
إذا كنت تدير بنية تحتية ظاهرية تعتمد على VMware vSphere (أو أي مكدس تقنية آخر) ، فغالبًا ما تسمع شكاوى من المستخدمين: "الجهاز الظاهري بطيء!". في هذه السلسلة من المقالات ، سأحلل مقاييس الأداء وأشرح لماذا "يبطئ" ولماذا يتأكد من أنه "لا يبطئ".
سأنظر في جوانب الأداء التالية للأجهزة الافتراضية:
- وحدة المعالجة المركزية،
- RAM،
- DISK،
- الشبكة.
سأبدأ مع وحدة المعالجة المركزية.
لتحليل الأداء نحتاج:
- عدادات أداء vCenter هي عدادات أداء يمكن عرض رسوماتها البيانية من خلال عميل vSphere. تتوفر المعلومات حول هذه العدادات في أي إصدار عميل (عميل "كثيف" في C # ، عميل ويب على Flex و عميل ويب على HTML5). في هذه المقالات ، سنستخدم لقطات شاشة من عميل C # ، فقط لأنها تبدو أفضل في صورة مصغرة :)
- ESXTOP هي أداة مساعدة يتم تشغيلها من سطر أوامر ESXi. من خلال مساعدتها ، يمكنك الحصول على قيم عدادات الأداء في الوقت الفعلي أو تحميل هذه القيم لفترة معينة إلى ملف .csv لمزيد من التحليل. بعد ذلك ، سوف أخبركم المزيد عن هذه الأداة وأقدم بعض الروابط المفيدة للوثائق والمقالات ذات الصلة.
قليلا من الناحية النظرية
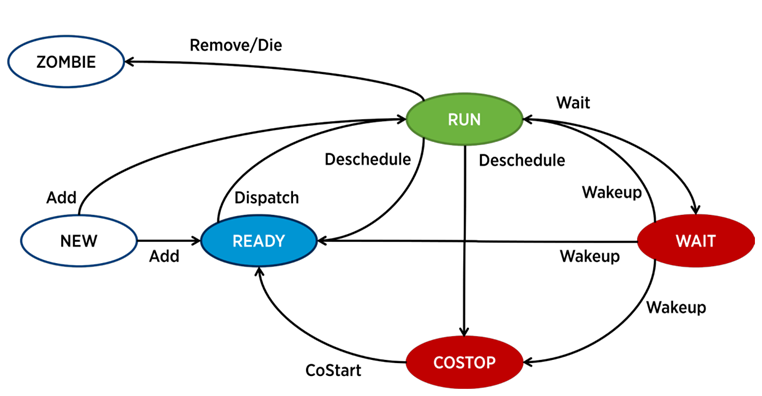
في ESXi ، تكون هناك عملية منفصلة مسؤولة عن تشغيل كل vCPU (قلب الجهاز الظاهري) - العالم في مصطلحات VMware. هناك أيضًا عمليات خدمة ، ولكن من وجهة نظر تحليل أداء VM ، فهي أقل إثارة للاهتمام.
يمكن أن تكون العملية في ESXi في إحدى الحالات الأربع:
- تشغيل - العملية تقوم ببعض الأعمال المفيدة.
- انتظر - لا تؤدي العملية أي عمل (خاملاً) أو تنتظر الإدخال / الإخراج.
- Costop هو الشرط الذي يحدث في الأجهزة الافتراضية متعددة النواة. يحدث ذلك عندما يتعذر على جدولة وحدة التحكم في برنامج Hypervisor (ESXi CPU Scheduler) جدولة جميع المراكز النشطة في الجهاز الظاهري لتعمل في وقت واحد على مراكز الخادم الفعلية. في العالم المادي ، تعمل جميع نوى المعالج بشكل متوازٍ ، ويتوقع نظام التشغيل الضيف داخل الجهاز VM سلوكًا مشابهًا ، لذلك يتعين على برنامج Hypervisor أن يبطئ نوى VM ، التي لديها القدرة على إنهاء الإيقاع بشكل أسرع. في الإصدارات الحديثة من ESXi ، يستخدم برنامج جدولة وحدة المعالجة المركزية آلية تسمى الجدولة المشتركة المريحة: ينظر برنامج hypervisor في الفجوة بين "الأسرع" و "أبطأ" قلب الجهاز الظاهري (الانحراف) ، وإذا تجاوزت الفجوة حدًا معينًا ، فإن القلب "السريع" ينتقل إلى حالة costop إذا كان لقلب VM قضاء كثير من الوقت في هذه الحالة ، فقد يتسبب ذلك في مشاكل في الأداء.
- جاهز - تذهب العملية إلى هذه الحالة عندما لا يكون لدى برنامج hypervisor القدرة على تخصيص الموارد لتنفيذها. قيم جاهزة عالية يمكن أن يسبب مشاكل الأداء VM.
عدادات أداء وحدة المعالجة المركزية الأساسية لجهاز افتراضي
استخدام وحدة المعالجة المركزية ، ٪. يوضح النسبة المئوية لاستخدام وحدة المعالجة المركزية لفترة معينة.
