يتم تطبيق أنظمة التعديل التلقائي في خدمات الويب والتطبيقات حيث يكون من الضروري معالجة عدد كبير من رسائل المستخدم. يمكن لهذه الأنظمة أن تقلل من تكاليف التعديل اليدوي ، وتسريعها ومعالجة جميع رسائل المستخدم في الوقت الحقيقي. في المقال ، سنتحدث عن بناء نظام تعديل تلقائي لمعالجة اللغة الإنجليزية باستخدام خوارزميات التعلم الآلي. سنناقش كامل خط أنابيب العمل من المهام البحثية واختيار خوارزميات ML إلى طرحها في الإنتاج. دعونا نرى أين تبحث عن مجموعات البيانات الجاهزة وكيفية جمع البيانات للمهمة بنفسك.
أعد مع إيرا ستيبانيوك ( id_step ) ، عالم البيانات في Poteha Labsوصف المهمة
نعمل مع الدردشات النشطة متعددة المستخدمين ، حيث يمكن أن تأتي الرسائل القصيرة من العشرات من المستخدمين في دردشة واحدة كل دقيقة. وتتمثل المهمة في تسليط الضوء على الرسائل والرسائل السامة مع أي ملاحظات فاحشة في حوارات من هذه الدردشات. من وجهة نظر التعلم الآلي ، هذه مهمة تصنيف ثنائية ، حيث يجب تعيين كل رسالة إلى أحد الفصول.
لحل هذه المشكلة ، بادئ ذي بدء ، كان من الضروري فهم ماهية الرسائل السامة وما الذي يجعلها سامة بالضبط. للقيام بذلك ، نظرنا إلى عدد كبير من رسائل المستخدم النموذجية على الإنترنت. فيما يلي بعض الأمثلة التي قسمناها بالفعل إلى رسائل سامة وعادية.
يمكن ملاحظة أن الرسائل السامة تحتوي غالبًا على كلمات فاضحة ، ولكن لا يزال هذا ليس شرطًا أساسيًا. قد لا تحتوي الرسالة على كلمات غير لائقة ، ولكن قد تكون مسيئة لشخص (مثال (1)). بالإضافة إلى ذلك ، تحتوي الرسائل السامة والعادية في بعض الأحيان على نفس الكلمات التي يتم استخدامها في سياقات مختلفة - مسيئة أم لا (مثال (2)). هذه الرسائل تحتاج أيضا إلى أن تكون قادرة على التمييز.
بعد أن درسنا العديد من الرسائل ، بالنسبة لنظام الاعتدال لدينا ، أطلقنا على تلك الرسائل اسماء تحتوي على عبارات بذيئة أو تعابير مهينة أو كراهية لشخص ما.
معطيات
فتح البيانات
إحدى مجموعات البيانات الأكثر اعتدالًا هي مجموعة البيانات من
تحدي تصنيف Kaggle
Toxic Comment . جزء من العلامات في مجموعة البيانات غير صحيح: على سبيل المثال ، يمكن تعليم الرسائل التي تحتوي على كلمات فاحشة على أنها طبيعية. لهذا السبب ، لا يمكنك فقط خوض مسابقات Kernel والحصول على خوارزمية تصنيف جيدة الأداء. تحتاج إلى العمل أكثر مع البيانات ، ومعرفة أي الأمثلة ليست كافية ، وإضافة بيانات إضافية مع مثل هذه الأمثلة.
بالإضافة إلى المسابقات ، هناك العديد من المنشورات العلمية مع روابط لمجموعات البيانات المناسبة (على
سبيل المثال ) ، ولكن لا يمكن استخدام جميعها في المشروعات التجارية. تحتوي معظم مجموعات البيانات هذه على رسائل من الشبكة الاجتماعية Twitter ، حيث يمكنك العثور على العديد من التغريدات السامة. بالإضافة إلى ذلك ، يتم جمع البيانات من Twitter ، حيث يمكن استخدام علامات تصنيف معينة للبحث عن رسائل المستخدم السامة وترميزها.
