
قبل التاريخ
لقد حدث أن الخادم تعرض للهجوم من قبل فيروس رانسومواري ، والذي ، بواسطة "حظ" ، وضع جانباً ملفات .ibd جزئيًا (ملفات البيانات الأولية لجداول innodb) ، لكن تم تشفير ملفات .fpm بالكامل (ملفات البنية). في الوقت نفسه ، يمكن تقسيم .idb إلى:
- يخضع للاسترداد من خلال الأدوات القياسية والأدلة. لمثل هذه الحالات ، هناك مقال عظيم ؛
- الجداول المشفرة جزئيا. معظمها عبارة عن طاولات كبيرة ، والتي (كما فهمت) ، لم يكن لدى المهاجمين ذاكرة RAM كافية للتشفير الكامل ؛
- حسنًا ، الجداول المشفرة بالكامل والتي لا يمكن استردادها.
كان من الممكن تحديد الخيار الذي تنتمي إليه الجداول عن طريق فتحه في أي محرر نصوص تحت الترميز المطلوب (في حالتي هو UTF8) والنظر ببساطة إلى الملف لوجود حقول نصية ، على سبيل المثال:
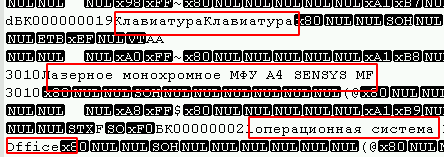
أيضًا ، في بداية الملف ، يمكنك ملاحظة عدد كبير من 0 بايت ، وعادة ما تؤثر عليها الفيروسات التي تستخدم خوارزمية تشفير البلوك (الأكثر شيوعًا).

في حالتي ، ترك المهاجمون في نهاية كل ملف مشفر سلسلة من 4 بايت (1 ، 0 ، 0 ، 0) ، مما سهل المهمة. كان البرنامج النصي كافيًا للبحث عن الملفات غير المصابة:
def opened(path): files = os.listdir(path) for f in files: if os.path.isfile(path + f): yield path + f for full_path in opened("C:\\some\\path"): file = open(full_path, "rb") last_string = "" for line in file: last_string = line file.close() if (last_string[len(last_string) -4:len(last_string)]) != (1, 0, 0, 0): print(full_path)
وبالتالي اتضح للعثور على الملفات التي تنتمي إلى النوع الأول. الثاني ينطوي على دليل طويل ، ولكن وجدت بالفعل كان كافيا. سيكون كل شيء على ما يرام ، ولكن من الضروري معرفة الهيكل الدقيق تمامًا (بالطبع) كان هناك مثل هذه الحالة التي اضطررت إلى العمل مع طاولة متغيرة باستمرار. لم يتذكر أحد ما إذا كان نوع الحقل يتغير أم أنه تمت إضافة عمود جديد.
لسوء الحظ ، لم تستطع Debri City المساعدة في هذه الحالة ، لذلك تتم كتابة هذه المقالة.
وصول الى هذه النقطة
هناك بنية جدول منذ 3 أشهر لا تتوافق مع المجال الحالي (ربما حقل واحد ، ولكن ربما أكثر). هيكل الجدول:
CREATE TABLE `table_1` ( `id` INT (11), `date` DATETIME , `description` TEXT , `id_point` INT (11), `id_user` INT (11), `date_start` DATETIME , `date_finish` DATETIME , `photo` INT (1), `id_client` INT (11), `status` INT (1), `lead__time` TIME , `sendstatus` TINYINT (4) );
في هذه الحالة ، تحتاج إلى استخراج:
id_point INT (11)؛id_user INT (11)؛date_start DATETIME ؛date_finish DATETIME.
من أجل الاسترداد ، يتم استخدام تحليل البايت لملف .ibd ، متبوعًا بترجمته في شكل أكثر قابلية للقراءة. نظرًا لإيجاد ما هو مطلوب ، يكفي أن نحلل أنواع البيانات مثل int و datatime ، فقط سيتم وصفها في المقالة ، لكن في بعض الأحيان سوف تشير أيضًا إلى أنواع بيانات أخرى ، والتي يمكن أن تساعد في حوادث أخرى مماثلة.
المشكلة 1 : الحقول ذات الأنواع DATETIME و TEXT لها قيمة فارغة ، ويتم تخطيها ببساطة في الملف ، ولهذا السبب ، لم يكن من الممكن تحديد بنية الاسترداد في حالتي. في الأعمدة الجديدة ، كانت القيمة الافتراضية خالية ، وقد يتم فقد بعض المعاملات بسبب الإعداد innodb_flush_log_at_trx_commit = 0 ، لذلك يجب قضاء وقت إضافي لتحديد البنية.
