
في الآونة الأخيرة ، كانت هناك عدة مقالات تنتقد ImageNet ، وربما أشهر مجموعة من الصور المستخدمة لتدريب الشبكات العصبية.
في المقالة الأولى ، يعمل تقريب شبكات CNN مع نماذج الميزات المحلية بشكل جيد بشكل مدهش على ImageNet ، يأخذ المؤلفون نموذجًا مشابهًا لكيس الكلمات ويستخدمون أجزاء من الصورة كـ "كلمات". يمكن أن يصل حجم هذه الأجزاء إلى 9 × 9 بكسل. وفي الوقت نفسه ، في مثل هذا النموذج ، حيث لا توجد معلومات كاملة حول الترتيب المكاني لهذه الأجزاء ، فإن المؤلفين يحصلون على دقة تتراوح من 70 إلى 86٪ (على سبيل المثال ، دقة ResNet-50 العادية هي حوالي 93٪).
في المقالة الثانية من CNNs المدربة من ImageNet ، تنحاز نحو الملمس ، يستنتج المؤلفون أن مجموعة بيانات ImageNet بأكملها والطريقة التي يرى بها الأشخاص والشبكات العصبية الصور خاطئة ويقترحون استخدام مجموعة بيانات جديدة - Stylized-ImageNet.
بمزيد من التفاصيل حول ما يراه الناس في الصور والشبكات العصبية
ImageNet
بدأ إنشاء مجموعة بيانات ImageNet في عام 2006 بجهود البروفيسور فاي فاي لي وتستمر في التطور حتى يومنا هذا. في الوقت الحالي ، يحتوي على حوالي 14 مليون صورة تنتمي إلى أكثر من 20 ألف فئة مختلفة.
منذ عام 2010 ، تم استخدام مجموعة فرعية من مجموعة البيانات هذه ، والمعروفة باسم ImageNet 1K مع ما يقرب من مليون صورة وآلاف الطبقات ، في تحدي التعرف البصري على نطاق واسع لـ ImageNet (ILSVRC). في هذه المسابقة ، في عام 2012 ، حصلت AlexNet ، وهي شبكة عصبية تلافيفية ، على أعلى دقة بنسبة 60 ٪ وأعلى 5 بنسبة 80 ٪.
في هذه المجموعة الفرعية من مجموعة البيانات ، يقوم الأشخاص من البيئة الأكاديمية بقياس SOTA الخاصة بهم عندما يقدمون بنية شبكة جديدة.
القليل عن عملية التعلم في مجموعة البيانات هذه. سنتحدث عن بروتوكول التدريب على ImageNet في البيئة الأكاديمية. أي أنه عندما يتم عرض نتائج بعض المجموعات SE أو شبكة ResNeXt أو DenseNet في المقالة ، فإن العملية تبدو كما يلي: تتعلم الشبكة لمدة 90 عصور ، وتنخفض سرعة التعلم بحلول العصرين الثلاثين والستين ، كل 10 مرات ، كمحسِّن يتم تحديد SGD عادي مع تسوس صغير للوزن ، ويتم استخدام RandomCrop و HorizontalFlip فقط من التعزيزات ، وعادةً ما يتم تغيير حجم الصورة إلى 224 × 224 بكسل.
فيما يلي مثال لرسالة pytorch للتدريب على ImageNet.
BagNet
دعنا نعود إلى المقالات المذكورة سابقًا. في البداية ، أراد المؤلفون أن يكون النموذج أسهل في التفسير من الشبكات العميقة العادية. مستوحاة من فكرة نماذج الحقائب ، يقومون بإنشاء مجموعة خاصة بهم من النماذج - BagNets. باستخدام كأساس شبكة ResNet-50 المعتادة.
باستبدال بعض التلفيفات 3x3 بـ 1x1 في ResNet-50 ، فإنها تضمن تقليل مجال الخلايا العصبية في الطبقة التلافيفية الأخيرة بشكل كبير ، حتى 9x9 بكسل. وبالتالي ، فإنهم يقصرون المعلومات المتاحة لخلية عصبية فردية على جزء صغير جدًا من الصورة بأكملها - وهو عبارة عن رقعة من عدة وحدات بكسل. تجدر الإشارة إلى أنه بالنسبة إلى ResNet-50 البكر ، فإن حجم حقل الاستلام يزيد عن 400 بكسل ، والذي يغطي الصورة بالكامل ، والتي عادةً ما يتغير حجمها إلى 224 × 224 بكسل.
هذا التصحيح هو أقصى جزء من الصورة يمكن للنموذج من خلالها استخراج البيانات المكانية. في نهاية النموذج ، تم تلخيص جميع البيانات ببساطة ، ولا يستطيع النموذج بأي حال معرفة مكان كل تصحيح بالنسبة إلى التصحيحات الأخرى.
في المجموع ، تم اختبار ثلاثة أنواع من الشبكات مع مجال تقبلا 9x9 ، 17x17 و 33x33. وعلى الرغم من الافتقار الكامل للمعلومات المكانية ، فقد تمكنت هذه النماذج من تحقيق دقة جيدة في التصنيف على ImageNet. دقة أعلى 5 للبقع كانت 9x9 70 ٪ ، 17x17 - 80 ٪ ، 33x33 - 86 ٪. للمقارنة ، تبلغ دقة ResNet-50 top-5 حوالي 93٪.

