يمكن العثور على الدورة الكاملة باللغة الروسية على
هذا الرابط .
دورة اللغة الإنجليزية الأصلية متاحة على
هذا الرابط .
 ومن المقرر محاضرات جديدة كل 2-3 أيام.
ومن المقرر محاضرات جديدة كل 2-3 أيام.مقابلة مع سيباستيان ترون ، الرئيس التنفيذي لشركة Udacity
"لذلك ، نحن لا نزال معكم ومعنا ، كما كان من قبل ، سيباستيان." نريد فقط مناقشة الطبقات المتصلة بالكامل ، تلك الطبقات الكثيفة نفسها. قبل ذلك ، أود أن أطرح سؤالاً واحداً. ما هي الحدود والعقبات الرئيسية التي ستقف في طريق التعلم العميق وسيكون لها أكبر تأثير عليها في السنوات العشر القادمة؟ كل شيء يتغير بسرعة! ما رأيك سيكون "الشيء الكبير" التالي؟
- أود أن أقول شيئين. الأول هو الذكاء الاصطناعى العام لأكثر من مهمة. هذا رائع! يمكن للناس حل أكثر من مشكلة ويجب ألا يفعلوا الشيء نفسه أبدًا. والثاني هو جلب التكنولوجيا إلى السوق. بالنسبة لي ، فإن خصوصية التعلم الآلي هي أنه يوفر لأجهزة الكمبيوتر القدرة على مراقبة وإيجاد أنماط في البيانات ، مما يساعد الناس على أن يصبحوا أفضل في المجال - على مستوى الخبراء! يمكن استخدام التعلم الآلي في القانون والطب والسيارات ذاتية الحكم. طور مثل هذه التطبيقات لأنها يمكن أن تجلب مبلغًا هائلاً من المال ، ولكن الأهم من ذلك ، لديك الفرصة لجعل العالم مكانًا أفضل كثيرًا.
"أحب حقًا الطريقة التي تقول بها كل شيء في صورة واحدة للتعلم العميق وتطبيقه - إنها مجرد أداة يمكن أن تساعدك في حل مشكلة معينة.
- نعم بالضبط! أداة لا تصدق ، أليس كذلك؟
- نعم ، نعم ، أنا أتفق معك تمامًا!
"تقريبا مثل العقل البشري!"
- لقد ذكرت التطبيقات الطبية في أول مقابلة لنا ، في الجزء الأول من دورة الفيديو. في أي التطبيقات ، في رأيك ، استخدام التعلم العميق يسبب أعظم البهجة والمفاجأة؟
- الكثير! جدا! الطب على قائمة قصيرة من المجالات التي تستخدم بنشاط التعلم العميق. لقد فقدت أختي منذ بضعة أشهر ، وكانت مريضة بالسرطان ، وهو أمر محزن للغاية. أعتقد أن هناك العديد من الأمراض التي يمكن اكتشافها في وقت مبكر - في المراحل المبكرة ، مما يجعل من الممكن علاجها أو إبطاء عملية تطورها. في الواقع ، تتمثل الفكرة في نقل بعض الأدوات إلى المنزل (المنزل الذكي) ، بحيث يمكن اكتشاف مثل هذه الانحرافات في الصحة قبل وقت طويل من اللحظة التي يراها الشخص نفسه. أود أيضًا أن أضيف - كل شيء متكرر ، أي عمل مكتبي ، حيث تقوم بنفس نوع الإجراءات مرارًا وتكرارًا ، على سبيل المثال ، مسك الدفاتر. حتى أنا ، كمدير تنفيذي ، أقوم بالكثير من الإجراءات المتكررة. سيكون أمرا رائعا لأتمتة لهم ، حتى العمل مع مراسلات البريد!
- لا استطيع الاختلاف معك! في هذا الدرس ، سوف نقدم الطلاب إلى دورة تدريبية مع طبقة الشبكة العصبية تسمى طبقة كثيفة. هل يمكن أن تخبرنا بمزيد من التفصيل عن رأيك في الطبقات المتصلة بالكامل؟
- لذلك ، لنبدأ بحقيقة أنه يمكن توصيل كل شبكة بطرق مختلفة. قد يكون لدى بعضها اتصال ضيق للغاية ، مما يتيح لك الحصول على بعض الفوائد في التوسع و "الفوز" ضد الشبكات الكبيرة. في بعض الأحيان لا تعرف عدد الاتصالات التي تحتاجها ، لذلك تقوم بتوصيل كل شيء بكل شيء - وهذا ما يسمى طبقة متصلة بالكامل. وأضيف أن هذا النهج لديه قوة وإمكانات أكثر بكثير من شيء أكثر تنظيماً.
- أنا أتفق معك تماما! شكرًا لك على مساعدتنا في تعلم المزيد حول الطبقات المتصلة بالكامل. إنني أتطلع إلى اللحظة التي نبدأ فيها أخيرًا في تنفيذها وكتابة التعليمات البرمجية.
- استمتع! سيكون ممتعا حقا!
مقدمة
- مرحبًا بك مرة أخرى! في الدرس الأخير ، تعرفت على كيفية إنشاء أول شبكة عصبية لديك باستخدام TensorFlow و Keras ، وكيف تعمل الشبكات العصبية ، وكيف تعمل عملية التدريب (التدريب). على وجه الخصوص ، رأينا كيفية تدريب النموذج لتحويل الدرجات المئوية إلى درجات فهرنهايت.

- تعرفنا أيضًا على مفهوم الطبقات المتصلة بالكامل (الطبقات الكثيفة) ، وهي الطبقة الأكثر أهمية في الشبكات العصبية. لكن في هذا الدرس سنفعل أشياء أكثر برودة! في هذا الدرس ، سنقوم بتطوير شبكة عصبية يمكنها التعرف على عناصر الملابس والصور. كما ذكرنا سابقًا ، يستخدم التعلم الآلي المدخلات المسماة "الميزات" ، والإخراج المسمى "الملصقات" ، والذي يتعلم به النموذج ويجد خوارزمية تحويل. لذلك ، أولاً ، سنحتاج إلى العديد من الأمثلة لتدريب الشبكة العصبية للتعرف على عناصر مختلفة من الملابس. واسمحوا لي أن أذكركم بأن مثال التدريب هو زوج من القيم - ميزة إدخال وتصنيف مخرجات ، يتم إدخالهما في مدخلات الشبكة العصبية. في مثالنا الجديد ، سيتم استخدام الصورة كمدخلات ، ويجب أن تكون تسمية الإخراج هي فئة الملابس التي ينتمي إليها عنصر الملابس المعروض في الصورة. لحسن الحظ ، مجموعة البيانات هذه موجودة بالفعل. ويسمى الأزياء MNIST. سنلقي نظرة فاحصة على مجموعة البيانات هذه في الجزء التالي.
أزياء مجموعة البيانات MNIST
مرحبًا بك في عالم مجموعة البيانات MNIST! لذلك ، تتكون مجموعتنا من 28 × 28 صورة ، يمثل كل بكسل منها ظلًا رماديًا.

تحتوي مجموعة البيانات على صور القمصان والقمصان والصنادل وحتى الأحذية. فيما يلي قائمة كاملة بما تحتويه مجموعة بيانات MNIST الخاصة بنا:
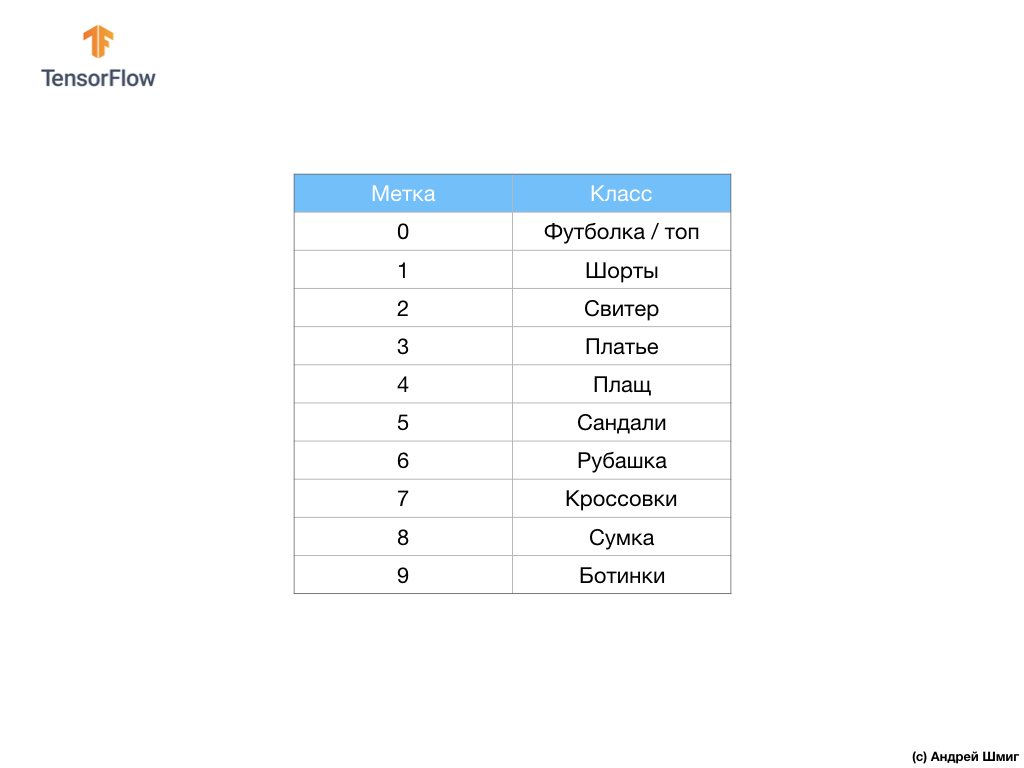
كل صورة إدخال يتوافق مع واحدة من التسميات المذكورة أعلاه. تحتوي مجموعة بيانات Fashion MNIST على 70000 صورة ، لذلك لدينا مكان للبدء فيه والعمل معه. من بين هؤلاء الـ 70،000 ، سوف نستخدم 60،000 لتدريب الشبكة العصبية.