المشكلة 2 : تجدر الإشارة إلى أن الصفوف المحذوفة من خلال DELETE ستكون جميعها في ملف ibd تمامًا ، ولكن لن يتم تحديث بنيتها باستخدام ALTER TABLE. نتيجة لذلك ، يمكن أن تختلف بنية البيانات من بداية الملف إلى نهايته. إذا كنت تستخدم غالبًا OPTIMIZE TABLE ، فمن غير المحتمل أن تواجه مشكلة مماثلة.
يرجى ملاحظة أن إصدار DBMS يؤثر على طريقة تخزين البيانات ، وقد لا يعمل هذا المثال في الإصدارات الرئيسية الأخرى. في حالتي ، تم استخدام نسخة ويندوز mariadb 10.1.24. أيضًا ، على الرغم من أنك في mariadb تعمل مع جداول InnoDB ، فهي في الواقع XtraDB ، والتي تستبعد إمكانية تطبيق الأسلوب مع InnoDB mysql.
تحليل الملف
في python ، يعرض نوع البيانات bytes () البيانات في Unicode بدلاً من مجموعة الأرقام المعتادة. على الرغم من أنه يمكنك مراعاة الملف في هذا النموذج ، ولكن للراحة ، يمكنك ترجمة البايتات إلى نموذج رقمي عن طريق ترجمة صفيف البايت إلى صفيف منتظم (قائمة (example_byte_array)). في أي حال ، كلتا الطريقتين مفيدة للتحليل.
بعد النظر في العديد من ملفات ibd ، يمكنك العثور على ما يلي:
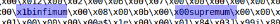
علاوة على ذلك ، إذا قمت بتقسيم الملف على هذه الكلمات الرئيسية ، فستحصل في الغالب على كتل بيانات مسطحة. سوف نستخدم infimal بمثابة المقسوم عليه.
table = table.split("infimum".encode())
ملاحظة مثيرة للاهتمام ، بالنسبة للجداول التي تحتوي على كمية صغيرة من البيانات ، بين infimal و supremum ، يوجد مؤشر لعدد الصفوف في الكتلة.
 - جدول اختبار مع الصف الأول
- جدول اختبار مع الصف الأول
 - جدول الاختبار مع 2 صفوف
- جدول الاختبار مع 2 صفوف
يمكن تخطي صفيف جدول الصفوف [0]. بعد أن نظرت فيه ، لم أتمكن من العثور على البيانات الأولية للجداول. على الأرجح ، يتم استخدام هذه الكتلة لتخزين الفهارس والمفاتيح.
بدءًا من الجدول [1] وترجمته إلى صفيف رقمي ، يمكنك بالفعل ملاحظة بعض الأنماط ، وهي:

هذه هي القيم int المخزنة في سلسلة. تشير البايت الأول إلى ما إذا كان الرقم موجبًا أم سالبًا. في حالتي ، جميع الأرقام إيجابية. من الـ 3 بايت المتبقية ، يمكنك تحديد الرقم باستخدام الوظيفة التالية. السيناريو:
def find_int(val: str):
على سبيل المثال ، 128 ، 0 ، 0 ، 1 = 1 ، أو 128 ، 0 ، 75 ، 108 = 19308 .
يحتوي الجدول على مفتاح أساسي مع زيادة تلقائية ، وهنا يمكنك أيضًا العثور عليه

بمقارنة البيانات من جداول الاختبار ، تم الكشف عن أن كائن DATETIME يتكون من 5 بايت ، يبدأ بـ 153 (على الأرجح يشير إلى فترات سنوية). نظرًا لأن نطاق DATTIME هو "1000-01-01" إلى "9999-12-31" ، أعتقد أن عدد البايتات يمكن أن يختلف ، لكن في حالتي ، تنخفض البيانات في الفترة من 2016 إلى 2019 ، لذلك نحن نفترض أن 5 بايت كافية .
