كما هو الحال في
معظم المنشورات ، حدثت مشكلة في الخدمة الموزعة ، دعنا نسمي هذه الخدمة ألفين. هذه المرة لم أجد المشكلة بنفسي ، أخبرني الرجال من العميل.
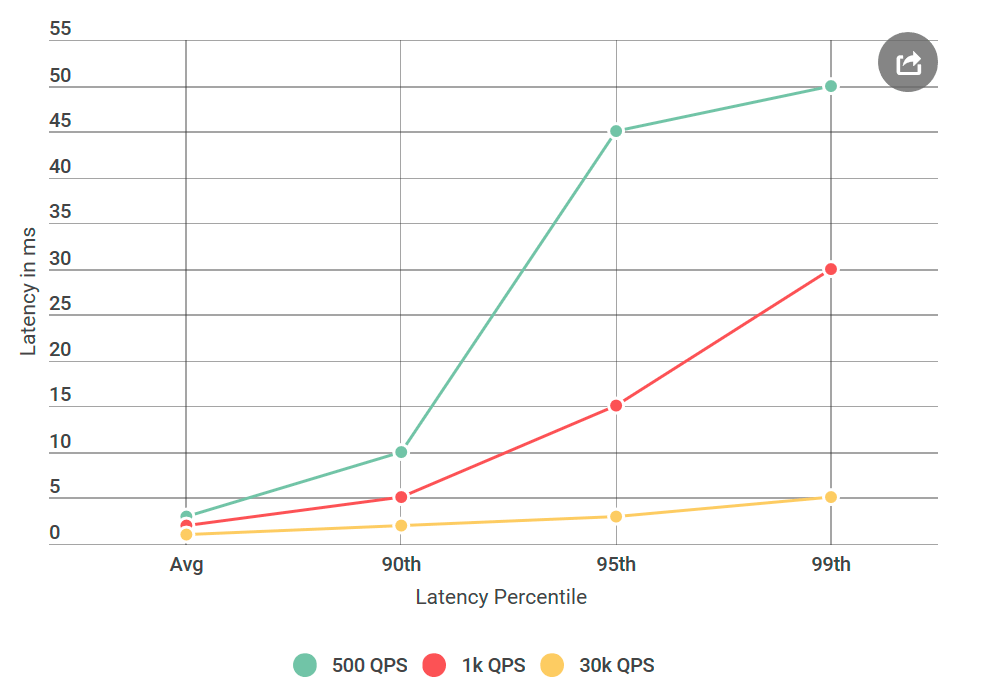
بمجرد أن استيقظت من خطاب ساخط بسبب التأخير الكبير لألفين ، الذي خططنا لإطلاقه في المستقبل القريب. على وجه الخصوص ، واجه العميل تأخيرًا مئويًا بنسبة 99 في المائة حول 50ms ، أعلى بكثير من ميزانية التأخير. كان هذا مفاجئًا ، حيث أنني اختبرت الخدمة جيدًا ، خاصة فيما يتعلق بالتأخيرات ، لأن هذا موضوع شكاوى متكررة.
قبل إعطاء ألفين للاختبار ، أجريت العديد من التجارب مع 40 ألف طلب في الثانية (QPS) ، وأظهرت جميعها تأخيرًا أقل من 10 مللي ثانية. كنت على استعداد للإعلان أنني لا أتفق مع نتائجها. لكن مرة أخرى نظرت إلى الرسالة ، لفتت الانتباه إلى شيء جديد: بالتأكيد لم أختبر الشروط التي ذكروها ، كانت QPS أقل بكثير من الشروط. اختبرت على 40K QPS ، وأنها فقط على 1K. لقد أجريت تجربة أخرى ، هذه المرة مع QPS أقل ، فقط لإرضائهم.
منذ أن كتبت عن هذا على مدونتي ، ربما تكون قد فهمت بالفعل: لقد تبين أن أعدادهم صحيحة. لقد اختبرت عميلي الظاهري مرارًا وتكرارًا ، كل ذلك بنفس النتيجة: عدد الطلبات المنخفض لا يزيد من التأخير فحسب ، بل يزيد أيضًا عدد الطلبات بتأخير يزيد عن 10 مللي ثانية. بمعنى آخر ، إذا تجاوز عدد طلبات البحث في 50 كيلو بايت تقريبًا 50 طلبًا في الثانية الواحدة 50 مللي ثانية ، ثم كان هناك 100 طلب في الثانية الواحدة في كل ثانية كان هناك 100 طلب يفوق 50 مللي ثانية. المفارقة!
