
نجا التكنولوجيا من هاري بوتر حتى يومنا هذا. الآن ، لإنشاء فيديو كامل للشخص ، واحدة فقط من صوره أو صوره كافية. نشر باحثو التعلم الآلي من Skolkovo ومركز Samsung AI Center في موسكو عملهم على إنشاء مثل هذا النظام ، إلى جانب عدد من مقاطع الفيديو للمشاهير والأشياء الفنية التي حصلت على حياة جديدة.

يمكن قراءة نص العمل العلمي هنا . كل شيء مثير للاهتمام هناك ، مع الكثير من الصيغ ، لكن المعنى بسيط: يسترشد نظامهم بـ "المعالم" ، ومشاهد الوجه ، مثل الأنف وعينين وحاجبين وخط الذقن. حتى انها على الفور يمسك ما هو الشخص. وبعد ذلك يمكنه نقل كل شيء آخر (لون ، ملمس الوجه ، شارب ، قش ، إلخ) إلى فيديو أي شخص آخر. تكييف الوجه القديم مع مواقف جديدة.
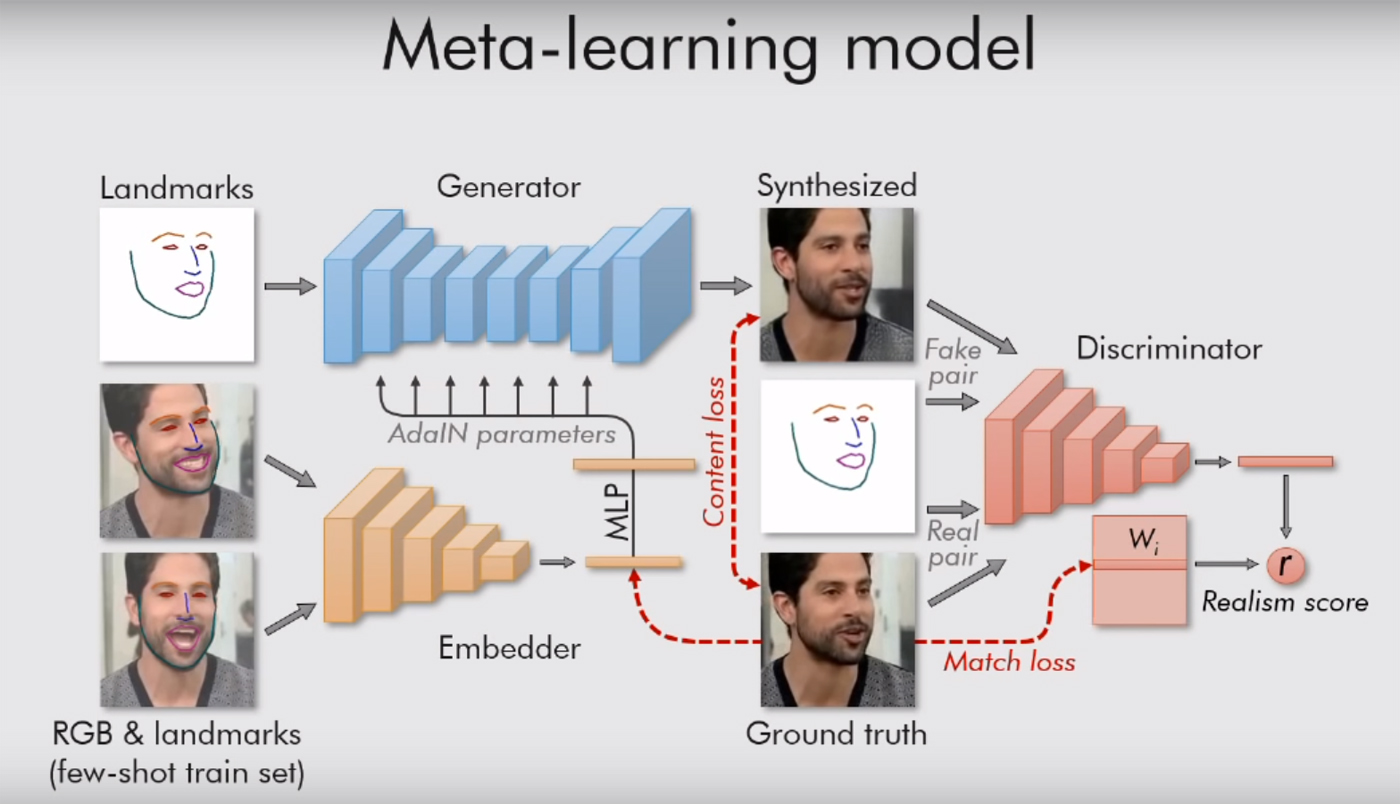
بالطبع ، هذا يعمل فقط على صور. يحتاج النموذج إلى شخص واحد فقط ، مع توجيه الوجه نحونا ، حتى يتمكن من رؤية كلتا العينين على الأقل. ثم يمكن للنظام القيام بأي شيء معه ، ونقل أي تعبيرات الوجه إليه. يكفي أن تقدم لها فيديو مناسب (مع شخص آخر مع رأسه في نفس الموقف تقريبًا).
في وقت سابق ، كانت منظمة العفو الدولية قد تعلمت بالفعل كيفية إنشاء أعمدة ، وسخر مستخدمو الإنترنت من المشاهير من خلال إدراج وجوههم في الصور الإباحية وصنع الميمات مع نيكولاس كيج. لكن من أجل هذا ، كان عليهم تدريب الخوارزميات بالميغابايت (أو غيغابايت الأفضل) من البيانات ، للعثور على أكبر عدد ممكن من الصور ومقاطع الفيديو ذات الوجوه المشهورة قدر الإمكان من أجل تحقيق نتيجة لائقة أو أقل. قال خالق Deepfakes نفسه أن الأمر يستغرق من 8 إلى 12 ساعة لتجميع فيديو قصير واحد. يولد النظام الجديد النتيجة على الفور ، ويحتاج عند الإدخال إلى صورة واحدة فقط.
مع النظام السابق ، لن نكون قادرين على إلقاء نظرة على الموناليزا الحية ، لدينا زاوية واحدة فقط. الآن ، مع خوارزميات القياس ، أصبح هذا ممكنًا. لم يتحقق المثل الأعلى ، ولكن هناك شيء قريب بالفعل.

