
اعتاد الكثير من الناس على تصنيف فيلم على KinoPoisk أو imdb بعد مشاهدته ، والأقسام "تم شراؤها أيضًا مع هذا المنتج" و "المنتجات الشعبية" موجودة في أي متجر عبر الإنترنت. ولكن هناك أنواع أقل دراية من التوصيات. في هذه المقالة ، سأتحدث عن المهام الموصى بها من قبل أنظمة التوصية ، وأين يجب تشغيلها وما الذي يجب على google تشغيله.
ماذا نوصي؟
ماذا لو أردنا التوصية
بمسار مريح للمستخدم ؟ الجوانب المختلفة للرحلة مهمة للمستخدمين المختلفين: توفر المقاعد ، وقت السفر ، حركة المرور ، تكييف الهواء ، منظر جميل من النافذة. مهمة غير عادية ، ولكن من الواضح تمامًا كيفية بناء مثل هذا النظام.
ماذا لو نوصي
الأخبار ؟ الأخبار سرعان ما أصبحت قديمة - تحتاج إلى عرض أحدث المقالات للمستخدمين في حين أنها لا تزال ذات صلة. من الضروري أن نفهم محتوى المقال. بالفعل أكثر صعوبة.
وإذا كنا نوصي
المطاعم بناء على ملاحظات؟ لكننا لا نوصي فقط بالمطعم ، ولكن أيضًا بالأطباق المحددة التي تستحق المحاولة. يمكنك أيضًا تقديم توصيات للمطاعم حول ما يستحق التحسين.
ماذا لو قمنا
بتوسيع المهمة وحاولنا الإجابة على السؤال: "ما المنتج الذي سيكون موضع اهتمام أكبر مجموعة من الأشخاص؟". لقد أصبح غير عادي للغاية وليس من الواضح على الفور كيفية حل هذا.
في الواقع ، هناك العديد من الاختلافات في مهمة التوصيات ولكل منها الفروق الدقيقة الخاصة به. يمكنك أن توصي أشياء غير متوقعة تماما. المثال المفضل لدي هو التوصية
بالمعاينات على Netflix .

مهمة أضيق
تأخذ مهمة مألوفة ومألوفة من التوصية بالموسيقى. ما الذي نريد أن نوصي به بالضبط؟

في هذه المجموعة ، يمكنك العثور على أمثلة لمختلف التوصيات من Spotify و Google و Yandex.
- تسليط الضوء على المصالح المتجانسة في ديلي ميكس
- شخصية أخبار إطلاق الرادار ، الإصدارات الجديدة الموصى بها ، العرض الأول
- اختيار شخصي لما تحب - قائمة تشغيل اليوم
- اختيار شخصي للمسارات التي لم يسمعها المستخدم بعد - Discover Weekly، Dejavu
- مزيج من النقطتين السابقتين وانحياز في مسارات جديدة - أنا أشعر أنني محظوظ
- تقع في المكتبة ، ولكن لم يسمع بعد - ذاكرة التخزين المؤقت
- أفضل أغانيك 2018
- المسارات التي استمعت إليها في سن الرابعة عشر والتي شكلت أذواقك - كبسولة وقتك
- المسارات التي قد تعجبك ، ولكنها تختلف عن ما يستمع إليه المستخدم عادة - قواطع التذوق
- مسارات الفنانين الذين يؤدون في مدينتك
- مجموعات النمط
- اختيارات النشاط والمزاج
وبالتأكيد يمكنك الخروج بشيء آخر. حتى إذا كنا قادرين تمامًا على التنبؤ بالمسارات التي يحبها المستخدم ، فلا يزال السؤال مطروحًا في أي شكل وفي أي تنسيق يجب إصداره.
