سوق
الإحصاءات الموزعة والبيانات الضخمة ، وفقًا
للإحصاءات ، ينمو بنسبة تتراوح بين 18 و 19٪ سنويًا. لذا ، فإن مسألة اختيار البرامج لهذه الأغراض لا تزال ذات صلة. في هذا المنشور ، سنبدأ بالسبب في الحاجة إلى الحوسبة الموزعة ، والاطلاع على اختيار البرنامج ، والتحدث عن استخدام Hadoop مع Cloudera ، وأخيرا ، دعونا نتحدث عن اختيار الأجهزة وكيفية تأثيرها على الأداء بطرق مختلفة.
لماذا نحتاج إلى الحوسبة الموزعة في الأعمال العادية؟ كل شيء بسيط ومعقد في نفس الوقت. بسيط - لأنه في معظم الحالات ، نقوم بإجراء عمليات حسابية بسيطة نسبيًا لكل وحدة معلومات. إنه أمر صعب نظرًا لوجود الكثير من هذه المعلومات. كثير نتيجة لذلك ، يجب عليك
معالجة تيرابايت من البيانات في 1000 مؤشر
ترابط . وبالتالي ، فإن سيناريوهات الاستخدام عالمية تمامًا: يمكن تطبيق العمليات الحسابية أينما كان من الضروري مراعاة عدد كبير من المقاييس في مجموعة أكبر من البيانات.
مثال على ذلك مؤخرًا: تحدد سلسلة البيتزا Dodo Pizza استنادًا إلى تحليل لقاعدة طلبات العملاء بأنه عند اختيار بيتزا ذات حشوة تعسفية ، عادةً ما يعمل المستخدمون بست مجموعات أساسية فقط من المكونات بالإضافة إلى اثنين من المكونات العشوائية. وفقا لهذا ، ضبطت البيتزا المشتريات. بالإضافة إلى ذلك ، كانت قادرة على التوصية بشكل أفضل للمستخدمين بالمنتجات الإضافية المقدمة في مرحلة الطلب ، مما ساعد على زيادة الأرباح.
مثال آخر: أتاح
تحليل أوضاع السلع لمحل H&M تقليل النطاق في المتاجر الفردية بنسبة 40٪ ، مع الحفاظ على مستوى المبيعات. تم تحقيق ذلك من خلال التخلص من مراكز البيع الرديئة ، وتم أخذ الموسمية في الاعتبار في الحسابات.
اختيار الأداة
معيار الصناعة لهذا النوع من الحوسبة هو Hadoop. لماذا؟ لأن Hadoop هو إطار ممتاز وموثق جيدًا (يصدر Habr نفسه الكثير من المقالات المفصلة حول هذا الموضوع) ، ويرافقه مجموعة كاملة من المرافق والمكتبات. يمكنك إدخال مجموعات ضخمة من البيانات المهيكلة وغير المنظمة على حد سواء ، وسيقوم النظام نفسه بتوزيعها بين القوة الحاسوبية. علاوة على ذلك ، يمكن زيادة أو تعطيل هذه القدرات نفسها في أي وقت - نفس قابلية التوسع الأفقي في العمل.
في عام 2017 ،
خلصت شركة الاستشارات المؤثرة غارتنر
إلى أن Hadoop ستصبح قديمة. والسبب في ذلك هو أمر عادي للغاية: يعتقد المحللون أن الشركات سوف تهاجر بشكل كبير إلى السحابة ، لأنهم يمكن أن يدفعوا ثمن استخدام القوة الحاسوبية. العامل الثاني المهم ، الذي يُفترض أنه قادر على "دفن" Hadoop - هو سرعة العمل. لأن خيارات مثل Apache Spark أو Google Cloud DataFlow أسرع من MapReduce الكامنة في Hadoop.
تقع Hadoop على عدة أعمدة ، أبرزها تقنيات MapReduce (نظام توزيع البيانات للحوسبة بين الخوادم) ونظام ملفات HDFS. تم تصميم هذا الأخير خصيصًا لتخزين المعلومات الموزعة بين عقد الكتلة: يمكن وضع كل كتلة ذات حجم ثابت على عدة عقد ، وبفضل النسخ المتماثل ، يكون النظام مقاومًا لفشل العقد الفردية. بدلاً من جدول الملفات ، يتم استخدام خادم خاص يسمى NameNode.
