 أرسلت بواسطة ليودميلا Dezhkina ، مهندس الحلول ، DataArt
أرسلت بواسطة ليودميلا Dezhkina ، مهندس الحلول ، DataArtمنذ حوالي ستة أشهر ، عمل فريقنا على منصة الصيانة التنبؤية - وهو نظام يجب أن يتنبأ بالأخطاء المحتملة وتعطل المعدات. تقع هذه المنطقة عند تقاطع إنترنت الأشياء والتعلم الآلي ، وعليك العمل هنا مع الأجهزة ، وفي الواقع ، مع البرامج. سوف نناقش في هذه المقالة كيف نبني Serverless ML مع مكتبة Scikit-learn على AWS. سأتحدث عن الصعوبات التي واجهناها وعن الأدوات التي استخدمتها لتوفير الوقت.
فقط في حالة ، قليلا عن نفسك.لقد شاركت في البرمجة لأكثر من 12 عامًا ، وخلال هذا الوقت شاركت في العديد من المشاريع. بما في ذلك الألعاب ، التجارة الإلكترونية ، الأحمال الكبيرة والبيانات الكبيرة. منذ حوالي ثلاث سنوات شاركت في مشاريع متعلقة بالتعلم الآلي والتعلم العميق.
 بدا الأمر وكأنه المتطلبات التي طرحها العميل من البداية
بدا الأمر وكأنه المتطلبات التي طرحها العميل من البدايةكانت المقابلة مع العميل صعبة ، وتحدثنا أساسًا عن التعلم الآلي ، وسُئلنا كثيرًا عن الخوارزميات وتجربة شخصية محددة. لكنني لن أكون متواضعًا - في هذا الجزء ، نفهم جيدًا في البداية. أول حجر عثرة كان قطعة الأجهزة التي يحتوي عليها النظام. ومع ذلك ، فإن تجربتي مع الحديد شخصيًا ليست متنوعة جدًا.
أوضح لنا العميل: "انظر ، لدينا ناقل." جئت على الفور بحزام ناقل عند الخروج في سوبر ماركت. ماذا وماذا يمكن أن تدرس هناك؟ لكن سرعان ما أصبح من الواضح أن كلمة ناقل تخفي مركز فرز بمساحة 300-400 متر مربع. م ، وفي الواقع ، هناك العديد من الناقلات هناك. وهذا يعني أن العديد من عناصر المعدات يجب أن تكون متصلاً: أجهزة الاستشعار والروبوتات. رسم توضيحي كلاسيكي لمفهوم
"الثورة الصناعية 4.0" ، الذي يجتمع فيه إنترنت الأشياء و ML.
سيكون موضوع الصيانة التنبؤية بالتأكيد في ارتفاع لمدة لا تقل عن سنتين إلى ثلاث سنوات أخرى. يتحلل كل ناقل إلى عناصر: من روبوت أو محرك يحرك حزام النقل إلى محمل منفصل. علاوة على ذلك ، إذا فشل أي من هذه الأجزاء ، فإن النظام بأكمله يتوقف ، وفي بعض الحالات يمكن أن تكلف ساعة من النقل الخمول مليون ونصف المليون دولار (هذا ليس مبالغة!).
يتمثل أحد عملائنا في نقل البضائع والخدمات اللوجستية: على أساسها ، تفريغ الروبوتات 40 شاحنة في 8 دقائق. لا يمكن أن يكون هناك أي تأخير هنا ، يجب أن تأتي السيارات وتذهب وفقًا لجدول زمني صارم للغاية ، لا أحد يقوم بإصلاح أي شيء أثناء عملية التفريغ. بشكل عام ، لا يوجد سوى شخصين أو ثلاثة أشخاص لديهم أقراص في هذه القاعدة. ولكن هناك عالمًا مختلفًا قليلاً حيث لا يبدو كل شيء عصريًا للغاية ، وحيث يكون الميكانيكا مع القفازات وبدون أجهزة الكمبيوتر على الجسم مباشرة.
يتألف أول مشروع نموذج أولي صغير لدينا من حوالي 90 مستشعرًا ، وكل شيء سار على ما يرام حتى تم تحجيم المشروع. لتجهيز أصغر جزء منفصل من مركز الفرز الحقيقي ، هناك حوالي 550 جهاز استشعار مطلوبة بالفعل.