التدريج الكلاسيكية
في البيان الكلاسيكي للمشكلة ، كل ما لدينا هو مصفوفة تصنيف عنصر المستخدم. انها قليلة للغاية ومهمتنا هي ملء القيم المفقودة. عادةً ما يتم استخدام RMSE من التصنيف المتوقع كمقياس ، ومع ذلك ،
هناك رأي مفاده أن هذا غير صحيح تمامًا وينبغي مراعاة خصائص التوصية ككل ، وليس دقة التنبؤ برقم معين.
كيفية تقييم الجودة؟
التقييم عبر الإنترنت
أفضل طريقة لتقييم جودة النظام هي التحقق المباشر من المستخدمين في سياق مقاييس العمل. قد يكون هذا هو نسبة النقر إلى الظهور (CTR) ، أو الوقت الذي يقضيه النظام ، أو عدد المشتريات. لكن التجارب على المستخدمين غالية الثمن ، ولا أريد نشر خوارزمية سيئة حتى لمجموعة صغيرة من المستخدمين ، لذلك يستخدمون مقاييس الجودة في وضع عدم الاتصال قبل الاختبار عبر الإنترنت.
تقييم غير متصل
عادةً ما تستخدم مقاييس التصنيف ، مثل MAP @ k و nDCG @ k ، كمقاييس جودة.
Relevance في سياق
MAP@k هي قيمة ثنائية ، وفي سياق
nDCG@k يمكن أن يكون هناك مقياس تصنيف.
ولكن ، بالإضافة إلى دقة التنبؤ ، قد نكون مهتمين بأشياء أخرى:
- overage - حصة البضائع التي يصدرها مقدم التوصية ،
- التخصيص - ما مدى اختلاف التوصيات بين المستخدمين ،
- التنوع - مدى تنوع المنتجات في التوصية.
بشكل عام ، هناك مراجعة جيدة للمقاييس ، ما
مدى جودة نظام التوصية الخاص بك؟ دراسة استقصائية للتقييمات في التوصية . مثال على إضفاء الطابع الرسمي على مقاييس الجدة يمكن العثور عليه في
التصنيف والملاءمة في مقاييس الجدة والتنوع للأنظمة الموصى بها .
معطيات
ملاحظات صريحة
مصفوفة التقدير مثال على بيانات صريحة. أعجبني ، لم يعجبني ، التقييم - عبر المستخدم نفسه بوضوح عن درجة اهتمامه بالعنصر. هذه البيانات عادة ما تكون نادرة. على سبيل المثال ، في
تحدي Rekko في بيانات الاختبار ، 34٪ فقط من المستخدمين لديهم علامة واحدة على الأقل.
ردود الفعل الضمنية
هناك المزيد من المعلومات حول التفضيلات الضمنية - المشاهدات والنقرات وإشارات مرجعية وإعداد الإشعارات. ولكن إذا شاهد المستخدم الفيلم - فهذا يعني فقط أنه قبل مشاهدة الفيلم بدا مثيرا للاهتمام بالنسبة له. لا يمكننا استخلاص استنتاجات مباشرة حول ما إذا كان الفيلم محبوبًا أم لا.
وظائف الخسارة للتعلم
لاستخدام الملاحظات الضمنية ، توصلنا إلى طرق تدريس مناسبة.
النظرية الشخصية البايزية
المقال الأصلي .
من المعروف العناصر التي تفاعل المستخدم معها. نحن نفترض أن هذه أمثلة إيجابية يحبها. لا يزال هناك العديد من العناصر التي لم يتفاعل معها المستخدم. لا ندري أيًا منها سيكون موضع اهتمام المستخدم وأيهما ليس كذلك ، لكننا نعرف بالتأكيد أن هذه الأمثلة كلها لن تكون إيجابية. نجعل تعميمًا تقريبيًا ونعتبر غياب التفاعل كمثال سلبي.
سنقوم بتجربة ثلاثة أضعاف {user ، عنصر موجب ، عنصر سلبي} وغرامة النموذج إذا تم تصنيف مثال سلبي أعلى من إيجابي.
