مرحبا بالجميع. يقوم فريقي في Tinkoff ببناء أنظمة التوصية. إذا كنت راضيًا عن استرداد النقود الشهري ، فهذا عملنا. لقد صممنا أيضًا نظام توصيات للعروض الخاصة المقدمة من الشركاء ونشارك في مجموعات فردية من القصص في تطبيق Tinkoff. ونحن نحب المشاركة في مسابقات التعلم الآلي للحفاظ على أنفسنا في حالة جيدة.
لمدة شهرين من 18 فبراير إلى 18 أبريل ، عقدت مسابقة في Boosters.pro لبناء نظام توصيات يعتمد على بيانات حقيقية من واحدة من أكبر دور السينما الروسية على الإنترنت Okko . يهدف المنظمون إلى تحسين نظام التوصية الحالي. في الوقت الحالي ، تتوفر المسابقة في وضع الحماية ، حيث يمكنك اختبار أساليبك وصقل مهاراتك في بناء أنظمة التوصية.
وصف البيانات
يتم الوصول إلى المحتوى في Okko من خلال التطبيق على التلفزيون أو الهاتف الذكي ، أو من خلال واجهة الويب. يمكن استئجار المحتوى أو شراؤه (P) أو عرضه عن طريق الاشتراك (S). قدم منظم المسابقة بيانات عن مشاهدات الأيام N (N> 60) ، بالإضافة إلى ذلك ، كانت المعلومات حول التصنيفات والإشارات المرجعية متوفرة. تجدر الإشارة إلى أحد التفاصيل المهمة ، إذا شاهد المستخدم فيلمًا واحدًا عدة مرات أو عدة حلقات من المسلسل ، فسيتم تسجيل فقط تاريخ آخر معاملة وإجمالي الوقت المستغرق لكل وحدة محتوى في الجهاز اللوحي.
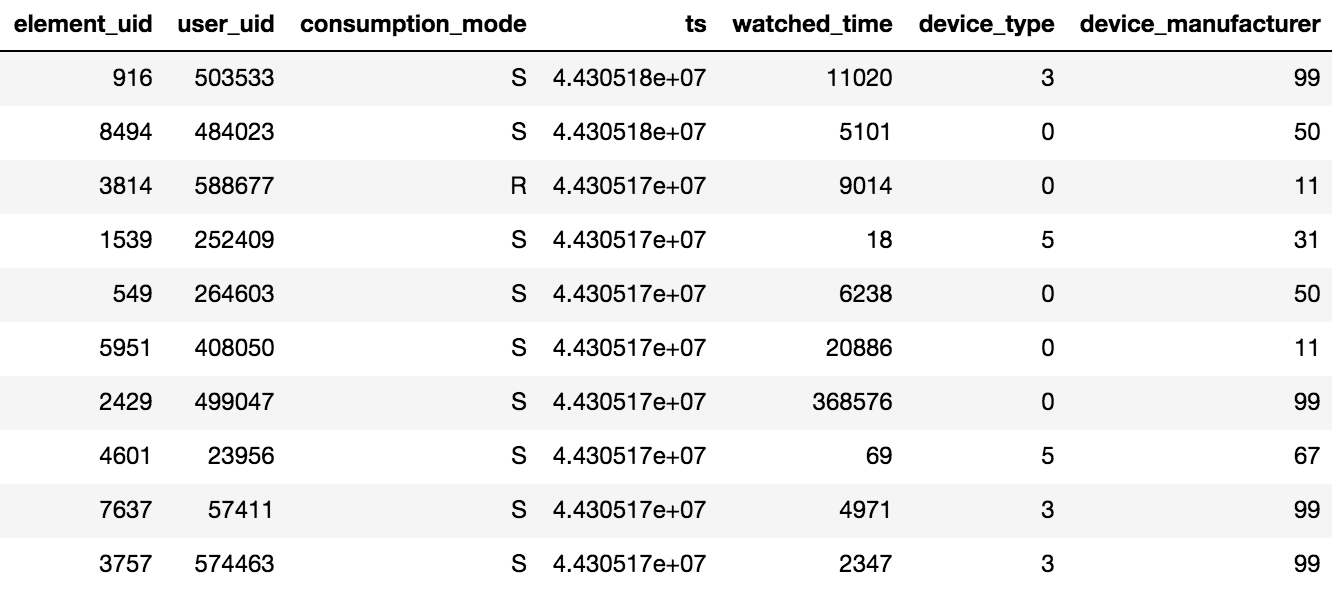
تم توفير حوالي 10 مليون معاملة و 450 ألف تقييم و 950 ألف حقائق مرجعية لـ 500 ألف مستخدم.
