
مرحبا يا هبر! سيستمر منطقيًا وصف تشغيل الدواخل من منصة دفع كبيرة مع وصف لكيفية عمل جميع هذه المكونات في العالم الحقيقي على الأجهزة الفعلية. في هذا المنشور ، أتحدث عن كيفية وأين توجد تطبيقات المنصة ، وكيف تصل إليها حركة المرور من العالم الخارجي ، وسأشرح أيضًا مخطط الرف القياسي لنا مع المعدات الموجودة في أي من مراكز البيانات الخاصة بنا.
النهج والقيود

يبدو أحد المتطلبات الأولى التي صاغناها قبل تطوير النظام الأساسي "القدرة على توسيع نطاق موارد الحوسبة الخطية لضمان معالجة أي عدد من المعاملات."
النهج التقليدية للأنظمة المدفوعة التي يستخدمها المشاركون في السوق تعني وجود سقف ، وإن كان مرتفعًا جدًا وفقًا للبيانات. عادة ما يبدو الأمر كالتالي: "يمكن للمعالجة الخاصة بنا قبول 1000 معاملة في الثانية."
لا يتوافق هذا النهج مع أهداف أعمالنا وهندستها. نحن لا نريد أن يكون لدينا أي حد. في الواقع ، سيكون من الغريب أن نسمع من ياندكس أو جوجل عبارة "يمكننا معالجة مليون عملية بحث في الثانية". يجب أن تعالج المنصة العديد من الطلبات التي يحتاجها العمل في الوقت الحالي نظرًا للهندسة المعمارية ، والتي تسمح ، ببساطة ، بإرسال عامل تكنولوجيا المعلومات مع عربة من الخوادم ، التي سيقوم بتثبيتها على الرفوف ، والاتصال بالمحول والمغادرة. وسيقوم منسق النظام الأساسي بنقل نسخ من مثيلات تطبيق الأعمال إلى قدرات جديدة ، ونتيجة لذلك سنحصل على زيادة في RPS التي نحتاج إليها.
الشرط الثاني المهم هو ضمان توافر عالية للخدمات المقدمة. سيكون من المضحك ، ولكن ليس مفيدًا للغاية ، إنشاء منصة دفع يمكنها قبول عدد لا حصر له من الدفعات في / dev / null.
ولعل أكثر الطرق فعالية لتحقيق توفر كبير هو تكرار الكيانات التي تخدم الخدمة عدة مرات حتى لا يؤثر فشل أي عدد معقول من التطبيقات أو المعدات أو مراكز البيانات على التوافر الإجمالي للمنصة.
يتطلب تكرار التطبيقات المتعددة عددًا كبيرًا من الخوادم الفعلية وأجهزة الشبكة ذات الصلة. هذا الحديد يكلف المال ، وكمية لدينا بالطبع ، لا يمكننا شراء الكثير من الحديد باهظ الثمن. لذلك تم تصميم المنصة بطريقة تستوعب بسهولة وتشعر بالراحة على عدد كبير من الحديد غير مكلفة وغير قوية للغاية ، أو حتى في سحابة عامة.
إن استخدام الخوادم التي ليست الأقوى من حيث قوة الحوسبة له مزاياه - لا يكون لفشلها تأثير حاسم على الحالة العامة للنظام ككل. تخيل ما هو أفضل - إذا كان خادم العلامة التجارية باهظ الثمن ، كبيرًا وموثوقًا به يحترق ، يقوم بتشغيل نظام إدارة قواعد البيانات (DBMS) وفقًا لمخطط العبد (وفقًا لقانون مورفي ، فمن المؤكد أنه سيحترق ، وفي مساء يوم 31 ديسمبر) أو اثنين من الخوادم في مجموعة مكونة من 30 عقدة تعمل وفقًا لنظام masterless -scheme؟
بناءً على هذا المنطق ، قررنا عدم إنشاء نقطة فشل أخرى هائلة في شكل صفيف قرص مركزي. يتم توفير أجهزة الكتلة الشائعة لنا من خلال مجموعة Ceph ، التي يتم نشرها بشكل متقارب للغاية على نفس الخوادم ، ولكن مع بنية شبكة منفصلة.