مرجح تقريبي - رتبة الزوج
أضف إلى الفكرة السابقة معدل التعلم التكيفي. سنقوم بتقييم تدريب النظام استنادًا إلى عدد العينات التي كان علينا البحث فيها للعثور على مثال سلبي للزوج المعطى {user، example positive} ، الذي قيمه النظام أعلى من الإيجابي.
إذا وجدنا مثل هذا المثال في المرة الأولى ، فيجب أن تكون الغرامة كبيرة. إذا كان عليك البحث لفترة طويلة ، فإن النظام يعمل جيدًا بالفعل ولا تحتاج إلى دفع مبالغ كبيرة.
ماذا يستحق التفكير؟
بداية باردة
بمجرد أن تعلمنا وضع تنبؤات للمستخدمين الحاليين والمنتجات ، يثور سؤالان: - "كيف ننصح بمنتج لم يره أحد حتى الآن؟" و "ما الذي ينبغي أن أوصي به المستخدم الذي ليس لديه تصنيف واحد بعد؟" لحل هذه المشكلة ، يحاولون استخراج المعلومات من مصادر أخرى. قد تكون هذه بيانات عن مستخدم من خدمات أخرى ، أو استبيان أثناء التسجيل ، أو معلومات حول عنصر من محتوياته.
في هذه الحالة ، هناك مهام تكون فيها حالة البداية الباردة ثابتة. في "التوصية المستندة إلى الجلسة" ، يجب أن يكون لديك وقت لفهم شيء ما عن المستخدم أثناء وجوده على الموقع. تظهر عناصر جديدة باستمرار في مقدمي الأخبار أو منتجات الأزياء ، في حين أن العناصر القديمة سرعان ما أصبحت قديمة.
ذيل طويل
إذا قمنا بحساب شعبيته لكل عنصر في شكل عدد المستخدمين الذين تفاعلوا معه أو أعطوا تقييمًا إيجابيًا ، فسنحصل في كثير من الأحيان على رسم بياني كما في الصورة:
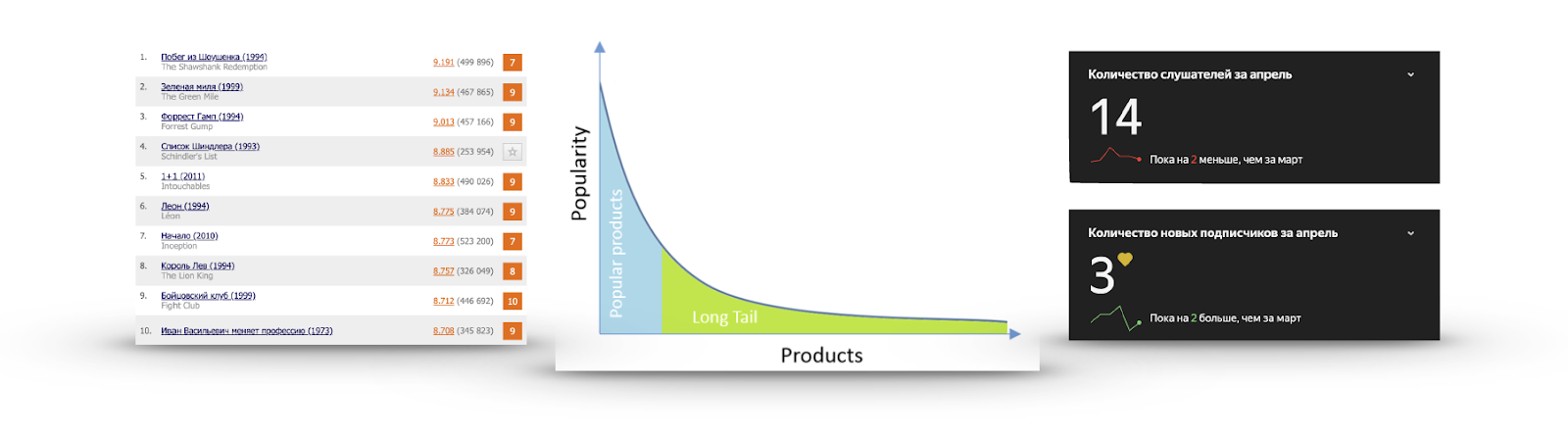
هناك عدد صغير جدًا من العناصر التي يعرفها الجميع. لا جدوى من التوصية بها ، لأن المستخدم على الأرجح إما قد شاهدها بالفعل ولم يقدم تقييمًا لها ، إما يعرف عنها وسيراها ، أو قرر بشدة عدم مشاهدتها على الإطلاق. لقد شاهدت مقطع الفيديو الخاص بقائمة شندلر أكثر من مرة ، لكنني لن أراها.
