أهلا وسهلا بك!
اسمي Marat Gayanov ، أود أن أشاطركم حلا لمشكلة من
أفضل Reverser المسابقة ، لإظهار كيفية جعل كجن لهذه الحالة.
وصف
في هذه المسابقة ، يتم تزويد المشاركين بألعاب ROM لـ Sega Mega Drive (
best_reverser_phd9_rom_v4.bin ).
المهمة: لالتقاط مثل هذا المفتاح الذي سيتم التعرف عليه مع عنوان البريد الإلكتروني للمشترك باعتباره صحيحًا.
لذلك الحل ...
الأدوات
التحقق من طول المفتاح
لا يقبل البرنامج كل مفتاح: تحتاج إلى ملء الحقل بالكامل ، فهذه 16 حرفًا. إذا كان المفتاح أقصر ، فسترى رسالة: "طول خاطئ! حاول مرة أخرى ... ".
دعونا نحاول العثور على هذا السطر في البرنامج ، والذي سنستخدم فيه البحث الثنائي (Alt-B). ما سوف نجد؟
لن نجد هذا فقط ، ولكن أيضًا خطوط الخدمة الأخرى القريبة: "مفتاح خاطئ! حاول مرة أخرى ... "و" أنت أفضل عكسي! ".
قمت بتعيين
WRONG_LENGTH_MSG YOU_ARE_THE_BEST_MSG و
WRONG_KEY_MSG و
WRONG_KEY_MSG للراحة.
ضع استراحة على قراءة العنوان
0x0000FDFA - اكتشف من الذي يعمل مع الرسالة "طول خاطئ! حاول مرة أخرى ... ". وتشغيل مصحح الأخطاء (سيتوقف عدة مرات قبل أن يمكن إدخال المفتاح ، فقط اضغط F9 في كل محطة). أدخل بريدك الإلكتروني ، مفتاح
ABCD .
يؤدي المصحح إلى
0x00006FF0 tst.b (a1)+ :
لا يوجد شيء مثير للاهتمام في الكتلة نفسها. هو أكثر إثارة للاهتمام من الذي ينقل السيطرة هنا. ننظر إلى مكدس الاتصال:
انقر واحصل هنا - على التعليمات
0x00001D2A jsr (sub_6FC0).l :
نرى أنه تم العثور على جميع الرسائل الممكنة في مكان واحد. ولكن دعنا
WRONG_KEY_LEN_CASE_1D1C على
WRONG_KEY_LEN_CASE_1D1C نقل التحكم في
WRONG_KEY_LEN_CASE_1D1C كتلة
WRONG_KEY_LEN_CASE_1D1C . لن نقوم بتعيين فترات راحة ، فقط حرك المؤشر فوق السهم متجهًا إلى الكتلة. يقع المتصل على
0x000017DE loc_17DE (والتي
CHECK_KEY_LEN تسميتها إلى
CHECK_KEY_LEN ):
ضع فاصلًا على العنوان
0x000017EC cmpi.b 0x20 (a0, d0.l) (يبحث التعليمات في هذا السياق لمعرفة ما إذا كان هناك حرف فارغ في نهاية صفيف حروف المفتاح) ،
0x000017EC cmpi.b 0x20 (a0, d0.l) إدخال البريد ومفتاح
ABCD . يتوقف المصحح ويظهر أن المفتاح الذي تم إدخاله يقع على العنوان
0x00FF01C7 (المخزن في تلك اللحظة في السجل
a0 ):
هذا اكتشاف جيد ، من خلاله سنحصل على كل شيء على الإطلاق. لكن أولاً ، قم بترميز بايت المفتاح للراحة:
عند التمرير لأعلى من هذا المكان ، نرى أن البريد مخزّن بجوار المفتاح:
نحن نغطس بشكل أعمق وأعمق ، وقد حان الوقت لإيجاد معيار لصحة المفتاح. بدلا من ذلك ، في النصف الأول من المفتاح.
معيار لصحة النصف الأول من المفتاح
الحسابات الأولية
من المنطقي أن نفترض أنه بعد التحقق من الطول مباشرة ، ستتبع عمليات أخرى باستخدام المفتاح. النظر في كتلة مباشرة بعد الاختيار:
هذه الكتلة تمر بأعمال تمهيدية.
get_hash_2b الدالة
get_hash_2b (في الأصل
sub_1526 ) مرتين. أولاً ، يتم إرسال عنوان البايت الأول من المفتاح إليه (التسجيل
a0 يحتوي على العنوان
KEY_BYTE_0 ) ، للمرة الثانية - الخامسة (
KEY_BYTE_4 ).