لتحديد الوقت بدون ثوانٍ ، تمت كتابة الوظائف التالية. السيناريو:
day_ = lambda x: x % 64 // 2
لمدة عام وشهر ، لم يكن من الممكن كتابة وظيفة عمل صحية ، لذلك كان لا بد لي من hardcode. السيناريو:
ym_list = {'2016, 1': '153, 152, 64', '2016, 2': '153, 152, 128', '2016, 3': '153, 152, 192', '2016, 4': '153, 153, 0', '2016, 5': '153, 153, 64', '2016, 6': '153, 153, 128', '2016, 7': '153, 153, 192', '2016, 8': '153, 154, 0', '2016, 9': '153, 154, 64', '2016, 10': '153, 154, 128', '2016, 11': '153, 154, 192', '2016, 12': '153, 155, 0', '2017, 1': '153, 155, 128', '2017, 2': '153, 155, 192', '2017, 3': '153, 156, 0', '2017, 4': '153, 156, 64', '2017, 5': '153, 156, 128', '2017, 6': '153, 156, 192', '2017, 7': '153, 157, 0', '2017, 8': '153, 157, 64', '2017, 9': '153, 157, 128', '2017, 10': '153, 157, 192', '2017, 11': '153, 158, 0', '2017, 12': '153, 158, 64', '2018, 1': '153, 158, 192', '2018, 2': '153, 159, 0', '2018, 3': '153, 159, 64', '2018, 4': '153, 159, 128', '2018, 5': '153, 159, 192', '2018, 6': '153, 160, 0', '2018, 7': '153, 160, 64', '2018, 8': '153, 160, 128', '2018, 9': '153, 160, 192', '2018, 10': '153, 161, 0', '2018, 11': '153, 161, 64', '2018, 12': '153, 161, 128', '2019, 1': '153, 162, 0', '2019, 2': '153, 162, 64', '2019, 3': '153, 162, 128', '2019, 4': '153, 162, 192', '2019, 5': '153, 163, 0', '2019, 6': '153, 163, 64', '2019, 7': '153, 163, 128', '2019, 8': '153, 163, 192', '2019, 9': '153, 164, 0', '2019, 10': '153, 164, 64', '2019, 11': '153, 164, 128', '2019, 12': '153, 164, 192', '2020, 1': '153, 165, 64', '2020, 2': '153, 165, 128', '2020, 3': '153, 165, 192','2020, 4': '153, 166, 0', '2020, 5': '153, 166, 64', '2020, 6': '153, 1, 128', '2020, 7': '153, 166, 192', '2020, 8': '153, 167, 0', '2020, 9': '153, 167, 64','2020, 10': '153, 167, 128', '2020, 11': '153, 167, 192', '2020, 12': '153, 168, 0'} def year_month(x1, x2):
أنا متأكد من أنك إذا قضيت عددًا من الوقت ، فيمكن تصحيح سوء الفهم هذا.
بعد ذلك ، ترجع الدالة كائن التاريخ والوقت من سلسلة. السيناريو:
def find_data_time(val:str): val = [int(v) for v in val.split(", ")] day = day_(val[2]) hour = hour_(val[2], val[3]) minutes = min_(val[3], val[4]) year, month = year_month(val[1], val[2]) return datetime(year, month, day, hour, minutes)
كان من الممكن اكتشاف القيم المتكررة بشكل متكرر من int و int و datetime و datetime 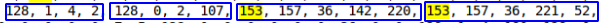 يبدو أن هذا هو ما تحتاجه. علاوة على ذلك ، لا يتم تكرار هذا التسلسل مرتين في كل سطر.
يبدو أن هذا هو ما تحتاجه. علاوة على ذلك ، لا يتم تكرار هذا التسلسل مرتين في كل سطر.
باستخدام تعبير عادي ، نجد البيانات اللازمة:
fined = re.findall(r'128, \d*, \d*, \d*, 128, \d*, \d*, \d*, 153, 1[6,5,4,3]\d, \d*, \d*, \d*, 153, 1[6,5,4,3]\d, \d*, \d*, \d*', int_array)
يرجى ملاحظة أنه عند البحث عن طريق هذا التعبير ، لن يكون من الممكن تحديد القيم الخالية في الحقول المطلوبة ، لكن في حالتي ، هذا ليس بالأمر الحاسم. بعد أن حلقة من خلال العثور عليها. السيناريو:
result = [] for val in fined: pre_result = [] bd_int = re.findall(r"128, \d*, \d*, \d*", val) bd_date= re.findall(r"(153, 1[6,5,4,3]\d, \d*, \d*, \d*)", val) for it in bd_int: pre_result.append(find_int(bd_int[it])) for bd in bd_date: pre_result.append(find_data_time(bd)) result.append(pre_result)
في الواقع كل شيء ، البيانات من مجموعة النتائج ، هذه هي البيانات التي نحتاجها. ### ملاحظة.
أنا أفهم أن هذه الطريقة ليست مناسبة للجميع ، ولكن الهدف الرئيسي من المقالة هو المطالبة بالتحرك بدلاً من حل جميع مشاكلك. أعتقد أن الحل الأصح هو البدء في دراسة الكود المصدري لماريب نفسه ، لكن بسبب الوقت المحدود ، بدا أن الطريقة الحالية هي الأسرع.
في بعض الحالات ، بعد تحليل الملف ، يمكنك تحديد البنية التقريبية واستعادة إحدى الطرق القياسية من الروابط أعلاه. سيكون أكثر صحة بكثير ويسبب مشاكل أقل.