يعد التعرف على شخص ما هو أحد أقدم الأفكار للتعرف على الأشخاص الذين حاولوا عمومًا تنفيذه تقنيًا. يمكن سرقة كلمات المرور أو التجسس عليها أو نسيانها ، ويمكن تزوير المفاتيح. لكن الخصائص الفريدة للشخص نفسه يصعب تزويرها وفقدانها. يمكن أن يكون ذلك بصمات أصابع وصوت ورسم لأوعية الشبكية ومشية وغير ذلك.

بالطبع ، أنظمة القياسات الحيوية تحاول خداع! هذا ما سنتحدث عنه اليوم. كيف يحاول المهاجمون التحايل على أنظمة التعرف على الوجه من خلال انتحال شخصية شخص آخر وكيف يمكن اكتشاف ذلك.
يمكنك مشاهدة نسخة فيديو من هذه القصة هنا ، وأولئك الذين يفضلون القراءة للعرض ، أدعوكم إلى المتابعة
وفقًا لأفكار مديري هوليود وكتاب الخيال العلمي ، من السهل جدًا خداع التعريف الحيوي. من الضروري فقط تقديم "الأجزاء المطلوبة" للنظام إلى المستخدم الحقيقي ، سواء بشكل فردي أو عن طريق أخذه كرهينة. أو يمكنك "وضع قناع" لشخص آخر على نفسك ، على سبيل المثال ، باستخدام قناع زرع طبيعي أو بشكل عام ، تقديم علامات وراثية كاذبة
في الحياة الحقيقية ، يحاول المهاجمون أيضًا تقديم أنفسهم كشخص آخر. على سبيل المثال ، سرقة أحد البنوك من خلال ارتداء قناع الرجل الأسود ، كما في الصورة أدناه.

يبدو التعرف على الوجوه مجالًا واعدًا جدًا للاستخدام في قطاع الأجهزة المحمولة. إذا كان الجميع معتادًا منذ فترة طويلة على استخدام بصمات الأصابع ، وكانت تقنية الصوت تتطور بشكل تدريجي ومنصف إلى حد ما ، ثم مع تحديد الوجه ، تطور الموقف بشكل غير عادي ويستحق القليل من الانحدار في تاريخ المشكلة.
كيف بدأ كل شيء أو من الخيال إلى الواقع
أنظمة التعرف اليوم تثبت دقة هائلة. مع ظهور مجموعات البيانات الكبيرة والمعماريات المعقدة ، أصبح من الممكن تحقيق دقة التعرف على الوجوه حتى 0.000001 (خطأ واحد لكل مليون!) وهي الآن مناسبة للنقل إلى المنصات المحمولة. وكان عنق الزجاجة ضعفهم.
من أجل انتحال شخصية شخص آخر في واقعنا التقني ، وليس في الفيلم ، يتم استخدام الأقنعة في أغلب الأحيان. يحاولون أيضًا خداع نظام الكمبيوتر عن طريق تقديم شخص آخر بدلاً من وجوههم. يمكن أن تكون الأقنعة بجودة مختلفة تمامًا ، بدءًا من صورة شخص آخر مطبوعًا على الوجه الذي تتم طباعته على الطابعة إلى أقنعة ثلاثية الأبعاد معقدة للغاية مع التدفئة. يمكن تقديم الأقنعة بشكل منفصل في شكل ورقة أو شاشة ، أو تلبس على الرأس.
تم لفت الانتباه إلى الموضوع من خلال محاولة ناجحة لخداع نظام Face ID على iPhone X بقناع معقد من مسحوق الحجر مع إدخالات خاصة حول العينين تقلد دفء الوجه الحي باستخدام الأشعة تحت الحمراء.
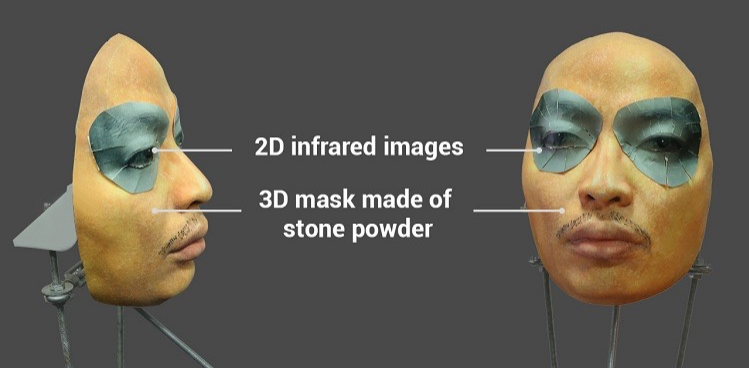
يزعم أنه باستخدام مثل هذا القناع كان من الممكن خداع Face ID على iPhone X. ويمكن العثور على بعض النص هنا
يعد وجود هذه الثغرات أمرًا خطيرًا للغاية بالنسبة للأنظمة المصرفية أو أنظمة الدولة لمصادقة المستخدم وجهًا ، حيث ينطوي تغلغل المهاجم على خسائر كبيرة.
مصطلحات
مجال البحث عن مكافحة الخداع في الوجه جديد تمامًا ، وحتى الآن لا يمكن حتى التفاخر بمصطلحات ثابتة.
دعونا نوافق على استدعاء محاولة لخداع نظام تحديد الهوية من خلال تقديمه مع معلمة القياس الحيوي وهمية (في هذه الحالة ، شخص) هجوم خداع .
تبعا لذلك ، فإن مجموعة من التدابير الوقائية لمواجهة هذا الخداع ستسمى مكافحة الغش . يمكن تنفيذه في شكل مجموعة متنوعة من التقنيات والخوارزميات المدمجة في ناقل نظام تحديد الهوية.
تقدم ISO مجموعة موسعة قليلاً من المصطلحات ، مع مصطلحات مثل هجوم العرض التقديمي - محاولات لجعل النظام يقوم بتعريف المستخدم بطريقة غير صحيحة أو السماح له بتجنب التعريف عن طريق إظهار صورة ومقاطع فيديو مسجلة وما إلى ذلك. عادي (Bona Fide) - يتوافق مع الخوارزمية المعتادة للنظام ، أي كل شيء ليس هجومًا. أداة هجوم العرض التقديمي تعني وسيلة للهجوم ، على سبيل المثال ، جزء مصطنع من الجسم. وأخيراً ، كشف هجوم العرض التقديمي - وسيلة تلقائية للكشف عن مثل هذه الهجمات. ومع ذلك ، لا تزال المعايير نفسها قيد التطوير ، لذلك من المستحيل التحدث عن أي مفاهيم ثابتة. المصطلحات باللغة الروسية غائبة تمامًا تقريبًا.
لتحديد جودة العمل ، غالبًا ما تستخدم الأنظمة مقياس HTER (نصف معدل الخطأ الإجمالي - نصف الخطأ الكلي) ، والذي يتم حسابه على أنه مجموع معاملات التعريفات المسموح بها عن طريق الخطأ (FAR - معدل القبول الخاطئ) والتعريفات الممنوعة عن طريق الخطأ (FRR - معدل الرفض الخاطئ) ، مقسمة في النصف.
HTER = (FAR + FRR) / 2
تجدر الإشارة إلى أنه في الأنظمة البيومترية ، عادة ما يتم إعطاء FAR أقصى الاهتمام ، من أجل القيام بكل ما هو ممكن لمنع المهاجم من دخول النظام. وهم يحرزون تقدماً جيداً في هذا (تذكروا المليون من بداية المقال؟) الجانب الآخر هو الزيادة الحتمية في FRR - عدد المستخدمين العاديين الذين تم تصنيفهم عن طريق الخطأ على أنهم دخيلون. إذا كان من الممكن التضحية بهذا من أجل أنظمة الدولة والدفاع وأنظمة أخرى مماثلة ، فستكون التقنيات المحمولة التي تعمل بمقياسها الهائل ومجموعة متنوعة من أجهزة المشتركين ، وبشكل عام ، الأجهزة الموجهة من منظور المستخدم ، حساسة جدًا لأي عوامل يمكن أن تجعل المستخدمين يرفضون الخدمات. إذا كنت ترغب في تقليل عدد الهواتف المحطمة على الحائط بعد رفض الهوية العاشر على التوالي ، فيجب عليك الانتباه إلى FRR!
أنواع الهجمات. نظام الغش

دعونا أخيرًا نكتشف بالضبط كيف يخاد المهاجمون نظام التعرف ، وكذلك كيف يمكن معارضة ذلك.
الأكثر شعبية وسائل الغش والأقنعة. لا يوجد شيء أكثر وضوحًا من وضع قناع شخص آخر وتقديم وجهك إلى نظام تحديد الهوية (يشار إليه غالبًا باسم هجوم القناع).