قمت بتسميتها مثل هذه الوظيفة لأنها تعتبر شيئًا يشبه تجزئة 2 بايت. هذا هو الاسم الأكثر قابلية للفهم الذي التقطته.
لن أفكر في الوظيفة نفسها ، لكنني سأكتبها على الفور في الثعبان. إنها تقوم بأشياء بسيطة ، لكن وصفها مع لقطات الشاشة سيشغل مساحة كبيرة.
أهم ما يمكن قوله حول هذا الموضوع: يتم توفير عنوان الإدخال للإدخال ، ويتم العمل على 4 بايت من هذا العنوان. أي أنهم أرسلوا البايت الأول من المفتاح إلى الإدخال ، وستعمل الوظيفة مع 1،2،3،4. المقدمة الخامسة ، وظيفة تعمل مع 5،6،7،8. بمعنى آخر ، في هذه الكتلة ، توجد حسابات خلال النصف الأول من المفتاح. تتم كتابة النتيجة إلى سجل
d0 .
وبالتالي فإن وظيفة
get_hash_2b :
اكتب على الفور وظيفة فك شفرة التجزئة:
لم أتوصل إلى وظيفة فك ترميز أفضل ، وهي غير صحيحة تمامًا. لذلك ، سوف أتحقق من هذا القبيل (ليس في الوقت الحالي ، ولكن بعد ذلك بكثير):
key_4s == decode_hash_4s(get_hash_2b(key_4s))
تحقق من تشغيل
get_hash_2b . نحن مهتمون بحالة السجل
d0 بعد تنفيذ الوظيفة.
0x000017FE فواصل على
0x000017FE ،
0x00001808 ، المفتاح الذي
0x00001808 ABCDEFGHIJKLMNOP .
يتم
0xABCD القيم
0xABCD ،
0xEF01 في السجل
d0 . وما الذي سوف يعطيه
get_hash_2b ؟
>>> first_hash = get_hash_2b("ABCD") >>> hex(first_hash) 0xabcd >>> second_hash = get_hash_2b("EFGH") >>> hex(second_hash) 0xef01
تم التحقق
ثم
xor eor.w d0, d5 إنتاج
xor eor.w d0, d5 ، ويتم إدخال النتيجة في
d5 :
>>> hex(0xabcd ^ 0xef01) 0x44cc
الحصول على مثل هذا التجزئة هو
0x44CC ويتكون من الحسابات الأولية. علاوة على ذلك ، يصبح كل شيء أكثر تعقيدًا فقط.
أين تذهب التجزئة
لا يمكننا الذهاب إلى أبعد من ذلك إذا كنا لا نعرف كيف يعمل البرنامج مع التجزئة. بالتأكيد ينتقل من
d5 إلى الذاكرة ، لأن السجل في متناول اليدين في مكان آخر. يمكننا العثور على مثل هذا الحدث من خلال التتبع (مشاهدة
d5 ) ، ولكن ليس يدويًا ، ولكن تلقائي. سوف يساعد النص التالي:
#include <idc.idc> static main() { auto d5_val; auto i; for(;;) { StepOver(); GetDebuggerEvent(WFNE_SUSP, -1); d5_val = GetRegValue("d5"); // d5 if (d5_val != 0xFFFF44CC){ break; } } }
اسمحوا لي أن أذكرك بأننا الآن في آخر فاصل
0x00001808 eor.w d0, d5 . الصق البرنامج النصي (
Shift-F2 ) ، انقر فوق "
Runسيتوقف البرنامج النصي عند التعليمات
0x00001C94 move.b (a0, a1.l), d5 ، ولكن بحلول هذه اللحظة تم مسح
d5 بالفعل. ومع ذلك ، نرى أن القيمة من
d5 نقلها بواسطة التعليمة
0x00001C56 move.w d5,a6 : يتم كتابتها في الذاكرة على العنوان
0x00FF0D46 (2 بايت).
