
تصريحات افتتاح
لقد قدمت هذا التقرير باللغة الإنجليزية في مؤتمر GopherCon Russia 2019 في موسكو والروسية في الاجتماع الذي عقد في نيجني نوفغورود. فهو يقع في حوالي مؤشر صورة نقطية - أقل شيوعا من شجرة B ، ولكن ليس أقل إثارة للاهتمام. أشارك
تسجيل الخطاب في المؤتمر باللغة الإنجليزية ونسخة النص باللغة الروسية.
سنقوم بفحص كيفية عمل فهرس الصورة النقطية ، عندما يكون أفضل ، وعندما يكون أسوأ من الفهارس الأخرى ، وفي هذه الحالات يكون أسرع بكثير منهم ؛ سنرى DBMSs الشائعة التي لديها بالفعل فهارس نقطية. محاولة الكتابة الخاصة بك على الذهاب. وبالنسبة للحلوى ، سوف نستخدم المكتبات الجاهزة لإنشاء قاعدة بيانات متخصصة فائقة السرعة.
آمل حقًا أن يكون عملي مفيدًا وممتعًا لك. دعنا نذهب!
مقدمة
http://bit.ly/bitmapindexeshttps://github.com/mkevac/gopherconrussia2019مرحبا بالجميع! الساعة السادسة مساء ، كلنا متعبون للغاية. وقت كبير للحديث عن النظرية المملة لفهارس قاعدة البيانات ، أليس كذلك؟ لا تقلق ، سيكون لديّ سطرين من شفرة المصدر هنا وهناك. :-)
إذا كان بدون نكات ، فإن التقرير مليء بالمعلومات ، وليس لدينا الكثير من الوقت. لذلك دعونا نبدأ.

اليوم سأتحدث عن ما يلي:
- ما هي الفهارس
- ما هو فهرس الصورة النقطية؟
- حيث يتم استخدامه وحيث لا يتم استخدامه ولماذا ؛
- تنفيذ بسيط على الذهاب والصراع قليلا مع المترجم.
- أقل بساطة قليلاً ، ولكن تنفيذ أكثر إنتاجية في Go-assembler ؛
- "مشاكل" فهارس الصورة النقطية؛
- التطبيقات الحالية.
إذن ما هي الفهارس؟
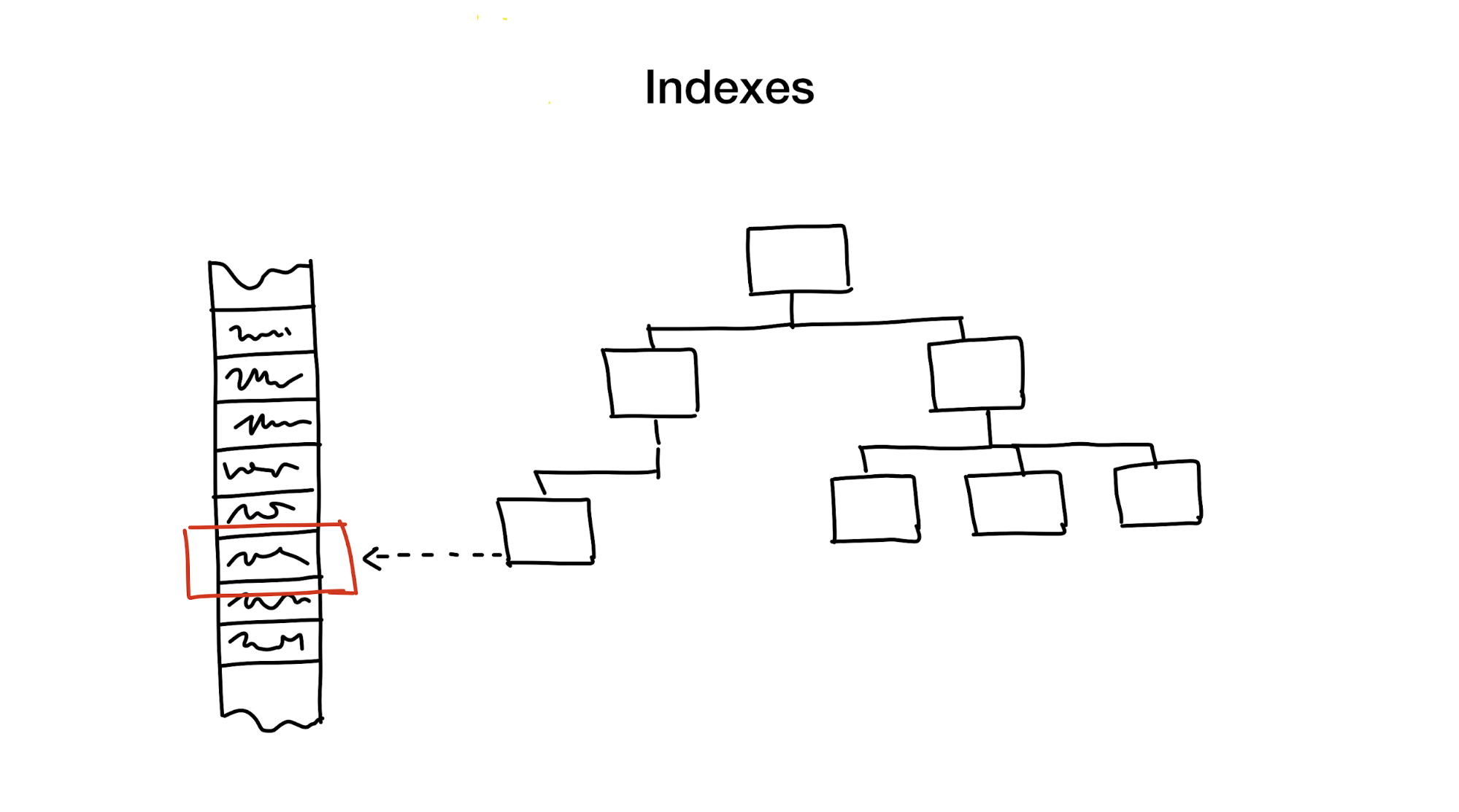
الفهرس هو بنية بيانات منفصلة نحتفظ بها ونحدثها بالإضافة إلى البيانات الرئيسية. يتم استخدامه لتسريع البحث. بدون الفهارس ، سيتطلب البحث المرور الكامل عبر البيانات (عملية تسمى الفحص الكامل) ، وهذه العملية لها تعقيد حسابي خطي. لكن قواعد البيانات عادة ما تحتوي على كمية هائلة من البيانات والتعقيد الخطي بطيء للغاية. من الناحية المثالية ، سوف نحصل على لوغاريتمي أو ثابت.
هذا موضوع معقد للغاية ، غارق في التفاصيل الدقيقة والحلول الوسط ، لكن بعد النظر إلى عقود من التطوير والبحث في قواعد البيانات المختلفة ، أنا مستعد للقول بأن هناك فقط عدد قليل من الأساليب المستخدمة على نطاق واسع لإنشاء فهارس قاعدة البيانات.

تتمثل الطريقة الأولى في تقليل منطقة البحث بشكل هرمي ، وتقسيم منطقة البحث إلى أجزاء أصغر.
عادة ما نفعل هذا باستخدام جميع أنواع الأشجار. مثال على ذلك ، صندوق كبير يحتوي على مواد في خزانتك ، حيث توجد صناديق أصغر تحتوي على مواد مقسمة حسب مواضيع مختلفة. إذا كنت بحاجة إلى مواد ، فمن المحتمل أنك ستبحث عنها في صندوق به عبارة "المواد" ، وليس في العبارة التي تقول "ملفات تعريف الارتباط" ، أليس كذلك؟
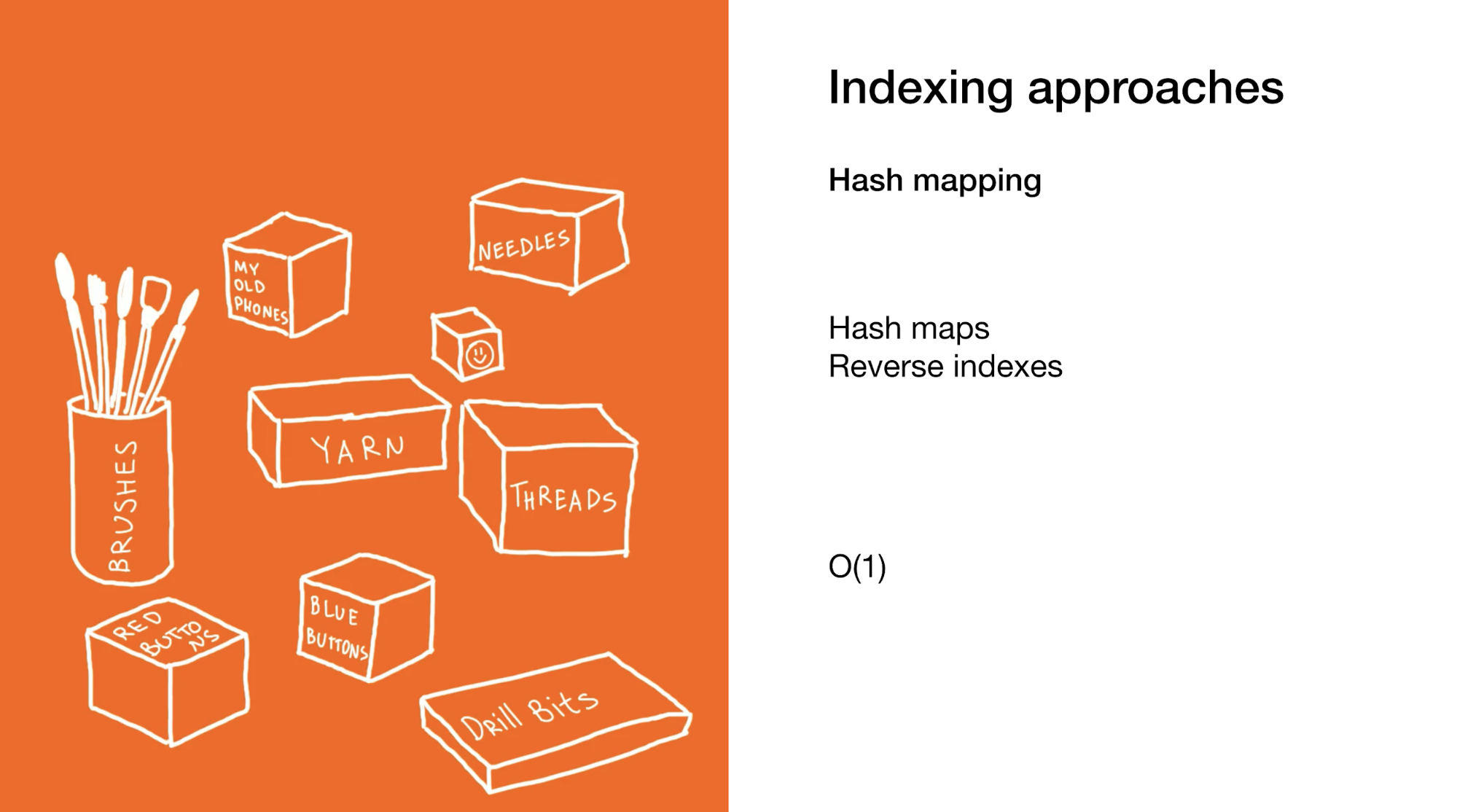
الطريقة الثانية هي تحديد العنصر أو مجموعة العناصر المطلوبة فورًا. نقوم بذلك في خرائط التجزئة أو في فهارس عكسية. استخدام خرائط التجزئة مشابه جدًا للمثال السابق ، فقط بدلاً من مربع به مربعات في خزانتك يوجد الكثير من الصناديق الصغيرة مع العناصر النهائية.

