
هل أنت على دراية بموقف تقضي فيه وقتًا هائلاً في اختيار فيلم مشابه للوقت الذي شاهدته فيه؟ بالنسبة لمستخدمي دور السينما على الإنترنت ، هذه مشكلة شائعة ، وبالنسبة إلى دور السينما نفسها - الأرباح المفقودة.
لحسن الحظ ، لدينا Rekko - نظام من التوصيات الشخصية التي ساعدت مستخدمي Okko بنجاح لمدة عام في اختيار الأفلام والمسلسلات من أكثر من عشرة آلاف وحدة من المحتوى. سوف أخبرك في المقال كيف يتم الترتيب من وجهة النظر الحسابية والتقنية ، وكيف نتعامل مع تطويره وكيف نقيم النتائج. حسنًا ، سوف أخبرك أيضًا بنتائج اختبار A / B السنوي.
أولا ، القليل من التاريخ. بدأت Okko وجودها في عام 2011 كجزء من Iota ، بدءًا من اسم Yota Play.
بالفعل في عام 2011 ، قبل المستخدمون بحماس فكرة مشاهدة فيلم بشكل قانوني على الإنترنت كانت Yota Play خدمة فريدة من نوعها في وقتها: فهي تتكامل بشكل وثيق مع الشبكات الاجتماعية وتستخدم المعلومات حول الأفلام التي يشاهدها ويصنفها الأصدقاء في العديد من أجزاء الخدمة ، بما في ذلك التوصيات.

في عام 2012 ، تقرر استكمال التوصيات الاجتماعية مع تلك الخوارزمية. هكذا ظهر "Oracle" - أول نظام توصية للسينما الإلكترونية Okko. فيما يلي بعض المقتطفات من مستند التصميم الخاص به:
تم استخدام نهج مماثل في نظام تنفيذ التوصيات الشخصية. يتم استخدام مقياس المستويات من "لا شيء" (الفراغ ، الغياب) إلى "كل شيء" (بالكامل ، الحد الأقصى). في النطاق [127 .. + 127] 0 - هو الوسط أو "القاعدة". على هذا النطاق ، يتم أيضًا تقييم درجة التعاطف مع الشخصية الرئيسية والسعر الشخصي للمنتج ودرجة اللون "الأحمر". على سبيل المثال ، يقدر حجم الكون بـ +127 (على مقياس الأبعاد) ، ويقدر الظلام بـ 127 (على مقياس شدة الضوء).
عند تقديم التوصيات ، من المهم ليس فقط الخلفية ، ولكن أيضًا طبيعة المستخدم المعين. يحتوي ملف التعريف الشخصي أيضًا على 4 مقاييس لأنواع الشخصيات (وفقًا لـ K. Leonhard - إثبات ، مذعور ، عالق ، مثير).
لا تعتمد الحدود الفسيولوجية للدماغ على خصائص شخصية الشخص وعلى مدى كونه ودودًا ومؤنسًا. وفقا للأستاذ ، توجد قيود في القشرة المخية الحديثة ، القسم المسؤول عن الأفكار الواعية والكلام. ويؤخذ هذا التقييد أيضًا في الاعتبار في النظام المُطبَّق ، خاصةً عند وضع توصيات لنوع متعصب من الشخصية وعند تشكيل عينة من هؤلاء المستخدمين بين الروابط الاجتماعية.

كما فهمت بالفعل ، كانت الأوقات برية ، ولم تقتصر الحدود الفسيولوجية للدماغ على أي شيء ، ويمكن للقشرة الدماغية الجديدة فيركلوك نفسها أن تنتج توصيات شخصية بسرعة الضوء. لذلك ، فقد تقرر أن النموذج على الفور إلى الإنتاج.
بقدر ما يمكن للمرء أن يحكم من القطع الأثرية المتبقية للحضارة القديمة ، كان "أوراكل" مزيجًا بريًا من خوارزميات التصفية التعاونية ، متمرسًا بسخاء مع قواعد العمل.

بحلول منتصف عام 2013 ، بدأ الجميع بالتخلي قليلاً وقررت أخيرًا التحقق من جودة آلة التوصية. للقيام بذلك ، تم إطلاق محرر مُدرَّب خصيصًا تملؤه الأقسام الرئيسية للتطبيق واختبار A / B: رأى نصف المستخدمين مخرجات الخوارزمية ، ونصفها - اختيار المحرر.
نحن الآن نقرأ مقالات عن الانتصارات القادمة للذكاء الاصطناعي ومع الرعب تخيل اليوم الذي سيخسر فيه عملنا. بعد ذلك ، في عام 2013 ، كان الوضع مختلفًا: فقد هزم الشخص ببطولة السيارة ، وخلق المزيد من الوظائف في قسم المحتوى. تم إيقاف تشغيل Oracle ولم يتم تشغيله مرة أخرى. قريباً ، اختفت جميع الشرائح الاجتماعية ، وتحولت Yota Play إلى Okko.
تميزت الفترة من 2013 إلى 2016 بـ "شتاء" الذكاء الاصطناعي والحكم الشمولي لإدارة المحتوى: لم تكن هناك توصيات شخصية في الخدمة.
بحلول منتصف عام 2017 ، أصبح من الواضح أنه لا يمكنك العيش مثل هذا بعد الآن. كانت نجاحات Netflix معروفة للجميع ، وكانت الصناعة بأكملها تسير بخطى سريعة نحو التخصيص. لم يعد المستخدمون مهتمين بالخدمات الثابتة "الغبية" ، فقد بدأوا بالفعل في التعود على الواجهات "الذكية" ، فهمهم تمامًا والتنبؤ بكل رغباتهم.
كالتكرار الأول ، قررنا الاندماج مع اثنين من كبار الموردين الروس للتوصيات. مرة واحدة في اليوم ، أخذت كلتا الخدمتين البيانات اللازمة من Okko ، وسرعت بصناديقها السوداء على خوادم بعيدة وتحميل النتائج.
وفقا لنتائج اختبار A / B لمدة ستة أشهر ، لم يتم العثور على فروق ذات دلالة إحصائية في مجموعات المراقبة والاختبار.
في نهاية اختبار A / B هذا ، جئت إلى Okko للبدء في جعل الخدمة شخصية حقيقية مع رئيس التحليلات ، ميخائيل أليكسييف ( malekseev ). بعد أقل من عام ، انضم إلينا دانيل كازاكوف ( xaph ) ، وأخيراً شكل الفريق الحالي.
اعتبارات عامة
عندما تبرز أمامك مشكلة العمل التي درسها المجتمع الدولي منذ فترة طويلة والتي ، علاوة على ذلك ، تحتاج إلى حلها بسرعة ، فمن المغري أن تأخذ أول حل للشبكة العصبية العميقة الشعبية التي لديك ، وتدفع البيانات إليها بمجرفة ، وتدخلها في المنتج.

الشيء الرئيسي هو عدم الخضوع لهذا الإغراء. مهمة المجتمع العلمي - لتحقيق أقصى سرعة على مجموعات البيانات الفاسدة والتركيبية - لا تتزامن في الغالب مع مهمة العمل - لكسب المزيد من المال ، بينما تنفق موارد أقل.

لا ، هذا لا يعني أنك لا تحتاج إلى شبكات متكررة ، ويمكنك جمع المليارات باستخدام طريقة k المجاورة. قد يتضح فقط أن تحليل المصفوفة الكلاسيكية في بياناتك سيسمح لك بكسب 100 مليون شرطية إضافية في السنة ، وشبكات متكررة - 105 مليون في السنة. في الوقت نفسه ، ستكلف صيانة مجموعة من الخوادم التي تحمل بطاقات فيديو لهذه الشبكات نفسها 10 ملايين سنويًا وتتطلب عدة أشهر إضافية للتطوير والتنفيذ ، وسيتطلب الدمج البسيط لتحلل المصفوفة الجاهزة في قسم آخر من الخدمة وقائمة البريد شهرًا من التحسينات وسيمنح 100 مليون شرطية أخرى في السنة.
لذلك ، من المهم أن تبدأ بالأساسيات - الأساليب الأساسية التي أثبتت جدواها - والتقدم نحو مناهج أكثر حداثة ، وتأكد من قياس وتوقع التأثير الذي ستحدثه كل طريقة جديدة على الأعمال التجارية ، ومقدار التكلفة التي ستكسبها والمقدار الذي ستتيح لك تحقيقه.
Okko يمكن قياس جيدا. حرفيًا ، يتم فحص كل ميزة جديدة ، كل ابتكار لدينا من خلال اختبار A / B ، في سياق مجموعة متنوعة من مجموعات المستخدمين ، ويتم فحص الآثار بحثًا عن دلالة إحصائية وفقط بعد ذلك يتم اتخاذ قرار بشأن قبول الوظيفة الجديدة أو رفضها.

على سبيل المثال ، تقارن لوحة معلومات Rekko الحالية بين مجموعات التحكم والاختبار لأكثر من 50 مقياسًا ، بما في ذلك الإيرادات ، والوقت الذي تقضيه في الخدمة ، ووقت اختيار الفيلم ، وعدد مرات المشاهدة عن طريق الاشتراك ، وتحويل الشراء ، والتجديد التلقائي ، وغيرها الكثير. ونعم ، ما زلنا نحتفظ بمجموعة صغيرة من المستخدمين الذين لم يتلقوا أبدًا توصيات مخصصة (آسف).

حول أنظمة التوصية
لتبدأ ، مقدمة صغيرة لأنظمة التوصية.
الهدف من نظام التوصية هو لكل مستخدم في قصته من التفاعل مع العناصر لبناء علاقة ترتيب على مجموعة من جميع العناصر. هذا يعني هذا: بغض النظر عن عنصرين اعتباطيين نتخذهما ، يمكننا دائمًا تحديد أيهما أفضل للمستخدم ، وأيهما أقل.
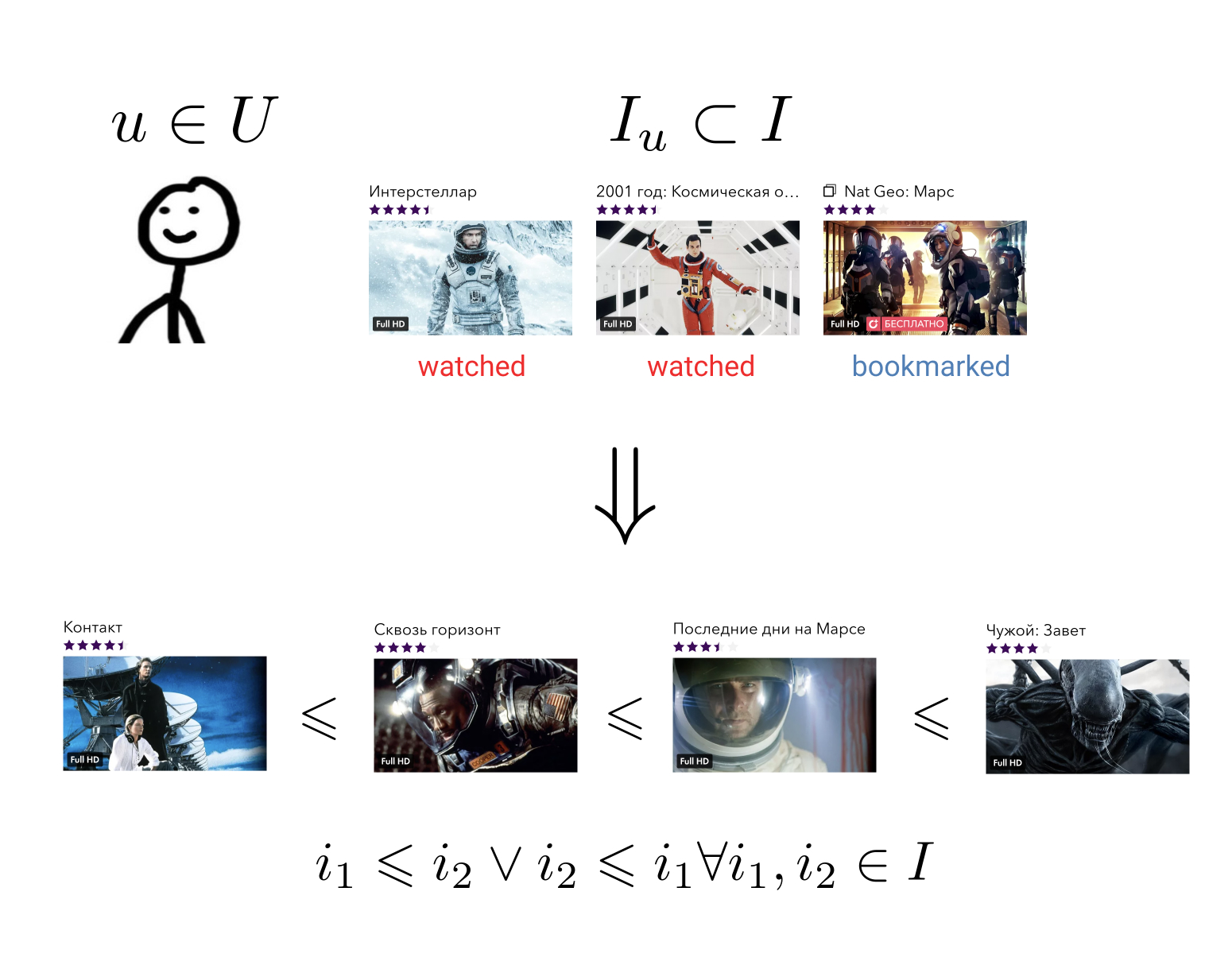
يمكن اختزال هذه المهمة العامة إلى مهمة أكثر بساطة: عناصر الخريطة إلى مجموعة محددة بالفعل علاقة الطلب. على سبيل المثال ، على مجموعة من الأرقام الحقيقية. في هذه الحالة ، من الضروري لكل مستخدم ولكل عنصر أن يتمكن من التنبؤ بقيمة معينة - إلى أي مدى يفضل هذا المستخدم هذا العنصر.

بوجود علاقة ترتيب على عناصرنا ، يمكننا حل العديد من مشكلات العمل ، على سبيل المثال ، يمكنك الاختيار من بين جميع العناصر N الأكثر صلة بالمستخدم أو فرز نتائج البحث وفقًا لتفضيلاته.
من الناحية المثالية ، نحتاج إلى مجموعة كاملة من علاقات الطلب الحساسة للسياق. إذا دخل المستخدم إلى مجموعة "Action" ، فمن المرجح أنه يفضل فيلم "Destroyer" على فيلم "Oscar" ، ولكن في مجموعة "Films with Sylvester Stallone" ، قد يكون التفضيل هو عكس ذلك. يمكن تقديم أمثلة مماثلة ليوم الأسبوع أو الوقت من اليوم أو الجهاز الذي دخل المستخدم من الخدمة إليه.

تقليديًا ، يتم تقسيم جميع طرق إنشاء التوصيات الشخصية إلى ثلاث مجموعات كبيرة: التصفية التعاونية (CF) ، ونماذج المحتوى (نماذج المحتوى ، CM) والنماذج الهجينة التي تجمع بين أول طريقتين.
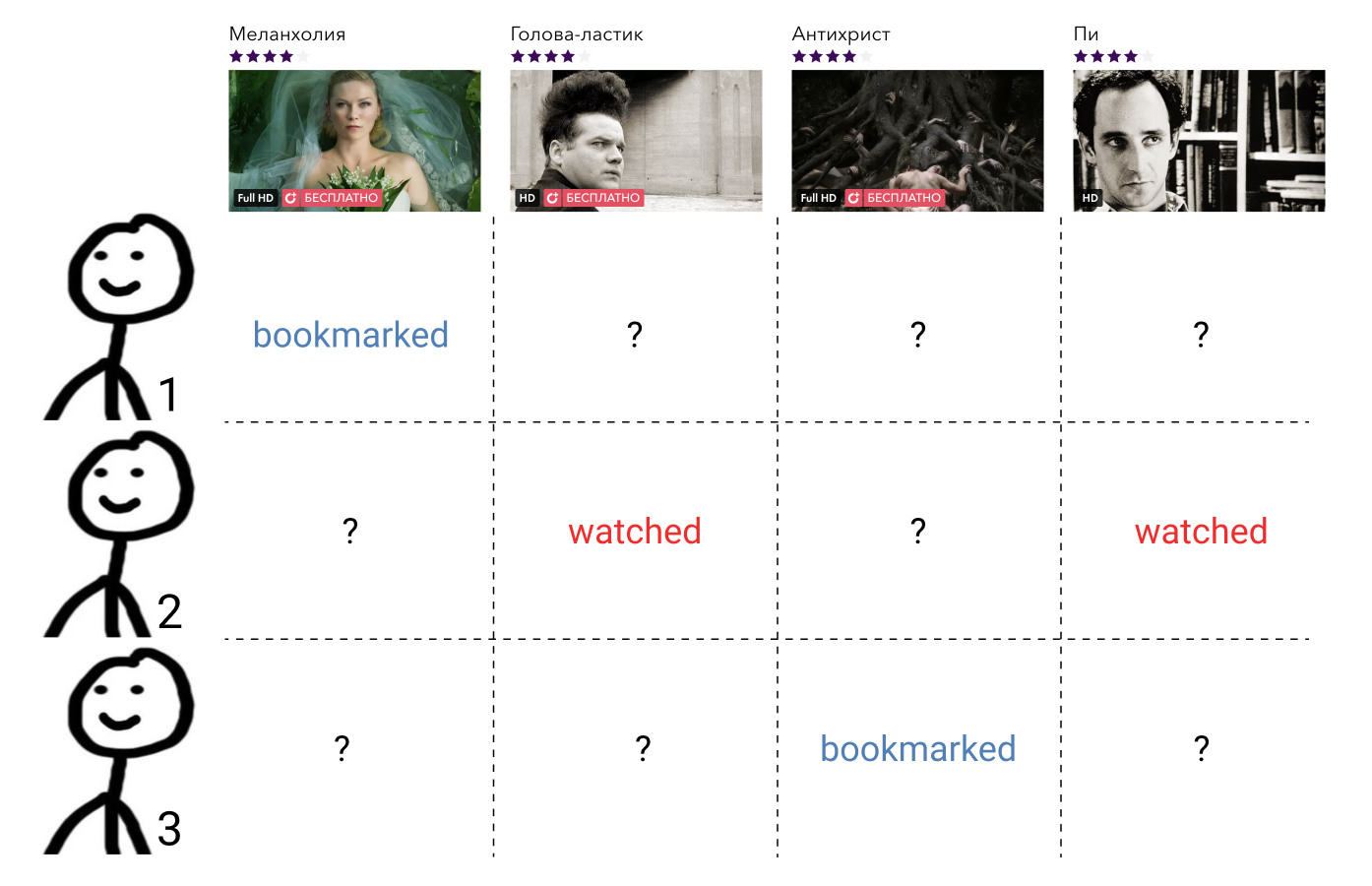
تستخدم أساليب التصفية التعاونية معلومات حول تفاعلات جميع المستخدمين وجميع العناصر. يتم تقديم هذه المعلومات ، كقاعدة عامة ، في شكل مصفوفة متفرق ، حيث تتوافق الصفوف مع المستخدمين ، والأعمدة للعناصر ، ويحتوي المستخدم والعنصر على القيمة التي تميز التفاعل بينهما ، أو وجود فجوة إذا لم يكن هناك مثل هذا التفاعل. مهمة بناء علاقة ترتيب هنا تقلل من مهمة ملء عناصر المصفوفة المفقودة.
هذه الطرق ، كقاعدة عامة ، سهلة الفهم والتنفيذ ، سريعة ، ولكن لا تظهر أفضل نتيجة.
نماذج المحتوى - طرق تعلم الآلة التعسفي لحل مشاكل التصنيف أو الانحدار ، والمعلمة بمجموعة معينة من المعلمات . عند المدخل ، يقبلون سمات المستخدم وخصائص العنصر ، والإخراج هو درجة ملاءمة العنصر المحدد لهذا المستخدم. لا يتم تدريس هذه النماذج على تفاعلات جميع المستخدمين وجميع العناصر ، مثل أساليب التصفية التعاونية ، ولكن فقط على السوابق الفردية.

مثل هذه النماذج ، كقاعدة عامة ، أكثر دقة بكثير من أساليب التصفية التعاونية ، لكنها أبطأ بكثير في السرعة. تخيل لو كان لدينا وظيفة ذات شكل عام يقبل علامات المستخدمين والعناصر كمدخل ، ثم يجب أن يسمى لكل زوج . في حالة ألف مستخدم وعشرة آلاف عنصر ، فهذه عبارة عن مليون مكالمة.
تجمع النماذج الهجينة نقاط القوة في كلا النهجين ، وتقدم توصيات الجودة في فترة زمنية معقولة.
النهج الأكثر شعبية المختلط اليوم هو بنية من مستويين ، حيث يختار نموذج التصفية التعاونية عددًا صغيرًا (100 - 1000) من المرشحين من جميع العناصر الممكنة ، والتي يتم تصنيفها بعد ذلك بواسطة نموذج محتوى أكثر قوة. في بعض الأحيان يمكن أن يكون هناك العديد من هذه المراحل لاختيار المرشحين ويستخدم نموذج متزايد التعقيد في كل مستوى جديد.

هذه الهندسة لديها العديد من المزايا:
- الأجزاء التعاونية والمحتوى ليست مترابطة ويمكن تدريبها بشكل منفصل بترددات مختلفة ؛
- الجودة دائماً أفضل من النموذج التعاوني بشكل منفصل ؛
- السرعة أعلى بكثير من نموذج المحتوى بشكل منفصل ؛
- "مجاني" نحصل على المتجهات من نموذج تعاوني ، والذي يمكن استخدامه لحل المشكلات ذات الصلة.
إذا تحدثنا عن تقنيات محددة ، فهناك الكثير من المجموعات الممكنة.
كجزء تعاوني ، يمكنك الحصول على اشتراكات المستخدم ، والمحتوى الشائع ، والمحتوى الشائع بين أصدقاء المستخدم ، ويمكنك تطبيق مصفوفة أو عامل توتر ، وتدريب DSSM أو أي طريقة أخرى مع التنبؤ السريع إلى حد ما.
كنموذج للمحتوى ، يمكن استخدام أي نهج بشكل عام ، من الانحدار الخطي إلى الشبكات العميقة.
في Okko ، نركز حاليًا على مزيج من عوامل المصفوفة مع فقدان WARP والتدرج اللوني على الأشجار ، والتي سأناقشها الآن بالتفصيل.
المرحلة الأولى: اختيار المرشحين
أعتقد أنني لا أكذب إذا قلت إن خوارزميات عامل المصفوفة هي أكثر الطرق شيوعًا للتصفية التعاونية. يتضح جوهر الطريقة من الاسم: نحن نحاول تقديم المصفوفة التي سبق ذكرها لتفاعلات المستخدم مع المحتوى من خلال ناتج مصفوفتين من الرتبة الأدنى ، أحدهما سيكون "مصفوفة مستخدم" والآخر "مصفوفة عناصر". مع هذا التحلل ، يمكننا استعادة المصفوفة الأصلية جنبا إلى جنب مع جميع القيم المفقودة.

في هذه الحالة ، بالطبع ، نحن أحرار في اختيار معيار لتشابه المصفوفات المتاحة والمستعادة. أبسط معيار هو الانحراف المعياري.
سمح - صف مصفوفة المستخدم المقابلة للمستخدم و - عمود مصفوفة العنصر المقابلة للعنصر . ثم ، عند ضرب المصفوفات ، منتجهم يعني حجم التفاعل المقصود بين المستخدم المعطى والعنصر. الآن حساب الانحراف المعياري بين هذه الكمية والقيمة المبدئية المعروفة للتفاعل لجميع أزواج من تفاعل المستخدمين والعناصر ، نحصل على وظيفة الخسارة التي يمكن التقليل منها.
كقاعدة عامة ، لا يزال يضاف إلى تنظيم.
مثل هذه المشكلة ليست محدبة ومعقدة NP. ومع ذلك ، فمن السهل أن تلاحظ أنه عند إصلاح إحدى المصفوفات ، تتحول المهمة إلى انحدار خطي بالنسبة للمصفوفة الثانية ، مما يعني أنه يمكننا البحث عن حل تكراري ، أو تجميد بالتناوب إما مصفوفة المستخدم أو مصفوفة العناصر. يسمى هذا النهج بالتناوب المربعات الصغرى (ALS).

الإضافة الرئيسية لـ ALS هي السرعة والقدرة على التوازي بسهولة. لهذا ، فهو محبوب للغاية في Yandex.Zen و Vkontakte ، حيث يبلغ عدد المستخدمين والعناصر في عشرات الملايين.
ومع ذلك ، إذا كنا نتحدث عن كمية البيانات التي تناسبها على جهاز واحد ، فإن ALS لا تصمد أمام النقد. مشكلته الرئيسية هي أنه يحسن وظيفة الخسارة الخاطئة. تذكر صياغة مهمة بناء نظام التوصية. نريد أن نحصل على علاقة الطلب في المجموعة ، وبدلاً من ذلك نحسن الانحراف المعياري.
من السهل إعطاء مثال على مصفوفة يكون الانحراف المعياري بها ضئيلًا للغاية ، لكن ترتيب العناصر يائس.
دعونا نرى ما يمكننا القيام به حيال ذلك. في رأس المستخدم ، يتم ترتيب جميع العناصر التي تفاعل معها بترتيب معين. على سبيل المثال ، يعرف على وجه اليقين أن Interstellar أفضل من Gravity و Gravity و Alien هي أفلام جيدة على قدم المساواة ، وكلها أسوأ قليلاً من Terminator. في الوقت نفسه ، يواجه أيضًا موقفًا معينًا من الأفلام التي لم يشاهدها المستخدم بعد ، وكذلك الأمر بالنسبة للجميع. قد يعتقد أن مثل هذه الأفلام بدائية أسوأ من تلك الأفلام التي شاهدها. أو ربما يعتبر ذلك ، على سبيل المثال ، فيلم Prometheus فيلمًا سيئًا ، وأي فيلم لم يشاهده بعد سيكون أفضل منه.
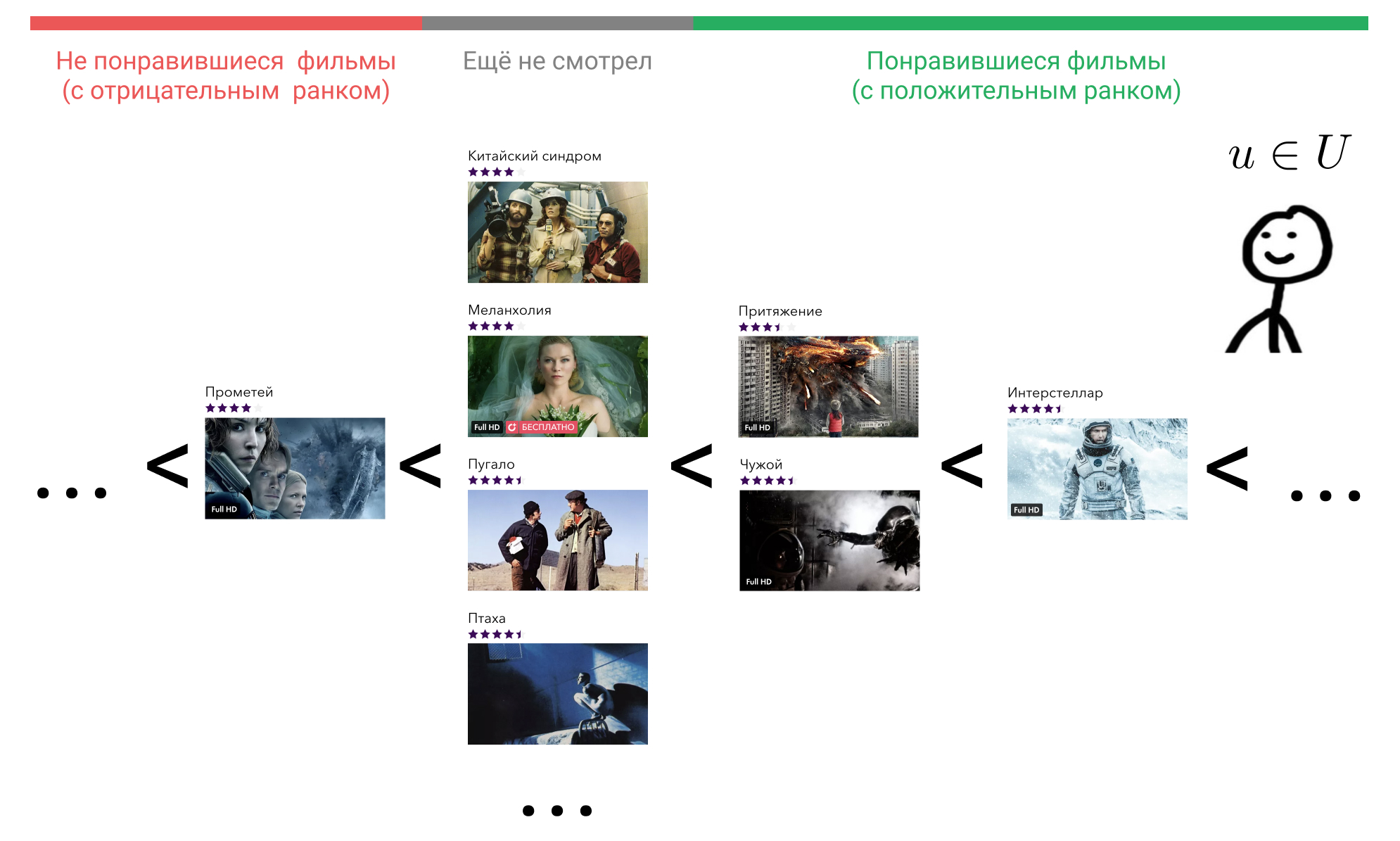
تخيل أنه وفقًا لبعض علامات سلوك المستخدم في الخدمة ، يمكننا استعادة هذا الترتيب من خلال عرض العنصر الذي تفاعلت به ، في عدد صحيح يستخدم الوظيفة . العديد من الأفلام التي المستخدم تفاعلت ، تشير إلى . نحن نتفق على ذلك إذا لم يتفاعل المستخدم مع الفيلم هذا هو . وبالتالي ، إذا اعتبر المستخدم الفيلم سيئًا ، إذن ، وإذا كان جيدا ، ثم .

الآن يمكننا إدخال رتبة .
هنا يدل على وظيفة المؤشر ويساوي الوحدة إذا صحيح والصفر خلاف ذلك.
دعنا نتوقف لمدة دقيقة ونفكر فيما يعنيه هذا الترتيب.
نحن إصلاح المستخدم ، هذا هو بعض المستخدمين محددة ، أي واحد - نحن لسنا مهتمين. وفقا لذلك ، ناقلاتها سوف تكون ثابتة.
خذ الآن أي فيلم شاهده ، على سبيل المثال ، بين النجوم. في الصيغة ، هذا . بعد ذلك ، نجد فيلمًا يعتبره المستخدم أسوأ من Interstellar. يمكننا الاختيار من بين "جاذبية" ، "أجنبي" ، "بروميثيوس" ، أو أي فيلم لم يشاهده بعد.

خذ "الجذب". في الصيغة ، هذا . , «» , , «» . . «», «» , .
, , «». , .
.
— , . , . , , .
. ? , , , , .
: . , , . ,
حيث — .
, , , .
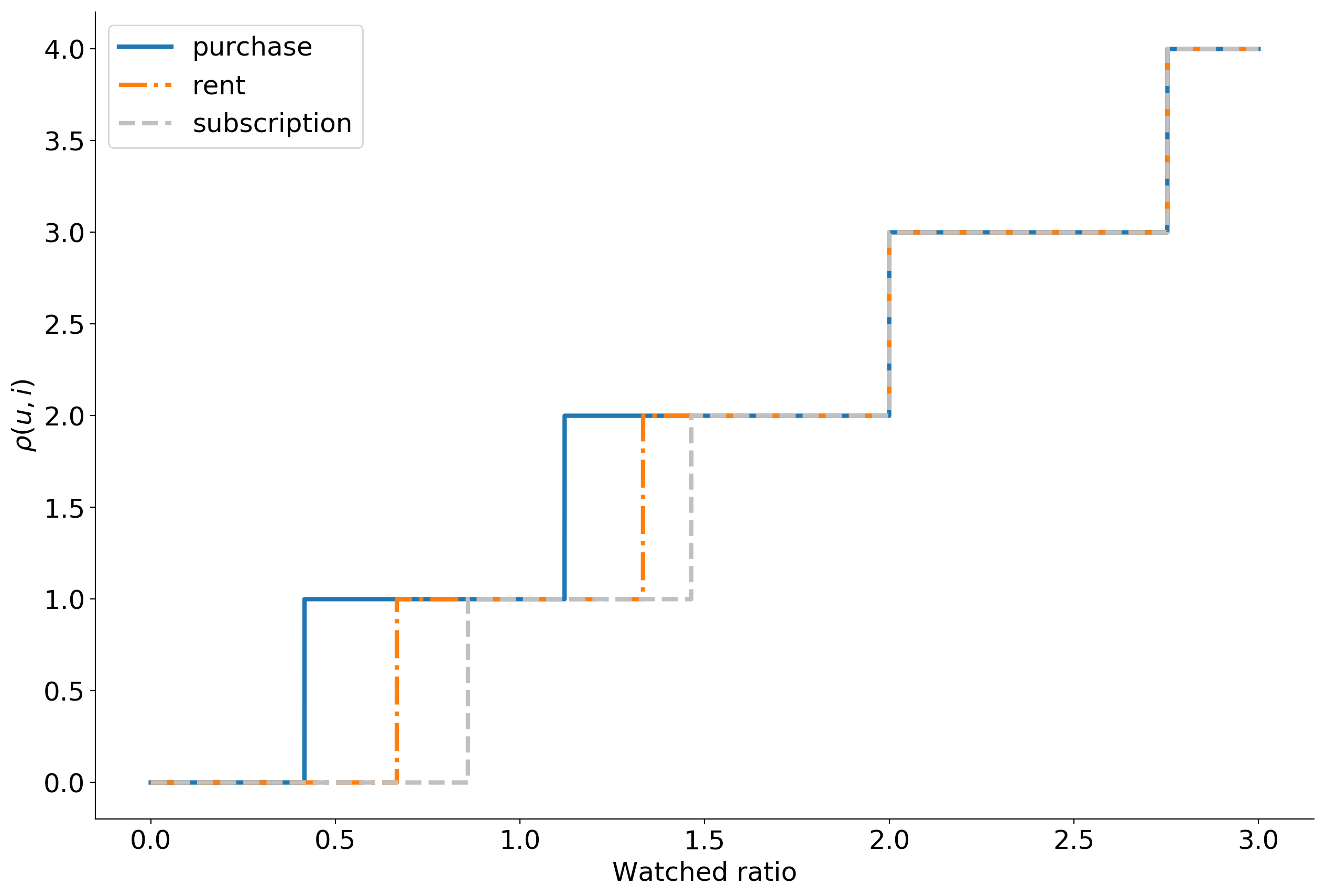
WARP WSABIE: Scaling Up To Large Vocabulary Image Annotation . , , . 10%.
. Okko :
- ;
- ;
- ( );
- ;
- 0 10.
, , . 399 , , . , . -, .
— . , explicit : , . , , implicit .
, , . . , .
, , .
, Cython , LightFM .
:

, top-N : . , Approximate nearest neighbor algorithm based on navigable small world graphs .
, , , , . , - , . : , .
يتم تجنب هذه المشكلات بواسطة نماذج المحتوى. إنها قوية ومعبرة ويمكنك لصق أي علامات عليها ، لكنها بطيئة للغاية. الحل هو تشغيل نموذج المحتوى ليس على جميع العناصر ، ولكن على المرشحين الذين تم الحصول عليهم من تحلل المصفوفة. يمكن أن يكون هناك أكبر عدد ممكن من المرشحين حسب إدارتك للمعالجة ، لكن من الأفضل أن يكون عدد المرشحين على الأقل ضعفي العدد. في حالتنا ، بالنسبة للأفلام المائة الموصى بها ، كان الحل الأفضل هو استخدام 400 مرشح.

يمكن تقسيم السمات التي نقدمها إلى نموذج المحتوى إلى ثلاث مجموعات: سمات المستخدم وسمات العناصر وعلامات التفاعل. في المجموع ، يتم الحصول على حوالي 50 علامات.
كعلامات للمستخدمين ، نستخدم إحصائيات مجمّعة عن سلوكهم في الخدمة ، على سبيل المثال:
- نسبة عرض الاشتراك
- توزيع الأجهزة التي يسجل المستخدم منها الدخول إلى التطبيق ،
- وقت الحياة في الخدمة ،
- ور. د.
بالنسبة للأفلام ، نستخدم جميع المعلومات الوصفية المتوفرة تقريبًا: النوع ، سنة الإصدار ، البلد ، الممثل ، المخرج ، الحد الأدنى للسن ، إلخ. تساعد مقاييس الأعمال المجمعة أيضًا بشكل جيد: نسبة الزيارات إلى البطاقة ، عدد مرات المشاهدة ، الإضافات إلى المفضلة ، التوزيع من خلال طرق العرض ، الأجهزة ، الخ
تشمل علامات التفاعل السرعة من مرحلة اختيار المرشحين والإحصائيات المجمعة لجميع تفاعلات المستخدم والأفلام السابقة بمشاركة نفس الممثلين والمخرجين وكتاب السيناريو مثل الفيلم المعني.
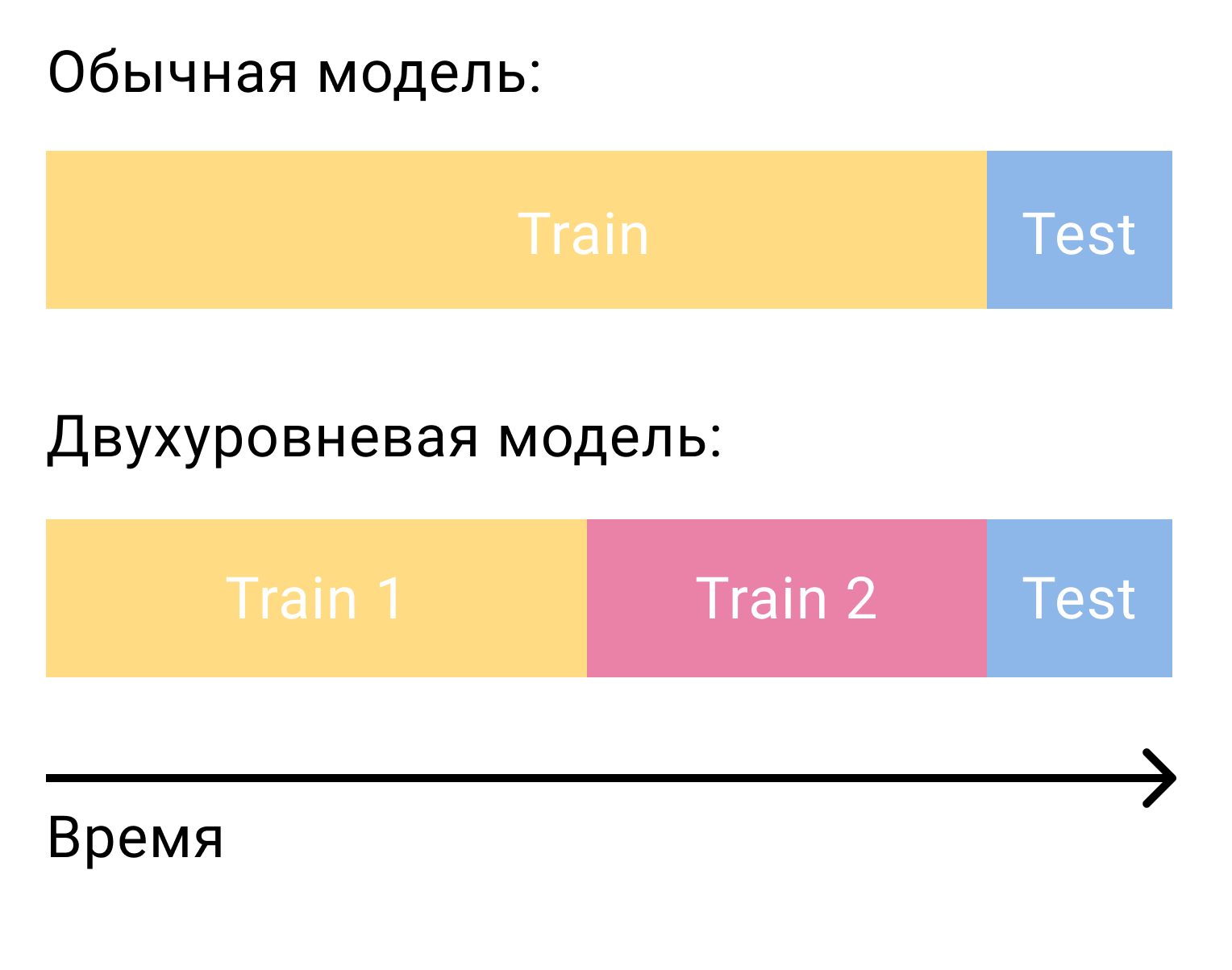
السؤال الأكثر شيوعًا الذي ينشأ عندما يتعلق الأمر بتصنيف المرشحين بنموذج المستوى الثاني هو كيفية تدريب هذا النموذج. في حالة عامل المصفوفة وحده ، كنا بحاجة إلى مجموعتين ، مفصولة الوقت والتدريب والاختبار. في حالة وجود نظام على مرحلتين ، سنحتاج إلى ثلاثة منهم - تدريبان واختبار واحد.
في مجموعة التدريب الأولى ، سنقوم بتدريب نموذج المستوى الأول وبناء المرشحين. من المرشحين ، من المهم استبعاد تلك العناصر التي تفاعل المستخدم معها في هذه المجموعة. ثم سنرى أي من المرشحين الذين تفاعل معهم المستخدم في المجموعة التدريبية الثانية. نحن نسميهم إيجابيات ، والمرشحين الباقين سلبيات. سيكون هذا مجموعة التدريب الخاصة بنا لنموذج المحتوى.
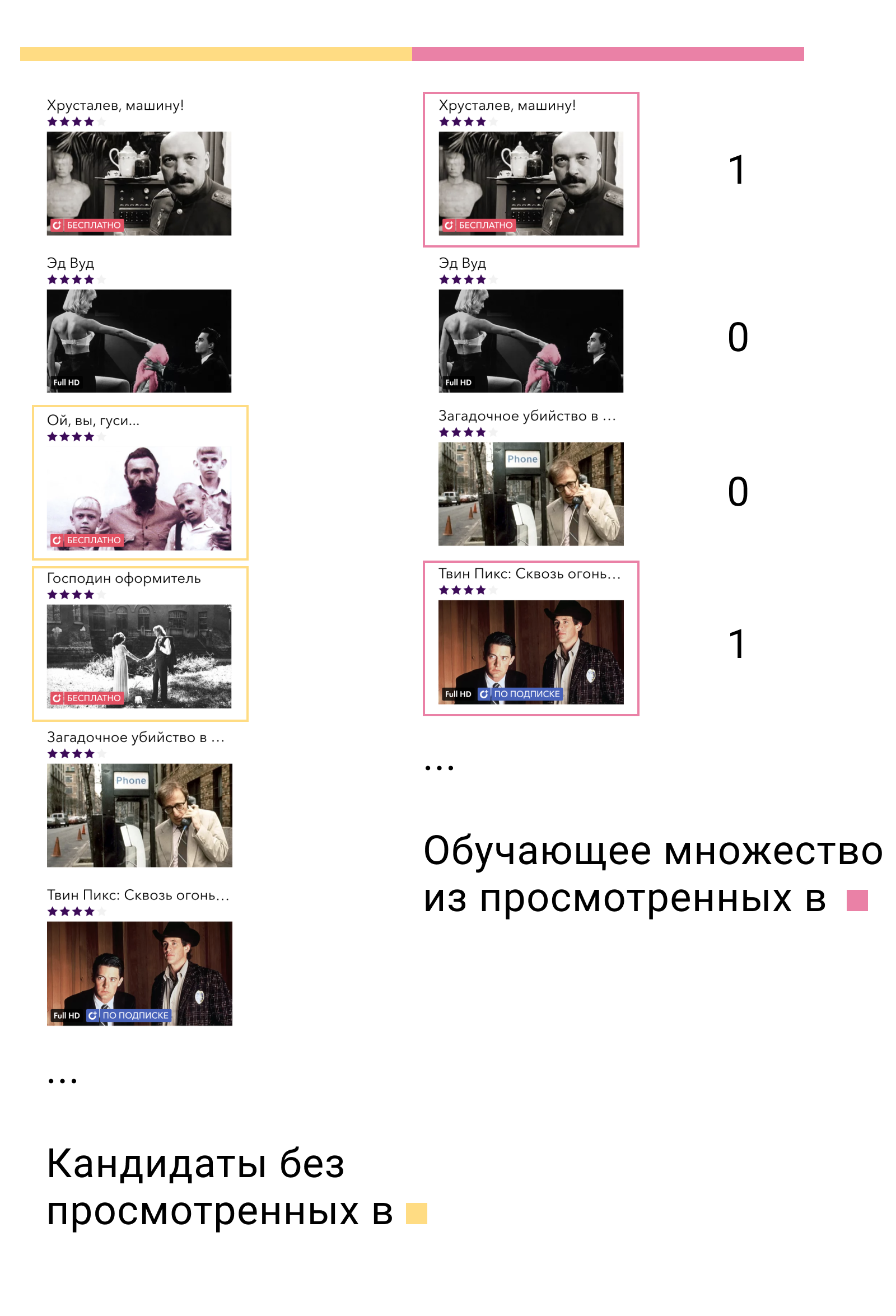
لماذا تعمل؟ أولاً ، نقوم بتدريب النموذج تمامًا على البيانات التي سيتم استخدامه عليها - إخراج نموذج المستوى الأول. ثانياً ، من بين جميع الأمثلة السلبية المحتملة ، نأخذ الأمثلة الأكثر تعقيدًا - تلك التي يسميها نموذج المستوى الأول ذات الصلة بالمستخدم ، ولكنها ليست كذلك.
ما التالي؟ الحل الأبسط والأكثر وضوحًا هو حل مشكلة التصنيف الثنائي ثم فرز العناصر بترتيب تنازلي لاحتمال أن تكون مثالًا إيجابيًا. ولكن يمكننا أن نتذكر مرة أخرى بيان مشكلة بناء نظام التوصية ، وفهم أن التصنيف الثنائي ليس هو المشكلة التي نحلها ، والانتقال مرة أخرى إلى مشكلة التصنيف.
في XGBoost و LightGBM ، وظيفة الخسارة الأساسية لمهام الترتيب هي LambdaMART. إذا لم تخوض في التفاصيل ، فإن الحدس وراءها بسيط للغاية. إذا - نموذج الانتاج على سبيل المثال ، ثم احتمال أن العنصر سيكون لها رتبة أعلى من العنصر سوف تكون متساوية
يمكن عندئذٍ كتابة وظيفة الخسارة على النحو التالي.
هنا هو الاحتمال الحقيقي للترتيب. سوف نحدده على أنه 1 إذا ، 0 إذا و 0.5 في القضية .
يعطي النموذج ثنائي المستوى زيادة بنسبة 50٪ في المقاييس مقارنةً بالنموذج أحادي المستوى. تضيف وظيفة خسارة الترتيب 10٪ أخرى.
المكافأة: الأفلام ذات الصلة
تذكر ، في مزايا منهجنا ، ذكرت المتجهات "الحرة" من عامل المصفوفة التي يمكن استخدامها لحل المشاكل ذات الصلة؟ لذلك ، واحدة من هذه المهام - البحث عن أفلام مماثلة - قررنا.
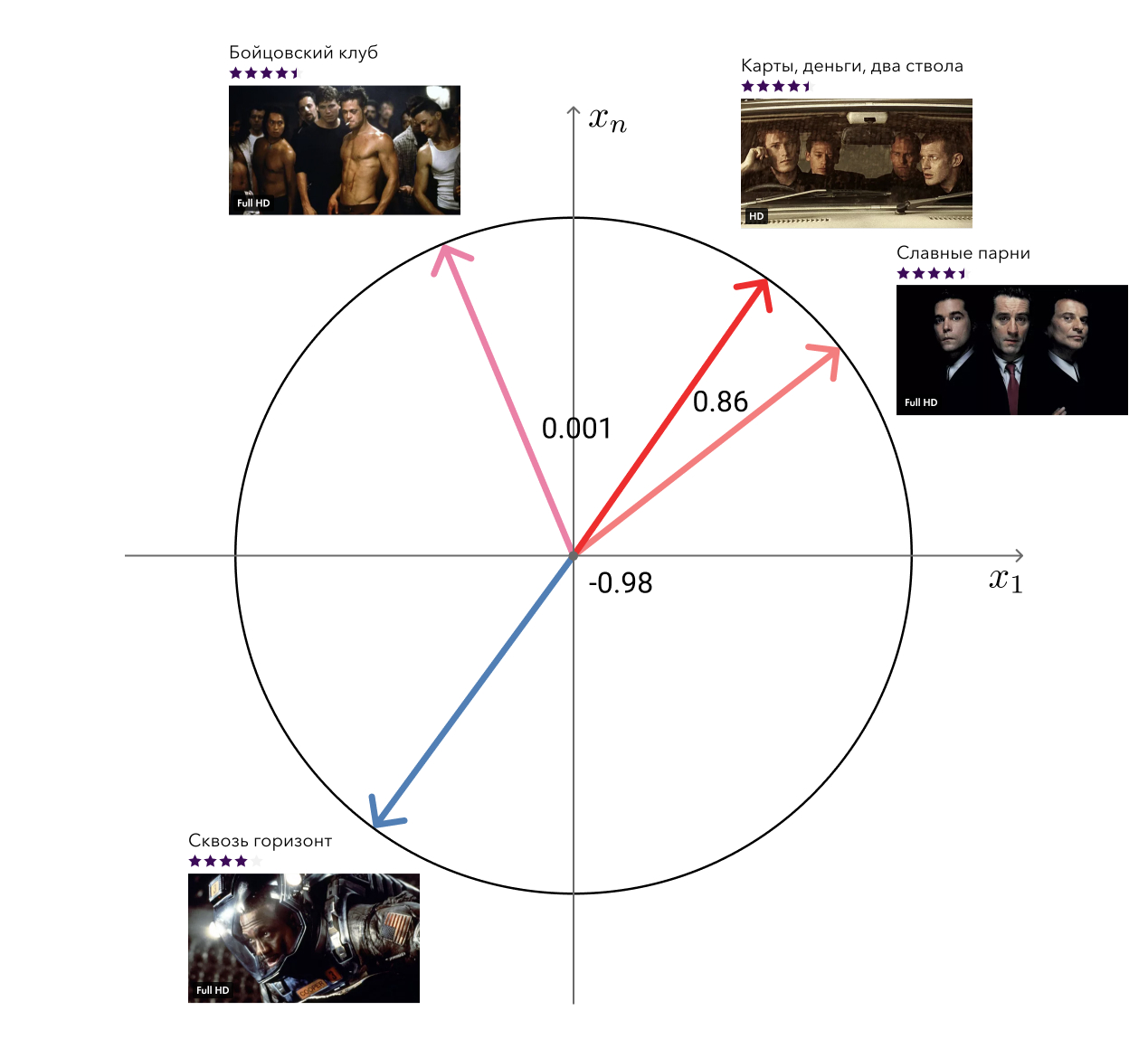
حل الخزي بسيط: بالنسبة لكل فيلم ، نأخذ اتجاهه ونبحث عن الأقرب من مسافة جيب التمام إليه. يبدو كافيا للعين. المستوى التالي هو إضافة معلومات التعريف واستخدام خوارزميات الرسم البياني.

التنفيذ الفني
بالإضافة إلى الجزء الحسابي ، أريد أن أتحدث قليلاً عن التنفيذ. يتكون Rekko من ثلاثة مكونات: lynch ، rekko -asks و rekko-service.
يعمل Lynch على جهاز واحد قوي ، ويستيقظ بشكل دوري ، ويقوم بإعداد البيانات لخدمة microservice ويضعها في S3.
توجد خدمات microservices rekko و rekko-service في بيئة منتج Okko ، إلى جانب جميع الخدمات وقواعد البيانات الصغيرة الأخرى. يقوم أولهم بمراقبة S3 باستمرار للتغييرات ، إن وجدت ، ويقوم بتنزيلها ووضعها في قواعد البقالة. يستخدم microservice الثاني هذه النتائج المحسوبة من أجل الاستجابة في الوقت الحقيقي لطلبات المستخدم وحساب توصياتهم.

تتم كتابة Microservices في Python باستخدام الصقر ، gunicorn و gevent ولا تمثل أي شيء مثير للاهتمام باستثناء منطق الأعمال. مثل كل الخدمات الصغيرة الأخرى لبيئة منتج Okko ، يتم إغلاقها بواسطة الموازن.
لينش هو أكثر إثارة للاهتمام من ذلك بكثير.
ما الذي يجب القيام به لحساب الجزء التالي من التوصيات للمستخدمين؟ على الأقل:
- تنزيل البيانات الجديدة التي ظهرت منذ آخر إعادة فرز الأصوات ؛
- معالجتها
- تدريب عامل المصفوفة ؛
- بناء المرشحين
- إعادة ترتيب المرشحين
- تطبيق قواعد العمل
- تفريغ.
يبدو أنه لا يبدو مخيفًا ، يمكنك وضع كل جزء في وظيفة منفصلة والاتصال بهم بدوره:
data = extract_data() data = transform_data(data) mf_model = train_mf_model(data) candidates = build_candidates(mf_model) predictions = build_predictions(content_model, candidates) upload_predictions(predictions)
حسنًا ، كل شيء قام بعمل رائع ، هل نختلف؟ ليس حقا لكن ماذا لو سقطت الورقة بأكملها في مكان ما؟ حسنا ، على سبيل المثال ، بسبب نقص الذاكرة. سيتعين علينا إعادة تشغيل كل شيء مرة أخرى ، حتى لو أمضينا بالفعل بضع ساعات في تدريب النموذج وبناء المرشحين.
حسنًا ، فلنحفظ جميع النتائج الوسيطة في الملفات ، وبعد الخريف ، تحقق من النتائج الموجودة بالفعل ، واستعادة الحالة وبدء العمليات الحسابية من اللحظة المناسبة. في الحقيقة ، هذه الفكرة أسوأ من السابقة. قد تتم مقاطعة البرنامج في منتصف الكتابة إلى ملف ، وعلى الرغم من وجوده ، إلا أنه في حالة غير صحيحة. في أفضل الأحوال ، سينخفض الحساب بالكامل ؛ وفي أسوأ الأحوال ، سينتهي بنتيجة خاطئة.
حسنًا ، دعنا نكتب إلى الملف الذري. ونقوم بإخراج كل وظيفة في كيان منفصل ونشير إلى التبعيات بينها. والنتيجة هي سلسلة من العمليات الحسابية ، والتي يمكن أن يؤديها كل عنصر أو لا.

بالفعل ليست سيئة. ولكن في الواقع ، لن يتم وصف جميع الحسابات الضرورية بقائمة. لن يتطلب التعامل مع مصفوفة التعلم بيانات المعاملات فحسب ، بل يتطلب أيضًا تصنيفات المستخدمين ، وسيتطلب بناء المرشحين قائمة بالأفلام التي يتم تذكرها لاستبعادها ، وسيحتاج حساب الأفلام المشابهة إلى معالجة مصفوفة مصورة ومعلومات تعريفية من الكتالوج ، وما إلى ذلك. لم تعد مهامنا مضمنة في قائمة متصلة ببساطة ، ولكن في رسم بياني موجه بدون دورات (Directed Acyclic Graph، DAG).

DAG هي منظمة الحوسبة شعبية للغاية. هناك إطاران رئيسيان لبناء DAG: Airflow و Luigi . نحن في Okko استقر على هذا الأخير. تم تطوير Luigi في Spotify ، وهو يتطور بنشاط ، ويكتب بالكامل في بيثون ، ويمكن تمديده بسهولة ويسمح لك بتنظيم العمليات الحسابية بمرونة كبيرة.
يتم تعريف المهمة في Luigi بواسطة فئة ترث من luigi.Task وتنفذ ثلاث طرق مطلوبة: requires ، luigi.Task output ويعمل. هذا ما تبدو عليه المهمة النموذجية:
سوف تضمن لويجي إتمام المهام بالترتيب الصحيح دون تجاوز استهلاك الموارد المتاحة. إذا كان من الممكن تنفيذ المهام بشكل متوازٍ ، فستعمل على التوازي ، مع الاستفادة القصوى من وحدة المعالجة المركزية وتقليل وقت التنفيذ الكلي. إذا فشلت بعض المهام ، فسيقوم بإعادة تشغيلها عدة مرات وفي حالة الفشل سيبلغنا. في هذه الحالة ، سيتم تنفيذ جميع المهام التي يمكن تنفيذها. هذا يعني ، على سبيل المثال ، أن وجود خطأ في مهمة ترتيب المرشحين لا يعيق عد وتحميل قائمة الأفلام المشابهة.
يتكون Lynch حاليًا من 47 مهمة فريدة تنتج حوالي 100 نسخة منها. بعضها مشغول بالعمل المباشر ، وبعضهم يحسب المقاييس ويرسلها إلى أداة Splunk BI الخاصة بنا. يرسل لينش أيضًا بشكل دوري إحصاءات وتقارير أساسية عن عمله إلينا عبر البرق. يكتب أيضا عن الأخطاء ، ولكن في PM.
الرصد والانقسام والنتائج

القاعدة الأولى لعلوم البيانات: لا تخبر أحداً عن الرواتب في علوم البيانات. القاعدة الثانية لعلوم البيانات: تلك التي لا يمكن قياسها لا يمكن تحسينها.
نحاول تتبع كل شيء. بادئ ذي بدء ، هذا ، بالطبع ، ترتيب المقاييس على البيانات التاريخية. فهي تساعد حتى في مرحلة البحث في اختيار أفضل نموذج من عدة واختيار معلمات مفرطة له.
بالنسبة إلى النماذج التي تعمل في الإنتاج ، نأخذ أيضًا في الاعتبار المقاييس ، ولكننا نرصدها يوميًا. هذه المقاييس متقلبة للغاية ، ولكن يمكن قولها إذا كان النموذج فجأة لسبب ما يتحلل. عندما يتم إطلاق نموذج جديد في المنتج ، يمكنك تركه في وضع الخمول لمدة أسبوع والتأكد من أن المقاييس لا تنحسر. بعد ذلك ، يمكنك تمكينه لبعض المستخدمين ، تشغيل اختبار A / B ومراقبة مقاييس العمل بالفعل.

بالإضافة إلى ذلك ، فإننا نعتبر توزيع التوصيات حسب النوع والبلد والسنة والنوع ، إلخ. وهذا يسمح لنا بفهم الطبيعة الحالية لتفضيلات المستخدم ومقارنتها ببيانات المشاهدة الحقيقية وأخطاء في قواعد العمل.

من المهم أيضًا تتبع توزيعات جميع الصفات المستخدمة. يمكن أن يكون التغيير الحاد فيها ناتجًا عن خطأ في مصدر البيانات وقد يؤدي إلى نتائج غير متوقعة.
ولكن ، بطبيعة الحال ، فإن أهم شيء يتطلب عن كثب هو مقاييس العمل. كجزء من نظام التوصية ، مقاييس العمل الرئيسية بالنسبة لنا هي:
- الإيرادات من نماذج استهلاك المعاملات والاشتراكات (إيرادات TVOD / SVOD) ؛
- متوسط العائد لكل زائر (متوسط العائد لكل زائر ، ARPV) ؛
- الشيك المتوسط (متوسط سعر الشراء ، APPP) ؛
- متوسط المشتريات لكل مستخدم (APPU) ؛
- التحويل إلى الشراء (السجل التجاري للشراء) ؛
- التحويل إلى المشاهدة عن طريق الاشتراك (CR to watch) ؛
- التحويل خلال الفترة التجريبية (CR إلى المحاكمة).
في الوقت نفسه ، ننظر بشكل منفصل إلى المقاييس من قسمي "التوصيات" و "المشابهة" ومقاييس الخدمة بأكملها ككل من أجل مراعاة تأثير إعادة التوزيع والنظر في الموقف من زوايا مختلفة.
قد يبدو هذا مثل لوحة معلومات تقارن عدة طرز:

كما قلت في البداية ، فإننا لا نقارن بين النماذج فقط مع بعضها البعض ، ولكن أيضًا بين مجموعة من المستخدمين والتوصيات ضد مجموعة من المستخدمين بدون توصيات. هذا يسمح لنا بتقييم التأثير الصافي لتنفيذ Rekko وفهم ما نحن فيه الآن وما هو هامش التحسين الذي لا يزال قائما. وفقًا لاختبار A / B هذا ، لدينا حاليًا:
- ARPV + 3.5٪
- ARPV بهامش + 5٪
- APPU + 4.3 ٪
- السجل التجاري للمحاكمة + 2.6 ٪
- CR لمشاهدة + 2.5 ٪
- APPP -1 ٪
يمكن تقسيم الأفلام في السينما عبر الإنترنت إلى مجموعتين: عناصر جديدة ومحتوى قديم. نحن نعرف بالفعل كيفية بيع الأخبار الجيدة. الغرض الرئيسي من التوصيات الشخصية هو الحصول على محتوى قديم مناسب للمستخدمين من الكتالوج. وهذا يؤدي إلى زيادة في عدد عمليات الشراء وتراجع متوسط الفحص ، لأن هذا المحتوى أرخص بشكل طبيعي. ولكن مثل هذا المحتوى بهامش كبير ، والذي يعوض عن هبوط الشيك ويعطي زيادة في الإيرادات.
أدى المزيد من محتوى الاشتراك ذي الصلة إلى زيادة التحويل خلال الفترة التجريبية وعرضها عن طريق الاشتراك.
التحدي Rekko
من 18 شباط (فبراير) إلى 18 نيسان (أبريل) 2019 ، إلى جانب منصة Boosters ، عقدنا تحدي Rekko ، حيث دعينا المشاركين إلى بناء نظام توصيات يستند إلى بيانات المنتج مجهولة المصدر.

من المتوقع أن يكون المشاركون الذين بنوا نظامًا ذا مستويين يشبه نظامنا في القمة. تمكن الفائزون الذين احتلوا المركزين الأول والثالث من الإضافة إلى المجموعة RNN. وتمكن المشارك من المركز الثامن من الصعود عليه باستخدام نماذج التصفية التعاونية فقط.
كتب إفجيني سميرنوف ، الذي احتل المركز الثاني في المسابقة ، مقالة تحدث فيها عن قراره.
في الوقت الحالي ، تتوفر المسابقة في صورة صندوق رمل ، بحيث يمكن لأي شخص مهتم بأنظمة التوصية تجربة أيديهم عليها واكتساب خبرة مفيدة.
استنتاج
مع هذه المقالة ، أردت أن أوضح لك أن أنظمة التوصية في الإنتاج ليست صعبة على الإطلاق ، ولكنها ممتعة ومربحة. الشيء الرئيسي هو التفكير في الأهداف ، وليس الوسائل لتحقيقها وقياس كل شيء باستمرار.
في المقالات المستقبلية ، سنعلمك أكثر عن مطبخ Okko الداخلي ، لذلك لا تنسَ الاشتراك وما شابه.