ناقشنا في المقالات السابقة
محرك فهرسة PostgreSQL ، وواجهة طرق الوصول ، والأساليب التالية:
فهارس التجزئة ،
وأشجار B ، و
GiST ، و
SP-GiST ، و
GIN ، و
RUM . موضوع هذه المقالة هو فهارس BRIN.
BRIN
المفهوم العام
على عكس الفهارس التي جمعناها بالفعل ، فإن فكرة BRIN هي تجنب النظر في صفوف غير مناسبة بالتأكيد بدلاً من العثور على تلك المطابقة بسرعة. هذا هو دائمًا فهرس غير دقيق: لا يحتوي على أرقام TID لصفوف الجدول على الإطلاق.
بشكل مبسط ، يعمل BRIN بشكل جيد مع الأعمدة حيث ترتبط القيم مع موقعها الفعلي في الجدول. بمعنى آخر ، إذا كان استعلام بدون جملة ORDER BY يُرجع قيم العمود تقريبًا بالترتيب المتزايد أو التنازلي (ولا توجد فهارس في هذا العمود).
تم إنشاء طريقة الوصول هذه في نطاق
Axle ، المشروع الأوروبي لقواعد البيانات التحليلية الضخمة للغاية ، مع التركيز على الجداول التي يبلغ حجمها عدة تيرابايت أو عشرات تيرابايت الكبيرة. من الميزات المهمة في BRIN التي تمكننا من إنشاء فهارس على هذه الجداول هي الحجم الصغير والحد الأدنى من تكاليف الصيانة العامة.
هذا يعمل على النحو التالي. ينقسم الجدول إلى
نطاقات تكون عدة صفحات كبيرة (أو عدة كتل كبيرة ، وهو نفسه) - ومن هنا جاء الاسم: Block Range Index، BRIN. يخزن الفهرس
معلومات موجزة عن البيانات الموجودة في كل نطاق. كقاعدة عامة ، هذا هو الحد الأدنى والحد الأقصى للقيم ، لكن الأمر يختلف ، كما هو موضح أكثر. افترض أنه يتم تنفيذ استعلام يحتوي على شرط العمود ؛ إذا لم تدخل القيم المطلوبة في الفاصل الزمني ، فيمكن تخطي النطاق بالكامل ؛ ولكن إذا حصلوا ، فسوف يتعين فحص جميع الصفوف في جميع الكتل لاختيار المطابقة بينها.
لن يكون من الخطأ التعامل مع BRIN ليس كمؤشر ، ولكن كمسرع للمسح المتسلسل. يمكننا اعتبار BRIN بديلاً للتقسيم إذا اعتبرنا كل نطاق كقسم "افتراضي".
الآن دعونا نناقش هيكل الفهرس بمزيد من التفصيل.
هيكل
تحتوي الصفحة الأولى (أكثر تحديدًا ، صفر) على البيانات الأولية.
توجد الصفحات التي تحتوي على معلومات الملخص في إزاحة معينة من البيانات التعريفية. يحتوي كل صف فهرس في تلك الصفحات على معلومات موجزة عن نطاق واحد.
بين صفحة التعريف والبيانات التلخيصية ، توجد صفحات ذات
خريطة النطاق العكسي (يُشار إليها اختصارًا باسم "revmap"). في الواقع ، هذا صفيف مؤشرات (TID) إلى صفوف الفهرس المطابق.
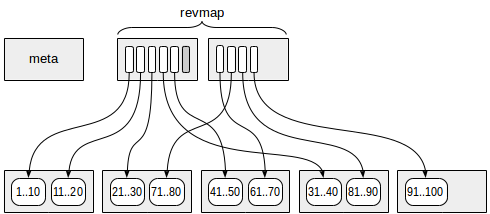
بالنسبة لبعض النطاقات ، يمكن أن يؤدي المؤشر الموجود في "revmap" إلى عدم وجود صف فهرس (يتم وضع علامة باللون الرمادي في الشكل). في مثل هذه الحالة ، يعتبر النطاق ليس لديه معلومات موجزة بعد.
مسح الفهرس
كيف يتم استخدام الفهرس إذا كان لا يحتوي على إشارات إلى صفوف الجدول؟ بالتأكيد لا يمكن لطريقة الوصول هذه إرجاع الصفوف TID بواسطة TID ، لكن يمكنها إنشاء صورة نقطية. يمكن أن يكون هناك نوعان من صفحات الصورة النقطية: دقيقة ، إلى الصف ، وغير دقيقة ، إلى الصفحة. إنها صورة نقطية غير دقيقة يُستخدم.