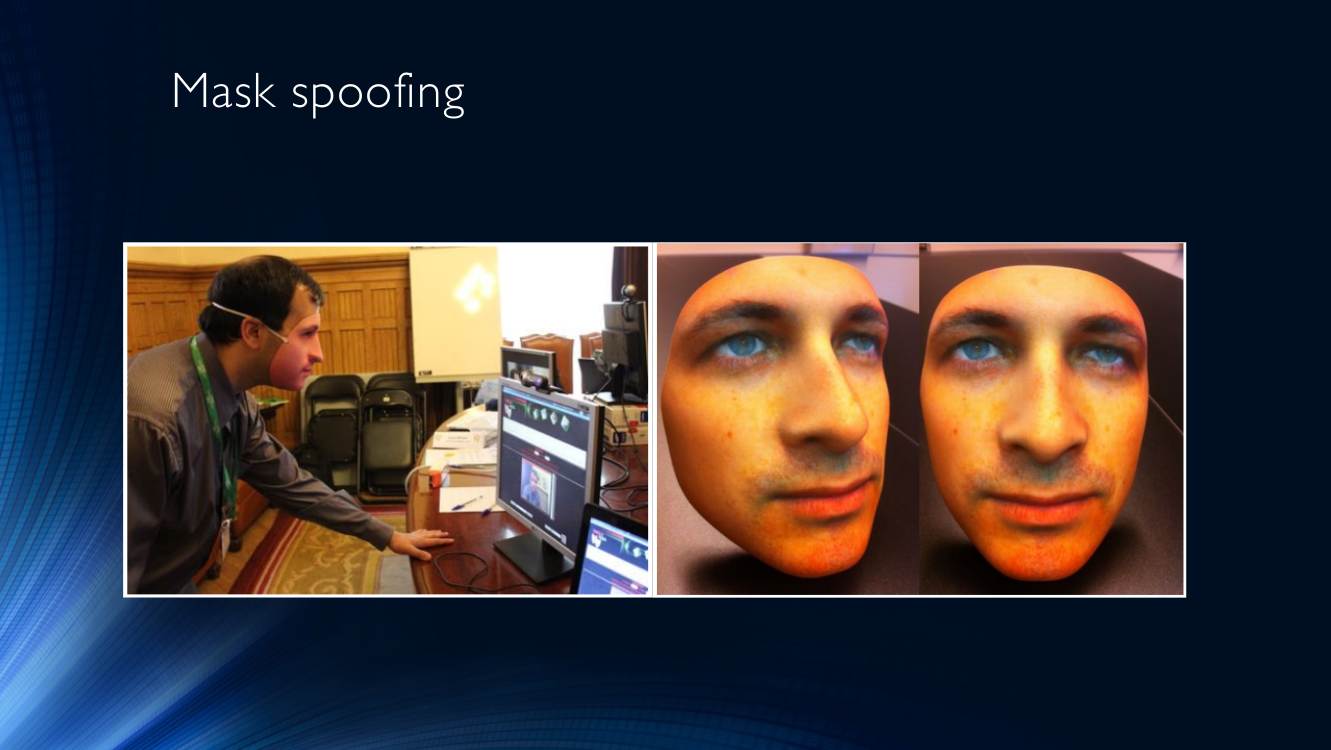
يمكنك أيضًا طباعة صورة لنفسك أو لشخص آخر على قطعة من الورق وإحضارها إلى الكاميرا (دعنا نسمي هذا النوع من الهجوم الهجوم المطبوع).

الأمر الأكثر تعقيدًا هو هجوم إعادة التشغيل ، عندما يتم عرض النظام على شاشة جهاز آخر يتم تشغيل مقطع فيديو مسجل عليه مسبقًا مع شخص آخر. يتم تعويض مدى تعقيد التنفيذ من خلال الكفاءة العالية لمثل هذا الهجوم ، نظرًا لأن أنظمة التحكم غالبًا ما تستخدم العلامات المستندة إلى تحليل تسلسل الوقت ، على سبيل المثال ، تتبع الوامض ، والحركات الدقيقة للرأس ، ووجود تعبيرات الوجه ، والتنفس ، وما إلى ذلك. كل هذا يمكن استنساخها بسهولة على الفيديو.

يحتوي كلا النوعين من الهجمات على عدد من الميزات المميزة التي تجعل من الممكن اكتشافهما ، وبالتالي التمييز بين شاشة الكمبيوتر اللوحي أو ورقة من شخص حقيقي.
نلخص الخصائص المميزة التي تسمح لنا بتحديد هذين النوعين من الهجمات في جدول:
خوارزميات الكشف عن الهجوم. الكلاسيكية القديمة الجيدة

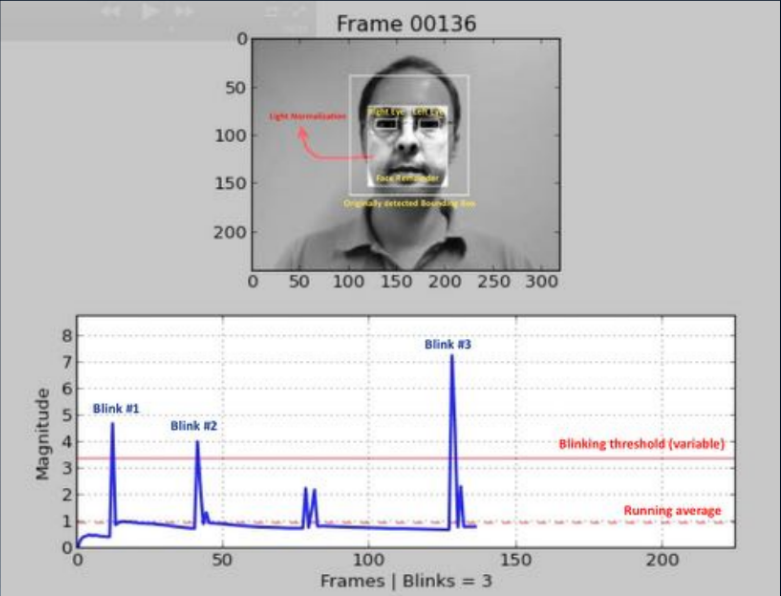
يستند أحد أقدم الأساليب (2007 ، 2008) إلى اكتشاف يومض بشري عن طريق تحليل الصورة باستخدام قناع. النقطة المهمة هي بناء نوع من المصنف الثنائي الذي يسمح لك بتحديد الصور بعيون مفتوحة ومغلقة في سلسلة من الإطارات. يمكن أن يكون هذا تحليلًا لدفق الفيديو باستخدام تحديد أجزاء الوجه (اكتشاف المعالم) ، أو استخدام شبكة عصبية بسيطة. واليوم تستخدم هذه الطريقة في الغالب ؛ تتم مطالبة المستخدم بأداء سلسلة من الإجراءات: أدر رأسك ، وغمز ، وابتسامة ، وأكثر من ذلك. إذا كان التسلسل عشوائيًا ، فليس من السهل على المهاجم الاستعداد له مسبقًا. لسوء الحظ ، بالنسبة للمستخدم الصادق ، فإن هذا البحث لا يمكن التغلب عليه دائمًا ، كما أن المشاركة تنخفض بشكل حاد.
يمكنك أيضًا استخدام ميزات التدهور في جودة الصورة عند الطباعة أو اللعب على الشاشة. على الأرجح ، سيتم الكشف عن بعض الأنماط المحلية ، حتى لو كانت بعيدة المنال من العين ، في الصورة. يمكن القيام بذلك ، على سبيل المثال ، عن طريق حساب الأنماط الثنائية المحلية (LBP ، النمط الثنائي المحلي) لمناطق مختلفة من الوجه بعد تحديده من الإطار ( PDF ). يمكن اعتبار النظام الموصوف مؤسس الاتجاه الكامل لخوارزميات مكافحة الخداع على أساس تحليل الصورة. باختصار ، عند حساب LBP ، كل بكسل في الصورة ، يتم التقاط ثمانية من جيرانها بالتسلسل ومقارنة شدتها. إذا كانت الكثافة أكبر من البكسل المركزي ، يتم تعيين واحد ، إذا كان أقل ، صفر. وبالتالي ، يتم الحصول على تسلسل 8 بت لكل بكسل. استنادًا إلى التسلسلات التي تم الحصول عليها ، يتم إنشاء رسم بياني لكل بكسل ، يتم تغذيته إلى مدخلات مصنف SVM.