PLC وأجهزة الاستشعار
جهاز التحكم المنطقي القابل للبرمجة - جهاز كمبيوتر صغير مع برنامج دوري مدمج - غالبًا ما يستخدم لأتمتة العملية. في الواقع ، بمساعدة PLC ، نأخذ قراءات من المستشعرات: على سبيل المثال ، التسارع والسرعة ، مستوى الجهد ، الاهتزاز على طول المحاور ، درجة الحرارة (في حالتنا ، 17 مؤشرًا). أجهزة الاستشعار غالبا ما تكون خاطئة. على الرغم من أن مشروعنا عمره أكثر من 8 أشهر ، إلا أنه لا يزال لدينا مختبر خاص بنا ، حيث نجرب أجهزة الاستشعار ، ونختار أنسب النماذج. الآن ، على سبيل المثال ، نحن نفكر في استخدام أجهزة الاستشعار بالموجات فوق الصوتية.
شخصيا ، رأيت لأول مرة PLC ، فقط عندما ضربت موقع العميل. كمطور ، لم أصادفهم من قبل ، وكان الأمر غير سار: بمجرد أن بحثنا عن محركين أعمق من اثنين وثلاثة وأربعة مراحل في محادثة ، بدأت أفقد الخيط. حوالي 80 ٪ من الكلمات كانت لا تزال واضحة ، ولكن المعنى العام انزلق بعناد. بشكل عام ، هذه مشكلة خطيرة ، حيث تصل جذورها إلى عتبة مرتفعة إلى حد ما للدخول في برمجة PLC - كمبيوتر صغير حيث يمكنك حقًا فعل شيء ما بتكلفة لا تقل عن 200-300 دولار. البرمجة نفسها ليست معقدة ، والمشاكل تبدأ فقط عندما يتم توصيل المستشعر إلى ناقل أو محرك حقيقي.
 37 في 1 مجموعة الاستشعار القياسية
37 في 1 مجموعة الاستشعار القياسيةأجهزة الاستشعار ، كما تعلمون ، مختلفة. أبسط تلك التي تمكنا من إيجاد التكلفة من 18 دولارًا. السمة الرئيسية - "النطاق الترددي والدقة" - مقدار البيانات التي ينقلها المستشعر في دقيقة واحدة. من تجربتي الخاصة ، يمكنني القول أنه إذا ادعى الصانع ، على سبيل المثال ، 30 نقطة بيانات في الدقيقة ، فمن غير المرجح أن يزيد عددها في الواقع عن 15. وهذا يمثل أيضًا مشكلة خطيرة: الموضوع عصري ، وتحاول بعض الشركات جني الأموال من هذه الضجة. لقد اختبرنا مستشعرات بقيمة 158 دولارًا ، أتاح عرض النطاق الترددي لها نظريًا التخلص من جزء من الكود. ولكن في الواقع ، تبين أنها تناظرية مطلقة لتلك الأجهزة نفسها بسعر 18 دولارًا لكل قطعة.
المرحلة الأولى: نعلق أجهزة الاستشعار ، وجمع البيانات
في الواقع ، كانت المرحلة الأولى من المشروع هي تثبيت الأجهزة ، والتركيب في حد ذاته عملية طويلة ومملة. هذا أيضًا علم كامل - قد تعتمد البيانات التي يجمعها على كيفية توصيل المستشعر بمحرك أو صندوق. كانت لدينا حالة عندما تم ربط أحد مجسيتين متطابقين داخل الصندوق ، والآخر بالخارج. يشير المنطق إلى أن درجة الحرارة في الداخل يجب أن تكون أعلى ، لكن البيانات التي تم جمعها تشير إلى غير ذلك. اتضح أن النظام فشل ، ولكن عندما وصل المطور إلى المصنع ، رأى أن المستشعر لم يكن في الصندوق فقط ، بل على المروحة الموجودة هناك.