يوضح الرسم التوضيحي أدناه سير عمل MapReduce. في المرحلة الأولى ، يتم تقسيم البيانات وفقًا لبعض الخصائص ، في المرحلة الثانية - يتم توزيعها وفقًا لقوة الحوسبة ، في المرحلة الثالثة - يتم إجراء الحساب.
تم إنشاء MapReduce في الأصل بواسطة Google لتلبية احتياجات البحث. ثم انتقلت MapReduce إلى رمز مجاني ، وتولى Apache المشروع. حسنًا ، انتقلت Google تدريجياً إلى حلول أخرى. فارق بسيط مثير للاهتمام: في الوقت الحالي ، تمتلك Google مشروعًا يُدعى Google Cloud Dataflow ، يتم وضعه كخطوة تالية بعد Hadoop ، كبديل سريع.
تكشف نظرة فاحصة أن Google Cloud Dataflow يستند إلى مجموعة متنوعة من Apache Beam ، بينما يتضمن Apache Beam إطار عمل Apache Spark جيد التوثيق ، والذي يسمح لنا بالتحدث عن نفس سرعة تنفيذ القرار تقريبًا. حسنًا ، يعمل Apache Spark جيدًا على نظام ملفات HDFS ، والذي يسمح لك بنشره على خوادم Hadoop.
أضف هنا حجم الوثائق وحلول تسليم المفتاح لـ Hadoop و Spark مقابل Google Cloud Dataflow ، ويصبح اختيار الأداة واضحًا. علاوة على ذلك ، يمكن للمهندسين أن يقرروا بأنفسهم أي كود - تحت Hadoop أو Spark - ليتم تنفيذه لهم ، مع التركيز على المهمة والخبرة والمؤهلات.
سحابة أو خادم محلي
حتى أن الاتجاه نحو الانتقال الشامل إلى السحابة قد ولد مصطلحًا مثيرًا للاهتمام مثل Hadoop-as-a-service. في هذا السيناريو ، أصبحت إدارة الخوادم المتصلة مهمة جدًا. لأنه ، للأسف ، على الرغم من شعبيته ، فإن Hadoop الخالصة هي أداة صعبة التكوين ، حيث يجب القيام بالكثير من الأشياء بيديك. على سبيل المثال ، تكوين الخوادم بشكل فردي ، ومراقبة أدائها ، وتكوين العديد من المعلمات بعناية. بشكل عام ، يمثل العمل مع أحد الهواة فرصة رائعة لفهم شيء ما أو تفويت شيء ما.
لذلك ، اكتسبت توزيعات مختلفة ، والتي تم تجهيزها في البداية بأدوات النشر والإدارة المناسبة ، شعبية كبيرة. واحدة من التوزيعات الأكثر شعبية التي تدعم Spark وتجعل الأمور سهلة هي Cloudera. يحتوي على نسخة مدفوعة ومجانية - وفي النهاية ، تتوفر جميع الوظائف الأساسية ، وبدون تحديد عدد العقد.

أثناء الإعداد ، سيتصل Cloudera Manager عبر SSH بخوادمك. نقطة مهمة: أثناء التثبيت ، من الأفضل الإشارة إلى أنه يجب أن يتم بواسطة ما يسمى
الطرود : حزم خاصة ، كل منها يحتوي على جميع المكونات الضرورية التي تم تكوينها للعمل مع بعضها البعض. في الواقع ، هذا هو نسخة محسنة من مدير الحزمة.
بعد التثبيت ، نحصل على وحدة التحكم في إدارة نظام المجموعة ، حيث يمكنك رؤية القياس عن بُعد حسب المجموعة ، والخدمات المثبتة ، بالإضافة إلى أنه يمكنك إضافة / إزالة الموارد وتعديل تكوين نظام المجموعة.