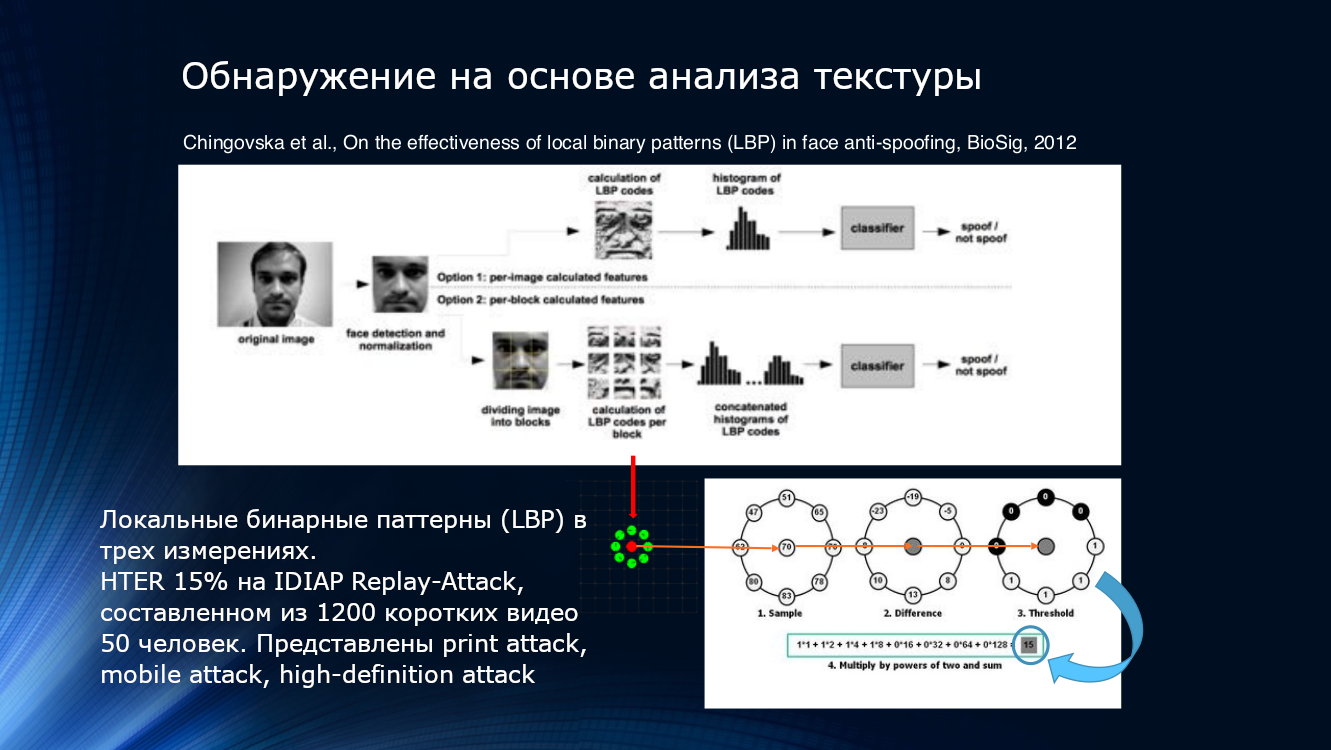
أنماط ثنائية المحلية ، الرسم البياني و SVM. يمكنك الانضمام إلى الكلاسيكية الخالدة هنا
مؤشر كفاءة HTER هو "بقدر" 15 ٪ ، وهذا يعني أن جزءا كبيرا من المهاجمين يتغلبون على الحماية دون بذل الكثير من الجهد ، على الرغم من أنه ينبغي الاعتراف بأنه تم القضاء على الكثير. تم اختبار الخوارزمية على مجموعة بيانات IDIAP Replay-Attack ، التي تتألف من 1200 مقطع فيديو قصير من 50 مجيبًا وثلاثة أنواع من الهجمات - الهجوم المطبوع والهجوم على الأجهزة المحمولة والهجوم عالي الدقة.
استمرت أفكار تحليل نسيج الصورة. في عام 2015 ، طوّر بوكينيفيت خوارزمية لتقسيم الصورة بدلاً من ذلك إلى قنوات ، بالإضافة إلى RGB التقليدي ، من أجل النتائج التي تم فيها حساب الأنماط الثنائية المحلية مرة أخرى ، والتي ، كما في الطريقة السابقة ، تم إدخالها في مدخلات مصنف SVN. كانت دقة HTER ، المحسوبة على مجموعات بيانات CASIA و Replay-Attack ، مثيرة للإعجاب في ذلك الوقت 3٪.
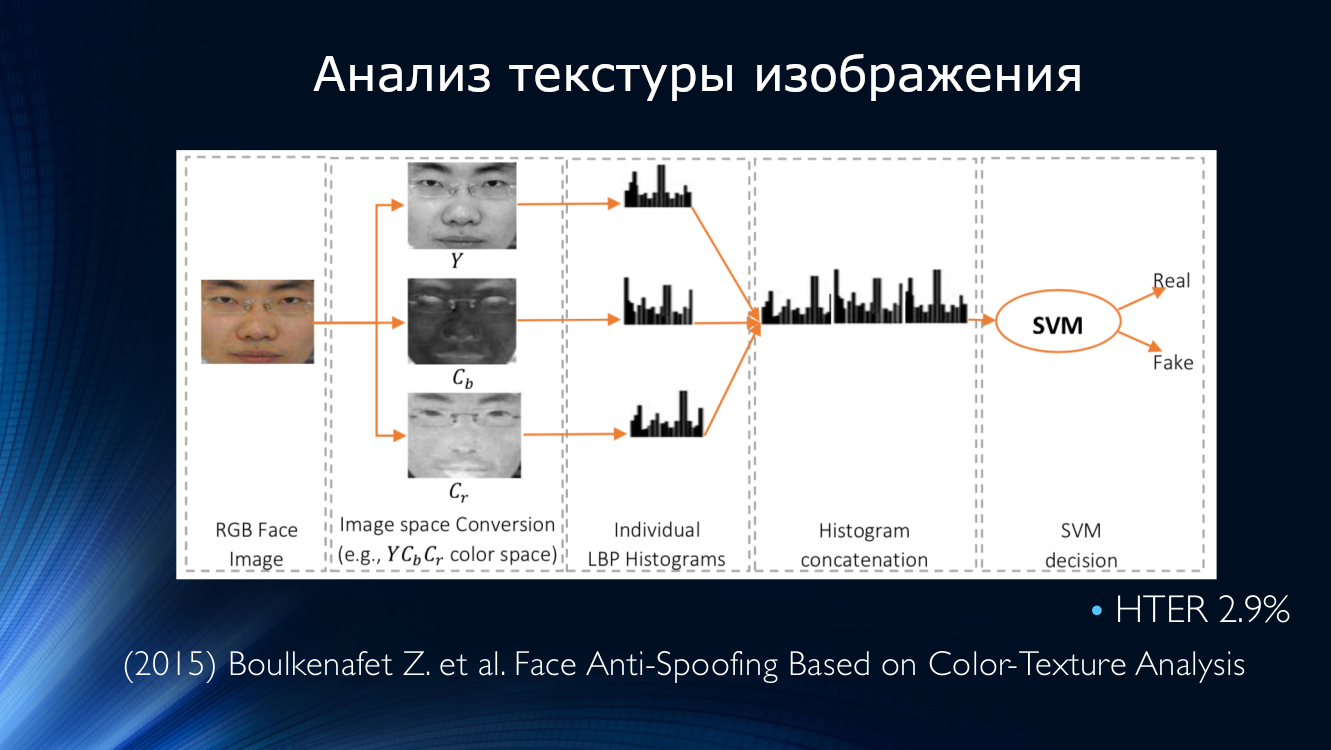
في الوقت نفسه ، ظهر العمل على الكشف عن تموج في النسيج. نشر باتيل مقالًا اقترح فيه البحث عن قطع أثرية للصور في شكل نقش دوري سببه تداخل المسحين. تبين أن هذا النهج عملي ، حيث أظهر نسبة HTER حوالي 6٪ على مجموعات بيانات IDIAP و CASIA و RAFS. كانت أيضًا المحاولة الأولى لمقارنة أداء الخوارزمية على مجموعات بيانات مختلفة.

نمط دوري في الصورة ناتج عن عمليات مسح التراكب
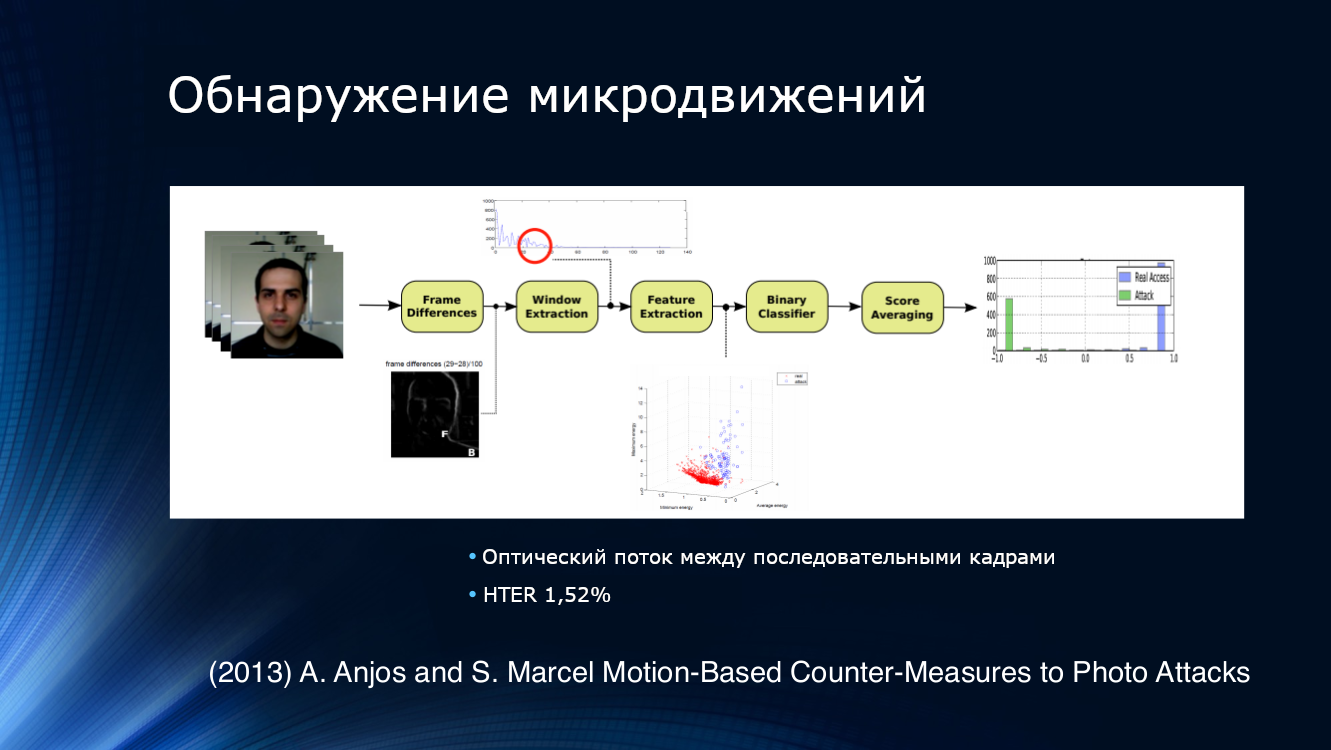
للكشف عن محاولات تقديم الصور ، كان الحل المنطقي هو محاولة تحليل ليس صورة واحدة ، ولكن تسلسلها مأخوذ من دفق الفيديو. على سبيل المثال ، اقترح أنجوس وزملاؤه عزل الميزات عن التيار البصري في أزواج متجاورة من الإطارات ، وإطعام المصنف الثنائي للإدخال ، وتوسيط النتائج. اتضح أن النهج كان فعالا للغاية ، حيث أظهر معدل HTER بنسبة 1.52 ٪ على مجموعة البيانات الخاصة بهم.