النهج الثالث هو التخلص من الحاجة للبحث. نفعل ذلك باستخدام مرشحات Bloom أو مرشحات الوقواق. السابق تقديم إجابة على الفور ، مما يلغي الحاجة إلى البحث.
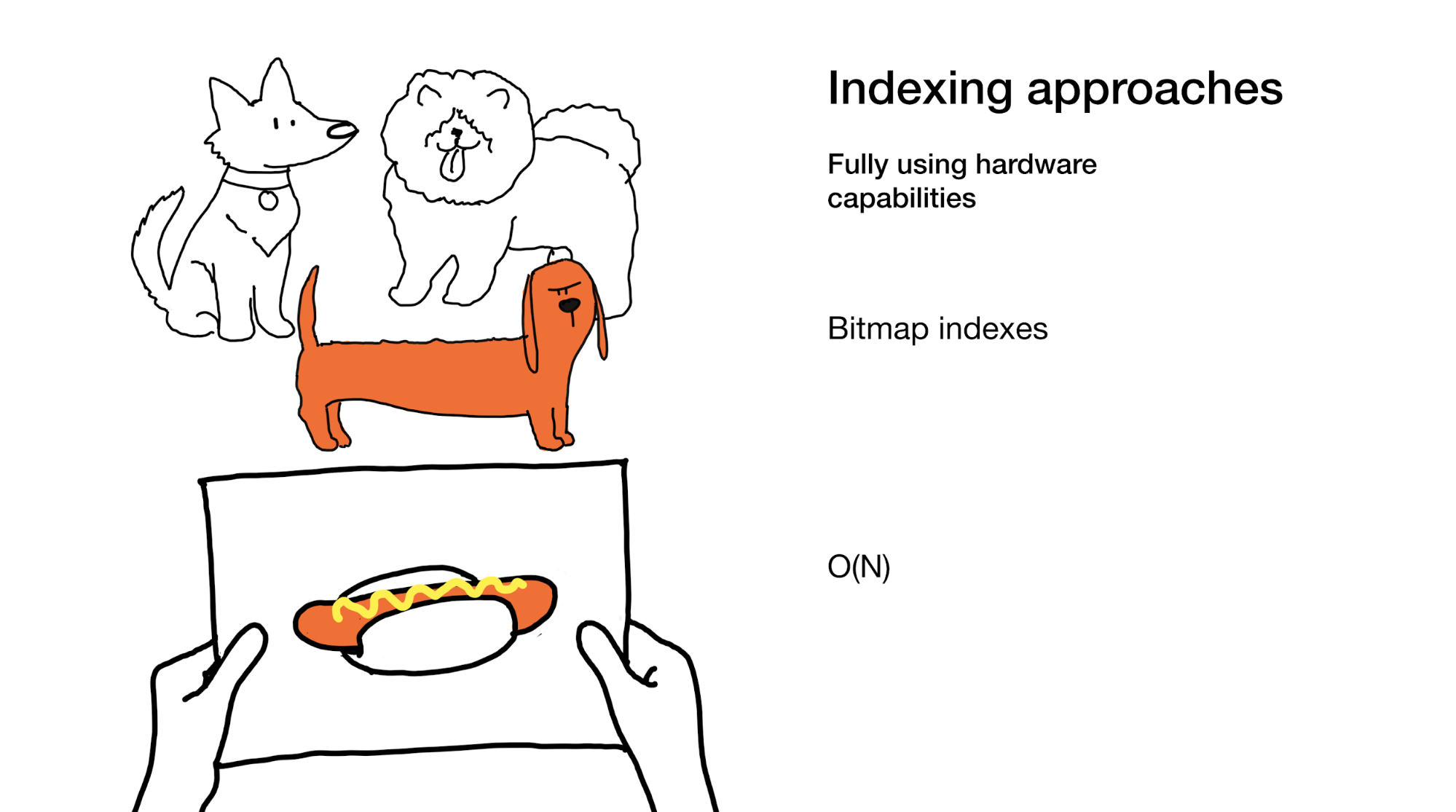
النهج الأخير هو الاستفادة الكاملة من جميع القدرات التي يعطينا الحديد الحديث. هذا هو بالضبط ما نفعله في مؤشرات الصورة النقطية. نعم ، عند استخدامها ، نحتاج أحيانًا إلى استعراض الفهرس بأكمله ، لكننا نقوم به بكفاءة عالية.
كما قلت ، موضوع فهارس قاعدة البيانات واسع وتفيض بالتنازلات. هذا يعني أنه في بعض الأحيان يمكننا استخدام عدة طرق في نفس الوقت: إذا كنا بحاجة إلى تسريع البحث أكثر أو إذا كان من الضروري تغطية جميع أنواع البحث الممكنة.
سأتحدث اليوم عن النهج الأقل شهرة من هذه - حول فهارس الصورة النقطية.
من أنا لأتحدث عن هذا؟
أعمل كقيادة فريق في Badoo (ربما كنت تعرف منتجاتنا الأخرى ، Bumble). لدينا بالفعل أكثر من 400 مليون مستخدم حول العالم والعديد من الميزات التي تشارك في اختيار أفضل زوج لهم. نقوم بذلك باستخدام خدمات مخصصة تستخدم فهارس الصور النقطية.
إذن ما هو فهرس الصورة النقطية؟
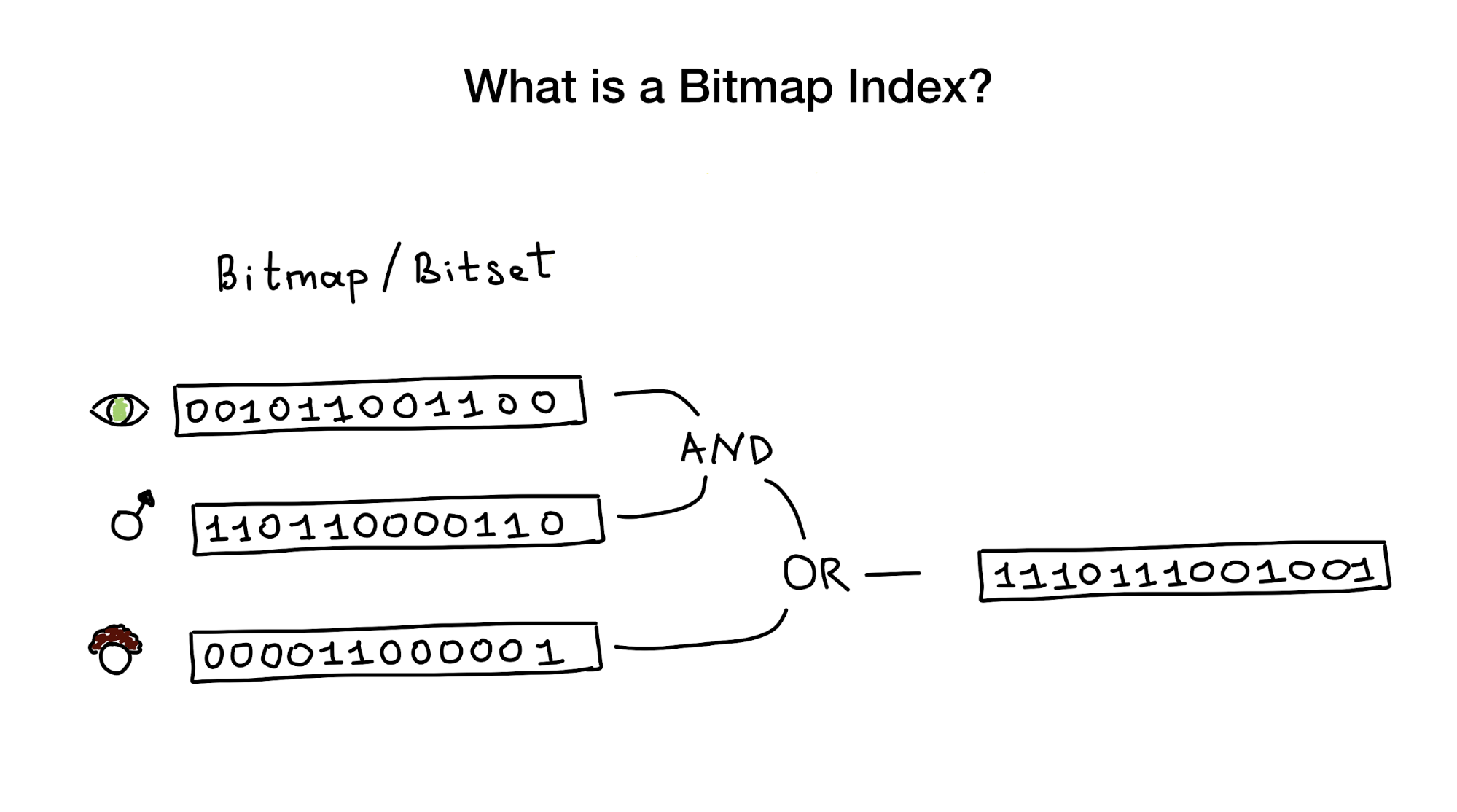
فهارس الصورة النقطية ، كما يخبرنا الاسم ، استخدم الصور النقطية أو مجموعات البت لتطبيق فهرس البحث. من وجهة نظر عين الطير ، يتكون هذا الفهرس من واحدة أو أكثر من الصور النقطية التي تمثل أي كيانات (مثل الأشخاص) وخصائصها أو معلماتها (العمر ، لون العين ، وما إلى ذلك) ، ومن خوارزمية تستخدم عمليات البت (AND ، أو ، لا) للرد على استعلام البحث.

قيل لنا إن فهارس الصور النقطية هي الأنسب ومثمرة للغاية للحالات التي يوجد فيها بحث يجمع بين الاستعلامات عبر العديد من الأعمدة التي ليس لها أهمية تذكر (تخيل "لون العين" أو "الحالة الزوجية" مقابل شيء مثل "المسافة من مركز المدينة") ). لكن في وقت لاحق سأظهر أنها تعمل بشكل مثالي في حالة الأعمدة ذات الشهرة العالية.
النظر في أبسط مثال على فهرس الصورة النقطية.

تخيل أن لدينا قائمة بمطاعم موسكو ذات الخصائص الثنائية مثل:
- بالقرب من المترو (بالقرب من المترو) ؛
- يوجد موقف خاص للسيارات (به موقف خاص للسيارات) ؛
- يوجد شرفة (بها شرفة) ؛
- يمكنك حجز جدول (يقبل الحجوزات) ؛
- مناسبة للنباتيين (نباتي ودية) ؛
- غالية (غالية).
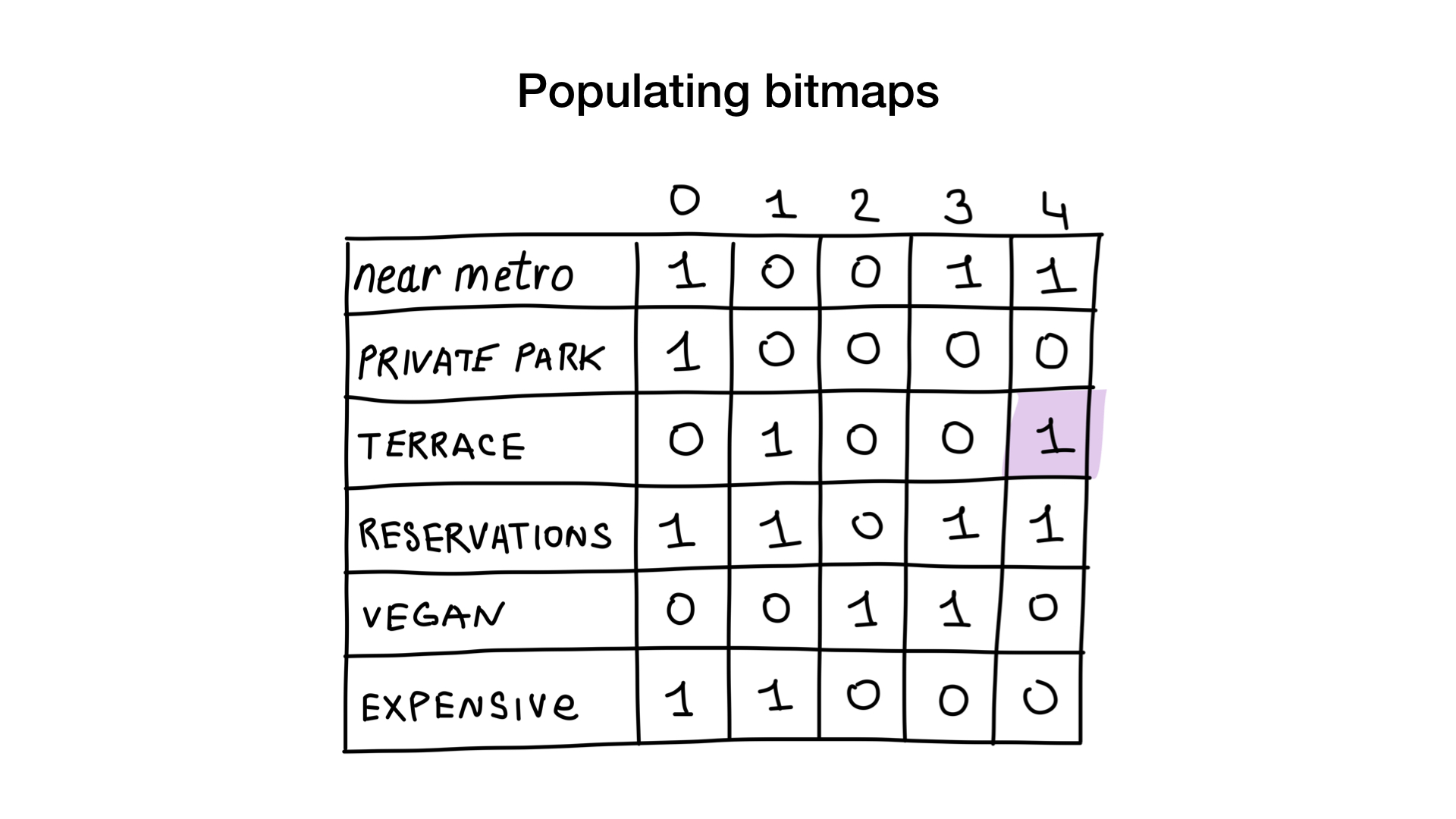
دعنا نمنح كل مطعم رقمًا تسلسليًا يبدأ من 0 ونخصص ذاكرة لـ 6 صور نقطية (واحد لكل سمة). ثم نملأ هذه الصور النقطية ، اعتمادًا على ما إذا كان المطعم لديه هذه الخاصية أم لا. إذا كان مطعم 4 لديه شرفة ، فسيتم تعيين البت رقم 4 في الصورة النقطية "هناك شرفة" على 1 (إذا لم يكن هناك شرفة ، ثم إلى 0).