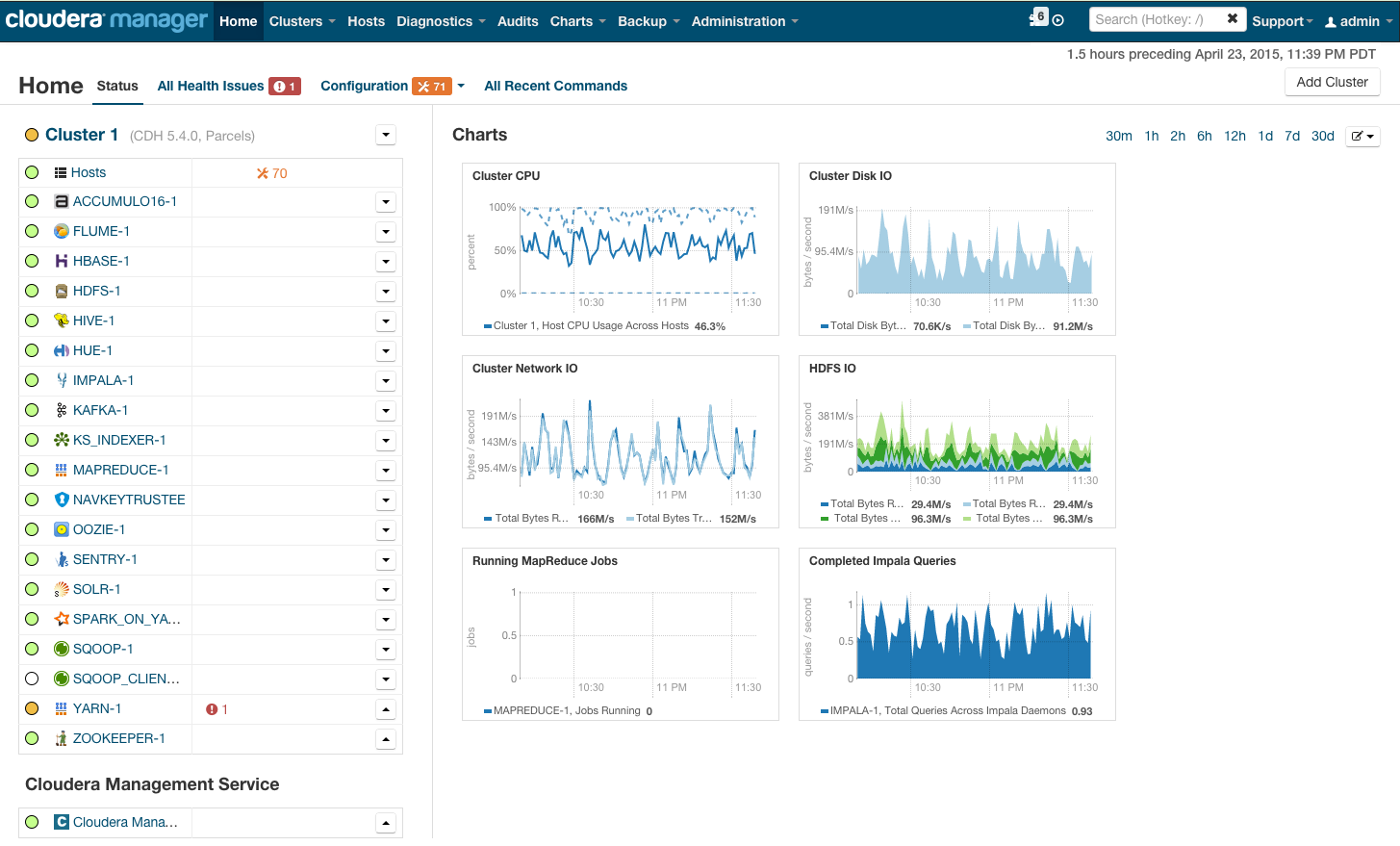
نتيجة لذلك ، ترى مقصورة الصاروخ التي ستأخذك إلى المستقبل المشرق لـ BigData. ولكن قبل أن تقولي "هيا بنا" ، دعنا نقع تحت الغطاء.
متطلبات الأجهزة
يذكر كلوديرا التكوينات المختلفة الممكنة على موقعه على الإنترنت. المبادئ العامة التي بنيت عليها مبينة في الرسم التوضيحي:
لتليين هذه الصورة المتفائلة يمكن MapReduce. إذا نظرت مرة أخرى إلى المخطط من القسم السابق ، يصبح من الواضح أنه في جميع الحالات تقريبًا قد تتعرض مهمة MapReduce إلى عنق الزجاجة عند قراءة البيانات من القرص أو من الشبكة. هذا وارد أيضًا في مدونة كلوديا. نتيجة لذلك ، بالنسبة إلى أي عمليات حسابية سريعة ، بما في ذلك من خلال Spark ، والتي تُستخدم غالبًا للحسابات في الوقت الفعلي ، تعد سرعة الإدخال / الإخراج مهمة جدًا. لذلك ، عند استخدام Hadoop ، من المهم جدًا أن تدخل الآلات المتوازنة والسريعة إلى المجموعة ، والتي ، بعبارة خفيفة ، لا يتم توفيرها دائمًا في البنية التحتية السحابية.