من ناحية أخرى ، تنخفض شعبية بسرعة كبيرة ، ولم ير أي شخص الغالبية العظمى من العناصر. يعد تقديم توصيات من هذا الجزء أكثر فائدة: هناك محتوى مثير للاهتمام من غير المرجح أن يجد المستخدم نفسه فيه. على سبيل المثال ، على اليمين توجد إحصائيات استماع لإحدى مجموعاتي المفضلة على Yandex.Music.
الاستكشاف مقابل الاستغلال
دعنا نقول أننا نعرف بالضبط ما يحب المستخدم. هل هذا يعني أننا يجب أن نوصي بالشيء نفسه؟ هناك شعور بأن مثل هذه التوصيات سرعان ما تصبح مملة وأحيانا يجدر إظهار شيء جديد. عندما نوصي بالضبط ما ينبغي أن يكون الاستغلال. إذا حاولنا إضافة شيء أقل شعبية إلى التوصيات أو تنويعها بطريقة أو بأخرى - فهذا استكشاف. أريد تحقيق التوازن بين هذه الأشياء.
توصيات غير شخصية
الخيار الأسهل هو التوصية بالشيء نفسه للجميع.
الترتيب حسب الشعبية
النتيجة = (التصنيفات الإيجابية) - (التصنيفات السلبية)
يمكنك طرح الكراهية من الإعجابات وترتيبها. لكن في هذه الحالة ، لا نأخذ في الاعتبار نسبة النسبة المئوية. هناك شعور بأن 200 إعجاب من بين 50 كرهًا لا يختلفون عن 1200 إعجاب و 1050 إعجابًا.
النتيجة = (التقييمات الإيجابية) / (إجمالي التقييمات)
يمكنك تقسيم عدد مرات الإعجابات على عدد الأشياء التي لا تعجبك ، ولكن في هذه الحالة ، لا نأخذ في الاعتبار عدد التصنيفات ، وسيتم تصنيف المنتج الذي يحمل تصنيفًا واحدًا بقيمة 5 نقاط أعلى من منتج شائع جدًا بمتوسط تصنيف 4.8.
كيف
لا يمكن الفرز حسب التصنيف المتوسط والنظر في عدد التصنيفات؟ احسب الفاصل الزمني للثقة: "بناءً على التقديرات المتاحة ، هل هناك احتمال بنسبة 95٪ للحصة الحقيقية للتصنيفات الإيجابية على الأقل؟" قدم إدوين ويلسون إجابة هذا السؤال في عام 1927.
- لوحظ حصة من التصنيفات الإيجابية
- 1-ألفا الكمية للتوزيع الطبيعي
Sovstrechaemosti
يتضمن اختيار مجموعات المنتجات التي تمت مواجهتها بشكل متكرر مجموعة كاملة من مهام التنقيب عن الأنماط: التنقيب
الدوري عن الأنماط ،
التنقيب عن القاعدة المتسلسلة ،
التنقيب عن الأنماط المتسلسلة ،
التنقيب عن العناصر عالية الفائدة ،
التنقيب المتكرر لعناصر العناصر (تحليل السلة) . سيكون لكل مهمة محددة
أساليبها الخاصة ، ولكن إذا كانت خوارزميات معممة تقريبًا للعثور على مجموعات متكررة ، فتجري بحثًا مختصراً في اتساع النطاق ، مع محاولة عدم فرز الخيارات السيئة بوضوح.