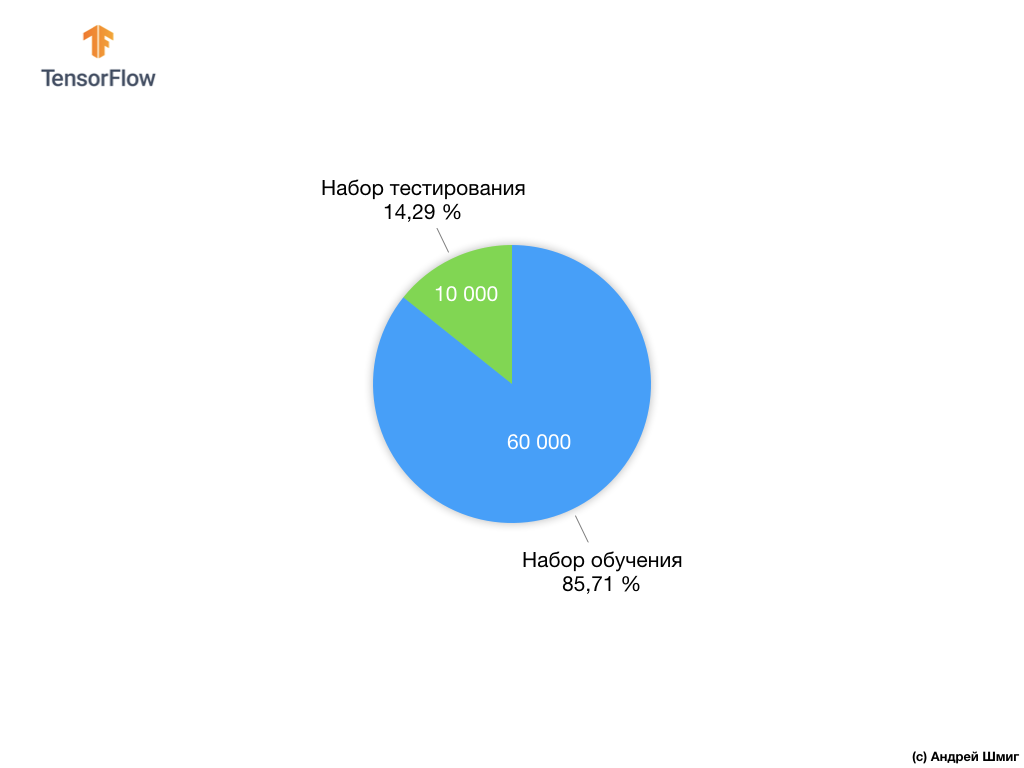
وسوف نستخدم العناصر العشرة آلاف المتبقية للتحقق من مدى تعلم شبكتنا العصبية التعرف على عناصر الملابس. في وقت لاحق سنشرح لماذا قسمنا مجموعة البيانات إلى مجموعة تدريب ومجموعة اختبار.
حتى هنا لدينا مجموعة البيانات الأزياء MNIST.
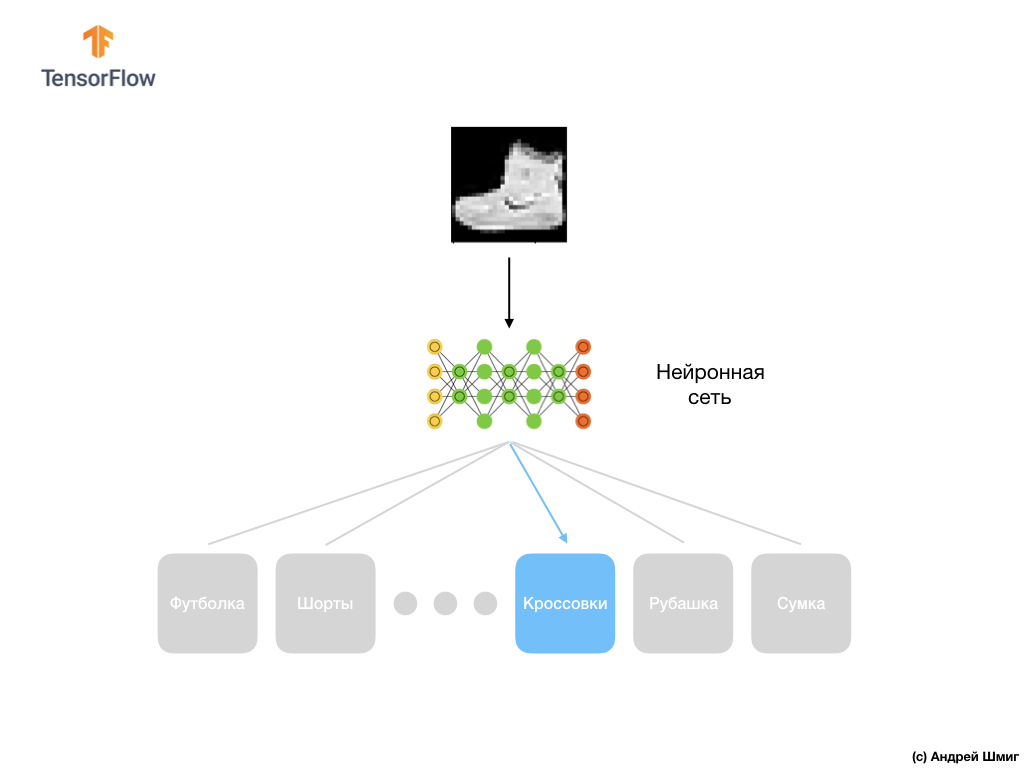
تذكر أن كل صورة في مجموعة البيانات هي صورة بحجم 28 × 28 بلون ظلال الرمادي ، مما يعني أن كل صورة بحجم 784 بايت. تتمثل مهمتنا في إنشاء شبكة عصبية ، تستقبل وحدات البايت 784 هذه عند المدخلات ، وعند إرجاع الناتج إلى فئة الملابس من أصل 10 المتاحة ، ينتمي العنصر المقدم في الإدخال.
الشبكة العصبية
في هذا الدرس ، سوف نستخدم شبكة عصبية عميقة تتعلم تصنيف الصور من مجموعة بيانات Fashion MNIST.
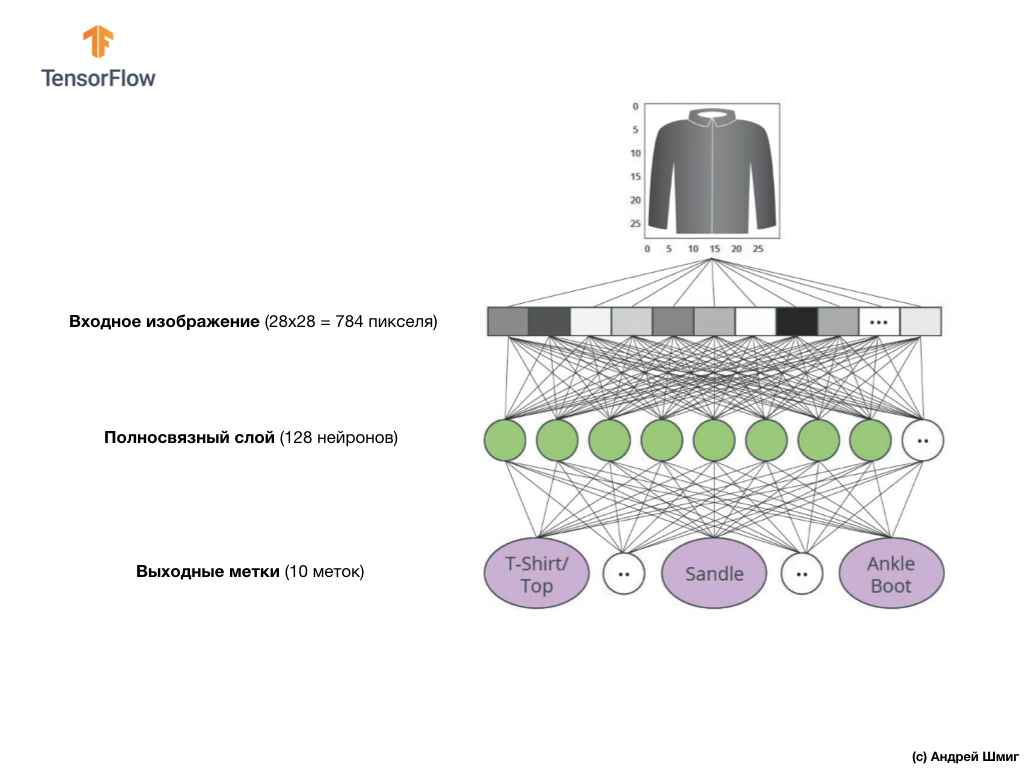
الصورة أعلاه توضح كيف ستبدو شبكتنا العصبية. دعونا ننظر في الأمر بمزيد من التفاصيل.