تذكر: يتم تخزين التجزئة في 0x00FF0D46 .نحن نلاحظ الإرشادات التي تمت قراءتها من
0x00FF0D46-0x00FF0D47 (وضعنا استراحة للقراءة). اشتعلت 4 كتل:




كيفية اختيار الحق / اليمين؟
العودة إلى البداية:
تحدد هذه الكتلة ما إذا كان البرنامج سيذهب إلى
LOSER_CASE أو إلى
WINNER_CASE :
نرى أنه في سجل
d1 يجب أن يكون صفر للفوز.
أين هو صفر مجموعة؟ فقط قم بالتمرير لأعلى:
إذا تم استيفاء
loc_1EEC في كتلة
loc_1EEC :
*(a6 + 0x24) == *(a6 + 0x22)
ثم نحصل على صفر في
d5 .
إذا وضعنا استراحة على التعليمات
0x00001F16 beq.w loc_20EA ،
0x00001F16 beq.w loc_20EA أن
a6 + 0x24 = 0x00FF0D6A 0x4840 تخزين القيمة
0x4840 هناك. وفي
a6 + 0x22 = 0x00FF0D68 يتم تخزين.
إذا أدخلنا مفاتيح مختلفة ورسائل البريد ،
0xCB4C - أن
0xCB4C - .
سيتم قبول النصف الأول من المفتاح فقط إذا كان في 0x00FF0D6A سيكون 0x00FF0D6A أيضًا. هذا هو المعيار لصحة النصف الأول من المفتاح.اكتشفنا الكتل المكتوبة بلغة
0x00FF0D6A - وضعت استراحة في السجل ، وأدخل البريد والمفتاح مرة أخرى.
loc_EAC كتلة
loc_EAC هذه (يوجد 3 منها في الواقع ، ولكن أول اثنين فقط خرجوا من
0x00FF0D6A ):
تنتمي هذه الكتلة إلى وظيفة
sub_E3E .
من خلال مكدس الاتصال ، اكتشفنا أن وظيفة
sub_E3E تسمى في الكتل
loc_1F94 ،
loc_203E :
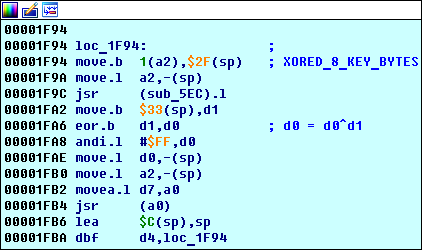

تذكر أننا وجدنا 4 كتل في وقت سابق؟
loc_1F94 رأينا هناك - هذه هي بداية خوارزمية معالجة المفتاح الرئيسية.
أول حلقة مهمة loc_1F94
يمكن
loc_1F94 حقيقة أن
loc_1F94 عبارة عن دورة من التعليمات البرمجية: يتم تنفيذها مرات
d4 (راجع التعليمات
0x00001FBA d4,loc_1F94 ):
ما الذي تبحث عنه:
- هناك وظيفة
sub_5EC . - يستدعي التعليمة 0x00001FB4 jsr (a0) وظيفة sub_E3E (يمكن رؤية ذلك بتتبع بسيط).
ما يجري هنا:
- تكتب الدالة
sub_5EC نتيجة تنفيذها إلى سجل d0 (تتم مناقشة ذلك في قسم منفصل أدناه). - يتم تخزين البايت في العنوان
sp+0x33 ( 0x00FFFF79 ، يخبرنا المصحح) في السجل d1 ، وهو يساوي البايت الثاني من عنوان تجزئة المفتاح ( 0x00FF0D47 ). من السهل إثبات ذلك إذا وضعت استراحة على الرقم 0x00FFFF79 : ستعمل على التعليمات 0x00001F94 move.b 1(a2), 0x2F(sp) . يقوم السجل a2 في هذه اللحظة بتخزين العنوان 0x00FF0D46 - عنوان التجزئة ، وهو 0x1(a2) = 0x00FF0D46 + 1 - عنوان البايت الثاني 0x1(a2) = 0x00FF0D46 + 1 . - السجل
d0 هو مكتوب d0^d1 .
- يتم إعطاء نتيجة xor'a الناتجة إلى الدالة
sub_E3E ، التي يعتمد سلوكها على حساباتها السابقة (كما هو موضح أدناه). - كرر.