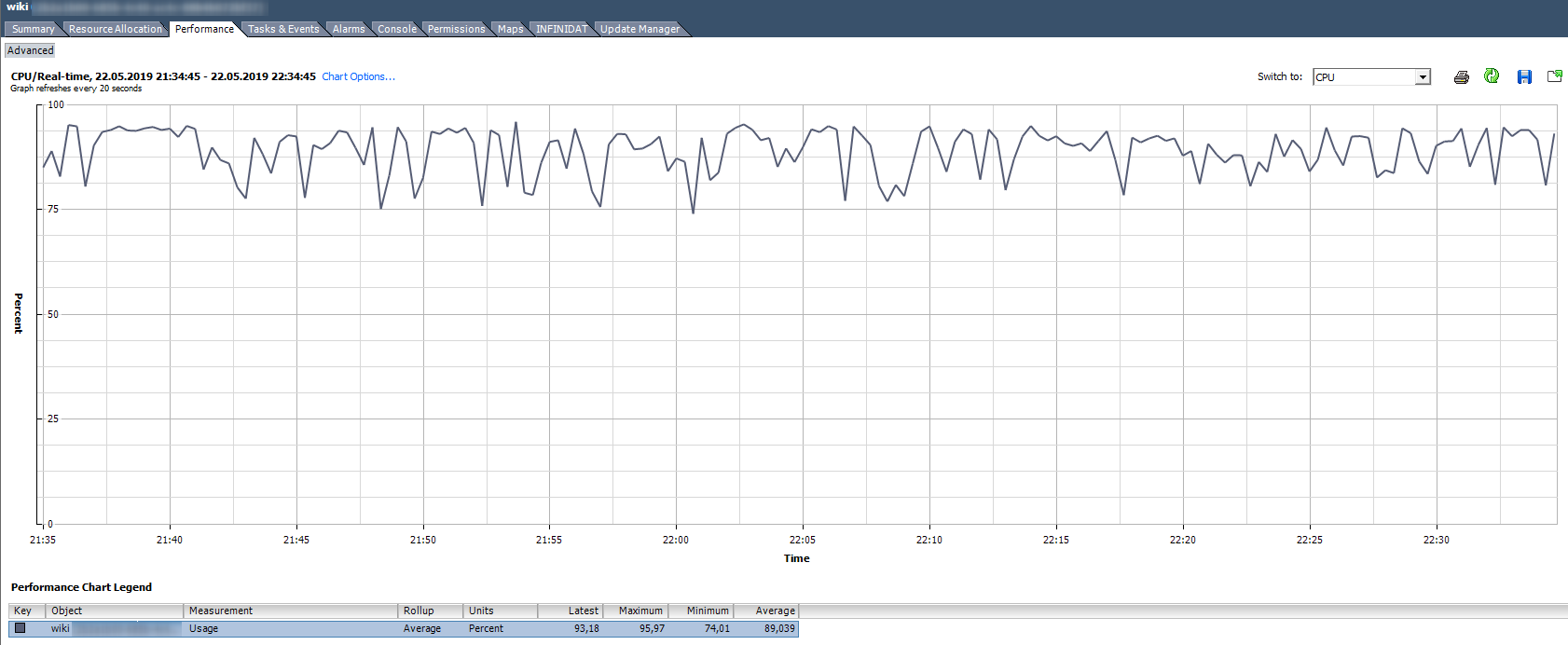 كيف نحلل؟
كيف نحلل؟ إذا كان جهاز VM يستخدم وحدة المعالجة المركزية بثبات بنسبة 90٪ أو أن هناك قمم تصل إلى 100٪ ، عندئذٍ نواجه مشكلات. يمكن التعبير عن المشكلات ليس فقط في التشغيل "البطيء" للتطبيق داخل VM ، ولكن أيضًا في عدم إمكانية الوصول إلى VM عبر الشبكة. إذا أظهر نظام المراقبة أن جهاز VM يقع بشكل دوري ، فعليك الانتباه إلى القمم الموجودة في الرسم البياني لاستخدام وحدة المعالجة المركزية.
هناك إنذار قياسي ، والذي يوضح تحميل وحدة المعالجة المركزية للجهاز الظاهري:
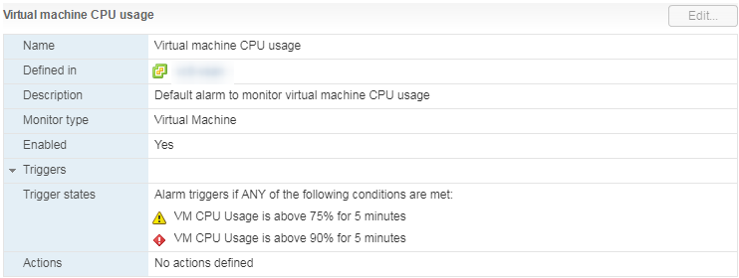 ما يجب القيام به
ما يجب القيام به إذا كان استخدام وحدة المعالجة المركزية (CPU) يسيطر باستمرار على VM ، فيمكنك عندئذٍ التفكير في زيادة عدد وحدات vCPU (لسوء الحظ ، هذا لا يساعد دائمًا) أو نقل وحدات VM إلى خادم به معالجات أكثر كفاءة.
استخدام وحدة المعالجة المركزية في ميغاهيرتز
في الرسوم البيانية لـ vCenter Usage في٪ يمكنك فقط مشاهدة الجهاز الظاهري بالكامل ، لا توجد رسوم بيانية للنوى الفردية (تحتوي Esxtop على قيم في٪ for cores). لكل نواة ، يمكنك أن ترى الاستخدام في ميغاهيرتز.