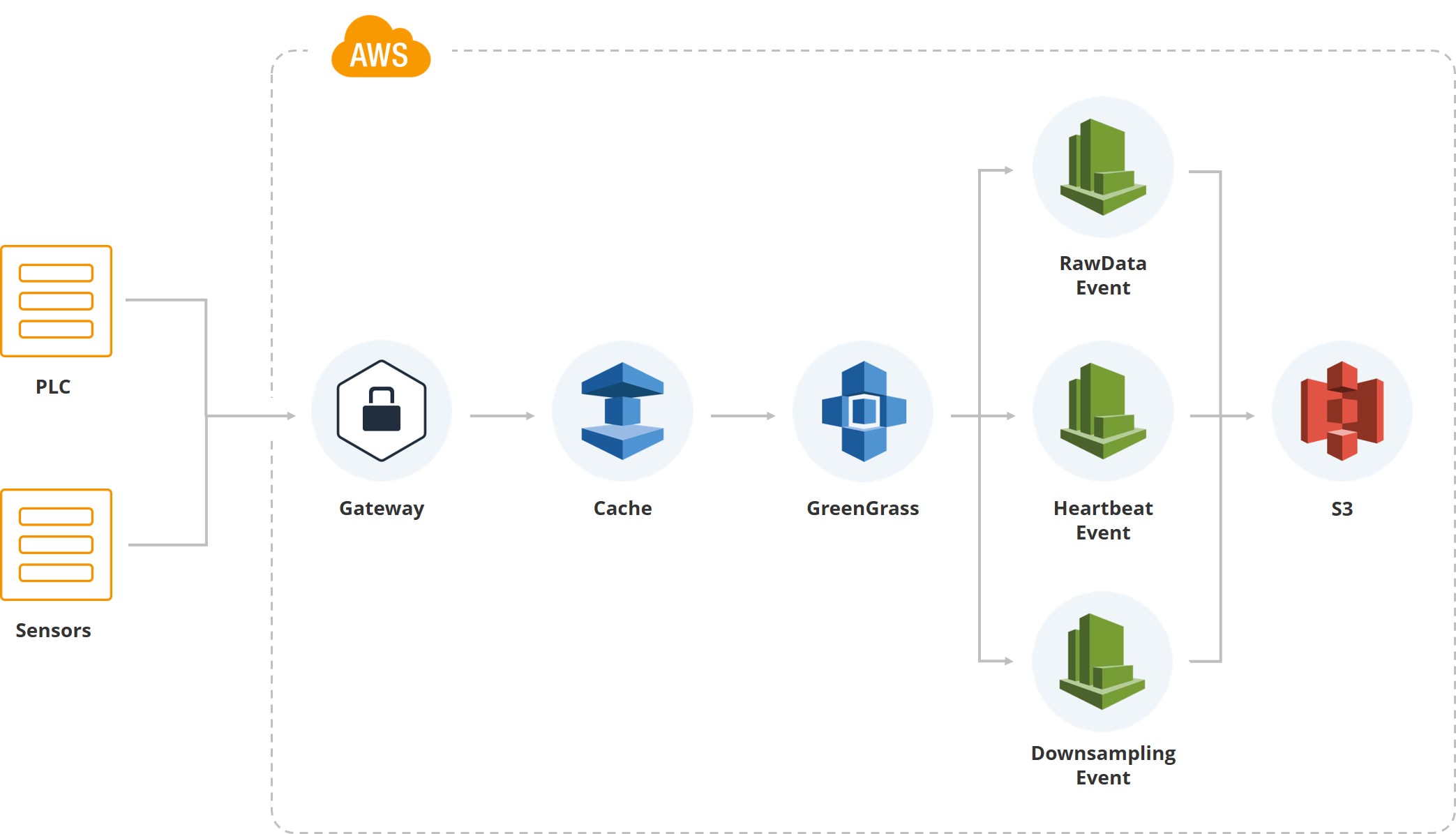
يوضح هذا الرسم التوضيحي كيف دخلت البيانات الأولى النظام. لدينا بوابة ، وهناك PLC وأجهزة الاستشعار المرتبطة به. علاوة على ذلك ، بالطبع ، يتم تشغيل ذاكرة التخزين المؤقت - المعدات عادة على بطاقات الهاتف المحمول ويتم نقل جميع البيانات عبر الإنترنت عبر الهاتف النقال. نظرًا لأن أحد مراكز الفرز التابعة للعميل يقع في منطقة غالبًا ما تكون فيها الأعاصير ، وقد ينقطع الاتصال ، فنحن نجمع البيانات على البوابة حتى تتم استعادتها.
بعد ذلك ، نستخدم خدمة Greengrass من Amazon ، التي ترسل البيانات داخل نظام السحابة (AWS).
بمجرد أن تكون البيانات داخل السحابة ، يتم تشغيل مجموعة من الأحداث. على سبيل المثال ، لدينا حدث للبيانات الأولية التي تحفظ بيانات نظام الملفات. يوجد "دقات قلب" للإشارة إلى أداء النظام العادي. هناك "اختزال" ، والذي يتم استخدامه للعرض على واجهة المستخدم ، وللتجهيز (يتم أخذ متوسط القيمة ، على سبيل المثال ، في الدقيقة لمؤشر معين). أي أنه بالإضافة إلى البيانات الأولية ، لدينا بيانات مختصرة تقع على شاشات المستخدمين الذين يراقبون النظام.
يتم تخزين البيانات الخام في شكل النيابة العامة. في البداية ، اخترنا JSON ، ثم جربنا ملف CSV ، ولكن في النهاية توصلنا إلى استنتاج مفاده أن كل من فريق التحليلات وفريق التطوير راضون عن "الباركيه".