يستخدم باحثو موسكو أيضًا شبكة الخصومة التوليدية. نموذجان من الخوارزمية يقاتلون بعضهم البعض. يحاول كل منهم خداع الخصم وإثبات أن الفيديو الذي تنشئه حقيقي. وبهذه الطريقة ، يتم تحقيق مستوى معين من الواقعية: لا يتم عرض صورة للوجه الإنساني "إلى النور" إذا لم يكن نموذج الناقد متأكداً من مصداقيته بأكثر من 90٪. كما يقول المؤلفون في عملهم ، يتم تنظيم عشرات الملايين من المعلمات في الصور ، ولكن بسبب هذا النظام ، يتغلى العمل بسرعة كبيرة.

إذا كان هناك العديد من الصور ، فإن النتيجة تتحسن. مرة أخرى ، إن أسهل طريقة هي العمل مع المشاهير الذين يتم أخذهم بالفعل من جميع الزوايا الممكنة. لتحقيق "الواقعية المثالية" هناك حاجة إلى 32 طلقة. في هذه الحالة ، سيتم تمييز صور الذكاء الاصطناعي التي تم إنشاؤها في دقة منخفضة عن الصور البشرية الحقيقية. لم يعد الأشخاص غير المدربين في هذه المرحلة قادرين على تحديد هوية مزيفة - ربما تبقى الفرص مع الخبراء أو مع أقرباء "التجريبية" من كل هذه الصور.
إذا كانت هناك صورة أو صورة واحدة فقط ، فستكون النتيجة هي الأفضل دائمًا. يمكنك مشاهدة القطع الأثرية على الفيديو عندما يكون الرأس في حالة حركة دون أي مشاكل. يقول الباحثون أنفسهم أن أضعف نقطة هي النظرة. النموذج الذي يعتمد على معالم الوجه لا يفهم دائمًا كيف وأين يجب أن ينظر الشخص.