الخوارزمية بسيطة. يتم مسح خريطة النطاقات بالتسلسل (أي ، يتم تمرير النطاقات بترتيب موقعها في الجدول). يتم استخدام المؤشرات لتحديد صفوف الفهرس بمعلومات موجزة عن كل نطاق. إذا كان نطاق لا يحتوي على القيمة المطلوبة ، فإنه يتم تخطيها ، وإذا كان يمكن أن يحتوي على القيمة (أو المعلومات التلخيصية غير متوفرة) ، تتم إضافة جميع صفحات النطاق إلى الصورة النقطية. ثم يتم استخدام الصورة النقطية الناتجة كالمعتاد.
تحديث الفهرس
هو أكثر إثارة للاهتمام كيف يتم تحديث الفهرس عندما يتم تغيير الجدول.
عند
إضافة إصدار جديد من صف إلى صفحة جدول ، فإننا نحدد النطاق الذي يتضمنه ونستخدم خريطة النطاقات للعثور على صف الفهرس بمعلومات الملخص. كل هذه عمليات حسابية بسيطة. فلنكن ، على سبيل المثال ، حجم النطاق أربعة وفي الصفحة 13 ، يحدث إصدار صف بقيمة 42. عدد النطاق (بدءًا من الصفر) هو 13/4 = 3 ، لذلك ، في "revmap" نأخذ المؤشر مع الإزاحة 3 (رقم الطلب هو أربعة).
الحد الأدنى للقيمة لهذا النطاق هو 31 ، والقيمة القصوى هي 40. نظرًا لأن القيمة الجديدة البالغة 42 هي خارج الفترة الزمنية ، فإننا نقوم بتحديث القيمة القصوى (انظر الشكل). ولكن إذا كانت القيمة الجديدة لا تزال ضمن الحدود المخزنة ، فلن تحتاج إلى تحديث الفهرس.

كل هذا يتعلق بالموقف عند حدوث الإصدار الجديد من الصفحة في نطاق تتوفر فيه معلومات الملخص. عند إنشاء الفهرس ، يتم حساب المعلومات الموجزة لجميع النطاقات المتاحة ، ولكن بينما يتم توسيع الجدول ، يمكن أن تحدث صفحات جديدة خارج الحدود. هناك خياران متاحان هنا:
- عادة لا يتم تحديث الفهرس على الفور. هذه ليست مشكلة كبيرة: كما ذكر بالفعل ، عند فحص المؤشر ، سيتم النظر في المجموعة بأكملها. يتم التحديث الفعلي أثناء "فراغ" ، أو يمكن إجراؤه يدويًا عن طريق استدعاء وظيفة "brin_summarize_new_values".
- إذا أنشأنا الفهرس باستخدام "autosummarize" ، فسيتم التحديث على الفور. ولكن عندما يتم ملء صفحات النطاق بقيم جديدة ، يمكن أن تحدث التحديثات كثيرًا ، لذلك ، يتم إيقاف تشغيل هذه المعلمة افتراضيًا.
عند حدوث نطاقات جديدة ، يمكن أن يزيد حجم "revmap". عندما تحتاج الخريطة ، الواقعة بين صفحة التعريف والبيانات التلخيصية ، إلى تمديدها بواسطة صفحة أخرى ، يتم نقل إصدارات الصفوف الموجودة إلى بعض الصفحات الأخرى. لذلك ، توجد خريطة النطاقات دائمًا بين صفحة التعريف وبيانات الملخص.
عندما يتم
حذف صف ، ... لا شيء يحدث. يمكننا أن نلاحظ أنه في بعض الأحيان يتم حذف الحد الأدنى أو الحد الأقصى للقيمة ، وفي هذه الحالة يمكن تخفيض الفاصل الزمني. ولكن للكشف عن هذا ، سيتعين علينا قراءة جميع القيم في النطاق ، وهذا مكلف.
لا تتأثر صحة الفهرس ، ولكن قد يتطلب البحث البحث في نطاقات أكثر مما هو مطلوب بالفعل. بشكل عام ، يمكن إعادة حساب المعلومات الموجزة يدويًا لمثل هذه المنطقة (عن طريق استدعاء الدالتين "brin_desummarize_range" و "brin_summarize_new_values") ، لكن كيف يمكننا اكتشاف هذه الحاجة؟ على أي حال ، لا يوجد إجراء تقليدي متاح لهذه الغاية.
أخيرًا ،
تحديث الصف هو مجرد حذف الإصدار القديم وإضافة إصدار جديد.
مثال
دعونا نحاول بناء مستودع بيانات صغير خاص بنا للبيانات من جداول
قاعدة البيانات التجريبية . لنفترض أنه لأغراض إعداد تقارير استقصاء المعلومات ، هناك حاجة إلى جدول غير طبيعي ليعكس الرحلات الجوية المغادرة من المطار أو التي هبطت في المطار بدقة مقعد في المقصورة. ستتم إضافة بيانات كل مطار إلى الجدول مرة واحدة يوميًا ، عندما يكون منتصف الليل في المنطقة الزمنية المناسبة. لن يتم تحديث البيانات أو حذفها.