الآن لدينا أبسط فهرس نقطي ممكن ، ويمكننا استخدامه للإجابة على استفسارات مثل:
- "أرني المطاعم المناسبة للنباتيين" ؛
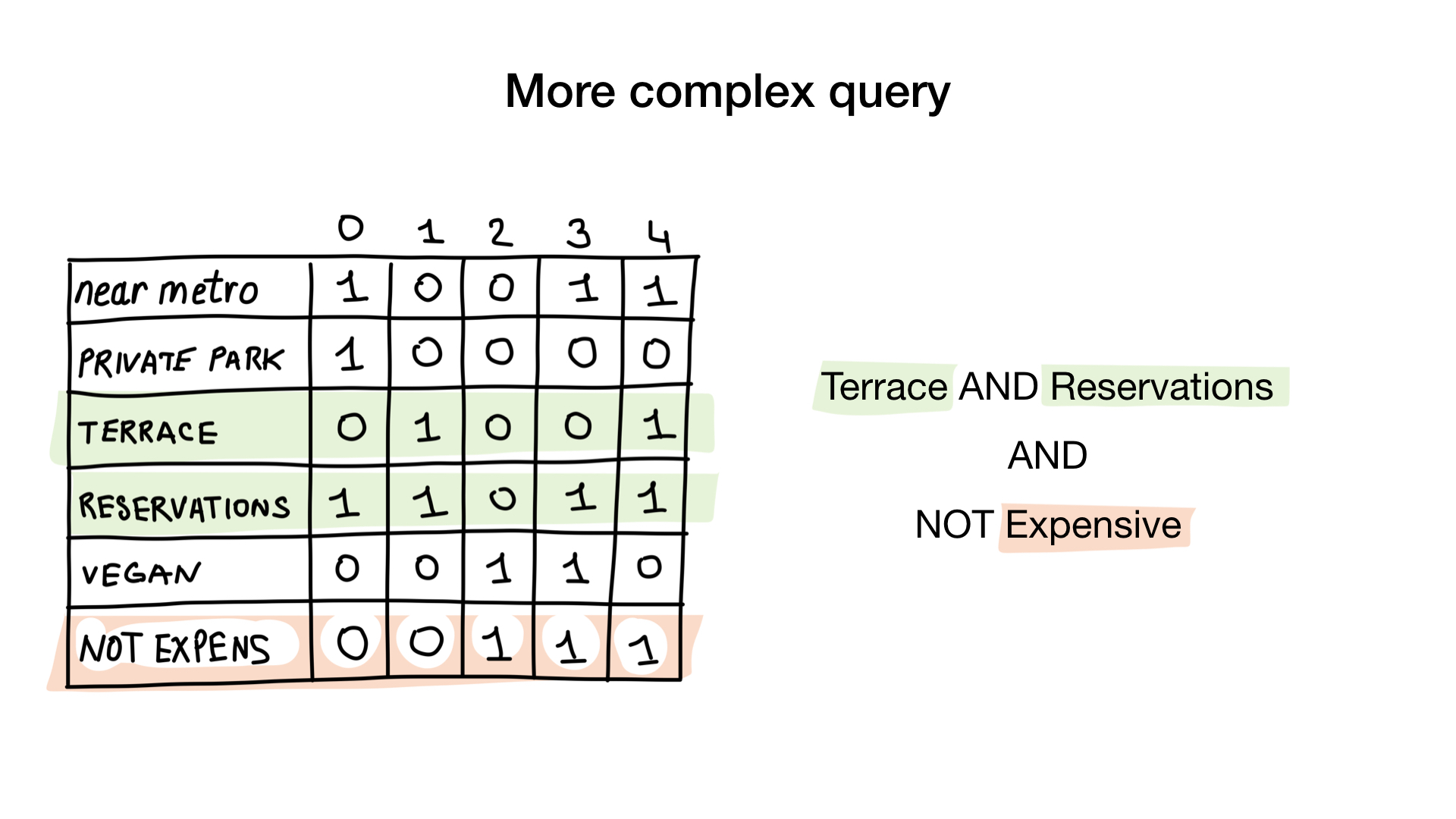
- "أرني المطاعم الرخيصة مع شرفة حيث يمكنك حجز طاولة."
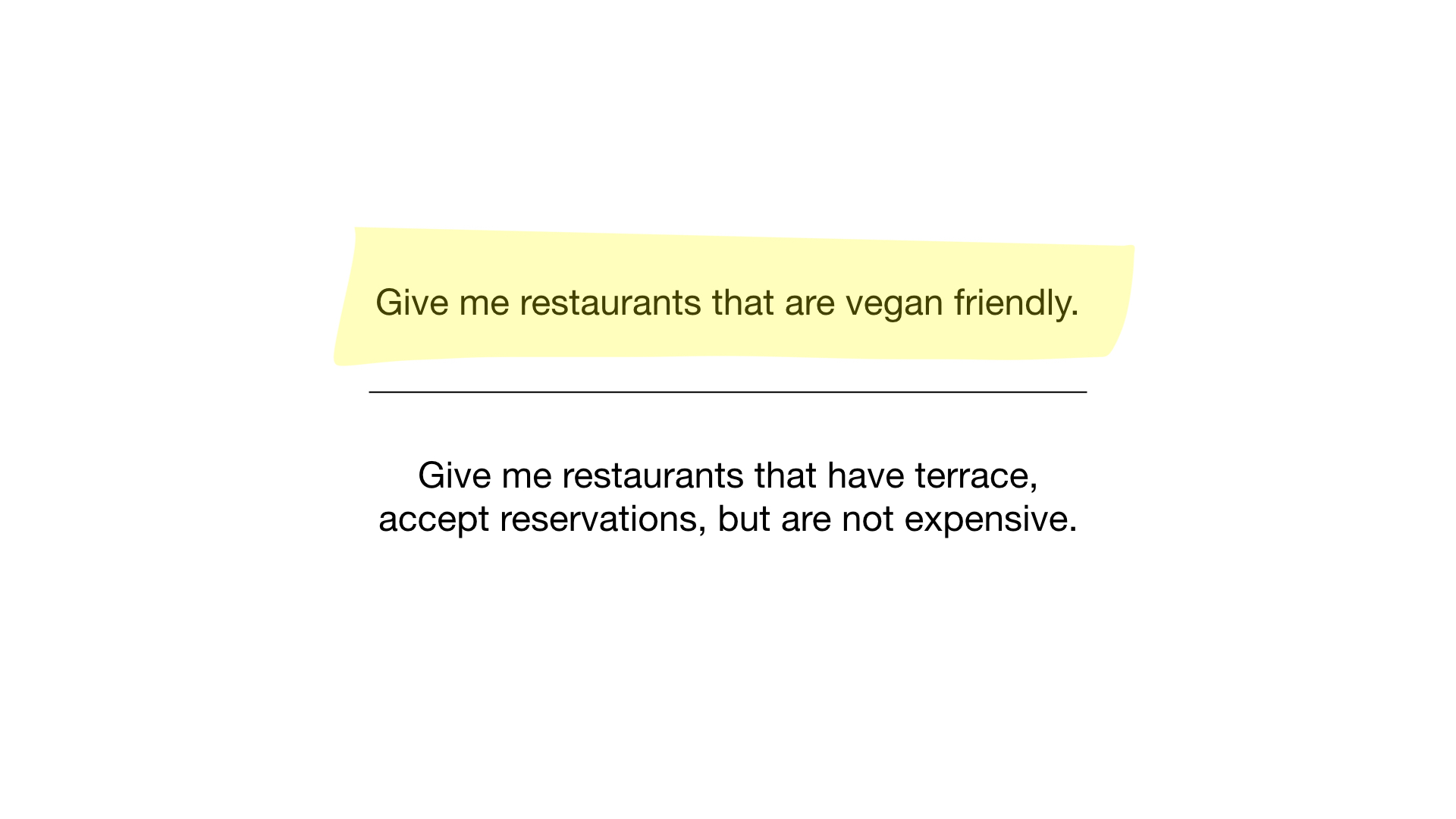
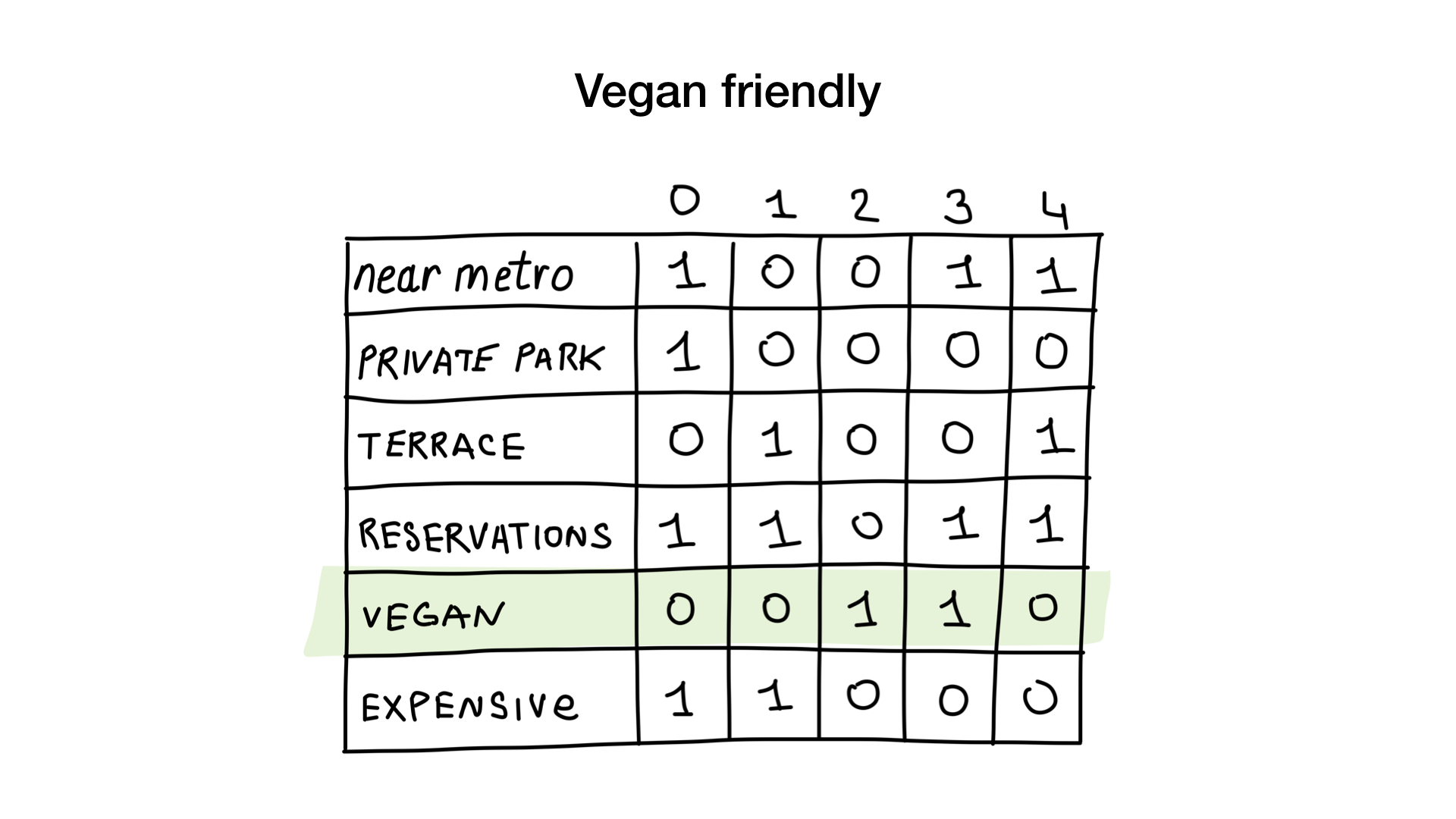
كيف؟ لنرى. الطلب الأول بسيط للغاية. كل ما نحتاج إلى القيام به هو أخذ صورة نقطية "مناسبة للنباتيين" وتحويلها إلى قائمة من المطاعم التي يتم عرض أجزاءها.
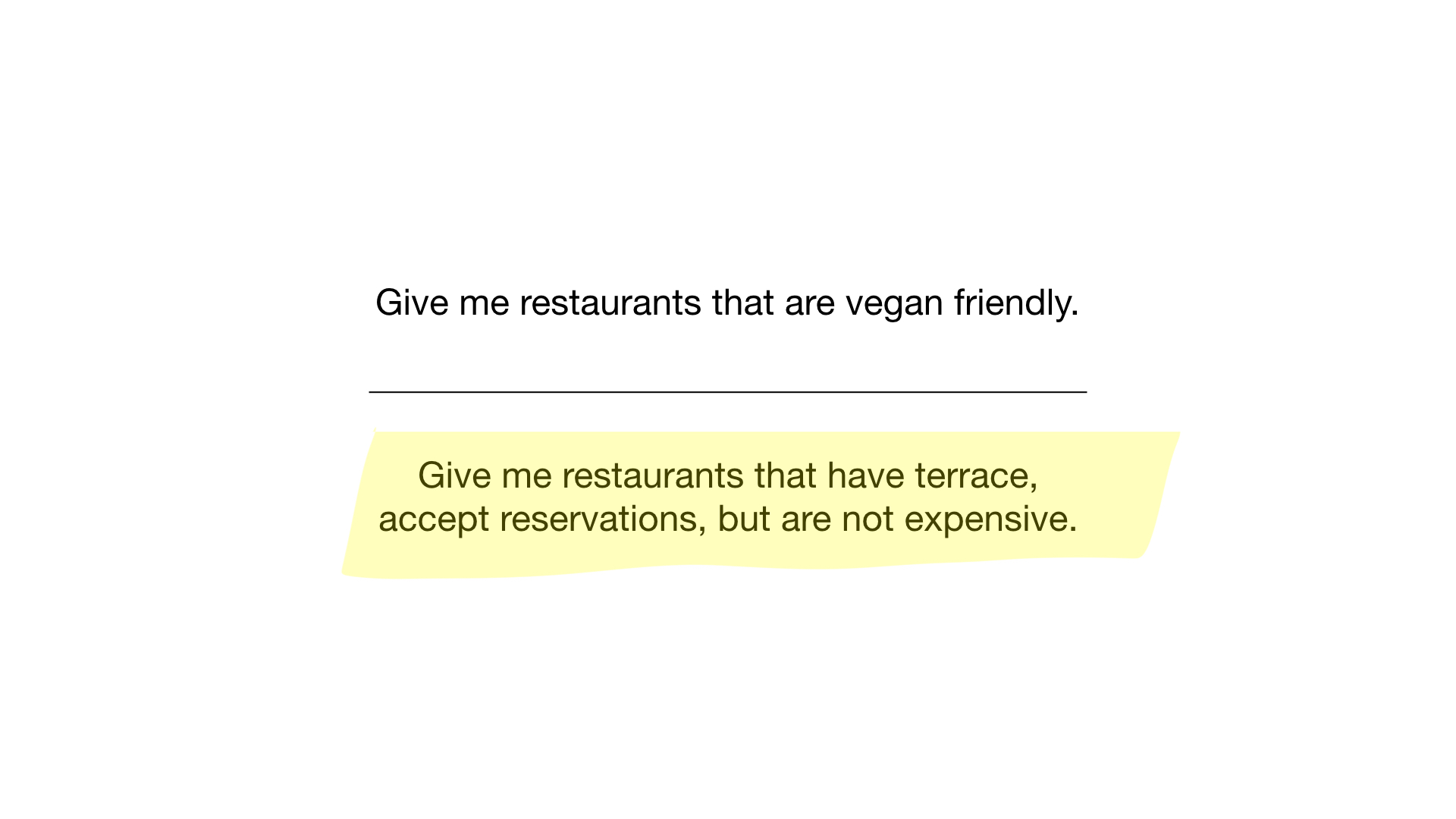

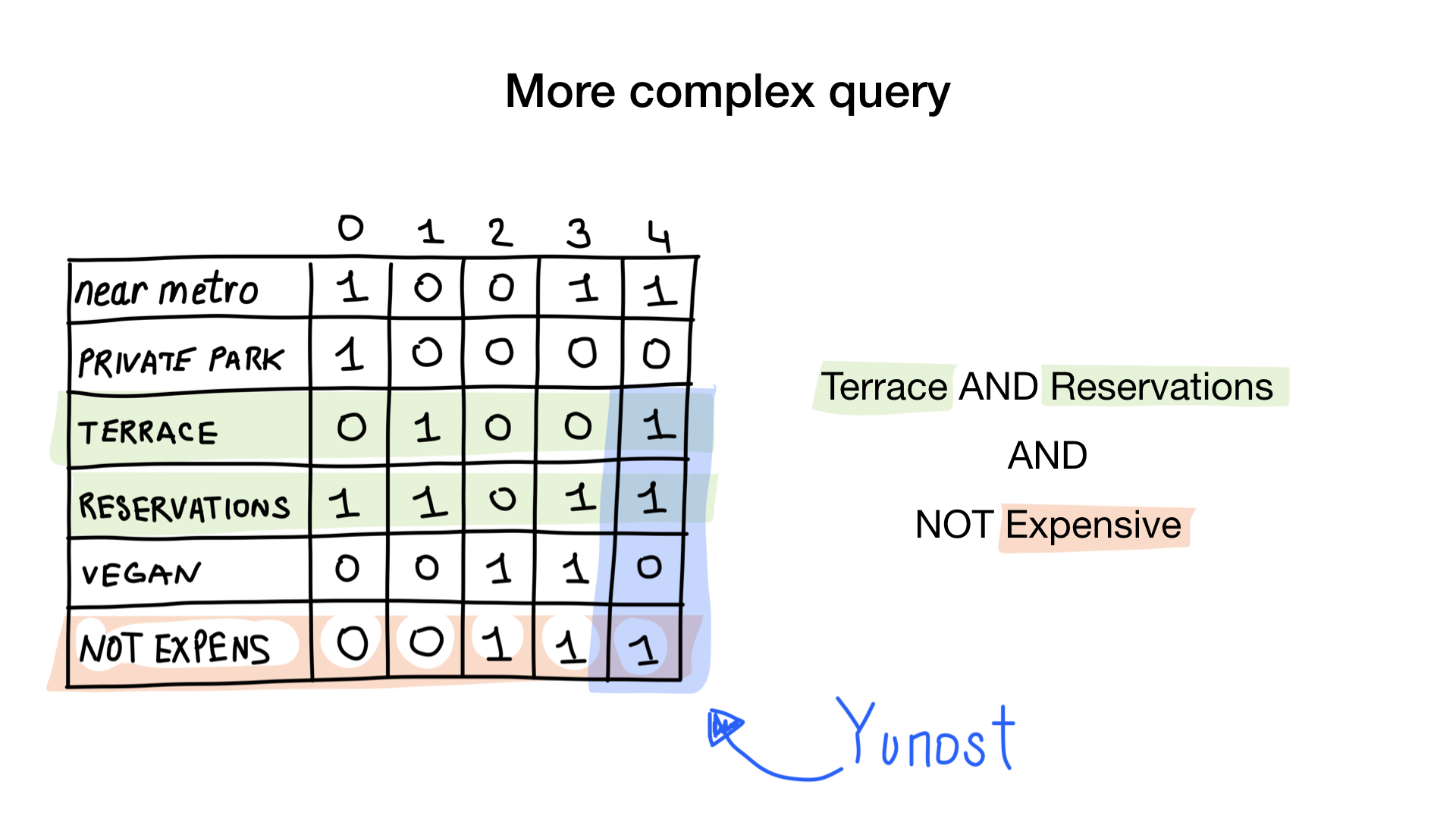
الاستعلام الثاني أكثر تعقيدًا قليلاً. نحتاج إلى استخدام العملية NOT bit في الصورة النقطية "الباهظة الثمن" للحصول على قائمة من المطاعم الرخيصة ، ثم قم بتعيينها مع الصورة النقطية "يمكنك حجز جدول" وتعيين النتيجة مع الصورة النقطية "هناك شرفة". سوف تحتوي الصورة النقطية الناتجة على قائمة المؤسسات التي تفي بجميع معاييرنا. في هذا المثال ، هذا هو مطعم Yunost فقط.
هناك الكثير من النظرية ، لكن لا تقلق ، فسوف نرى الكود قريبًا.
أين يتم استخدام فهارس الصورة النقطية؟

إذا قمت بفهرسة الصور النقطية "google" ، فستكون 90٪ من الإجابات مرتبطة بطريقة أوراكل بـ Oracle DB. ولكن ما تبقى من DBMS ربما يدعم مثل هذا الشيء الرائع ، أليس كذلك؟ ليس حقا
دعنا نذهب من خلال قائمة المشتبه بهم الرئيسيين.