طريقة مثيرة للاهتمام لتتبع الحركات ، والتي هي بمعزل إلى حد ما عن النهج التقليدية. منذ عام 2013 ، لم يكن مبدأ "تطبيق صورة أولية على مدخلات الشبكة التلافيفية وضبط طبقات الشبكة للحصول على النتيجة" أمرًا معتادًا بالنسبة للمشروعات الحديثة في مجال التعليم العميق ، فقد طبق Bharadzha باستمرار تحولات أولية أكثر تعقيدًا. على وجه الخصوص ، استخدم خوارزمية تكبير الفيديو Eulerian المعروفة بعمل علماء من معهد ماساتشوستس للتكنولوجيا ، والتي استخدمت بنجاح لتحليل التغيرات اللونية في الجلد اعتمادا على النبض. لقد استبدلت LBP بـ HOOF (الرسوم البيانية لاتجاهات التدفق البصري) ، بعد أن لاحظت بشكل صحيح أنه بما أننا نريد تتبع الحركات ، فنحن بحاجة إلى علامات مناسبة ، وليس فقط تحليل الملمس. تم استخدام نفس SVM ، التقليدية في ذلك الوقت ، كمصنف. أظهرت الخوارزمية نتائج رائعة للغاية على مجموعات البيانات Print Attack (0٪) و Replay Attack (1.25٪).

دعونا نتعلم بالفعل الشبكة!

من مرحلة ما أصبح من الواضح أن الانتقال إلى التعلم العميق قد نضج. تفوقت "ثورة التعلم العميقة" سيئة السمعة على مكافحة الخداع.
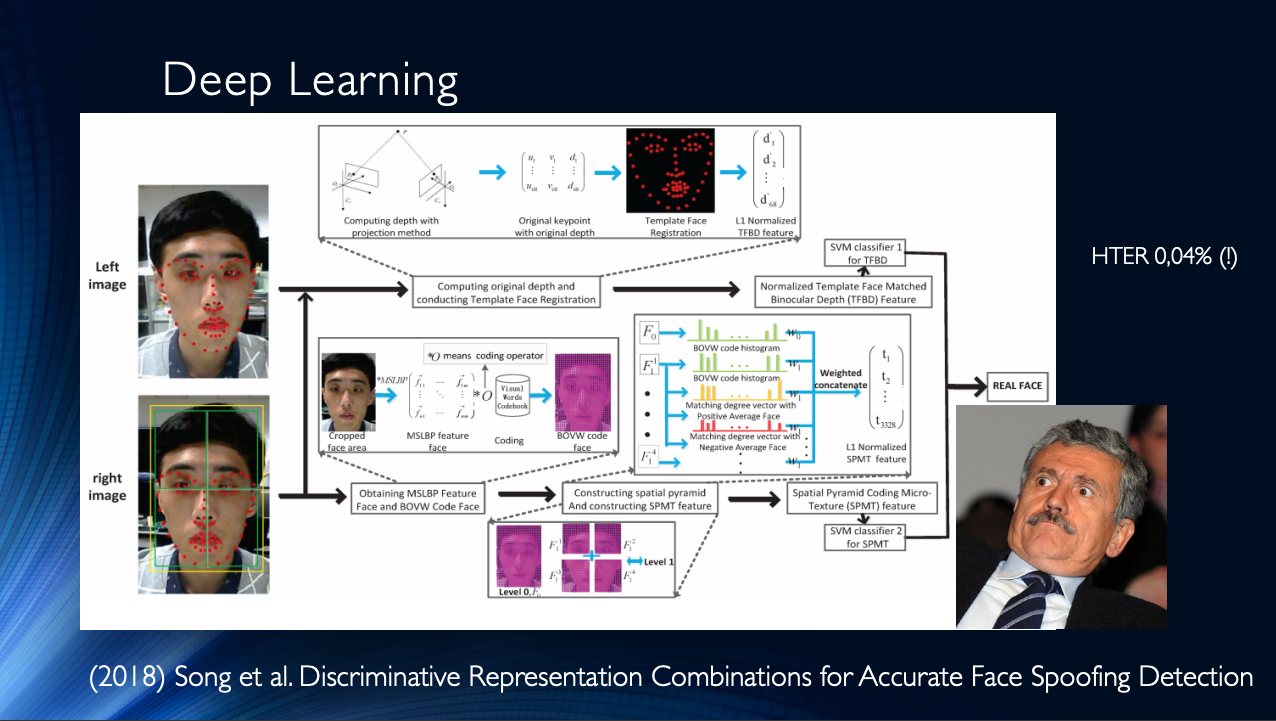
يمكن اعتبار "السنونو الأول" طريقة لتحليل خرائط العمق في أقسام فردية ("تصحيحات") من الصورة. من الواضح أن الخريطة العميقة هي علامة جيدة جدًا لتحديد المستوى الذي توجد به الصورة. إذا كان ذلك فقط لأن الصورة على ورقة لا يوجد بها "عمق" بحكم التعريف. في أعمال Ataum في عام 2017 ، تم استخراج العديد من الأقسام الصغيرة المنفصلة من الصورة ؛ تم حساب خرائط العمق لها ، والتي تم دمجها بعد ذلك مع خريطة عمق الصورة الرئيسية. تمت الإشارة إلى أن عشرة تصحيحات عشوائية لوجه الصورة تكفي لتحديد هوية مطبوعة مطبوعة بشكل موثوق. بالإضافة إلى ذلك ، جمع المؤلفون معًا نتائج شبكتين عصبيتين تلافيقيتين ، أولهما قاما بحساب خرائط العمق للبقع والثانية للصورة ككل. عند التدريب على مجموعات البيانات ، تم ربط فئة مطبوعة مطبوعة بخريطة عمق صفرية ، وارتبطت سلسلة من المقاطع المختارة عشوائياً بنموذج وجه ثلاثي الأبعاد. بشكل عام ، لم تكن خريطة العمق نفسها مهمة للغاية ، حيث تم استخدام وظيفة مؤشر معينة منها فقط ، والتي تميز "عمق القسم". وأظهرت الخوارزمية قيمة HTER من 3.78 ٪. تم استخدام ثلاث مجموعات بيانات عامة للتدريب - CASIA-MFSD و MSU-USSA و Replay-Attack.

لسوء الحظ ، أدى توفر عدد كبير من الأطر الممتازة للتعلم العميق إلى ظهور عدد كبير من المطورين الذين يحاولون "مواجهة" لحل مشكلة مكافحة الخداع بطريقة معروفة جيدًا لتجميع الشبكات العصبية. عادةً ما يبدو كأنه مجموعة من خرائط الميزات في مخرجات العديد من الشبكات التي تم تدريبها مسبقًا على مجموعة بيانات واسعة الانتشار يتم تغذيتها إلى مصنف ثنائي.