وهكذا ، توصلنا منطقيا إلى المخطط العام للحامل الشامل مع موارد الحوسبة في شكل خوادم غير مكلفة وغير قوية للغاية في مركز البيانات. إذا كنا بحاجة إلى المزيد من الموارد ، فإننا إما ننهي أي رف مجاني مع خوادم ، أو نضع واحدة أخرى ، ويفضل أن يكون ذلك أقرب.

حسنًا ، في النهاية ، إنه جميل فقط. عندما يتم تثبيت كمية واضحة من نفس الحديد في الرفوف ، يتيح لك ذلك حل مشاكل الجودة المزروعة لمزرعة الأسلاك ، مما يتيح لك التخلص من أعشاش السنونو وخطر التعرض للتشابك في الأسلاك وإسقاط المعالجة. جيد من وجهة نظر هندسية ، يجب أن يكون النظام جميلًا في كل مكان - سواء من الداخل في شكل رمز أو من الخارج في شكل خوادم وأجهزة شبكة. نظام جميل يعمل بشكل أفضل وأكثر موثوقية ، وكان لدي أمثلة كافية للتحقق من ذلك من تجربتي الخاصة.
يرجى عدم الاعتقاد بأننا محتالون أو أن العمل يقره التمويل. تطوير وصيانة النظام الأساسي الموزع هو في الواقع متعة مكلفة للغاية. في الواقع ، هذا أكثر تكلفة من امتلاك نظام كلاسيكي ، مبني ، مشروط ، على أجهزة قوية ذات علامة تجارية مع Oracle / MSSQL ، خوادم التطبيقات وغيرها من الروابط.
يؤتي ثمارنا ثباتًا كبيرًا ، وقدرات التحجيم الأفقية المرنة للغاية ، والافتقار إلى الحد الأقصى لعدد المدفوعات في الثانية ، وبغض النظر عن مدى غرابة الأمر - الكثير من المرح لفريق تكنولوجيا المعلومات. بالنسبة لي ، فإن مستوى متعة المطورين و devops من النظام الذي يقومون بإنشائه لا يقل أهمية عن وقت التطوير المتوقع ، وكمية ونوعية الميزات التي تم طرحها.
خادم البنية التحتية

من الناحية المنطقية ، يمكن تقسيم قدرات الخادم الخاصة بنا إلى فئتين رئيسيتين: خوادم للأجهزة التشعبية ، والتي تعد كثافة وحدة المعالجة المركزية وذاكرة الوصول العشوائي لكل وحدة مهمة ، وخوادم التخزين ، حيث يكون التركيز الرئيسي على مقدار مساحة القرص لكل وحدة ، ويتم بالفعل اختيار وحدة المعالجة المركزية وذاكرة الوصول العشوائي ل عدد الأقراص.
في الوقت الحالي ، يبدو خادمنا الكلاسيكي لقوة الحوسبة كما يلي:
- وحدة المعالجة المركزية 2xXeon E5-2630 ؛
- ذاكرة الوصول العشوائي 128G ؛
- 3xSATA SSD (Ceph SSD pool) ؛
- 1xNVMe SSD (dm-cache).
خادم لتخزين الحالات:
- 1xXeon E5-2630 وحدة المعالجة المركزية.
- 12-16 HDD ؛
- SSDs 2 ل block.db ؛
- ذاكرة الوصول العشوائي 32G.
البنية التحتية للشبكة
في اختيار أجهزة الشبكة ، يختلف أسلوبنا إلى حد ما. ما زلنا نستخدم المحولات ذات العلامات التجارية للتبديل والتوجيه بين شبكات محلية ظاهرية ، والآن هي Cisco SG500X-48 و Cisco Nexus C5020 في SAN.
فعليًا ، يتم توصيل كل خادم بالشبكة بواسطة 4 منافذ فعلية:
- 2x1GbE - شبكة الإدارة و RPC بين التطبيقات ؛
- 2x10GbE - شبكة للتخزين.
يتم الجمع بين واجهات داخل الآلات عن طريق الترابط ، ثم تتباعد حركة المرور الموسومة وفقا للشبكة المحلية المرغوبة.
ربما هذا هو المكان الوحيد في بنيتنا التحتية حيث يمكنك رؤية ملصق البائع الشهير. نظرًا للتوجيه وفلتر الشبكة وفحص حركة المرور ، فإننا نستخدم مضيفات Linux. نحن لا نشتري أجهزة التوجيه المتخصصة. كل ما نحتاجه نحن تكوينه على خوادم تشغل Gentoo (iptables للتصفية ، BIRD للتوجيه الديناميكي ، Suricata كـ IDS / IPS ، Wallarm as WAF).
