لقد ناقشنا بالفعل
محرك فهرسة PostgreSQL ، وواجهة طرق الوصول ، وطرق الوصول الرئيسية ، مثل:
فهارس التجزئة ، و
B- tree ، و
GiST ، و
SP-GiST ، و
GIN . في هذه المقالة ، سنراقب كيف يتحول الجن إلى رم.
رم
على الرغم من أن المؤلفين يدعون أن الجن هو جني قوي ، إلا أن فكرة المشروبات قد فازت في النهاية: أطلق على الجيل التالي من GIN اسم رم.
تعمل طريقة الوصول هذه على توسيع المفهوم الذي يقوم عليه GIN وتمكننا من إجراء البحث عن النص الكامل بشكل أسرع. في هذه السلسلة من المقالات ، هذه هي الطريقة الوحيدة التي لم يتم تضمينها في تسليم PostgreSQL القياسي وهي امتداد خارجي. تتوفر العديد من خيارات التثبيت لذلك:
- خذ حزمة "yum" أو "apt" من مستودع PGDG . على سبيل المثال ، إذا قمت بتثبيت PostgreSQL من حزمة "postgresql-10" ، فقم أيضًا بتثبيت "postgresql-10-rum".
- بناء من شفرة المصدر على جيثب وتثبيت بنفسك (التعليمات هناك أيضا).
- استخدم كجزء من Postgres Pro Enterprise (أو على الأقل قراءة الوثائق من هناك).
حدود الجن
ما هي قيود GIN التي يمكّننا RUM من تجاوزها؟
أولاً ، لا يحتوي نوع البيانات "tsvector" على معجم فقط ، بل يحتوي أيضًا على معلومات حول مواضعها داخل المستند. كما لاحظنا
في المرة الأخيرة ، لا يخزن مؤشر GIN هذه المعلومات. لهذا السبب ، فإن عمليات البحث عن العبارات ، التي ظهرت في الإصدار 9.6 ، مدعومة من قبل فهرس GIN بشكل غير فعال وعليها الوصول إلى البيانات الأصلية لإعادة الفحص.
ثانياً ، تقوم أنظمة البحث عادةً بإرجاع النتائج مرتبة حسب الصلة (مهما كان ذلك يعني). يمكننا استخدام دالات التصنيف "ts_rank" و "ts_rank_cd" لتحقيق هذه الغاية ، ولكن يجب حسابها لكل صف من النتيجة ، وهو بطيء بالتأكيد.
بالنسبة للتقريب الأول ، يمكن اعتبار طريقة الوصول إلى RUM بمثابة GIN التي تخزن بالإضافة إلى ذلك معلومات الموقع ويمكن أن تعرض النتائج بالترتيب المطلوب (مثل
GiST يمكنه إرجاع أقرب الجيران). دعنا ننتقل خطوة بخطوة.