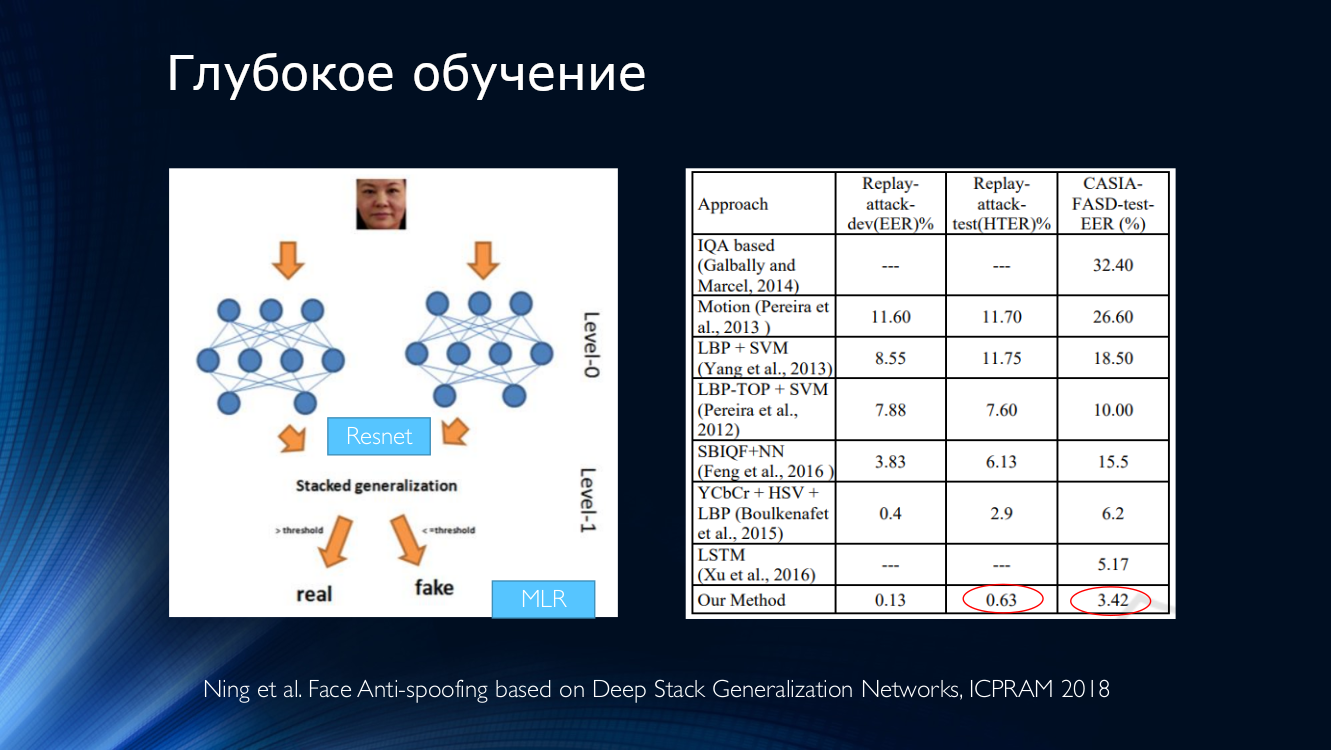
بشكل عام ، تجدر الإشارة إلى أنه حتى الآن ، تم نشر عدد غير قليل من الأعمال ، والتي تظهر بشكل عام نتائج جيدة ، والتي توحد فقط صغير واحد "لكن". وأظهرت كل هذه النتائج في مجموعة بيانات واحدة محددة! يتفاقم الموقف بسبب محدودية توافر مجموعات البيانات ، وعلى سبيل المثال ، في لعبة Replay-Attack سيئة السمعة ، فليس من المستغرب أن تكون نسبة HTER 0٪. كل هذا يؤدي إلى ظهور بنى معقدة للغاية ، مثل هذه ، باستخدام العديد من الميزات البارعة ، خوارزميات مساعدة مجمعة على المكدس ، مع العديد من المصنفات ، يتم حساب متوسط نتائجها ، وهكذا ... يحصل المؤلفون على HTER = 0.04٪ في المخرجات!
هذا يشير إلى أن مشكلة مكافحة الخداع في الوجه قد تم حلها ضمن مجموعة بيانات محددة. دعنا نجلب للطاولة مختلف الأساليب الحديثة القائمة على الشبكات العصبية. من السهل أن نرى أن "النتائج المرجعية" تحققت بطرق متنوعة للغاية لم تنشأ إلا في عقول المطورين المستفسرين.
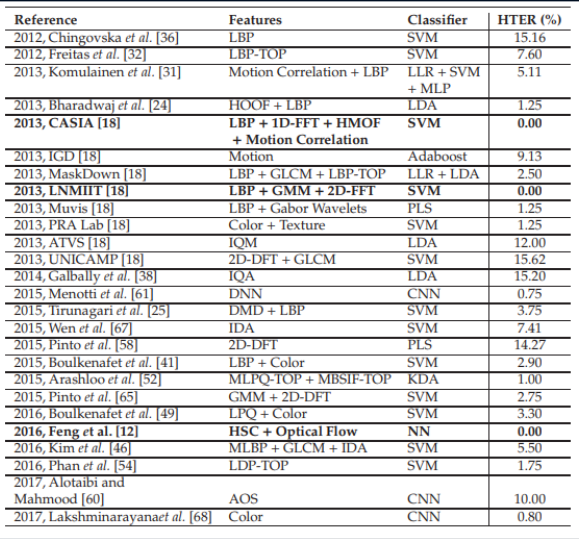
النتائج المقارنة لمختلف الخوارزميات. الجدول مأخوذ من هنا .
لسوء الحظ ، فإن نفس العامل "الصغير" ينتهك الصورة الجيدة للنضال من أجل عشرة في المئة. إذا حاولت تدريب الشبكة العصبية على مجموعة بيانات واحدة وتطبيقها على أخرى ، فستكون النتائج غير متفائلة. والأسوأ من ذلك أن محاولات تطبيق المصنفات في الحياة الواقعية لا تترك أي أمل على الإطلاق.
على سبيل المثال ، نأخذ البيانات من عام 2015 ، حيث تم استخدام مقياس لجودته لتحديد صحة الصورة المعروضة. ألقِ نظرة على نفسك:
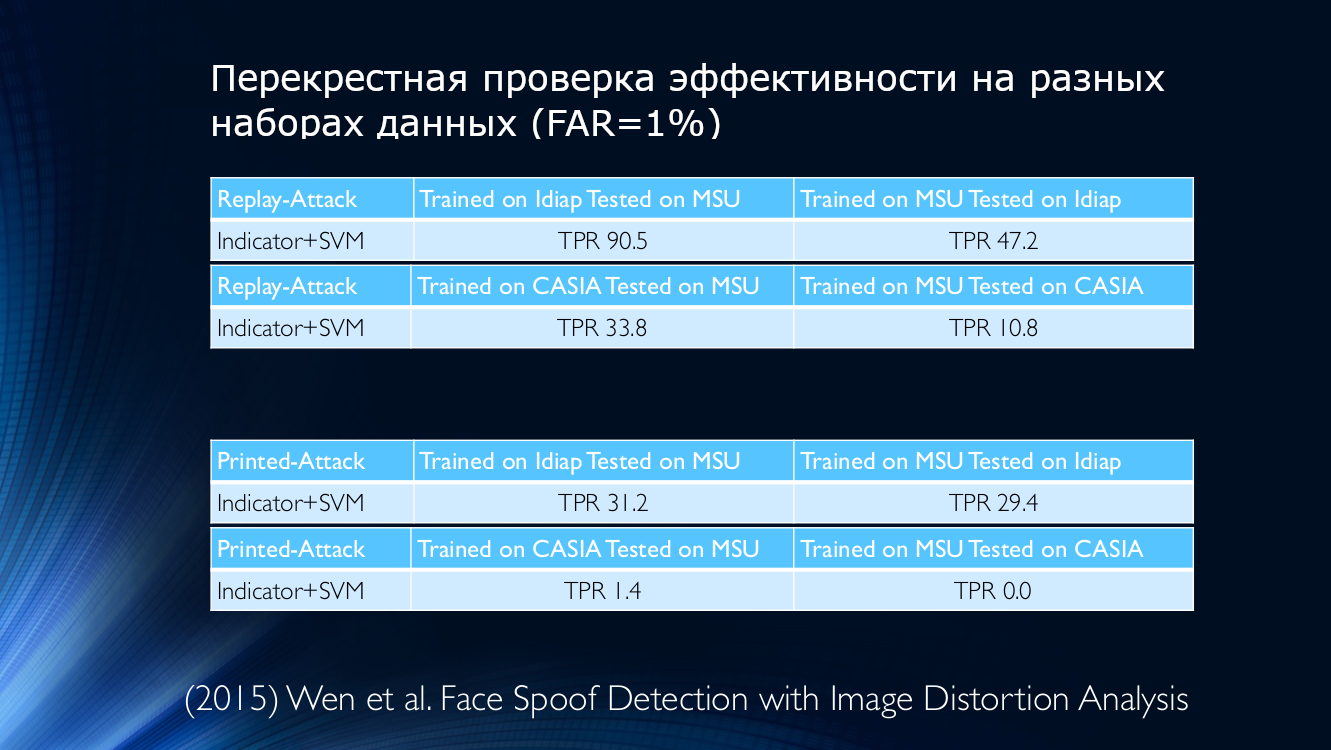
بمعنى آخر ، ستعطي خوارزمية مدربة على بيانات Idiap ، لكن يتم تطبيقها على جامعة ولاية ميشيغان ، معدل اكتشاف إيجابيًا حقيقيًا قدره 90.5 ٪ ، وإذا قمت بالعكس (تدريب على جامعة ولاية ميشيغان واختبار برنامج Idiap) ، فيمكن تحديد 47.2 فقط بشكل صحيح ٪ (!) بالنسبة للمجموعات الأخرى ، يزداد الموقف سوءًا ، على سبيل المثال ، إذا قمت بتدريب الخوارزمية على جامعة ولاية ميشيغان وتحقق منها على CASIA ، فإن TPR سيكون 10.8 ٪! هذا يعني أن عددًا كبيرًا من المستخدمين الشرفاء تم تعيينهم عن طريق الخطأ للمهاجمين ، وهو ما لا يمكن إلا أن يكون محبطًا. حتى التدريب عبر قواعد البيانات لا يمكنه عكس الموقف ، والذي يبدو أنه طريقة معقولة تمامًا للخروج.
دعونا نرى المزيد. تُظهر النتائج المقدمة في مقالة Patel 2016 أنه حتى مع وجود خطوط معالجة معقدة بدرجة كافية واختيار ميزات موثوقة مثل الوامض والملمس ، فإن النتائج على مجموعات بيانات غير مألوفة لا يمكن اعتبارها مرضية. لذلك ، في مرحلة ما أصبح من الواضح تمامًا أن الطرق المقترحة لم تكن كافية بشكل يائس لتلخيص النتائج.