في الواقع ، تم إنشاء الإصدار الأول من النظام على DynamoDB ، ولا أريد أن أقول شيئًا سيئًا عن قاعدة البيانات هذه. إنه بمجرد أن نحصل على التحليلات - علماء الرياضيات الذين يجب أن يعملوا مع البيانات التي تم الحصول عليها - اتضح أن لغة الاستعلام على DynamoDB كانت معقدة للغاية بالنسبة لهم. كان لديهم لإعداد البيانات خصيصا ل ML والتحليلات. لذلك ، استقرنا على Athena ، محرر الاستعلام في AWS. بالنسبة لنا ، تتمثل مزاياه في أنه يسمح لك بقراءة بيانات الباركيه ، وكتابة SQL ، وجمع النتائج في ملف CSV. ما يحتاجه فريق التحليلات
المرحلة الثانية: ماذا نحلل؟
لذلك ، من كائن صغير واحد ، جمعنا حوالي 3 غيغابايت من البيانات الخام. الآن نحن نعرف الكثير عن درجة الحرارة ، والاهتزاز ، والتسارع المحوري. لذلك ، فقد حان الوقت لعلماء الرياضيات لدينا لجمع لفهم كيف ، وفي الواقع ، ما نحاول التنبؤ به على أساس هذه المعلومات.
الهدف هو تقليل تعطل المعدات. لا يدخل الأشخاص إلى مصنع Coca-Cola هذا إلا عندما يتلقون إشارة حول انهيار أو تسرب زيت أو خلل على الأرض. تبدأ تكلفة روبوت واحد بمبلغ 30000 دولار ، ولكن يتم بناء جميع الإنتاج تقريبًا عليها
لا يدخل الأشخاص إلى مصنع Coca-Cola هذا إلا عندما يتلقون إشارة حول انهيار أو تسرب زيت أو خلل على الأرض. تبدأ تكلفة روبوت واحد بمبلغ 30000 دولار ، ولكن يتم بناء جميع الإنتاج تقريبًا عليها يعمل حوالي 10000 شخص في ستة مصانع في تسلا ، وبالنسبة لإنتاج مثل هذا النطاق فإن هذا قليل جدًا. ومن المثير للاهتمام ، مصانع مرسيدس هي أكثر آلية. من الواضح أن جميع الروبوتات المعنية تحتاج إلى مراقبة مستمرة
يعمل حوالي 10000 شخص في ستة مصانع في تسلا ، وبالنسبة لإنتاج مثل هذا النطاق فإن هذا قليل جدًا. ومن المثير للاهتمام ، مصانع مرسيدس هي أكثر آلية. من الواضح أن جميع الروبوتات المعنية تحتاج إلى مراقبة مستمرةكلما كان الروبوت أكثر تكلفة ، قل اهتزاز جزء عمله. مع الإجراءات البسيطة ، قد لا يكون هذا أمرًا حاسمًا ، ولكن العمليات الأكثر دقة ، على سبيل المثال مع رقبة الزجاجة ، تتطلب تقليلها إلى الحد الأدنى. بالطبع ، يجب مراقبة مستوى اهتزاز السيارات باهظة الثمن باستمرار.
الخدمات التي توفر الوقت
أطلقنا التثبيت الأول خلال ما يزيد قليلاً عن ثلاثة أشهر ، وأعتقد أنه سريع.
 في الواقع ، هذه هي النقاط الخمس الرئيسية التي سمحت لإنقاذ جهود التنمية
في الواقع ، هذه هي النقاط الخمس الرئيسية التي سمحت لإنقاذ جهود التنميةأول شيء قمنا بتخفيضه هو أن معظم النظام مبني على AWS ، والذي يتدرج بمفرده. بمجرد أن يتجاوز عدد المستخدمين حدًا معينًا ، يتم تشغيل الفحص التلقائي ، ولا يتعين على أي من الفريق قضاء بعض الوقت في هذا الأمر.
أود أن ألفت الانتباه إلى الفروق الدقيقة. أولاً ، نحن نعمل مع كميات كبيرة من البيانات ، وفي الإصدار الأول من النظام كان لدينا خطوط أنابيب من أجل عمل نسخ احتياطية. بعد مرور بعض الوقت ، أصبحت البيانات أكثر من اللازم ، وأصبح الاحتفاظ بنسخ لها مكلفًا للغاية. بعد ذلك ، تركنا البيانات الأولية ملقاة في المجموعة للقراءة فقط ، ونحظر حذفها ورفض النسخ الاحتياطية.
يشتمل نظامنا على تكامل مستمر ، لدعم موقع جديد ولا يتطلب التثبيت الجديد الكثير من الوقت.