تضييق نطاق البحث
في مواجهة مشكلة التأخير في نظام موزع مع العديد من المكونات ، فإن أول ما عليك فعله هو تقديم قائمة قصيرة من المشتبه بهم. نحفر أعمق قليلاً في هندسة ألفين:
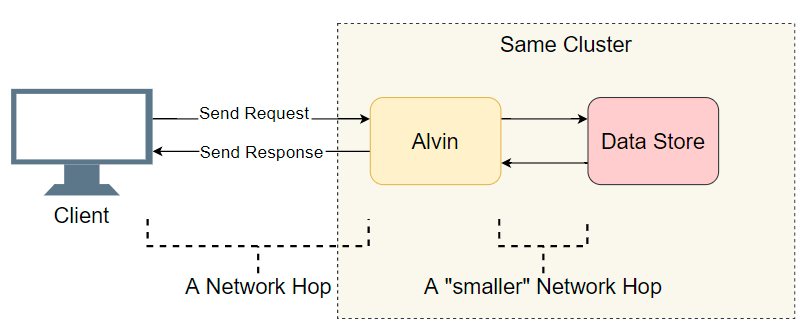
نقطة انطلاق جيدة هي قائمة انتقالات الإدخال / الإخراج المكتملة (مكالمات شبكة / بحث القرص ، إلخ). دعنا نحاول معرفة مكان التأخير. بالإضافة إلى الإدخال / الإخراج الواضح مع العميل ، يتخذ ألفين خطوة إضافية: فهو يصل إلى مستودع البيانات. ومع ذلك ، تعمل وحدة التخزين هذه في نفس المجموعة مع Alvin ، لذلك يجب أن يكون هناك تأخير أقل من العميل. لذلك ، قائمة المشتبه بهم:
- مكالمة شبكة من العميل إلى ألفين.
- شبكة الاتصال من ألفين إلى مستودع البيانات.
- البحث على القرص في مستودع البيانات.
- اتصال الشبكة من مستودع البيانات إلى ألفين.
- اتصال الشبكة من ألفين إلى العميل.
دعونا نحاول شطب بعض النقاط.
مستودع البيانات
أول شيء فعلته هو تحويل Alvin إلى خادم ping-ping لا يتعامل مع الطلبات. عند تلقي الطلب ، تقوم بإرجاع استجابة فارغة. إذا انخفض التأخير ، فلن يُسمع خطأ في تنفيذ Alvin أو مستودع البيانات. في التجربة الأولى ، نحصل على الرسم البياني التالي:
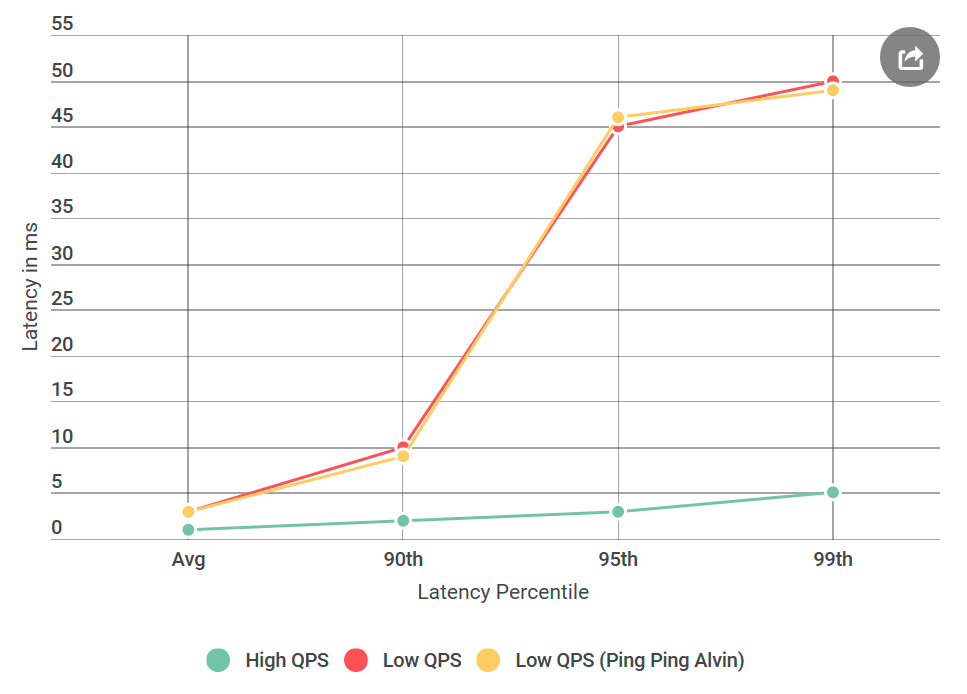
كما ترى ، عند استخدام خادم ping-ping ، لا توجد تحسينات. هذا يعني أن مستودع البيانات لا يزيد من التأخير وقائمة المشتبه بهم إلى النصف:
- مكالمة شبكة من العميل إلى ألفين.