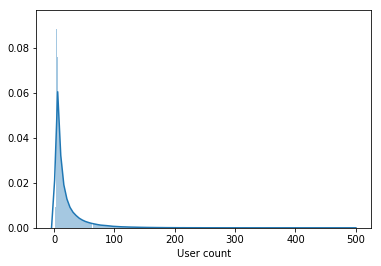
لا تحتوي العينة على مستخدمين نشطين فحسب ، بل تحتوي أيضًا على مستخدمين شاهدوا فيلمين طوال الفترة بأكملها.
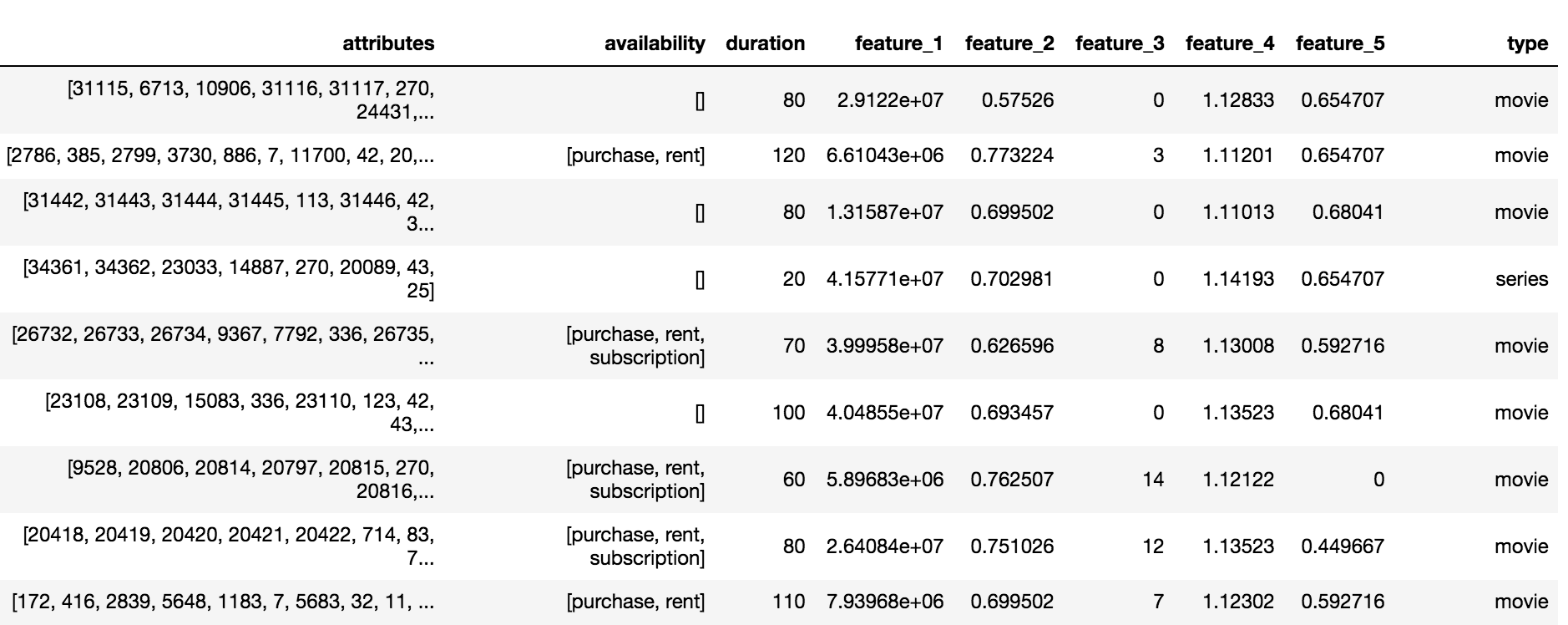
يحتوي كتالوج Okko على ثلاثة أنواع من المحتوى: الأفلام (الفيلم) ، السلسلة (السلسلة) والأفلام التسلسلية (multipart_movie) ، أي ما مجموعه 10200 كائن. بالنسبة لكل كائن ، كانت هناك مجموعة من السمات والسمات مجهولة الهوية (feature_1 ، ... ، feature_5) متوفرة ، والاشتراك ، أو التأجير أو توفر الشراء والمدة.