كيف نحلل؟ يحدث أن التطبيق لم يتم تحسينه للعمارة متعددة النواة: فهو يستخدم نواة واحدة فقط بنسبة 100٪ ، والباقي خاملاً دون تحميل. على سبيل المثال ، مع إعدادات النسخ الاحتياطي الافتراضية ، يبدأ MS SQL العملية على نواة واحدة فقط. نتيجة لذلك ، يتم إبطاء النسخ الاحتياطي ليس بسبب سرعة القرص البطيئة (هذا ما اشتكى المستخدم منه في البداية) ، ولكن بسبب عدم قدرة المعالج على التعامل معه. تم حل المشكلة عن طريق تغيير المعلمات: بدأ النسخ الاحتياطي يعمل بالتوازي في عدة ملفات (على التوالي ، في العديد من العمليات).
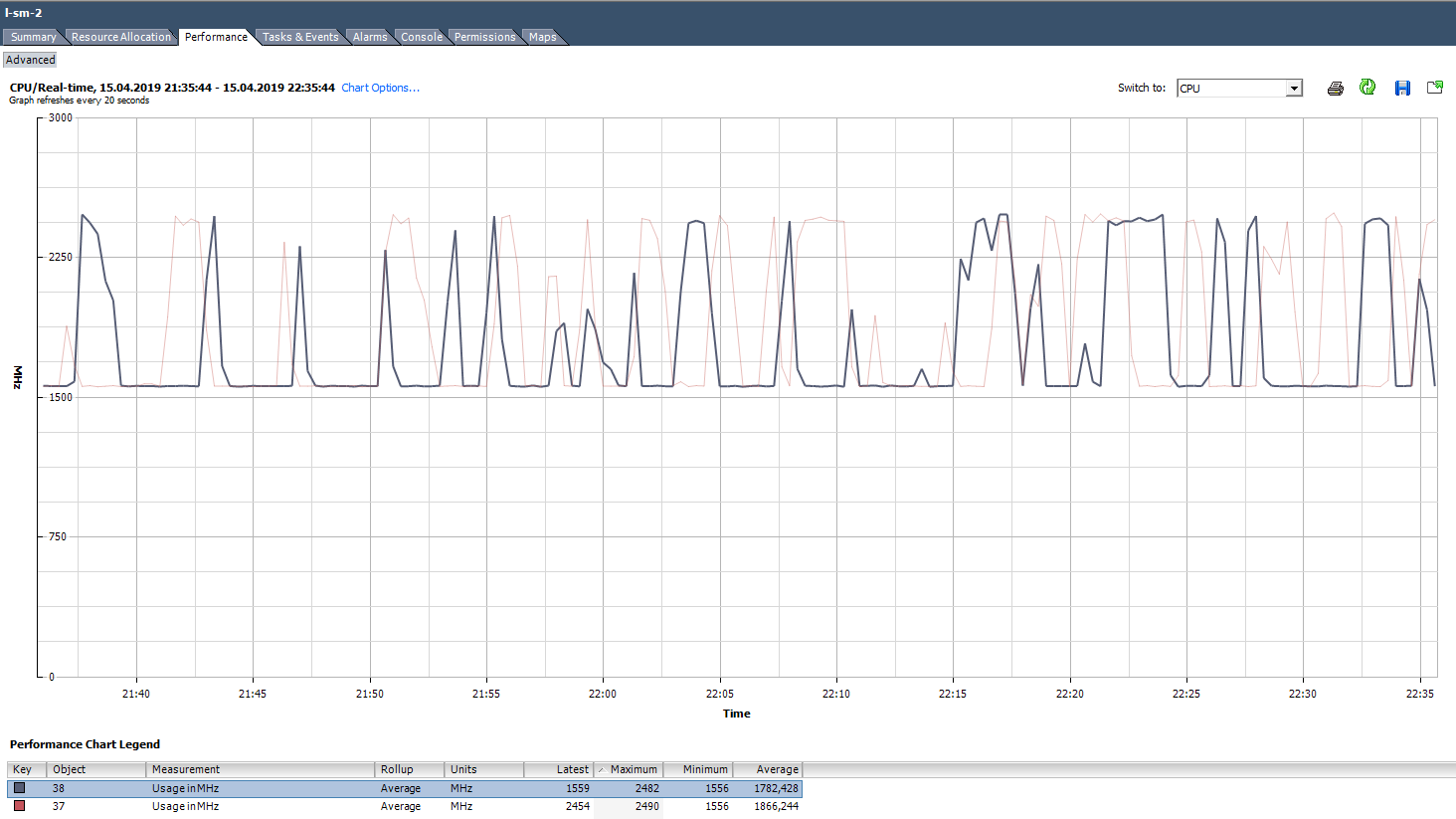 مثال على الحمل غير المتكافئ للنواة.
مثال على الحمل غير المتكافئ للنواة.هناك أيضًا موقف (كما في الرسم البياني أعلاه) عندما يتم تحميل النوى بشكل غير متساو وبعضها يصل إلى 100٪. كما هو الحال مع تحميل نواة واحدة فقط ، لن يعمل التنبيه على CPU Usage (إنه موجود على الجهاز الظاهري بالكامل) ، ولكن ستكون هناك مشكلات في الأداء.
