديك سوى مائة lambdas في مشروعك. الآن ، قام زملاؤك بتحويل فصول مجهولة إلى lambdas ، وبدأوا في استخدام التدفقات أو بعض المكتبات التفاعلية. نتيجة لذلك ، بدلاً من مائة lambdas ، هناك عشرة آلاف. والآن ، للعثور على الخيارات الثلاثة الضرورية ، يتعين على IDE البحث في خيارات أكثر من مائة مرة.
قلت "ربما" لأننا ، بطبيعة الحال ، نعود إلى هذا البحث من وقت لآخر ونحاول تسريعه. لكن الأمر أشبه بالتجديف في مجرى النهر ، أو بالأحرى إلى أعلى الشلال. نحن نحاول جاهدين ، ولكن عدد lambdas في المشاريع يستمر في النمو بسرعة كبيرة.