كل يوم ، يعمل عشرات الآلاف من الموظفين من عدة آلاف من المنظمات حول العالم في Pyrus. نحن نعتبر استجابة الخدمة (سرعة معالجة الطلبات) ميزة تنافسية مهمة ، لأنها تؤثر بشكل مباشر على تجربة المستخدم. المقياس الرئيسي بالنسبة لنا هو "النسبة المئوية للاستعلامات البطيئة". عند دراسة سلوكها ، لاحظنا أنه بمجرد توقف دقيقة واحدة على خوادم التطبيقات ، يكون هناك حوالي 1000 مللي ثانية. في هذه الفواصل الزمنية ، لا يستجيب الخادم وينشأ قائمة انتظار من عشرات الطلبات. ستتم مناقشة البحث عن أسباب وإزالة الاختناقات الناتجة عن تجميع البيانات المهملة في التطبيق في هذه المقالة.

لغات البرمجة الحديثة يمكن تقسيمها إلى مجموعتين. في لغات مثل C / C ++ أو Rust ، يتم استخدام الإدارة اليدوية للذاكرة ، لذلك يقضي المبرمجون وقتًا أطول في كتابة التعليمات البرمجية ، وإدارة عمر الكائنات ، ثم تصحيح الأخطاء. في الوقت نفسه ، تعتبر الأخطاء الناتجة عن الاستخدام غير الصحيح للذاكرة من أكثر الأمور صعوبة في تصحيح الأخطاء ، لذلك يتم إجراء معظم التطويرات الحديثة بلغات مع الإدارة التلقائية للذاكرة. وتشمل هذه ، على سبيل المثال ، Java ، C # ، Python ، Ruby ، Go ، PHP ، JavaScript ، إلخ. يوفر المبرمجون وقت التطوير ، ولكن يتعين عليك دفع وقت التنفيذ الإضافي الذي يقضيه البرنامج بانتظام على جمع البيانات المهملة - مما يؤدي إلى تحرير الذاكرة التي تشغلها الكائنات التي لا توجد بها روابط متبقية في البرنامج. في البرامج الصغيرة ، تكون هذه المرة ضئيلة ، ولكن مع زيادة عدد الكائنات وكثافة إنشائها ، تبدأ مجموعة البيانات المهملة في تقديم مساهمة ملحوظة في إجمالي وقت تنفيذ البرنامج.
تعمل خوادم الويب Pyrus على النظام الأساسي .NET ، والذي يستخدم الإدارة التلقائية للذاكرة. معظم مجموعات القمامة هي "أوقفوا العالم" ، أي في وقت عملهم ، توقفوا عن جميع خيوط التطبيق. تقوم التجميعات غير المحظورة (الخلفية) بإيقاف جميع مؤشرات الترابط فعليًا ، ولكن لفترة قصيرة جدًا من الوقت. أثناء حظر سلاسل الرسائل ، لا يقوم الخادم بمعالجة الطلبات ، وتجميد الطلبات الحالية ، وتضاف طلبات جديدة إلى قائمة الانتظار. نتيجة لذلك ، يتم إبطاء الطلبات التي تمت معالجتها في وقت تجميع البيانات المهملة مباشرةً ، وتتم معالجة الطلبات بشكل أبطأ فور الانتهاء من تجميع البيانات المهملة بسبب قوائم الانتظار المتراكمة. هذا يزيد من سوء "النسبة المئوية للاستعلامات البطيئة".
مسلحين بالكتاب المنشور حديثًا
Konrad Kokosa: Pro .NET Memory Management (حول كيفية إحضار نسخته الأولى إلى روسيا في غضون يومين ، يمكنك كتابة منشور منفصل) ، مخصص بالكامل لموضوع إدارة الذاكرة في .NET ، بدأنا في دراسة المشكلة.
قياس
لوضع ملف تعريف على خادم الويب Pyrus ، استخدمنا الأداة PerfView (
https://github.com/Microsoft/perfview ) ، التي تم توضيحها لتوصيف تطبيقات .NET. تعتمد الأداة المساعدة على مشغل Event Tracing for Windows (ETW) ولها تأثير ضئيل على أداء التطبيق المُمَكّن ، والذي يسمح باستخدامه على خادم قتالي. بالإضافة إلى ذلك ، يعتمد التأثير على الأداء على أنواع الأحداث والمعلومات التي نجمعها. نحن لا نجمع أي شيء - يعمل التطبيق كالمعتاد. أيضا ، لا يتطلب PerfView إما إعادة ترجمة أو إعادة تشغيل التطبيق.
تشغيل تتبع PerfView مع / GCCollectOnly المعلمة (وقت التتبع 1.5 ساعة). في هذا الوضع ، يقوم فقط بجمع أحداث تجميع البيانات المهملة وله تأثير ضئيل على الأداء. دعونا نلقي نظرة على تقرير التتبع لـ Memory Group / GCStats ، وفيه ملخص لأحداث أداة تجميع مجمعي البيانات المهملة:
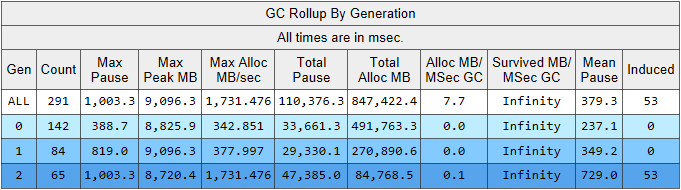
هنا نرى العديد من المؤشرات المثيرة للاهتمام في وقت واحد:
- متوسط وقت الإيقاف المؤقت للبناء في الجيل الثاني هو 700 مللي ثانية ، والحد الأقصى للإيقاف المؤقت حوالي ثانية. يوضح هذا الرقم الوقت الذي تتوقف عنده كافة مؤشرات الترابط في تطبيق .NET ، على وجه الخصوص ، ستتم إضافة هذا التوقف المؤقت لجميع الطلبات التي تمت معالجتها.
- عدد التجميعات من الجيل الثاني يمكن مقارنته بالجيل الأول وأقل قليلاً من عدد التجميعات من الجيل 0.
- يسرد العمود المستحث 53 مجموعة في الجيل الثاني. التجميع المستحث هو نتيجة لاستدعاء صريح إلى GC.Collect (). في التعليمات البرمجية الخاصة بنا ، لم نعثر على دعوة واحدة لهذه الطريقة ، مما يعني أن بعض المكتبات المستخدمة من قبل التطبيق لدينا هي المسؤولة.
دعنا نوضح الملاحظة حول عدد مجموعات القمامة. تعتمد فكرة تقسيم الكائنات على حياتها على
فرضية الأجيال : جزء كبير من الكائنات التي تم إنشاؤها يموت بسرعة ، ومعظم الكائنات الأخرى تعيش طويلاً (بمعنى آخر ، كائنات قليلة لها عمر "متوسط"). تحت هذا الوضع يتم سجن أداة تجميع مجمعي البيانات المهملة .NET ، وفي هذا الوضع يجب أن تكون تجميعات الجيل الثاني أصغر بكثير من الجيل 0. وهذا هو ، من أجل التشغيل الأمثل لجامع القمامة ، يجب علينا تكييف عمل تطبيقنا مع فرضية الأجيال. دعونا نصوغ القاعدة على النحو التالي: يجب أن تموت الأشياء إما بسرعة ، دون أن تبقى على قيد الحياة إلى الجيل الأكبر سناً ، أو أن تعيش فيها وتعيش فيها إلى الأبد. تنطبق هذه القاعدة أيضًا على الأنظمة الأساسية الأخرى التي تستخدم الإدارة التلقائية للذاكرة مع الفصل بين الأجيال ، مثل Java.
يمكن استخراج البيانات التي تهمنا من جدول آخر في تقرير GCStats:

فيما يلي بعض الحالات التي يحاول فيها أحد التطبيقات إنشاء كائن كبير (في كائنات .NET Framework> يتم إنشاء 85000 بايت في الحجم في LOH - Large Object Heap) ، ويتعين عليه انتظار اكتمال تجميع الجيل الثاني ، والذي يحدث بالتوازي في الخلفية. هذه الإيقاف المؤقت للمخصص ليست مهمة مثل الإيقاف المؤقت لمجمع البيانات المهملة ، لأنها تؤثر على مؤشر ترابط واحد فقط. قبل ذلك ، استخدمنا إصدار .NET Framework 4.6.1 ، وفي الإصدار 4.7.1 وضعت Microsoft اللمسات الأخيرة على أداة تجميع مجمعي البيانات المهملة ، حيث تسمح لك الآن بتخصيص ذاكرة في Large Object Heap أثناء إنشاء خلفية الجيل الثاني:
https://docs.microsoft.com / ru-ru / dotnet / framework / whats-new / # common-language-runtime-clrلذلك ، قمنا بالترقية إلى أحدث إصدار 4.7.2 في ذلك الوقت.
الجيل الثاني يبني
لماذا لدينا الكثير من بنيات الجيل القديم؟ الافتراض الأول هو أن لدينا تسرب للذاكرة. لاختبار هذه الفرضية ، دعونا نلقي نظرة على حجم الجيل الثاني (أنشأنا مراقبة عدادات الأداء المقابلة في Zabbix). من الرسوم البيانية لحجم الجيل الثاني لخادمي Pyrus ، يمكن ملاحظة أن حجمه ينمو أولاً (ويرجع ذلك أساسًا إلى ملء ذاكرات التخزين المؤقت) ، ولكن بعد ذلك يستقر (الإخفاقات الكبيرة في الرسم البياني - إعادة التشغيل المنتظمة لخدمة الويب لتحديث الإصدار):
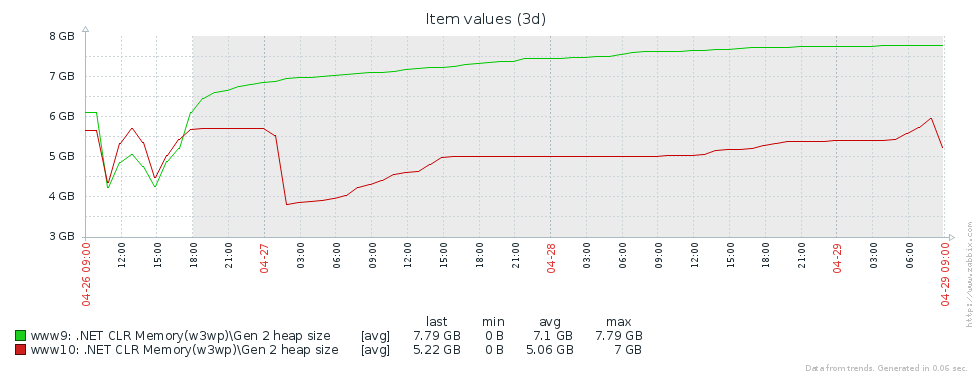
هذا يعني أنه لا توجد أي تسربات ملحوظة في الذاكرة ، أي أن عددًا كبيرًا من تجميعات الجيل الثاني تحدث لسبب آخر. الفرضية التالية هي أن هناك الكثير من حركة الذاكرة ، أي أن العديد من الكائنات تقع في الجيل الثاني ، وتموت العديد من الكائنات هناك. يحتوي PerfView على وضع / GCOnly للعثور على مثل هذه الكائنات. من تقارير التتبع ، دعنا ننتبه إلى مكدسات الوفيات الناتجة عن الكائنات 2 (خشن العينات) التي تحتوي على مجموعة مختارة من الكائنات التي تموت في الجيل الثاني ، جنبًا إلى جنب مع مكدسات استدعاء الأماكن التي تم إنشاء هذه الكائنات فيها. هنا نرى النتائج التالية:
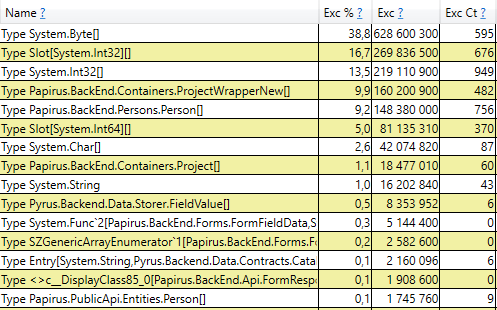
بعد فتح الخط ، نرى في الداخل مجموعة مكالمات من تلك الأماكن في الشفرة التي تنشئ كائنات ترقى إلى الجيل الثاني. من بينها:
- System.Byte [] إذا نظرت إلى الداخل ، فسنرى أن أكثر من نصفها عبارة عن مخازن مؤقتة للتسلسل في JSON:
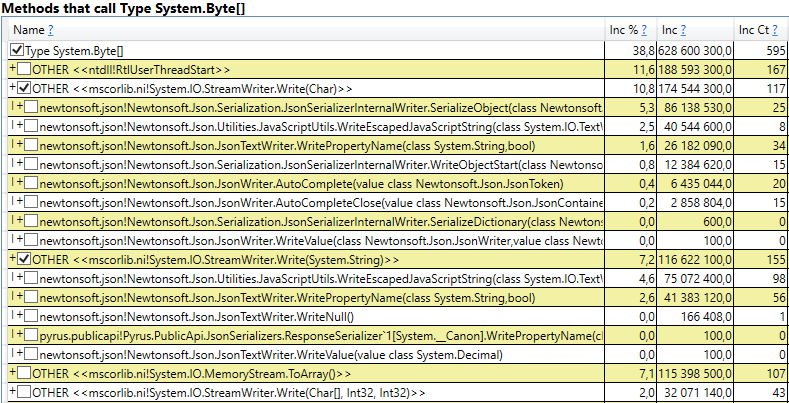
- الفتحة [System.Int32] [] (هذا جزء من تطبيق HashSet) ، System.Int32 [] ، إلخ. هذا هو رمزنا الذي يحسب ذاكرات التخزين المؤقت للعميل - تلك الدلائل والنماذج والقوائم والأصدقاء وما إلى ذلك التي يراها هذا المستخدم والتي يتم تخزينها مؤقتًا في متصفحه أو تطبيقه المحمول:

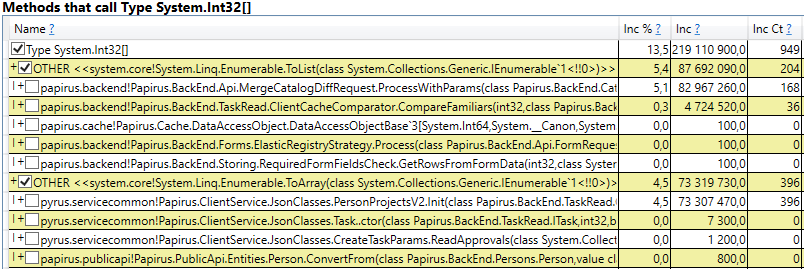
ومن المثير للاهتمام أن المخازن المؤقتة لـ JSON ولحساب ذاكرة التخزين المؤقت للعميل كلها كائنات مؤقتة تعيش على نفس الطلب. لماذا ترقى إلى الجيل الثاني؟ لاحظ أن كل هذه الكائنات عبارة عن صفائف بحجم كبير إلى حد ما. وفي حجم> 85000 بايت ، يتم تخصيص الذاكرة الخاصة بهم في كومة كائن كبيرة ، والتي يتم جمعها فقط مع الجيل الثاني.
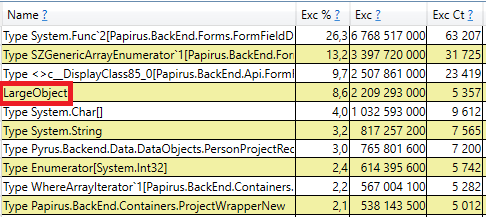
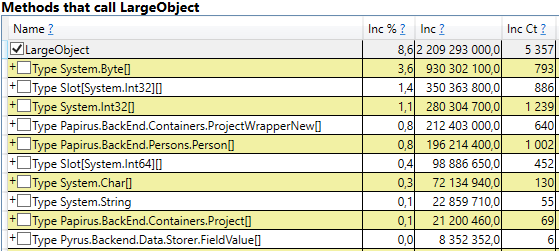
للتحقق ، افتح قسم "GC Heap Alloc Ignore Free (Coarse Sampling)" في نتائج العرض / نتائج GCOnly. هناك نرى السطر LargeObject ، حيث يقوم PerfView بتجميع إنشاء كائنات كبيرة ، وداخلنا نرى جميع الصفائف نفسها التي رأيناها في التحليل السابق. نحن ندرك السبب الجذري للمشاكل مع جامع البيانات المهملة: نقوم بإنشاء العديد من الكائنات الكبيرة المؤقتة.
التغييرات في نظام Pyrus
استنادًا إلى نتائج القياس ، حددنا المجالات الرئيسية لمزيد من العمل: مكافحة الأشياء الكبيرة عند حساب ذاكرة التخزين المؤقت للعميل والتسلسل في JSON. هناك العديد من الحلول لهذه المشكلة:
- أبسط شيء هو عدم إنشاء كائنات كبيرة. على سبيل المثال ، إذا تم استخدام مخزن مؤقت كبير B في تحويلات البيانات المتسلسلة A-> B-> C ، في بعض الأحيان يمكن دمج هذه التحولات عن طريق تحويلها إلى A-> C ، والتخلص من إنشاء كائن B. هذا الخيار غير قابل للتطبيق دائمًا ، لكنه أبسط وأكثر فعالية.
- مجموعة من الأشياء. بدلاً من إنشاء كائنات جديدة باستمرار ورميها بعيدًا ، وتحميل أداة تجميع مجمعي البيانات المهملة ، يمكننا تخزين مجموعة من الكائنات المجانية. في أبسط الحالات ، عندما نحتاج إلى كائن جديد ، فإننا نأخذه من التجمع ، أو ننشئ كائنًا جديدًا إذا كان التجمع فارغًا. عندما لا نحتاج إلى الكائن ، نعيده إلى التجمع. مثال جيد على ذلك هو ArrayPool في .NET Core ، والذي يتوفر أيضًا في .NET Framework كجزء من حزمة System.Buffers Nuget.
- استخدم أشياء صغيرة بدلاً من الأشياء الكبيرة.
دعنا نفكر بشكل منفصل في كلتا الحالتين للأشياء الكبيرة - تخزين ذاكرة التخزين المؤقت للعميل والتسلسل في JSON.
حساب ذاكرة التخزين المؤقت للعميل
يقوم عميل الويب Pyrus وتطبيقات الهاتف المحمول بتخزين البيانات المتاحة للمستخدم (المشاريع ، النماذج ، المستخدمين ، إلخ.) يتم استخدام التخزين المؤقت لتسريع العمل ، كما أنه ضروري للعمل في وضع عدم الاتصال. يتم حساب التخزين المؤقت على الخادم ونقله إلى العميل. إنهم فرديون لكل مستخدم ، حيث يعتمدون على حقوق الوصول الخاصة بهم ، ويتم تحديثهم غالبًا ، على سبيل المثال ، عند تغيير الأدلة التي لديه حق الوصول إليها.
وبالتالي ، يتم إجراء الكثير من حسابات التخزين المؤقت للعميل بشكل منتظم على الخادم ، ويتم إنشاء العديد من الكائنات المؤقتة قصيرة العمر. إذا كان المستخدم منظمة كبيرة ، فيمكنه الوصول إلى العديد من الكائنات ، على التوالي ، ستكون ذاكرة التخزين المؤقت للعميل كبيرة. هذا هو السبب في أننا رأينا تخصيص الذاكرة للصفائف المؤقتة الكبيرة في كومة الكائنات الكبيرة.
دعونا نحلل الخيارات المقترحة للتخلص من إنشاء كائنات كبيرة:
- التخلص الكامل من الأشياء الكبيرة. هذا النهج غير قابل للتطبيق ، نظرًا لأن خوارزميات إعداد البيانات تستخدم ، من بين أشياء أخرى ، الفرز وتوحيد المجموعات ، وتتطلب مخازن مؤقتة.
- باستخدام مجموعة من الأشياء. هذا النهج لديه صعوبات:
- مجموعة متنوعة من المجموعات المستخدمة وأنواع العناصر فيها: HashSet ، List و Array تستخدم (يمكن الجمع بين الأخير 2). يتم تخزين Int32 و Int64 ، وكذلك جميع أنواع فئات البيانات في مجموعات. لكل نوع مستخدم ، ستحتاج إلى مجموعة خاصة بك ، والتي ستقوم أيضًا بتخزين مجموعات من مختلف الأحجام.
- وقت الحياة الصعب للمجموعات. للحصول على فوائد من المجموعة ، يجب إعادة الكائنات الموجودة فيها بعد الاستخدام. يمكن القيام بذلك إذا تم استخدام الكائن في طريقة واحدة. ولكن في حالتنا ، يكون الموقف أكثر تعقيدًا ، نظرًا لأن العديد من الكائنات الكبيرة تنتقل بين الطرق ، يتم وضعها في هياكل البيانات ، ويتم نقلها إلى هياكل أخرى ، إلخ.
- تحقيق. هناك ArrayPool من Microsoft ، لكننا ما زلنا بحاجة إلى قائمة و HashSet. لم نجد أي مكتبة مناسبة ، لذلك سيتعين علينا تنفيذ الفصول بأنفسنا.
- استخدام الأشياء الصغيرة. يمكن تقسيم صفيف كبير إلى عدة قطع صغيرة ، لن أقوم بتحميل كومة كائن كبير ، ولكن سيتم إنشاؤها في الجيل 0 ، ثم انتقل على طول المسار القياسي في الأول والثاني. نأمل ألا يرتقوا إلى المستوى الثاني ، ولكن سيتم تجميعهم بواسطة جامع البيانات المهملة في 0 ، أو في الحالات القصوى في الجيل الأول. ميزة هذا النهج هي أن التغييرات على التعليمات البرمجية الموجودة ضئيلة. الصعوبة:
- تحقيق. لم نجد أي مكتبات مناسبة ، لذلك يتعين علينا كتابة الفصول بأنفسنا. نقص المكتبات أمر مفهوم ، نظرًا لأن السيناريو "المجموعات التي لا تُحمّل كومة الكائنات الكبيرة" هو نطاق ضيق جدًا.
قررنا أن نسير على الطريق الثالث ونخترع دراجتنا لكتابة قائمة و HashSet ، وليس تحميل كومة الكائنات الكبيرة.
قائمة قطعة
يقوم ChunkedList <T> بتنفيذ واجهات قياسية ، بما في ذلك IList <T> ، والتي تتطلب الحد الأدنى من التغييرات على الكود الموجود. نعم ، ومكتبة Newtonsoft.Json التي نستخدمها قادرة تلقائيًا على إجراء تسلسل لها ، حيث إنها تقوم بتنفيذ IEnumerable <T>:
public sealed class ChunkedList<T> : IList<T>, ICollection<T>, IEnumerable<T>, IEnumerable, IList, ICollection, IReadOnlyList<T>, IReadOnlyCollection<T> {
تحتوي القائمة القياسية <T> على الحقول التالية: صفيف للعناصر وعدد العناصر المعبأة. في ChunkedList <T> هناك مجموعة من صفائف العناصر ، وعدد الصفائف المملوءة بالكامل ، وعدد العناصر في الصفيف الأخير. كل صفيف من العناصر مع أقل من 85000 بايت:

private T[][] chunks; private int currentChunk; private int currentChunkSize;
نظرًا لأن ChunkedList <T> معقدة إلى حد ما ، فقد كتبنا اختبارات مفصلة عليها. يجب اختبار أي عملية في وضعين على الأقل: في "صغير" عندما تناسب القائمة بأكملها قطعة واحدة يصل حجمها إلى 85000 بايت ، و "كبيرة" عندما تتكون من أكثر من قطعة واحدة. علاوة على ذلك ، بالنسبة للطرق التي تغير الحجم (على سبيل المثال ، إضافة) ، تكون السيناريوهات أكبر: "صغيرة" -> "صغيرة" ، "صغيرة" -> "كبيرة" ، "كبيرة" -> "كبيرة" ، "كبيرة" -> " صغير. " هنا هناك عدد لا بأس به من الحالات الحدودية المربكة التي تؤدي اختبارات الوحدة أداءً جيدًا.
يتم تبسيط الموقف من خلال حقيقة أن بعض الأساليب من واجهة IList غير مستخدمة ، ويمكن حذفها (مثل Insert ، Remove). إن تنفيذها واختبارها سيكونان من النفقات العامة. بالإضافة إلى ذلك ، يتم تبسيط اختبارات وحدة الكتابة من خلال حقيقة أننا لسنا بحاجة إلى الوصول إلى وظائف جديدة ، يجب أن تتصرف ChunkedList <T> بنفس القائمة <T>. بمعنى ، يتم تنظيم جميع الاختبارات على النحو التالي: إنشاء قائمة <T> وقائمة ChunkedList <T> ، وتنفيذ نفس العمليات عليها ومقارنة النتائج.
قمنا بقياس الأداء باستخدام مكتبة BenchmarkDotNet للتأكد من أننا لم نبطئ رمزنا كثيرًا عند التبديل من القائمة <T> إلى ChunkedList <T>. لنختبر ، على سبيل المثال ، إضافة عناصر إلى القائمة:
[Benchmark] public ChunkedList<int> ChunkedList() { var list = new ChunkedList<int>(); for (int i = 0; i < N; i++) list.Add(i); return list; }
ونفس الاختبار باستخدام قائمة <T> للمقارنة. النتائج عند إضافة 500 عنصر (كل شيء يناسب مجموعة واحدة):
النتائج عند إضافة 50000 عنصر (مقسم إلى عدة صفائف):
وصف مفصل للأعمدة في النتائج BenchmarkDotNet=v0.11.4, OS=Windows 10.0.17763.379 (1809/October2018Update/Redstone5) Intel Core i7-8700K CPU 3.70GHz (Coffee Lake), 1 CPU, 12 logical and 6 physical cores [Host] : .NET Framework 4.7.2 (CLR 4.0.30319.42000), 64bit RyuJIT-v4.7.3324.0 DefaultJob : .NET Framework 4.7.2 (CLR 4.0.30319.42000), 64bit RyuJIT-v4.7.3324.0
إذا نظرت إلى عمود "متوسط" ، الذي يعرض متوسط وقت تنفيذ الاختبار ، يمكنك أن ترى أن تطبيقنا أبطأ من 2 إلى 2.5 مرة فقط من المعيار. بالنظر إلى أنه في الكود الحقيقي ، لا تشكل العمليات مع القوائم سوى جزء صغير من جميع الإجراءات المنجزة ، ويصبح هذا الاختلاف ضئيلاً. لكن العمود "Gen 2 / 1k op" (عدد التجميعات من الجيل الثاني لتشغيل 1000 اختبار) يوضح أننا حققنا الهدف: مع عدد كبير من العناصر ، لا ينشئ ChunkedList القمامة في الجيل الثاني ، والتي كانت مهمتنا.
مجموعة قطعة
وبالمثل ، تطبق ChunkedHashSet <T> واجهة ISet <T>. عند كتابة ChunkedHashSet <T> ، أعدنا استخدام منطق القطعة الصغير المطبق بالفعل في ChunkedList. للقيام بذلك ، اتخذنا تطبيق HashSet <T> جاهزًا من مصدر مرجع .NET ، المتوفر بموجب ترخيص MIT ، واستبدلنا المصفوفات بقوائم ChunkedLists فيها.
في اختبارات الوحدات ، نستخدم نفس الخدعة كما في القوائم: سنقوم بمقارنة سلوك ChunkedHashSet <T> مع المرجع HashSet <T>.
وأخيرا ، اختبارات الأداء. العملية الرئيسية التي نستخدمها هي اتحاد المجموعات ، وهذا هو السبب في أننا نختبرها:
public ChunkedHashSet<int> ChunkedHashSet(int[][] source) { var set = new ChunkedHashSet<int>(); foreach (var arr in source) set.UnionWith(arr); return set; }
والاختبار نفسه بالضبط ل HashSet القياسية. الاختبار الأول للمجموعات الصغيرة:
var source = new int[][] { Enumerable.Range(0, 300).ToArray(), Enumerable.Range(100, 600).ToArray(), Enumerable.Range(300, 1000).ToArray(), }
الاختبار الثاني للمجموعات الكبيرة التي تسببت في مشكلة مجموعة من الكائنات الكبيرة:
var source = new int[][] { Enumerable.Range(0, 30000).ToArray(), Enumerable.Range(10000, 60000).ToArray(), Enumerable.Range(30000, 100000).ToArray(), }
النتائج تشبه القوائم. ChunkedHashSet أبطأ بنسبة 2-2.5 مرة ، ولكن في نفس الوقت على مجموعات كبيرة ، يتم تحميل الجيل الثاني من طلبيتي الحجم أقل.
التسلسل في JSON
يوفر خادم الويب Pyrus العديد من واجهات برمجة التطبيقات التي تستخدم تسلسلًا مختلفًا. لقد اكتشفنا إنشاء كائنات كبيرة في واجهة برمجة التطبيقات (API) المستخدمة من قبل الروبوتات وأداة المزامنة (يشار إليها فيما يلي باسم واجهة برمجة التطبيقات العامة). لاحظ أن واجهة برمجة التطبيقات تستخدم بشكل أساسي التسلسل الخاص بها ، والذي لا يتأثر بهذه المشكلة. لقد كتبنا عن هذا في المقال
https://habr.com/ar/post/227595/ ، في القسم "2. لا تعرف أين يقع عنق الزجاجة في تطبيقك ". وهذا يعني أن واجهة برمجة التطبيقات الرئيسية تعمل جيدًا بالفعل ، وقد ظهرت المشكلة في واجهة برمجة التطبيقات (API) العامة نظرًا لتزايد عدد الطلبات وكمية البيانات في الردود.
لنقم بتحسين واجهة برمجة التطبيقات العامة. باستخدام مثال واجهة برمجة التطبيقات الرئيسية ، نعلم أنه يمكنك إرجاع استجابة للمستخدم في وضع التدفق. بمعنى ، لا تحتاج إلى إنشاء مخازن مؤقتة متوسطة تحتوي على الاستجابة بالكامل ، ولكن اكتب الاستجابة فورًا إلى الدفق.
بعد الفحص الدقيق ، اكتشفنا أنه في عملية إجراء تسلسل الاستجابة ، نقوم بإنشاء مخزن مؤقت مؤقت للنتيجة الوسيطة ("المحتوى" عبارة عن مجموعة من وحدات البايت التي تحتوي على JSON بترميز UTF-8):
var serializer = Newtonsoft.Json.JsonSerializer.Create(...); byte[] content; var sw = new StreamWriter(new MemoryStream(), new UTF8Encoding(false)); using (var writer = new Newtonsoft.Json.JsonTextWriter(sw)) { serializer.Serialize(writer, result); writer.Flush(); content = ms.ToArray(); }
لنرى أين يتم استخدام المحتوى. لأسباب تاريخية ، تعتمد واجهة برمجة التطبيقات (API) العامة على WCF ، والذي يعد XML تنسيق الطلب والاستجابة القياسي له. في حالتنا ، تحتوي استجابة XML على عنصر "ثنائي" واحد ، يتم من خلاله كتابة JSON المشفر في Base64:
public class RawBodyWriter : BodyWriter { private readonly byte[] _content; public RawBodyWriter(byte[] content) : base(true) { _content = content; } protected override void OnWriteBodyContents(XmlDictionaryWriter writer) { writer.WriteStartElement("Binary"); writer.WriteBase64(_content, 0, _content.Length); writer.WriteEndElement(); } }
لاحظ أن المخزن المؤقت المؤقت غير مطلوب هنا. يمكن كتابة JSON على الفور إلى المخزن المؤقت XmlWriter الذي يوفره لنا WCF ، وترميزه في Base64 أثناء الطيران. وبالتالي ، سنعمل على التخلص من تخصيص الذاكرة:
protected override void OnWriteBodyContents(XmlDictionaryWriter writer) { var serializer = Newtonsoft.Json.JsonSerializer.Create(...); writer.WriteStartElement("Binary"); Stream stream = new Base64Writer(writer); Var sw = new StreamWriter(stream, new UTF8Encoding(false)); using (var jsonWriter = new Newtonsoft.Json.JsonTextWriter(sw)) { serializer.Serialize(jsonWriter, _result); jsonWriter.Flush(); } writer.WriteEndElement(); }
هنا Base64Writer عبارة عن مجمّع بسيط عبر XmlWriter يقوم بتنفيذ واجهة Stream ، التي تكتب إلى XmlWriter باسم Base64. في الوقت نفسه ، من الواجهة بأكملها ، يكفي تطبيق طريقة كتابة واحدة فقط ، والتي تسمى في StreamWriter:
public class Base64Writer : Stream { private readonly XmlWriter _writer; public Base64Writer(XmlWriter writer) { _writer = writer; } public override void Write(byte[] buffer, int offset, int count) { _writer.WriteBase64(buffer, offset, count); } <...> }
التي يسببها جي سي
دعونا نحاول التعامل مع مجموعات القمامة المستحثة الغامضة. لقد قمنا بإعادة فحص الكود لدينا 10 مرات لمكالمات GC.Collect ، لكن هذا فشل. لقد تمكنت من التقاط هذه الأحداث في PerfView ، لكن مكدس الاتصال ليس مؤشراً للغاية (حدث DotNETRuntime / GC / Triggered):
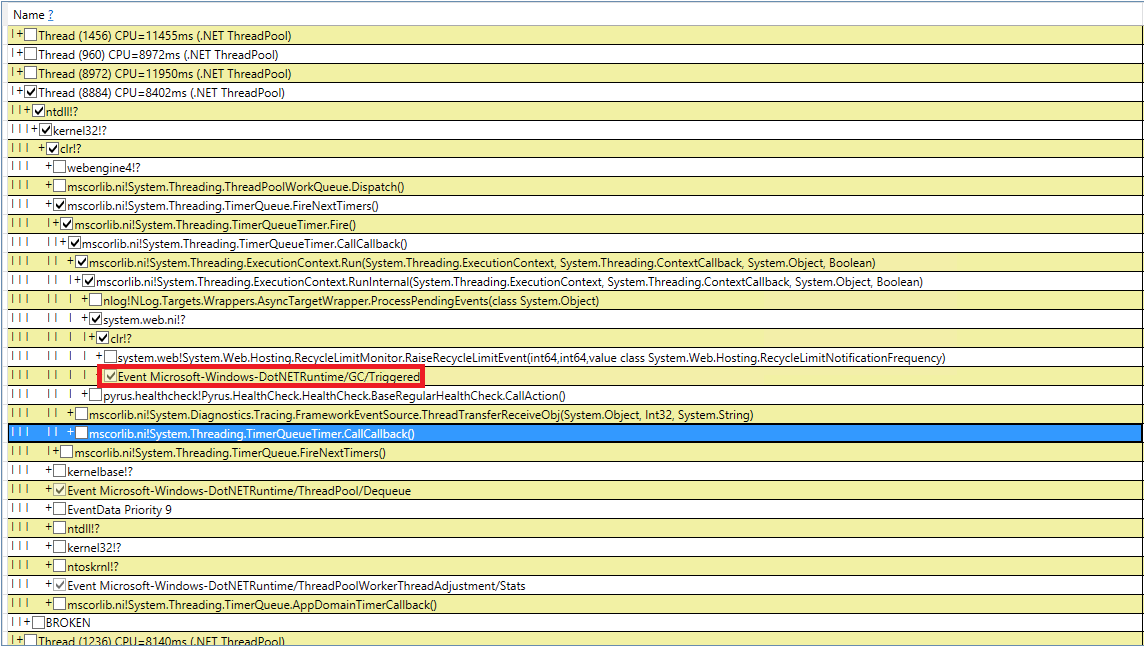
هناك فكرة صغيرة - استدعاء RecycleLimitMonitor.RaiseRecycleLimitEvent قبل جمع القمامة المستحث. دعنا نتتبع مكدس المكالمات إلى أسلوب RaiseRecycleLimitEvent:
RecycleLimitMonitor.RaiseRecycleLimitEvent(...) RecycleLimitMonitor.RecycleLimitMonitorSingleton.AlertProxyMonitors(...) RecycleLimitMonitor.RecycleLimitMonitorSingleton.CollectInfrequently(...) RecycleLimitMonitor.RecycleLimitMonitorSingleton.PBytesMonitorThread(...)
تتوافق أسماء الطرق مع وظائفها:
- في مُنشئ RecycleLimitMonitor.RecycleLimitMonitorSingleton ، يتم إنشاء مؤقت يستدعي PBytesMonitorThread في فاصل زمني معين.
- PBytesMonitorThread بجمع إحصائيات حول استخدام الذاكرة ، وفي بعض الحالات ، يستدعي CollectInfrequently.
- استدعاء CollectInfrequently AlertProxyMonitors ، يحصل على منطقي نتيجة لذلك ، ويستدعي GC.Collect () إذا أصبح صحيحاً. كما يراقب الوقت المنقضي منذ آخر مكالمة لجامع البيانات المهملة ، ولا يسميها كثيرًا.
- يمر AlertProxyMonitors من خلال قائمة تشغيل تطبيقات الويب IIS ، حيث يقوم كل منهم برفع كائن RecycleLimitMonitor المقابل ، ويستدعي RaiseRecycleLimitEvent.
- رفع RaiseRecycleLimitEvent قائمة IObserver <RecycleLimitInfo>. تلقي معالجات كمعلمة RecycleLimitInfo ، حيث يمكنهم تعيين علامة RequestGC ، والتي ترجع إلى CollectInfrequently ، مما تسبب في جمع القمامة المستحث.
يكشف التحقيق الإضافي عن إضافة معالجات IObserver <RecycleLimitInfo> في الأسلوب RecycleLimitMonitor.Subscribe () ، والذي يسمى في طريقة AspNetMemoryMonitor.Subscribe (). أيضاً ، يتم تعليق معالج IObserver <RecycleLimitInfo> الافتراضي (فئة RecycleLimitObserver) في فئة AspNetMemoryMonitor ، التي تقوم بتنظيف ذاكرة التخزين المؤقت لـ ASP.NET وأحيانًا تطلب جمع البيانات المهملة.
تم حل لغز الـ GC المستحث. يبقى لمعرفة مسألة لماذا تسمى هذه المجموعة القمامة. تراقب RecycleLimitMonitor استخدام ذاكرة IIS (بتعبير أدق ، عدد البايتات الخاصة) ، وعندما يقترب استخدامه من حد معين ، يبدأ بواسطة خوارزمية مربكة إلى حد ما لرفع حدث RaiseRecycleLimitEvent. يتم استخدام قيمة AspNetMemoryMonitor.ProcessPrivateBytesLimit كحد الذاكرة ، وبالتالي فهي تحتوي على المنطق التالي:
- إذا تم تعيين "تجمع التطبيقات" في IIS على "حد الذاكرة الخاصة (KB)" ، فسيتم أخذ القيمة بالكيلوبايت من هناك
- خلاف ذلك ، بالنسبة للأنظمة 64 بت ، يتم أخذ 60٪ من الذاكرة الفعلية (لأنظمة 32 بت ، يكون المنطق أكثر تعقيدًا).
نتيجة الاستقصاء هي: ASP.NET تقترب من حد الذاكرة وتبدأ في استدعاء مجموعة البيانات المهملة بشكل منتظم. لم يتم تعيين "الحد الأقصى للذاكرة الخاصة (KB)" ، لذلك تم تحديد ASP.NET بنسبة 60٪ من الذاكرة الفعلية. تم حجب المشكلة عن طريق حقيقة أنه على خادم إدارة المهام أظهرت وجود الكثير من الذاكرة الخالية ويبدو أنها كانت مفقودة. لقد قمنا بزيادة قيمة "حد الذاكرة الخاصة (KB)" في "إعدادات تجمع التطبيقات" في IIS إلى 80٪ من الذاكرة الفعلية. هذا يشجع ASP.NET على استخدام المزيد من الذاكرة المتوفرة. لقد أضفنا أيضًا مراقبة عداد الأداء ".NET CLR Memory / # Induced GC" حتى لا تفوت في المرة التالية التي يقرر فيها ASP.NET أنه يقترب من حد استخدام الذاكرة.
القياسات المتكررة
دعونا نرى ما حدث مع مجموعة القمامة بعد كل هذه التغييرات. لنبدأ بـ perfview / GCCollectOnly (وقت التتبع - ساعة واحدة) ، تقرير GCStats:
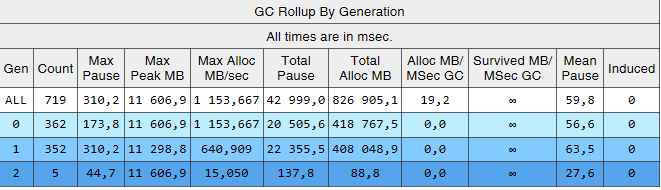
يمكن ملاحظة أن تجميعات الجيل الثاني أصبحت الآن طلبيتين بحجم أقل من 0 و 1. أيضا ، انخفض وقت هذه الجمعيات. لم يعد يتم ملاحظة التجميعات المستحثة. لنلقِ نظرة على قائمة تجميعات الجيل الثاني:
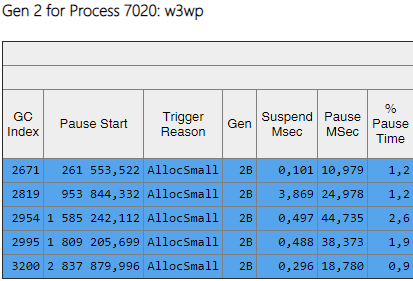
يوضح العمود Gen أن جميع التجميعات من الجيل الثاني أصبحت خلفية (يعني "2B" الجيل الثاني ، الخلفية). بمعنى أن معظم العمل يتم تنفيذه بالتوازي مع تنفيذ التطبيق ، ويتم حظر جميع المواضيع لفترة قصيرة (العمود "إيقاف مؤقت MSec"). دعنا ننظر إلى التوقف عند إنشاء كائنات كبيرة:

يمكن ملاحظة أن عدد هذه الإيقاف المؤقت عند إنشاء كائنات كبيرة انخفض بشكل كبير.
النتائج
بفضل التغييرات الموضحة في المقالة ، كان من الممكن تقليل عدد ومدة التجميعات من الجيل الثاني بشكل كبير. تمكنت من العثور على سبب التجميعات المستحثة والتخلص منها. زاد عدد التجميعات من الجيلين الأول والثاني ، لكن متوسط المدة انخفض (من 200 مللي إلى ~ 60 مللي ثانية). انخفضت مدة التجميع القصوى للجيلين 0 و 1 ، ولكن ليس بشكل ملحوظ. أصبحت تجميعات الجيل الثاني أسرع ، وقد توقفت فترات التوقف الطويلة التي تصل إلى 1000 مللي ثانية تمامًا.
بالنسبة إلى المقياس الرئيسي - "النسبة المئوية للاستعلامات البطيئة" ، فقد انخفض بنسبة 40٪ بعد كل التغييرات.
بفضل عملنا ، أدركنا ما هي عدادات الأداء اللازمة لتقييم الموقف مع الذاكرة وجمع القمامة ، وإضافتها إلى Zabbix للمراقبة المستمرة. فيما يلي قائمة بأهم تلك التي نوليها الاهتمام ومعرفة السبب (على سبيل المثال ، زيادة تدفق الطلبات ، وكمية كبيرة من البيانات المرسلة ، وخلل في التطبيق):