ما يجب القيام به إذا قام البرنامج الموجود في الجهاز الظاهري بتحميل النواة بشكل غير متساو (يستخدم فقط نواة واحدة أو جزءًا من النوى) ، فلا فائدة من زيادة عددهم. في هذه الحالة ، من الأفضل نقل جهاز VM إلى خادم به معالجات أكثر كفاءة.
يمكنك أيضًا محاولة التحقق من إعدادات الطاقة في BIOS الخادم. يقوم العديد من المسؤولين بتشغيل وضع "الأداء العالي" في نظام الإدخال والإخراج الأساسي (BIOS) وبالتالي إيقاف تشغيل تقنيات توفير الطاقة للحالات C والحالات P. تستخدم معالجات Intel الحديثة تقنية Turbo Boost ، مما يزيد من تواتر نوى المعالجات الفردية بسبب النوى الأخرى. لكنه يعمل فقط مع التقنيات الموفرة للطاقة المضمنة. إذا أوقفنا تشغيلها ، فلن يتمكن المعالج من تقليل استهلاك الطاقة للنواة التي لم يتم تحميلها.
توصي VMware بعدم إيقاف تشغيل تقنيات توفير الطاقة على الخوادم ، ولكن باختيار أوضاع تزيد من إدارة الطاقة إلى برنامج Hypervisor. في الوقت نفسه ، في إعدادات الطاقة في برنامج Hypervisor ، تحتاج إلى تحديد High Performance.
إذا كان لديك VMs منفصلة (أو نوى VM) في البنية التحتية الخاصة بك والتي تتطلب زيادة وتيرة وحدة المعالجة المركزية ، فإن التكوين الصحيح لاستهلاك الطاقة يمكن أن يحسن أداءهم بشكل كبير.
جاهزية وحدة المعالجة المركزية (الجاهزية)
إذا كان VM core (vCPU) في حالة الاستعداد ، فإنه لا يقوم بعمل مفيد. تحدث هذه الحالة عندما لا يجد برنامج hypervisor لبًا ماديًا مجانيًا يمكن تعيين عملية vCPU للجهاز الظاهري عليه.
كيف نحلل؟ عادةً ، إذا كانت نوى الجهاز الظاهري في حالة استعداد لأكثر من 10٪ من الوقت ، فستلاحظ مشكلات في الأداء. ببساطة ، أكثر من 10 ٪ من الوقت ينتظر VM لتوافر الموارد المادية.
في vCenter ، يمكنك رؤية عدادين يرتبطان بوحدة المعالجة المركزية الجاهزة:
يمكن عرض قيم العدادات على كل من VM بالكامل وللنواة الفردية.
يُظهر الجاهزية القيمة فورًا بالنسب المئوية ، ولكن فقط في الوقت الفعلي (بيانات الساعة الأخيرة ، فاصل القياس 20 ثانية). يستخدم هذا العداد فقط للبحث عن المشاكل "في المطاردة الساخنة".