- اتصال الشبكة من ألفين إلى العميل.
عظيم! القائمة تتقلص بسرعة. اعتقدت أنني اكتشفت السبب.
gRPC
لقد حان الوقت
لتعريفك بلاعب جديد:
gRPC . هذه مكتبة مفتوحة المصدر من Google لإجراء اتصالات
RPC قيد التشغيل. على الرغم من أن
gRPC مُحسّن بشكل جيد ويستخدم على نطاق واسع ، فقد استخدمته لأول مرة على نظام بهذا الحجم ، وتوقعت أن يكون عملي في التنفيذ دون المستوى الأمثل - بعبارة ملطفة.
أثار وجود
gRPC في المكدس سؤالًا جديدًا: ربما يكون هذا تنفيذي أم هل يسبب
gRPC نفسه مشكلة تأخير؟ أضف إلى قائمة المشتبه به الجديد:
- يستدعي العميل مكتبة
gRPC
gRPC مكتبة gRPC على العميل مكالمة شبكة إلى مكتبة gRPC على الخادم
- مكتبة
gRPC تصل إلى Alvin (لا توجد عملية في حالة خادم ping-pong)
لجعلك تفهم شكل التعليمات البرمجية ، لا يختلف تطبيق العميل / ألفين كثيرًا عن
أمثلة خادم العميل غير
المتزامن .
ملاحظة: القائمة أعلاه مبسطة قليلاً ، حيث يتيح لك gRPC استخدام نموذج Stream الخاص بك (القالب؟) ، حيث gRPC تنفيذ gRPC وتنفيذ المستخدم. من أجل البساطة ، سوف نلتزم بهذا النموذج.
سوف التوصيف إصلاح كل شيء
عند عبور مستودعات البيانات ، اعتقدت أنني قد انتهيت تقريبًا: سنقوم بتطبيق ملف التعريف ومعرفة مكان حدوث التأخير. " أنا
معجب كبير بالتشكيل الجانبي الدقيق لأن وحدات المعالجة المركزية سريعة جدًا وغالبًا لا تكون عنق الزجاجة. تحدث معظم التأخيرات عندما يجب أن يتوقف المعالج عن المعالجة من أجل القيام بشيء آخر. تم إنشاء ملف تعريف دقيق لوحدة المعالجة المركزية فقط لهذا الغرض: فهو يسجل بدقة جميع
مفاتيح السياق ويجعل من الواضح أين تحدث التأخيرات.
أخذت أربعة ملفات تعريف: تحت QPS عالية (زمن انتقال منخفض) ومع خادم ping-pong على QPS منخفض (زمن وصول عالٍ) ، سواء من جانب العميل أو من جانب الخادم. وفقط في حالة ، كما أخذت ملف تعريف عينة المعالج. عند مقارنة ملفات التعريف ، عادة ما أبحث عن مكدس استدعاء غير طبيعي. على سبيل المثال ، على الجانب السيئ مع تأخير كبير ، هناك الكثير من مفاتيح التبديل للسياق (10 مرات أو أكثر). ولكن في حالتي ، تزامن عدد مفاتيح تبديل السياق تقريبًا. بالنسبة لرعبي ، لم يكن هناك شيء مهم هناك.
تصحيح إضافية
كنت يائسة. لم أكن أعرف الأدوات الأخرى التي يمكن استخدامها ، وكانت خطتي التالية في الأساس هي تكرار التجارب بصيغ مختلفة ، وليس تشخيص المشكلة بوضوح.
ماذا لو
من البداية ، كنت قلقًا بشأن وقت التأخير المحدد البالغ 50 مللي ثانية. هذا وقت كبير جدا. قررت أن أقوم بقطع الأجزاء من الكود حتى أتمكن من معرفة الجزء الذي كان يسبب هذا الخطأ. ثم اتبعت التجربة التي نجحت.
كالعادة ، مع العقل الخلفي يبدو أن كل شيء كان واضحا. أنا وضعت العميل على نفس الجهاز مع ألفين - وأرسلت الطلب إلى
localhost . والزيادة في التأخير قد اختفت!