يتم قطع مجموعات نادرة عند الدعم الحد المعطى - عدد أو تكرار حدوث مجموعة في البيانات.
بعد إبراز مجموعة العناصر المتكررة ، يتم تقييم جودة الاعتماد عليها باستخدام مقاييس الرفع أو الثقة (أ ، ب) / الثقة (! A ، ب). وهي تهدف إلى إزالة التبعيات الخاطئة.
على سبيل المثال ، يمكن العثور على الموز في سلة البقالة إلى جانب السلع المعلبة. لكن النقطة ليست في بعض الارتباطات الخاصة ، ولكن في حقيقة أن الموز يحظى بشعبية في حد ذاته ، ويجب أن يؤخذ ذلك في الاعتبار عند البحث عن التطابقات.
توصيات شخصية
المحتوى القائم
تتمثل فكرة النهج القائم على المحتوى في إنشاء متجه لتفضيلاته في مساحة الكائنات استنادًا إلى سجل تصرفات المستخدم والتوصية بمنتجات قريبة من هذا المتجه.
وهذا هو ، يجب أن يكون العنصر بعض الوصف المميز. على سبيل المثال ، قد تكون هذه أنواعًا من الأفلام. يشكل تاريخ الإعجابات والكراهيات للأفلام متجهًا للأفضليات ،
تسليط الضوء على بعض الأنواع وتجنب الآخرين. بمقارنة متجه المستخدم ومتجه العناصر ، يمكنك عمل ترتيب والحصول على توصيات.
تصفية التعاونية

تفترض التصفية التعاونية مصفوفة تقييم عنصر المستخدم. تتمثل الفكرة في العثور على "الجيران" الأكثر تشابهًا لكل مستخدم وملء الثغرات الخاصة بمستخدم معين من خلال تقدير متوسط تصنيفات "الجيران".
وبالمثل ، يمكنك إلقاء نظرة على تشابه العناصر ، معتبرة أن العناصر المماثلة يحبها أشخاص مماثلون. من الناحية الفنية ، سيكون هذا مجرد اعتبار لمصفوفة التقديرات المنقولة.
يستخدم المستخدمون مقياس التقييم بشكل مختلف - لا يضعه أحد أبدًا فوق ثمانية ، ويستخدم شخص ما المقياس بأكمله. من المفيد أخذ ذلك في الاعتبار ، وبالتالي فمن الممكن التنبؤ ليس بالتصنيف نفسه ، ولكن الانحراف عن التصنيف المتوسط.
\ widehat {r} _ {ai} = \ overline {r} _ {a} + \ frac {\ sum (r_ {ui} - \ overline {r} _ {u}) w_ {ua}} {w_ { تعميم الوصول إلى الخدمات}
أو يمكنك تطبيع التقديرات مسبقًا.
مصفوفة عامل
من الرياضيات ،
نعلم أن أي مصفوفة يمكن أن تتحلل إلى نتاج ثلاث مصفوفات. لكن مصفوفة التصنيفات قليلة للغاية ، 99٪ شائعة. و SVD لا يعرف ما هي الفجوات. ملء لهم بقيمة متوسطة أمر غير مرغوب فيه للغاية. وبشكل عام ، لسنا مهتمين جدًا بمصفوفة القيم الفردية - نريد فقط الحصول على عرض خفي للمستخدمين والكائنات ، والتي عند مضاعفةها ، ستقارب التصنيف الحقيقي. يمكنك أن تتحلل على الفور إلى اثنين من المصفوفات.
ماذا تفعل مع يمر؟ مطرقة عليهم. اتضح أنه يمكنك التدريب على التقديرات التقريبية بواسطة مقياس RMSE باستخدام SGD أو ALS ، مع تجاهل الإغفالات تمامًا. أول خوارزمية مثل
Funk SVD ، التي تم اختراعها في عام 2006 أثناء حل المنافسة من Netflix.