يتم تحقيق موازنة التحميل المتوازنة من خلال استخدام المحاكاة الافتراضية Openstack على الخوادم التي تحتوي على وحدات معالجة مركزية قوية متعددة النواة. يتم تخصيص عقد البيانات موارد المعالج والأقراص المحددة. في حل
Atos Codex Data Lake Engine ، يتم تحقيق المحاكاة الافتراضية الواسعة ، وهذا هو السبب في أننا فزنا في الأداء على حد سواء (تم تقليل تأثير البنية التحتية للشبكة) وفي TCO (تم استبعاد الخوادم الفعلية غير الضرورية).
في حالة استخدام خوادم BullSequana S200 ، نحصل على حمولة موحدة جدًا ، خالية من بعض الاختناقات. يتضمن الحد الأدنى من التكوين 3 خوادم BullSequana S200 ، ولكل منها جهازي JBOD ، بالإضافة إلى خيارات S200 إضافية اختيارية تحتوي على أربعة عقد بيانات متصلة اختياريًا. فيما يلي مثال للتحميل في اختبار TeraGen:
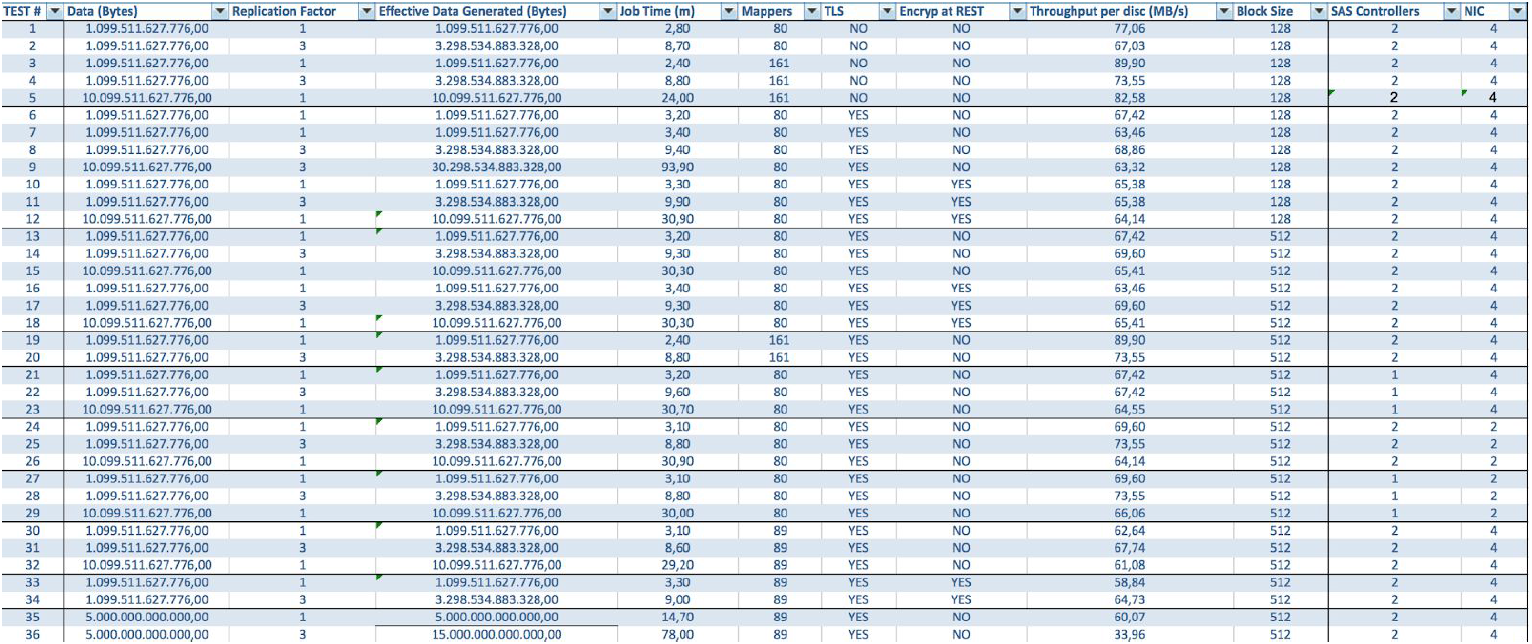
تُظهر الاختبارات مع وحدات تخزين بيانات مختلفة وقيم النسخ المتماثل النتائج نفسها من حيث موازنة التحميل بين عقد نظام المجموعة. فيما يلي رسم بياني لتوزيع الوصول إلى القرص عن طريق اختبارات الأداء.