من الواضح أن الوقت الحقيقي مبني على الأحداث. على الرغم من ، بطبيعة الحال ، تنشأ صعوبات بسبب حقيقة أن بعض الأحداث تعمل مرتين أو أن النظام يفقد اللمس ، على سبيل المثال ، بسبب الظروف الجوية.
يتم تشفير البيانات ، كما هو مطلوب من قبل العميل ، تلقائيًا في AWS. كل عميل لديه دلو خاص به ، ونحن لا نفعل ما نقوم بتشفيره على الإطلاق.
لقاء مع المحللين
لقد تلقينا الرمز الأول بتنسيق PDF إلى جانب طلب لتطبيق نموذج أو آخر. حتى بدأنا في استلام الكود في شكل .ipynb ، كان الأمر مخيفًا ، ولكن الحقيقة هي أن المحللين هم علماء رياضيات بعيدون عن البرمجة. جميع عملياتنا تتم في السحابة ، لا نسمح بتنزيل البيانات. معا ، كل هذه النقاط دفعتنا لتجربة منصة SageMaker.
يسمح لك SageMaker باستخدام حوالي 80 خوارزمية خارج الصندوق ؛ ويشمل ذلك الأطر: Caffe2 ، Mxnet ، Gluon ، TensorFlow ، Pytorch ، مجموعة أدوات Microsoft المعرفية. في الوقت الحالي ، نستخدم Keras + TensorFlow ، لكن الجميع باستثناء مجموعة أدوات Microsoft المعرفية تمكنوا من تجربتها. تتيح لنا هذه التغطية الواسعة عدم تقييد فريقنا التحليلي.

خلال الثلاثة إلى الأربعة أشهر الأولى ، قام الناس بكل العمل بمساعدة رياضيات بسيطة ، ولم يكن هناك في الحقيقة ML. يعتمد جزء من النظام على قوانين رياضية بحتة ، وهو مصمم للبيانات الإحصائية. وهذا يعني أننا نراقب متوسط مستوى الحرارة ، وإذا رأينا أنه ينفد عن نطاقه ، يتم تشغيل التنبيهات.
ثم يتبع تدريب النموذج. كل شيء يبدو سهلاً وبسيطًا ، وهكذا يبدو قبل بدء التنفيذ.
بناء وتدريب ونشر ...

سوف أصف بإيجاز كيف خرجنا من هذا الموقف. انظر إلى العمود الثاني: نقوم بجمع البيانات ومعالجتها وتنظيفها واستخدام S3 bucket و Glue لإطلاق الأحداث وإنشاء "أقسام". لدينا جميع البيانات مرتبة في أقسام أثينا ، وهذا هو أيضا فارق بسيط ، لأن أثينا مبنية على قمة S3. أثينا نفسها رخيصة جدا. لكننا ندفع مقابل قراءة البيانات وإخراجها من S3 ، لأن كل طلب يمكن أن يكون مكلفًا للغاية. لذلك ، لدينا نظام كبير من الأقسام.
لدينا downtimer. و Amazon EMR ، التي تسمح لك بجمع البيانات بسرعة. في الواقع ، بالنسبة لهندسة المعالم ، في السحابة الخاصة بنا ، لكل محلل ، تم رفع دفتر ملاحظات Jupyter - وهذا هو حالهم. ويقومون بتحليل كل شيء مباشرة في السحابة نفسها.
بفضل SageMaker ، تمكنا في المقام الأول من تخطي مرحلة مجموعات التدريب. إذا لم نستخدم هذا النظام الأساسي ، فسنضطر إلى رفع مجموعات في Amazon ، وسيتعين على أحد مهندسي DevOps متابعتها. يسمح SageMaker باستخدام معلمات الطريقة ، والصورة الموجودة على Docker لرفع الكتلة ، يبقى فقط الإشارة إلى عدد الحالات في المعلمة التي تريد استخدامها.
علاوة على ذلك ، ليس لدينا للتعامل مع التحجيم. إذا كنا نريد معالجة بعض الخوارزميات الكبيرة أو إذا كنا بحاجة ماسة إلى حساب شيء ما ، فسنقوم بتمكين القياس التلقائي (كل هذا يتوقف على ما إذا كنت تريد استخدام وحدة المعالجة المركزية أو وحدة معالجة الرسومات).
بالإضافة إلى ذلك ، يتم تشفير جميع موديلاتنا: ويظهر ذلك أيضًا في SageMaker - الثنائيات الموجودة في S3.