يظهر هيكل النموذج في الشكل أعلاه. يتم تحويل كل تصحيح من qxqx3 بكسل مقطوع من الصورة إلى ناقل 2048. بعد ذلك ، يتم تغذية هذا المتجه لإدخال مصنف خطي ، والذي ينتج درجات لكل فئة من فئات 1000. من خلال جمع درجات كل تصحيح في صفيف ثنائي الأبعاد ، يمكنك الحصول على خريطة حرارة لكل فئة ولكل بكسل من الصورة الأصلية. تم الحصول على الدرجات النهائية للصورة من خلال جمع خريطة الحرارة لكل فئة.
أمثلة لخرائط الحرارة لبعض الفئات:

كما ترون ، فإن أكبر مساهمة في الاستفادة لفئة معينة تتم بواسطة تصحيحات موجودة عند حواف الكائنات. يتم تجاهل بقع من الخلفية تقريبا. كل شيء على ما يرام حتى الآن.
دعونا نلقي نظرة على بقع الأكثر إفادة:

على سبيل المثال ، أخذ المؤلفون أربعة فصول. لكل منهم ، تم اختيار تصحيحات 2 × 7 الأكثر أهمية (أي ، تصحيحات حيث كانت درجة هذه الفئة هي الأعلى). يتم أخذ الصف العلوي المكون من 7 تصحيحات من صور للفئة المطابقة فقط ، القاع - من العينة الكاملة للصور.
ما يمكن رؤيته في هذه الصور رائع. على سبيل المثال ، بالنسبة لفئة tench (tench ، السمك) ، تعد الأصابع ميزة مميزة. نعم ، أصابع الإنسان العادية على خلفية خضراء. وكل هذا بسبب وجود صياد في جميع الصور تقريبًا مع هذه الفئة ، والذي ، في الواقع ، يحمل هذه السمكة بين يديه ، ويظهر الكأس.
لأجهزة الكمبيوتر المحمول ، ميزة مميزة هي مفاتيح الحروف. تحسب مفاتيح الآلة الكاتبة أيضًا في هذه الفئة.
السمة المميزة لغلاف الكتب هي الحروف على خلفية ملونة. فليكن نقشًا على قميص أو حقيبة.
يبدو أن هذه المشكلة لا ينبغي أن تزعجنا. لأنه متأصل فقط في فئة ضيقة من الشبكات ذات مجال تقبلي محدود للغاية. لكن علاوة على ذلك ، قام المؤلفون بحساب الارتباط بين اللوجيستات (مخرجات الشبكة قبل softmax النهائي) المعينة لكل فئة من فئات BagNet مع حقل تقبلي مختلف ، وكذلك السجلات من VGG-16 ، التي تحتوي على حقل تقريبي كبير بما فيه الكفاية. ووجدوها عالية جدا.
العلاقة بين BagNets و VGG-16 تساءل المؤلفون عما إذا كان BagNet يحتوي على أي تلميحات حول كيفية اتخاذ الشبكات الأخرى القرارات.
في أحد الاختبارات ، استخدموا تقنية مثل Image Scrambling. والتي تتكون في استخدام مولد نسيج يعتمد على مصفوفات غرام لإنشاء صورة حيث يتم حفظ القوام ، ولكن المعلومات المكانية مفقودة.