رف نموذجي في العاصمة
عند التوسع ، لا تختلف الرفوف الموجودة فعليًا عن بعضها البعض باستثناء أجهزة توجيه الوصلة الصاعدة المثبتة في أحدها.
يمكن أن تختلف النسب الدقيقة للخوادم من فئات مختلفة ، ولكن بشكل عام ، يتم الحفاظ على المنطق - هناك عدد أكبر من الخوادم للحوسبة أكثر من الخوادم لتخزين البيانات.
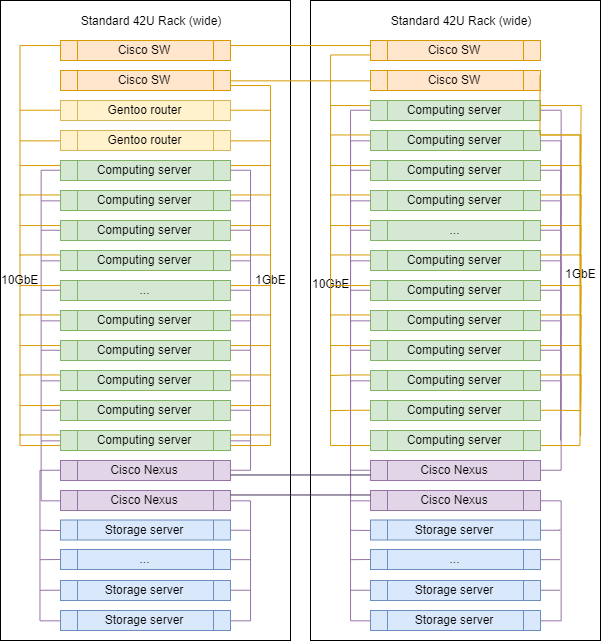
حظر الأجهزة ومشاركة الموارد
دعونا نحاول وضع كل شيء معًا. تخيل أننا بحاجة إلى وضع العديد من خدماتنا المصغرة في البنية التحتية ، لمزيد من الوضوح ، ستكون هذه خدمات صغيرة تحتاج إلى التواصل مع بعضها البعض عبر RPC وواحد منها Machinegun ، الذي يخزن الحالة في مجموعة Riak ، فضلاً عن بعض الخدمات المساعدة ، مثل مثل العقد ES و القنصل.
سيبدو التصميم النموذجي كما يلي:
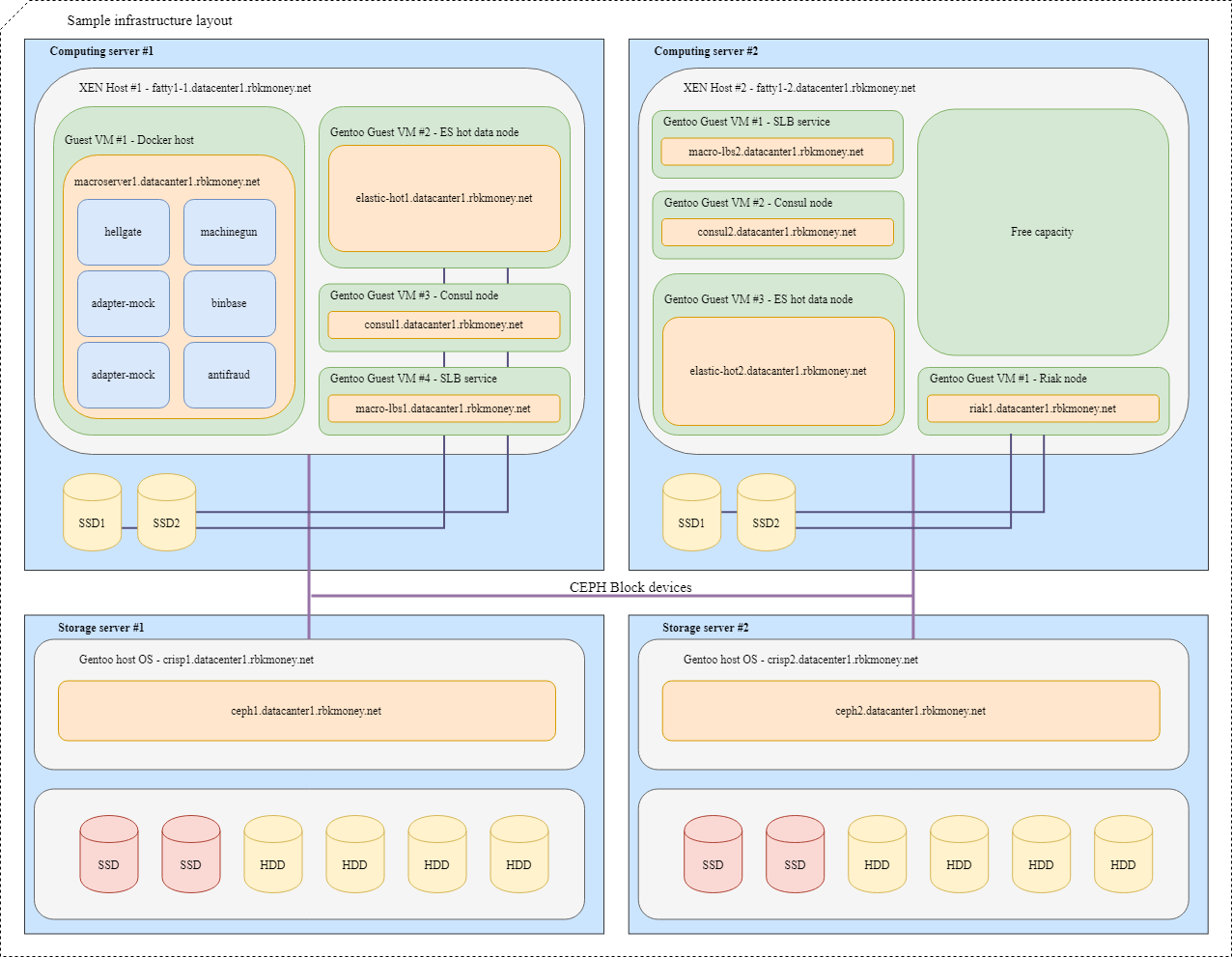