البحث عن العبارات
يمكن أن يحتوي استعلام بحث النص الكامل على عوامل تشغيل خاصة تأخذ في الاعتبار المسافة بين lexemes. على سبيل المثال ، يمكننا العثور على المستندات التي يتم فيها فصل "اليد" عن "الفخذ" بكلمتين أخريين:
postgres=# select to_tsvector('Clap your hands, slap your thigh') @@ to_tsquery('hand <3> thigh');
?column? ---------- t (1 row)
أو يمكننا الإشارة إلى أن الكلمات يجب أن تكون واحدة تلو الأخرى:
postgres=# select to_tsvector('Clap your hands, slap your thigh') @@ to_tsquery('hand <-> slap');
?column? ---------- t (1 row)
يمكن لفهرس GIN المعتاد إرجاع المستندات التي تحتوي على كلا اللغتين ، لكن لا يمكننا التحقق من المسافة بينهما إلا من خلال البحث في tsvector:
postgres=# select to_tsvector('Clap your hands, slap your thigh');
to_tsvector -------------------------------------- 'clap':1 'hand':3 'slap':4 'thigh':6 (1 row)
في فهرس RUM ، لا يشير كل lexeme فقط إلى صفوف الجدول: يتم تزويد كل TID بقائمة المواضع التي يحدث فيها lexeme في المستند. هذه هي الطريقة التي يمكننا بها تصور الفهرس الذي تم إنشاؤه على جدول "slit-sheet" ، وهو بالفعل مألوف لدينا (يتم استخدام فئة مشغل "rum_tsvector_ops" لـ tsvector افتراضيًا):
postgres=# create extension rum; postgres=# create index on ts using rum(doc_tsv);
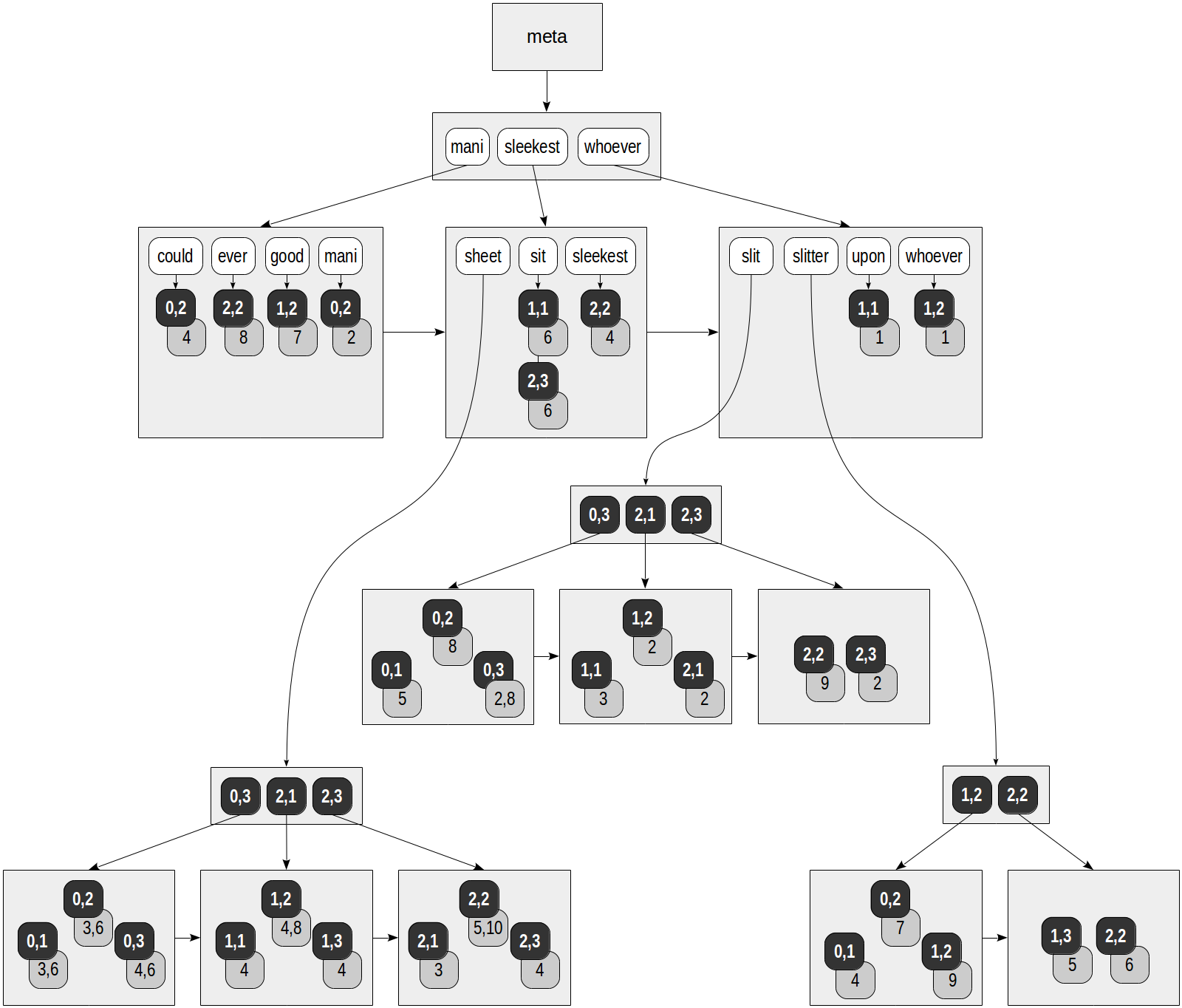
المربعات الرمادية في الشكل تحتوي على معلومات الموقع المضافة:
postgres=# select ctid, left(doc,20), doc_tsv from ts;
ctid | left | doc_tsv -------+----------------------+--------------------------------------------------------- (0,1) | Can a sheet slitter | 'sheet':3,6 'slit':5 'slitter':4 (0,2) | How many sheets coul | 'could':4 'mani':2 'sheet':3,6 'slit':8 'slitter':7 (0,3) | I slit a sheet, a sh | 'sheet':4,6 'slit':2,8 (1,1) | Upon a slitted sheet | 'sheet':4 'sit':6 'slit':3 'upon':1 (1,2) | Whoever slit the she | 'good':7 'sheet':4,8 'slit':2 'slitter':9 'whoever':1 (1,3) | I am a sheet slitter | 'sheet':4 'slitter':5 (2,1) | I slit sheets. | 'sheet':3 'slit':2 (2,2) | I am the sleekest sh | 'ever':8 'sheet':5,10 'sleekest':4 'slit':9 'slitter':6 (2,3) | She slits the sheet | 'sheet':4 'sit':6 'slit':2 (9 rows)
يوفر GIN أيضًا الإدراج المؤجل عند تحديد معلمة "fastupdate" ؛ تتم إزالة هذه الوظيفة من RUM.
لنرى كيف يعمل الفهرس على البيانات الحية ، دعنا نستخدم
الأرشيف المألوف لقائمة بريد الهاكرز pgsql.
fts=# alter table mail_messages add column tsv tsvector; fts=# set default_text_search_config = default; fts=# update mail_messages set tsv = to_tsvector(body_plain);
... UPDATE 356125
هذه هي الطريقة التي يتم بها تنفيذ استعلام يستخدم البحث عن العبارات باستخدام فهرس GIN:
fts=# create index tsv_gin on mail_messages using gin(tsv); fts=# explain (costs off, analyze) select * from mail_messages where tsv @@ to_tsquery('hello <-> hackers');
QUERY PLAN --------------------------------------------------------------------------------- Bitmap Heap Scan on mail_messages (actual time=2.490..18.088 rows=259 loops=1) Recheck Cond: (tsv @@ to_tsquery('hello <-> hackers'::text)) Rows Removed by Index Recheck: 1517 Heap Blocks: exact=1503 -> Bitmap Index Scan on tsv_gin (actual time=2.204..2.204 rows=1776 loops=1) Index Cond: (tsv @@ to_tsquery('hello <-> hackers'::text)) Planning time: 0.266 ms Execution time: 18.151 ms (8 rows)
كما نرى من الخطة ، يتم استخدام مؤشر GIN ، لكنه يُرجع 1776 من التطابقات المحتملة ، منها 259 تركت و 1517 يتم إسقاطها في مرحلة إعادة الفحص.
دعنا نحذف مؤشر GIN ونبني RUM.