تم تجهيز VGG-16 ، المدربين على صور عادية كاملة ، مع هذه الصور المخفوقة بشكل جيد. انخفضت دقة أعلى 5 من 90 ٪ إلى 80 ٪. وهذا يعني ، حتى الشبكات التي تحتوي على حقل تقريبي كبير إلى حد ما لا تزال تفضل تذكر القوام وتجاهل المعلومات المكانية. لذلك ، لم تنخفض دقتها بشكل كبير على الصور المخفوقة.
أجرى المؤلفون سلسلة من التجارب حيث قاموا بمقارنة أجزاء الصور الأكثر أهمية لشبكة BagNet والشبكات الأخرى (VGG-16 و ResNet-50 و ResNet-152 و DenseNet-169). ألمح كل شيء إلى أن الشبكات الأخرى ، مثل BagNet ، تعتمد على أجزاء صغيرة من الصور وترتكب نفس الأخطاء عند اتخاذ القرارات. كان هذا ملحوظًا بشكل خاص بالنسبة للشبكات غير العميقة جدًا مثل VGG.
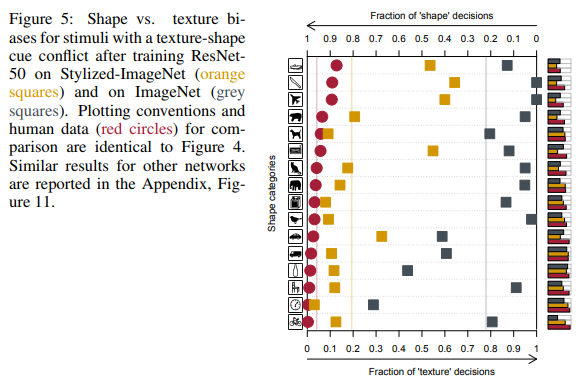
دفع ميل الشبكات هذا إلى اتخاذ القرارات على أساس القوام ، على عكسنا ، الأشخاص الذين يفضلون الشكل (انظر الشكل أدناه) ، مؤلفي المقالة الثانية إلى إنشاء مجموعة بيانات جديدة تستند إلى ImageNet.
ImageNet منمق
بادئ ذي بدء ، قام مؤلفو المقالة باستخدام نقل النمط بإنشاء مجموعة من الصور يتناقض فيها الشكل (البيانات المكانية) والقوام في صورة واحدة. وقمنا بمقارنة نتائج الأشخاص وشبكات الإلتفاف العميقة للمباني المختلفة على مجموعة بيانات مركبة من 16 فئة.

في أقصى اليمين ، يرى الناس قطة وشبكة - فيل.

مقارنة نتائج الناس والشبكات العصبية.
كما ترون ، يعتمد الأشخاص عند تعيين كائن لفئة معينة على شكل الكائنات ، والشبكات العصبية على القوام. في الشكل أعلاه ، رأى الناس قطة وشبكة - فيل.
نعم ، هنا يمكنك أن تشكو من حقيقة أن الشباك هي أيضًا على حق إلى حد ما ، وهذا ، على سبيل المثال ، يمكن أن يكون فيلًا تم تصويره من مسافة قريبة مع وشم قطة محبوبة. لكن حقيقة أن الشبكات عند اتخاذ القرارات تتصرف بشكل مختلف عن سلوك الناس ، نظر المؤلفون في المشكلة وبدأوا في البحث عن طرق لحلها.
كما ذكر أعلاه ، بالاعتماد فقط على القوام ، فإن الشبكة قادرة على تحقيق نتيجة جيدة بدقة 86 ٪ أعلى - 5. وهذا لا يتعلق بالعديد من الفئات ، حيث تساعد المواد على تصنيف الصور بشكل صحيح ، ولكن حول معظم الفئات.
تكمن المشكلة في ImageNet نفسها ، حيث سيظهر لاحقًا أن الشبكة قادرة على تعلم النموذج ، لكن لا ، لأن القوام كافية لمجموعة البيانات هذه ، والخلايا العصبية المسؤولة عن القوام موجودة على طبقات ضحلة ، والتي هي أسهل بكثير للتدريب.
باستخدام هذه المرة آلية نقل نمط AdaIN مختلفة قليلاً ، أنشأ المؤلفون مجموعة بيانات جديدة - Stylized ImageNet. تم أخذ شكل الكائنات من ImageNet ، ومجموعة من القوام من هذه المنافسة على Kaggle . البرنامج النصي للجيل متاح على الرابط .