نشر النموذج
نحن نقترب من النموذج الأول الذي تم نشره في بيئة. في الواقع ، يسمح لك SageMaker بحفظ التحف الفنية ، ولكن في هذه المرحلة كان لدينا الكثير من الجدل ، لأن SageMaker لديه تنسيق النموذج الخاص به. أردنا الابتعاد عنها ، والتخلص من القيود ، بحيث يتم تخزين نماذجنا في شكل مخلل حتى نتمكن من استخدام حتى Keras ، حتى TensorFlow أو أي شيء آخر إذا رغبت في ذلك. على الرغم من أننا استخدمنا النموذج الأول من SageMaker ، كما هو ، من خلال واجهة برمجة التطبيقات الأصلية.
SageMaker يسمح لك بتبسيط العمل على ثلاث مراحل. في كل مرة تحاول فيها التنبؤ بشيء ما ، يجب عليك بدء عملية معينة ، وإعطاء البيانات ، والحصول على قيم التنبؤ. كل شيء سار بشكل جيد مع هذا حتى كانت هناك حاجة إلى خوارزميات مخصصة.

يعرف المحللون أن لديهم CI ومستودع. يوجد مجلد في مستودع CI حيث يجب وضع ثلاثة ملفات. Serve.py هو ملف يسمح لـ SageMaker برفع خدمة Flask والتواصل مع SageMaker نفسه. Train.py هي فئة مع طريقة القطار ، والتي يجب أن تضع كل ما هو مطلوب للنموذج. أخيرًا ، Forecast.py - بمساعدتهم يرفعون هذه الفئة ، التي توجد بها طريقة. بعد الوصول ، يقومون بجمع جميع أنواع الموارد من S3 من هناك - داخل SageMaker لدينا صورة تتيح لك تشغيل أي شيء من الواجهة وبرمجيًا (لا نحد منها).
من SageMaker ، يمكننا الوصول إلى Forecast.py - الصورة الداخلية هي مجرد تطبيق Flask الذي يسمح لك بالاتصال بالتنبؤ أو التدريب باستخدام معلمات معينة. كل هذا مرتبط بـ S3 ، بالإضافة إلى ذلك ، لديهم القدرة على حفظ الطرز من Jupyter Notebook. وهذا هو ، في Jupyter Notebook ، يستطيع المحللون الوصول إلى جميع البيانات ، ويمكنهم القيام ببعض التجارب.
في الإنتاج ، كل هذا يقع على النحو التالي. لدينا مستخدمين ، وهناك قيم نقطة النهاية المتوقعة. تقع البيانات على S3 وتذهب إلى أثينا. كل ساعتين ، يتم إطلاق خوارزمية تقوم بحساب التنبؤ للساعتين التاليتين. هذه الخطوة الزمنية ترجع إلى حقيقة أنه في حالتنا ، حوالي 6 ساعات من التحليلات تكفي لقول أن هناك خطأ ما في المحرك. حتى في لحظة التشغيل ، يسخن المحرك من 5 إلى 10 دقائق ، ولا تحدث قفزات حادة.
في النظم الحرجة ، على سبيل المثال ، عندما تقوم Air France بفحص توربينات الطائرات ، يتم التنبؤ بمعدل 10 دقائق. في هذه الحالة ، تبلغ الدقة 96.5٪.
إذا رأينا أن هناك خطأ ما ، فسيتم تشغيل نظام الإشعارات. ثم يتلقى أحد المستخدمين العديدين على الساعة أو جهازًا آخر إشعارًا بأن محركًا معينًا يتصرف بشكل غير طبيعي. يذهب ويتحقق من حالته.
إدارة مثيلات دفتر الملاحظات
في الواقع ، كل شيء بسيط للغاية. عند العمل ، يطلق المحلل مثيلًا على Jupyter Notebook. يحصل على الدور والدورة ، لذلك لا يمكن لشخصين تحرير الملف نفسه. في الواقع ، لدينا الآن مثيل لكل محلل.
خلق وظيفة التدريب
SageMaker لديه فهم وظائف التدريب. نتيجته ، إذا كنت تستخدم واجهة برمجة تطبيقات (API) فقط - ثنائية يتم تخزينها على S3: من المعلمات التي تقدمها ، يتم الحصول على النموذج الخاص بك.