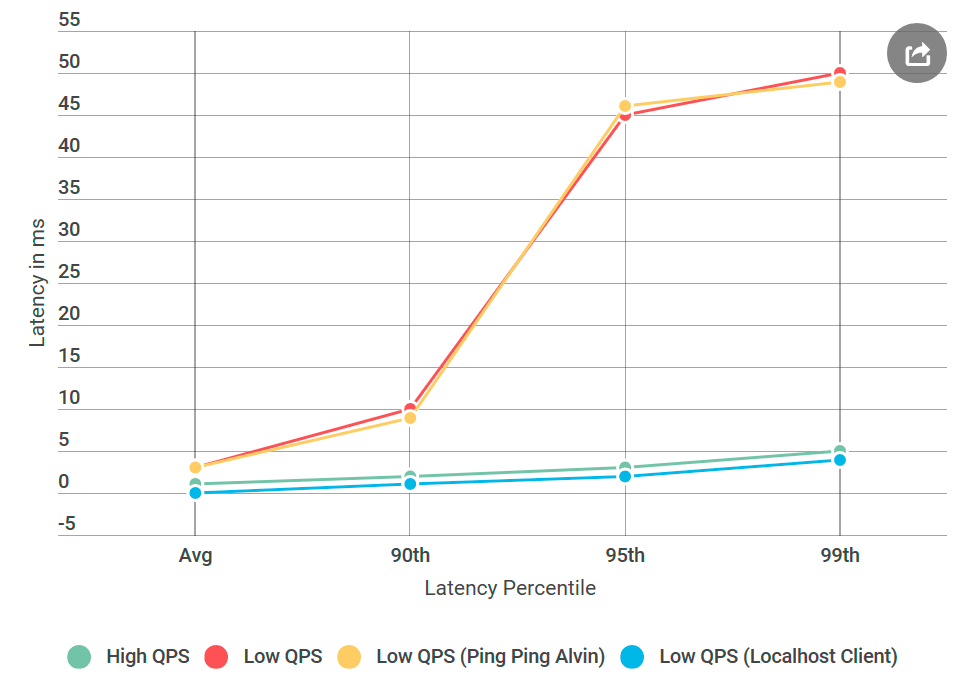
كان هناك خطأ في الشبكة.
تعلم مهارات مهندس الشبكة
يجب أن أعترف بأن معرفتي بتقنيات الشبكات أمر فظيع ، خاصة بالنظر إلى حقيقة أنني أعمل معهم يوميًا. لكن الشبكة كانت المشتبه الرئيسي ، وكنت بحاجة لمعرفة كيفية تصحيحها.
لحسن الحظ ، فإن الإنترنت يحب أولئك الذين يرغبون في التعلم. بدا مزيج ping و tracert بداية جيدة بما يكفي لتصحيح مشكلات نقل الشبكة.
أولاً ، ركضت
PsPing على منفذ TCP الخاص بـ
Alvin . لقد استخدمت الخيارات الافتراضية - لا شيء خاص. من بين أكثر من ألف صوت ، لم يتجاوز واحد 10 مللي ثانية ، باستثناء الأول للاحماء. هذا يتناقض مع الزيادة الملحوظة في تأخير 50 مللي ثانية في النسبة المئوية 99: هناك ، لكل 100 طلب ، يجب أن نرى طلب واحد مع تأخير قدره 50 مللي ثانية.
ثم حاولت
tracert : ربما تكون المشكلة في إحدى العقد على طول الطريق بين ألفين والعميل. ولكن عاد التتبع خالي الوفاض.
وبالتالي ، فإن سبب التأخير لم يكن رمز بلدي ، وليس تنفيذ gRPC ، وليس الشبكة. لقد بدأت بالفعل في القلق من أنني لن أفهم هذا أبداً.
الآن ما OS نحن على
gRPC على نطاق واسع على نظام Linux ، لكنه غريب بالنسبة لنظام Windows. قررت إجراء تجربة ناجحة: لقد أنشأت جهازًا افتراضيًا لنظام التشغيل Linux ، وقمت بتجميع Alvin لنظام Linux ، ونشرته.