قيمة الإدخال لشبكتنا العصبية هي صفيف أحادي البعد بطول 784 ، صفيف بنفس الطول بالضبط لسبب أن كل صورة 28 × 28 بكسل (= 784 بكسل في المجموع في الصورة) ، والتي سنقوم بتحويلها إلى صفيف أحادي البعد. تسمى عملية تحويل صورة ثنائية الأبعاد إلى متجه التسطيح ويتم تنفيذها من خلال طبقة تنعيم - طبقة مسطحة.
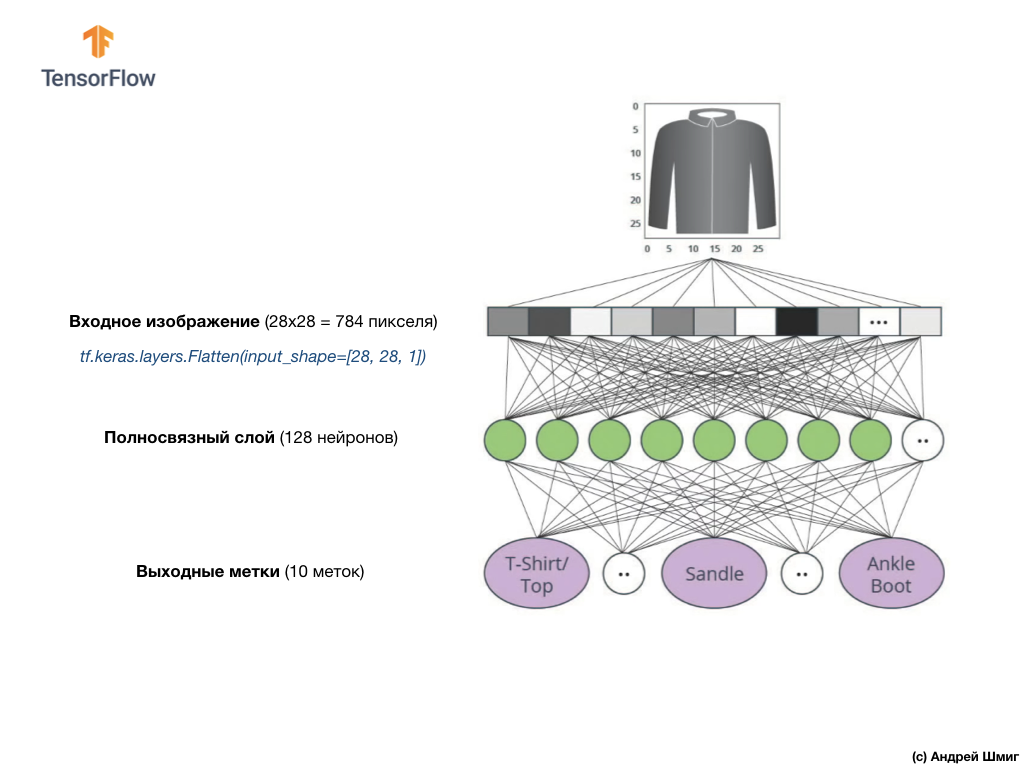
يمكنك إجراء التنعيم عن طريق إنشاء الطبقة المناسبة:
tf.keras.layers.Flatten(input_shape=[28, 28, 1])
تحول هذه الطبقة صورة ثنائية الأبعاد 28 × 28 بكسل (1 بايت لظلال رمادية لكل بكسل) إلى صفيف 1D من 784 بكسل.
سيتم ربط قيم المدخلات ارتباطًا تامًا بأول طبقة شبكية
dense ، حجمنا الذي اخترناه يساوي 128 خلية عصبية.
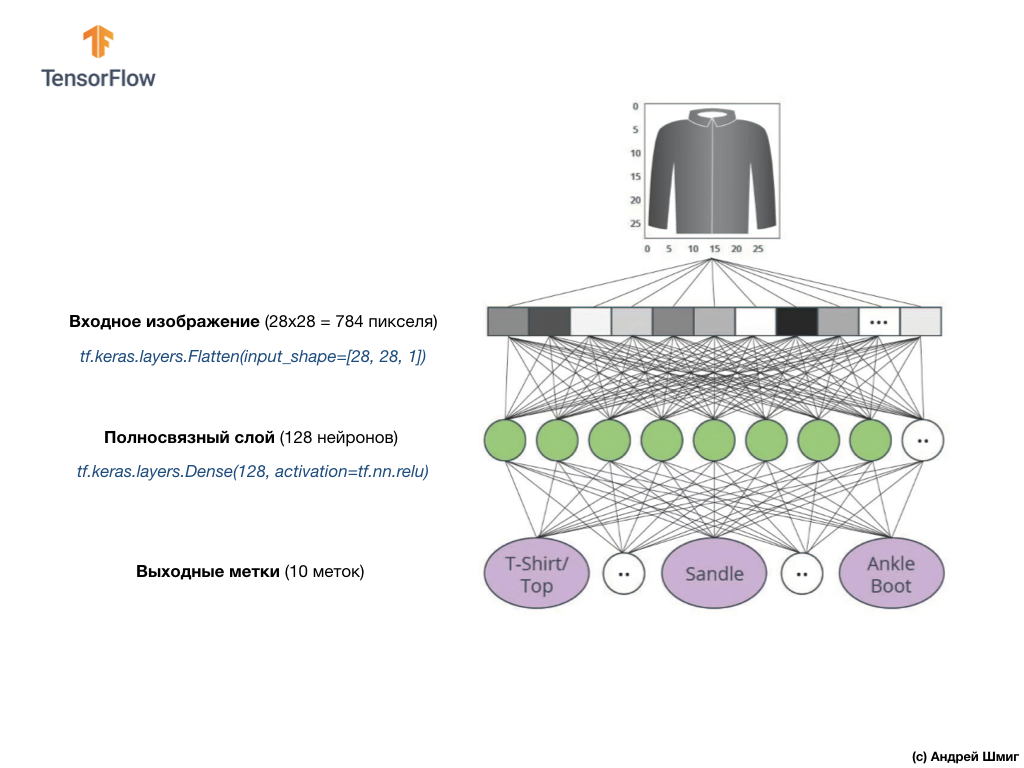
إليك ما سيبدو عليه إنشاء هذه الطبقة في الكود:
tf.keras.layers.Dense(128, activation=tf.nn.relu)
توقف عن ذلك! ما هو
tf.nn.relu ؟ لم نستخدم هذا في مثالنا السابق على الشبكة العصبية عند تحويل الدرجات المئوية إلى فهرنهايت! خلاصة القول هي أن المهمة الحالية أكثر تعقيدًا بكثير من المهمة التي استخدمت كمثال لتقصي الحقائق - تحويل الدرجات المئوية إلى درجات فهرنهايت.
ReLU هي وظيفة رياضية
ReLU المتصلة بالكامل والتي تعطي مزيدًا من القوة
ReLU . في الواقع ، هذا امتداد صغير لطبقتنا المتصلة بالكامل ، والذي يسمح لشبكتنا العصبية بحل مشاكل أكثر تعقيدًا. لن ندخل في التفاصيل ، ولكن يمكن العثور على مزيد من المعلومات المفصلة أدناه.
أخيرًا ، تتكون الطبقة الأخيرة لدينا ، والمعروفة أيضًا باسم طبقة الإخراج ، من 10 خلايا عصبية. يتكون من 10 خلايا عصبية لأن مجموعة بيانات Fashion MNIST تحتوي على 10 فئات ملابس. تمثل كل من قيم المخرجات العشرة هذه احتمال وجود صورة الإدخال في فئة الملابس هذه. بمعنى آخر ، تعكس هذه القيم "ثقة" النموذج في صحة تنبؤ الصورة المودعة وارتباطها بفئة محددة من أصل 10 فئات ملابس في الخرج. على سبيل المثال ، ما هو احتمال أن تظهر الصورة فستانًا ، أحذية رياضية ، أحذية ، إلخ.
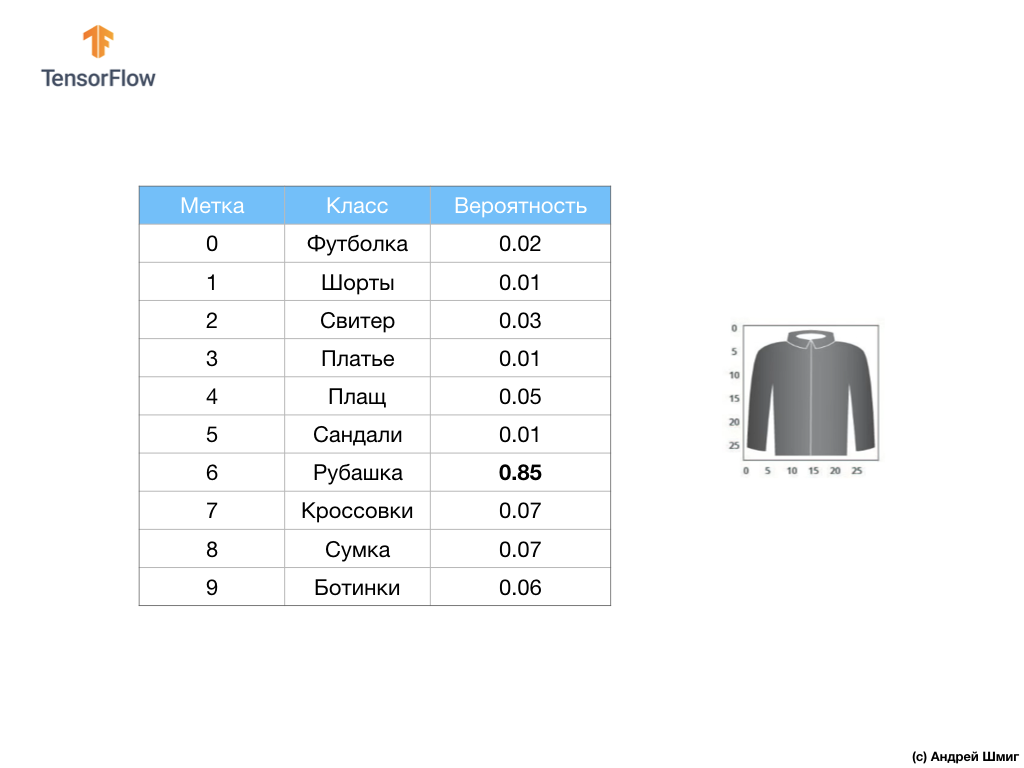
على سبيل المثال ، إذا تم إرسال صورة قميص إلى مدخلات شبكتنا العصبية ، يمكن أن يعطينا النموذج نتائج مثل تلك التي تراها في الصورة أعلاه - احتمال أن تكون صورة الإدخال مطابقة لتسمية المخرجات.