sagemaker = boto3.client('sagemaker') sagemaker.create_training_job(**create_training_params) status = sagemaker.describe_training_job(TrainingJobName=job_name)['TrainingJobStatus'] print(status) try: sagemaker.get_waiter('training_job_completed_or_stopped').wait(TrainingJobName=job_name) finally: status = sagemaker.describe_training_job(TrainingJobName=job_name)['TrainingJobStatus'] print("Training job ended with status: " + status) if status == 'Failed': message = sagemaker.describe_training_job(TrainingJobName=job_name)['FailureReason'] print('Training failed with the following error: {}'.format(message)) raise Exception('Training job failed')
مثال التدريب التدريب
{ "AlgorithmSpecification": { "TrainingImage": image, "TrainingInputMode": "File" }, "RoleArn": role, "OutputDataConfig": { "S3OutputPath": output_location }, "ResourceConfig": { "InstanceCount": 2, "InstanceType": "ml.c4.8xlarge", "VolumeSizeInGB": 50 }, "TrainingJobName": job_name, "HyperParameters": { "k": "10", "feature_dim": "784", "mini_batch_size": "500", "force_dense": "True" }, "StoppingCondition": { "MaxRuntimeInSeconds": 60 * 60 }, "InputDataConfig": [ { "ChannelName": "train", "DataSource": { "S3DataSource": { "S3DataType": "S3Prefix", "S3Uri": data_location, "S3DataDistributionType": "FullyReplicated" } }, "CompressionType": "None", "RecordWrapperType": "None" } ] }
خيارات. الأول هو الدور: يجب الإشارة إلى ما يستطيع مثيل SageMaker الوصول إليه. هذا هو ، في حالتنا ، إذا كان المحلل يعمل مع اثنين من الإنتاجات المختلفة ، يجب أن يرى دلو واحد وليس رؤية الآخر. تكوين الإخراج هو المكان الذي تحفظ فيه جميع بيانات تعريف النموذج.
إننا نتخطى القياس التلقائي ويمكننا ببساطة تحديد عدد الحالات التي ترغب في تشغيل هذه الوظيفة التدريبية عليها. في البداية ، استخدمنا بشكل عام المثيلات المتوسطة بدون TensorFlow أو Keras ، وكان ذلك كافياً.
Hyperparameters. يمكنك تحديد صورة Docker التي تريد أن تبدأ فيها. كقاعدة عامة ، توفر Amazon قائمة بالخوارزميات وصورها ، أي ، يجب عليك تحديد معلمات تشعبية - معلمات الخوارزمية نفسها.
إنشاء نموذج
%%time import boto3 from time import gmtime, strftime job_name = 'kmeans-lowlevel-' + strftime("%Y-%m-%d-%H-%M-%S", gmtime()) print("Training job", job_name) from sagemaker.amazon.amazon_estimator import get_image_uri image = get_image_uri(boto3.Session().region_name, 'kmeans') output_location = 's3://{}/kmeans_example/output'.format(bucket) print('training artifacts will be uploaded to: {}'.format(output_location)) create_training_params = \ { "AlgorithmSpecification": { "TrainingImage": image, "TrainingInputMode": "File" }, "RoleArn": role, "OutputDataConfig": { "S3OutputPath": output_location }, "ResourceConfig": { "InstanceCount": 2, "InstanceType": "ml.c4.8xlarge", "VolumeSizeInGB": 50 }, "TrainingJobName": job_name, "HyperParameters": { "k": "10", "feature_dim": "784", "mini_batch_size": "500", "force_dense": "True" }, "StoppingCondition": { "MaxRuntimeInSeconds": 60 * 60 }, "InputDataConfig": [ { "ChannelName": "train", "DataSource": { "S3DataSource": { "S3DataType": "S3Prefix", "S3Uri": data_location, "S3DataDistributionType": "FullyReplicated" } }, "CompressionType": "None", "RecordWrapperType": "None" } ] } sagemaker = boto3.client('sagemaker') sagemaker.create_training_job(**create_training_params) status = sagemaker.describe_training_job(TrainingJobName=job_name)['TrainingJobStatus'] print(status) try: sagemaker.get_waiter('training_job_completed_or_stopped').wait(TrainingJobName=job_name) finally: status = sagemaker.describe_training_job(TrainingJobName=job_name)['TrainingJobStatus'] print("Training job ended with status: " + status) if status == 'Failed': message = sagemaker.describe_training_job(TrainingJobName=job_name)['FailureReason'] print('Training failed with the following error: {}'.format(message)) raise Exception('Training job failed') %%time import boto3 from time import gmtime, strftime model_name=job_name print(model_name) info = sagemaker.describe_training_job(TrainingJobName=job_name) model_data = info['ModelArtifacts']['S3ModelArtifacts'] print(info['ModelArtifacts']) primary_container = { 'Image': image, 'ModelDataUrl': model_data } create_model_response = sagemaker.create_model( ModelName = model_name, ExecutionRoleArn = role, PrimaryContainer = primary_container) print(create_model_response['ModelArn'])
إنشاء نموذج هو نتيجة عمل التدريب. بعد الانتهاء من هذا الأخير ، وعندما تراقبه ، يتم حفظه على S3 ، ويمكنك استخدامه.