سيبدو الجدول كما يلي:
demo=# create table flights_bi( airport_code char(3), airport_coord point,
يمكننا محاكاة إجراءات تحميل البيانات باستخدام حلقات متداخلة: واحدة خارجية تلو الأخرى (سننظر
في قاعدة بيانات كبيرة ، وبالتالي 365 يومًا) ، وحلقة داخلية - حسب المناطق الزمنية (من UTC + 02 إلى UTC + 12) . الاستعلام طويل جدًا وليس له أهمية خاصة ، لذلك سأخفيه تحت المفسد.
محاكاة لتحميل البيانات إلى التخزين DO $$ <<local>> DECLARE curdate date := (SELECT min(scheduled_departure) FROM flights); utc_offset interval; BEGIN WHILE (curdate <= bookings.now()::date) LOOP utc_offset := interval '12 hours'; WHILE (utc_offset >= interval '2 hours') LOOP INSERT INTO flights_bi WITH flight ( airport_code, airport_coord, flight_id, flight_no, scheduled_time, actual_time, aircraft_code, flight_type ) AS ( ;
demo=# select count(*) from flights_bi;
count ---------- 30517076 (1 row)
demo=# select pg_size_pretty(pg_total_relation_size('flights_bi'));
pg_size_pretty ---------------- 4127 MB (1 row)
نحصل على 30 مليون صف و 4 غيغابايت. ليست كبيرة الحجم ، لكنها جيدة بما يكفي لجهاز كمبيوتر محمول: أخذني المسح المتسلسل حوالي 10 ثوانٍ.
على أي أعمدة يجب أن ننشئ الفهرس؟
نظرًا لأن فهارس BRIN لها حجم صغير وتكاليف عامة معتدلة ، وتحدث التحديثات بشكل غير متكرر ، إن وجدت ، تنشأ فرصة نادرة لإنشاء العديد من الفهارس "في حالة" ، على سبيل المثال ، في جميع الحقول التي يمكن للمستخدمين من خلالها إنشاء استعلاماتهم المخصصة . لن يكون مفيدًا - لا يهم ، ولكن حتى فهرس غير فعال للغاية سيعمل بشكل أفضل من المسح المتسلسل بالتأكيد. بالطبع ، هناك مجالات لا جدوى منها بناء فهرس ؛ سوف الحس السليم النقي يدفعهم.
لكن من الغريب أن نقتصر على هذه النصيحة ، لذلك ، دعونا نحاول ذكر معيار أكثر دقة.
لقد ذكرنا بالفعل أن البيانات يجب أن ترتبط إلى حد ما بموقعها الفعلي. من المنطقي هنا أن نتذكر أن PostgreSQL يجمع إحصائيات أعمدة الجدول ، والتي تشمل قيمة الارتباط. يستخدم المخطط هذه القيمة للاختيار بين المسح الدوري للفحص والصورة النقطية ، ويمكننا استخدامه لتقدير مدى إمكانية تطبيق فهرس BRIN.
في المثال أعلاه ، من الواضح أن البيانات مرتبة حسب الأيام (حسب "المجدولة" ، وكذلك "الفعلي" - لا يوجد فرق كبير). هذا لأنه عند إضافة صفوف إلى الجدول (بدون عمليات حذف وتحديثات) ، يتم وضعها في الملف واحدًا تلو الآخر. في محاكاة تحميل البيانات ، لم نستخدم حتى جملة ORDER BY ، وبالتالي ، يمكن اختلاط التواريخ خلال يوم ، بشكل عام ، بطريقة تعسفية ، ولكن يجب أن يكون الطلب في مكانه. دعونا التحقق من هذا:
demo=# analyze flights_bi; demo=# select attname, correlation from pg_stats where tablename='flights_bi' order by correlation desc nulls last;
attname | correlation --------------------+------------- scheduled_time | 0.999994 actual_time | 0.999994 fare_conditions | 0.796719 flight_type | 0.495937 airport_utc_offset | 0.438443 aircraft_code | 0.172262 airport_code | 0.0543143 flight_no | 0.0121366 seat_no | 0.00568042 passenger_name | 0.0046387 passenger_id | -0.00281272 airport_coord | (12 rows)
القيمة التي ليست قريبة جدًا من الصفر (من الناحية المثالية ، بالقرب من علامة زائد ، كما هو الحال في هذه الحالة) ، تخبرنا أن مؤشر BRIN سيكون مناسبًا.
فئة السفر "fare_condition" (يحتوي العمود على ثلاث قيم فريدة) ونوع الرحلة "flight_type" (قيمتان فريدتان) ظهر بشكل غير متوقع في المكانين الثاني والثالث. هذا هو الوهم: الارتباط رسميًا مرتفعًا ، بينما في الواقع في عدة صفحات متتالية سيتم مواجهة جميع القيم الممكنة بشكل مؤكد ، مما يعني أن BRIN لن يحقق أي فائدة.