يمكن أيضًا الاطلاع على قيم العداد الجاهز من منظور تاريخي. هذا مفيد لإنشاء أنماط وللتحليل الأعمق للمشكلة. على سبيل المثال ، إذا كان الجهاز الظاهري يبدأ في مواجهة مشاكل في الأداء في وقت معين ، فيمكنك مقارنة الفواصل الزمنية لقيمة تعليق وحدة المعالجة المركزية الجاهزية بالحمل الكلي على الخادم حيث يعمل جهاز VM ، واتخاذ تدابير لتقليل الحمل (إذا تعذر على DRS التعامل).
جاهز ، على عكس الجاهزية ، لا يظهر بالنسب المئوية ، ولكن بالمللي ثانية. هذا هو عداد نوع Summation ، أي أنه يوضح المدة التي كان فيها VM في حالة الاستعداد أثناء فترة القياس. يمكنك ترجمة هذه القيمة إلى النسبة المئوية بواسطة صيغة بسيطة:
(قيمة تلخيص وحدة المعالجة المركزية الجاهزة / (الفاصل الزمني للتحديث الافتراضي للمخطط بالثواني * 1000)) * 100 = وحدة المعالجة المركزية جاهزة٪
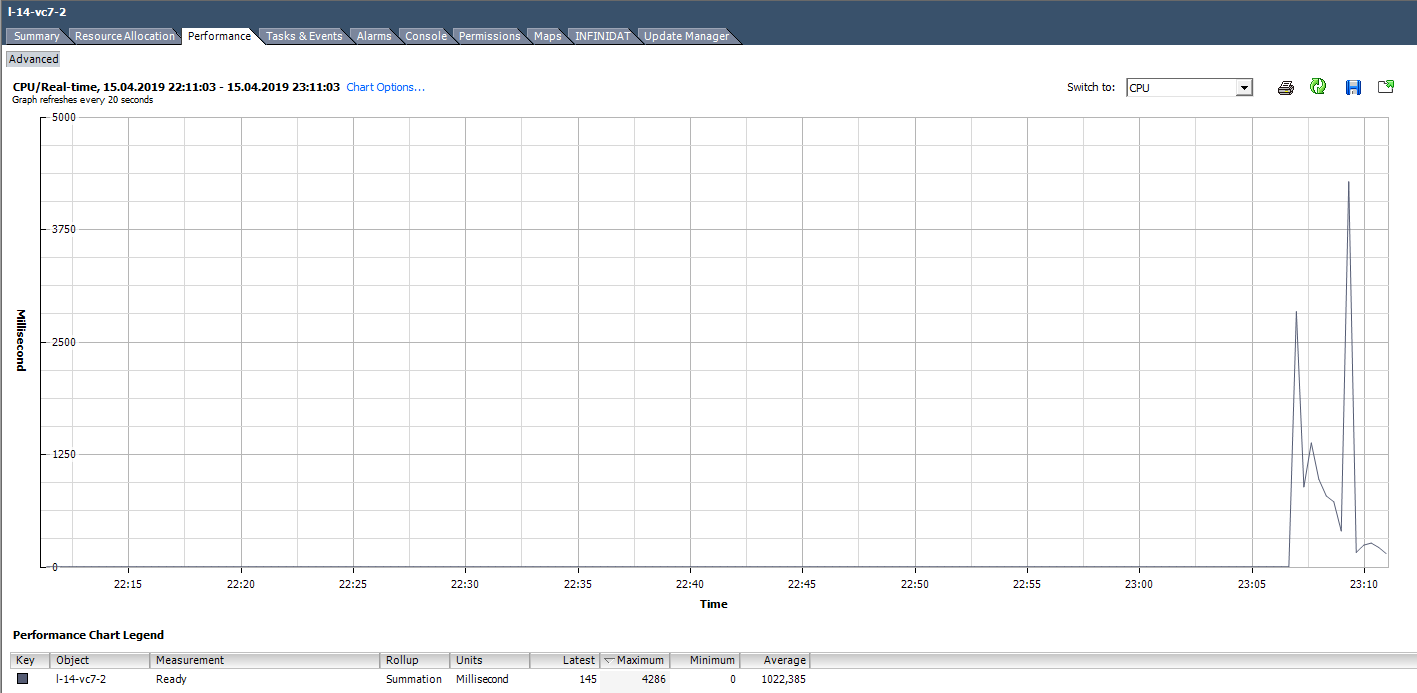
على سبيل المثال ، بالنسبة لـ VMs في الرسم البياني أدناه ، تكون قيمة الذروة لـ Ready للجهاز الظاهري بأكمله كما يلي:
عند حساب القيمة الجاهزة كنسبة مئوية ، يجب الانتباه إلى نقطتين:
- قيمة Ready عبر VM بالكامل هي مجموع Ready عبر النوى.
- فترة القياس. في الوقت الفعلي ، تبلغ هذه المدة 20 ثانية ، على سبيل المثال ، على المخططات اليومية ، تبلغ 300 ثانية.
مع استكشاف الأخطاء وإصلاحها النشطة ، يمكن تفويت هذه النقاط البسيطة بسهولة ويمكن قضاء وقت ثمين في حل المشكلات غير الموجودة.
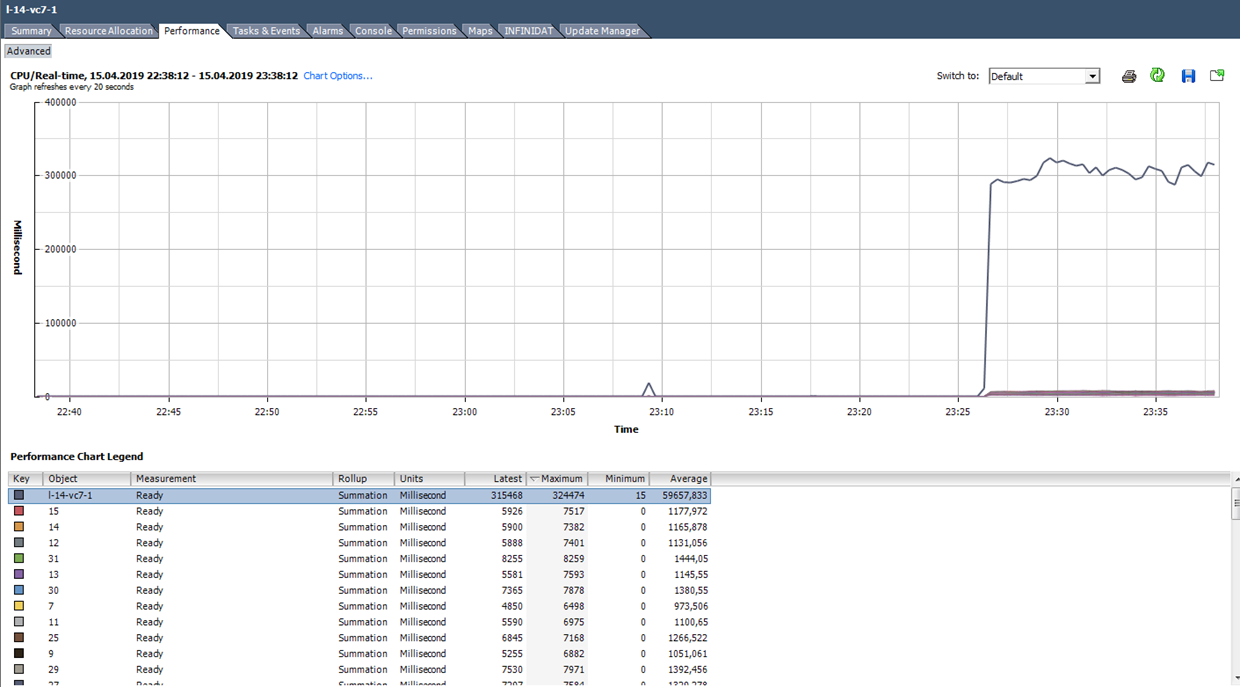
نحسب جاهزًا استنادًا إلى البيانات من الرسم البياني أدناه. (324474 / (20 * 1000)) * 100 = 1622٪ لكامل VM. إذا نظرت إلى النوى ، فستتحول إلى مخيف غير كبير: 1622/64 = 25٪ لكل قلب. في هذه الحالة ، يكون اكتشاف الخدعة بسيطًا جدًا: القيمة الجاهزة غير واقعية. ولكن إذا كنا نتحدث عن 10-20 ٪ لكامل VM بعدة نوى ، فيمكن لكل قيمة أن تكون ضمن النطاق الطبيعي.