لا يدعم MySQL بعد فهارس الصور النقطية ، ولكن هناك اقتراح مع اقتراح لإضافة هذا الخيار (
https://dev.mysql.com/worklog/task/؟id=1524 ).
لا يدعم PostgreSQL فهارس الصور النقطية ، لكنه يستخدم الصور النقطية البسيطة وعمليات البت لدمج نتائج البحث عبر عدة فهارس أخرى.
يحتوي Tarantool على فهارس بت ، وهو يدعم البحث البسيط عنها.
لدى Redis حقول بت بسيطة
(https://redis.io/commands/bitfield ) دون القدرة على البحث من خلالها.
لا يدعم MongoDB حتى الآن فهارس الصور النقطية ، ولكن يوجد أيضًا اقتراح مع اقتراح لإضافة هذا الخيار
https://jira.mongodb.org/browse/SERVER-1723يستخدم Elasticsearch الصور النقطية داخل
(https://www.elastic.co/blog/frame-of-reference-and-roaring-bitmaps ).

- لكن جارًا جديدًا ظهر في منزلنا: بيلوسا. هذه قاعدة بيانات جديدة غير علائقية مكتوبة في Go. أنه يحتوي على فهارس الصورة النقطية فقط ويستند كل شيء عليها. سنتحدث عنها بعد قليل.
الذهاب التنفيذ
لكن لماذا نادراً ما تستخدم فهارس الصورة النقطية؟ قبل الإجابة على هذا السؤال ، أود أن أوضح لك تنفيذ فهرس صورة نقطية بسيط جدًا على Go.

الصور النقطية هي في الأساس مجرد أجزاء من البيانات. في Go ، دعونا نستخدم شرائح البايت لهذا الغرض.
لدينا صورة نقطية واحدة لكل مطعم مميز ، وكل جزء في الصورة النقطية يشير إلى ما إذا كان مطعم معين لديه هذه الخاصية أم لا.

سنحتاج وظيفتين مساعدتين. سيتم استخدام واحد لملء الصور النقطية لدينا مع بيانات عشوائية. عشوائي ، ولكن مع احتمال معين أن المطعم لديه كل الممتلكات. على سبيل المثال ، أعتقد أن هناك عددًا قليلًا جدًا من المطاعم في موسكو لا يمكنك حجز طاولة فيها ، ويبدو لي أن حوالي 20٪ من المنشآت مناسبة للنباتيين.
تقوم الوظيفة الثانية بتحويل الصورة النقطية إلى قائمة المطاعم.


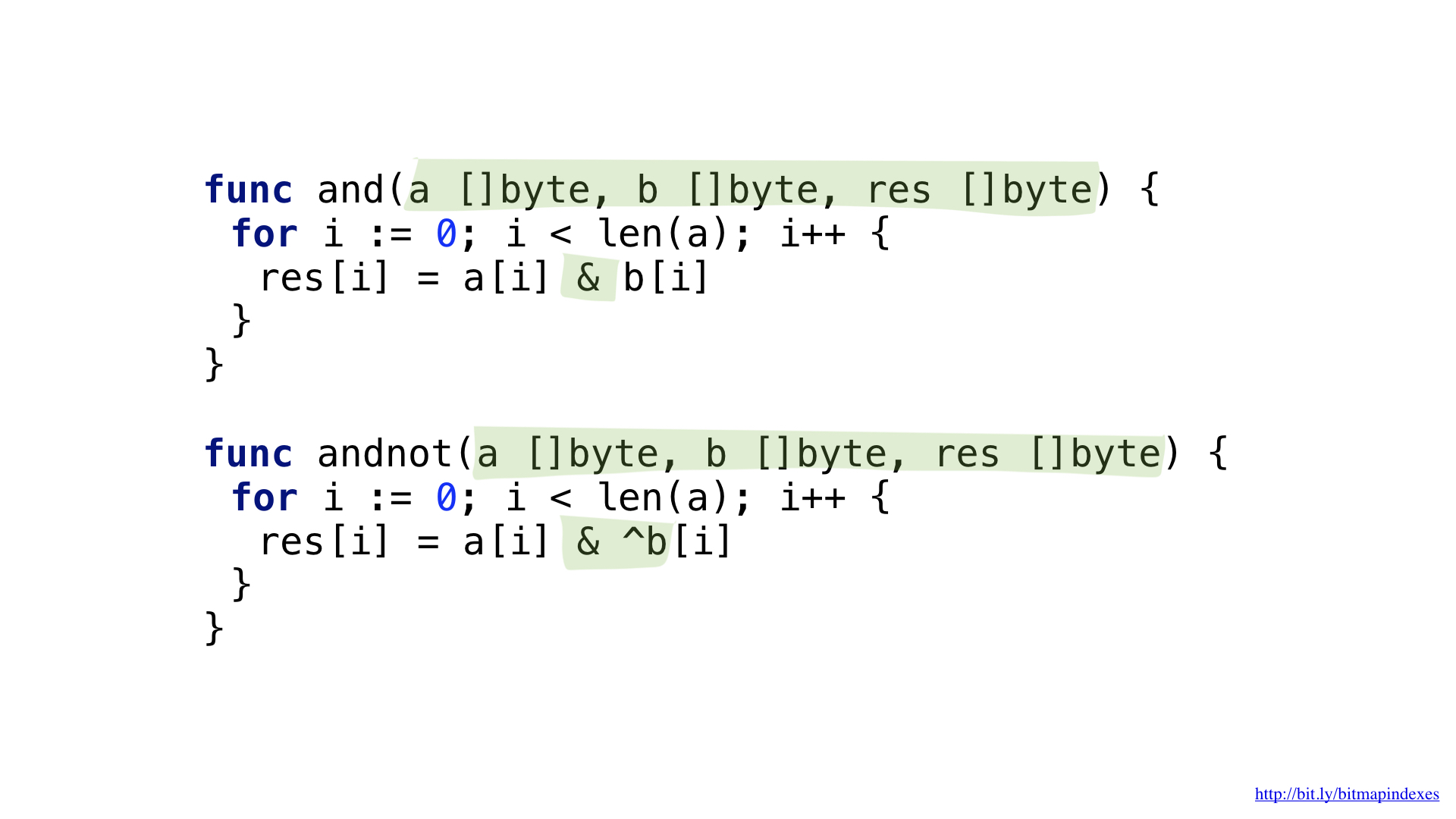
للإجابة على الطلب "أرني المطاعم الرخيصة التي تحتوي على شرفة وتمكّن من حجز طاولة" ، نحتاج إلى عمليتين بت: NOT و AND.
يمكننا تبسيط الكود الخاص بنا قليلاً باستخدام العملية "NOT" الأكثر تعقيدًا.
لدينا وظائف لكل من هذه العمليات. كل منهما يمر عبر الشرائح ، ويأخذ العناصر المقابلة من كل منهما ، ويجمعها مع عملية قليلاً ويضع النتيجة في الشريحة الناتجة.
والآن يمكننا استخدام الصور النقطية ووظائفنا للاستجابة لاستعلام البحث.

الأداء ليس مرتفعًا للغاية ، على الرغم من أن الوظائف بسيطة للغاية وقد قمنا بحفظها بشكل جيد في حقيقة أننا لم نرجع شريحة ناتجة جديدة في كل مرة تم فيها استدعاء الوظيفة.
بعد التوصيف قليلاً مع pprof ، لاحظت أن برنامج التحويل البرمجي Go غاب عن التحسين البسيط للغاية ، ولكنه مهم للغاية: تضمين الدالة.
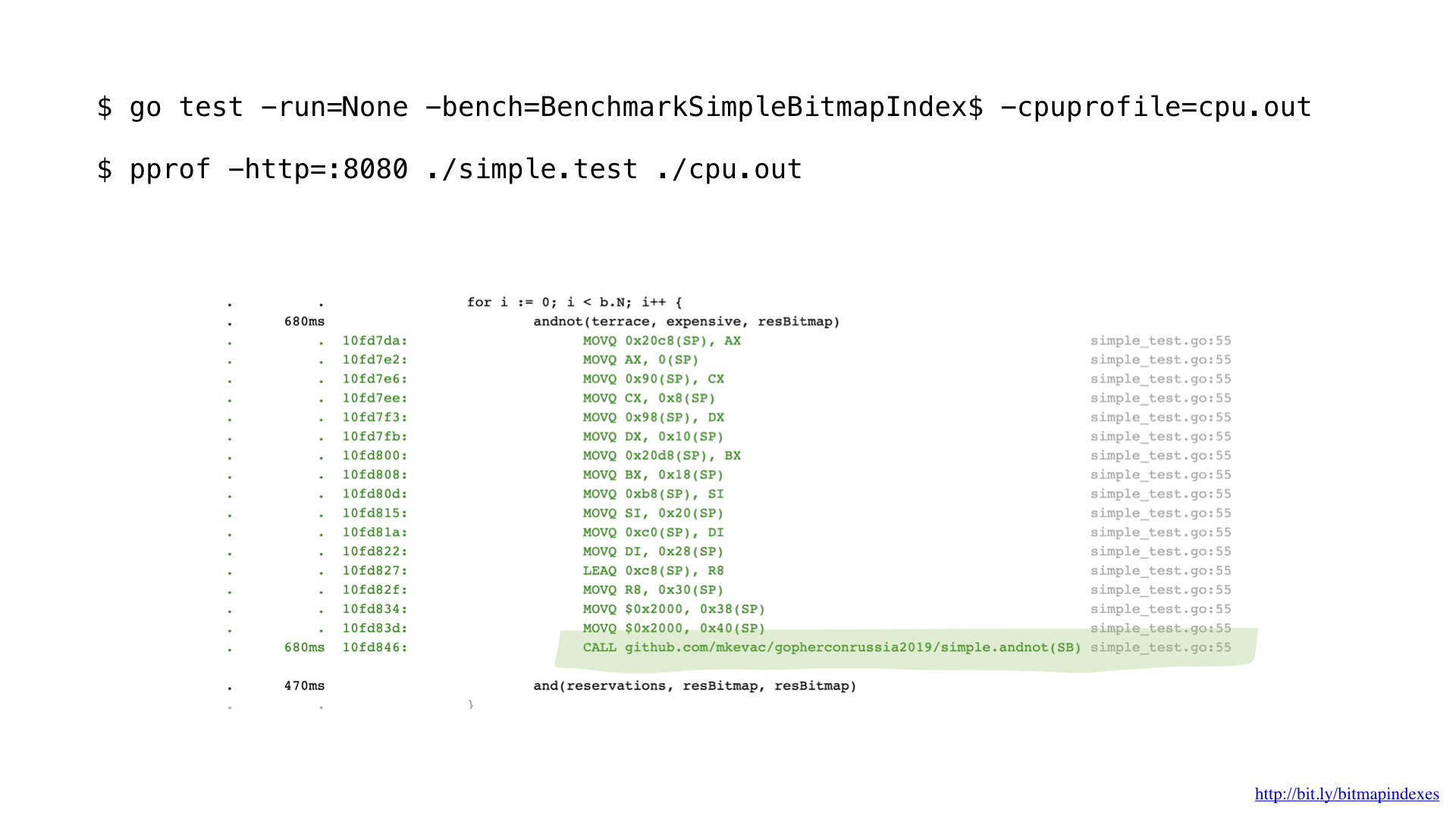
الحقيقة هي أن برنامج التحويل البرمجي Go يخاف بشكل رهيب من الحلقات التي تمر عبر الشرائح ، ويرفض رفضًا قاطعًا تضمين الدالات المضمنة التي تحتوي على حلقات.
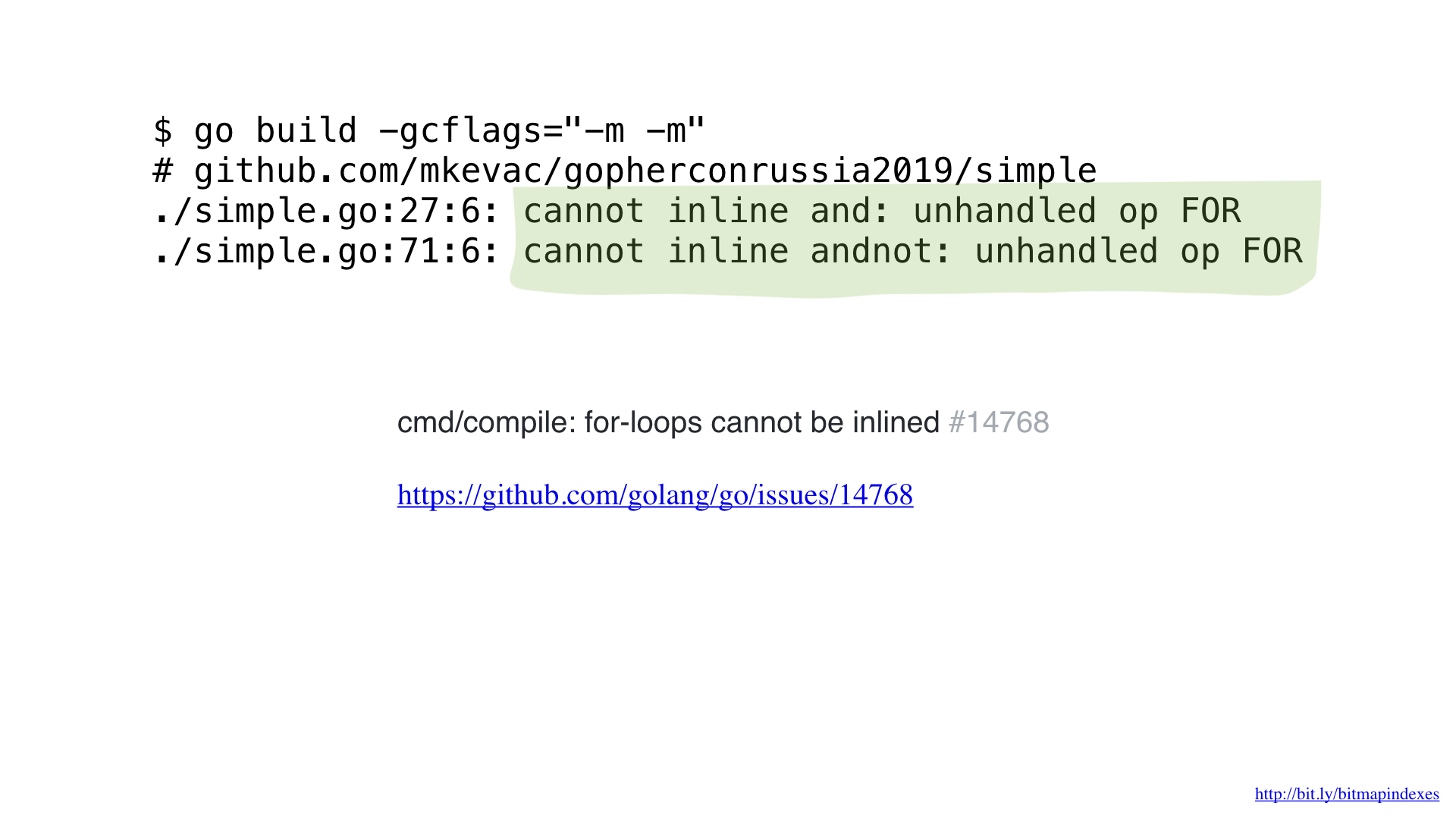
لكنني لست خائفًا ، ويمكنني خداع المترجم باستخدام goto بدلاً من حلقة ، كما في الأيام الخوالي.


وكما ترون ، يقوم المترجم الآن بسعادة بتضمين وظيفتنا! نتيجة لذلك ، نجحنا في توفير حوالي 2 ميكروثانية. ليس سيئا!