تنتقل المنطقة الزمنية "airport_utc_offset" بعد ذلك: في المثال المدروس ، خلال دورة اليوم ، يتم ترتيب المطارات حسب المناطق الزمنية "حسب الإنشاء".
إنه هذان الحقلان ، الوقت والمنطقة الزمنية ، التي سنجري المزيد من التجارب عليها.
ممكن إضعاف العلاقة
يمكن أن تضعف العلاقة التي يتم وضعها "بالبناء" بسهولة عند تغيير البيانات. والأمر هنا ليس في تغيير إلى قيمة معينة ، ولكن في بنية عنصر التحكم التزامن المتعدد: يتم حذف إصدار الصف القديم في صفحة واحدة ، ولكن قد يتم إدراج إصدار جديد حيثما تتوفر مساحة حرة. نتيجة لهذا ، تختلط الصفوف بأكملها أثناء التحديثات.
يمكننا التحكم في هذا التأثير جزئيًا عن طريق تقليل قيمة معلمة التخزين "fillfactor" وبهذه الطريقة تترك مساحة خالية على الصفحة للحصول على التحديثات المستقبلية. ولكن هل نريد زيادة حجم طاولة ضخمة بالفعل؟ إضافة إلى ذلك ، هذا لا يحل مشكلة الحذف: فهم أيضًا "يعينون الفخاخ" للصفوف الجديدة عن طريق تحرير المساحة في مكان ما داخل الصفحات الموجودة. نتيجة لهذا ، سيتم إدراج الصفوف التي قد تصل إلى نهاية الملف ، في مكان تعسفي.
بالمناسبة ، هذه حقيقة غريبة. نظرًا لأن فهرس BRIN لا يحتوي على إشارات إلى صفوف الجدول ، فإن توفره يجب ألا يعوق تحديثات HOT على الإطلاق ، ولكنه كذلك.
لذلك ، تم تصميم BRIN بشكل رئيسي للجداول ذات الأحجام الكبيرة وحتى الضخمة التي لا يتم تحديثها على الإطلاق أو يتم تحديثها بشكل طفيف. ومع ذلك ، فإنه يتواءم تمامًا مع إضافة صفوف جديدة (إلى نهاية الجدول). هذا ليس مفاجئًا نظرًا لأنه تم إنشاء طريقة الوصول هذه بهدف تخزين البيانات وإعداد التقارير التحليلية.
ما حجم مجموعة نحتاج لتحديد؟
إذا تعاملنا مع جدول تيرابايت ، فإن شاغلنا الرئيسي عند اختيار حجم النطاق لن يكون جعل مؤشر BRIN أكبر من اللازم. ومع ذلك ، في وضعنا ، يمكننا تحمل تحليل البيانات بشكل أكثر دقة.
للقيام بذلك ، يمكننا تحديد قيم فريدة من عمود ونرى على عدد الصفحات التي تحدث. توطين القيم يزيد من فرص النجاح في تطبيق مؤشر BRIN. علاوة على ذلك ، فإن عدد الصفحات التي تم العثور عليها سيطالبك بحجم النطاق. ولكن إذا كانت القيمة "موزعة" على جميع الصفحات ، فإن BRIN تكون عديمة الفائدة.
بالطبع ، يجب أن نستخدم هذه التقنية مع مراقبة دقيقة للهيكل الداخلي للبيانات. على سبيل المثال ، ليس من المنطقي اعتبار كل تاريخ (بشكل أكثر دقة ، طابع زمني ، بما في ذلك الوقت أيضًا) قيمة فريدة - نحتاج إلى تقريبه إلى أيام.
من الناحية الفنية ، يمكن إجراء هذا التحليل من خلال النظر في قيمة العمود "ctid" المخفي ، والذي يوفر المؤشر لإصدار صف (TID): رقم الصفحة ورقم الصف داخل الصفحة. لسوء الحظ ، لا توجد تقنية تقليدية لتقسيم TID إلى عنصريها ، لذلك ، علينا أن نلقي أنواعًا من خلال تمثيل النص:
demo=# select min(numblk), round(avg(numblk)) avg, max(numblk) from ( select count(distinct (ctid::text::point)[0]) numblk from flights_bi group by scheduled_time::date ) t;
min | avg | max ------+------+------ 1192 | 1500 | 1796 (1 row)
demo=# select relpages from pg_class where relname = 'flights_bi';
relpages ---------- 528172 (1 row)
يمكننا أن نرى أن كل يوم يتم توزيعه عبر الصفحات بشكل متساوٍ ، والأيام تختلط قليلاً مع بعضها البعض (1500 & مرات 365 = 547500 ، وهو أكبر قليلاً فقط من عدد الصفحات في الجدول 528172). هذا واضح في الواقع "عن طريق البناء" على أي حال.