كم مرة تعمل هذه الدورة؟
اكتشف هذا. قم بتشغيل البرنامج النصي التالي:
#include <idc.idc> static main() { auto pc_val, d4_val, counter=0; while(pc_val != 0x00001F16) { StepOver(); GetDebuggerEvent(WFNE_SUSP, -1); pc_val = GetRegValue("pc"); if (pc_val == 0x00001F92){ counter++; d4_val = GetRegValue("d4"); print(d4_val); } } print(counter); }
0x00001F92 subq.l 0x1,d4 - هنا يتم تحديد ما سيحدث في
d4 مباشرة قبل الحلقة:
نحن نتعامل مع الدالة sub_5EC.
sub_5EC
جزء هام من الكود:
حيث
0x2c(a2) دائمًا
0x00FF1D74 .
يمكن إعادة كتابة هذه القطعة مثل هذا في الكود الزائف:
d0 = a2 + 0x2C *(a2+0x2C) = *(a2+0x2C) + 1 #*(0x00FF1D74) = *(0x00FF1D74) + 1 result = *(d0) & 0xFF
وهذا هو ، 4 بايت من
0x00FF1D74 هي العنوان ، ل يعاملون مثل المؤشر.
كيفية إعادة كتابة وظيفة
sub_5EC في بيثون؟
- أو قم بتفريغ ذاكرة والعمل معها.
- أو اكتب فقط كل القيم التي تم إرجاعها.
الطريقة الثانية التي أحبها أكثر ، ولكن ماذا لو كانت القيم التي تم إرجاعها مختلفة مع بيانات التفويض المختلفة؟ تحقق من ذلك.
سيساعد البرنامج النصي في هذا:
#include <idc.idc> static main() { auto pc_val=0, d0_val; while(pc_val != 0x00001F16){ pc_val = GetRegValue("pc"); if (pc_val == 0x00001F9C) StepInto(); else StepOver(); GetDebuggerEvent(WFNE_SUSP, -1); if (pc_val == 0x00000674){ d0_val = GetRegValue("d0") & 0xFF; print(d0_val); } } }
أنا فقط مقارنة النواتج إلى وحدة التحكم مع مفاتيح مختلفة ، رسائل.
تشغيل البرنامج النصي عدة مرات باستخدام مفاتيح مختلفة ، سنرى أن دالة
sub_5EC تُرجع دائمًا القيمة التالية من الصفيف:
def sub_5EC_gen(): dump = [0x92, 0x8A, 0xDC, 0xDC, 0x94, 0x3B, 0xE4, 0xE4, 0xFC, 0xB3, 0xDC, 0xEE, 0xF4, 0xB4, 0xDC, 0xDE, 0xFE, 0x68, 0x4A, 0xBD, 0x91, 0xD5, 0x0A, 0x27, 0xED, 0xFF, 0xC2, 0xA5, 0xD6, 0xBF, 0xDE, 0xFA, 0xA6, 0x72, 0xBF, 0x1A, 0xF6, 0xFA, 0xE4, 0xE7, 0xFA, 0xF7, 0xF6, 0xD6, 0x91, 0xB4, 0xB4, 0xB5, 0xB4, 0xF4, 0xA4, 0xF4, 0xF4, 0xB7, 0xF6, 0x09, 0x20, 0xB7, 0x86, 0xF6, 0xE6, 0xF4, 0xE4, 0xC6, 0xFE, 0xF6, 0x9D, 0x11, 0xD4, 0xFF, 0xB5, 0x68, 0x4A, 0xB8, 0xD4, 0xF7, 0xAE, 0xFF, 0x1C, 0xB7, 0x4C, 0xBF, 0xAD, 0x72, 0x4B, 0xBF, 0xAA, 0x3D, 0xB5, 0x7D, 0xB5, 0x3D, 0xB9, 0x7D, 0xD9, 0x7D, 0xB1, 0x13, 0xE1, 0xE1, 0x02, 0x15, 0xB3, 0xA3, 0xB3, 0x88, 0x9E, 0x2C, 0xB0, 0x8F] l = len(dump) offset = 0 while offset < l: yield dump[offset] offset += 1 0x02، 0x15، 