بالنسبة إلى VMs ذات التطبيقات التي تتطلب أقصى سرعة لجهاز الكتلة ، مثل العقد الساخنة Riak و Elasticsearch ، يتم استخدام أقسام على أقراص NVMe المحلية. يتم ربط VMs بإحكام إلى برنامج Hypervisor ، وتكون التطبيقات نفسها مسؤولة عن توفر وسلامة بياناتها.
بالنسبة لأجهزة الكتلة الشائعة ، نستخدم Ceph RBD ، عادةً مع ذاكرة التخزين المؤقت للكتابة dm على قرص NVMe المحلي. يمكن أن يكون OSD للجهاز إما فلاش كامل أو HDD مع سجل SSD ، وهذا يتوقف على وقت الاستجابة المطلوب.
تسليم حركة المرور إلى التطبيقات
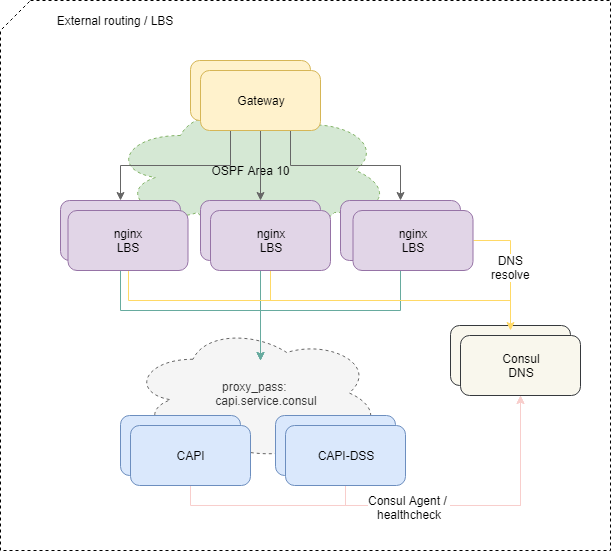
لموازنة الطلبات الواردة من الخارج ، نستخدم نظام OSPFv3 ECMP القياسي. الأجهزة الافتراضية الصغيرة مع nginx، bird، القنصل تعلن في OSPF cloud عناوين anycast الشائعة من واجهة lo. على أجهزة التوجيه ، بالنسبة لهذه العناوين ، ينشئ Bird مسارات متعددة القفزات توفر موازنة لكل تدفق ، حيث يكون التدفق هو "src-ip src-port dst-ip dst-port". لتعطيل الموازن المفقود بسرعة ، يتم استخدام بروتوكول BFD.