إذا لاحظت ، ستلاحظ أن الاحتمال الأكبر - 0.85 يشير إلى العلامة 6 ، التي تتوافق مع القميص. النموذج متأكد بنسبة 85 ٪ من أن الصورة على القميص. عادةً ما يكون للأشياء التي تبدو مثل القمصان درجة عالية من الاحتمالات ، والأشياء الأقل تشابهًا سيكون لها معدل احتمال أقل.
نظرًا لأن جميع قيم المخرجات العشرة تتوافق مع الاحتمالات ، فعند جمع كل هذه القيم ، نحصل على 1. وتسمى هذه القيم العشر أيضًا توزيع الاحتمالات.
نحتاج الآن إلى طبقة مخرجات لحساب الاحتمالات لكل تسمية.

وسنفعل ذلك باستخدام الأمر التالي:
tf.keras.layers.Dense(10, activation=tf.nn.softmax)
في الواقع ، كلما أنشأنا شبكات عصبية تعمل على حل مشكلات التصنيف ، نستخدم دائمًا طبقة متصلة تمامًا كالطبقة الأخيرة من الشبكة العصبية. يجب أن تحتوي الطبقة الأخيرة من الشبكة العصبية على عدد الخلايا العصبية التي تساوي عدد الفئات ، والتي نحدد
softmax ونستخدم وظيفة تنشيط softmax.
ReLU - وظيفة تنشيط الخلايا العصبية
في هذا الدرس ، تحدثنا عن
ReLU كشيء يوسع قدرات شبكتنا العصبية
ReLU قوة إضافية.
ReLU هي وظيفة رياضية تبدو كما يلي:
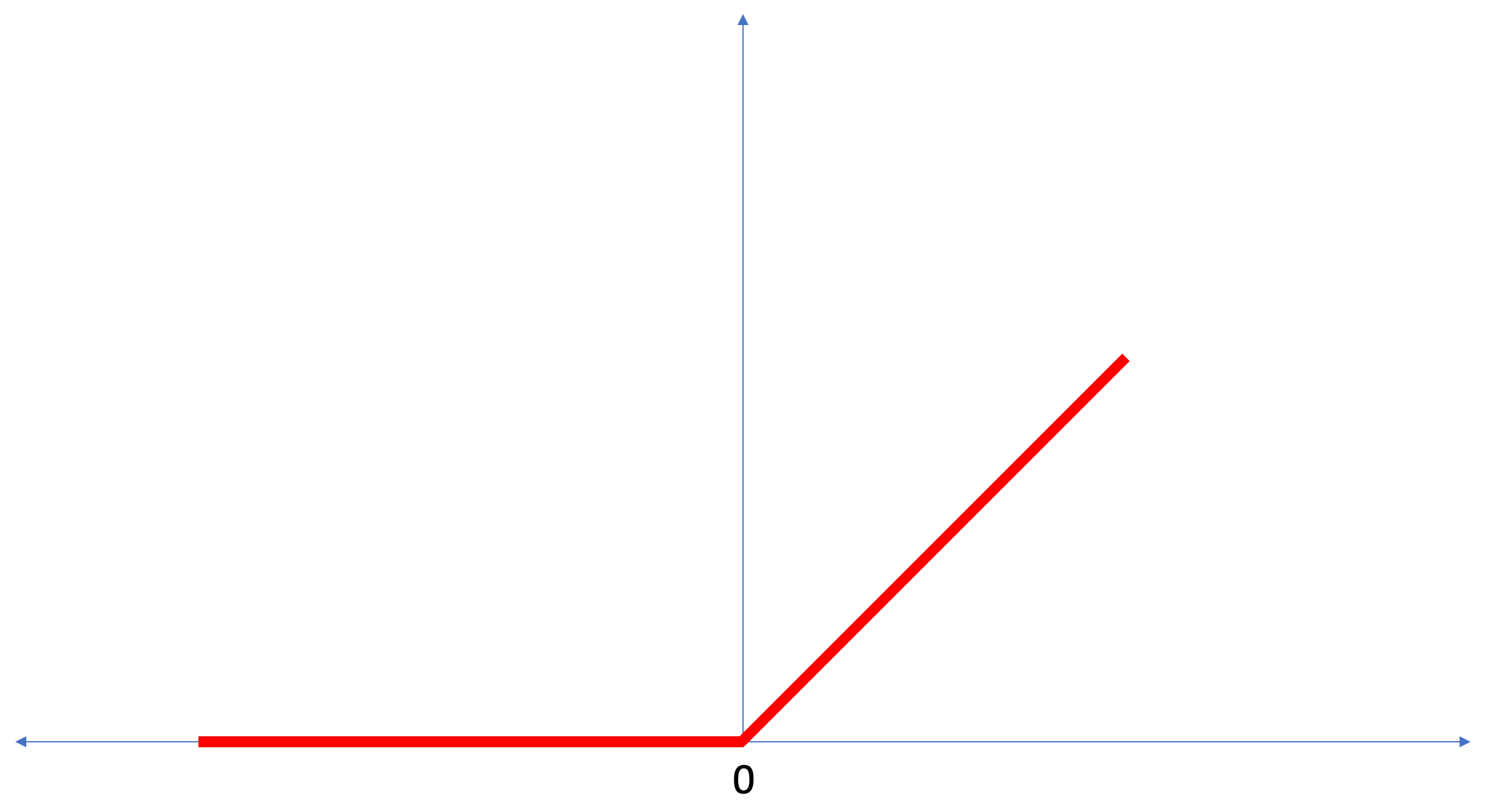
تقوم دالة
ReLU بإرجاع 0 إذا كانت قيمة الإدخال قيمة سالبة أو صفر ، في جميع الحالات الأخرى ستُرجع الدالة قيمة الإدخال الأصلية.
ReLU يجعل من الممكن حل المشاكل غير الخطية.
تحويل الدرجات المئوية إلى الدرجات فهرنهايت مهمة خطية ، لأن التعبير
f = 1.8*c + 32 هو معادلة الخط -
y = m*x + b . لكن معظم المهام التي نريد حلها غير خطية. في مثل هذه الحالات ، يمكن أن تساعد إضافة وظيفة تنشيط ReLU إلى الطبقة المتصلة بالكامل لدينا في هذا النوع من المهام.
ReLU هي مجرد نوع واحد من وظائف التنشيط. هناك وظائف التنشيط مثل السيني ، ReLU ، ELU ، tanh ، ومع ذلك ، فمن
ReLU الذي غالبا ما يستخدم كدالة التنشيط الافتراضية. لإنشاء نماذج تتضمن ReLU واستخدامها ، لن تحتاج إلى فهم كيفية عملها داخليًا. إذا كنت لا تزال تريد أن تفهم بشكل أفضل ، فنحن نوصيك
بهذا المقال .
دعنا نذهب إلى الشروط الجديدة المقدمة في هذا الدرس:
- تجانس - عملية تحويل صورة ثنائية الأبعاد إلى ناقل 1D ؛
- ReLU هي وظيفة التنشيط التي تسمح للنموذج بحل المشكلات غير الخطية ؛
- Softmax - دالة تحسب الاحتمالات لكل فئة مخرجات ممكنة ؛
- التصنيف - فئة من مهام التعلم الآلي المستخدمة لتحديد الاختلافات بين فئتين أو أكثر (فصول).
التدريب والاختبار
عند تدريب نموذج ، أي نموذج في التعلم الآلي ، من الضروري دائمًا تقسيم مجموعة البيانات إلى مجموعتين مختلفتين على الأقل - مجموعة البيانات المستخدمة للتدريب ومجموعة البيانات المستخدمة للاختبار. في هذا الجزء سوف نفهم لماذا يستحق القيام بذلك.
دعونا نتذكر كيف قمنا بتوزيع مجموعة البيانات الخاصة بنا من Fashion MNIST التي تتكون من 70،000 نسخة.
اقترحنا تقسيم 70،000 إلى جزأين - في الجزء الأول ، اترك 60،000 للتدريب ، وفي الجزء الثاني 10،000 للاختبار. سبب هذا النهج هو السبب التالي: بعد تدريب النموذج على 60000 نسخة ، من الضروري التحقق من النتائج وفعالية عملها على أمثلة لم تكن موجودة في مجموعة البيانات التي تم تدريب النموذج عليها.