المعلومات القيمة هنا هي عدد محدد من الصفحات. مع حجم النطاق التقليدي البالغ 128 صفحة ، سيتم تعبئة كل يوم نطاقات 9-14. يبدو هذا واقعيًا: من خلال استعلام ليوم معين ، يمكننا أن نتوقع حدوث خطأ حوالي 10٪.
لنجرب:
demo=# create index on flights_bi using brin(scheduled_time);
حجم الفهرس صغير بحجم 184 كيلوبايت:
demo=# select pg_size_pretty(pg_total_relation_size('flights_bi_scheduled_time_idx'));
pg_size_pretty ---------------- 184 kB (1 row)
في هذه الحالة ، بالكاد يكون من المنطقي زيادة حجم النطاق على حساب فقدان الدقة. ولكن يمكننا تقليل الحجم إذا لزم الأمر ، وستزداد الدقة (على العكس من ذلك ، إلى جانب حجم الفهرس).
الآن دعونا ننظر إلى المناطق الزمنية. هنا لا يمكننا استخدام نهج القوة الغاشمة أيضًا. يجب تقسيم جميع القيم على عدد دورات اليوم بدلاً من تكرار التوزيع في كل يوم. بالإضافة إلى ذلك ، نظرًا لوجود مناطق زمنية قليلة فقط ، يمكننا أن ننظر إلى التوزيع بأكمله:
demo=# select airport_utc_offset, count(distinct (ctid::text::point)[0])/365 numblk from flights_bi group by airport_utc_offset order by 2;
airport_utc_offset | numblk --------------------+-------- 12:00:00 | 6 06:00:00 | 8 02:00:00 | 10 11:00:00 | 13 08:00:00 | 28 09:00:00 | 29 10:00:00 | 40 04:00:00 | 47 07:00:00 | 110 05:00:00 | 231 03:00:00 | 932 (11 rows)
في المتوسط ، تملأ البيانات لكل منطقة زمنية 133 صفحة في اليوم ، لكن التوزيع غير منتظم إلى حد كبير: يتناسب Petropavlovsk-Kamchatskiy and Anadyr مع ما لا يقل عن ست صفحات ، بينما تتطلب موسكو والحي المجاور مئات منها. الحجم الافتراضي للنطاق ليس جيدًا هنا ؛ لنقم ، على سبيل المثال ، بتعيينها إلى أربع صفحات.
demo=# create index on flights_bi using brin(airport_utc_offset) with (pages_per_range=4); demo=# select pg_size_pretty(pg_total_relation_size('flights_bi_airport_utc_offset_idx'));
pg_size_pretty ---------------- 6528 kB (1 row)
خطة التنفيذ
دعونا ننظر في كيفية عمل فهارسنا. دعنا نختار يومًا ما ، على سبيل المثال ، قبل أسبوع (في قاعدة البيانات التجريبية ، يتم تحديد "اليوم" من خلال وظيفة "booking.now"):
demo=# \set d 'bookings.now()::date - interval \'7 days\'' demo=# explain (costs off,analyze) select * from flights_bi where scheduled_time >= :d and scheduled_time < :d + interval '1 day';
QUERY PLAN -------------------------------------------------------------------------------- Bitmap Heap Scan on flights_bi (actual time=10.282..94.328 rows=83954 loops=1) Recheck Cond: ... Rows Removed by Index Recheck: 12045 Heap Blocks: lossy=1664 -> Bitmap Index Scan on flights_bi_scheduled_time_idx (actual time=3.013..3.013 rows=16640 loops=1) Index Cond: ... Planning time: 0.375 ms Execution time: 97.805 ms
كما نرى ، استخدم المخطط الفهرس الذي تم إنشاؤه. ما مدى دقة ذلك؟ تخبرنا نسبة هذا العدد من الصفوف التي تفي بشروط الاستعلام ("الصفوف" من عقدة Bitmap Heap Scan) إلى إجمالي عدد الصفوف التي يتم إرجاعها باستخدام الفهرس (نفس القيمة بالإضافة إلى الصفوف التي تمت إزالتها عن طريق إعادة فحص الفهرس). في هذه الحالة 83954 / (83954 + 12045) ، وهو ما يقرب من 90 ٪ ، كما هو متوقع (هذه القيمة سوف تتغير من يوم إلى آخر).
من أين ينشأ رقم 16640 في "الصفوف الفعلية" لعقد مسح نقطية؟ الشيء هو أن هذه العقدة من الخطة تقوم بإنشاء صورة نقطية غير دقيقة (صفحة صفحة) ولا تعلم تمامًا عدد الصفوف التي ستلمسها الصورة النقطية ، بينما يلزم عرض شيء ما. لذلك ، في حالة اليأس ، يفترض أن تحتوي صفحة واحدة على 10 صفوف. تحتوي الصورة النقطية على إجمالي 1664 صفحة (تظهر هذه القيمة في "Heap Blocks: lossy = 1664")؛ إذاً ، نحن نحصل على 16640. إجمالاً ، هذا رقم لا معنى له ، ولا ينبغي لنا الانتباه إليه.