fts=# drop index tsv_gin; fts=# create index tsv_rum on mail_messages using rum(tsv);
يحتوي الفهرس الآن على جميع المعلومات اللازمة ، ويتم إجراء البحث بدقة:
fts=# explain (costs off, analyze) select * from mail_messages where tsv @@ to_tsquery('hello <-> hackers');
QUERY PLAN -------------------------------------------------------------------------------- Bitmap Heap Scan on mail_messages (actual time=2.798..3.015 rows=259 loops=1) Recheck Cond: (tsv @@ to_tsquery('hello <-> hackers'::text)) Heap Blocks: exact=250 -> Bitmap Index Scan on tsv_rum (actual time=2.768..2.768 rows=259 loops=1) Index Cond: (tsv @@ to_tsquery('hello <-> hackers'::text)) Planning time: 0.245 ms Execution time: 3.053 ms (7 rows)
الترتيب حسب الصلة
لإرجاع المستندات بسهولة بالترتيب المطلوب ، يدعم فهرس RUM عوامل تشغيل الطلبية ، والتي ناقشناها في مقالة متعلقة بـ
GiST . يُعرّف امتداد RUM مثل هذا المشغل ،
<=> ، والذي يُرجع مسافة ما بين المستند ("tsvector") والاستعلام ("tsquery"). على سبيل المثال:
fts=# select to_tsvector('Can a sheet slitter slit sheets?') <=>l to_tsquery('slit');
?column? ---------- 16.4493 (1 row)
fts=# select to_tsvector('Can a sheet slitter slit sheets?') <=> to_tsquery('sheet');
?column? ---------- 13.1595 (1 row)
يبدو أن المستند أكثر صلة بالاستعلام الأول منه للاستعلام الثاني: كلما تحدثت الكلمة كثيرًا ، كلما كانت "القيمة" أقل.
دعونا نحاول مرة أخرى مقارنة GIN و RUM بحجم بيانات كبير نسبيًا: سنختار عشرة مستندات ذات صلة تحتوي على "hello" و "hackers".
fts=# explain (costs off, analyze) select * from mail_messages where tsv @@ to_tsquery('hello & hackers') order by ts_rank(tsv,to_tsquery('hello & hackers')) limit 10;
QUERY PLAN --------------------------------------------------------------------------------------------- Limit (actual time=27.076..27.078 rows=10 loops=1) -> Sort (actual time=27.075..27.076 rows=10 loops=1) Sort Key: (ts_rank(tsv, to_tsquery('hello & hackers'::text))) Sort Method: top-N heapsort Memory: 29kB -> Bitmap Heap Scan on mail_messages (actual ... rows=1776 loops=1) Recheck Cond: (tsv @@ to_tsquery('hello & hackers'::text)) Heap Blocks: exact=1503 -> Bitmap Index Scan on tsv_gin (actual ... rows=1776 loops=1) Index Cond: (tsv @@ to_tsquery('hello & hackers'::text)) Planning time: 0.276 ms Execution time: 27.121 ms (11 rows)
يُرجع مؤشر GIN 1776 من التطابقات ، والتي يتم تصنيفها كخطوة منفصلة لتحديد أفضل 10 نتائج.
باستخدام فهرس RUM ، يتم تنفيذ الاستعلام باستخدام مسح فهرس بسيط: لا يتم فحص أي مستندات إضافية ، ولا يلزم إجراء فرز منفصل:
fts=# explain (costs off, analyze) select * from mail_messages where tsv @@ to_tsquery('hello & hackers') order by tsv <=> to_tsquery('hello & hackers') limit 10;
QUERY PLAN -------------------------------------------------------------------------------------------- Limit (actual time=5.083..5.171 rows=10 loops=1) -> Index Scan using tsv_rum on mail_messages (actual ... rows=10 loops=1) Index Cond: (tsv @@ to_tsquery('hello & hackers'::text)) Order By: (tsv <=> to_tsquery('hello & hackers'::text)) Planning time: 0.244 ms Execution time: 5.207 ms (6 rows)
معلومات اضافية
يمكن بناء فهرس RUM ، وكذلك GIN ، على عدة حقول. ولكن بينما تخزن GIN lexemes من كل عمود بشكل مستقل عن تلك الموجودة في عمود آخر ، فإن RUM تمكننا من "ربط" الحقل الرئيسي ("tsvector" في هذه الحالة) بحقل إضافي. للقيام بذلك ، نحتاج إلى استخدام فئة مشغل متخصصة "rum_tsvector_addon_ops":
fts=# create index on mail_messages using rum(tsv RUM_TSVECTOR_ADDON_OPS, sent) WITH (ATTACH='sent', TO='tsv');
يمكننا استخدام هذا الفهرس لإرجاع النتائج المصنفة في الحقل الإضافي:
fts=# select id, sent, sent <=> '2017-01-01 15:00:00' from mail_messages where tsv @@ to_tsquery('hello') order by sent <=> '2017-01-01 15:00:00' limit 10;
id | sent | ?column? ---------+---------------------+---------- 2298548 | 2017-01-01 15:03:22 | 202 2298547 | 2017-01-01 14:53:13 | 407 2298545 | 2017-01-01 13:28:12 | 5508 2298554 | 2017-01-01 18:30:45 | 12645 2298530 | 2016-12-31 20:28:48 | 66672 2298587 | 2017-01-02 12:39:26 | 77966 2298588 | 2017-01-02 12:43:22 | 78202 2298597 | 2017-01-02 13:48:02 | 82082 2298606 | 2017-01-02 15:50:50 | 89450 2298628 | 2017-01-02 18:55:49 | 100549 (10 rows)
نحن هنا نبحث عن مطابقة الصفوف لتكون أقرب وقت ممكن من التاريخ المحدد ، بغض النظر في وقت سابق أو في وقت لاحق. للحصول على النتائج التي تسبق (أو تتبع) التاريخ المحدد بدقة ، نحتاج إلى استخدام
<=| (أو
|=> ) المشغل.