إنه يشبه اجتياز امتحان في المدرسة بطريقته الخاصة. قبل أن تجتاز الامتحان ، فأنت تشارك بجد في حل مشكلات فصل معين. بعد ذلك ، في الاختبار ، تصادف نفس فئة المشاكل ، لكن مع بيانات إدخال مختلفة. ليس من المنطقي تقديم نفس البيانات التي كانت أثناء التدريب ، وإلا سيتم تقليل المهمة إلى تذكر القرارات ، وليس البحث عن نموذج الحل. لهذا السبب واجهت في الامتحانات مهام لم تكن موجودة في المناهج الدراسية من قبل. بهذه الطريقة فقط يمكننا التحقق مما إذا كان النموذج قد تعلم الحل العام أم لا.
يحدث الشيء نفسه مع التعلم الآلي. يمكنك عرض بعض البيانات التي تمثل فئة معينة من المهام التي تريد معرفة كيفية حلها. في حالتنا ، مع مجموعة بيانات من Fashion MNIST ، نريد أن تكون الشبكة العصبية قادرة على تحديد الفئة التي ينتمي إليها عنصر الملابس في الصورة. هذا هو السبب في أننا ندرب نموذجنا على 60000 أمثلة تحتوي على جميع فئات عناصر الملابس. بعد التدريب ، نريد التحقق من فعالية النموذج ، لذلك نقوم بإطعام 10000 قطعة من الملابس التي لم يطلع عليها النموذج بعد. إذا قررنا عدم القيام بذلك ، وليس الاختبار مع 10000 مثال ، فلن نكون قادرين على أن نقول على وجه اليقين ما إذا كان نموذجنا قد تم تدريبه فعليًا لتحديد فئة عنصر الملابس أو إذا تذكرت جميع أزواج قيم المدخلات + المخرجات.
هذا هو السبب في أننا نعلم دائمًا مجموعة بيانات للتدريب ومجموعة بيانات للاختبار.
TensorFlow هي عبارة عن مجموعة من بيانات التدريب الجاهزة للاستخدام.
عادة ما يتم تقسيم مجموعات البيانات إلى عدة كتل ، يتم استخدام كل منها في مرحلة معينة من التدريب واختبار فعالية الشبكة العصبية. في هذا الجزء نتحدث عن:
- مجموعة بيانات التدريب : مجموعة بيانات مخصصة لتدريب شبكة عصبية ؛
- مجموعة بيانات الاختبار : مجموعة بيانات مصممة للتحقق من كفاءة الشبكة العصبية ؛
النظر في مجموعة بيانات أخرى ، والتي أسميها مجموعة بيانات التحقق من الصحة. لا يتم استخدام مجموعة البيانات هذه لتدريب النموذج ، فقط
أثناء التدريب. لذلك ، بعد أن مر نموذجنا بعدة دورات تدريبية ، نقوم بإطعامنا مجموعة بيانات الاختبار الخاصة بنا وننظر في النتائج. على سبيل المثال ، إذا انخفضت قيمة وظيفة الخسارة أثناء التدريب ، وتدهورت الدقة في مجموعة بيانات الاختبار ، فهذا يعني أن نموذجنا ببساطة يتذكر أزواج من قيم المدخلات والمخرجات.
يتم إعادة استخدام مجموعة بيانات التحقق في نهاية التدريب لقياس الدقة النهائية لتوقعات النموذج.
لمزيد من
المعلومات حول التدريب ومجموعات بيانات الاختبار ، راجع دورة الأعطال في Google .
جزء عملي في CoLab
رابط إلى CoLab الأصلي باللغة الإنجليزية ورابط إلى CoLab الروسية .
تصنيف الصور من الملابس البنود
في هذا الجزء من الدرس ، سنقوم ببناء وتدريب شبكة عصبية لتصنيف صور عناصر الملابس ، مثل الفساتين والأحذية الرياضية والقمصان والقمصان وغيرها.
كل شيء على ما يرام إذا كانت بعض اللحظات غير واضحة. الغرض من هذه الدورة هو تعريفك بـ TensorFlow وفي نفس الوقت شرح خوارزميات عملها وتطوير فهم مشترك للمشاريع باستخدام TensorFlow ، بدلاً من الخوض في تفاصيل التنفيذ.
في هذا الجزء ، نستخدم
tf.keras ، واجهة برمجة تطبيقات عالية المستوى لبناء نماذج التدريب في TensorFlow.
تثبيت واستيراد التبعيات
سنحتاج
إلى مجموعة بيانات TensorFlow ، وهي واجهة برمجة التطبيقات التي تعمل على تبسيط عملية التحميل والوصول إلى مجموعات البيانات التي توفرها العديد من الخدمات. سنحتاج أيضًا إلى بعض المكتبات المساعدة.
!pip install -U tensorflow_datasets
from __future__ import absolute_import, division, print_function, unicode_literals
استيراد مجموعة البيانات Fashion MNIST
يستخدم هذا المثال مجموعة بيانات Fashion MNIST ، التي تحتوي على 70000 صورة لعناصر الملابس في 10 فئات في درجات الرمادي. تحتوي الصور على عناصر ملابس ذات دقة منخفضة (28 × 28 بكسل) ، كما هو موضح أدناه:

يتم استخدام Fashion MNIST كبديل لمجموعة البيانات MNIST الكلاسيكية - غالبًا ما تستخدم كـ "Hello، World!" في التعلم الآلي ورؤية الكمبيوتر. تحتوي مجموعة البيانات MNIST على صور لأرقام مكتوبة بخط اليد (0 ، 1 ، 2 ، إلخ) بنفس تنسيق عناصر الملابس في مثالنا.
في مثالنا ، نستخدم Fashion MNIST نظرًا للتنوع ولأن هذه المهمة أكثر إثارة للاهتمام من وجهة نظر التنفيذ من حل مشكلة نموذجية في مجموعة بيانات MNIST. مجموعتا البيانات صغيرتان بدرجة كافية ، وبالتالي ، يتم استخدامهما للتحقق من قابلية التشغيل الصحيحة للخوارزمية. مجموعات بيانات رائعة لبدء تعلم التعلّم الآلي والاختبار وتصحيح الأخطاء.
سنستخدم 60000 صورة لتدريب الشبكة و 10000 صورة لاختبار دقة التدريب وتصنيف الصور. يمكنك الوصول مباشرة إلى مجموعة بيانات Fashion MNIST من خلال TensorFlow باستخدام واجهة برمجة التطبيقات:
dataset, metadata = tfds.load('fashion_mnist', as_supervised=True, with_info=True) train_dataset, test_dataset = dataset['train'], dataset['test']
عن طريق تحميل مجموعة بيانات ، نحصل على بيانات التعريف ومجموعة بيانات التدريب ومجموعة بيانات الاختبار.
- تم تدريب النموذج على مجموعة بيانات من `train_dataset`
- تم اختبار النموذج على مجموعة بيانات من `test_dataset`
الصور عبارة عن صفائف
2828 ثنائية الأبعاد ، حيث يمكن أن تكون القيم في كل خلية في الفاصل الزمني
[0, 255] . التسميات - مجموعة من الأعداد الصحيحة ، حيث تكون كل قيمة في الفاصل الزمني
[0, 9] . تتوافق هذه التسميات مع فئة صورة الإخراج كما يلي:
كل صورة تنتمي إلى علامة واحدة. نظرًا لأن أسماء الفئات غير موجودة في مجموعة البيانات الأصلية ، فلنحفظها لاستخدامها في المستقبل عندما نرسم الصور:
class_names = [' / ', "", "", "", "", "", "", "", "", ""]
نحن البحوث البيانات
دعنا ندرس شكل وهيكل البيانات المقدمة في مجموعة التدريب قبل تدريب النموذج. ستظهر التعليمة البرمجية التالية أن 60،000 صورة موجودة في مجموعة بيانات التدريب ، وأن 10000 صورة موجودة في مجموعة بيانات الاختبار:
num_train_examples = metadata.splits['train'].num_examples num_test_examples = metadata.splits['test'].num_examples print(' : {}'.format(num_train_examples)) print(' : {}'.format(num_test_examples))
معالجة البيانات مسبقا
تكون قيمة كل بكسل في الصورة في النطاق
[0,255] . لكي يعمل النموذج بشكل صحيح ، يجب تسوية هذه القيم - يتم تقليلها إلى قيم في الفاصل الزمني
[0,1] . لذلك ، أقل قليلاً ، نعلن وننفذ وظيفة التطبيع ، ثم نطبقها على كل صورة في مجموعات بيانات التدريب والاختبار.
def normalize(images, labels): images = tf.cast(images, tf.float32) images /= 255 return images, labels
نحن ندرس البيانات التي تمت معالجتها
لنرسم صورة لنلقي نظرة عليها:
نعرض أول 25 صورة من مجموعة بيانات التدريب وتحت كل صورة نشير إلى الفئة التي ينتمي إليها.
تأكد من أن البيانات في التنسيق الصحيح ونحن على استعداد لبدء إنشاء وتدريب الشبكة.
plt.figure(figsize=(10,10)) i = 0 for (image, label) in test_dataset.take(25): image = image.numpy().reshape((28,28)) plt.subplot(5,5,i+1) plt.xticks([]) plt.yticks([]) plt.grid(False) plt.imshow(image, cmap=plt.cm.binary) plt.xlabel(class_names[label]) i += 1 plt.show()

بناء نموذج
يتطلب بناء الشبكة العصبية طبقات ضبط ، ثم تجميع نموذج بوظائف التحسين والخسارة.