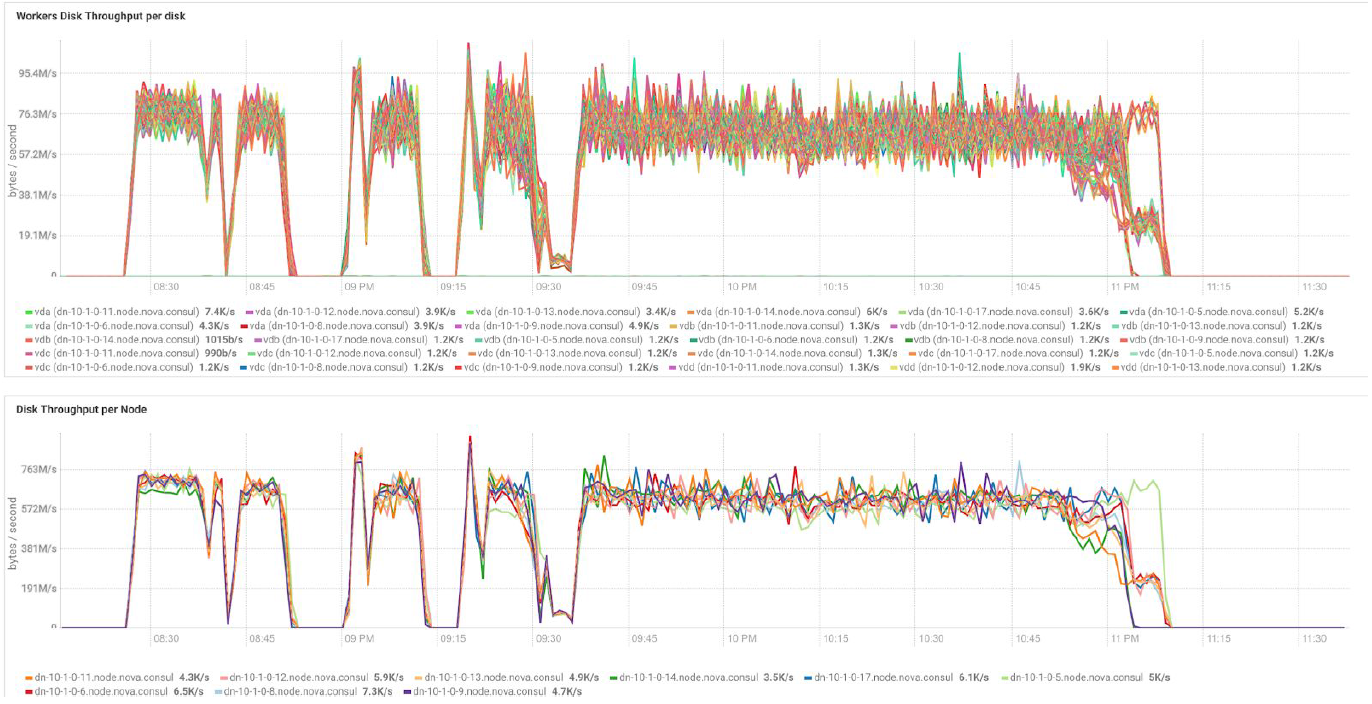
تستند الحسابات إلى الحد الأدنى من التكوين لخوادم 3 BullSequana S200. ويشمل 9 عقد البيانات و 3 العقد الرئيسية ، وكذلك الأجهزة الافتراضية المحجوزة في حالة نشر الحماية على أساس OpenStack الافتراضية. نتيجة اختبار TeraSort: حجم كتلة 512 ميجابايت لمعامل النسخ المتماثل لثلاثة تشفير هو 23.1 دقيقة.