 ما يجب القيام به
ما يجب القيام به تشير القيمة العالية لـ Ready إلى أن الخادم لا يحتوي على موارد معالج كافية للتشغيل العادي للأجهزة الافتراضية. في هذه الحالة ، يبقى فقط للحد من زيادة الاشتراك على المعالج (vCPU: pCPU). من الواضح ، يمكن تحقيق ذلك عن طريق تقليل معلمات أجهزة VM الموجودة أو عن طريق نقل جزء من VM إلى خوادم أخرى.
شارك وقفة
كيف نحلل؟ يحتوي هذا العداد أيضًا على نوع الملخص ويترجم إلى نسب مئوية مثل جاهز:
(قيمة تجميع وحدة المعالجة المركزية المشتركة / (الفاصل الزمني للتحديث الافتراضي للمخطط بالثواني * 1000)) * 100 = وحدة المعالجة المركزية٪ المشتركة
هنا تحتاج أيضًا إلى الانتباه إلى عدد النوى لكل VM وفاصل القياس.
في حالة costop ، لا يقوم النواة بعمل مفيد. مع التحديد الصحيح لحجم VM والحمل العادي على الخادم ، يجب أن تكون عداد الوقف المشترك قريبة من الصفر.
 في هذه الحالة ، من الواضح أن الحمل غير طبيعي :)ما يجب القيام به
في هذه الحالة ، من الواضح أن الحمل غير طبيعي :)ما يجب القيام به إذا تم تشغيل العديد من VMs مع عدد كبير من النوى على برنامج Hypervisor نفسه وكان هناك زيادة في الاشتراك على وحدة المعالجة المركزية ، فيمكن أن تتطور عداد الوقف المشترك ، مما سيؤدي إلى مشاكل في أداء هذه الأجهزة.
أيضًا ، ستزيد co-stop إذا تم استخدام مؤشرات الترابط للنواة النشطة من جهاز VM على نفس مركز الخادم الفعلي مع تمكين ميزة المعالجة المفرطة. قد ينشأ مثل هذا الموقف ، على سبيل المثال ، إذا كان VM يحتوي على عدد أكبر من النوى فعليًا على الخادم حيث يعمل ، أو إذا تم تمكين إعداد "preferHT" لـ VM. يمكنك أن تقرأ عن هذا الإعداد
هنا .
لتجنب حدوث مشاكل في أداء VM نظرًا للتوقف المشترك العالي ، حدد حجم VM وفقًا لتوصيات الشركة المصنعة للبرامج التي تعمل على هذا VM ، ومع إمكانيات الخادم الفعلي حيث يتم تشغيل VM.
لا تضيف حبات في المحمية ، فقد يتسبب ذلك في مشاكل في الأداء ليس فقط من VM نفسها ، ولكن أيضًا لجيران الخوادم.
مقاييس وحدة المعالجة المركزية المفيدة الأخرى
Run - مقدار الوقت (مللي ثانية) لفترة قياس vCPU كان في حالة RUN ، أي أنه تم القيام بعمل مفيد بالفعل.
الخمول - كم من الوقت (مللي ثانية) لفترة قياس vCPU كان غير نشط. قيم الخمول عالية ليست مشكلة ، فقط vCPU كان "لا شيء للقيام به".
الانتظار - كم من الوقت (مللي ثانية) لفترة قياس vCPU كان في حالة الانتظار. نظرًا لأن IDLE مضمن في هذا العداد ، فإن قيم الانتظار العالية لا تشير أيضًا إلى وجود مشكلة. ولكن إذا كانت الانتظار عالٍ منخفضة ، فإن جهاز VM كان ينتظر اكتمال عمليات الإدخال / الإخراج ، وهذا بدوره قد يشير إلى وجود مشكلة في أداء القرص الثابت أو بعض أجهزة VM الافتراضية.
الحد الأقصى المحدود - كان مقدار الوقت (مللي ثانية) لفترة قياس vCPU في حالة الاستعداد نظرًا لحد المورد المحدد. إذا كان الأداء منخفضًا بشكل غير مفهوم ، فمن المفيد التحقق من قيمة هذا العداد وحد وحدة المعالجة المركزية في إعدادات VM. قد يكون لـ VMs بالفعل حدود لا تعرفها. على سبيل المثال ، يحدث هذا عندما تم مائل VM من القالب الذي تم تعيين حد وحدة المعالجة المركزية عليه.