ماذا عن المطارات؟ على سبيل المثال ، لنأخذ المنطقة الزمنية لـ Vladivostok ، التي تملأ 28 صفحة يوميًا:
demo=# explain (costs off,analyze) select * from flights_bi where airport_utc_offset = interval '8 hours';
QUERY PLAN ---------------------------------------------------------------------------------- Bitmap Heap Scan on flights_bi (actual time=75.151..192.210 rows=587353 loops=1) Recheck Cond: (airport_utc_offset = '08:00:00'::interval) Rows Removed by Index Recheck: 191318 Heap Blocks: lossy=13380 -> Bitmap Index Scan on flights_bi_airport_utc_offset_idx (actual time=74.999..74.999 rows=133800 loops=1) Index Cond: (airport_utc_offset = '08:00:00'::interval) Planning time: 0.168 ms Execution time: 212.278 ms
يستخدم المخطط مرة أخرى فهرس BRIN الذي تم إنشاؤه. دقة أسوأ (حوالي 75 ٪ في هذه الحالة) ، ولكن هذا هو متوقع لأن العلاقة أقل.
يمكن بالتأكيد ربط العديد من فهارس BRIN (تمامًا مثل أي فهارس أخرى) بمستوى الصورة النقطية. على سبيل المثال ، فيما يلي البيانات الموجودة في المنطقة الزمنية المحددة لمدة شهر (لاحظ "عقدة" صورة نقطية):
demo=# \set d 'bookings.now()::date - interval \'60 days\'' demo=# explain (costs off,analyze) select * from flights_bi where scheduled_time >= :d and scheduled_time < :d + interval '30 days' and airport_utc_offset = interval '8 hours';
QUERY PLAN --------------------------------------------------------------------------------- Bitmap Heap Scan on flights_bi (actual time=62.046..113.849 rows=48154 loops=1) Recheck Cond: ... Rows Removed by Index Recheck: 18856 Heap Blocks: lossy=1152 -> BitmapAnd (actual time=61.777..61.777 rows=0 loops=1) -> Bitmap Index Scan on flights_bi_scheduled_time_idx (actual time=5.490..5.490 rows=435200 loops=1) Index Cond: ... -> Bitmap Index Scan on flights_bi_airport_utc_offset_idx (actual time=55.068..55.068 rows=133800 loops=1) Index Cond: ... Planning time: 0.408 ms Execution time: 115.475 ms
مقارنة مع شجرة ب
ماذا لو قمنا بإنشاء فهرس B-tree منتظم في نفس الحقل مثل BRIN؟
demo=# create index flights_bi_scheduled_time_btree on flights_bi(scheduled_time); demo=# select pg_size_pretty(pg_total_relation_size('flights_bi_scheduled_time_btree'));
pg_size_pretty ---------------- 654 MB (1 row)
يبدو أن
عدة آلاف من المرات أكبر من برين! ومع ذلك ، يتم تنفيذ الاستعلام بشكل أسرع قليلاً: استخدم المخطط إحصائيات لمعرفة أن البيانات مرتبة فعليًا وليست هناك حاجة لإنشاء صورة نقطية ، وبشكل أساسي ، لا يلزم إعادة فحص حالة الفهرس:
demo=# explain (costs off,analyze) select * from flights_bi where scheduled_time >= :d and scheduled_time < :d + interval '1 day';
QUERY PLAN ---------------------------------------------------------------- Index Scan using flights_bi_scheduled_time_btree on flights_bi (actual time=0.099..79.416 rows=83954 loops=1) Index Cond: ... Planning time: 0.500 ms Execution time: 85.044 ms
هذا شيء رائع حول BRIN: نحن نضحي بالكفاءة ، لكننا نكتسب مساحة كبيرة جدًا.
فئات المشغل
minmax
بالنسبة لأنواع البيانات التي يمكن مقارنة قيمها مع بعضها البعض ، تتكون معلومات الملخص من
الحد الأدنى والحد الأقصى للقيم . تحتوي أسماء فئات المشغِّل المقابلة على "minmax" ، على سبيل المثال ، "date_minmax_ops". في الواقع ، هذه هي أنواع البيانات التي كنا نفكر فيها حتى الآن ، ومعظم الأنواع من هذا النوع.