علاوة على ذلك ، على سبيل الإيجاز ، سيتم الإشارة إلى ImageNet باسم IN ، و ImageNet منمق كـ SIN .
أخذ المؤلفون ResNet-50 وثلاثة BagNet مع حقل تقريبي مختلف وتم تدريبهم على نموذج منفصل لكل من مجموعة البيانات.
وهنا ما فعلوه:
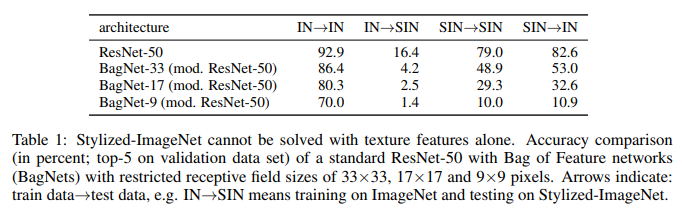
ما نراه هنا. ResNet-50 المدربين على IN غير قادر تماما على SIN. مما يؤكد جزئياً أنه عند التدريب على IN ، تتأرجح الشبكة إلى القوام وتتجاهل شكل الكائنات. في الوقت نفسه ، تتوافق ResNet-50 المدربة على SIN بشكل مثالي مع كل من SIN و IN. أي إذا كانت محرومة من مسار بسيط ، تتبع الشبكة مسارًا صعبًا - فهي تعلم شكل الكائنات.
بدأت BagNet أخيرًا في التصرف كما هو متوقع ، لا سيما على تصحيحات صغيرة ، لأنه لا يوجد لديه شيء يتعلق بالتشبث به - المعلومات عن النسيج مفقودة ببساطة من SIN.
في تلك الفئات الستة عشر التي تم ذكرها سابقًا ، بدأت ResNet-50 ، المدربة على SIN ، في تقديم إجابات أكثر تشابهًا مع تلك التي يقدمها الأشخاص:
بالإضافة إلى تدريب ResNet-50 على SIN ، حاول المؤلفون تدريب الشبكة على مجموعة مختلطة من SIN و IN ، بما في ذلك الضبط بشكل منفصل على IN النقي.

كما ترون ، عند استخدام SIN + IN للتدريب ، تحسنت النتائج ليس فقط في المهمة الرئيسية - تصنيف الصور على ImageNet ، ولكن أيضًا على مهمة اكتشاف الكائنات في مجموعة بيانات PASCAL VOC 2007.
بالإضافة إلى ذلك ، أصبحت شبكات SIN المدربة أكثر مقاومة للضوضاء المختلفة في البيانات.
استنتاج
حتى الآن ، في عام 2019 ، بعد سبع سنوات من النجاح مع AlexNet ، عندما تُستخدم الشبكات العصبية على نطاق واسع في رؤية الكمبيوتر ، عندما أصبح ImageNet 1K بحكم الواقع المعيار لتقييم أداء النماذج في البيئة الأكاديمية ، فإن آلية كيفية اتخاذ الشبكات العصبية للقرارات ليست واضحة تمامًا. . وكيف تؤثر مجموعات البيانات التي تم تدريب هذه الشبكات عليها.
حاول مؤلفو المقالة الأولى تسليط الضوء على كيفية اتخاذ مثل هذه القرارات في شبكات ذات بنية حقيبة الميزات ذات مجال تقبلي محدود ، وهو ما يسهل تفسيره. وبمقارنة إجابات BagNet والشبكات العصبية العميقة المعتادة ، توصلنا إلى استنتاج مفاده أن عمليات صنع القرار فيها متشابهة تمامًا.
قارن مؤلفو المقالة الثانية كيف ينظر الناس والشبكات العصبية إلى صور تتناقض فيها الأشكال والقوام مع بعضها البعض. واقترحوا استخدام مجموعة بيانات جديدة ، Stylized ImageNet ، لتقليل الاختلافات الحسية. بعد الحصول على زيادة في دقة التصنيف على ImageNet وكشف عن مجموعات بيانات الطرف الثالث على سبيل المكافأة.
يمكن التوصل إلى الاستنتاج الرئيسي على النحو التالي: الشبكات التي تدرس في الصور ، والتي لديها القدرة على تذكر الخصائص المكانية ذات المستوى الأعلى للكائنات ، تفضل طريقة أسهل لتحقيق الهدف - التحليق فوق القوام. إذا كانت مجموعة البيانات التي يتدربون عليها تسمح بذلك.
بالإضافة إلى الاهتمام الأكاديمي ، تعد مشكلة تركيب النسيج مهمة بالنسبة لنا جميعًا الذين يستخدمون نماذج مدربة مسبقًا لنقل التعلم في مهامهم.
إحدى النتائج المهمة لكل هذا بالنسبة لنا هي أنه يجب ألا تثق في وزن النماذج التي يتم تدريبها مسبقًا على ImageNet ، حيث تم استخدام إضافات بسيطة لمعظمها ، والتي لا تساهم بأي حال من الأحوال في التخلص من التجاوز. ومن الأفضل ، إذا أمكن ذلك ، تدريب نماذج على تعزيزات أكثر خطورة أو Stylized ImageNet + ImageNet في العش. لتكون دائمًا قادرًا على المقارنة بين الأكثر ملاءمة لمهمتنا الحالية.