مرحبا بالجميع. اسمي Danila ، أعمل في فريق يقوم بتطوير البنية التحتية التحليلية في Avito. المركزية لهذه البنية التحتية هو اختبار A / B.
تعد تجارب A / B أداة رئيسية لصنع القرار في Avito. في دورة تطوير منتجاتنا ، يعد اختبار A / B أمرًا ضروريًا. نحن نختبر كل فرضية ونطرح تغييرات إيجابية فقط.
نحن نجمع مئات المقاييس ونستطيع الانتقال بها إلى أقسام الأعمال: القطاعات ، المناطق ، المستخدمون المصرح لهم ، إلخ. نقوم بذلك تلقائيًا باستخدام منصة واحدة للتجارب. في هذه المقالة ، سوف أخبرك بتفاصيل كافية عن كيفية ترتيب المنصة وسنتعمق في بعض التفاصيل الفنية المثيرة للاهتمام.

المهام الرئيسية للمنصة A / B تصاغ على النحو التالي.
- يساعدك بسرعة تشغيل التجارب
- يتحكم في تقاطعات التجربة غير المرغوب فيها
- التهم المقاييس ، القانون الأساسي. الاختبارات ، تصور النتائج
بمعنى آخر ، تساعد المنصة في اتخاذ قرارات خالية من الأخطاء بشكل أسرع.
إذا تركنا عملية تطوير الميزات التي يتم إرسالها للاختبار ، فإن الدورة الكاملة للتجربة تبدو كما يلي:

- يقوم العميل (المحلل أو مدير المنتج) بتكوين معلمات التجربة من خلال لوحة المسؤول.
- تقوم الخدمة المقسمة ، وفقًا لهذه المعلمات ، بتوزيع مجموعة A / B الضرورية على جهاز العميل.
- يتم تجميع إجراءات المستخدم في سجلات أولية تمر عبر التجميع وتتحول إلى مقاييس.
- يتم تشغيل المقاييس من خلال الاختبارات الإحصائية.
- يتم تصور النتائج على البوابة الداخلية في اليوم التالي للإطلاق.
كل نقل البيانات في دورة يستغرق يوم واحد. وكقاعدة عامة ، تستمر التجارب أسبوعًا ، لكن العميل يتلقى زيادة في النتائج كل يوم.
الآن دعونا نتعمق في التفاصيل.
إدارة التجربة
تستخدم لوحة الإدارة تنسيق YAML لتكوين التجارب.

هذا حل مناسب لفريق صغير: الانتهاء من قدرات التكوين دون واجهة. يؤدي استخدام التكوينات النصية إلى تبسيط العمل للمستخدم: تحتاج إلى إجراء نقرات أقل باستخدام الماوس. يتم استخدام حل مشابه بواسطة إطار Airbnb A / B.
لتقسيم حركة المرور إلى مجموعات ، نستخدم تقنية تجزئة الملح الشائعة.
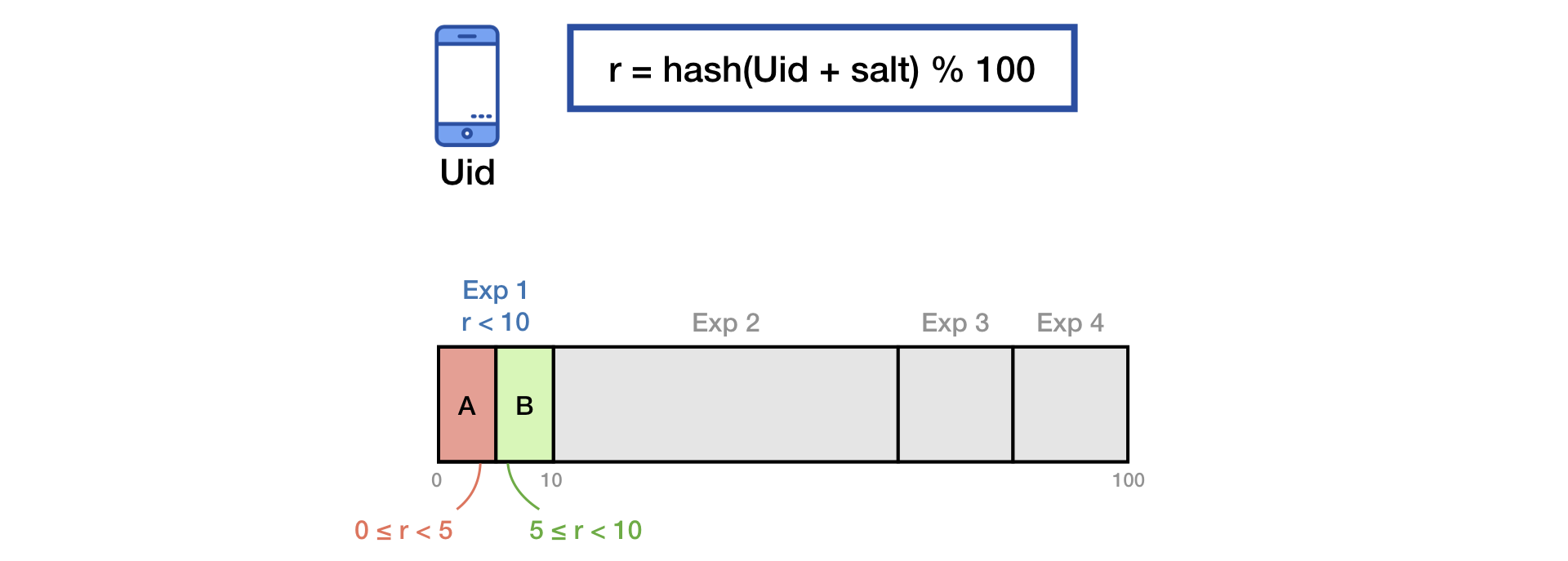
للقضاء على تأثير "ذاكرة" المستخدمين ، عند بدء تجربة جديدة ، نقوم بخلط إضافي مع الملح الثاني:

ويرد نفس المبدأ في عرض ياندكس .