عند إضافة أي من الموازنات أو إخفاقها ، تحصل أجهزة التوجيه الأولية على المسار المقابل أو تحذفها ، ويتم تسليم حركة مرور الشبكة إليهم وفقًا لنهج المسارات المتعددة التكلفة المتساوية. وإذا لم نتدخل بشكل خاص ، فسيتم توزيع كل حركة مرور الشبكة بالتساوي على جميع الموازنات المتاحة على كل تدفق IP.
بالمناسبة ، يحتوي النهج الخاص بموازنة ECMP على عيوب غير واضحة ، مما قد يؤدي إلى خسائر غير واضحة تمامًا لبعض حركة المرور ، خاصةً إذا كانت أجهزة التوجيه الأخرى أو جدران الحماية المكونة بشكل غريب على الطريق بين الأنظمة.
لحل المشكلة ، نستخدم البرنامج الخفي PMTUD في هذا الجزء من البنية التحتية.
علاوة على ذلك ، تنتقل حركة المرور داخل المنصة إلى خدمات ميكروية محددة وفقًا لتهيئة nginx على الموازنات.
وإذا كانت موازنة حركة المرور الخارجية بسيطة إلى حد ما ومفهومة ، فسيكون من الصعب تمديد هذا المخطط إلى الداخل - نحتاج إلى أكثر من مجرد التحقق من توفر الحاوية مع وجود خدمة ميكروية على مستوى الشبكة.
لكي تبدأ الخدمة المصغّرة في تلقي الطلبات ومعالجتها ، يجب أن تسجّل في خدمة اكتشاف الخدمة (نستخدم القنصل ) ، وتخضع للفحوصات الصحية كل ثانية ولديك اختبار RTT معقول.
إذا شعرت microservice وتصرفت بشكل جيد ، يبدأ القنصل في حل عنوان الحاوية الخاصة به عند الوصول إلى DNS الخاص به باسم الخدمة. نحن نستخدم service.consul للمنطقة الداخلية ، على سبيل المثال ، سيتم تسمية microservice الإصدار 2 من واجهة برمجة التطبيقات المشتركة باسم capi-v2.service.consul .
يبدو التكوين nginx فيما يتعلق بالتوازن في النهاية كما يلي:
location = /v2/ { set $service_hostname "${staging_pass}capi-v2.service.consul"; proxy_pass http://$service_hostname:8022; }
وبالتالي ، إذا لم نتدخل مرة أخرى عن قصد ، فسيتم توزيع حركة المرور من الموازنات بالتساوي بين جميع الخدمات المصغرة المسجلة في Service Discovery ، مما يؤدي إلى إضافة أو إزالة مثيلات جديدة من الخدمات المصغرة اللازمة بشكل تلقائي.
إذا ذهب الطلب من الموازن إلى الأعلى ، وتوفي في الطريق ، فسنعيد 502 - لا يمكن للموازن في مستواه تحديد ما إذا كان الطلب عاجزًا أم لا ، لذلك نعطي معالجة هذه الأخطاء لمستوى أعلى من المنطق.
الشغف والمواعيد النهائية
بشكل عام ، لسنا خائفين ولا نتردد في تقديم أخطاء 5xx مع واجهة برمجة التطبيقات ، فهذا جزء طبيعي من النظام إذا أجريت المعالجة الصحيحة لمثل هذه الأخطاء على مستوى منطق أعمال RPC. يتم وصف مبادئ هذه المعالجة في نموذجنا كدليل صغير يسمى Erry Retry Policy ، نقوم بتوزيعها على عملائنا التاجر وتنفيذها داخل خدماتنا.
لتبسيط هذه المعالجة ، قمنا بتنفيذ عدة طرق.
أولاً ، بالنسبة لأي طلبات لتغيير الحالة إلى API الخاصة بنا ، يمكنك تحديد مفتاح فريد للغباء داخل الحساب ، والذي يعمل إلى الأبد ويسمح لك بالتأكد من أن مكالمة متكررة مع نفس مجموعة البيانات ستعود بنفس الإجابة.