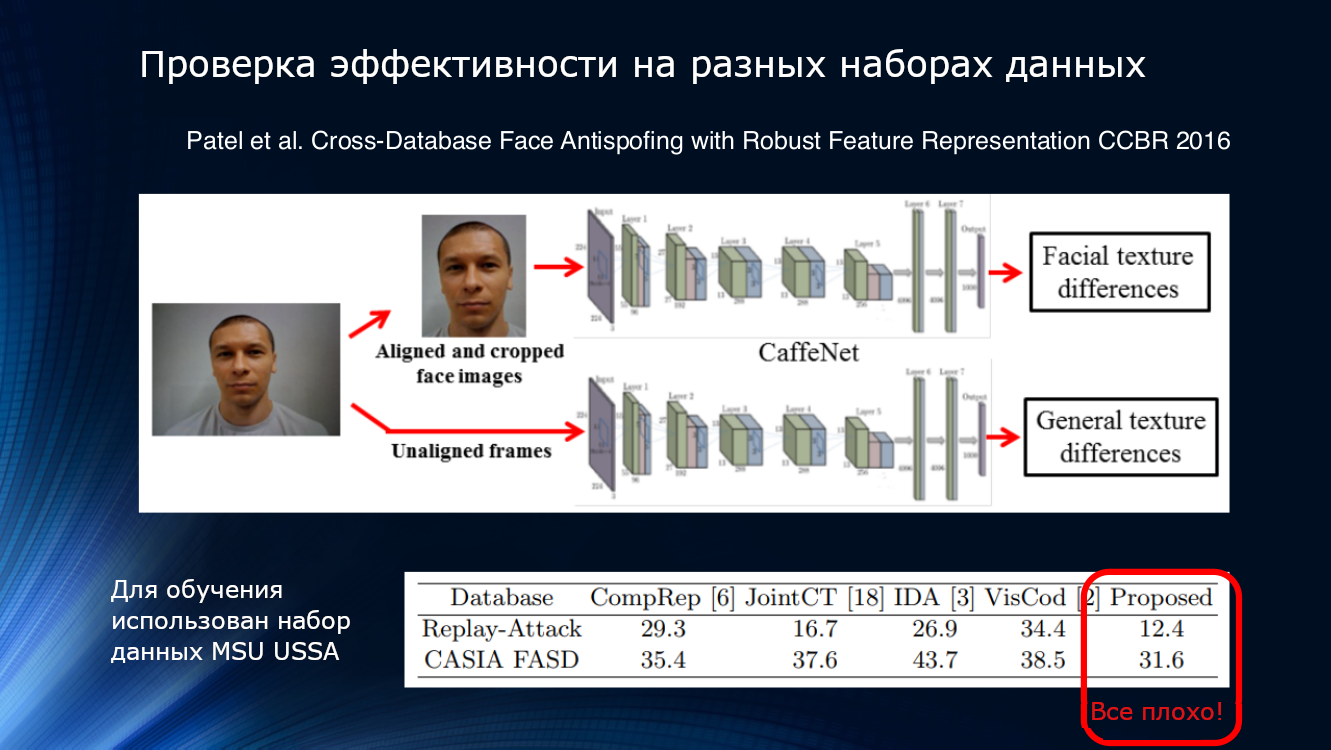
وإذا قمت بترتيب مسابقة ...
بالطبع ، في مجال مكافحة الخداع وجه كان لا يخلو من المنافسة. في عام 2017 ، عقدت مسابقة في جامعة أولو في فنلندا على مجموعة البيانات الجديدة الخاصة بها مع بروتوكولات مثيرة للاهتمام للغاية ، موجهة تحديداً للاستخدام في مجال تطبيقات الهاتف المحمول.
- البروتوكول 1: هناك فرق في الإضاءة والخلفية. يتم تسجيل مجموعات البيانات في أماكن مختلفة وتختلف في الخلفية والإضاءة.
-البروتوكول 2: تم استخدام نماذج مختلفة من الطابعات والشاشات للهجمات. لذلك ، في مجموعة بيانات التحقق ، يتم استخدام تقنية غير موجودة في مجموعة التدريب
البروتوكول 3: التبادلية لأجهزة الاستشعار. يتم تسجيل مقاطع الفيديو وهجمات المستخدمين الحقيقية على خمسة هواتف ذكية مختلفة وتستخدم في مجموعة بيانات التدريب. , .
- 4: .
. , , , - . , , 10%. :
GRADIENT
- ( HSV YCbCr), .
- .
- HSV YCbCr, . ROI (region-of-interest) 160×160 ..
- ROI 3×3 5×5 , LBP , 6018.
- (Recursive Feature Elimination) 6018 1000.
- SVM .|
SZCVI
Recod
- SqueezeNet Imagenet
- Transfer learning : CASIA UVAD
- 224×224 pixels. , , , CNN.
- .
CPqD
- Inception-v3, ImageNet
- C
- , , 224×224 RGB |
, . LBP, , , .. GRADIANT , , , . .
. , . -, ( 15 NUAA 1140 MSU-USSA) , , , , . , , , , . -, . , CASIA , . , , , , … , , , .
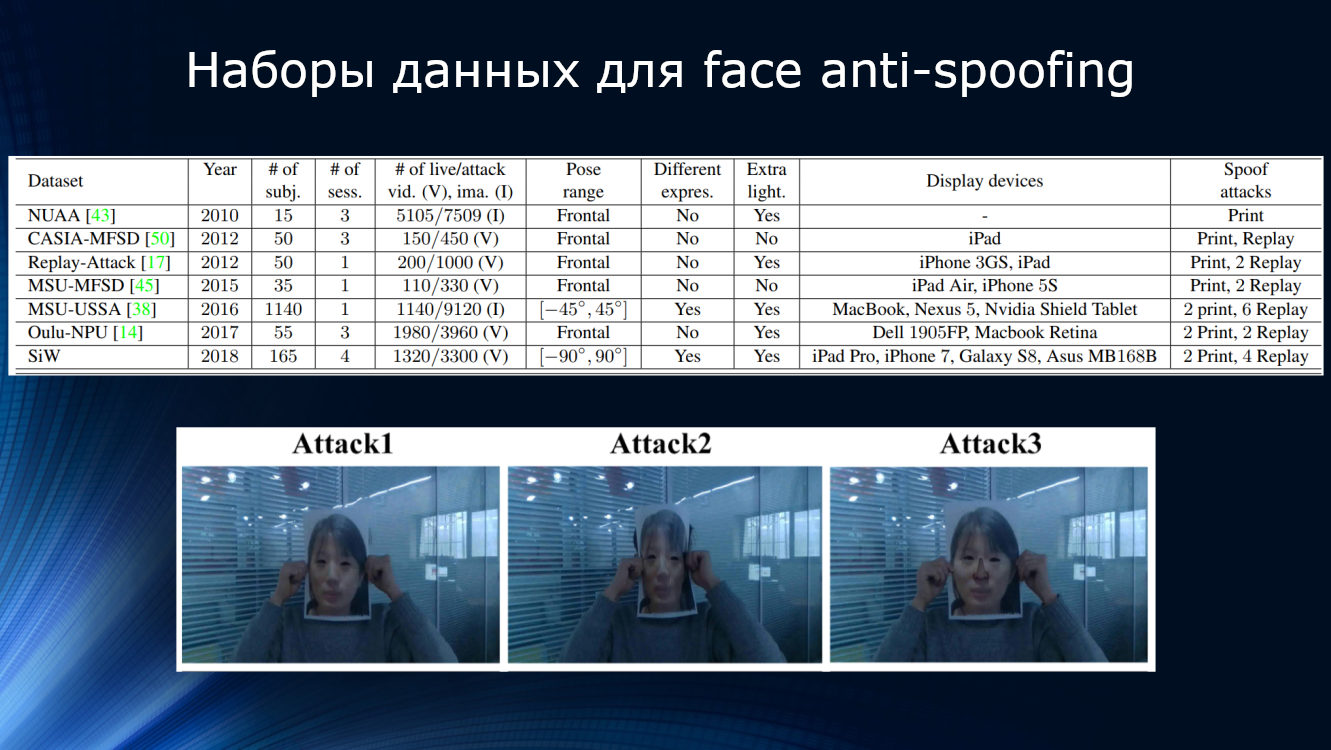
30 . , , . , .
, , « ». . , (rPPG – remote photoplethysmography), . , , -, – . . , , , . , , . , , , .


أظهر العمل قيمة HTER حوالي 10 ٪ ، مما يؤكد قابلية التطبيق الرئيسية لهذه الطريقة. هناك العديد من الأعمال التي تؤكد احتمالات هذا النهج.
