مرحباً عزيزي القراء من هبر. اسمي رستم وأنا المطور الرئيسي لشركة DAR الكازاخستانية لتقنية المعلومات. في هذه المقالة ، سأخبرك بما تحتاج إلى معرفته قبل الانتقال إلى قوالب Sourcing Event و CQRS باستخدام مجموعة أدوات Akka.
حوالي عام 2015 ، بدأنا في تصميم نظامنا البيئي. بعد التحليل وبناءً على الخبرة المكتسبة مع Scala و Akka ، قررنا التوقف عند مجموعة أدوات Akka. كان لدينا تطبيقات ناجحة لقوالب Sourcing Event مع CQRS وليس ذلك. تراكم الخبرة في هذا المجال ، والتي أود مشاركتها مع القراء. سنبحث في كيفية قيام عكا بتنفيذ هذه الأنماط ، وكذلك الأدوات المتاحة والتحدث عن عيوب عكا. آمل أنه بعد قراءة هذا المقال ، سيكون لديك فهم أكثر لمخاطر التحول إلى مجموعة أدوات Akka.
حول مواضيع CQRS و Event Sourcing ، تم كتابة العديد من المقالات حول Habré والموارد الأخرى. هذه المقالة مخصصة للقراء الذين يفهمون بالفعل ما هي CQRS و Sourcing Event. في المقالة أريد أن أركز على عكا.
تصميم يحركه المجال
تمت كتابة الكثير من المواد حول التصميم القائم على المجال (DDD). هناك كل من المعارضين ومؤيدي هذا النهج. أريد أن أضيف بمفردي أنه إذا قررت التبديل إلى Event Sourcing و CQRS ، فلن يكون من الضروري دراسة DDD. بالإضافة إلى ذلك ، فإن فلسفة DDD محسوسة في جميع أدوات Akka.
في الواقع ، تعد Event Sourcing و CQRS جزءًا صغيرًا من الصورة الكبيرة التي يطلق عليها "تصميم يحركه المجال". عند تصميم وتطوير ، قد يكون لديك العديد من الأسئلة حول كيفية تنفيذ هذه القوالب بشكل صحيح والاندماج في النظام البيئي ، ومعرفة DDD سوف تجعل حياتك أسهل.
في هذه المقالة ، يعني مصطلح الكيان (الكيان بواسطة DDD) ممثل الثبات الذي لديه معرف فريد.
لماذا سكالا؟
غالبًا ما يُسألنا لماذا سكالا ، وليس جافا. سبب واحد هو عكا. الإطار نفسه ، مكتوب بلغة سكالا مع دعم لغة جافا. هنا يجب أن أقول أن هناك أيضًا تطبيق على .NET ، ولكن هذا موضوع آخر. لكي لا أتسبب في مناقشة ، لن أكتب لماذا Scala أفضل أو أسوأ من Java. سأخبركم فقط ببعض الأمثلة التي ، في رأيي ، تتمتع Scala بميزة على Java عند العمل مع Akka:
- أشياء غير قابلة للتغيير. في Java ، تحتاج إلى كتابة أشياء ثابتة بنفسك. صدقوني ، ليس من السهل وليس المريح جدًا أن تكتب باستمرار المعايير النهائية. في
case class Scala case class قابل للتغيير بالفعل مع وظيفة copy المضمنة - أسلوب الترميز. عند تطبيقه في Java ، ستظل تكتب بأسلوب Scala ، أي وظيفياً.
فيما يلي مثال لتنفيذ الممثل في Scala و Java:
سكالا:
object DemoActor { def props(magicNumber: Int): Props = Props(new DemoActor(magicNumber)) } class DemoActor(magicNumber: Int) extends Actor { def receive = { case x: Int => sender() ! (x + magicNumber) } } class SomeOtherActor extends Actor { context.actorOf(DemoActor.props(42), "demo")
جافا:
static class DemoActor extends AbstractActor { static Props props(Integer magicNumber) { return Props.create(DemoActor.class, () -> new DemoActor(magicNumber)); } private final Integer magicNumber; public DemoActor(Integer magicNumber) { this.magicNumber = magicNumber; } @Override public Receive createReceive() { return receiveBuilder() .match( Integer.class, i -> { getSender().tell(i + magicNumber, getSelf()); }) .build(); } } static class SomeOtherActor extends AbstractActor { ActorRef demoActor = getContext().actorOf(DemoActor.props(42), "demo");
(مثال مأخوذ من هنا )
انتبه إلى تطبيق الأسلوب createReceive() باستخدام مثال لغة Java. داخليا ، من خلال مصنع ReceiveBuilder ، يتم تطبيق مطابقة الأنماط. receiveBuilder() هي طريقة من Akka لدعم تعبيرات lambda ، وهي مطابقة النمط في Java. في سكالا ، يتم تنفيذ هذا أصلاً. موافق ، الرمز في Scala أقصر وأسهل في القراءة.