البيانات اليدوية
بعد أن جمعنا مجموعة البيانات من المصادر المفتوحة وقمنا بتدريبها على النموذج الأساسي ، أصبح من الواضح أن البيانات المفتوحة ليست كافية: جودة النموذج ليست مرضية. بالإضافة إلى فتح البيانات لحل المشكلة ، تم توفير مجموعة غير مخصصة من الرسائل من مراسلة الألعاب مع عدد كبير من الرسائل السامة لنا.

لاستخدام هذه البيانات لمهمتها ، كان لا بد من وصفها بطريقة أو بأخرى. في ذلك الوقت ، كان هناك بالفعل مصنف أساسي مدرّب ، قررنا استخدامه لوضع علامات نصف آلية. بعد تشغيل جميع الرسائل من خلال النموذج ، حصلنا على احتمالات سمية كل رسالة وفرزها بترتيب تنازلي. في بداية هذه القائمة ، جمعت رسائل بكلمات فاحشة ومهينة. في النهاية ، على العكس ، هناك رسائل مستخدم عادية. وبالتالي ، لا يمكن تمييز معظم البيانات (التي تحتوي على قيم احتمال كبيرة وصغيرة جدًا) ، ولكن يتم تعيينها على الفور لفئة معينة. يبقى لتمييز الرسائل التي وقعت في منتصف القائمة ، والتي تم القيام بها يدويا.
زيادة البيانات
غالبًا في مجموعات البيانات ، يمكنك رؤية الرسائل التي تم تغيير الخطأ على المصنف عليها ، والشخص يفهم معناها بشكل صحيح.
وذلك لأن المستخدمين يعدلون ويتعلمون خداع أنظمة الاعتدال بحيث ترتكب الخوارزميات أخطاء في الرسائل السامة ويظل المعنى واضحًا للشخص. ما يفعله المستخدمون الآن:
- الأخطاء المطبعية تولد: أنت غبي الأحمق ، fack لك ،
- استبدال الأحرف الأبجدية بأرقام مماثلة في الوصف: n1gga ، b0ll0cks ،
- إدراج مساحات إضافية: احمق ،
- إزالة المسافات بين الكلمات: dieyoustupid .
لتدريب المصنف المقاوم لهذه البدائل ، عليك القيام بما يفعله المستخدمون: إنشاء نفس التغييرات في الرسائل وإضافتها إلى مجموعة التدريب على البيانات الرئيسية.
بشكل عام ، هذا الصراع أمر لا مفر منه: سيحاول المستخدمون دائمًا العثور على نقاط الضعف والاختراق ، وسيطبق المشرفون خوارزميات جديدة.
وصف المهام الفرعية
واجهنا مهام فرعية لتحليل الرسائل في وضعين مختلفين:
- الوضع عبر الإنترنت - تحليل الرسائل في الوقت الفعلي ، مع أقصى سرعة استجابة ؛
- وضع غير متصل بالشبكة - تحليل سجلات الرسائل وتخصيص مربعات حوار سامة.
في الوضع عبر الإنترنت ، نقوم بمعالجة كل رسالة مستخدم وتشغيلها من خلال النموذج. إذا كانت الرسالة سامة ، فقم بإخفائها في واجهة الدردشة ، وإذا كانت طبيعية ، فقم بعرضها. في هذا الوضع ، يجب معالجة جميع الرسائل بسرعة كبيرة: يجب أن يعطي النموذج استجابة بسرعة حتى لا يعطل بنية الحوار بين المستخدمين.
في وضع عدم الاتصال ، لا توجد حدود زمنية للعمل ، وبالتالي أردت تطبيق النموذج بأعلى جودة.
وضع على الانترنت. بحث القاموس
بغض النظر عن النموذج الذي يتم اختياره بعد ذلك ، يجب علينا العثور على الرسائل وتصفيتها بكلمات فاحشة. لحل هذه المشكلة الفرعية ، من الأسهل تجميع قاموس من الكلمات والتعبيرات غير الصالحة التي لا يمكن تخطيها ، والبحث عن مثل هذه الكلمات في كل رسالة. يجب أن يكون البحث سريعًا ، لذلك لا تتناسب خوارزمية البحث عن سلسلة فرعية ساذجة في ذلك الوقت. الخوارزمية المناسبة للعثور على مجموعة من الكلمات في السلسلة هي
خوارزمية Aho-Korasik . بسبب هذا النهج ، من الممكن التعرف بسرعة على بعض الأمثلة السامة وحظر الرسائل قبل إرسالها إلى الخوارزمية الرئيسية. يتيح لك استخدام خوارزمية ML "فهم معنى" الرسائل وتحسين جودة التصنيف.