من أجل منع التقاطعات المحتملة للتجارب الخطرة ، نستخدم المنطق المماثل لـ "الطبقات" في Google .
جمع القياسات
نضع السجلات الأولية في Vertica ونجمعها في جداول الإعداد بالهيكل:

الملاحظات عادة ما تكون عدادات أحداث بسيطة. تستخدم الملاحظات كمكونات في صيغة الحساب المتري.
معادلة حساب أي قياس عبارة عن كسر ، في البسط والمقام الذي يمثل مجموع الملاحظات:
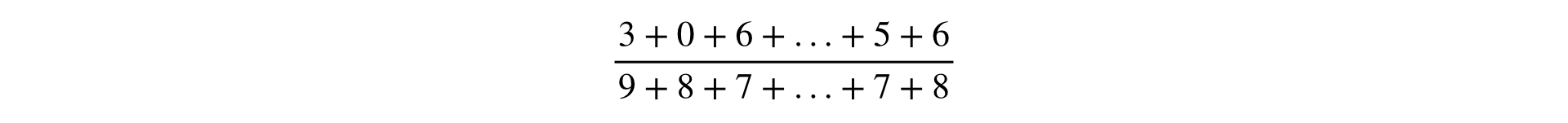
في أحد تقارير ياندكس ، تم تقسيم المقاييس إلى نوعين: حسب المستخدمين والنسبة. هذا أمر منطقي ، ولكن في البنية التحتية ، من المريح مراعاة جميع المقاييس بنفس طريقة حساب Ratio. هذا التعميم صالح ، لأن قياس "posyuzerny" يمكن تمثيله بوضوح على أنه جزء صغير:
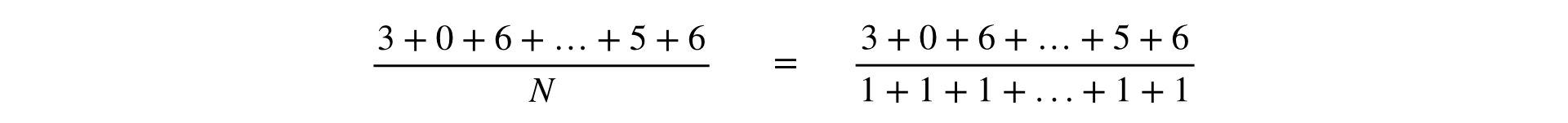
نلخص الملاحظات في البسط وقاسم المقياس بطريقتين.
بسيطة:
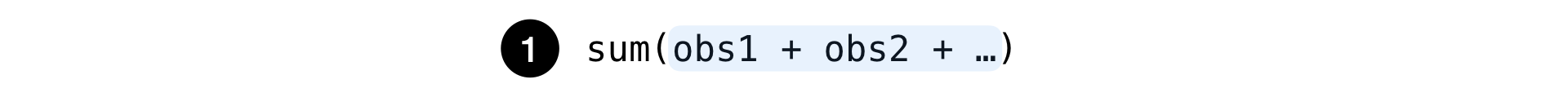
هذا هو المقدار المعتاد لأي مجموعة من الملاحظات: عدد عمليات البحث ، والنقرات على الإعلانات ، إلخ.
وأكثر تعقيدا:

عدد فريد من المفاتيح ، في المجموعة التي يكون فيها مجموع الملاحظات أكبر من عتبة معينة.
يتم ضبط هذه الصيغ بسهولة باستخدام تكوين YAML:

المعلمات groupby والعتبة اختيارية. فقط يحددون الطريقة الثانية للجمع.
تسمح لك المعايير الموصوفة بتكوين أي مقياس تقريبًا على الإنترنت يمكنك التفكير فيه. في الوقت نفسه ، يتم الحفاظ على المنطق البسيط الذي لا يفرض تحميلًا مفرطًا على البنية التحتية.
المعيار الإحصائي
نقيس أهمية الانحرافات بواسطة المقاييس باستخدام الطرق الكلاسيكية: اختبار T ، اختبار Mann-Whitney U. الشرط الضروري الرئيسي لتطبيق هذه المعايير هو أن الملاحظات في العينة لا ينبغي أن تعتمد على بعضها البعض. في جميع تجاربنا تقريبًا ، نعتقد أن المستخدمين (Uid) يحققون هذا الشرط.

الآن السؤال الذي يطرح نفسه: كيفية إجراء اختبار T و MW لاختبار مقاييس النسبة؟ بالنسبة لاختبار T ، يجب أن تكون قادرًا على قراءة تباين العينة ، وبالنسبة للميغاواط ، يجب أن تكون العينة "معرفة من قبل المستخدم".
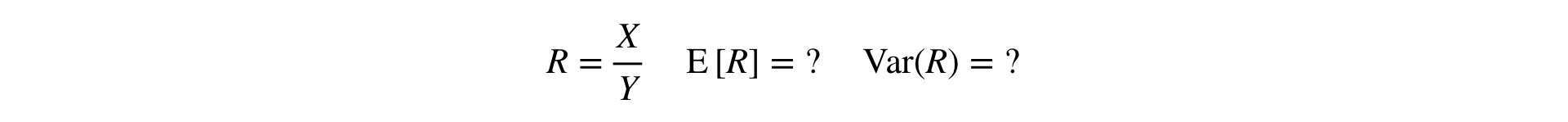
الإجابة: تحتاج إلى توسيع نسبة في سلسلة تايلور إلى الدرجة الأولى عند نقطة :
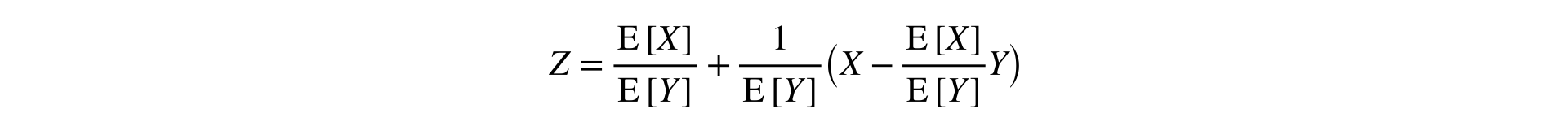
تحول هذه الصيغة عينتين (البسط والمقام) إلى واحدة ، مع الحفاظ على الوسط والتباين (غير متناظرين) ، مما يسمح باستخدام الإحصائيات الكلاسيكية. الاختبارات.
هناك فكرة مماثلة يطلق عليها زملاؤهم في ياندكس طريقة خط النسبة (الظهور لمرة واحدة والمرتين ).
تحجيم الأداء
باستخدام سريع ل stat stat. تجعل المعايير من الممكن تنفيذ ملايين التكرارات (مقارنات المعالجة مقابل التحكم) في دقائق على خادم عادي تمامًا يحتوي على 56 مركزًا. ولكن في حالة وجود كميات كبيرة من البيانات ، فإن الأداء يعتمد أولاً على التخزين وقراءة الوقت من القرص.
يؤدي حساب مقاييس Uid يوميًا إلى إنشاء عينات بحجم إجمالي يبلغ مئات المليارات من القيم (بسبب العدد الكبير من التجارب المتزامنة ، ومئات المقاييس والتراكم التراكمي). من الصعب للغاية إخراج مثل هذه الكميات من القرص كل يوم (على الرغم من الكتلة الكبيرة لقاعدة عمود Vertica). لذلك ، نحن مضطرون للحد من أصل البيانات. لكننا نقوم بذلك تقريبًا دون فقدان المعلومات حول التباين باستخدام تقنية تسمى "الجرافة".
الفكرة بسيطة: لدينا Uid و ، وفقا لبقية التقسيم ، "نثرهم" في عدد من الجرافات (نشير إلى عددهم ب):
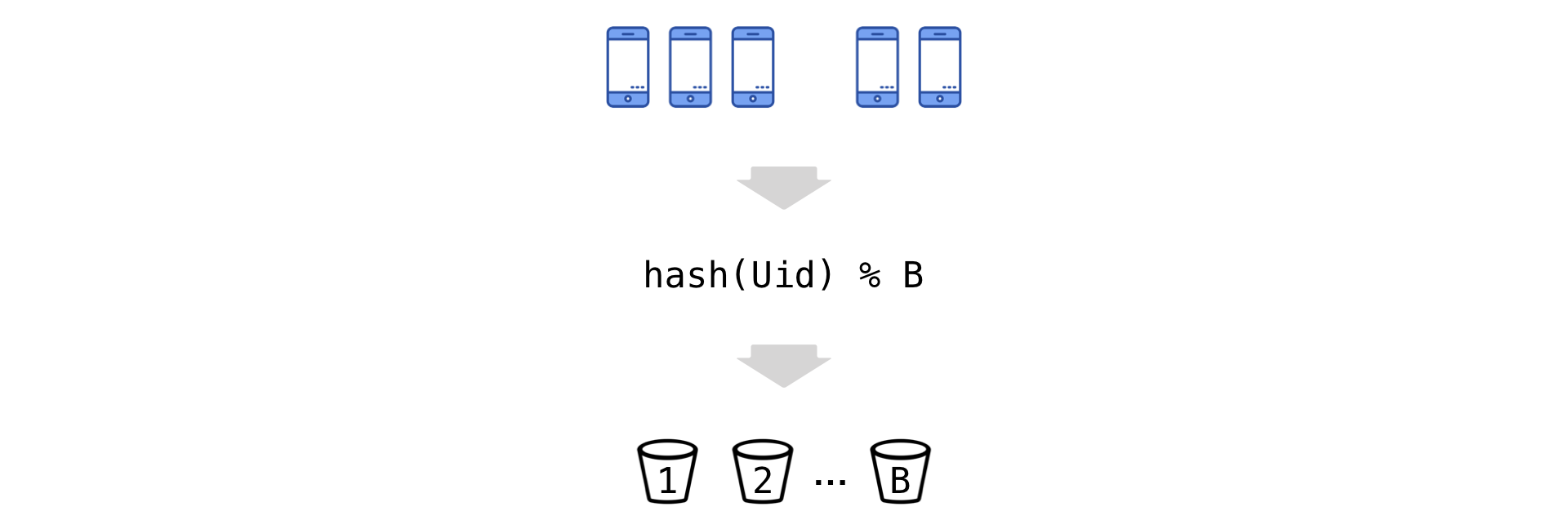
الآن ننتقل إلى الوحدة التجريبية الجديدة - الدلو. نلخص الملاحظات في المجموعة (البسط والمقام مستقلان):

مع هذا التحول ، يتم استيفاء شرط استقلالية الملاحظات ، ولا تتغير القيمة المترية ، ومن السهل التحقق من الحفاظ على تباين القياس (المتوسط على عينة من الملاحظات):

كلما زاد عدد الجرافات ، قلت المعلومات المفقودة ، وأصغر خطأ في المساواة. في Avito ، نأخذ B = 200.
كثافة التوزيع المترية بعد تحويل الجرافة تصبح دائمًا مشابهة للعادي.