- الوثائق والأمثلة. على الرغم من وجود أمثلة في الوثائق الرسمية في Java ، على الإنترنت ، توجد جميع الأمثلة تقريبًا في Scala. أيضًا ، سيكون من الأسهل بالنسبة لك التنقل في مصادر مكتبة عكا.
من حيث الأداء ، لن يكون هناك فرق بين Scala و Java ، حيث يدور كل شيء في JVM.
مستودع
قبل تنفيذ Sourcing Event مع Akka Persistence ، نوصي بأن تختار مسبقًا قاعدة بيانات لتخزين البيانات الدائم. يعتمد اختيار الأساس على متطلبات النظام وعلى رغباتك وتفضيلاتك. يمكن تخزين البيانات في NoSQL و RDBMS ، وفي نظام الملفات ، على سبيل المثال LevelDB من Google .
من المهم ملاحظة أن Akka Persistence غير مسؤول عن كتابة وقراءة البيانات من قاعدة البيانات ، ولكنه يقوم بذلك من خلال مكون إضافي يجب أن يقوم بتطبيق Akka Persistence API.
بعد اختيار أداة لتخزين البيانات ، تحتاج إلى تحديد مكون إضافي من القائمة ، أو كتابته بنفسك. الخيار الثاني ، أنا لا أوصي لماذا إعادة اختراع العجلة.
لتخزين البيانات بشكل دائم ، قررنا البقاء في كاساندرا. الحقيقة هي أننا نحتاج إلى قاعدة موثوقة وسريعة وموزعة. بالإضافة إلى ذلك ، ترافق Typesafe نفسها المكون الإضافي ، الذي ينفذ بالكامل واجهة برمجة تطبيقات Akka Persistence . يتم تحديثه باستمرار وبالمقارنة مع الآخرين ، كتب المساعد كاساندرا وثائق أكثر اكتمالا.
تجدر الإشارة إلى أن البرنامج المساعد لديه أيضا العديد من المشاكل. على سبيل المثال ، لا يوجد إصدار ثابت (في وقت كتابة هذا التقرير ، كان الإصدار الأخير هو 0.97). بالنسبة لنا ، كان أكبر مصدر إزعاج واجهناه أثناء استخدام هذا البرنامج المساعد هو فقدان الأحداث عند قراءة استعلام مستمر لبعض الكيانات. للحصول على صورة كاملة ، يوجد أدناه مخطط CQRS:
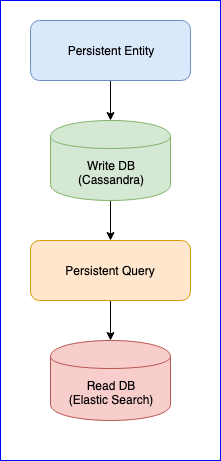
يقوم الكيان المستمر بتوزيع أحداث الكيان على علامات باستخدام خوارزمية تجزئة متناسقة (على سبيل المثال ، 10 قطع)
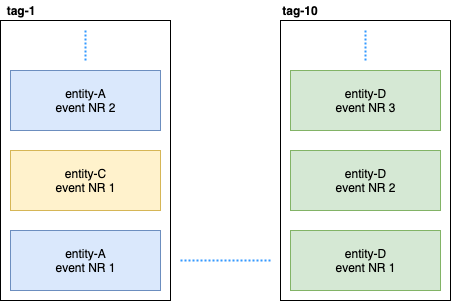
بعد ذلك ، يشترك Persistent Query في هذه العلامات ويطلق دفقًا يضيف بيانات إلى البحث المرن. نظرًا لأن Cassandra في كتلة ، ستنتشر الأحداث عبر العقد. يمكن أن تتراجع بعض العقد وسوف تستجيب ببطء أكثر من غيرها. ليس هناك ما يضمن أنك سوف تتلقى الأحداث في ترتيب صارم. لحل هذه المشكلة ، يتم تطبيق المكون الإضافي بحيث إذا تلقى حدثًا غير مُرتب ، على سبيل المثال ، entity-A event NR 2 ، فإنه ينتظر وقتًا معينًا للحدث الأولي وإذا لم يتلقه ، فسوف يتجاهل كل أحداث هذا الكيان. حتى حول هذا الموضوع ، كانت هناك مناقشات حول Gitter. إذا كان أي شخص مهتمًا ، يمكنك قراءة المراسلات بين @ kotdv ومطوري البرنامج المساعد: Gitter
كيف يمكن حل سوء الفهم هذا:
- تحتاج إلى تحديث المكون الإضافي إلى أحدث إصدار. في الإصدارات الأخيرة ، قام مطورو Typesafe بحل العديد من المشكلات المتعلقة بالتناسق النهائي. لكننا ما زلنا ننتظر نسخة مستقرة
- تمت إضافة إعدادات أكثر دقة للمكون المسؤول عن تلقي الأحداث. يمكنك محاولة زيادة المهلة المحددة للأحداث غير مرتبة من أجل تشغيل أكثر موثوقية
assandra-query-journal.events-by-tag.eventual-consistency.delay=10s الإضافي: c assandra-query-journal.events-by-tag.eventual-consistency.delay=10s - تكوين كاساندرا على النحو الموصى به من قبل DataStax. ضع أداة تجميع مجمعي البيانات المهملة G1 وقم بتخصيص أكبر قدر ممكن من الذاكرة لـ Cassandra .