شامل
عوامل تشغيل المقارنة غير محددة لجميع أنواع البيانات. على سبيل المثال ، لا يتم تعريفها للنقاط (نوع "النقطة") ، والتي تمثل الإحداثيات الجغرافية للمطارات. بالمناسبة ، لهذا السبب لا تُظهر الإحصائيات الارتباط لهذا العمود.
demo=# select attname, correlation from pg_stats where tablename='flights_bi' and attname = 'airport_coord';
attname | correlation ---------------+------------- airport_coord | (1 row)
لكن العديد من هذه الأنواع تمكننا من تقديم مفهوم "المنطقة المحيطة" ، على سبيل المثال ، مستطيل محيط للأشكال الهندسية. ناقشنا بالتفصيل كيف يستخدم فهرس
GiST هذه الميزة. وبالمثل ، يمكّن BRIN أيضًا جمع معلومات الملخص على الأعمدة التي تحتوي على أنواع البيانات مثل هذه:
المنطقة المحيطة لجميع القيم داخل النطاق هي مجرد قيمة الملخص.
بخلاف GiST ، يجب أن تكون قيمة الملخص لـ BRIN من نفس النوع مثل القيم التي يتم فهرستها. لذلك ، لا يمكننا بناء الفهرس للنقاط ، على الرغم من أنه من الواضح أن الإحداثيات يمكن أن تعمل في BRIN: خط الطول يرتبط ارتباطًا وثيقًا بالمنطقة الزمنية. لحسن الحظ ، لا شيء يعوق إنشاء الفهرس على تعبير بعد تحويل النقاط إلى مستطيلات متدهورة. في الوقت نفسه ، سنقوم بتعيين حجم النطاق على صفحة واحدة ، فقط لإظهار حالة الحد:
demo=# create index on flights_bi using brin (box(airport_coord)) with (pages_per_range=1);
حجم الفهرس صغير حتى 30 ميغابايت حتى في مثل هذه الحالة القصوى:
demo=# select pg_size_pretty(pg_total_relation_size('flights_bi_box_idx'));
pg_size_pretty ---------------- 30 MB (1 row)
الآن يمكننا تعويض الاستفسارات التي تحد من المطارات عن طريق الإحداثيات. على سبيل المثال:
demo=# select airport_code, airport_name from airports where box(coordinates) <@ box '120,40,140,50';
airport_code | airport_name --------------+----------------- KHV | Khabarovsk-Novyi VVO | Vladivostok (2 rows)
ومع ذلك ، سيرفض المخطط استخدام فهرسنا.
demo=# analyze flights_bi; demo=# explain select * from flights_bi where box(airport_coord) <@ box '120,40,140,50';
QUERY PLAN --------------------------------------------------------------------- Seq Scan on flights_bi (cost=0.00..985928.14 rows=30517 width=111) Filter: (box(airport_coord) <@ '(140,50),(120,40)'::box)
لماذا؟ لنقم بتعطيل المسح المتسلسل ونرى ما سيحدث:
demo=# set enable_seqscan = off; demo=# explain select * from flights_bi where box(airport_coord) <@ box '120,40,140,50';
QUERY PLAN -------------------------------------------------------------------------------- Bitmap Heap Scan on flights_bi (cost=14079.67..1000007.81 rows=30517 width=111) Recheck Cond: (box(airport_coord) <@ '(140,50),(120,40)'::box) -> Bitmap Index Scan on flights_bi_box_idx (cost=0.00..14072.04 rows=30517076 width=0) Index Cond: (box(airport_coord) <@ '(140,50),(120,40)'::box)
يبدو أنه
يمكن استخدام الفهرس ، لكن المخطط يفترض أن الصورة النقطية يجب أن تكون مبنية على الجدول بالكامل (انظر إلى "الصفوف" من عقدة Bitmap Index Scan) ، ولا عجب أن يختار المخطط المسح المتسلسل في هذه الحالة. المشكلة هنا هي أنه بالنسبة للأنواع الهندسية ، لا تجمع PostgreSQL أي إحصائيات ، ويتعين على المخطط أن يتعمد:
demo=# select * from pg_stats where tablename = 'flights_bi_box_idx' \gx
-[ RECORD 1 ]----------+------------------- schemaname | bookings tablename | flights_bi_box_idx attname | box inherited | f null_frac | 0 avg_width | 32 n_distinct | 0 most_common_vals | most_common_freqs | histogram_bounds | correlation | most_common_elems | most_common_elem_freqs | elem_count_histogram |
للأسف. لكن لا توجد شكاوى حول الفهرس - إنه يعمل ويعمل بشكل جيد:
demo=# explain (costs off,analyze) select * from flights_bi where box(airport_coord) <@ box '120,40,140,50';
QUERY PLAN ---------------------------------------------------------------------------------- Bitmap Heap Scan on flights_bi (actual time=158.142..315.445 rows=781790 loops=1) Recheck Cond: (box(airport_coord) <@ '(140,50),(120,40)'::box) Rows Removed by Index Recheck: 70726 Heap Blocks: lossy=14772 -> Bitmap Index Scan on flights_bi_box_idx (actual time=158.083..158.083 rows=147720 loops=1) Index Cond: (box(airport_coord) <@ '(140,50),(120,40)'::box) Planning time: 0.137 ms Execution time: 340.593 ms
يجب أن يكون الاستنتاج كما يلي: هناك حاجة إلى PostGIS إذا كان أي شيء غير ضروري مطلوبًا من الناحية الهندسية. يمكن أن تجمع الإحصاءات على أي حال.