وضع على الانترنت. نموذج تعلم الآلة الأساسي
بالنسبة للنموذج الأساسي ، قررنا استخدام نهج قياسي لتصنيف النص: TF-IDF + خوارزمية التصنيف الكلاسيكية. مرة أخرى لأسباب السرعة والأداء.
TF-IDF هو مقياس إحصائي يسمح لك بتحديد أهم الكلمات للنص في الجسم باستخدام معلمتين: تكرار الكلمات في كل وثيقة وعدد الوثائق التي تحتوي على كلمة معينة (بمزيد من التفاصيل
هنا ). بعد حساب كل كلمة في رسالة TF-IDF ، نحصل على تمثيل متجه لهذه الرسالة.
يمكن حساب TF-IDF للكلمات في النص ، وكذلك للكلمات والحروف n-gram. سيعمل هذا الامتداد بشكل أفضل ، حيث سيكون قادرًا على التعامل مع العبارات والكلمات التي تحدث بشكل متكرر والتي لم تكن موجودة في مجموعة التدريب (خارج المفردات).
from sklearn.feature_extraction.text import TfidfVectorizer from scipy import sparse vect_word = TfidfVectorizer(max_features=10000, lowercase=True, analyzer='word', min_df=8, stop_words=stop_words, ngram_range=(1,3)) vect_char = TfidfVectorizer(max_features=30000, lowercase=True, analyzer='char', min_df=8, ngram_range=(3,6)) x_vec_word = vect_word.fit_transform(x_train) x_vec_char = vect_char.fit_transform(x_train) x_vec = sparse.hstack([x_vec_word, x_vec_char])
مثال على استخدام TF-IDF على n غرام من الكلمات والحروفبعد تحويل الرسائل إلى متجهات ، يمكنك استخدام أي طريقة كلاسيكية للتصنيف:
الانحدار اللوجستي ، SVM ،
الغابة العشوائية ، التعزيز .
قررنا استخدام الانحدار اللوجستي في مهمتنا ، نظرًا لأن هذا النموذج يعطي زيادة في السرعة بالمقارنة مع المصنفات الكلاسيكية الأخرى من فئة ML ويتنبأ باحتمالات الفصل ، مما يسمح لك بتحديد عتبة تصنيف بمرونة في الإنتاج.
الخوارزمية التي يتم الحصول عليها باستخدام TF-IDF والانحدار اللوجستي تعمل بسرعة وتحدد الرسائل بكلمات وتعبيرات فاحشة ، لكنها لا تفهم دائمًا المعنى. على سبيل المثال ، غالبًا ما تندرج الرسائل ذات الكلمات "
الأسود " و "
النسمة " في فئة المواد السامة. أردت إصلاح هذه المشكلة وتعلم فهم معنى الرسائل بشكل أفضل باستخدام الإصدار التالي من المصنف.
وضع عدم الاتصال
لفهم معنى الرسائل بشكل أفضل ، يمكنك استخدام خوارزميات الشبكة العصبية:
- حفلات الزفاف (Word2Vec ، FastText)
- الشبكات العصبية (CNN ، RNN ، LSTM)
- نماذج جديدة سابقة التدريب (ELMo ، ULMFiT ، BERT)
سنناقش بعض هذه الخوارزميات وكيف يمكن استخدامها بمزيد من التفاصيل.
Word2Vec و FastText
تسمح لك نماذج التضمين بالحصول على تمثيلات متجهة للكلمات من النصوص. هناك
نوعان من Word2Vec : تخطي غرام و CBOW (كيس مستمر من الكلمات). في Skip-gram ، يتم التنبؤ بالسياق بالكلمة ، ولكن في CBOW ، بالعكس: يتم التنبؤ بالكلمة بواسطة السياق.