(CVPR 2018) JH-Ortega et al. تحليل الوقت لل Pulsebased الوجه لمكافحة الغش في مرئية و NIR
(2016) X. Li. وآخرون. تعميم الوجه لمكافحة الغش عن طريق الكشف عن نبض من أشرطة الفيديو وجه
(2016) J. Chen et al. Realsense = معدل ضربات القلب الحقيقي: تقدير ثابت لمعدل ضربات القلب من مقاطع الفيديو
(2014) سعادة تسلي وآخرون. عن بعد PPG قياس علامة حيوية باستخدام مناطق الوجه على التكيف
في عام 2018 ، اقترح ليو وزملاؤه من جامعة ميشيغان التخلي عن التصنيف الثنائي لصالح النهج الذي يطلقون عليه "الإشراف الثنائي" - أي باستخدام تقدير أكثر تعقيدًا يعتمد على خريطة عميقة وتصوير ضوئي ضوئي بعيد. لكل من هذه الصور الوجه ، أعيد بناء نموذج ثلاثي الأبعاد باستخدام شبكة العصبية واسمه مع خريطة العمق. تم تعيين صور مزيفة على خريطة عميقة تتكون من أصفار ، في النهاية إنها مجرد قطعة من الورق أو شاشة الجهاز! تم اعتبار هذه الخصائص "حقيقة" ؛ حيث تم تدريب الشبكات العصبية على مجموعة بيانات SiW الخاصة بها. بعد ذلك ، تم تركيب قناع وجه ثلاثي الأبعاد على صورة الإدخال ، وتم حساب خريطة العمق والنبض لذلك ، وتم ربط كل ذلك معًا في ناقل معقد إلى حد ما. نتيجة لذلك ، أظهرت الطريقة دقة حوالي 10 بالمائة على مجموعة بيانات OULU التنافسية. ومن المثير للاهتمام ، أن الفائز في المسابقة التي نظمتها جامعة أولو قام ببناء الخوارزمية على أنماط التصنيف الثنائي ، والتتبع الوامض وغيرها من علامات "المصممة يدويًا" ، وكان دقة حلها أيضًا حوالي 10٪. وكان المكسب فقط حوالي نصف في المئة! يتم دعم التكنولوجيا المدمجة الجديدة من خلال حقيقة أن الخوارزمية تم تدريبها على مجموعة البيانات الخاصة بها ، وتم اختبارها على OULU ، مما أدى إلى تحسين نتيجة الفائز. يشير هذا إلى قابلية معينة لنقل النتائج من مجموعة البيانات إلى مجموعة البيانات ، وما لم يكن الجحيم مزاحًا ، فمن الممكن للحياة الحقيقية. ومع ذلك ، عند محاولة إجراء التدريب على مجموعات البيانات الأخرى - CASIA و ReplayAttack ، كانت النتيجة مرة أخرى حوالي 28 ٪. بالطبع ، هذا يتجاوز أداء الخوارزميات الأخرى عند التدريب على مجموعات البيانات المختلفة ، ولكن مع قيم الدقة هذه ، لا يمكن الحديث عن أي استخدام صناعي!
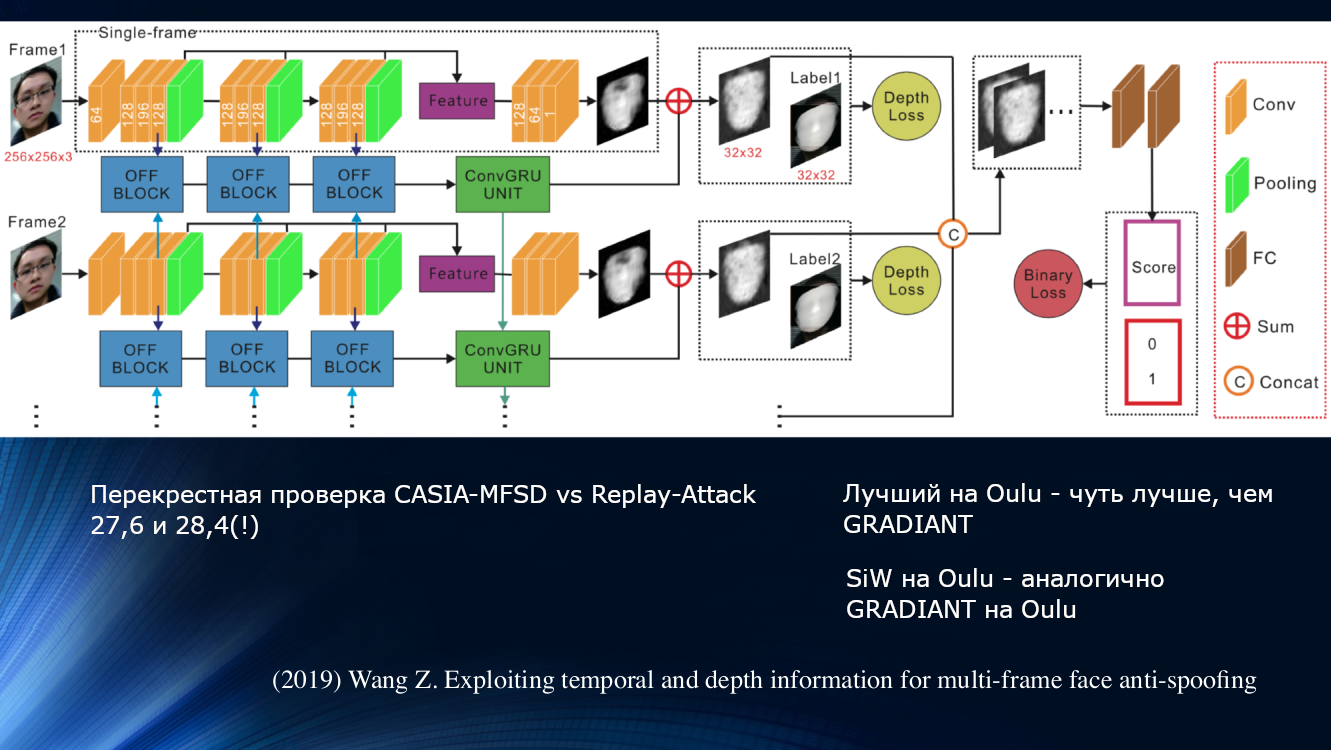
اقترح وانغ وزملاؤه مقاربة مختلفة في عمل حديث عام 2019. ولوحظ أنه عند تحليل التحفيز الدقيق للوجه ، فإن دوران وتشوهات الرأس تكون ملحوظة ، مما يؤدي إلى تغيير مميز في الزوايا والمسافات النسبية بين العلامات على الوجه. لذلك عندما يتم تحريك الوجه أفقياً ، تزداد الزاوية بين الأنف والأذن. لكن ، إذا قمت بتبديل ورقة مع صورة بنفس الطريقة ، فستقل الزاوية! للتوضيح ، يجدر بك اقتباس رسم من العمل.
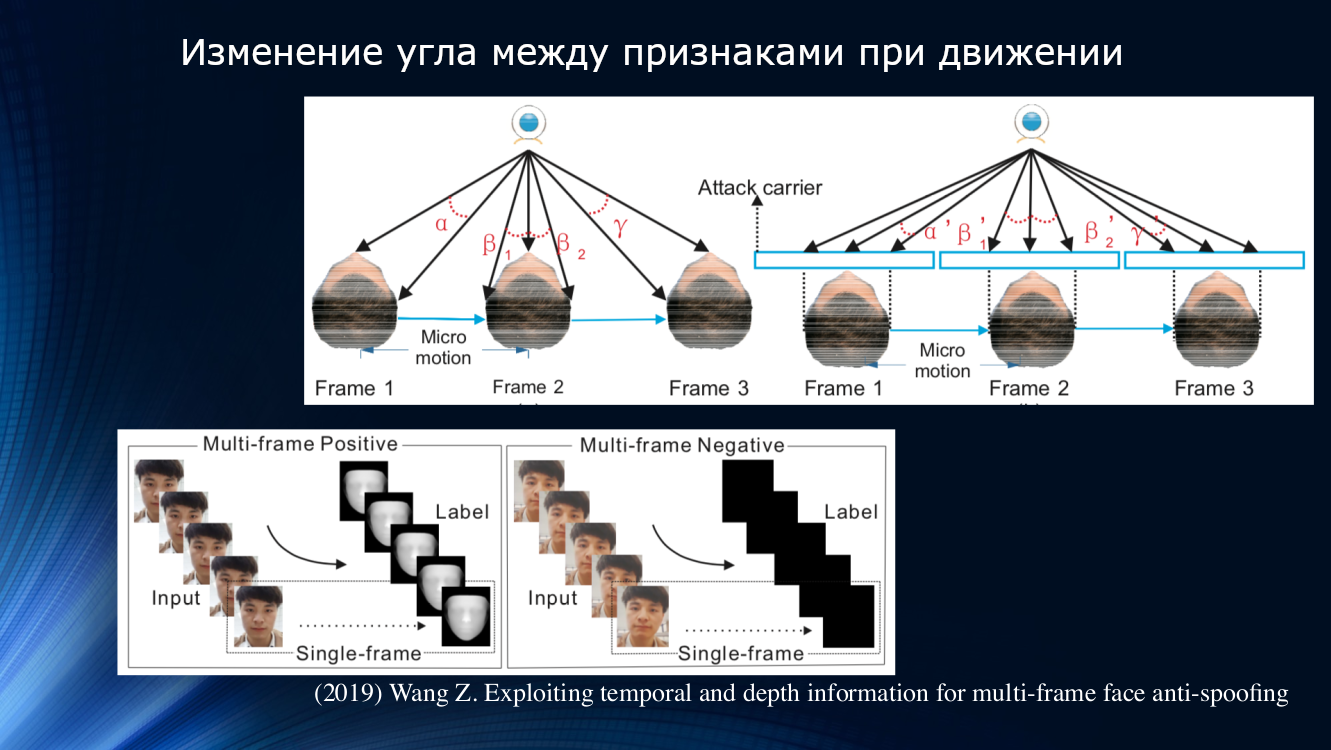
بناءً على هذا المبدأ ، بنى المؤلفون وحدة تعليمية كاملة لنقل البيانات بين طبقات الشبكة العصبية. وقد أخذ ذلك في الاعتبار "الإزاحات غير الصحيحة" لكل رتل في سلسلة من إطارين ، مما سمح باستخدام النتائج في المجموعة التالية من تحليل التبعية على المدى الطويل استنادًا إلى وحدة GRU Gated المتكررة . بعد ذلك تم ربط جميع العلامات ، وتم حساب وظيفة الخسارة ، وتم إجراء التصنيف النهائي. هذا سمح لنا بتحسين النتيجة على مجموعة بيانات OULU بشكل طفيف ، ولكن ظلت مشكلة الاعتماد على بيانات التدريب ، لأن الزوجين CASIA-MFSD و Replay-Attack كانا 17.5 و 24 بالمائة على التوالي.