عنق الزجاجة الثاني سهل لمعرفة ما إذا كنت تنظر بعناية إلى إخراج المجمّع. وقد أضاف المترجم فحص شريحة ملزمة مباشرة داخل أهم حلقة لدينا. الحقيقة هي أن Go هي لغة آمنة ، ويخشى المترجم أن تكون حججاتي الثلاث (ثلاث شرائح) مختلفة الأحجام. بعد كل شيء ، ثم سيكون هناك احتمال نظري لظهور ما يسمى تجاوز سعة المخزن المؤقت.
دعونا نطمئن المترجم من خلال إظهار أن جميع الشرائح لها نفس الحجم. يمكننا القيام بذلك عن طريق إضافة فحص بسيط في بداية وظيفتنا.
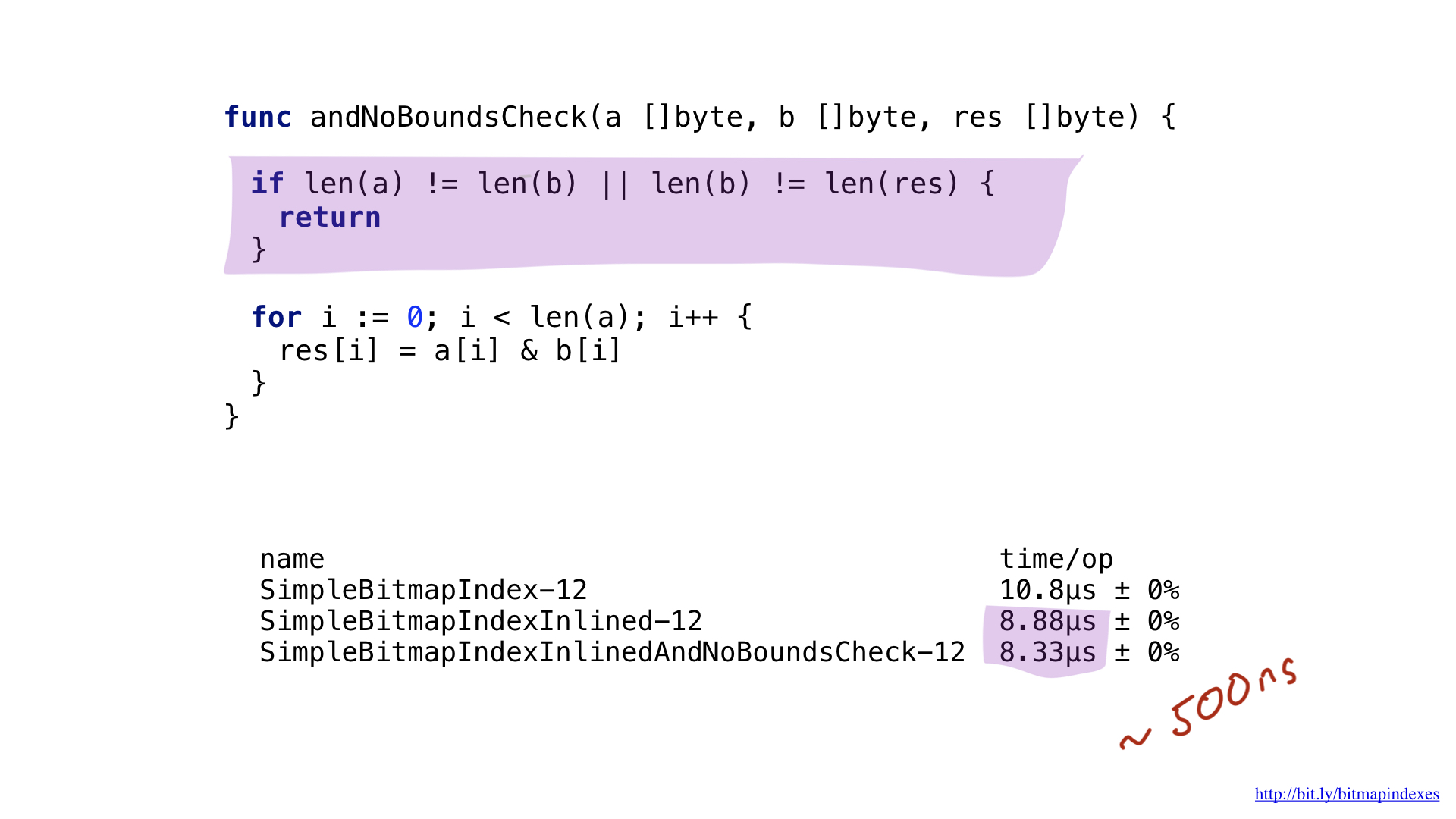
رؤية هذا ، المترجم يتخطى بسعادة الاختبار ، ونحن في نهاية المطاف توفير 500 نانوثانية أخرى.
دفعات كبيرة
حسنًا ، لقد تمكنا من ضغط بعض الأداء من خلال تنفيذنا البسيط ، ولكن هذه النتيجة ، في الواقع ، أسوأ بكثير من الممكن مع الأجهزة الحالية.
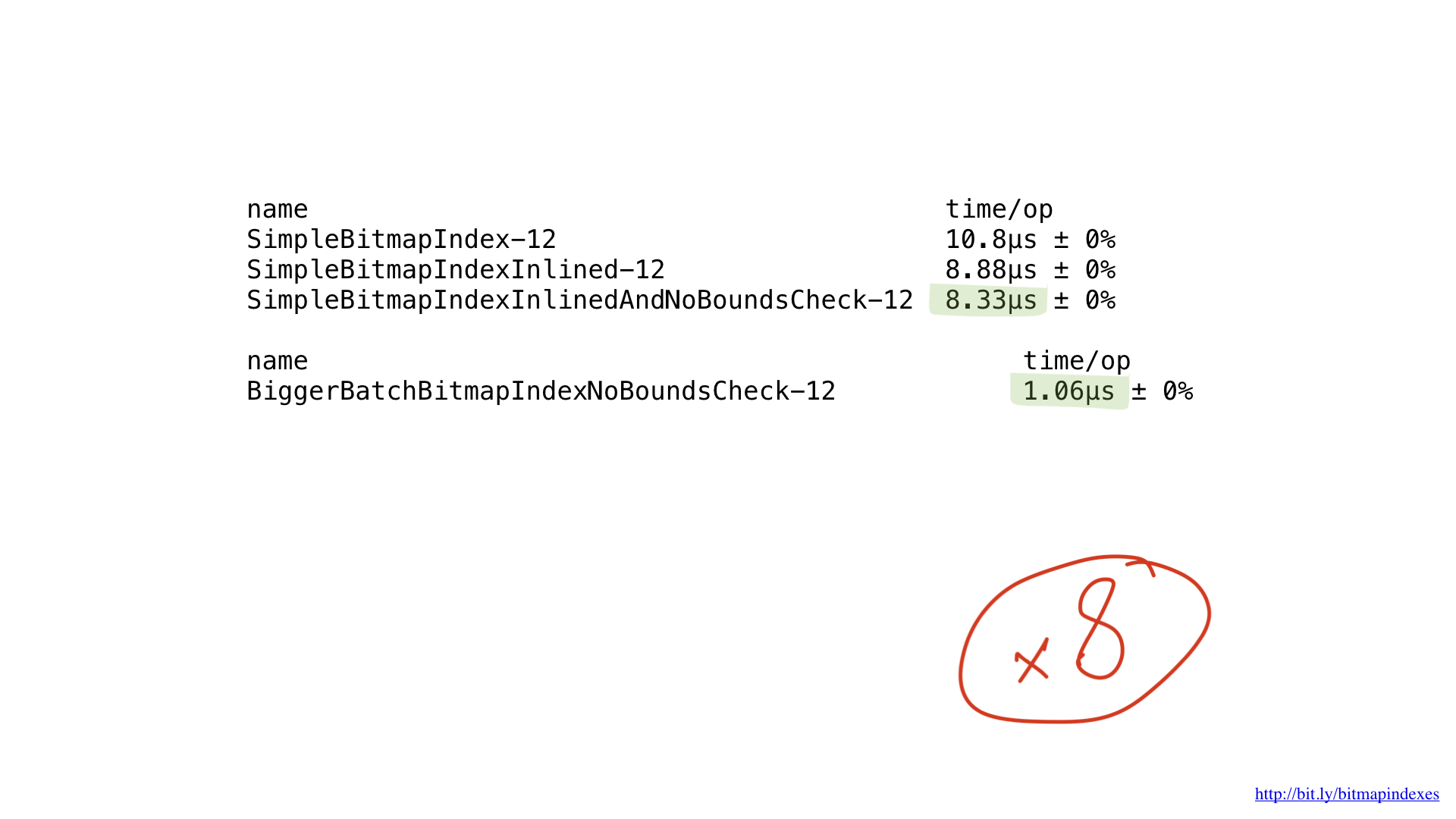
كل ما نقوم به هو عمليات البت الأساسية ، وأداء المعالجات لدينا بكفاءة عالية. لكن ، لسوء الحظ ، نقوم "بتغذية" معالجنا بقطع صغيرة جدًا من العمل. وظائفنا أداء عمليات بايت بايت. يمكننا بسهولة ضبط الكود الخاص بنا بحيث يعمل مع قطع 8 بايت باستخدام شرائح UInt64.

كما ترون ، فإن هذا التغيير الطفيف قد سرع من سرعة برنامجنا بمقدار ثماني مرات بسبب زيادة الدفعة بمقدار ثماني مرات. يمكن القول أن المكسب خطي.
تنفيذ المجمع

لكن هذه ليست النهاية. يمكن أن تعمل معالجاتنا مع قطع من 16 و 32 وحتى 64 بايت. وتسمى هذه العمليات "الواسعة" بيانات متعددة للتعليمات الفردية (SIMD ؛ تعليمة واحدة ، الكثير من البيانات) ، وعملية تحويل الكود بحيث يستخدم مثل هذه العمليات تسمى vectorization.
لسوء الحظ ، فإن برنامج التحويل البرمجي Go بعيدًا عن كونه طالبًا ممتازًا في مجال التوجيه. في الوقت الحالي ، الطريقة الوحيدة لتوجيه التعليمات البرمجية على Go هي اتخاذ هذه العمليات ووضعها يدويًا باستخدام أداة التجميع Go.

مجمع الجامع هو وحش غريب. ربما تعرف أن المجمّع هو شيء مرتبط بشدة بهندسة الكمبيوتر الذي تكتب له ، ولكن هذا ليس هو الحال مع Go. يشبه مجمع المجمّع IRL (لغة التمثيل الوسيطة) أو اللغة الوسيطة: فهو عمليًا بشكل مستقل عن النظام الأساسي. قدم روب بايك
عرضًا ممتازًا حول هذا الموضوع قبل بضع سنوات في GopherCon في دنفر.
بالإضافة إلى ذلك ، يستخدم Go التنسيق غير العادي Plan 9 ، والذي يختلف عن تنسيقي AT&T و Intel المعترف بهما عمومًا.

من الآمن القول أن كتابة Go المجمّع يدويًا ليست أكثر الأنشطة متعة.
ولكن ، لحسن الحظ ، هناك بالفعل أداتان رفيعتان تساعدنا في كتابة مجمِّع Go: PeachPy وتجنبهما. تنشئ كل من الأدوات المساعدة مجمعات Go من رمز المستوى الأعلى المكتوب في Python و Go ، على التوالي.

تعمل هذه الأدوات المساعدة على تبسيط أشياء مثل تخصيص السجل ودورات الكتابة وعمومًا تبسيط عملية إدخال عالم برمجة المجمّع في Go.
سنستخدم تجنب ، لذلك ستكون برامجنا برامج Go عادية تقريبًا.

هذا هو ما يبدو عليه أبسط مثال على برنامج تجنب. لدينا وظيفة رئيسية () تعرّف الوظيفة Add () بداخلها ، ومعنى ذلك هو إضافة رقمين. هناك وظائف إضافية للحصول على المعلمات بالاسم والحصول على واحدة من سجلات المعالج المجانية والمناسبة. كل عملية تشغيل للمعالج لها وظيفة مماثلة عند تجنب ، كما هو موضح في ADDQ. أخيرًا ، نرى وظيفة مساعدة لتخزين القيمة الناتجة.

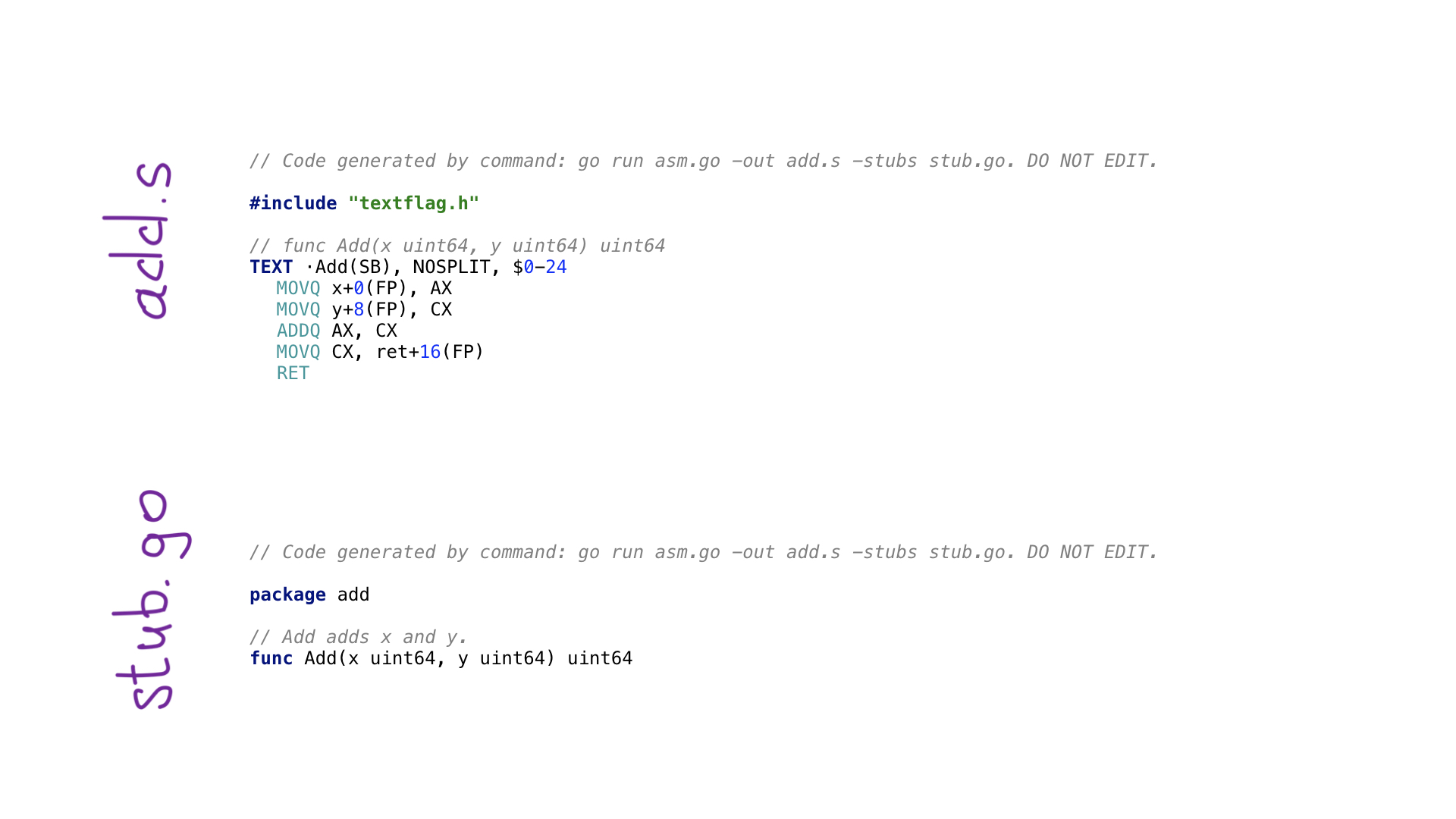
عن طريق الاتصال go create ، سنقوم بتنفيذ البرنامج على تجنب وفي النهاية سيتم إنشاء ملفين:
- add.s مع شفرة Go المجمعة الناتجة ؛
- stub.go مع رؤوس الوظائف لربط عالمين: اذهب والمجمع.
الآن بعد أن رأينا ماذا وكيف يمكن تجنبه ، دعونا نلقي نظرة على وظائفنا. قمت بتنفيذ كل من الإصدارات العددية والمتجهات (SIMD) للوظائف.
أولاً ، انظر إلى الإصدارات العددية.