جائزة Netflix
جائزة Netflix - حدث مهم أعطى دفعة قوية لتطوير أنظمة التوصيات. الهدف من المسابقة هو تجاوز نظام توصيات Cinematch RMSE الحالي بنسبة 10٪. تحقيقًا لهذه الغاية ، تم تقديم مجموعة بيانات كبيرة تحتوي على 100 مليون تصنيف في ذلك الوقت. قد لا تبدو المهمة صعبة للغاية ، ولكن من أجل تحقيق الجودة المطلوبة ، كان لا بد من إعادة اكتشاف المسابقة مرتين - تم استلام حل لمدة 3 سنوات فقط من المنافسة. إذا كان من الضروري الحصول على تحسن بنسبة 15 ٪ ، فربما لم يكن هذا ممكنا لتحقيقه على البيانات المقدمة.
خلال المنافسة ، تم العثور على
بعض الميزات
المثيرة للاهتمام في البيانات. يوضح الرسم البياني متوسط تصنيف الأفلام وفقًا لتاريخ ظهورها في كتالوج Netflix. ترتبط الفجوة الظاهرة بحقيقة أن Netflix في هذا الوقت تحول من مقياس موضوعي (فيلم سيء ، فيلم جيد) إلى فيلم شخصي (لم يعجبني ، لقد أحببته حقًا). يكون الأشخاص أقل أهمية عند التعبير عن تقييمهم ، بدلاً من وصف كائن ما.
يوضح هذا الرسم البياني كيف يتغير متوسط تصنيف الفيلم بعد الإصدار. يمكن أن نرى أن أكثر من 2000 يوم ترتفع النتيجة بنسبة 0.2. أي بعد أن لم يعد الفيلم جديدًا ، يبدأ أولئك الذين واثقون جدًا من أنه سيحبه الفيلم ، الذي يزيد التصنيف ، في مشاهدته.
حصل على الجائزة المتوسطة الأولى فريق من المتخصصين من AT&T - Korbell. بعد 2000 ساعة من العمل وتجميع مجموعة من 107 خوارزمية ، تمكنوا من الحصول على تحسن بنسبة 8.43 ٪.
من بين الطرز ، كان هناك تباين بين SVD و RBM ، والذي وفر بحد ذاته معظم المدخلات. خوارزميات 105 المتبقية تحسين مائة فقط من القياس. قام Netflix بتكييف هاتين الخوارزميات مع وحدات تخزين البيانات الخاصة به ومازال يستخدمهما كجزء من النظام.
في السنة الثانية من المسابقة ، اندمج الفريقان والآن حصلت على جائزة بيلكور في BigChaos. لقد هاجموا ما مجموعه 207 خوارزمية وحسّنوا الدقة بنسبة مائة أخرى ، ووصلوا إلى قيمة 0.8616. لا تزال الجودة المطلوبة غير محققة ، لكن من الواضح بالفعل أن كل شيء يجب أن ينجح في العام المقبل.
السنة الثالثة. بالاشتراك مع فريق آخر ، إعادة تسمية Pragmatic Chaos من Bellk وتحقيق الجودة المطلوبة ، أدنى قليلاً من The Ensemble. ولكن هذا ليس سوى الجزء العام من مجموعة البيانات.
على الجانب الخفي ، اتضح أن دقة هذه الفرق تتزامن مع المركز العشري الرابع ، لذلك تم تحديد الفائز بفارق ارتكاب 20 دقيقة.