هكذا تبدو من وجهة نظر المحللين. يذهب محللونا إلى النماذج ويقولون: في هذه الصورة ، أريد إطلاق هذا النموذج. يشيرون ببساطة إلى مجلد S3 ، صورة وإدخال المعلمات في واجهة رسومية. ولكن هناك فروق دقيقة وصعوبات ، لذلك انتقلنا إلى خوارزميات مخصصة.
إنشاء نقطة النهاية
%%time import time endpoint_name = 'KMeansEndpoint-' + strftime("%Y-%m-%d-%H-%M-%S", gmtime()) print(endpoint_name) create_endpoint_response = sagemaker.create_endpoint( EndpointName=endpoint_name, EndpointConfigName=endpoint_config_name) print(create_endpoint_response['EndpointArn']) resp = sagemaker.describe_endpoint(EndpointName=endpoint_name) status = resp['EndpointStatus'] print("Status: " + status) try: sagemaker.get_waiter('endpoint_in_service').wait(EndpointName=endpoint_name) finally: resp = sagemaker.describe_endpoint(EndpointName=endpoint_name) status = resp['EndpointStatus'] print("Arn: " + resp['EndpointArn']) print("Create endpoint ended with status: " + status) if status != 'InService': message = sagemaker.describe_endpoint(EndpointName=endpoint_name)['FailureReason'] print('Training failed with the following error: {}'.format(message)) raise Exception('Endpoint creation did not succeed')
هناك حاجة إلى الكثير من التعليمات البرمجية لإنشاء نقطة النهاية التي تشنجات من أي لامدا ومن الخارج. كل ساعتين ، يتم تشغيل حدث يسحب نقطة النهاية.
عرض نقطة النهاية

هكذا يراه المحللون. إنها تشير ببساطة إلى الخوارزمية والوقت وسحبها بيديه من الواجهة.
استدعاء نقطة النهاية
import json payload = np2csv(train_set[0][30:31]) response = runtime.invoke_endpoint(EndpointName=endpoint_name, ContentType='text/csv', Body=payload) result = json.loads(response['Body'].read().decode()) print(result)
وهذه هي الطريقة التي يتم بها من لامدا. وهذا يعني ، لدينا نقطة النهاية في الداخل ، وكل ساعتين نرسل حمولة من أجل وضع التنبؤ.
روابط SageMaker مفيدة: روابط github
هذه هي روابط مهمة جدا. بأمانة ، بعد أن بدأنا في استخدام واجهة المستخدم الرسومية المعتادة في Sagemaker ، أدرك الجميع أننا سنصل عاجلاً أم آجلاً إلى خوارزمية مخصصة ، وسيتم تجميع كل هذا يدويًا. باستخدام هذه الروابط ، لن تجد فقط استخدام الخوارزميات ، ولكن أيضًا تجميع الصور المخصصة:
github.com/awslabs/amazon-sagemaker-examplesgithub.com/aws-samples/aws-ml-vision-end2endgithub.com/juliensimongithub.com/aws/sagemaker-sparkما التالي؟
لقد اقتربنا من الإنتاج الرابع والآن ، بالإضافة إلى التحليلات ، لدينا طريقان للتطوير. أولاً ، نحاول الحصول على سجلات من الميكانيكا ، أي أننا نحاول التدريب مع الدعم. تبدو سجلات Mantainence الأولى التي تلقيناها كالتالي: لقد حدث شيء ما يوم الاثنين ، وصلت إلى هناك يوم الأربعاء ، وبدأت في إصلاحه يوم الجمعة. نحاول الآن تزويد العميل بـ CMS - نظام إدارة محتوى يسمح بتسجيل أحداث الفشل.
كيف يتم ذلك؟ كقاعدة عامة ، بمجرد حدوث الانهيار ، يصل الميكانيكي ويغير الجزء بسرعة كبيرة ، لكن يمكنه ملء جميع أنواع النماذج الورقية ، على سبيل المثال ، في غضون أسبوع. بحلول هذا الوقت ، ينسى الشخص ببساطة ما حدث بالضبط للجزء. CMS ، بالطبع ، يأخذنا إلى مستوى جديد من التفاعل مع الميكانيكا.
ثانياً ، سنقوم بتركيب أجهزة استشعار بالموجات فوق الصوتية على المحركات التي تقرأ الصوت وتشارك في التحليل الطيفي.
من الممكن أن نتخلى عن أثينا ، لأن استخدام S3 باهظ الثمن في البيانات الكبيرة. في الوقت نفسه ، أعلنت Microsoft مؤخرًا عن خدماتها الخاصة ، ويريد أحد عملائنا محاولة القيام بنفس الشيء في Azure. في الواقع ، واحدة من مزايا نظامنا هي أنه يمكن تفكيكها وتجميعها في مكان آخر ، مثل مكعبات.