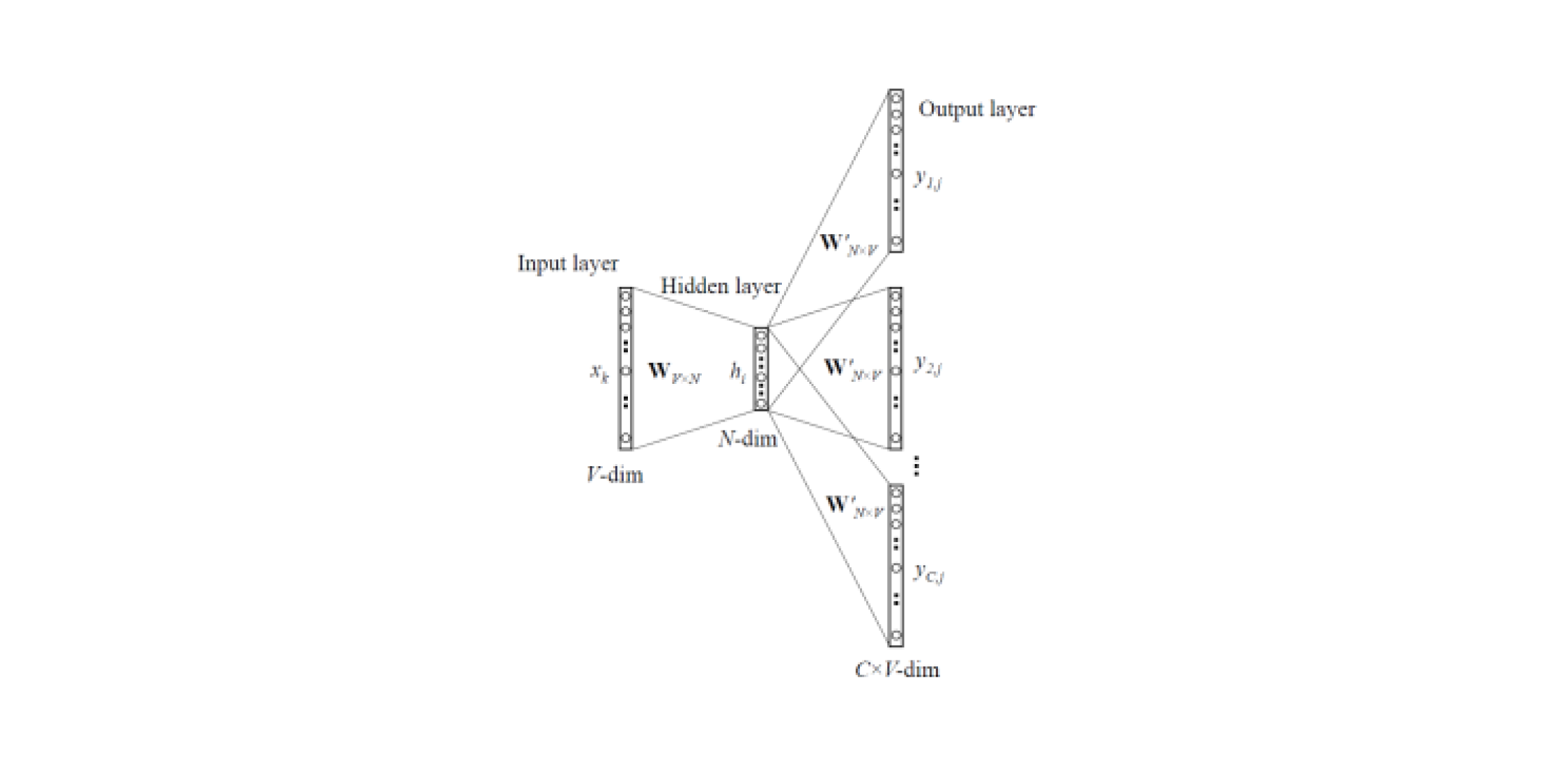
يتم تدريب هذه النماذج على مجموعة كبيرة من النصوص وتتيح لك الحصول على تمثيلات متجهة للكلمات من طبقة مخفية من شبكة عصبية مدربة. عيب هذه البنية هو أن النموذج يتعلم من مجموعة محدودة من الكلمات الموجودة في المجموعة. هذا يعني أنه بالنسبة لجميع الكلمات التي لم تكن في نصوص النصوص في مرحلة التدريب ، لن يكون هناك حفلات زفاف. وغالبًا ما يحدث هذا الموقف عند استخدام نماذج مُدرَّبة مسبقًا لمهامهم: بالنسبة لبعض الكلمات لن يكون هناك حفلات زفاف ، وبالتالي سيتم فقد قدر كبير من المعلومات المفيدة.
لحل المشكلة مع الكلمات غير الموجودة في القاموس (OOV ، خارج المفردات) هناك نموذج تضمين محسّن -
FastText . بدلاً من استخدام كلمات مفردة لتدريب الشبكة العصبية ، يقسم FastText الكلمات إلى n-grams (كلمات فرعية) ويتعلم منها. للحصول على تمثيل متجه لكلمة ، تحتاج إلى الحصول على تمثيلات متجه للون-ن من هذه الكلمة وإضافتها.
وبالتالي ، يمكن استخدام نماذج Word2Vec و FastText المدربة مسبقًا للحصول على متجهات الميزات من الرسائل. يمكن تصنيف الخصائص التي تم الحصول عليها باستخدام مصنفات ML الكلاسيكية أو شبكة عصبية متصلة بالكامل.
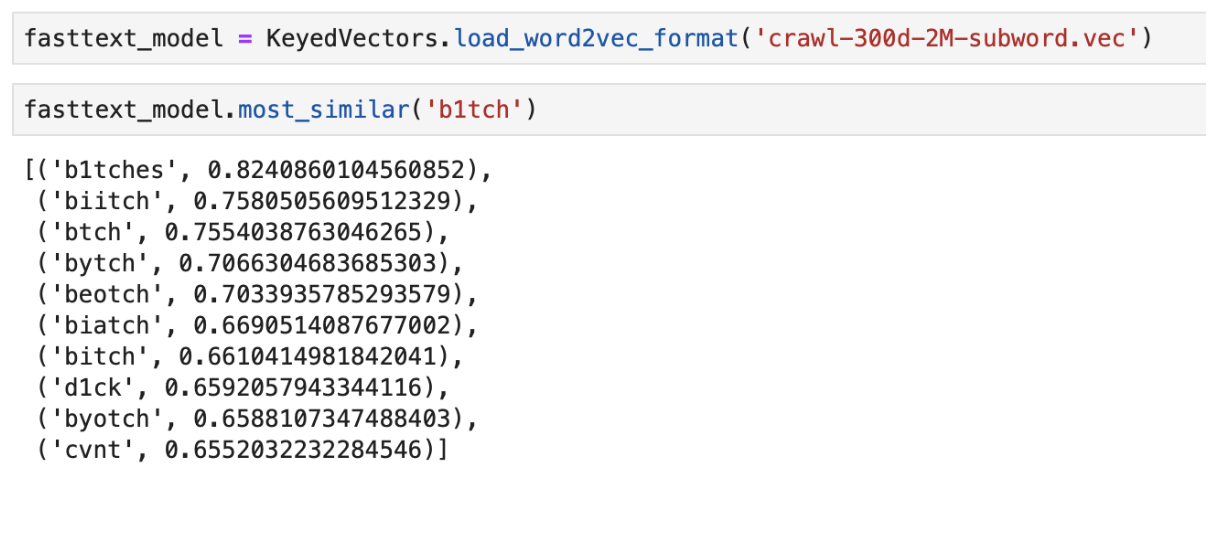 مثال على مخرجات الكلمات "الأقرب" في المعنى باستخدام FastText المدربين مسبقًا
مثال على مخرجات الكلمات "الأقرب" في المعنى باستخدام FastText المدربين مسبقًاCNN المصنف
لمعالجة وتصنيف النصوص من خوارزميات الشبكة العصبية ، يتم استخدام الشبكات المتكررة (LSTM ، GRU) في كثير من الأحيان ، لأنها تعمل بشكل جيد مع تسلسل. غالبًا ما تستخدم الشبكات التلافيفية (CNN) لمعالجة الصور ، ولكن
يمكن استخدامها أيضًا في مهمة تصنيف النص. النظر في كيفية القيام بذلك.
كل رسالة عبارة عن مصفوفة فيها على كل سطر للرمز المميز (الكلمة) يتم كتابة تمثيل المتجه. يتم تطبيق الإلتفاف على مصفوفة كهذه بطريقة معينة: مرشح الالتفاف "ينزلق" على كامل صفوف المصفوفة (متجهات الكلمات) ، لكنه يلتقط عدة كلمات في وقت واحد (عادةً ما بين 2-5 كلمات) ، وبالتالي معالجة الكلمات في سياق الكلمات المجاورة. يمكن رؤية تفاصيل كيفية حدوث ذلك في
الصورة .
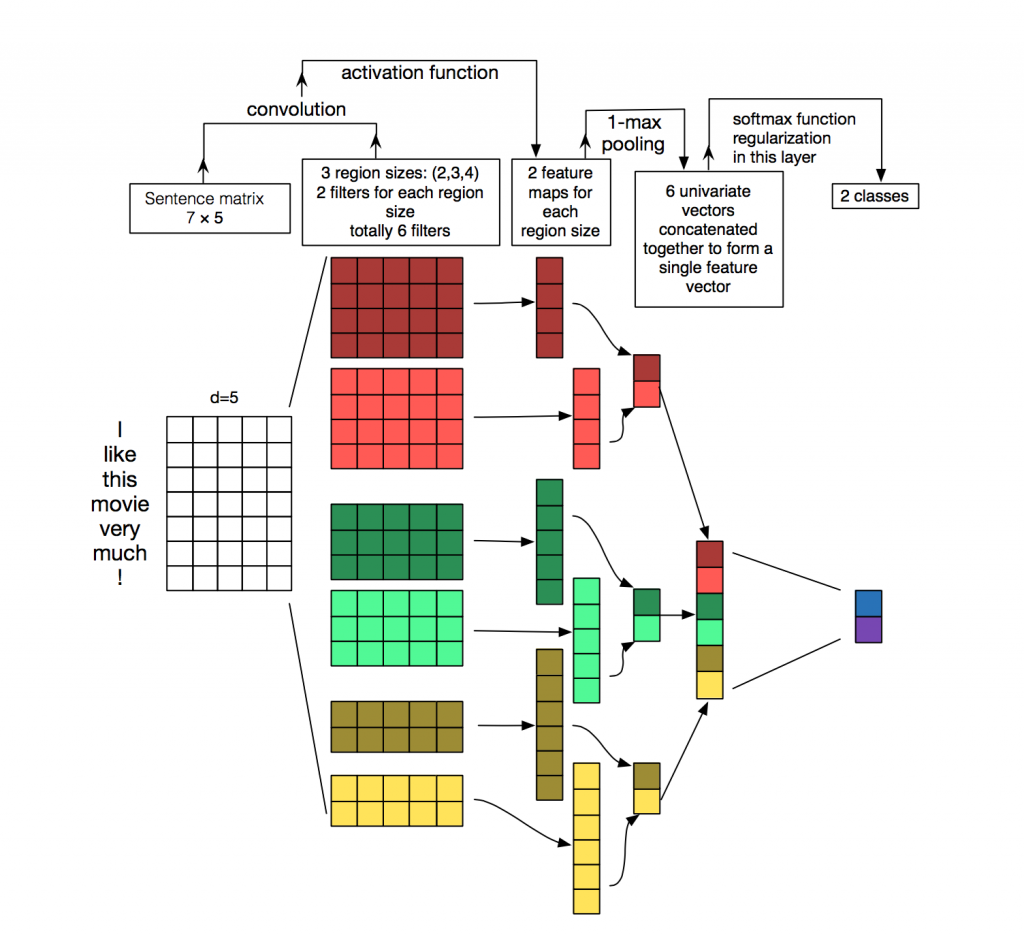
لماذا استخدام الشبكات التلافيفية لمعالجة الكلمات عندما يمكنك استخدام المتكررة؟ الحقيقة هي أن التلفيات تعمل بشكل أسرع بكثير. باستخدامها لتصنيف الرسائل ، يمكنك توفير وقت كبير للتدريب.