0xB3، 0xA3، def sub_5EC_gen(): dump = [0x92, 0x8A, 0xDC, 0xDC, 0x94, 0x3B, 0xE4, 0xE4, 0xFC, 0xB3, 0xDC, 0xEE, 0xF4, 0xB4, 0xDC, 0xDE, 0xFE, 0x68, 0x4A, 0xBD, 0x91, 0xD5, 0x0A, 0x27, 0xED, 0xFF, 0xC2, 0xA5, 0xD6, 0xBF, 0xDE, 0xFA, 0xA6, 0x72, 0xBF, 0x1A, 0xF6, 0xFA, 0xE4, 0xE7, 0xFA, 0xF7, 0xF6, 0xD6, 0x91, 0xB4, 0xB4, 0xB5, 0xB4, 0xF4, 0xA4, 0xF4, 0xF4, 0xB7, 0xF6, 0x09, 0x20, 0xB7, 0x86, 0xF6, 0xE6, 0xF4, 0xE4, 0xC6, 0xFE, 0xF6, 0x9D, 0x11, 0xD4, 0xFF, 0xB5, 0x68, 0x4A, 0xB8, 0xD4, 0xF7, 0xAE, 0xFF, 0x1C, 0xB7, 0x4C, 0xBF, 0xAD, 0x72, 0x4B, 0xBF, 0xAA, 0x3D, 0xB5, 0x7D, 0xB5, 0x3D, 0xB9, 0x7D, 0xD9, 0x7D, 0xB1, 0x13, 0xE1, 0xE1, 0x02, 0x15, 0xB3, 0xA3, 0xB3, 0x88, 0x9E, 0x2C, 0xB0, 0x8F] l = len(dump) offset = 0 while offset < l: yield dump[offset] offset += 1
لذا
sub_5EC جاهز.
sub_E3E السطر هو
sub_E3E .
sub_E3E
جزء هام من الكود:
فك:
, d2, . a2 0xFF0D46, a2 + 0x34 = 0xFF0D7A d0 = *(a2 + 0x34) *(a2 + 0x34) = *(a2 + 0x34) + 1 , a0 a0 = d0 *(a0) = d2 offset, d2. a2 0xFF0D46, a2 + 0x24 = 0xFF0D6A - , (. ) 0x00000000, d0 = *(a2 + 0x24) d2 = d0 ^ d2 d2 = d2 & 0xFF d2 = d2 + d2 - 2 0x00011FC0 + d2, ROM, 0x00011FC0 + d2 a0 = 0x00011FC0 d2 = *(a0 + d2) 8 d0 = d0 >> 8 d2 = d0 ^ d2 *(a2 + 0x24) = d2
sub_E3E الدالة
sub_E3E إلى الخطوات التالية:
- حفظ وسيطة الإدخال إلى صفيف.
- حساب تعويض الإزاحة.
- اسحب 2 بايت على العنوان
0x00011FC0 + offset (ROM). - النتيجة =
( >> 8) ^ (2 0x00011FC0 + offset) .
تخيل وظيفة
sub_E3E في هذا النموذج:
def sub_E3E(prev_sub_E3E_result, d2, d2_storage): def calc_offset(): return 2 * ((prev_sub_E3E_result ^ d2) & 0xff) d2_storage.append(d2) offset = calc_offset() with open("dump_00011FC0", 'rb') as f: dump_00011FC0_4096b = f.read() some = dump_00011FC0_4096b[offset:offset + 2] some = int.from_bytes(some, byteorder="big") prev_sub_E3E_result = prev_sub_E3E_result >> 8 return prev_sub_E3E_result ^ some
dump_00011FC0 هو مجرد ملف حيث قمت بحفظ 4096 بايت من
[0x00011FC0:00011FC0+4096] .
النشاط حول 1FC4
لم نر حتى الآن العنوان
0x00001FC4 ، لكن من السهل العثور عليه ، لأن الكتلة تنتقل مباشرةً بعد الدورة الأولى تقريبًا.
تقوم هذه الكتلة بتغيير المحتويات على العنوان
0x00FF0D46 (تسجيل
a2 ) ، وهذا هو المكان الذي يتم فيه تخزين مفتاح التجزئة ، لذلك نحن ندرس الآن هذا الحظر. دعونا نرى ما يحدث هنا.