الداخلية
يمكّننا الامتداد التقليدي "pageinspect" من النظر إلى مؤشر BRIN.
أولاً ، سيطالبكنا metainformation بحجم النطاق وعدد الصفحات المخصصة لـ "revmap":
demo=# select * from brin_metapage_info(get_raw_page('flights_bi_scheduled_time_idx',0));
magic | version | pagesperrange | lastrevmappage ------------+---------+---------------+---------------- 0xA8109CFA | 1 | 128 | 3 (1 row)
يتم تخصيص الصفحات 1-3 هنا لـ "revmap" ، بينما تحتوي البقية على بيانات موجزة. من "revmap" يمكننا الحصول على مراجع لبيانات الملخص لكل نطاق. قل ، المعلومات الموجودة في النطاق الأول ، والتي تتضمن 128 صفحة أولية ، موجودة هنا:
demo=# select * from brin_revmap_data(get_raw_page('flights_bi_scheduled_time_idx',1)) limit 1;
pages --------- (6,197) (1 row)
وهذه هي ملخص البيانات نفسها:
demo=# select allnulls, hasnulls, value from brin_page_items( get_raw_page('flights_bi_scheduled_time_idx',6), 'flights_bi_scheduled_time_idx' ) where itemoffset = 197;
allnulls | hasnulls | value ----------+----------+---------------------------------------------------- f | f | {2016-08-15 02:45:00+03 .. 2016-08-15 17:15:00+03} (1 row)
النطاق التالي:
demo=# select * from brin_revmap_data(get_raw_page('flights_bi_scheduled_time_idx',1)) offset 1 limit 1;
pages --------- (6,198) (1 row)
demo=# select allnulls, hasnulls, value from brin_page_items( get_raw_page('flights_bi_scheduled_time_idx',6), 'flights_bi_scheduled_time_idx' ) where itemoffset = 198;
allnulls | hasnulls | value ----------+----------+---------------------------------------------------- f | f | {2016-08-15 06:00:00+03 .. 2016-08-15 18:55:00+03} (1 row)
و هكذا.
بالنسبة لفئات "التضمين" ، سيعرض حقل "القيمة" شيئًا ما
{(94.4005966186523,69.3110961914062),(77.6600036621,51.6693992614746) .. f .. f}
القيمة الأولى هي مستطيل التضمين ، والحروف "f" في النهاية تدل على نقص العناصر الفارغة (الأولى) وتفتقر إلى القيم غير القابلة للتنشيط (الثانية). في الواقع ، فإن القيم غير القابلة للتنشيط هي عناوين "IPv4" و "IPv6" (نوع البيانات "inet").
خصائص
تذكيرك بالاستعلامات التي
تم تقديمها بالفعل .
فيما يلي خصائص طريقة الوصول:
amname | name | pg_indexam_has_property --------+---------------+------------------------- brin | can_order | f brin | can_unique | f brin | can_multi_col | t brin | can_exclude | f
يمكن إنشاء فهارس على عدة أعمدة. في هذه الحالة ، يتم جمع إحصائيات الملخص الخاصة به لكل عمود ، ولكن يتم تخزينها معًا لكل نطاق. بالطبع ، يكون هذا الفهرس منطقيًا إذا كان حجم ونطاق النطاق نفسه مناسبًا لجميع الأعمدة.
تتوفر خصائص طبقة الفهرس التالية:
name | pg_index_has_property ---------------+----------------------- clusterable | f index_scan | f bitmap_scan | t backward_scan | f
من الواضح ، يتم دعم فحص الصورة النقطية فقط.
ومع ذلك ، قد يبدو عدم وجود مجموعات مربكة. على ما يبدو ، نظرًا لأن مؤشر BRIN حساس للترتيب الفعلي للصفوف ، سيكون من المنطقي أن تكون قادرًا على تجميع البيانات وفقًا للفهرس. لكن هذا ليس كذلك. يمكننا فقط إنشاء فهرس "منتظم" (B-tree أو GiST ، اعتمادًا على نوع البيانات) ونظام المجموعة وفقًا لذلك. بالمناسبة ، هل تريد تجميع جدول ضخم من المفترض مع مراعاة الأقفال الحصرية ووقت التنفيذ واستهلاك مساحة القرص أثناء إعادة البناء؟
فيما يلي خصائص طبقة العمود:
name | pg_index_column_has_property --------------------+------------------------------ asc | f desc | f nulls_first | f nulls_last | f orderable | f distance_orderable | f returnable | f search_array | f search_nulls | t
الخاصية الوحيدة المتاحة هي القدرة على التعامل مع القيم الخالية.
اقرأ على .