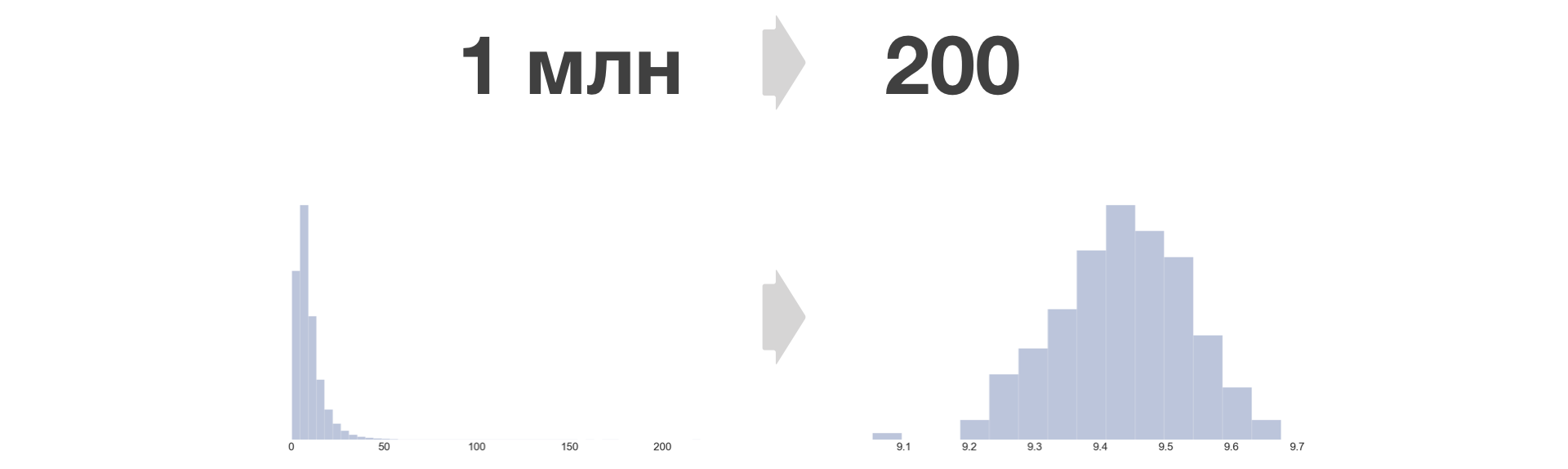
يمكن تقليل عدد العينات الكبيرة التي تريدها إلى حجم ثابت. يعتمد نمو حجم البيانات المخزنة في هذه الحالة بشكل خطي فقط على عدد التجارب والمقاييس.
نتائج التصور
كأداة للتصور ، نستخدم Tableau و webview على خادم Tableau. كل موظف Avito لديه حق الوصول إلى هناك. تجدر الإشارة إلى أن Tableau يؤدي المهمة بشكل جيد. إن تنفيذ حل مشابه باستخدام تطوير كامل للظهر / الأمام سيكون مهمة تتطلب الكثير من الموارد.
نتائج كل تجربة هي ورقة من عدة آلاف من الأرقام. يجب أن يكون التصور مثل تقليل الاستنتاجات غير الصحيحة في حالة تنفيذ الأخطاء من النوع الأول والثاني ، وفي نفس الوقت عدم "تفويت" التغييرات في المقاييس والأقسام المهمة.
أولاً ، نراقب مقاييس "الصحة" للتجارب. بمعنى ، نحن نجيب على الأسئلة: "هل صحيح أن المشاركين" سكبوا "في كل مجموعة من المجموعات؟" ، "هل تساوي المستخدمين المصرح لهم أو الجدد؟"
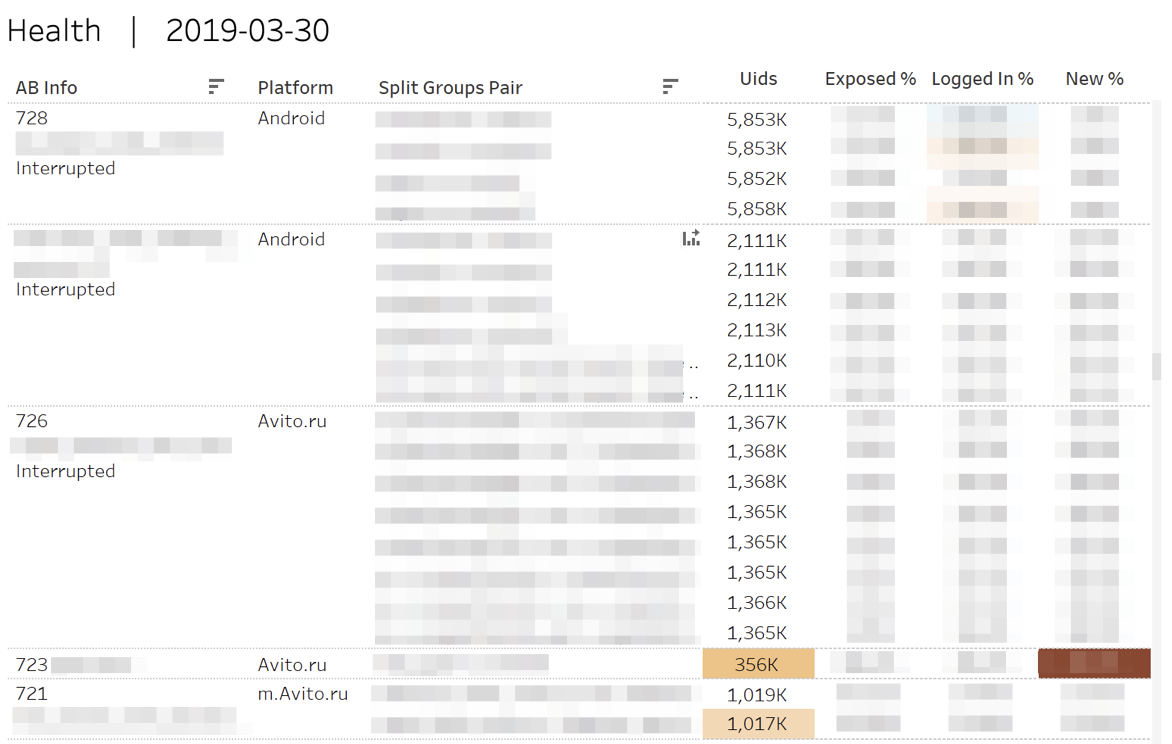
في حالة الانحرافات الإحصائية المهمة ، يتم تسليط الضوء على الخلايا المقابلة. عند التمرير فوق أي رقم ، يتم عرض الديناميات التراكمية لليوم.
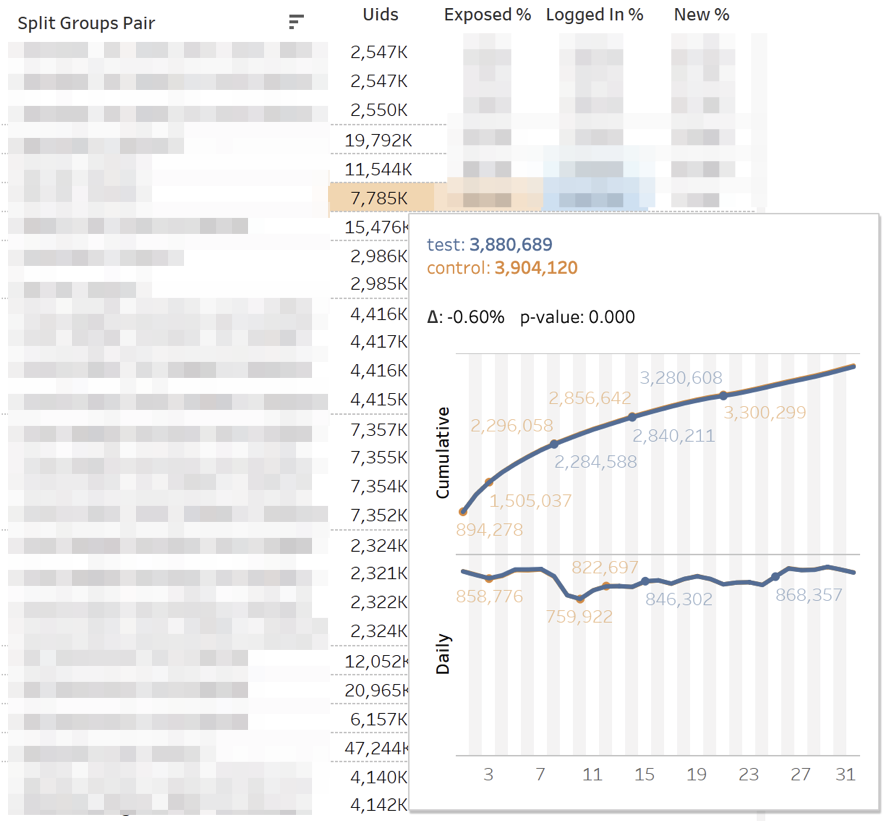
تبدو لوحة القيادة الرئيسية ذات المقاييس كما يلي:
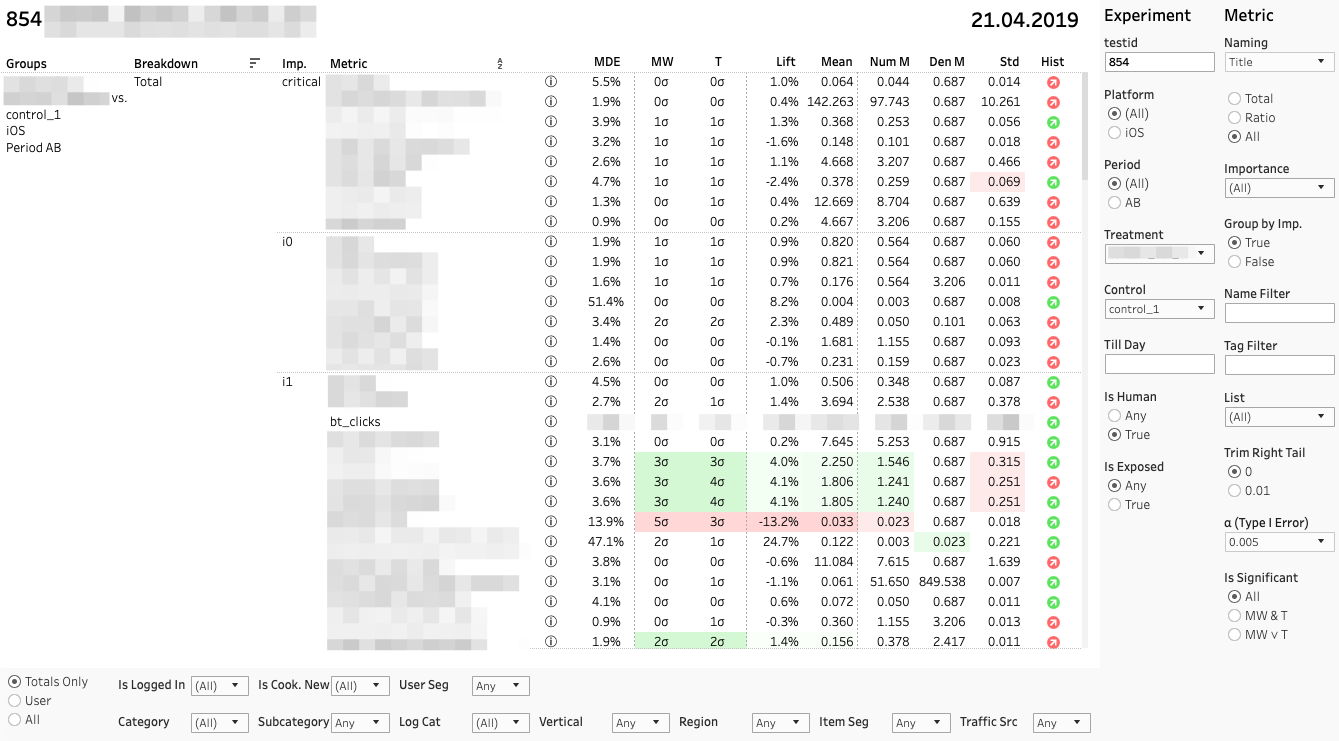
كل صف عبارة عن مقارنة بين المجموعات بواسطة مقياس معين في قسم معين. على اليمين لوحة مع مرشحات للتجارب والمقاييس. لوحة مرشح القسم السفلي.