في النهاية ، قمنا بحل المشكلة المتعلقة بالأحداث المفقودة ، ولكن يوجد الآن تأخير ثابت للبيانات على جانب طلب الاستمرارية (من خمس إلى عشر ثوان). تقرر ترك نهج البيانات المستخدمة في التحليلات ، وحيثما تكون السرعة مهمة ، ننشر الأحداث يدويًا على الحافلة. الشيء الرئيسي هو اختيار الآلية المناسبة لمعالجة البيانات أو نشرها: مرة واحدة على الأقل أو مرة واحدة على الأكثر. وصف جيد من عكا ويمكن الاطلاع هنا . كان من المهم بالنسبة لنا الحفاظ على تناسق البيانات ، وبالتالي ، بعد كتابة البيانات بنجاح إلى قاعدة البيانات ، قدمنا حالة انتقال تتحكم في النشر الناجح للبيانات على الناقل. ما يلي هو رمز عينة:
object SomeEntity { sealed trait Event { def uuid: String } case class DidSomething(uuid: String) extends Event /** * , . */ case class LastEventPublished(uuid: String) extends Event /** * , . * @param unpublishedEvents – , . */ case class State(unpublishedEvents: Seq[Event]) object State { def updated(event: Event): State = event match { case evt: DidSomething => copy( unpublishedEvents = unpublishedEvents :+ evt ) case evt: LastEventPublished => copy( unpublishedEvents = unpublishedEvents.filter(_.uuid != evt.uuid) ) } } } class SomeEntity extends PersistentActor { … persist(newEvent) { evt => updateState(evt) publishToEventBus(evt) } … }
إذا لم يكن من الممكن نشر الحدث SomeEntity ، SomeEntity بدء SomeEntity في البداية ، سيعرف أن حدث DidSomething يصل إلى الحافلة وسيحاول إعادة نشر البيانات مرة أخرى.
مسلسل
التسلسل هو نقطة بنفس القدر من الأهمية في استخدام عكا. لديه وحدة داخلية - عكا التسلسل . تستخدم هذه الوحدة لتسلسل الرسائل عند تبادلها بين الجهات الفاعلة وعند تخزينها من خلال واجهة برمجة تطبيقات Persistence. افتراضيًا ، يتم استخدام Java serializer ، ولكن يوصى باستخدام واحد آخر. المشكلة هي أن Java Serializer بطيء ويشغل مساحة كبيرة. هناك حلان شائعان - وهما JSON و Protobuf. JSON ، على الرغم من بطئها ، أسهل في التنفيذ والصيانة. إذا كنت بحاجة إلى تقليل تكلفة التسلسل وتخزين البيانات ، فيمكنك التوقف عند Protobuf ، ولكن بعد ذلك ستصبح عملية التطوير أبطأ. بالإضافة إلى نموذج المجال ، يجب عليك كتابة نموذج بيانات آخر. لا تنسى إصدار البيانات. كن مستعدًا دائمًا لكتابة التعيين بين نموذج المجال ونموذج البيانات.
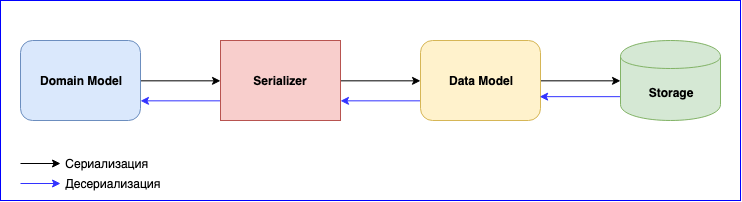
إضافة حدث جديد - كتابة التعيين. تم تغيير بنية البيانات - اكتب نسخة جديدة من نموذج البيانات وتغيير وظيفة التعيين. لا تنسى اختبارات للمتسللين. بشكل عام ، سيكون هناك الكثير من العمل ، لكن في النهاية ستحصل على مكونات متراصة بشكل فضفاض.
النتائج
- دراسة بعناية واختيار قاعدة مناسبة والبرنامج المساعد لنفسك. أوصي باختيار مكون إضافي يتم صيانته جيدًا ولن يتوقف عن التطوير. المنطقة جديدة نسبيًا ، لا تزال هناك مجموعة من العيوب التي لم يتم حلها بعد
- إذا قمت بتحديد سعة التخزين الموزعة ، فسيتعين عليك حل المشكلة مع تأخير يصل إلى 10 ثوانٍ بنفسك ، أو تحمله
- تعقيد التسلسل. يمكنك التضحية بالسرعة والتوقف على JSON ، أو اختيار Protobuf وكتابة الكثير من المحولات ودعمها.
- هناك إيجابيات لهذا القالب ، هذه مكونات مترابطه وفرق تطوير مستقله تبني نظام كبير واحد.