
منذ بعض الوقت ، حدث لي قصة غير سارة ، والتي كانت بمثابة حافز لمشروع صغير على جيثب وأسفرت عن هذا المقال.
في يوم عادي ، إصدار منتظم: يتم فحص جميع المهام صعودًا وهبوطًا بواسطة مهندس ضمان الجودة لدينا ، لذلك مع هدوء البقرة المقدسة "ننتقل" إلى المسرح. يتصرف التطبيق بشكل جيد ، في سجلات - الصمت. نقرر أن نفعل التبديل (المرحلة <-> همز). نقوم بالتبديل وإلقاء نظرة على الأجهزة ...
يستغرق بضع دقائق ، الرحلة مستقرة. يقوم مهندس ضمان الجودة بإجراء اختبار الدخان ، ويلاحظ أن التطبيق يتباطأ بشكل غير طبيعي. نحن شطب لتسخين المخابئ.
تمر دقيقتان ، أول شكوى من السطر الأول: يتم تنزيل البيانات من العملاء لفترة طويلة جدًا ، ويبطئ التطبيق ، ويستغرق وقتًا طويلاً للرد ، إلخ. نبدأ في القلق ... ننظر إلى السجلات ونبحث عن الأسباب المحتملة.
بعد دقيقتين ، تصل رسالة من مدراء قواعد البيانات. يكتبون أن وقت تنفيذ الاستعلامات إلى قاعدة البيانات (المشار إليها فيما يلي باسم قاعدة البيانات) قد اخترق كل الحدود الممكنة ويميل إلى ما لا نهاية.
أفتح المراقبة (أستخدم
JavaMelody ) ، أجد هذه الطلبات. أبدأ PGAdmin ، وأنا استنساخ. حقا طويلة. أقوم بإضافة "الشرح" ، وألقي نظرة على خطة التنفيذ ... لقد نسينا الفهارس.
لماذا لا تعد مراجعة الشفرة كافية؟
هذا الحادث علمني الكثير. نعم ، "أخمدت الحريق" لمدة ساعة ، وأوجد المؤشر الصحيح مباشرة على المنتج بطريقة ما (لا تنسَ الخيار "حذر"):
CREATE INDEX CONCURRENTLY IF NOT EXISTS ix_pets_name ON pets_table (name_column);
موافق ، كان هذا بمثابة نشر مع توقف. بالنسبة للتطبيق الذي أعمل عليه ، هذا غير مقبول.
لقد خلصت إلى نتائج وأضفت نقطة غامقة خاصة إلى قائمة مراجعة التعليمات البرمجية: إذا رأيت أنه أثناء عملية التطوير ، تمت إضافة / تغيير إحدى فئات السجل - أتحقق من عمليات ترحيل sql بحثًا عن وجود برنامج نصي يقوم بإنشاء وتعديل الفهرس. إذا لم يكن هناك ، فأنا أكتب إلى المؤلف سؤالًا: هل هو متأكد من أن الفهرس غير مطلوب هنا؟
من المحتمل ألا يكون هناك حاجة إلى فهرس إذا كانت هناك بيانات قليلة ، ولكن إذا عملنا مع جدول يتم فيه حساب عدد الصفوف بالملايين ، يمكن أن يصبح خطأ الفهرس قاتلاً ويؤدي إلى القصة الواردة في بداية المقالة.
في هذه الحالة ، أطلب من مؤلف طلب السحب (يشار إليه فيما يلي PR) أن يكون متأكدًا بنسبة 100٪ من أن الفهرس الذي كتبه في HQL مغطى جزئيًا على الأقل بالفهرس (يتم استخدام الفهرس المسح الضوئي). لهذا ، المطور:
- تطلق التطبيق
- البحث عن الاستعلام المحول (HQL -> SQL) في السجلات
- يفتح PGAdmin أو أداة أخرى لإدارة قاعدة البيانات
- يولد في قاعدة البيانات المحلية ، حتى لا يزعج أي شخص بتجاربه ، كمية من البيانات مقبولة للاختبارات (سجلات 10K - 20K على الأقل)
- يلبي الطلب
- يطلب خطة التنفيذ
- يدرس بعناية ويستخلص الاستنتاجات المناسبة
- يضيف / يعدل الفهرس ، مع التأكد من أن خطة التنفيذ مناسبة له
- إلغاء الاشتراك في العلاقات العامة التي فحصت تغطية الطلب
- تقييم بخبرة مخاطر وشدة الطلب ، ويمكنني التحقق من أفعالها
الكثير من الإجراءات الروتينية والعامل البشري ، لكن لبعض الوقت كنت راضية ، وعشت مع هذا.
في الطريق إلى البيت
يقولون إنه من المفيد جدًا في بعض الأحيان على الأقل الانتقال من العمل دون الاستماع إلى الموسيقى / المدونة الصوتية على طول الطريق. في هذا الوقت ، مجرد التفكير في الحياة ، يمكنك التوصل إلى استنتاجات وأفكار مثيرة للاهتمام.
ذات يوم مشيت إلى المنزل وفكرت فيما حدث في ذلك اليوم. كان هناك القليل من المراجعة ، لقد راجعت كل واحدة مع قائمة مرجعية وفعلت سلسلة من الإجراءات المذكورة أعلاه. شعرت بالتعب الشديد في ذلك الوقت ، فماذا بحق الجحيم؟ هل من المستحيل القيام بذلك تلقائيًا؟ .. لقد اتخذت خطوة سريعة ، مع الرغبة في "قص" هذه الفكرة بسرعة.
بيان المشكلة
ما هو الأكثر أهمية للمطور في خطة التنفيذ؟
بالطبع ، سحق المسح على كميات كبيرة من البيانات الناجمة عن عدم وجود فهرس.
وبالتالي ، كان من الضروري إجراء اختبار ما يلي:
- أجريت على قاعدة بيانات مع تكوين مماثل ل prod
- يعترض استعلام قاعدة بيانات تم إجراؤه بواسطة مستودع JPA (الإسبات)
- تحصل عليه خطة التنفيذ
- خطة تنفيذ Parsit ، ووضعها في بنية بيانات مريحة للفحوصات
- باستخدام مجموعة مريحة من أساليب تأكيد ، يتحقق التوقعات. على سبيل المثال ، لا يتم استخدام ذلك المسح seq.
كان من الضروري اختبار هذه الفرضية بسرعة عن طريق إنشاء نموذج أولي.
هندسة الحلول
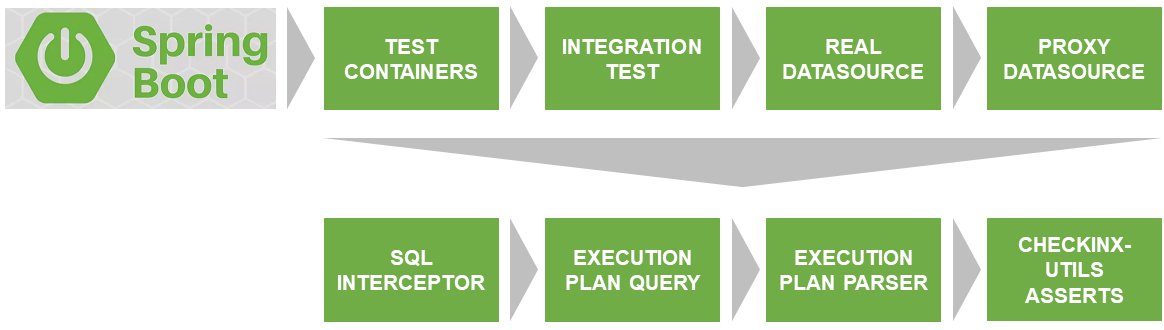
المشكلة الأولى التي كان من المقرر حلها هي إطلاق الاختبار على قاعدة بيانات حقيقية تطابق الإصدار والإعدادات مع تلك المستخدمة في المنتج.
بفضل
Docker & TestContainers ، يقومون بحل هذه المشكلة.
تعتبر SqlInterceptor و ExecutionPlanQuery و ExecutionPlanParse و AssertService هي الواجهات التي طبقتها حاليًا على Postgres. خطط لتنفيذ قواعد البيانات الأخرى. إذا كنت ترغب في المشاركة - مرحبًا بك. الرمز مكتوب باللغة Kotlin.
كل هذا معًا نشرته على جيثب ودعت
checkinx-utils . لا تحتاج إلى تكرار هذا ، فقط قم بتوصيل التبعية إلى checkinx في maven / gradle واستخدام تأكيدات مريحة. كيفية القيام بذلك ، سوف أصف بمزيد من التفصيل أدناه.
وصف تفاعل مكونات CheckInx
ProxyDataSource
المشكلة الأولى التي كان يجب حلها هي اعتراض استعلامات قاعدة البيانات الجاهزة للتنفيذ. بالفعل مع المعلمات المعمول بها ، دون أسئلة ، الخ
للقيام بذلك ، تحتاج إلى التفاف مصدر البيانات الحقيقي في وكيل معين ، مما سيتيح لك الاندماج في خط أنابيب تنفيذ الاستعلام ، وبالتالي ، اعتراضهم.