ثانياً ، قمنا بتطبيق آلية إضافية في شكل مُعرّف فريد لجلسة الدفع ، والذي يضمن عدم ملاءمة طلبات الخصم من الأموال ، وتوفير الحماية من الخصوم المتكررة الخاطئة ، حتى إذا لم تقم بإنشاء ونقل مفتاح منفصل لضعف العاطلين عن العمل.
ثالثًا ، قررنا تمكين وقت استجابة يمكن التنبؤ به وخاضع للرقابة الخارجية لأي مكالمة خارجية إلى API الخاصة بنا في شكل معلمة فصل وقت تحدد الحد الأقصى لوقت الانتظار لإكمال العملية عند الطلب. يكفي نقل ، على سبيل المثال ، رأس HTTP X-Request-Deadline: 10s للتأكد من أن طلبك سيتم تنفيذه في غضون 10 ثوانٍ أو سيتم قتله بواسطة النظام الأساسي في مكان ما بداخله ، وبعد ذلك يمكننا الاتصال بنا مرةً أخرى ، مع الاسترشاد طلب سياسة إعادة التوجيه.
نستخدم SaltStack كأداة إدارة لكل من التكوينات والبنية التحتية ككل. لم يتم إقلاع الأدوات المنفصلة للتحكم الآلي في قدرة الحوسبة في المنصة ، على الرغم من أننا نفهم بالفعل أننا سنذهب في هذا الاتجاه. مع حبنا لمنتجات Hashicorp ، من المحتمل أن يكون هذا هو Nomad.
تتمثل أدوات مراقبة البنية الأساسية الرئيسية في عمليات التحقق في Nagios ، ولكن بالنسبة إلى الكيانات التجارية ، نقوم بشكل أساسي بتكوين التنبيهات في Grafana. إنه يحتوي على أداة ملائمة للغاية لضبط الظروف ، ويسمح لك نموذج النظام الأساسي القائم على الحدث بكتابة كل شيء إلى Elasticsearch وتكوين شروط الاختيار.
توجد مراكز البيانات في موسكو ، حيث نقوم بتأجير مساحات الأرفف ، ونقوم بتركيب وإدارة جميع المعدات بشكل مستقل. نحن لا نستخدم البصريات المظلمة في أي مكان ، فنحن لا نملك سوى الإنترنت من خارج مقدمي الخدمات المحليين
بخلاف ذلك ، تعتبر مناهجنا في المراقبة والإدارة والخدمات ذات الصلة قياسية بالنسبة للصناعة ، لست متأكدًا من أن الوصف التالي لتكامل هذه الخدمات يستحق الذكر في منشور ما.
في هذه المقالة ، ربما أنهي سلسلة من مشاركات المراجعة حول كيفية ترتيب نظام الدفع الخاص بنا.
أعتقد أن الدورة كانت صريحة للغاية ، فقد قابلت بعض المقالات التي من شأنها أن تكشف بمثل هذه التفاصيل المطبخ الداخلي لأنظمة الدفع الكبيرة.
بشكل عام ، في رأيي ، يعد المستوى العالي من الانفتاح والصراحة أمرًا مهمًا للغاية لنظام الدفع. لا يؤدي هذا النهج إلى زيادة مستوى ثقة الشركاء والدائنين فحسب ، بل يؤدي أيضًا إلى ضبط الفريق والمبدعين والمشغلين للخدمة.
بناءً على هذا المبدأ ، قمنا مؤخرًا بوضع حالة النظام الأساسي وتاريخ الجهوزية لخدماتنا في متناول الجمهور. أصبح السجل اللاحق لوقت التشغيل والتحديثات والأعطال الآن متاحًا على الموقع https://status.rbk.money/ .
أتمنى أن تكون مهتمًا ، وربما يجد شخص ما طرقنا والأخطاء الموصوفة مفيدة. إذا كنت مهتمًا بأي من المجالات الموضحة في المنشورات وترغب في أن أفصح عنها بمزيد من التفصيل ، فيرجى عدم التردد في الكتابة في التعليقات أو في PM.
شكرا لك لأنك معنا!

ملاحظة: لراحتك ، مؤشر إلى المقالات السابقة في السلسلة: