مرحبا الزملاء!
ربما كان عنوان منشور اليوم يبدو أفضل مع علامة استفهام - من الصعب القول. على أي حال ، نود اليوم أن نقدم لك جولة قصيرة
ستقدمك إلى مكتبة
Dask ، المصممة لموازنة المهام في بيثون. نأمل أن نعود إلى هذا الموضوع بشكل أكثر شمولاً في المستقبل.
 الصورة التي التقطت في
الصورة التي التقطت فيDask هي ، دون المبالغة ، أداة معالجة البيانات الأكثر ثورية التي صادفتها. إذا كنت تحب
Pandas و Numpy ، ولكن في بعض الأحيان لا يمكنك التعامل مع البيانات التي لا تناسب ذاكرة الوصول العشوائي ، فإن Dask هو بالضبط ما تحتاجه. يدعم Dask إطار بيانات Pandas وهياكل البيانات Numpy (المصفوفات). يمكن تشغيل Dask إما على الكمبيوتر المحلي أو تحجيمها ، ثم تشغيلها في الكتلة. في الجوهر ، تكتب الرمز مرة واحدة فقط ، ثم تختار استخدامه على الجهاز المحلي أو نشره في مجموعة من العديد من العقد باستخدام بناء جملة Python الأكثر شيوعًا لكل هذا. الميزة نفسها رائعة ، لكنني قررت أن أكتب هذه المقالة فقط للتأكيد: يجب على كل عالم بيانات (على الأقل باستخدام Python) استخدام Dask. من وجهة نظري ، فإن سحر Dask هو أنه من خلال تقليل الرمز ، يمكنك موازاة ذلك باستخدام قوة الحوسبة المتوفرة بالفعل ، على سبيل المثال ، على جهاز الكمبيوتر المحمول. من خلال المعالجة المتوازية للبيانات ، يتم تشغيل البرنامج بشكل أسرع ، وعليك الانتظار أقل ، وبالتالي ، يتم ترك مزيد من الوقت للتحليلات. على وجه الخصوص ، في هذه المقالة سوف نتحدث عن كائن
dask.delayed وكيف يتلاءم مع دفق مهمة علم البيانات.
تقديم داسك
كمقدمة لـ Dask ، فيما يلي بعض الأمثلة فقط لإعطائك فكرة عن بناء الجملة الطبيعي غير المزعج تمامًا. أهم استنتاج أريد أن أقترحه في هذه الحالة هو أن المعرفة التي لديك بالفعل ستكون كافية للعمل ؛ ليس عليك أن تتعلم أداة بيانات كبيرة جديدة مثل Hadoop أو Spark.
تقدم Dask 3 مجموعات متوازية يمكنك من خلالها تخزين البيانات التي تتجاوز حجم ذاكرة الوصول العشوائي ، وهي Dataframes ، Bags and Arrays. في كل من هذه الأنواع من المجموعات ، يمكنك تخزين البيانات عن طريق تقسيمها بين ذاكرة الوصول العشوائي والقرص الصلب ، وكذلك توزيع البيانات عبر عقد متعددة في مجموعة.
يتكون Dask DataFrame من dataframes ، مثل تلك الموجودة في Pandas ، لذلك يسمح لك باستخدام مجموعة فرعية من الميزات من بناء جملة استعلام Pandas. يوجد أدناه مثال على الكود الذي يقوم بتنزيل جميع ملفات csv لعام 2018 ، ويوزع حقلًا ذو طابع زمني ، ويقوم بتشغيل طلب Pandas:
import dask.dataframe as dd df = dd.read_csv('logs/2018-*.*.csv', parse_dates=['timestamp']) df.groupby(df.timestamp.dt.hour).value.mean().compute()
مثال على Dataframeفي Dask Bag ، يمكنك تخزين ومعالجة مجموعات الكائنات الثعبانية التي لا تناسب الذاكرة. تعتبر Dask Bag رائعة لمعالجة السجلات ومجموعات المستندات بتنسيق json. في مثال التعليمات البرمجية هذا ، يتم تحميل جميع ملفات json لعام 2018 في بنية بيانات Dask Bag ، ويتم تحليل كل سجل json ، ويتم تصفية بيانات المستخدم باستخدام وظيفة lambda:
import dask.bag as db import json records = db.read_text('data/2018-*-*.json').map(json.loads) records.filter(lambda d: d['username'] == 'Aneesha').pluck('id').frequencies()
حقيبة داسك سبيل المثالتدعم بنية بيانات Dask Arrays شرائح Numpy. في المثال التالي ، يتم تقسيم مجموعة من بيانات HDF5 إلى كتل ذات أبعاد (5000 ، 5000):
import h5py f = h5py.File('myhdf5file.hdf5') dset = f['/data/path'] import dask.array as da x = da.from_array(dset, chunks=(5000, 5000))
مثال على مجموعة Daskالمعالجة المتوازية في Dask
عنوان آخر بنفس الدقة لهذا القسم سيكون "موت دورة متتابعة." بين الحين والآخر ، واجهت نمطًا شائعًا: التكرار على قائمة العناصر ، ثم تنفيذ طريقة Python مع كل عنصر ، ولكن باستخدام وسيطات إدخال مختلفة. تشتمل سيناريوهات معالجة البيانات الشائعة على حساب إجماليات الميزات لكل عميل أو تجميع الأحداث من السجل لكل طالب. بدلاً من تطبيق دالة على كل وسيطة في حلقة متسلسلة ، يسمح لك كائن Dask Delayed بمعالجة العديد من العناصر بشكل متواز. عند العمل مع Dask Delayed ، يتم وضع قائمة انتظار لجميع استدعاءات الوظائف ، في الرسم البياني للتنفيذ ، وبعد ذلك يتم التخطيط لمعالجتها.