كما في المثال السابق ، نطلب منك تزويدنا بسجل مجاني وصحيح للأغراض العامة ، ولا نحتاج إلى حساب الإزاحات والأحجام الخاصة بالوسائط. كل هذا تجنب يفعل بالنسبة لنا.

في وقت سابق ، استخدمنا التصنيفات و goto (أو القفزات) لتحسين الأداء وخداع برنامج التحويل البرمجي Go ، لكننا الآن نقوم به من البداية. والحقيقة هي أن الحلقات هي مفهوم مستوى أعلى. في المجمع ، لدينا فقط التسميات والقفزات.

يجب أن تكون الكود المتبقي مألوفة ومفهومة بالفعل. نحن نحاكي الحلقة بالملصقات والقفزات ، ونأخذ جزءًا صغيرًا من البيانات من شريحتين ، ونجمعها مع عملية قليلاً (وليس في هذه الحالة) ، ثم نضع النتيجة في الشريحة الناتجة. هذا كل شيء.

هذا هو ما يبدو رمز التجميع النهائي. لم نكن بحاجة إلى حساب الإزاحات والأحجام (الموضحة باللون الأخضر) أو تتبع السجلات المستخدمة (مظللة باللون الأحمر).
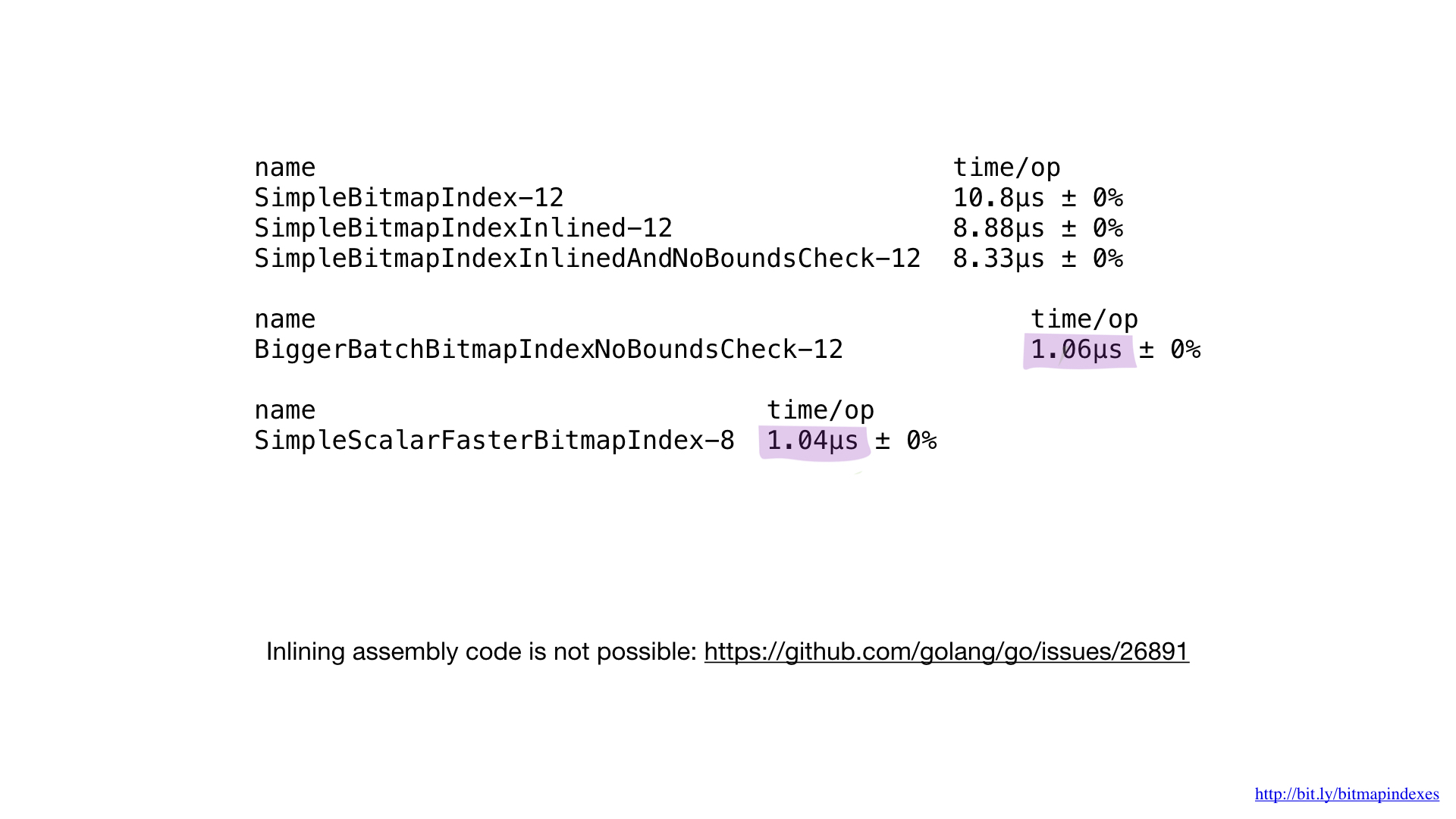
إذا قارنا أداء التنفيذ في المجمّع مع أداء أفضل تنفيذ في Go ، فسنرى أنه هو نفسه. ومن المتوقع. بعد كل شيء ، لم نفعل أي شيء خاص - لقد استنسخنا ما سيفعله برنامج التحويل البرمجي Go.
لسوء الحظ ، لا يمكننا فرض المترجم لتضمين وظائفنا المكتوبة في المجمع. لا يمتلك برنامج التحويل البرمجي Go هذه الميزة اليوم ، على الرغم من أن طلب إضافته موجود منذ بعض الوقت.
هذا هو السبب في أنه من المستحيل الحصول على أي فوائد من وظائف صغيرة في المجمع. نحتاج إما إلى كتابة وظائف كبيرة ، أو استخدام حزمة الرياضيات / بت جديدة ، أو تجاوز جانب المجمع.
دعونا الآن نلقي نظرة على الإصدارات المتجهية لوظائفنا.

في هذا المثال ، قررت استخدام AVX2 ، لذلك سنستخدم العمليات التي تعمل مع قطع 32 بايت. تشبه بنية الشفرة إلى حد كبير خيار القياس: تحميل المعلمات ، يرجى تزويدنا بسجل عام مجاني ، إلخ.
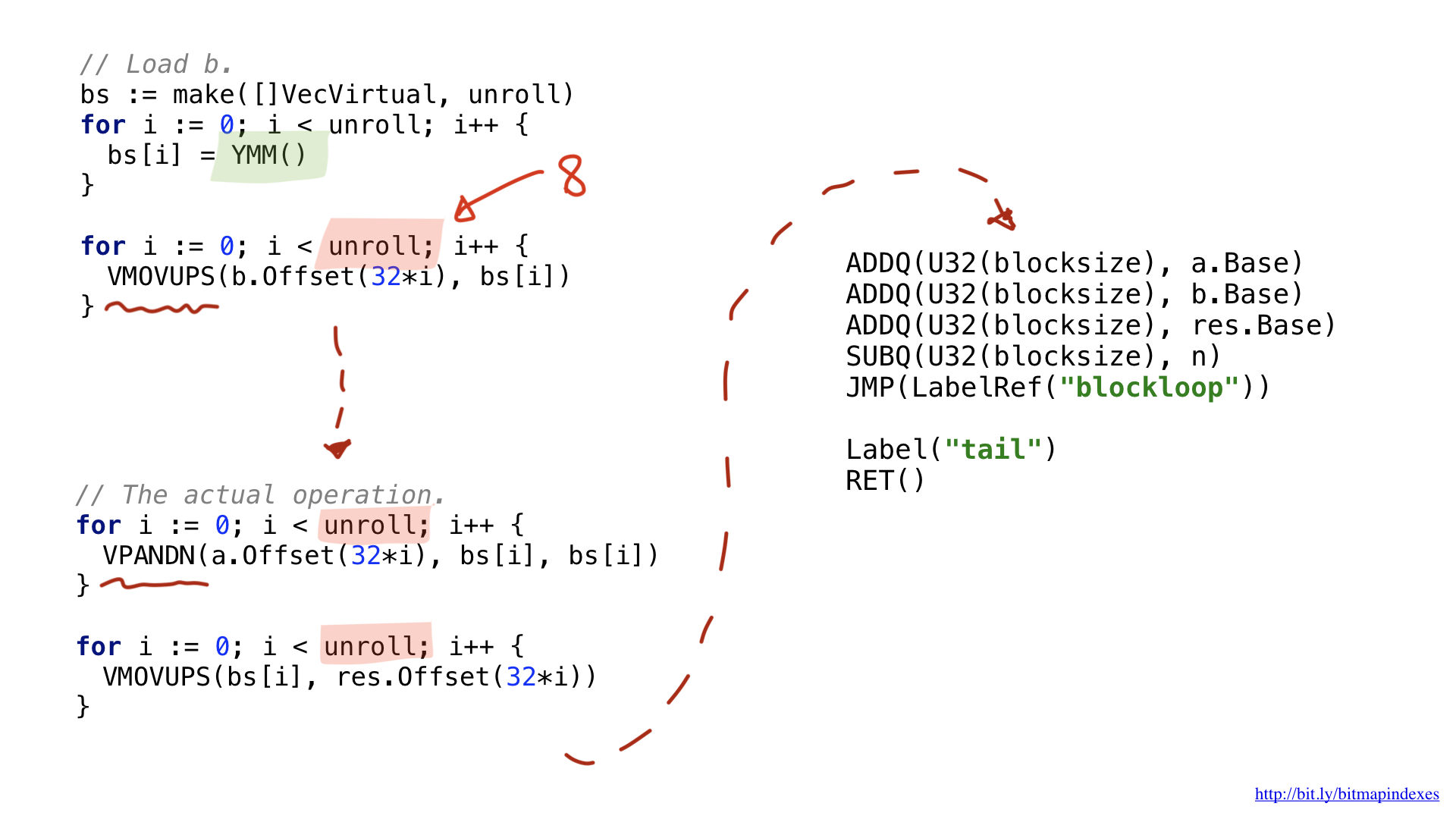
أحد الابتكارات هو أن عمليات المتجهات الأوسع تستخدم سجلات واسعة خاصة. في حالة القطع المكونة من 32 بايتًا ، فهذه هي السجلات التي تحتوي على البادئة Y. ولهذا السبب ترى الدالة YMM () في التعليمات البرمجية. إذا كنت أستخدم AVX-512 مع قطع 64 بت ، فستكون البادئة هي Z.
الابتكار الثاني هو أنني قررت استخدام تحسين يسمى loop unrolling ، أي القيام بثمانية عمليات حلقة يدوياً قبل القفز إلى بداية الحلقة. يقلل هذا التحسين من عدد البرنش (الفروع) في الكود ، وهو محدود بعدد السجلات المجانية المتاحة.
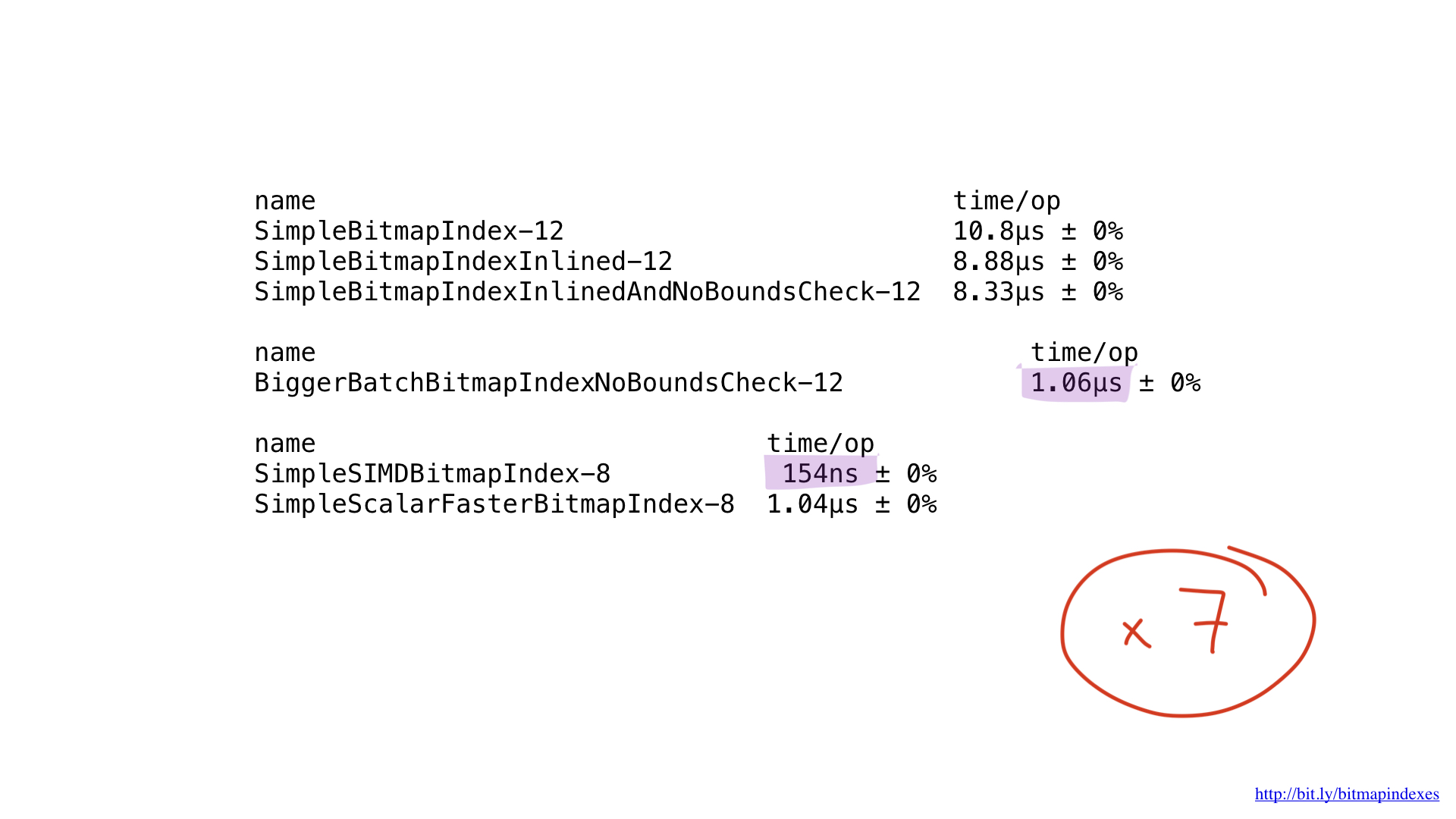
حسنا ، ماذا عن الأداء؟ إنها جميلة! حصلنا على تسارع حوالي سبع مرات مقارنة مع أفضل حل على الذهاب. مثير للإعجاب ، هاه؟
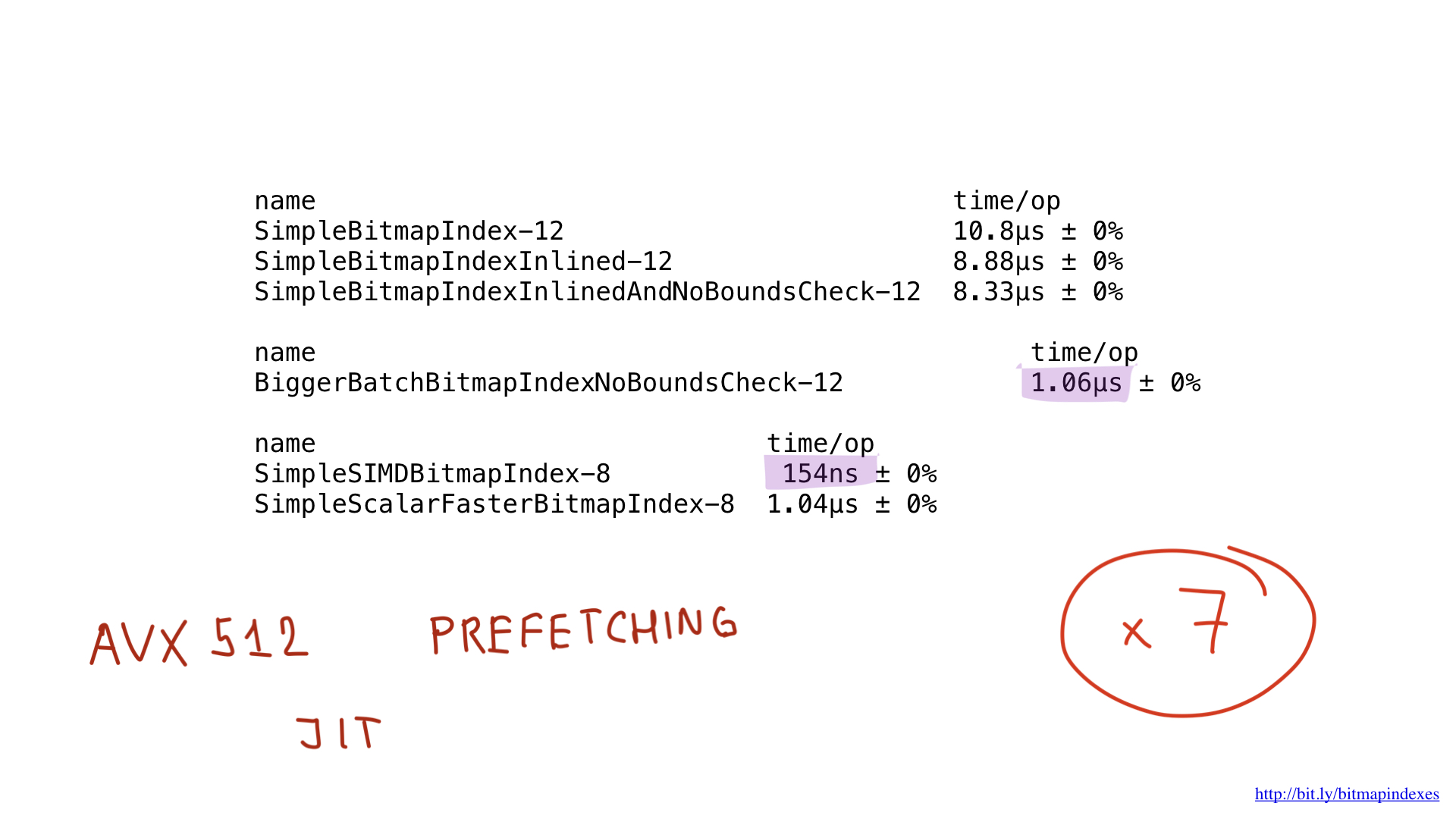
ولكن حتى من المحتمل تسريع هذا التطبيق باستخدام AVX-512 أو الجلب المسبق أو JIT (المترجم الفوري فقط) لمخطط الاستعلام. ولكن هذا بالتأكيد موضوع لتقرير منفصل.
مشاكل مؤشر الصورة النقطية
الآن وبعد أن نظرنا بالفعل في تطبيق بسيط لفهرس الصور النقطية Go ولغة التجميع الأكثر فاعلية ، دعونا نتحدث أخيرًا عن سبب ندرة استخدام فهارس الصور النقطية.

في الأوراق العلمية القديمة ، تم ذكر ثلاث مشكلات تتعلق بفهارس الصورة النقطية ، لكنني أوضح أن الأبحاث العلمية الأحدث لم تعد ذات صلة. لن نتعمق في كل من هذه المشاكل ، لكننا سننظر فيها بشكل سطحي.
مشكلة الكاردينال الكبير
لذلك ، يتم إخبارنا بأن فهارس الصور النقطية مناسبة فقط للحقول ذات الأهمية المنخفضة ، أي تلك التي لها قيم قليلة (على سبيل المثال ، النوع أو لون العين) ، والسبب هو أن التمثيل المعتاد لهذه الحقول (بت واحد لكل قيمة) في حالة الاصطلاحية الكبيرة ، سوف يستغرق مساحة كبيرة جدًا ، علاوة على ذلك ، سيتم ملء فهارس الصور النقطية هذه بشكل ضعيف (نادرًا).
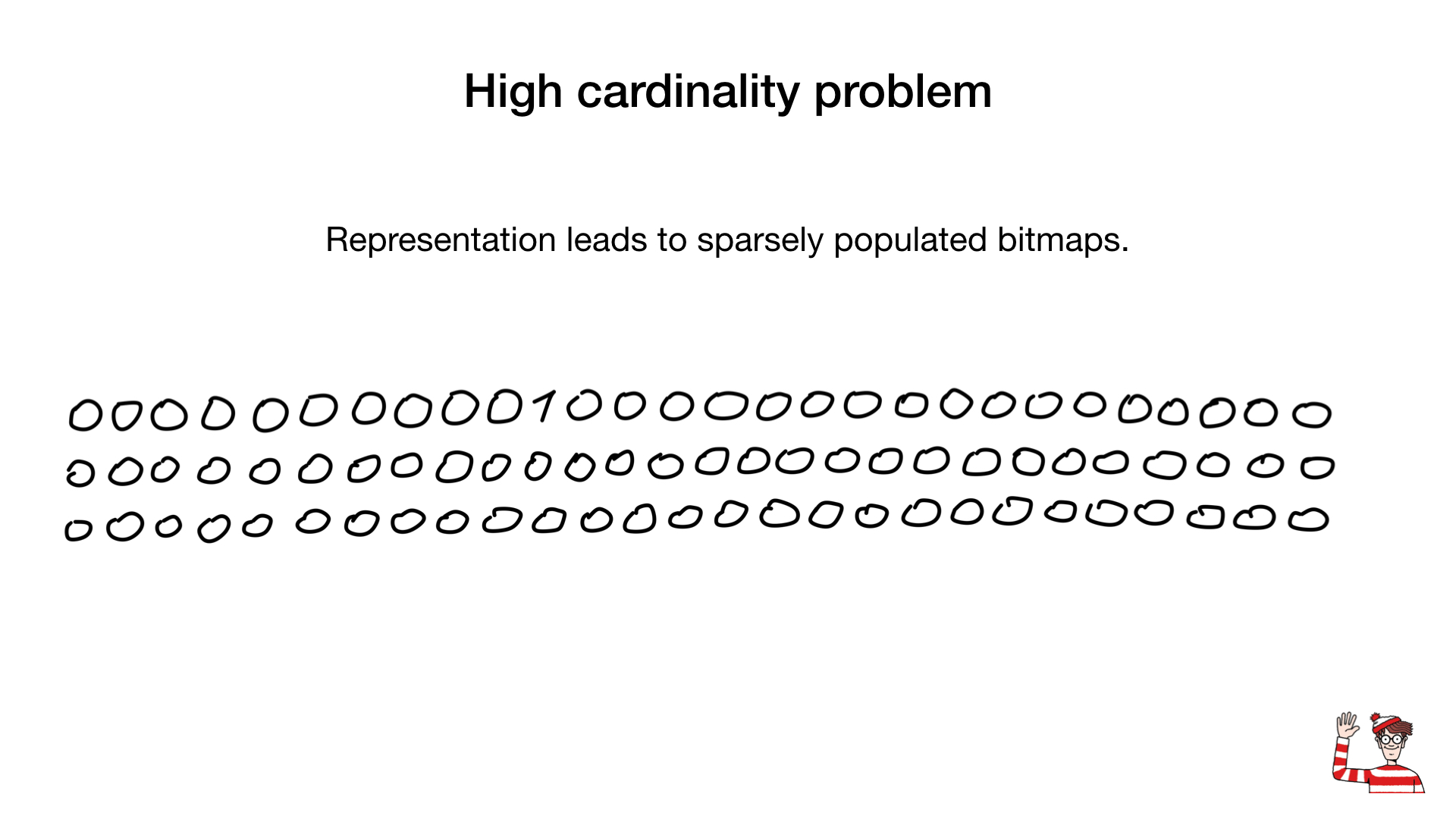
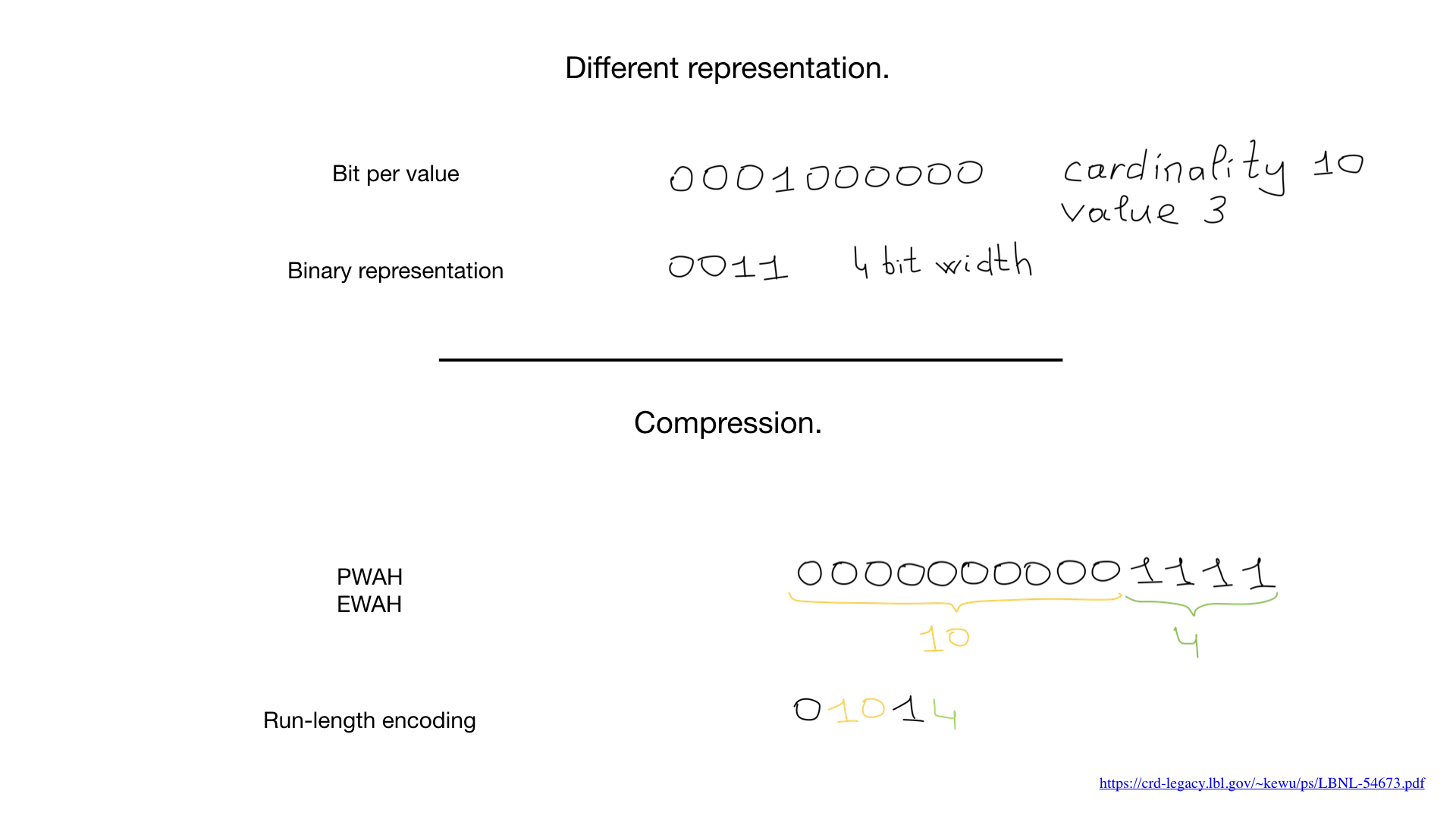 في بعض الأحيان ، يمكننا استخدام تمثيل آخر ، مثل التمثيل القياسي ، الذي نستخدمه لتمثيل الأرقام. ولكن كان ظهور خوارزميات الضغط التي غيرت كل شيء. خلال العقود الماضية ، توصل العلماء والباحثون إلى عدد كبير من خوارزميات الضغط للصور النقطية. ميزتهم الرئيسية هي أنك لا تحتاج إلى توسيع الصور النقطية لعمليات البت - يمكننا تنفيذ عمليات البت مباشرة على الصور النقطية المضغوطة.
في بعض الأحيان ، يمكننا استخدام تمثيل آخر ، مثل التمثيل القياسي ، الذي نستخدمه لتمثيل الأرقام. ولكن كان ظهور خوارزميات الضغط التي غيرت كل شيء. خلال العقود الماضية ، توصل العلماء والباحثون إلى عدد كبير من خوارزميات الضغط للصور النقطية. ميزتهم الرئيسية هي أنك لا تحتاج إلى توسيع الصور النقطية لعمليات البت - يمكننا تنفيذ عمليات البت مباشرة على الصور النقطية المضغوطة. في الآونة الأخيرة ، بدأت النهج المختلطة في الظهور ، مثل صور نقطية طافوا. يستخدمون في نفس الوقت ثلاثة عروض مختلفة للصور النقطية - في الواقع الصور النقطية والمصفوفات وما يسمى بتات التشغيل - والتوازن بينهما لزيادة الأداء وتقليل استهلاك الذاكرة.
في الآونة الأخيرة ، بدأت النهج المختلطة في الظهور ، مثل صور نقطية طافوا. يستخدمون في نفس الوقت ثلاثة عروض مختلفة للصور النقطية - في الواقع الصور النقطية والمصفوفات وما يسمى بتات التشغيل - والتوازن بينهما لزيادة الأداء وتقليل استهلاك الذاكرة.roaring . , Go.
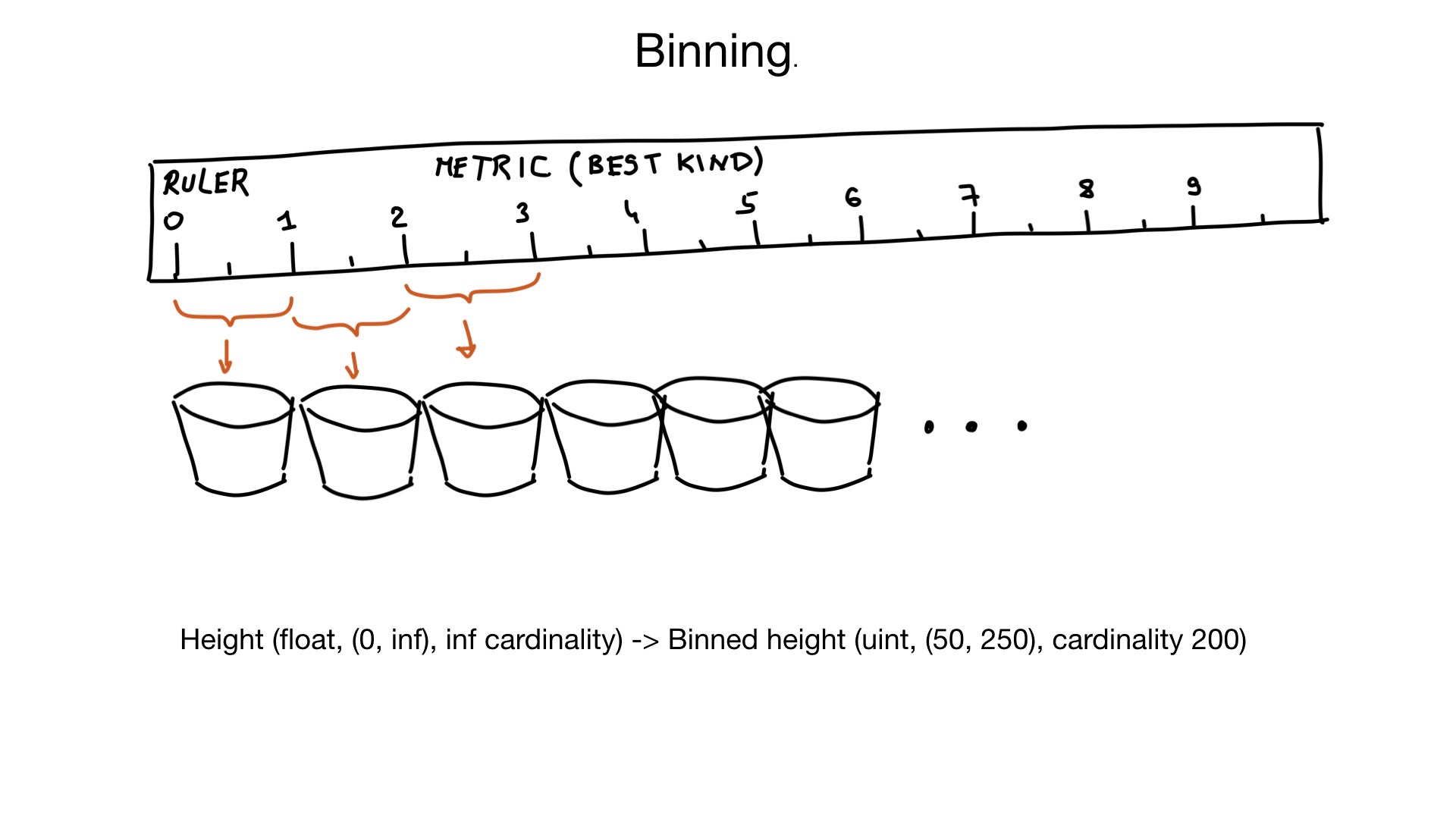
, , (binning). , , . — , , , . 185,2 185,3 .
, 1 .
, 50 250 , , , 200 .
, .
bitmap- , .
, . , . , , — lock contention, .
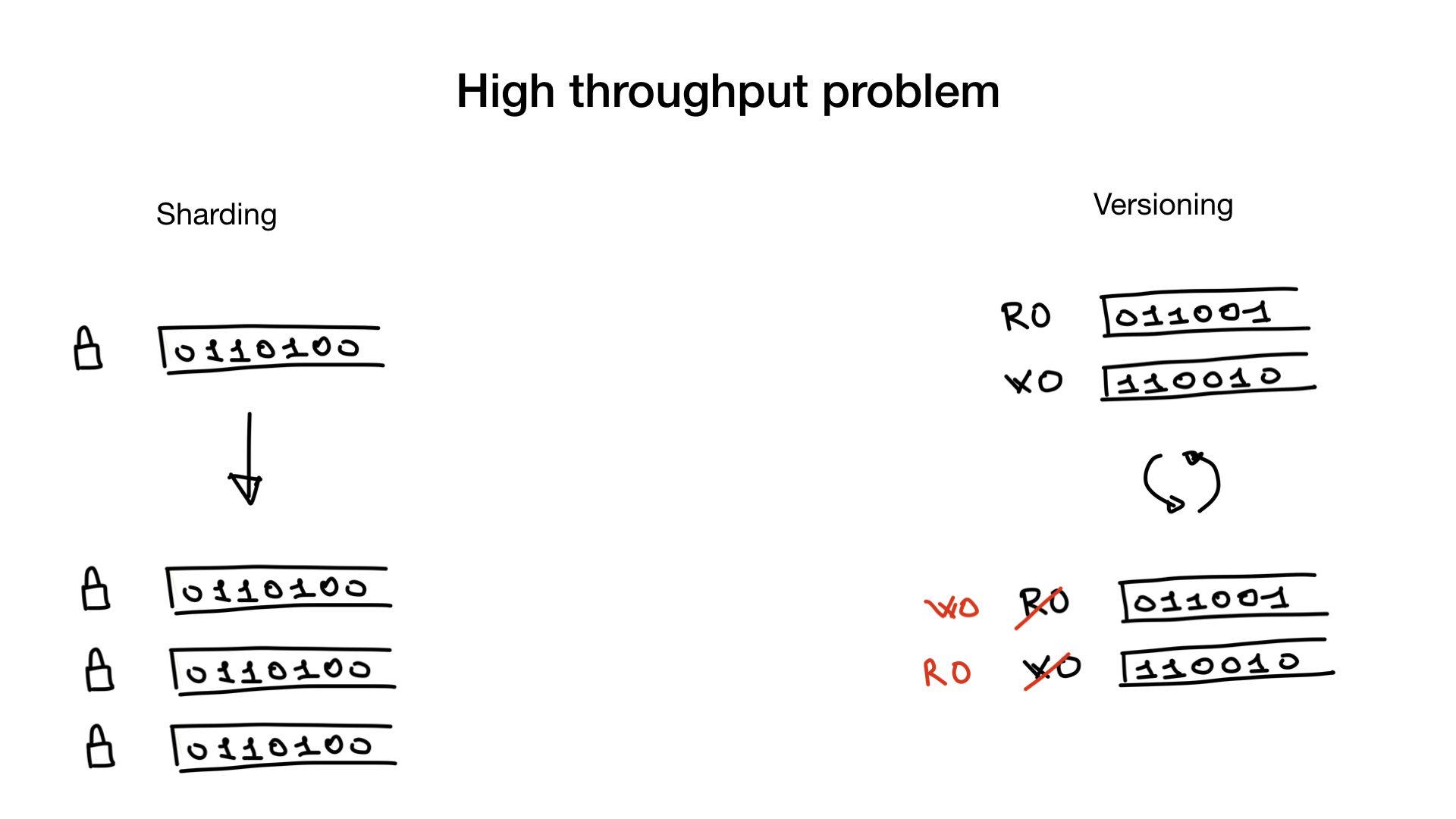
.
— . bitmap- , . lock contention.
— . , , — . - (, 100 500 ) . , , .
: .
bitmap- , , , , « ».
, , AND, OR . . - « 200 300 ».