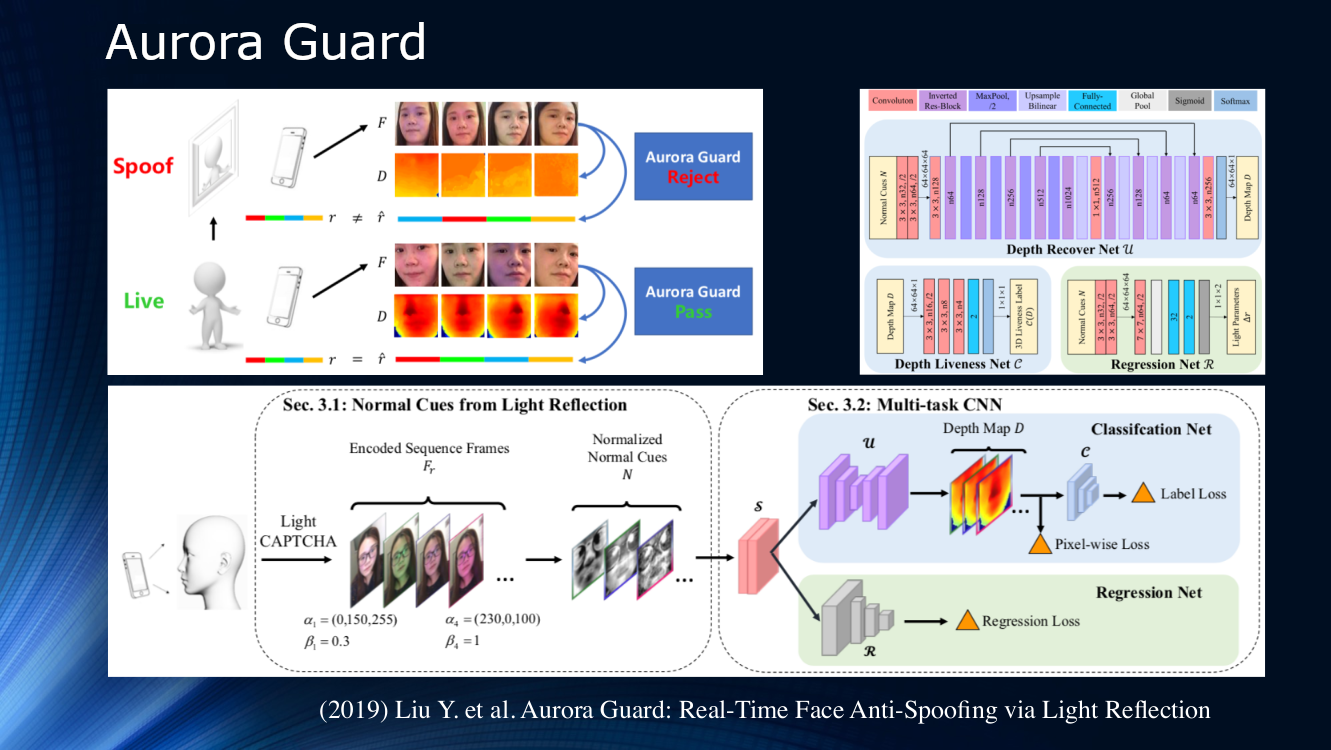
نحو النهاية ، تجدر الإشارة إلى عمل خبراء Tencent الذين اقترحوا تغيير طريقة تلقي صورة الفيديو الأصلية. بدلاً من مراقبة المشهد بشكل سلبي ، اقترحوا إلقاء الضوء بشكل ديناميكي على الوجه وقراءة الأفكار. منذ فترة طويلة مبدأ الإشعاع النشط للكائن مطبق في أنظمة الموقع بأنواعه المختلفة ، لذلك فإن استخدامه لدراسة الوجه يبدو منطقياً للغاية. من الواضح أنه لا يوجد عدد كافٍ من العلامات من أجل التعرف الموثوق في الصورة نفسها ، ويمكن أن تساعد إضاءة الهاتف أو شاشة الكمبيوتر اللوحي مع سلسلة من الرموز الضوئية (ضوء اختبار CAPTCHA وفقًا لمصطلحات المؤلفين) بشكل كبير. بعد ذلك ، يتم تحديد الفرق في التشتت والانعكاس على زوج من الإطارات ، ويتم تغذية النتائج على شبكة عصبية متعددة المهام لمزيد من المعالجة على خريطة العمق وحساب وظائف الخسارة المختلفة. في النهاية ، يتم إجراء انحدار إطارات الإضاءة الطبيعية. لم يحلل المؤلفون قدرة تعميم الخوارزمية على مجموعات البيانات الأخرى وقاموا بتدريبها على مجموعة البيانات الخاصة بهم. والنتيجة هي حوالي 1 ٪ ويذكر أن النموذج قد تم نشره بالفعل للاستخدام الحقيقي.
حتى عام 2017 ، لم تكن منطقة مكافحة الخداع في الوجه نشطة للغاية. لكن عام 2019 قدم بالفعل سلسلة كاملة من الأعمال ، والتي ترتبط بالترويج القوي لتقنيات التعرف على الوجه للجوّال ، من قبل شركة Apple أساسًا. بالإضافة إلى ذلك ، تهتم البنوك في تقنيات التعرف على الوجه. لقد جاء العديد من الأشخاص الجدد إلى هذه الصناعة ، مما يسمح لنا بالأمل في تحقيق تقدم سريع. لكن حتى الآن ، على الرغم من الألقاب الجميلة للمنشورات ، تظل القدرة على تعميم الخوارزميات ضعيفة للغاية ولا تسمح لنا بالتحدث عن أي ملاءمة للاستخدام العملي.
الاستنتاج. وأخيرا ، سأقول ذلك ...
- لم تفقد الأنماط الثنائية المحلية والتتبع الوامض والتنفس والحركات وغيرها من العلامات المصممة يدويًا أهميتها على الإطلاق. هذا يرجع في المقام الأول إلى حقيقة أن التدريب العميق في مجال مكافحة الخداع لا يزال ساذجًا للغاية.
- من الواضح أنه في الحل "نفسه" ، سيتم دمج عدة طرق. يجب استخدام تحليل الانعكاس والانتثار وخرائط العمق معًا. على الأرجح ، ستساعد إضافة قناة بيانات إضافية ، على سبيل المثال ، التسجيل الصوتي ونوع من أساليب النظام التي تتيح لك جمع العديد من التقنيات في نظام واحد
- تقريبًا جميع التقنيات المستخدمة في التعرف على الوجوه تجد تطبيقًا في مكافحة تزوير الوجه (غطاء!). كل شيء تم تطويره للتعرف على الوجوه ، بشكل أو بآخر ، قد وجد تطبيقًا لتحليل الهجوم
- وصلت مجموعات البيانات الحالية إلى التشبع. من بين عشرة مجموعات بيانات أساسية في خمس ، تم تحقيق خطأ صفر. يتحدث هذا بالفعل ، على سبيل المثال ، عن كفاءة الطرق المعتمدة على خرائط العمق ، لكنه لا يسمح بتحسين القدرة على التعميم. نحن بحاجة إلى بيانات جديدة وتجارب جديدة عليها
- هناك اختلال واضح بين درجة تطور التعرف على الوجوه ومكافحة الخداع. تقنيات الاعتراف متقدمة بشكل كبير على أنظمة الحماية. علاوة على ذلك ، فإن عدم وجود أنظمة حماية موثوقة تمنع الاستخدام العملي لأنظمة التعرف على الوجوه. لقد حدث أن الاهتمام الرئيسي تم توجيهه على وجه التحديد لمواجهة التعرف ، وظلت أنظمة الكشف عن الهجوم بمعزل إلى حد ما
- هناك حاجة قوية لنهج منظم لمواجهة مكافحة الغش. أظهرت المسابقة السابقة لجامعة أولو أنه عند استخدام مجموعة بيانات غير تمثيلية ، من الممكن تمامًا الهزيمة بتعديل مختص بسيط للحلول القائمة ، دون تطوير حلول جديدة. ربما منافسة جديدة يمكن أن تتحول المد
- مع الاهتمام المتزايد بالموضوع وإدخال تقنيات التعرف على الوجه من قبل اللاعبين الكبار ، ظهرت "نوافذ الفرصة" لفرق جديدة طموحة ، لأن هناك حاجة ماسة إلى حل جديد على المستوى المعماري