- الشرط الذي يحدد ما إذا كان يتم تحديد الفرع الأيسر أو الأيمن هو:
( ) & 0b1 != 0 . وهذا هو ، يتم التحقق من أول جزء من التجزئة. - إذا نظرت إلى كلا الفرعين ، سترى:
- في كلتا الحالتين ، يحدث تحول إلى اليمين بمقدار 1 بت.
- في الفرع الأيسر ، يتم تنفيذ عملية التجزئة
0x8000 . - في كلتا الحالتين ، تتم كتابة قيمة التجزئة المُعالجة إلى العنوان
0x00FF0D46 ، أي ، يتم استبدال التجزئة بقيمة جديدة. - العمليات الحسابية الإضافية ليست حرجة ، لأنه ، بشكل عام ، لا توجد عمليات كتابة في
(a2) (لا توجد تعليمات حول المعامل الثاني سيكون (a2) ).
تخيل كتلة مثل هذا:
def transform(hash_2b): new = hash_2b >> 1 if hash_2b & 0b1 != 0: new = new | 0x8000 return new
الحلقة الهامة الثانية هي loc_203E
loc_203E - الحلقة ، لأن
0x0000206C bne.s loc_203E .
تحسب هذه الدورة التجزئة وهنا هي
sub_E3E الرئيسية:
jsr (a0) هي استدعاء لوظيفة
sub_E3E التي قمنا بفحصها بالفعل - تعتمد على النتيجة السابقة لعملها وعلى بعض وسيطات الإدخال (تم تمريرها من خلال السجل
d2 أعلاه ، وهنا من خلال
d0 ).
دعونا معرفة ما يتم نقلها إليها من خلال سجل
d0 .
لقد التقينا بالفعل بالبناء
0x34(a2) - تقوم الدالة
sub_E3E بحفظ الوسيطة التي تم تمريرها هناك. هذا يعني أنه يتم استخدام الوسائط التي تم تمريرها مسبقًا في هذه الحلقة. لكن ليس كل شيء.
فك تشفير جزء الكود:
2 a2+0x1C move.w 0x1C(a2), d0 neg.l d0 a0 sub_E3E movea.l 0x34(a2), a0 , d0 2 a0-d0( d0 ) move.b (a0, d0.l), d0
خلاصة القول هي إجراء بسيط: في كل تكرار ، اتخذ
d0 الوسيطة المخزنة من نهاية الصفيف. وهذا هو ، إذا تم تخزين 4 في
d0 ، فإننا نأخذ العنصر الرابع من النهاية.
إذا كان الأمر كذلك ، ماذا بالضبط
d0 ؟ فعلت هنا بدون نصوص ، لكنني ببساطة كتبت بها ، وأضع استراحة في بداية هذه المجموعة. ها هم:
0x04, 0x04, 0x04, 0x1C, 0x1A, 0x1A, 0x06, 0x42, 0x02 .
الآن لدينا كل شيء لكتابة وظيفة حساب مفتاح التجزئة كاملة.
وظيفة حساب التجزئة الكامل
def finish_hash(hash_2b):
فحص الصحة
- في المصحح ، قمنا بتعيين فاصل إلى العنوان
0x0000180A move.l 0x1000,(sp) (مباشرة بعد حساب التجزئة). - فاصل لمعالجة
0x00001F16 beq.w loc_20EA (مقارنة التجزئة النهائي مع ثابت 0xCB4C ). - في البرنامج ، أدخل المفتاح
ABCDEFGHIJKLMNOP ، واضغط على Enter . - توقف مصحح الأخطاء عند
0x0000180A ، ونرى أن القيمة 0xFFFF44CC تتم 0x44CC سجل d5 ، 0x44CC هي التجزئة الأولى. - نبدأ المصحح كذلك.
- نتوقف عند
0x00001F16 ونرى أنه عند 0x00FF0D6A تكمن 0x4840 - التجزئة النهائي
- الآن تحقق من وظيفة finish_hash (hash_2b) لدينا:
>>> r = finish_hash(0x44CC) >>> print(hex(r)) 0x4840
نحن نبحث عن المفتاح الصحيح 1
المفتاح الصحيح هو هذا المفتاح الذي تجزئة النهائي هو
0xCB4C (وجدت أعلاه). ومن هنا السؤال: ما الذي يجب أن يكون أول تجزئة للنهائي لتصبح
0xCB4C ؟
من السهل الآن اكتشاف ذلك:
def find_CB4C(): result = [] for hash_2b in range(0xFFFF+1): final_hash = finish_hash(hash_2b) if final_hash == 0xCB4C: result.append(hash_2b) return result >>> r = find_CB4C() >>> print(r)
يقترح إخراج البرنامج أن هناك خيار واحد فقط: يجب أن تكون التجزئة الأولى هي
0xFEDC .