OR.

. , 50 . 50 .
, . range-encoded bitmaps.

- (, 200), , . 200 . 300: 300 . و هكذا.
, , . , 300 , , 199 . القيام به.

, bitmap-. , , . , S2 Google. , . « » ( ).
حلول جاهزة
. - - , , .
, , bitmap- . , SIMD, .
, , .

Roaring
-, roaring bitmaps-, . , , bitmap-.
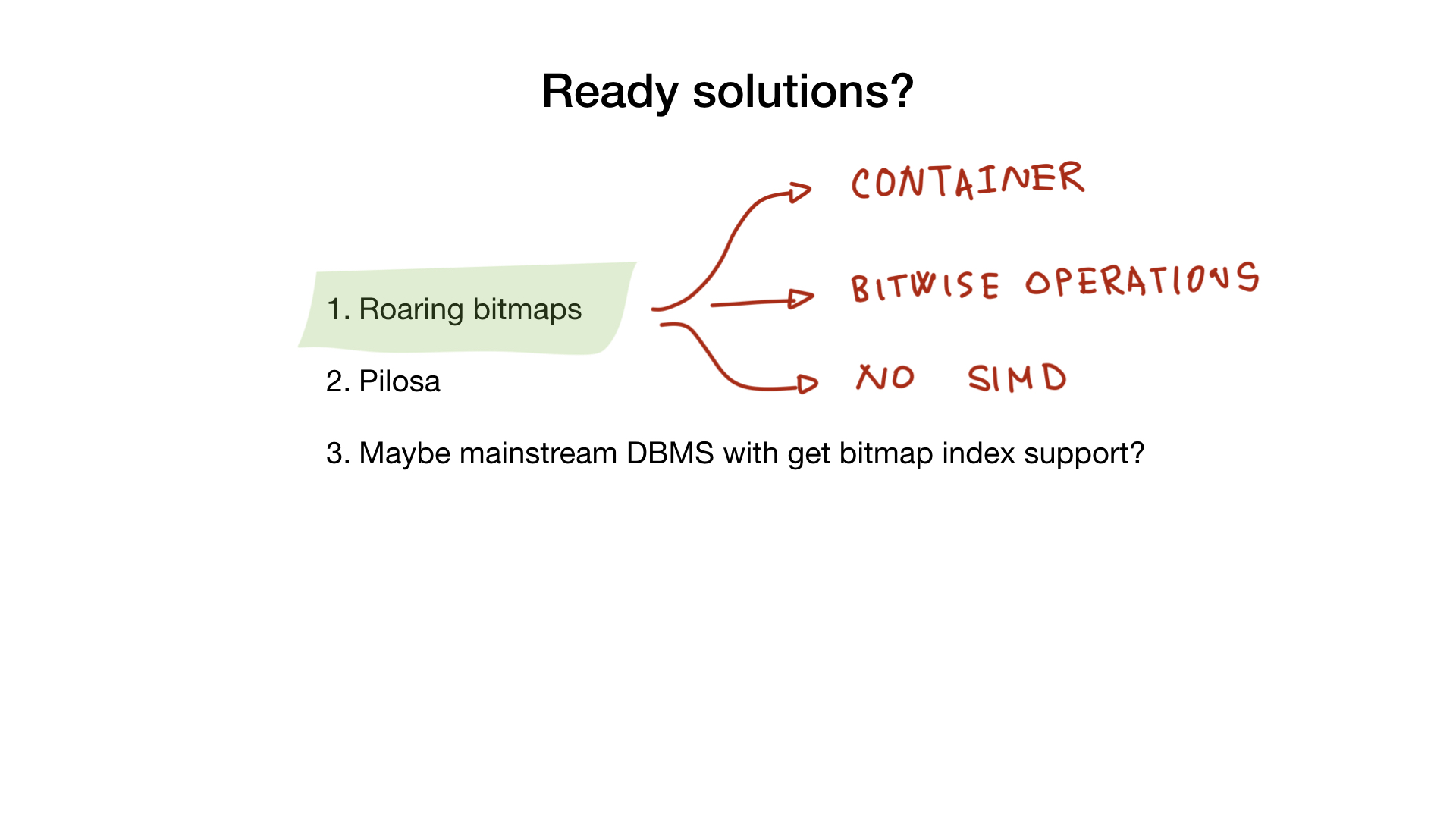
, Go- SIMD, , Go- , C, .
Pilosa
, , — Pilosa, , , bitmap- . , .
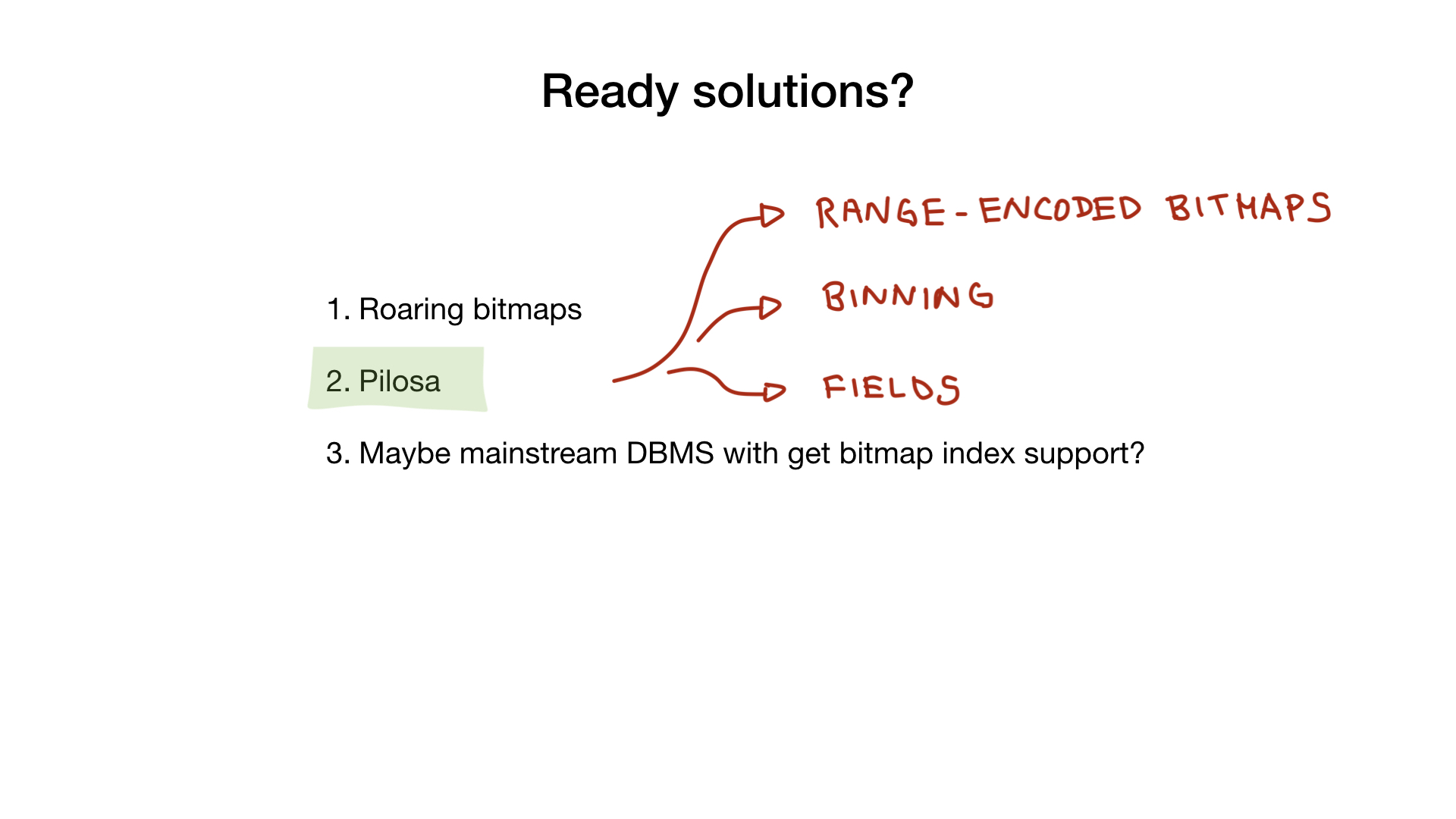
Pilosa roaring , , : , range-encoded bitmaps, . .
Pilosa .

, . Pilosa, , , , .
بعد ذلك ، نستخدم NOT في الحقل "غالي" ، ثم نتقاطع النتيجة (أو AND) مع حقل "الشرفة" وحقل "الحجوزات". وأخيرا ، نحصل على النتيجة النهائية. آمل حقًا أن يظهر هذا النوع الجديد من الفهارس في المستقبل المنظور في DBMS مثل MySQL و PostgreSQL - فهارس الصور النقطية.
آمل حقًا أن يظهر هذا النوع الجديد من الفهارس في المستقبل المنظور في DBMS مثل MySQL و PostgreSQL - فهارس الصور النقطية.
استنتاج

إذا لم تغفو بعد ، شكرًا. كان عليّ أن أتطرق إلى العديد من الموضوعات أثناء المرور بسبب ضيق الوقت ، لكنني آمل أن يكون التقرير مفيدًا ، وربما حافزًا.
من الجيد معرفة فهارس الصور النقطية ، حتى إذا لم تكن في حاجة إليها الآن. فليكن أداة أخرى في الدرج الخاص بك.
لقد قمت أنت وأنا بفحص حيل الأداء المختلفة لـ Go وتلك الأشياء التي لا يعملها برنامج التحويل البرمجي Go جيدًا حتى الآن. ولكن من المفيد للغاية أن يعرف كل مبرمج Go.
هذا هو كل ما أردت أن أقوله. شكرا لك