كما هو متوقع ، يتم تنفيذ الاستعلام فقط عن طريق مسح فهرس بسيط:
ts=# explain (costs off) select id, sent, sent <=> '2017-01-01 15:00:00' from mail_messages where tsv @@ to_tsquery('hello') order by sent <=> '2017-01-01 15:00:00' limit 10;
QUERY PLAN --------------------------------------------------------------------------------- Limit -> Index Scan using mail_messages_tsv_sent_idx on mail_messages Index Cond: (tsv @@ to_tsquery('hello'::text)) Order By: (sent <=> '2017-01-01 15:00:00'::timestamp without time zone) (4 rows)
إذا أنشأنا الفهرس بدون معلومات إضافية حول اقتران الحقل ، للاستعلام المماثل ، فسنضطر إلى فرز جميع نتائج مسح الفهرس.
بالإضافة إلى التاريخ ، يمكننا بالتأكيد إضافة حقول أنواع البيانات الأخرى إلى فهرس RUM. تقريبا جميع أنواع القواعد مدعومة. على سبيل المثال ، يمكن لمتجر على الإنترنت عرض البضائع بسرعة حسب الجدة (التاريخ) ، والسعر (رقمي) ، وشعبية أو قيمة الخصم (عدد صحيح أو نقطة عائمة).
فئات المشغلين الأخرى
لإكمال الصورة ، ينبغي أن نذكر فئات المشغلين الأخرى المتاحة.
لنبدأ بـ
"rum_tsvector_hash_ops" و
"rum_tsvector_hash_addon_ops" . إنها تشبه "rum_tsvector_ops" الذي تمت مناقشته بالفعل و "rum_tsvector_addon_ops" ، لكن الفهرس يخزن رمز شفرة lexeme بدلاً من lexeme نفسه. يمكن أن يقلل هذا حجم الفهرس ، ولكن بالطبع ، يصبح البحث أقل دقة ويتطلب إعادة الفحص. إلى جانب ذلك ، لم يعد الفهرس يدعم البحث عن التطابق الجزئي.
من المثير للاهتمام أن ننظر إلى فئة مشغل
"rum_tsquery_ops" . إنها تمكننا من حل مشكلة "معكوسة": العثور على استعلامات تطابق المستند. لماذا يمكن أن تكون هناك حاجة لهذا؟ على سبيل المثال ، لاشتراك المستخدم في سلع جديدة وفقًا لمرشحه أو لتصنيف المستندات الجديدة تلقائيًا. انظر إلى هذا المثال البسيط:
fts=# create table categories(query tsquery, category text); fts=# insert into categories values (to_tsquery('vacuum | autovacuum | freeze'), 'vacuum'), (to_tsquery('xmin | xmax | snapshot | isolation'), 'mvcc'), (to_tsquery('wal | (write & ahead & log) | durability'), 'wal'); fts=# create index on categories using rum(query); fts=# select array_agg(category) from categories where to_tsvector( 'Hello hackers, the attached patch greatly improves performance of tuple freezing and also reduces size of generated write-ahead logs.' ) @@ query;
array_agg -------------- {vacuum,wal} (1 row)
تم تصميم فئات المشغلين المتبقية
"rum_anyarray_ops" و
"rum_anyarray_addon_ops" لمعالجة المصفوفات بدلاً من "tsvector". نوقش هذا بالفعل من أجل GIN
في المرة الأخيرة ولا يحتاج إلى تكرار.