انتظار المبادلة - المدة التي انتظرت فيها وحدة المعالجة المركزية (VCPU) التشغيل مع VMkernel Swap خلال فترة القياس. إذا كانت قيم هذا العداد أعلى من الصفر ، فمن المؤكد أن لدى VM مشاكل في الأداء. سنتحدث أكثر عن SWAP في مقالة حول عدادات ذاكرة الوصول العشوائي.
ESXTOP
إذا كانت عدادات الأداء في vCenter جيدة لتحليل البيانات التاريخية ، فمن الأفضل إجراء تحليل إلكتروني للمشكلة في ESXTOP. هنا ، يتم تقديم جميع القيم في شكل نهائي (لا حاجة لترجمة أي شيء) ، والحد الأدنى لفترة القياس هو 2 ثانية.
يتم استدعاء شاشة ESXTOP على وحدة المعالجة المركزية بواسطة المفتاح "c" وتبدو كما يلي:

للراحة ، يمكنك ترك عمليات الجهاز الظاهري فقط عن طريق الضغط على Shift-V.
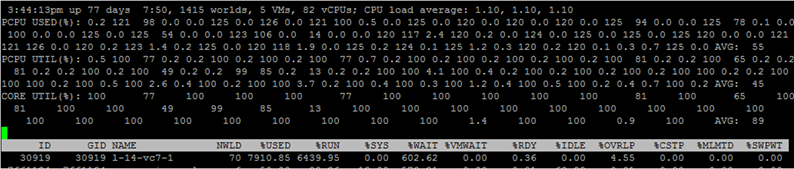
لمشاهدة مقاييس نوى VM الفردية ، اضغط على "e" واكتب في GID الخاص بـ VM الذي تهتم به (30919 في لقطة الشاشة أدناه):

انتقل لفترة وجيزة من خلال الأعمدة التي يتم تقديمها بشكل افتراضي. يمكن إضافة أعمدة إضافية عن طريق الضغط على "f".
NWLD (عدد العوالم) - عدد العمليات في المجموعة. لتوسيع المجموعة ومعرفة مقاييس كل عملية (على سبيل المثال ، لكل نواة جهاز VM متعدد النوى) ، اضغط على "e". إذا كان لدى المجموعة أكثر من عملية واحدة ، فإن قيم المقاييس للمجموعة تساوي مجموع مقاييس العمليات الفردية.
٪ مستخدم - كم عدد دورات وحدة المعالجة المركزية للخادم الذي يستخدم عملية أو مجموعة من العمليات.
٪ RUN - كم من الوقت خلال فترة القياس كانت العملية في حالة RUN ، أي القيام بعمل مفيد. إنه يختلف عن٪ USED من حيث أنه لا يأخذ في الحسبان الترابط المفرط ، وتيرة التردد والوقت الذي يقضيه في مهام النظام (٪ SYS).
٪ SYS - الوقت المستغرق في مهام النظام ، على سبيل المثال: معالجة المقاطعات ، الإدخال / الإخراج ، تشغيل الشبكة ، إلخ. يمكن أن تكون القيمة عالية إذا كان هناك الكثير من المدخلات / المخرجات على VM.
٪ OVRLP - مقدار الوقت الذي تستغرقه العملية الفعلية التي تقوم بها عملية VM في مهام العمليات الأخرى.
ترتبط هذه المقاييس على النحو التالي:
٪ مستخدم =٪ RUN +٪ SYS -٪ OVRLP.
عادةً ما يكون مقياس الاستخدام٪ أكثر إفادة.
٪ WAIT - كم من الوقت خلال فترة القياس كانت العملية في حالة الانتظار. يشمل الخمول.
٪ IDLE - كم من الوقت كانت العملية في حالة IDLE أثناء فترة القياس.
٪ SWPWT - ما المدة التي استغرقها vCPU في انتظار التشغيل مع VMkernel Swap خلال فترة القياس.
٪ VMWAIT - كم من الوقت كانت vCPU في حالة انتظار حدث (عادةً I / O) خلال فترة القياس. لا يوجد عداد مماثل في vCenter. تشير القيم العالية إلى مشاكل في الإدخال / الإخراج إلى VM.
٪ WAIT =٪ VMWAIT +٪ IDLE +٪ SWPWT.
إذا كان VM لا يستخدم VMkernel Swap ، فعند تحليل مشاكل الأداء ، فمن المستحسن أن ننظر إلى٪ VMWAIT ، لأن هذا المقياس لا يأخذ في الاعتبار الوقت الذي لم يفعل فيه VM شيئًا (٪ IDLE).
٪ RDY - إلى متى كانت العملية في حالة استعداد خلال فترة القياس.
٪ CSTP - إلى متى كانت العملية في حالة النشر أثناء فترة القياس.
٪ MLMTD - كم من الوقت خلال فترة قياس vCPU كان في حالة استعداد بسبب حد المورد المحدد.
٪ WAIT +٪ RDY +٪ CSTP +٪ RUN = 100٪ - يكون جوهر VM دائمًا في إحدى هذه الحالات الأربع.
وحدة المعالجة المركزية على المشرف
هناك أيضًا عدادات أداء وحدة المعالجة المركزية لبرنامج hypervisor في vCenter ، لكنها لا تمثل أي شيء مثير للاهتمام - إنها مجرد مجموع عدادات جميع أجهزة VM على الخادم.
الطريقة الأكثر ملاءمة لرؤية حالة وحدة المعالجة المركزية على الخادم هي في علامة تبويب الملخص:

بالنسبة للخادم ، وكذلك بالنسبة للجهاز الظاهري ، يوجد إنذار قياسي:
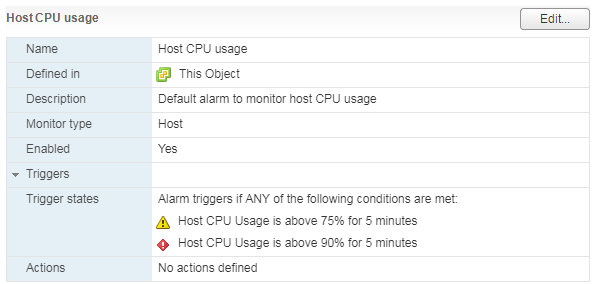
بفضل التحميل الكبير على وحدة المعالجة المركزية للخادم ، تبدأ أجهزة VM التي تعمل بها في مواجهة مشكلات الأداء.
في ESXTOP ، يتم تقديم بيانات استخدام وحدة المعالجة المركزية للخادم في الجزء العلوي من الشاشة. بالإضافة إلى تحميل وحدة المعالجة المركزية القياسية ، وهو أمر غير مهم بالنسبة لبرنامج Hypervisor ، هناك ثلاثة مقاييس أخرى:
CORE UTIL (٪) - تحميل جوهر الخادم الفعلي. يوضح هذا العداد الوقت الذي تستغرقه النواة في العمل خلال فترة القياس.
PCPU UTIL (٪) - إذا تم تمكين الترابط التشعبي ، فسيكون هناك موضوعان (PCPU) لكل جوهر فعلي. يوضح هذا المقياس مقدار الوقت الذي استغرقه كل مؤشر ترابط في العمل.
PCPU USED (٪) هو نفس PCPU UTIL (٪) ، لكنه يأخذ في الاعتبار تحجيم التردد (إما خفض التردد الأساسي لتوفير الطاقة أو زيادة التردد الأساسي بسبب تقنية Turbo Boost) والخيوط المفرطة.
PCPU_USED٪ = PCPU_UTIL٪ * التردد الأساسي الفعال / التردد الأساسي الاسمي.
 في هذه الصورة ، بالنسبة إلى بعض النوى ، بسبب تشغيل Turbo Boost ، فإن قيمة USED تزيد عن 100٪ ، لأن التردد الأساسي أعلى من القيمة الاسمية.
في هذه الصورة ، بالنسبة إلى بعض النوى ، بسبب تشغيل Turbo Boost ، فإن قيمة USED تزيد عن 100٪ ، لأن التردد الأساسي أعلى من القيمة الاسمية.بضع كلمات حول كيفية أخذ فرط الترابط في الاعتبار. إذا كانت العمليات تعمل بنسبة 100٪ من الوقت على كلا خيوط النواة الفعلية للخادم ، في حين أن النواة تعمل على التردد الاسمي ، إذن:
- CORE UTIL للنواة سيكون 100 ٪ ،
- PCPU UTIL لكلا المواضيع سيكون 100 ٪ ،
- سوف تستخدم PCED لكلا خيوط يكون 50 ٪.
إذا لم يعمل كلا الخيوط بنسبة 100٪ من الوقت خلال فترة القياس ، ثم في تلك الفترات التي عملت فيها الخيوط بشكل متوازٍ ، يتم تقسيم PCPU المستخدم للنوى إلى نصفين.
يحتوي ESXTOP أيضًا على شاشة مع معلمات استهلاك الطاقة لخادم وحدة المعالجة المركزية. هنا يمكنك معرفة ما إذا كان الخادم يستخدم تقنيات توفير الطاقة: حالات C و P. يتم الاتصال بواسطة المفتاح p:

مشاكل أداء وحدة المعالجة المركزية الشائعة
أخيرًا ، سأذهب لأسباب نموذجية لمشاكل في أداء وحدة المعالجة المركزية VM وإعطاء نصائح قصيرة لحلها:
لا يكفي سرعة الساعة الأساسية. إذا لم تكن هناك طريقة لنقل أجهزة VM إلى حبات أكثر كفاءة ، يمكنك محاولة تغيير إعدادات الطاقة لجعل Turbo Boost يعمل بكفاءة أكبر.
التحجيم غير الصحيح لـ VM (عدد كبير جدًا / قليل من النوى). إذا وضعت القليل من النوى ، سيكون هناك حمل كبير على وحدة VM CPU. إذا كان الكثير ، قبض على وقف المشترك عالية.
زيادة كبيرة على وحدة المعالجة المركزية على الخادم. إذا كان جهاز VM جاهزًا بشكل كبير ، قم بتقليل الزيادة في الاشتراك على وحدة المعالجة المركزية.
طوبولوجيا NUMA الخاطئة على الأجهزة الظاهرية الكبيرة. يجب أن يتطابق طوبولوجيا NUMA التي يراها VM (vNUMA) مع طوبولوجيا خادم NUMA (pNUMA). حول التشخيص والحلول الممكنة لهذه المشكلة مكتوبة ، على سبيل المثال ، في كتاب
"VMware vSphere 6.5 Host Resources Deep Dive" . , , . :)
CPU . .
.