إلمو
ELMo (التضمينات من نماذج اللغة) هي نموذج تضمين يستند إلى نموذج لغة تم
تقديمه مؤخرًا . يختلف نموذج التضمين الجديد عن طرازي Word2Vec و FastText. نواقل الكلمات ELMo لها مزايا معينة:
- يعتمد العرض التقديمي لكل كلمة على السياق بأكمله الذي يتم استخدامه فيه.
- يعتمد التمثيل على الرموز ، مما يسمح بتكوين تمثيلات موثوقة لكلمات OOV (خارج المفردات).
ELMo يمكن استخدامها لمختلف المهام في البرمجة اللغوية العصبية. على سبيل المثال ، لمهمتنا ، يمكن إرسال متجهات الرسائل المستلمة باستخدام ELMo إلى مصنف ML الكلاسيكي أو استخدام شبكة تلافيفية أو متصلة بالكامل.
تعتبر حفلات ELMo المدربة مسبقًا سهلة الاستخدام لمهمتك ، ويمكن العثور على مثال للاستخدام
هنا .
ميزات التنفيذ
قارورة API
تمت كتابة النموذج الأولي API في Flask ، حيث أنه سهل الاستخدام.
صورتين عامل الميناء
بالنسبة للنشر ، استخدمنا صورتين لرسو السفن: الصورة الأساسية ، حيث تم تثبيت جميع التبعيات ، والصورة الرئيسية لبدء تشغيل التطبيق. يعمل هذا على توفير وقت التجميع بشكل كبير ، حيث نادراً ما يتم إعادة بناء الصورة الأولى ، وهذا يوفر الوقت أثناء النشر. يقضي الكثير من الوقت في بناء وتحميل مكتبات التعلم الآلي ، وهو أمر غير ضروري مع كل التزام.
تجريب
خصوصية تنفيذ عدد كبير إلى حد ما من خوارزميات التعلم الآلي هو أنه حتى مع وجود مقاييس عالية حول مجموعة التحقق من الصحة ، يمكن أن تكون الجودة الحقيقية للخوارزمية في الإنتاج منخفضة. لذلك ، لاختبار تشغيل الخوارزمية ، استخدم الفريق بأكمله الروبوت في سلاك. هذا مناسب للغاية ، لأن أي عضو في الفريق يمكنه التحقق من الاستجابة التي تقدمها الخوارزميات لرسالة معينة. تتيح لك طريقة الاختبار هذه أن ترى على الفور كيف ستعمل الخوارزميات على البيانات الحية.
البديل الجيد هو إطلاق الحل في المواقع العامة مثل Yandex Toloka و AWS Mechanical Turk.
استنتاج
درسنا عدة طرق لحل مشكلة الإشراف التلقائي للرسائل ووصفنا ميزات تنفيذنا.
الملاحظات الرئيسية التي تم الحصول عليها أثناء العمل:
- يسمح البحث عن القاموس وخوارزمية التعلم الآلي بناءً على TF-IDF والانحدار اللوجستي بتصنيف الرسائل بسرعة ، ولكن ليس دائمًا بشكل صحيح.
- خوارزميات الشبكة العصبية والنماذج المدروسة مسبقًا من حفلات الزفاف تتكيف بشكل أفضل مع هذه المهمة ويمكن أن تحدد السمية ضمن معنى الرسالة.
بالطبع ، قمنا بنشر عرض تجريبي مفتوح
للكشف عن تعليقات Poteha Toxic Comment على روبوت
Facebook . ساعدنا في جعل الروبوت أفضل!
سأكون سعيدًا للإجابة على الأسئلة الواردة في التعليقات.