أحجام الفهرس وسجل الكتابة (WAL)
من الواضح أنه نظرًا لأن RUM يخزن معلومات أكثر من GIN ، فيجب أن يكون حجمه أكبر. كنا نقارن أحجام الفهارس المختلفة في المرة الأخيرة. دعنا نضيف RUM إلى هذا الجدول:
rum | gin | gist | btree --------+--------+--------+-------- 457 MB | 179 MB | 125 MB | 546 MB
كما نرى ، نما الحجم بشكل كبير ، وهو ما يمثل تكلفة البحث السريع.
يجدر الانتباه إلى نقطة أخرى غير واضحة: RUM عبارة عن امتداد ، أي أنه يمكن تثبيته دون أي تعديلات على جوهر النظام. تم تمكين هذا في الإصدار 9.6 بفضل تصحيح
ألكسندر كوروتكوف . واحدة من المشاكل التي كان لا بد من حلها لهذه الغاية هو إنشاء سجلات السجل. يجب أن تكون تقنية تسجيل العمليات موثوقة تمامًا ، وبالتالي ، لا يمكن ترك امتداد لهذا المطبخ. بدلاً من السماح للامتداد بإنشاء أنواع سجلات السجل الخاصة به ، يتم تنفيذ ما يلي: رمز الامتداد يبلغ عن عزمه على تعديل الصفحة وإجراء أي تغييرات عليها والإشارات إلى الإكمال وهي جوهر النظام ، الذي يقارن الإصدارات القديمة والجديدة من الصفحة ويولد سجلات سجل موحدة مطلوبة.
تقوم خوارزمية إنشاء السجل الحالية بمقارنة بايتات البايت ، والكشف عن الأجزاء المحدّثة ، وتسجيل كل من هذه الأجزاء ، مع إزاحتها من بداية الصفحة. هذا يعمل بشكل جيد عند تحديث عدة بايت فقط أو الصفحة بأكملها. ولكن إذا أضفنا جزءًا من الصفحة ، ونقل باقي المحتوى لأسفل (أو العكس ، أزل جزءًا ، ونقل المحتوى لأعلى) ، فسيتغير عدد البايتات بشكل ملحوظ أكثر مما تمت إضافته أو إزالته بالفعل.
لهذا السبب ، قد يؤدي تغيير فهرس RUM بشكل مكثف إلى إنشاء سجلات سجل ذات حجم أكبر بكثير من GIN (والتي ، كونها ليست امتدادًا ، ولكن جزءًا من الأساس ، تدير السجل من تلقاء نفسه). يعتمد مدى هذا التأثير المزعج إلى حد كبير على عبء العمل الفعلي ، ولكن للحصول على نظرة ثاقبة لهذه المشكلة ، دعونا نحاول إزالة وإضافة عدد من الصفوف عدة مرات ، تشابك هذه العمليات مع "فراغ". يمكننا تقييم حجم سجلات السجل على النحو التالي: في البداية والنهاية ، تذكر الموضع في السجل باستخدام وظيفة "pg_current_wal_location" ("pg_current_xlog_location" في الإصدارات الأقدم من عشرة) ثم انظر الفرق.
ولكن بالطبع ، يجب علينا النظر في الكثير من الجوانب هنا. نحتاج إلى التأكد من أن مستخدمًا واحدًا فقط يعمل مع النظام (وإلا ، سيتم أخذ السجلات "الإضافية" في الاعتبار). حتى إذا كان الأمر كذلك ، فنحن نأخذ في الاعتبار ليس فقط RUM ، ولكن أيضًا تحديثات الجدول نفسه والفهرس الذي يدعم المفتاح الأساسي. تؤثر قيم معلمات التكوين أيضًا على الحجم (تم استخدام مستوى السجل "المتماثلة" ، دون ضغط ، هنا). ولكن دعونا نحاول على أي حال.
fts=# select pg_current_wal_location() as start_lsn \gset
fts=# insert into mail_messages(parent_id, sent, subject, author, body_plain, tsv) select parent_id, sent, subject, author, body_plain, tsv from mail_messages where id % 100 = 0;
INSERT 0 3576
fts=# delete from mail_messages where id % 100 = 99;
DELETE 3590
fts=# vacuum mail_messages;
fts=# insert into mail_messages(parent_id, sent, subject, author, body_plain, tsv) select parent_id, sent, subject, author, body_plain, tsv from mail_messages where id % 100 = 1;
INSERT 0 3605
fts=# delete from mail_messages where id % 100 = 98;
DELETE 3637
fts=# vacuum mail_messages;
fts=# insert into mail_messages(parent_id, sent, subject, author, body_plain, tsv) select parent_id, sent, subject, author, body_plain, tsv from mail_messages where id % 100 = 2;
INSERT 0 3625
fts=# delete from mail_messages where id % 100 = 97;
DELETE 3668
fts=# vacuum mail_messages;
fts=# select pg_current_wal_location() as end_lsn \gset fts=# select pg_size_pretty(:'end_lsn'::pg_lsn - :'start_lsn'::pg_lsn);
pg_size_pretty ---------------- 3114 MB (1 row)
لذلك ، نحصل على حوالي 3 غيغابايت. ولكن إذا كررنا نفس التجربة مع فهرس GIN ، فإن هذا لن يؤدي إلا إلى حوالي 700 ميجابايت.
لذلك ، من المستحسن أن يكون لديك خوارزمية مختلفة ، والتي سوف تجد الحد الأدنى من عمليات الإدراج والحذف التي يمكن أن تحول حالة الصفحة إلى أخرى. تعمل الأداة المساعدة "Diff" بطريقة مماثلة. لقد نفذ
أوليغ إيفانوف بالفعل مثل هذه الخوارزمية ، وتجري مناقشة تصحيحه. في المثال أعلاه ، يتيح لنا هذا التصحيح تقليل حجم سجلات السجل بمقدار 1.5 مرة ، إلى 1900 ميجابايت ، على حساب تباطؤ بسيط.
لسوء الحظ ، تم تعليق التصحيح ولم يكن هناك أي نشاط حوله.
خصائص
كالعادة ، دعونا نلقي نظرة على خصائص طريقة الوصول إلى RUM ، مع الانتباه إلى الاختلافات من GIN (
تم تقديم الاستعلامات
بالفعل ).
فيما يلي خصائص طريقة الوصول:
amname | name | pg_indexam_has_property --------+---------------+------------------------- rum | can_order | f rum | can_unique | f rum | can_multi_col | t rum | can_exclude | t -- f for gin
تتوفر خصائص طبقة الفهرس التالية:
name | pg_index_has_property ---------------+----------------------- clusterable | f index_scan | t -- f for gin bitmap_scan | t backward_scan | f
لاحظ أنه ، على عكس GIN ، يدعم RUM فحص الفهرس - وإلا ، فلن يكون من الممكن إرجاع العدد المطلوب من النتائج في الاستعلامات مع جملة "الحد" بالضبط. ليست هناك حاجة لنظير المعلمة "gin_fuzzy_search_limit" وفقًا لذلك. ونتيجة لذلك ، يمكن استخدام الفهرس لدعم قيود الاستبعاد.
فيما يلي خصائص طبقة العمود:
name | pg_index_column_has_property --------------------+------------------------------ asc | f desc | f nulls_first | f nulls_last | f orderable | f distance_orderable | t -- f for gin returnable | f search_array | f search_nulls | f
الفرق هنا هو أن RUM يدعم مشغلي الطلبات. ومع ذلك ، لا ينطبق ذلك على جميع فئات المشغلين: على سبيل المثال ، هذا غير صحيح لـ "tsquery_ops".
اقرأ على .