تتكون كل مقارنة متري من عدة مقاييس. دعنا نحلل قيمهم من اليسار إلى اليمين:
1. MDE. الحد الأدنى للاكتشاف تأثير

⍺ و β هما احتمال خطأ محدد مسبقًا من النوع الأول والثاني. يعد MDE مهمًا للغاية إذا كان التغيير غير مهم من الناحية الإحصائية. عند اتخاذ قرار ، يجب أن يتذكر العميل عدم وجود القانون الأساسي. أهمية ليست بمثابة أي تأثير. موثوق بما فيه الكفاية ، يمكننا أن نقول فقط أن التأثير المحتمل ليس أكثر من MDE.
2. ميغاواط | T. مان ويتني U- و T- نتائج الاختبار
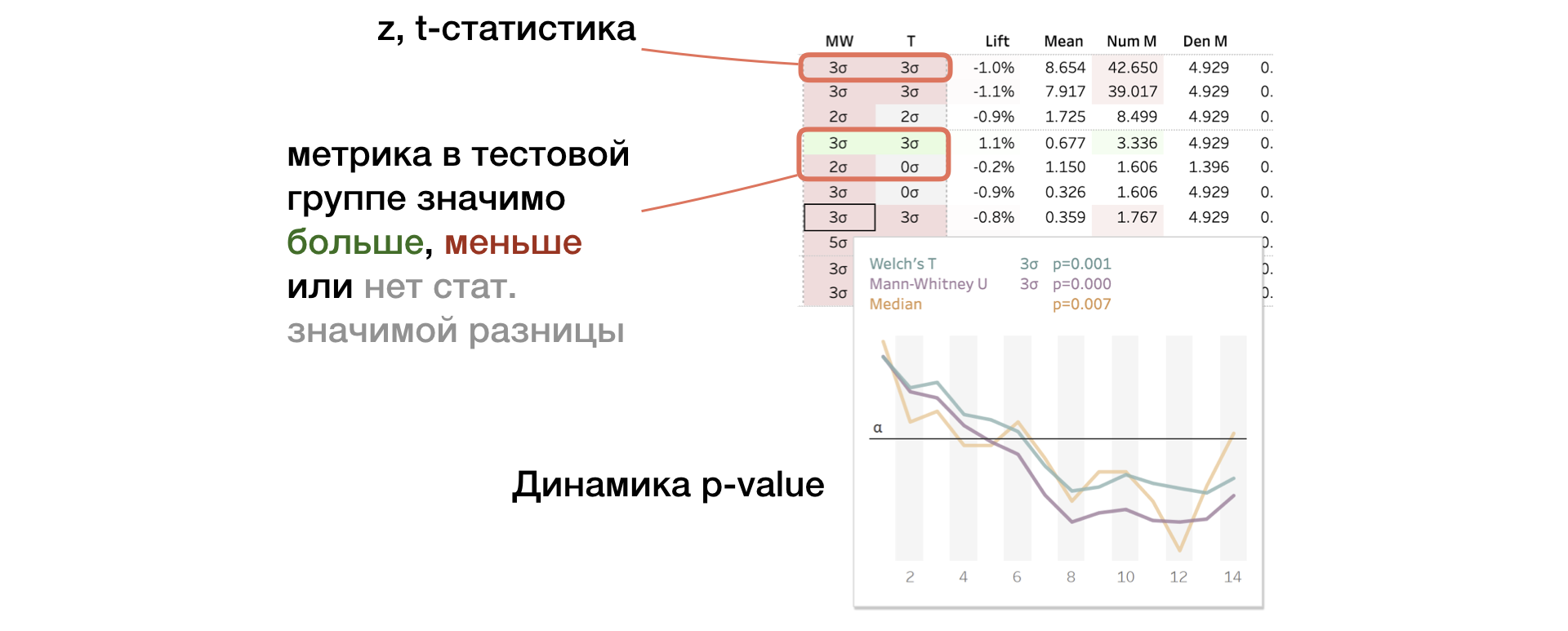
تعرض اللوحة قيمة الإحصاء z و t (بالنسبة إلى MW و T ، على التوالي). في تلميح الأدوات - ديناميات ف القيمة. إذا كان التغيير كبيرًا ، فسيتم تمييز الخلية باللون الأحمر أو الأخضر ، اعتمادًا على علامة الفرق بين المجموعتين. في هذه الحالة ، نقول أن المقياس "ملون".