دفعت Netflix المليون الموعود للفائزين ، لكنها لم
تستخدم الحل الناتج . لقد تبين أن تنفيذ المجموعة باهظ التكلفة ، وليس هناك فائدة كبيرة من ذلك - بعد كل شيء ، هناك خوارزمتان فقط توفران بالفعل معظم الزيادة في الدقة. والأهم من ذلك - في وقت انتهاء المسابقة في عام 2009 ، كان Netflix قد بدأ بالفعل المشاركة في خدمة البث بالإضافة إلى استئجار قرص DVD لمدة عامين. لديهم العديد من المهام والبيانات الأخرى التي يمكنهم استخدامها في نظامهم. ومع ذلك ، لا تزال خدمة تأجير بريد DVD الخاصة بهم
تخدم 2.7 مليون مشترك سعيد .
الشبكات العصبية
في أنظمة التوصية الحديثة ، هناك سؤال متكرر هو كيفية مراعاة مختلف مصادر المعلومات الصريحة والضمنية. غالبًا ما توجد بيانات إضافية حول المستخدم أو العنصر وتريد استخدامها. الشبكات العصبية هي وسيلة جيدة للمحاسبة عن هذه المعلومات.
فيما يتعلق بمسألة استخدام الشبكات للتوصيات ، يجب الانتباه إلى مراجعة
نظام التوصية القائم على التعلم العميق: استطلاع وجهات نظر جديدة . وهو يصف أمثلة على استخدام عدد كبير من البنيات لمختلف المهام.
هناك الكثير من الهياكل والمناهج. أحد الأسماء المتكررة هو
DSSM . أود أيضًا أن أذكر "
التصفية التعاونية اليقظة" .
تقترح ACF تقديم مستويين من التوهين:
- حتى مع وجود نفس التصنيفات ، تساهم بعض العناصر في تفضيلاتك أكثر من غيرها.
- العناصر ليست ذرية ، ولكنها تتكون من مكونات. بعضها له تأثير أكبر على التقييم من الآخرين. يمكن أن يكون الفيلم مثيرًا للاهتمام فقط بسبب وجود ممثل مفضل.
اللصوص متعدد الأسلحة هي واحدة من أكثر المواضيع شعبية في الآونة الأخيرة. ما هو قطاع الطرق متعدد المسلحين يمكن قراءته في مقال عن
حبري أو على
الوسط .
عند تطبيقها على التوصيات ، ستبدو مهمة Contextual-Bandit شيئًا من هذا القبيل: "نقوم بإطعام متجهات سياق المستخدم والعنصر إلى إدخال النظام ، نريد زيادة احتمال التفاعل (النقرات والمشتريات) لجميع المستخدمين مع مرور الوقت عن طريق إجراء تحديثات متكررة لسياسة التوصية." هذه الصيغة تحل بشكل طبيعي مشكلة الاستكشاف مقابل الاستغلال وتتيح لك طرح الاستراتيجيات المثلى لجميع المستخدمين بسرعة.
في أعقاب شعبية بنية المحولات ، هناك أيضًا محاولات لاستخدامها في التوصيات. تحاول
التوصية بالبند التالي مع الاهتمام الذاتي الجمع بين تفضيلات المستخدم على المدى الطويل والحديث لتحسين التوصيات.
الأدوات
لا تعد التوصيات موضوعًا شائعًا مثل CV أو NLP ، لذا لاستخدام أحدث تصميمات الشبكات التي يتعين عليك إما تنفيذها بنفسك ، أو نأمل أن يكون تنفيذ المؤلف مناسبًا ومفهومًا تمامًا. ومع ذلك ، لا تزال هناك بعض الأدوات الأساسية:
استنتاج
لقد تخطت أنظمة الموصى بها بعيدًا عن البيان القياسي حول ملء مصفوفة التقييمات ، وسيكون لكل منطقة محددة الفروق الدقيقة الخاصة بها. هذا يقدم صعوبات ، لكنه يضيف أيضًا اهتمامًا. بالإضافة إلى ذلك ، قد يكون من الصعب فصل نظام التوصية عن المنتج ككل. في الواقع ، ليست فقط قائمة العناصر مهمة ، ولكن أيضًا طريقة وسياق التقديم. ماذا وكيف ولمن ومتى يوصي. كل هذا يحدد انطباع التفاعل مع الخدمة.