ما هي الشخصيات التي نحتاجها حتى يكون أول تجزئة لها هو
0xFEDC ؟
منذ
0xFEDC = __4_ ^ __4_ ، تحتاج إلى العثور فقط على
__4_ ، لأن
__4_ = __4_ ^ 0xFEDC . ثم فك تشفير كل من التجزئة.
الخوارزمية هي كما يلي:
def get_first_half(): from collections import deque from random import randint def get_pairs(): pairs = [] for i in range(0xFFFF + 1): pair = (i, i ^ 0xFEDC) pairs.append(pair) pairs = deque(pairs) pairs.rotate(randint(0, 0xFFFF)) return list(pairs) pairs = get_pairs() for pair in pairs: key_4s_0 = decode_hash_4s(pair[0]) key_4s_1 = decode_hash_4s(pair[1]) hash_2b_0 = get_hash_2b(key_4s_0) hash_2b_1 = get_hash_2b(key_4s_1) if hash_2b_0 == pair[0] and hash_2b_1 == pair[1]: return key_4s_0, key_4s_1
مجموعة من الخيارات ، اختر أيًا منها.
نحن نبحث عن المفتاح الصحيح 2
النصف الأول من المفتاح جاهز ، ماذا عن الثاني؟
هذا هو أسهل جزء.
يقع الجزء المسؤول من التعليمات البرمجية في
0x00FF2012 ، وحصلت عليه من خلال التتبع اليدوي ، بدءًا من العنوان
0x00001F16 beg.w loc_20EA (التحقق من صحة النصف الأول من المفتاح). في السجل
a0 هو عنوان البريد ،
loc_FF2012 هي دورة ، لأن
bne.s loc_FF2012 . يتم تنفيذه طالما كان هناك
*(a0+d0) (البايت التالي من البريد).
يستدعي تعليمة
get_hash_2b jsr (a3) وظيفة
get_hash_2b المألوفة بالفعل ، والتي تعمل الآن مع النصف الثاني من المفتاح.
لنجعل الكود أكثر وضوحًا:
while(d1 != 0x20){ d2++ d1 = d1 & 0xFF d3 = d3 + d1 d0 = 0 d0 = d2 d1 = *(a0+d0) } d0 = get_hash_2b(key_byte_8) d3 = d0^d3 d0 = get_hash_2b(key_byte_12) d2 = d2 - 1 d2 = d2 << 8 d2 = d0^d2 if (d2 == d3) success_branch
في السجل
d2 -
( -1) << 8 . في
d3 ، مجموع بايتات أحرف البريد.
معيار الصحة هو كما يلي:
__ ^ d2 == ___2 ^ d3 .
نكتب وظيفة اختيار النصف الثاني من المفتاح:
def get_second_half(email): from collections import deque from random import randint def get_koeff(): k1 = sum([ord(c) for c in email]) k2 = (len(email) - 1) << 8 return k1, k2 def get_pairs(k1, k2): pairs = [] for a in range(0xFFFF + 1): pair = (a, (a ^ k1) ^ k2) pairs.append(pair) pairs = deque(pairs) pairs.rotate(randint(0, 0xFFFF)) return list(pairs) k1, k2 = get_koeff() pairs = get_pairs(k1, k2) for pair in pairs: key_4s_0 = decode_hash_4s(pair[0]) key_4s_1 = decode_hash_4s(pair[1]) hash_2b_0 = get_hash_2b(key_4s_0) hash_2b_1 = get_hash_2b(key_4s_1) if hash_2b_0 == pair[0] and hash_2b_1 == pair[1]: return key_4s_0, key_4s_1
كجن
يجب أن يكون البريد كبسولة.
def keygen(email): first_half = get_first_half() second_half = get_second_half(email) return "".join(first_half) + "".join(second_half) >>> email = "M.GAYANOV@GMAIL.COM" >>> print(keygen(email)) 2A4FD493BA32AD75
شكرا لاهتمامكم! كل رمز متاح
هنا .