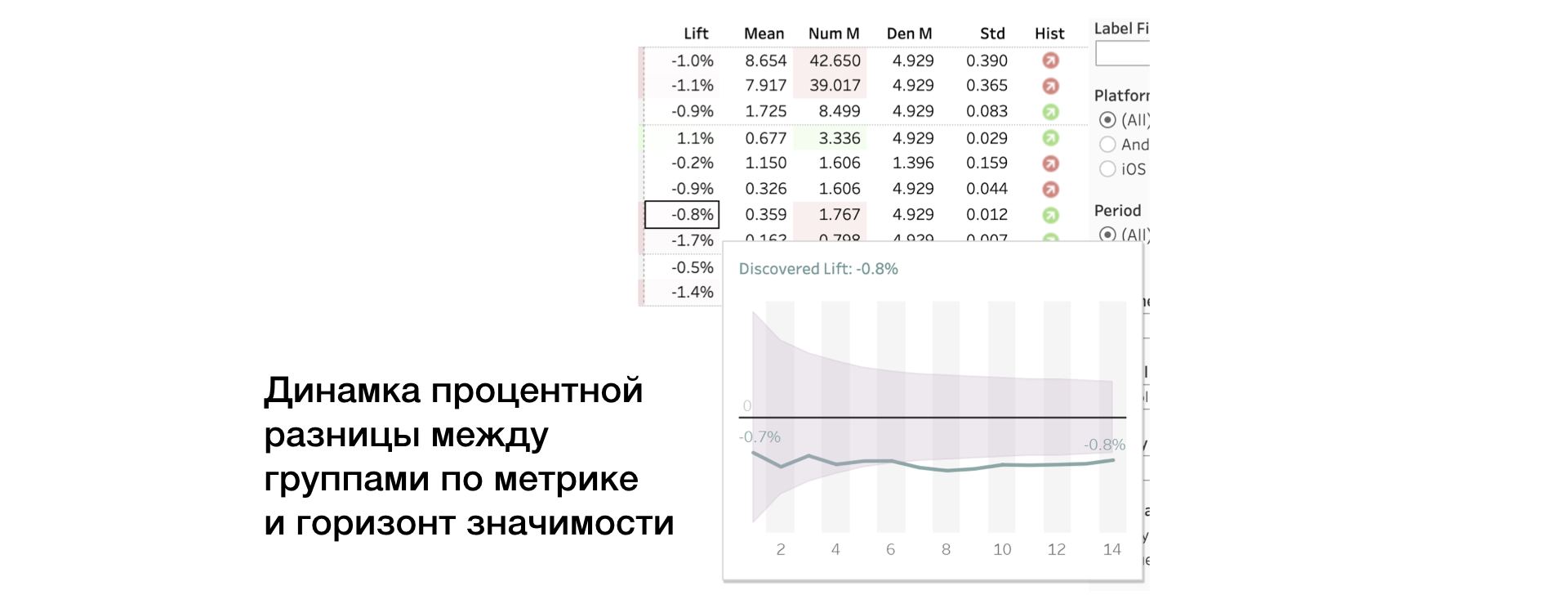
3. ارفع. نسبة الفرق بين المجموعات
4. يعني | Num | دن. القيمة المترية ، وكذلك البسط والمقام بشكل منفصل
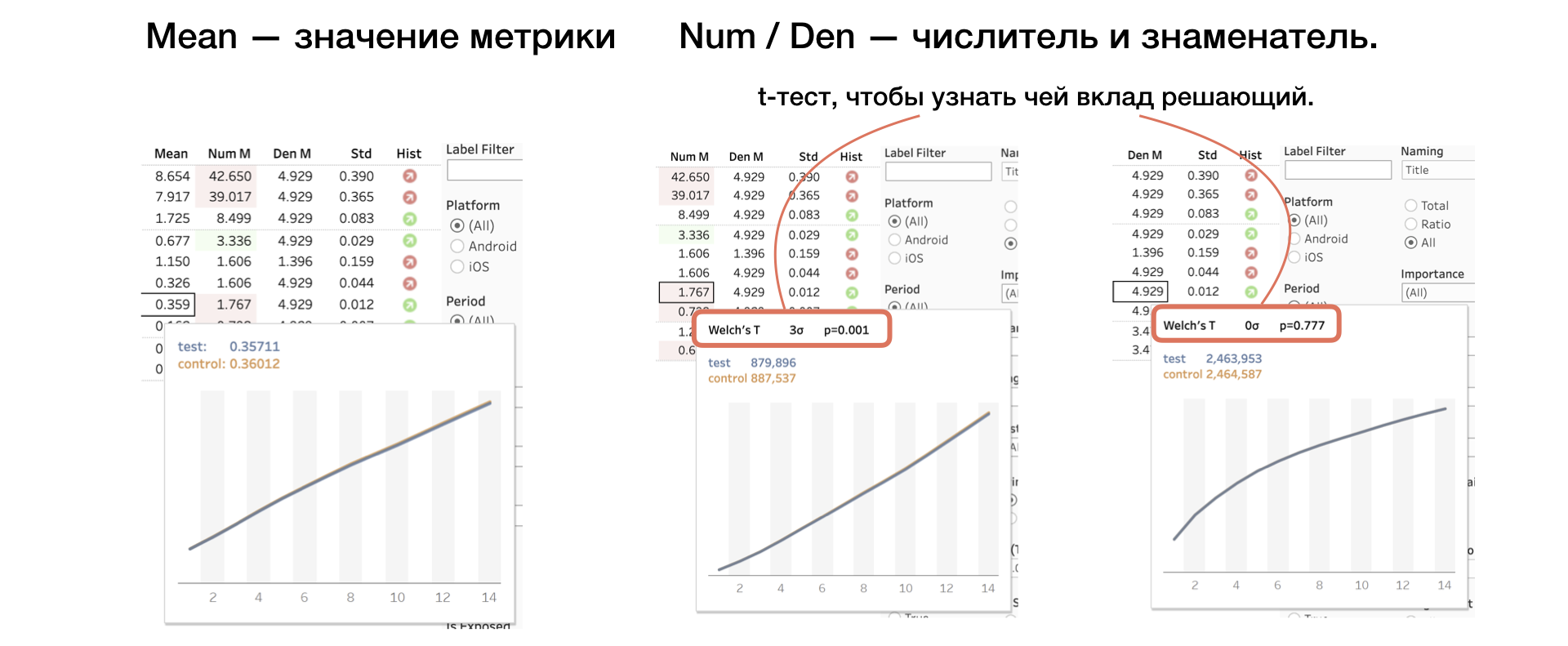
نحن نطبق اختبار T آخر على البسط والمقام ، مما يساعد على فهم من الذي له أهمية حاسمة.