تخصيص الطبقات
العنصر الأساسي في بناء الشبكة العصبية هو الطبقة. تستخرج الطبقة العرض من البيانات التي تدخل في مدخلاتها. نتيجة عمل عدة طبقات متصلة ، نحصل على وجهة نظر منطقية لحل المشكلة.
في أغلب الأوقات تقوم بالتعلم العميق ، ستنشئ روابط بين طبقات بسيطة. تحتوي معظم الطبقات ، على سبيل المثال ، مثل tf.keras.layers.Dense ، على مجموعة من المعلمات التي يمكن "تركيبها" أثناء عملية التعلم.
model = tf.keras.Sequential([ tf.keras.layers.Flatten(input_shape=(28, 28, 1)), tf.keras.layers.Dense(128, activation=tf.nn.relu), tf.keras.layers.Dense(10, activation=tf.nn.softmax) ])
تتكون الشبكة من ثلاث طبقات:
- إدخال
tf.keras.layers.Flatten - تحول هذه الطبقة الصور بحجم 28 × 28 بكسل إلى صفيف أحادي الأبعاد بحجم 784 (28 * 28). في هذه الطبقة ، ليست لدينا معلمات للتدريب ، لأن هذه الطبقة لا تتعامل إلا مع تحويل بيانات الإدخال. - طبقة خفية
tf.keras.layers.Dense - طبقة متصلة بإحكام من 128 خلية عصبية. تأخذ كل خلية (عقدة) كل قيم 784 من الطبقة السابقة كمدخلات ، وتغير قيم المدخلات وفقًا للأوزان الداخلية وعمليات التشرد أثناء التدريب ، وتُرجع قيمة واحدة إلى الطبقة التالية. ts.keras.layers.Dense طبقة الإخراج ts.keras.layers.Dense - softmax من 10 خلايا عصبية ، يمثل كل منها فئة معينة من عناصر الملابس. كما في الطبقة السابقة ، يتلقى كل خلية عصبية قيم إدخال جميع الخلايا العصبية الـ 128 في الطبقة السابقة. تتغير أوزان ونزوح كل خلية عصبية في هذه الطبقة أثناء التدريب بحيث تكون القيمة الناتجة في الفاصل الزمني [0,1] وتمثل احتمال أن الصورة تنتمي إلى هذه الفئة. مجموع جميع القيم الناتج من 10 الخلايا العصبية هي 1.
تجميع النموذج
قبل أن نبدأ في تدريب النموذج ، فإن الأمر يستحق بعض الإعدادات الإضافية. يتم إجراء هذه الإعدادات أثناء تجميع الطراز عندما يتم استدعاء طريقة الترجمة:
- دالة الخسارة - خوارزمية لقياس مدى القيمة المطلوبة عن القيمة المتوقعة.
- وظيفة التحسين - خوارزمية "لتركيب" المعلمات الداخلية (الأوزان والإزاحة) للنموذج لتقليل وظيفة الخسارة ؛
- المقاييس - تستخدم لمراقبة عملية التدريب والاختبار. يستخدم المثال التالي مقاييس مثل
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
نحن ندرب النموذج
أولاً ، نحدد تسلسل الإجراءات أثناء التدريب على مجموعة بيانات التدريب:
- كرر مجموعة بيانات الإدخال بعدد غير محدود من المرات باستخدام طريقة
dataset.repeat() (تحدد معلمة epochs الموضحة أدناه عدد مرات التكرار التدريبية المطلوب تنفيذها) - تقوم طريقة
dataset.shuffle(60000) جميع الصور بحيث لا يتأثر تدريب نموذجنا بترتيب إدخال بيانات الإدخال. - تخبر طريقة
dataset.batch(32) طريقة التدريب model.fit باستخدام كتل model.fit من 32 صورة وتسميات في model.fit مرة يتم فيها تحديث المتغيرات الداخلية للنموذج.
يتم التدريب عن طريق استدعاء طريقة
model.fit :
- يرسل
train_dataset إلى نموذج الإدخال. - يتعلم النموذج مطابقة الصورة المدخلة مع الملصق.
- تحدد المعلمات
epochs=5 عدد جلسات التدريب بـ 5 تكرارات تدريب كاملة على مجموعة بيانات ، مما يوفر لنا في النهاية تدريبًا على 5 * 60،000 = 300،000 أمثلة.
(يمكنك تجاهل معلمة
steps_per_epoch ، سيتم استبعاد هذه المعلمة قريبًا من الطريقة).
BATCH_SIZE = 32 train_dataset = train_dataset.repeat().shuffle(num_train_examples).batch(BATCH_SIZE) test_dataset = test_dataset.batch(BATCH_SIZE)
model.fit(train_dataset, epochs=5, steps_per_epoch=math.ceil(num_train_examples/BATCH_SIZE))
وهنا الاستنتاج:
Epoch 1/5
1875/1875 [==============================] - 26s 14ms/step - loss: 0.4921 - acc: 0.8267
Epoch 2/5
1875/1875 [==============================] - 20s 11ms/step - loss: 0.3652 - acc: 0.8686
Epoch 3/5
1875/1875 [==============================] - 20s 11ms/step - loss: 0.3341 - acc: 0.8782
Epoch 4/5
1875/1875 [==============================] - 19s 10ms/step - loss: 0.3111 - acc: 0.8858
Epoch 5/5
1875/1875 [==============================] - 16s 8ms/step - loss: 0.2911 - acc: 0.8922
أثناء التدريب النموذجي ، يتم عرض قيمة وظيفة الخسارة وقياس الدقة لكل تكرار تدريب. يحقق هذا النموذج دقة تبلغ حوالي 0.88 (88٪) في بيانات التدريب.
تحقق من الدقة
دعونا نتحقق من الدقة التي ينتجها النموذج على بيانات الاختبار. سوف نستخدم جميع الأمثلة التي لدينا في مجموعة بيانات الاختبار للتحقق من دقة.
test_loss, test_accuracy = model.evaluate(test_dataset, steps=math.ceil(num_test_examples/BATCH_SIZE)) print(" : ", test_accuracy)
الاستنتاج:
313/313 [==============================] - 1s 5ms/step - loss: 0.3440 - acc: 0.8793
: 0.8793
كما ترون ، تبين أن دقة مجموعة بيانات الاختبار أقل من دقة مجموعة بيانات التدريب. هذا أمر طبيعي تمامًا حيث تم تدريب النموذج على بيانات مجموعة البيانات. عندما يكتشف نموذج الصور التي لم يسبق له مثيل من قبل (من مجموعة بيانات train_datet) ، فمن الواضح أن كفاءة التصنيف ستنخفض.
التنبؤ واستكشاف
يمكننا استخدام النموذج المدربين للحصول على تنبؤات لبعض الصور.
for test_images, test_labels in test_dataset.take(1): test_images = test_images.numpy() test_labels = test_labels.numpy() predictions = model.predict(test_images)
predictions.shape
الخلاصة: في المثال أعلاه ، توقع النموذج تسميات لكل صورة إدخال اختبار. دعونا نلقي نظرة على التنبؤ الأول:(32, 10)
predictions[0]
الاستنتاج: array([3.1365351e-05, 9.0029374e-08, 5.0016739e-03, 6.3597057e-05, 6.8342477e-02, 1.0856857e-08, 9.2655218e-01, 1.8982398e-09, 8.4999456e-06, 1.0296091e-09], dtype=float32)
تذكر أن تنبؤات النماذج عبارة عن صفيف من 10 قيم. تصف هذه القيم "ثقة" النموذج في أن صورة الإدخال تنتمي إلى فئة معينة (قطعة ملابس). يمكننا أن نرى الحد الأقصى للقيمة على النحو التالي: np.argmax(predictions[0])
الاستنتاج: 6
هذا يعني أن النموذج كان أكثر ثقة بأن هذه الصورة تنتمي إلى الفئة المسمى 6 (class_names [6]). يمكننا التحقق والتأكد من أن النتيجة صحيحة وأنها صحيحة: test_labels[0]
6
يمكننا عرض جميع الصور المدخلة وتوقعات النموذج المقابلة لـ 10 فئات: def plot_image(i, predictions_array, true_labels, images): predictions_array, true_label, img = predictions_array[i], true_label[i], images[i] plt.grid(False) plt.xticks([]) plt.yticks([]) plt.imshow(img[...,0], cmap=plt.cm.binary) predicted_label = np.argmax(predictions_array) if predicted_label == true_label: color = 'blue' else: color = 'red' plt.xlabel("{} {:2.0f}% ({})".format(class_names[predicted_label], 100 * np.max(predictions_array), class_names[true_label]), color=color) def plot_value_array(i, predictions_array, true_label): predictions_array, true_label = predictions_array[i], true_label[i] plt.grid(False) plt.xticks([]) plt.yticks([]) thisplot = plt.bar(range(10), predictions_array, color="#777777") plt.ylim([0, 1]) predicted_label = np.argmax(predictions_array) thisplot[predicted_label].set_color('red') thisplot[true_label].set_color('blue')
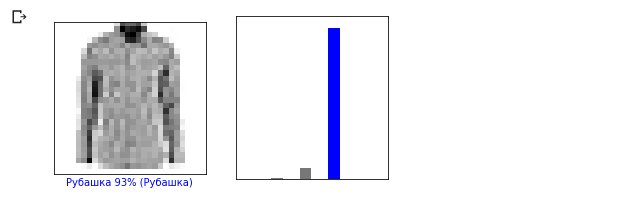
دعونا نلقي نظرة على الصورة 0th ، نتيجة التنبؤ بالنموذج ومجموعة من التنبؤات. i = 0 plt.figure(figsize=(6,3)) plt.subplot(1,2,1) plot_image(i, predictions, test_labels, test_images) plt.subplot(1,2,2) plot_value_array(i, predictions, test_labels)
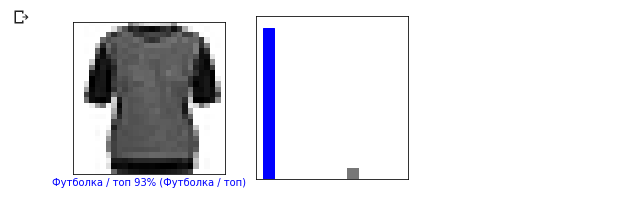
i = 12 plt.figure(figsize=(6,3)) plt.subplot(1,2,1) plot_image(i, predictions, test_labels, test_images) plt.subplot(1,2,2) plot_value_array(i, predictions, test_labels)
 دعنا الآن نعرض بعض الصور مع تنبؤاتها الخاصة. تنبؤات صحيحة أزرق و تنبؤات غير صحيحة أحمر. تعكس القيمة الموجودة أسفل الصورة النسبة المئوية للثقة التي تتوافق مع صورة الإدخال مع هذه الفئة. يرجى ملاحظة أن النتيجة قد تكون غير صحيحة حتى لو كانت قيمة "الثقة" عالية.