تم بالفعل تطبيق ProxyDataSource من قبل الكثيرين. لقد استخدمت حل
ttddyy الجاهزة ، والذي يسمح لي بتثبيت مستمع اعتراض الطلب الذي أحتاجه.
استبدل مصدر DataSource باستخدام فئة DataSourceWrapper (BeanPostProcessor).
SqlInterceptor
في الحقيقة ، تقوم طريقة start () الخاصة بها بتعيين المستمع في proxyDataSource وتبدأ في اعتراض الطلبات وتخزينها في قائمة العبارات الداخلية. الأسلوب stop () ، على التوالي ، يزيل المستمع المثبت.
ExecutionPlanQuery
هنا ، يتم تحويل الطلب الأصلي إلى طلب لخطة التنفيذ. في حالة Postgres ، هذا إضافة إلى الكلمة الأساسية الاستعلام "EXPLAIN".
علاوة على ذلك ، يتم تنفيذ هذا الاستعلام على نفس قاعدة البيانات من testcontainders ويتم إرجاع خطة التنفيذ "الخام" (قائمة الأسطر).
ExecutionPlanParser
من غير المريح العمل مع خطة تنفيذ خام. لذلك ، أنا تحليله إلى شجرة تتكون من العقد (PlanNode).
دعنا نحلل حقول PlanNode باستخدام مثال على ExecutionPlan حقيقي:
Index Scan using ix_pets_age on pets (cost=0.29..8.77 rows=1 width=36) Index Cond: (age < 10) Filter: ((name)::text = 'Jack'::text)
AssertService
من الممكن بالفعل العمل بشكل طبيعي مع بنية البيانات التي يتم إرجاعها بواسطة المحلل اللغوي. CheckInxAssertService هي مجموعة من عمليات التحقق من شجرة PlanNode الموضحة أعلاه. إنها تتيح لك ضبط lambdas الخاصة بك من الشيكات أو استخدام المعرّفات المحددة مسبقًا ، في رأيي ، الأكثر شيوعًا. على سبيل المثال ، بحيث لا يحتوي الاستعلام الخاص بك على Seq Scan ، أو تريد التأكد من استخدام فهرس معين / عدم استخدامه.
CoverageLevel
التعداد مهم جدا ، وسوف أصف ذلك بشكل منفصل:
بعد ذلك ، سوف نلقي نظرة على بعض أمثلة الاستخدام.
اختبار أمثلة باستخدام CheckInx
فعلت مشروعًا منفصلاً على GitHub
checkinx-demo ، حيث نفذت مستودع JPA لجدول الحيوانات الأليفة واختبارات لتغطية التحقق من المخزون ، والفهارس ، إلخ. سيكون من المفيد أن ننظر هناك كنقطة انطلاق.
قد يكون لديك اختبار مثل هذا:
@Test fun testFindByLocation() {
يمكن أن تكون خطة التنفيذ كما يلي:
Index Scan using ix_pets_location on pets pet0_ (cost=0.29..4.30 rows=1 width=46) Index Cond: ((location)::text = 'Moscow'::text)
... أو ما شابه ذلك إذا نسينا الفهرس (تتحول الاختبارات إلى اللون الأحمر):
Seq Scan on pets pet0_ (cost=0.00..19.00 rows=4 width=84) Filter: ((location)::text = 'Moscow'::text)
في مشروعي ، أستخدم في الغالب أبسط تأكيد ، والذي يقول أنه لا يوجد Seq Scan في خطة التنفيذ:
checkInxAssertService.assertCoverage(CoverageLevel.HALF, sqlInterceptor.statements[0])
يشير وجود مثل هذا الاختبار إلى أنني ، على الأقل ، درست خطة التنفيذ.
كما أنه يجعل إدارة المشروع أكثر وضوحًا ، ويزيد قابلية التوثيق وإمكانية التنبؤ بالشفرة.
وضع ذوي الخبرةأوصي باستخدام CheckInxAssertService ، لكن إذا لزم الأمر ، يمكنك تجاوز الشجرة التي تم تحليلها (ExecutionPlanParser) بنفسك أو بشكل عام ، تحليل خطة التنفيذ الأولية (نتيجة تنفيذ ExecutionPlanQuery).
@Test fun testFindByLocation() {
اتصال للمشروع
في مشروعي ، خصصت هذه الاختبارات لمجموعة منفصلة ، أطلق عليها اختبارات التكامل المكثفة.
الاتصال والبدء في استخدام checkinx-utils سهل بدرجة كافية. دعنا نبدأ مع بناء النص.
قم بتوصيل المستودع أولاً. يوما ما سوف أقوم بتحميل checkinx على maven ، ولكن الآن يمكنك تنزيل الأداة فقط من GitHub عبر jitpack.
repositories { // ... maven { url 'https://jitpack.io' } }
بعد ذلك ، أضف التبعية:
dependencies { // ... implementation 'com.github.tinkoffcreditsystems:checkinx-utils:0.2.0' }
نكمل الاتصال عن طريق إضافة التكوين. Postgres فقط معتمد حاليًا.
@Profile("test") @ImportAutoConfiguration(classes = [PostgresConfig::class]) @Configuration open class CheckInxConfig
إيلاء الاهتمام لملف الاختبار. وإلا ، ستجد ProxyDataSource في منتجك.
PostgresConfig يربط العديد من الفول:
- DataSourceWrapper
- PostgresInterceptor
- PostgresExecutionPlanParser
- PostgresExecutionPlanQuery
- CheckInxAssertServiceImpl
إذا كنت بحاجة إلى نوع من التخصيص لا توفره واجهة برمجة التطبيقات الحالية ، فيمكنك دائمًا الاستعاضة عن تطبيق واحد من الحبة.
المشكلات المعروفة
أحيانًا يفشل DataSourceWrapper في استبدال مصدر البيانات الأصلي بسبب وكيل Spring CGLIB. في هذه الحالة ، لا يأتي مصدر البيانات إلى BeanPostProcessor ، ولكن ScopedProxyFactoryBean وهناك مشاكل في التحقق من النوع.
سيكون الحل الأسهل هو إنشاء HikariDataSource يدويًا للاختبارات. ثم التكوين الخاص بك سيكون على النحو التالي:
@Profile("test") @ImportAutoConfiguration(classes = [PostgresConfig::class]) @Configuration open class CheckInxConfig { @Primary @Bean @ConfigurationProperties("spring.datasource") open fun dataSource(): DataSource { return DataSourceBuilder.create() .type(HikariDataSource::class.<i>java</i>) .build() } @Bean @ConfigurationProperties("spring.datasource.configuration") open fun dataSource(properties: DataSourceProperties): HikariDataSource { return properties.initializeDataSourceBuilder() .type(HikariDataSource::class.<i>java</i>) .build() } }
خطط التنمية
- أود أن أفهم ما إذا كان أي شخص آخر غيري يحتاج إلى هذا؟ للقيام بذلك ، قم بإنشاء استطلاع. سأكون سعيدا للرد بصراحة.
- تعرف على ما تحتاج إليه حقًا وقم بتوسيع القائمة القياسية لطرق التأكيد.
- كتابة تطبيقات لقواعد البيانات الأخرى.
- بناء sqlInterceptor.statements [0] لا يبدو واضحًا جدًا ، أريد تحسينه.
سأكون سعيدًا إذا ما أراد أحدهم الانضمام والحصول على بعض الائتمان من خلال ممارسته في Kotlin.
استنتاج
أنا متأكد من أنه ستكون هناك تعليقات:
من المستحيل التنبؤ بكيفية تصرف مخطط الاستعلام على المنتج ، كل هذا يتوقف على الإحصاءات التي تم جمعها .
في الواقع ، مخطط. باستخدام الإحصاءات التي تم جمعها في وقت سابق ، فإنه يمكن بناء خطة مختلفة عن تلك التي يجري اختبارها. المعنى مختلف قليلاً.
تتمثل مهمة المخطط في تحسين الطلب ، وليس تفاقمه. لذلك ، دون سبب واضح ، لن يستخدم فجأة Seq Scan ، ولكن يمكنك أن تدري.
أنت بحاجة إلى CheckInx حتى عند كتابة اختبار ، لا تنس أن تدرس خطة تنفيذ الاستعلام وتفكر في إمكانية إنشاء فهرس ، أو العكس ، تظهر بوضوح مع اختبار أنه لا توجد فهارس مطلوبة هنا وأنت راضٍ عن Seq Scan. هذا سيوفر لك الأسئلة غير الضرورية في مراجعة التعليمات البرمجية.
مراجع
- https://github.com/TinkoffCreditSystems/checkinx-utils
- https://github.com/dsemyriazhko/checkinx-demo
- https://github.com/ttddyy/datasource-proxy
- https://mvnrepository.com/artifact/org.testcontainers/postgresql
- https://github.com/javamelody/javamelody/wiki