5. الأمراض المنقولة جنسيا. الانحراف المعياري الانتقائي
6. اصمت. اختبار Shapiro-Wilk لمعرفة الحالة الطبيعية لتوزيع "الجرافة".
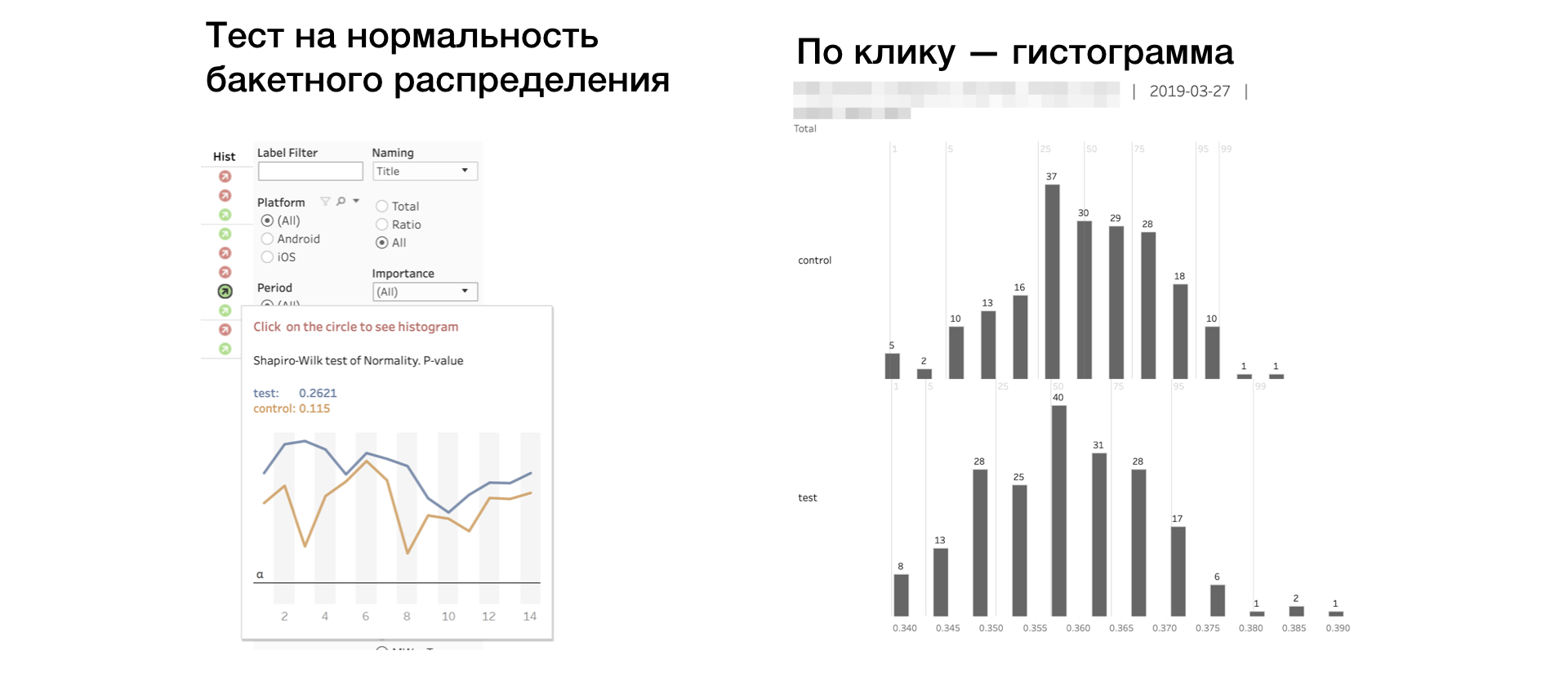
إذا كان المؤشر باللون الأحمر ، فربما يكون للعينة القيم المتطرفة أو الذيل الطويل بشكل غير طبيعي. في هذه الحالة ، يجب أن تأخذ النتيجة وفقًا لهذا المقياس بعناية ، أو لا تأخذ على الإطلاق. يؤدي النقر فوق المؤشر إلى فتح الرسم البياني للقياس حسب المجموعة. يوضح الرسم البياني بوضوح الحالات الشاذة - من الأسهل استخلاص النتائج.
استنتاج
ظهور منصة A / B في Avito هو نقطة تحول عندما بدأ منتجنا في النمو بشكل أسرع. كل يوم ، نقوم بإجراء تجارب خضراء تشحن الفريق ؛ و "الحمر" ، والتي توفر الغذاء الصحي للتفكير.
تمكنا من بناء نظام فعال لاختبار A / B والمقاييس. غالبًا ما نحل المشكلات المعقدة بطرق بسيطة. نظرًا لهذه البساطة ، تتمتع البنية التحتية بهامش أمان جيد.
أنا متأكد من أن أولئك الذين سوف يبنون منصة A / B في شركتهم وجدوا بعض الأفكار المثيرة للاهتمام في المقال. يسرني أن أشارككم تجربتنا.
اكتب الأسئلة والتعليقات - سنحاول الإجابة عليها.