دعنا الآن نعرض بعض الصور مع تنبؤاتها الخاصة. تنبؤات صحيحة أزرق و تنبؤات غير صحيحة أحمر. تعكس القيمة الموجودة أسفل الصورة النسبة المئوية للثقة التي تتوافق مع صورة الإدخال مع هذه الفئة. يرجى ملاحظة أن النتيجة قد تكون غير صحيحة حتى لو كانت قيمة "الثقة" عالية. num_rows = 5 num_cols = 3 num_images = num_rows * num_cols plt.figure(figsize=(2*2*num_cols, 2*num_rows)) for i in range(num_images): plt.subplot(num_rows, 2*num_cols, 2*i + 1) plot_image(i, predictions, test_labels, test_images) plt.subplot(num_rows, 2*num_cols, 2*i + 2) plot_value_array(i, predictions, test_labels)
 استخدم النموذج المدرب للتنبؤ بالتسمية لصورة واحدة:
استخدم النموذج المدرب للتنبؤ بالتسمية لصورة واحدة: img = test_images[0] print(img.shape)
الاستنتاج: (28, 28, 1)
تم tf.kerasتحسين النماذج في التنبؤات حسب الكتل (المجموعات). لذلك ، على الرغم من أننا نستخدم عنصرًا واحدًا ، فأنت بحاجة إلى إضافته إلى القائمة: img = np.array([img]) print(img.shape)
الخلاصة:(1, 28, 28, 1)الآن سوف نتوقع النتيجة: predictions_single = model.predict(img) print(predictions_single)
الاستنتاج: [[3.1365438e-05 9.0029722e-08 5.0016833e-03 6.3597123e-05 6.8342514e-02 1.0856857e-08 9.2655218e-01 1.8982469e-09 8.4999692e-06 1.0296091e-09]]
plot_value_array(0, predictions_single, test_labels) _ = plt.xticks(range(10), class_names, rotation=45)
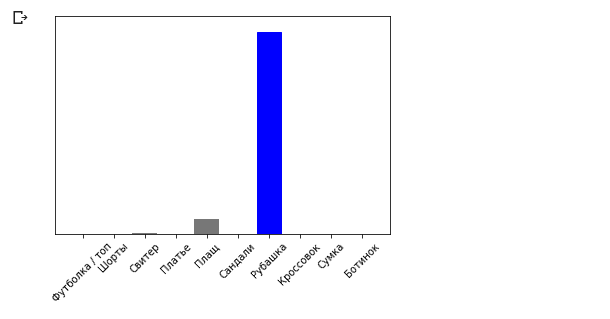 تُرجع طريقة model.predict قائمة بالقوائم (صفيف من المصفوفات) ، كل منها لصورة من كتلة إدخال. نحصل على النتيجة الوحيدة لصورة الإدخال الفردية الخاصة بنا:
تُرجع طريقة model.predict قائمة بالقوائم (صفيف من المصفوفات) ، كل منها لصورة من كتلة إدخال. نحصل على النتيجة الوحيدة لصورة الإدخال الفردية الخاصة بنا: np.argmax(predictions_single[0])
الاستنتاج: 6
كما سبق ، توقع النموذج التصنيف 6 (قميص).تمارين
تجربة نماذج مختلفة ومعرفة كيف ستتغير الدقة. على وجه الخصوص ، حاول تغيير الإعدادات التالية:- تعيين المعلمة epochs إلى 1 ؛
- تغيير عدد الخلايا العصبية في الطبقة المخفية ، على سبيل المثال ، من قيمة منخفضة من 10 إلى 512 ونرى كيف ستتغير دقة نموذج التنبؤ ؛
- إضافة طبقات إضافية بين الطبقة المسطحة (الطبقة الناعمة) والطبقة الكثيفة النهائية ، قم بتجربة عدد الخلايا العصبية في هذه الطبقة ؛
- لا تطبيع القيم بكسل ونرى ما سيحدث.
تذكر أن تقوم بتفعيل GPU بحيث تكون جميع العمليات الحسابية أسرع ( Runtime -> Change runtime type -> Hardware accelertor -> GPU). أيضًا ، إذا واجهتك مشكلات أثناء العملية ، فحاول إعادة تعيين إعدادات البيئة العامة:Edit -> Clear all outputsRuntime -> Reset all runtimes
الدرجات المئوية VS MNIST
- في هذه المرحلة ، واجهنا بالفعل نوعين من الشبكات العصبية. تعلمت شبكتنا العصبية الأولى كيفية تحويل الدرجات المئوية إلى الدرجات Frenheit ، مع إعادة قيمة واحدة يمكن أن تكون في مجموعة واسعة من القيم العددية.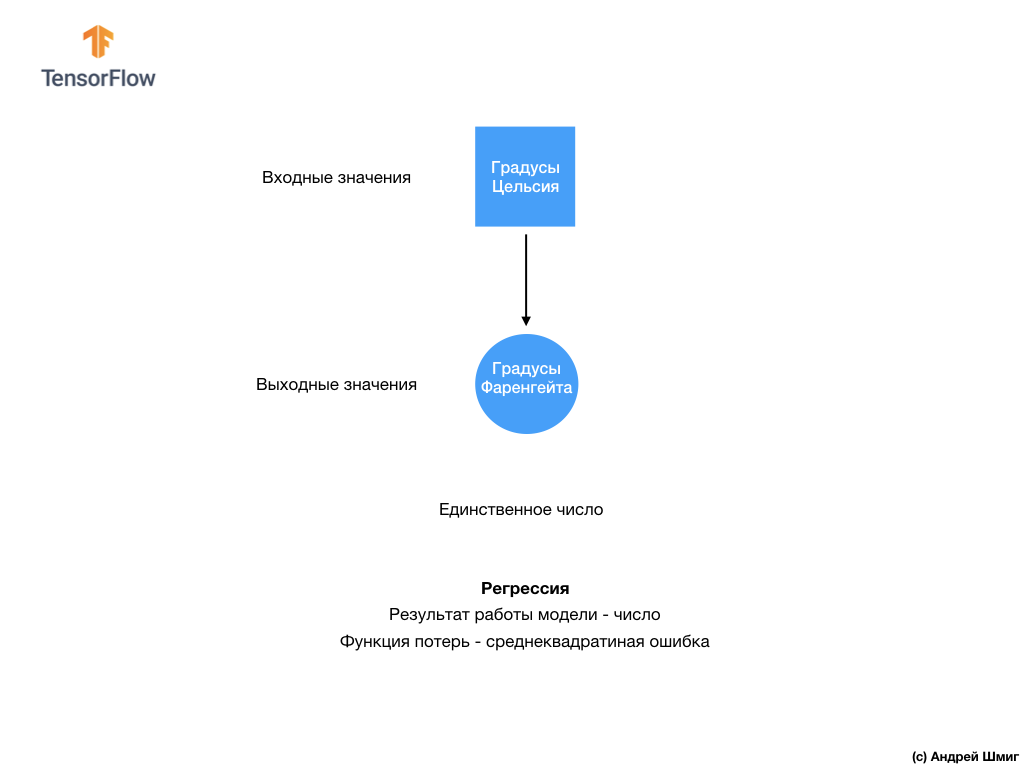 تقوم شبكتنا العصبية الثانية بإرجاع 10 قيم احتمالية تعكس ثقة الشبكة في أن صورة الإدخال تتوافق مع فئة معينة.يمكن استخدام الشبكات العصبية لحل المشكلات المختلفة.