كيف يمكنني توسيع النظام؟ تتوفر أنواع مختلفة من الامتدادات لـ Data Lake Engine:
- عقد البيانات: لكل 40 تيرابايت من المساحة القابلة للاستخدام
- العقد التحليلية مع القدرة على تثبيت GPU
- خيارات أخرى حسب احتياجات العمل (على سبيل المثال ، إذا كنت بحاجة إلى كافكا وما شابه)
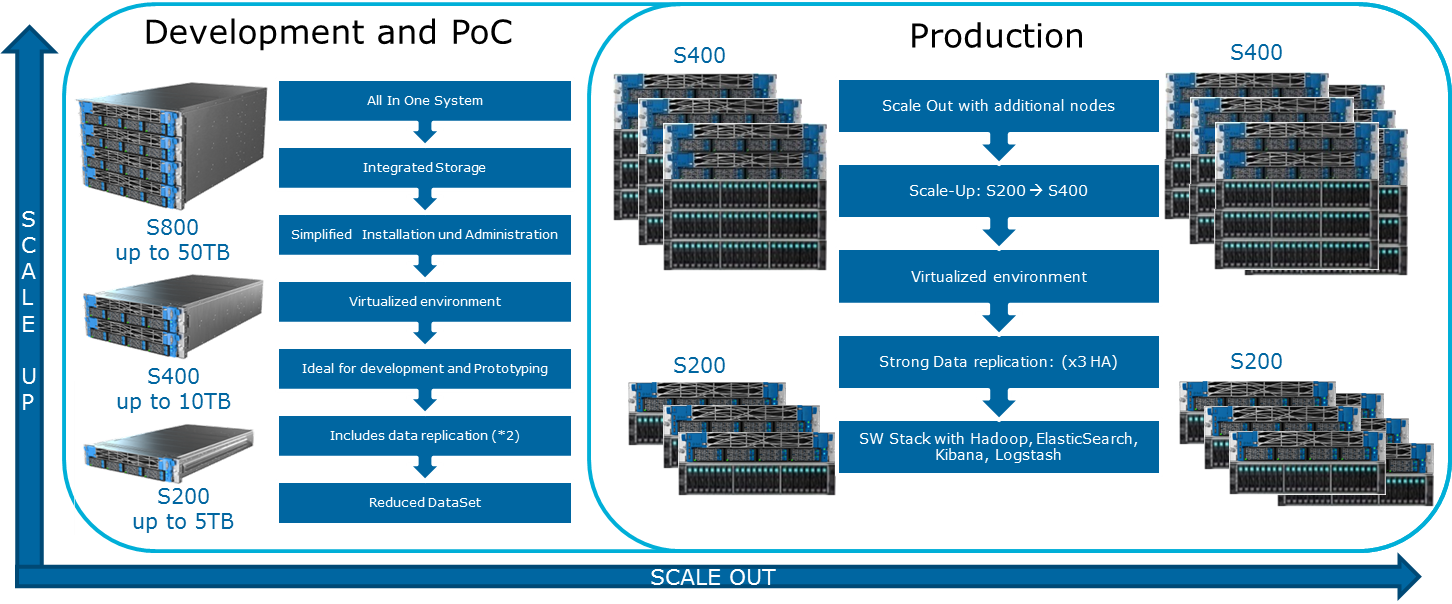
يتضمن Atos Codex Data Lake Engine كلاً من الخوادم نفسها والبرامج المثبتة مسبقًا ، بما في ذلك مجموعة Cloudera المرخصة ؛ Hadoop نفسها ، OpenStack مع الأجهزة الافتراضية القائمة على RedHat Enterprise Linux kernel ، ونظام النسخ المتماثل للبيانات والنسخ الاحتياطي (بما في ذلك استخدام عقدة النسخ الاحتياطي و Cloudera BDR - النسخ الاحتياطي واستعادة الكوارث). كان Atos Codex Data Lake Engine هو الحل الافتراضي الأول المعتمد من قِبل
Cloudera .
إذا كنت مهتمًا بالتفاصيل ، سنكون سعداء بالإجابة على أسئلتنا في التعليقات.