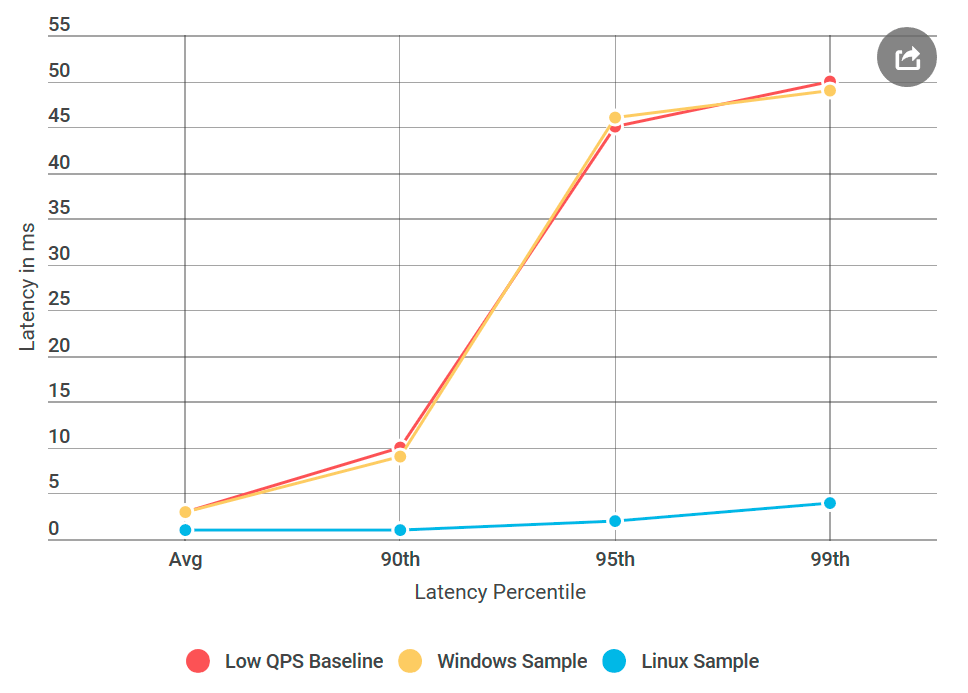
وإليك ما حدث: لم يكن لخادم ping-pong Linux أي تأخير مثل عقدة Windows المماثلة ، على الرغم من أن مصدر البيانات لم يختلف. اتضح أن المشكلة تكمن في تنفيذ gRPC لنظام التشغيل Windows.
خوارزمية Nagle
طوال هذا الوقت ، اعتقدت أنني كنت
gRPC علم
gRPC . الآن أدركت أن هذا يفتقر
gRPC إلى علامة Windows في
gRPC . لقد وجدت مكتبة RPC الداخلية ، والتي كنت متأكدًا من أنها تعمل جيدًا لجميع علامات
Winsock المثبتة. ثم أضاف كل هذه الأعلام إلى gRPC ونشر Alvin على Windows ، في خادم ping-pong الثابت لنظام Windows!

انتهيت
تقريبًا : بدأت في حذف العلامات المضافة واحدًا تلو الآخر إلى أن عاد الانحدار ، لذلك يمكنني تحديد سبب ذلك. كان
TCP_NODELAY سيئ السمعة ، وهو مفتاح خوارزمية Nagle.
تحاول خوارزمية Neigl تقليل عدد الحزم المرسلة عبر الشبكة عن طريق تأخير إرسال الرسائل حتى يتجاوز حجم الحزمة عددًا معينًا من وحدات البايت. على الرغم من أن هذا قد يكون مفيدًا للمستخدم العادي ، إلا أنه مدمر للخوادم في الوقت الفعلي ، نظرًا لأن نظام التشغيل سيؤخر بعض الرسائل ، مما يتسبب في حدوث تأخير في QPS المنخفض. كان لدى
gRPC هذه العلامة في تطبيق Linux لمآخذ TCP ، ولكن ليس لنظام Windows. أنا
ثابتة عليه .
استنتاج
كان هناك تأخير كبير في انخفاض QPS بسبب تحسين نظام التشغيل. إذا نظرنا إلى الوراء ، لم يكشف التنميط عن أي تأخير لأنه تم تنفيذه في وضع kernel وليس في
وضع المستخدم . لا أعرف إذا كان من الممكن مراقبة خوارزمية Nagle من خلال عمليات التقاط ETW ، لكن ذلك سيكون أمرًا مثيرًا للاهتمام.
أما بالنسبة لتجربة المضيف المحلي ، فربما لم تلمس رمز الشبكة الفعلي ، ولم تبدأ خوارزمية نيغل ، لذلك اختفت مشاكل التأخير عندما اتصل العميل بألفين عبر مضيف محلي.
في المرة التالية التي ترى فيها زيادة في زمن الانتقال مع تقليل عدد الطلبات في الثانية الواحدة ، يجب أن تكون خوارزمية Neigl في قائمة المشتبه بهم!