تقوم شبكتنا العصبية الثانية بإرجاع 10 قيم احتمالية تعكس ثقة الشبكة في أن صورة الإدخال تتوافق مع فئة معينة.يمكن استخدام الشبكات العصبية لحل المشكلات المختلفة.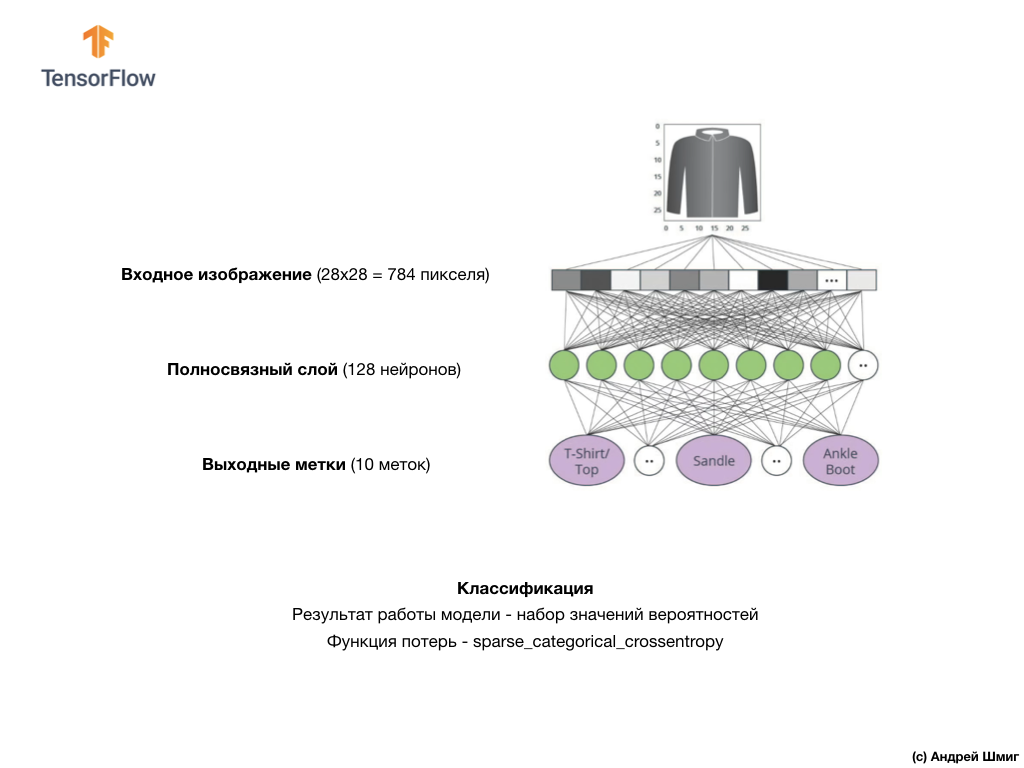 تسمى الفئة الأولى من المشكلات التي حللناها مع التنبؤ بقيمة واحدة الانحدار. يعد تحويل الدرجات المئوية إلى الدرجات فهرنهايت مثالاً على مهمة هذه الفئة. مثال آخر على هذه الفئة من المهام قد يكون مهمة تحديد قيمة المنزل حسب عدد الغرف والمساحة الكلية والموقع وخصائص أخرى.تسمى الفئة الثانية من المهام التي درسناها في هذا الدرس ، والتي تصنف الصور إلى فئات متاحة ، بالتصنيف . وفقًا لبيانات الإدخال ، سيعود النموذج بتوزيع الاحتمالية ("ثقة" النموذج الذي تنتمي إليه قيمة الإدخال في هذه الفئة). في هذا الدرس ، قمنا بتطوير شبكة عصبية تصنف عناصر الملابس إلى 10 فئات ، وفي الدرس التالي ، سنتعلم تحديد من يظهر في الصورة - كلب أو قطة ، تتعلق هذه المهمة أيضًا بمهمة التصنيف.مبلغ دعونا تصل النتائج وملاحظة الفرق بين هاتين الطبقتين من المشاكل - الانحدار و تصنيف .
تسمى الفئة الأولى من المشكلات التي حللناها مع التنبؤ بقيمة واحدة الانحدار. يعد تحويل الدرجات المئوية إلى الدرجات فهرنهايت مثالاً على مهمة هذه الفئة. مثال آخر على هذه الفئة من المهام قد يكون مهمة تحديد قيمة المنزل حسب عدد الغرف والمساحة الكلية والموقع وخصائص أخرى.تسمى الفئة الثانية من المهام التي درسناها في هذا الدرس ، والتي تصنف الصور إلى فئات متاحة ، بالتصنيف . وفقًا لبيانات الإدخال ، سيعود النموذج بتوزيع الاحتمالية ("ثقة" النموذج الذي تنتمي إليه قيمة الإدخال في هذه الفئة). في هذا الدرس ، قمنا بتطوير شبكة عصبية تصنف عناصر الملابس إلى 10 فئات ، وفي الدرس التالي ، سنتعلم تحديد من يظهر في الصورة - كلب أو قطة ، تتعلق هذه المهمة أيضًا بمهمة التصنيف.مبلغ دعونا تصل النتائج وملاحظة الفرق بين هاتين الطبقتين من المشاكل - الانحدار و تصنيف .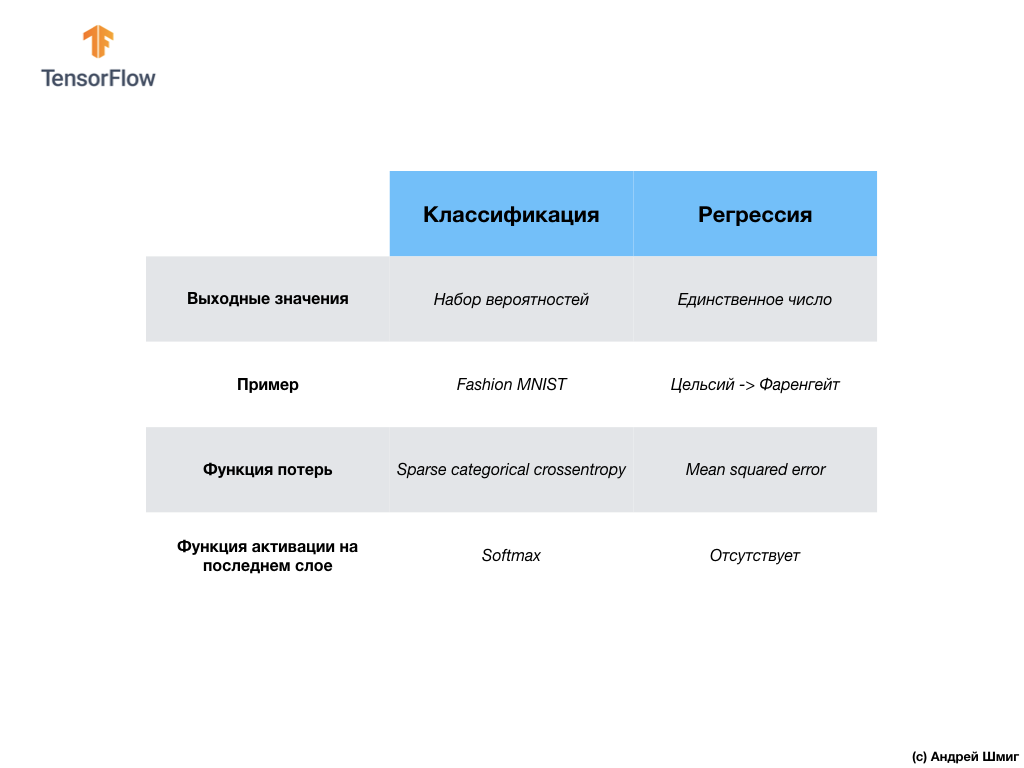 مبروك ، لقد درست نوعين من الشبكات العصبية! استعد للمحاضرة التالية ، سنقوم بدراسة نوع جديد من الشبكات العصبية - الشبكات العصبية التلافيفية (CNN).
مبروك ، لقد درست نوعين من الشبكات العصبية! استعد للمحاضرة التالية ، سنقوم بدراسة نوع جديد من الشبكات العصبية - الشبكات العصبية التلافيفية (CNN).النتائج
في هذا الدرس ، قمنا بتدريب الشبكة العصبية لتصنيف الصور بعناصر من الملابس. للقيام بذلك ، استخدمنا مجموعة بيانات Fashion MNIST ، التي تحتوي على 70000 صورة من عناصر الملابس. 60،000 منها كنا لتدريب الشبكة العصبية ، والباقي 10000 لاختبار فعالية عملها. لتقديم هذه الصور إلى مدخلات شبكتنا العصبية ، نحتاج إلى تحويلها (سلس) من 28x28 2D إلى تنسيق 1D من 784 عنصر. تتألف شبكتنا من طبقة متصلة تمامًا من 128 خلية وخلية مكونة من 10 خلايا عصبية ، تقابل عدد الملصقات (الفئات ، فئات عناصر الملابس). تمثل قيم الإخراج 10 توزيع الاحتمال لكل فئة. وظيفة تفعيل Softmaxتحسب توزيع الاحتمالات.وعلمنا أيضا حول الاختلافات بين الانحدار و تصنيف .- الانحدار : نموذج يُرجع قيمة مفردة ، مثل قيمة المنزل.
- التصنيف : نموذج يُرجع توزيع الاحتمالات بين عدة فئات. على سبيل المثال ، في مهمتنا مع Fashion MNIST ، كانت قيم المخرجات 10 قيم احتمالية ، ارتبطت كل منها بفئة معينة (فئة عنصر الملابس). أذكرك بأننا استخدمنا وظيفة تنشيط softmax لمجرد الحصول على توزيع الاحتمال على الطبقة الأخيرة.
... ومكالمة تحث على اتخاذ إجراء - اشترك ، ضع علامة زائد وشاركه :)
يوتيوببرقيةفكونتاكتي