كنت دائمًا كسول بعض الشيء في كتابة محرك الخيوط الخاص بي أو استخدام المزامنة ، لذا لن أريك أمثلة مشابهة للمقارنة. مع Dask ، لا يمكنك تغيير بناء الجملة ولا أسلوب البرمجة! تحتاج فقط إلى إضافة تعليق توضيحي أو التفاف الأسلوب ، والذي سيتم تنفيذه بالتوازي مع
@dask.delayed واستدعاء الطريقة الحسابية بعد تنفيذ رمز الحلقة.
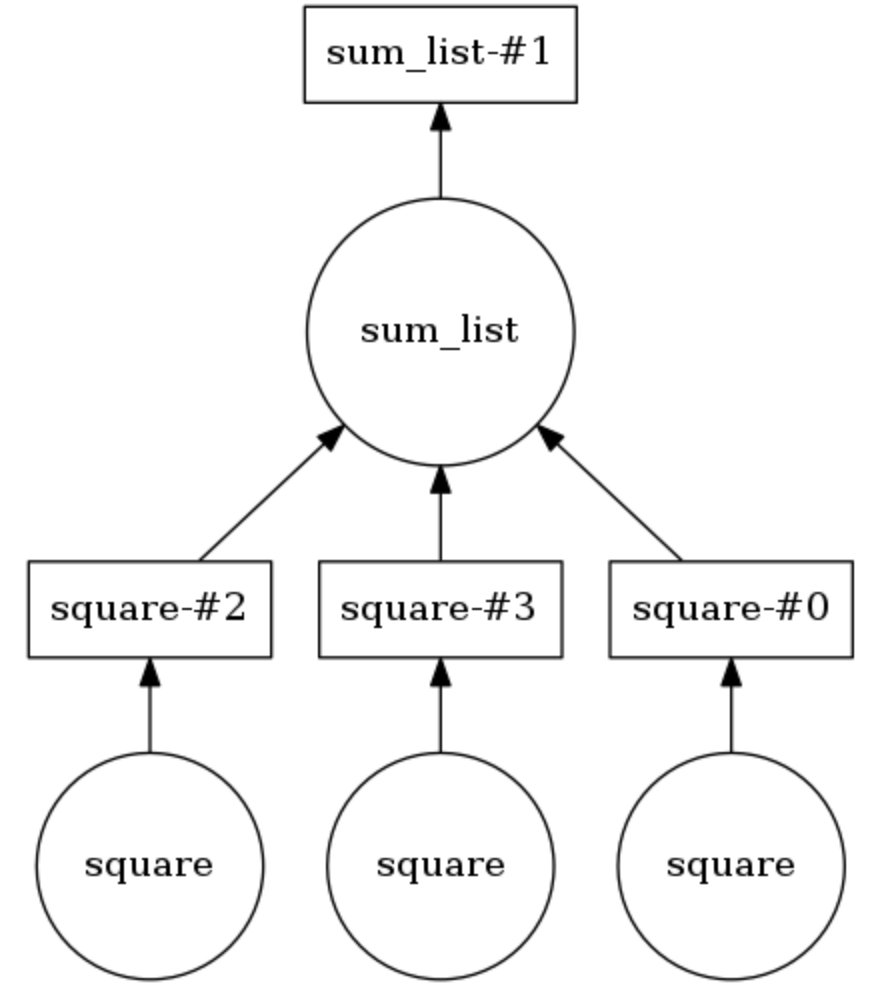
مثال الرسم البياني الحوسبة
في المثال أدناه ، يتم شرح
@dask.delayed . يتم تخزين ثلاثة أرقام في قائمة ، ويجب أن تكون مربعة ، ثم يتم تلخيصها معًا. ينشئ Dask رسمًا حسابيًا يوفر التنفيذ المتوازي لطريقة التربيع ، وبعد ذلك يتم تمرير نتيجة هذه العملية إلى طريقة
sum_list . يمكن عرض الرسم البياني الحسابي عن طريق
calling .visualize() .
Calling .compute() ينفذ الرسم البياني حساب. كما هو واضح من
الاستنتاج ، تتم معالجة عناصر القائمة ليس بالترتيب ، ولكن بالتوازي.
يمكن تعيين عدد
dask.set_options( pool=ThreadPool(10) (على سبيل المثال ،
dask.set_options( pool=ThreadPool(10) ) ، ويمكن أيضًا تبديلها بسهولة لاستخدام العمليات على الكمبيوتر المحمول أو الكمبيوتر الشخصي (مثل
dask.config.set( scheduler='processes' ) .
لذلك ، أوضحت كم سيكون تافهًا إضافة معالجة متوازية للمهام إلى مشروع من مجال "علوم البيانات" باستخدام Dask. قبل وقت قصير من كتابة هذه المقالة ، استخدمت Dask لتقسيم البيانات حول تدفقات نقرات المستخدمين (سجل الزيارة) إلى جلسات مدتها 40 دقيقة ، ثم تجميع السمات لكل مستخدم لمزيد من المجموعات. أخبرنا كيف استخدمت Dask!