الهدف المتغير ومتري
المهمة المطلوبة للتنبؤ بالكثير من المحتوى الذي سيستهلكه المستخدم على مدار الستين يومًا القادمة. يُعتقد أن المستخدم سوف يستهلك المحتوى إذا:
- شرائه أو استئجاره
- شاهد أكثر من نصف الفيلم عن طريق الاشتراك
- شاهد أكثر من ثلث السلسلة عن طريق الاشتراك
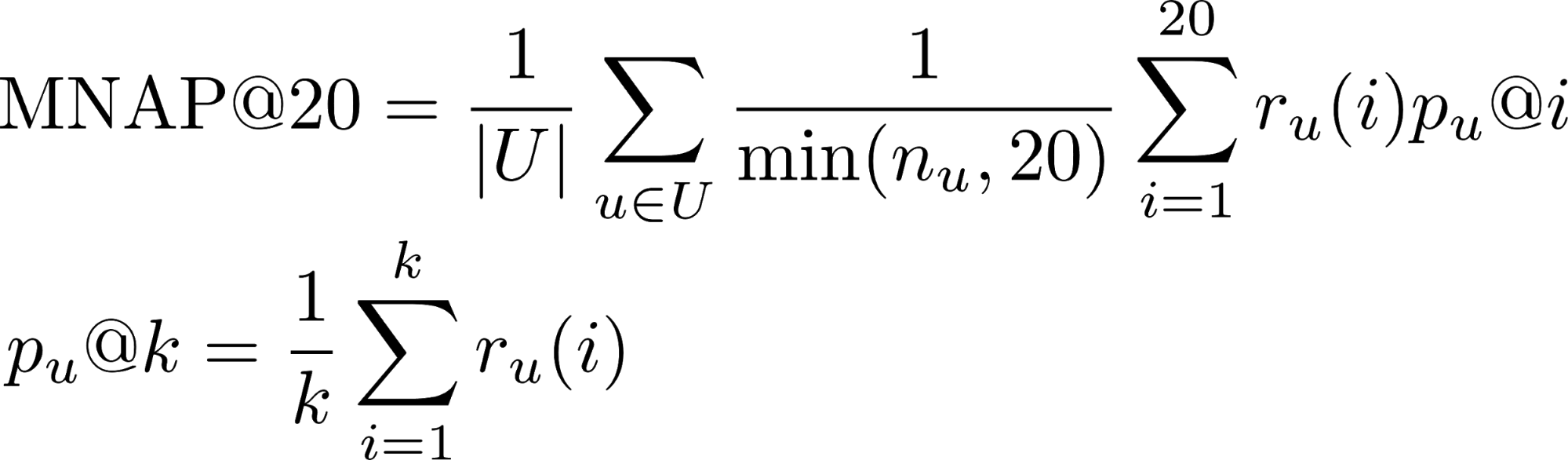
- r_u (i) - ما إذا كان المستخدم قد استهلك المحتوى الذي تنبأ به في المكان i (1 أو 0)
- n_u - عدد العناصر التي يستهلكها المستخدم أثناء فترة الاختبار
- U - العديد من مستخدمي الاختبار
يمكنك معرفة المزيد حول مقاييس مهمة التصنيف من هذا المنشور .
يشاهد معظم المستخدمين الأفلام حتى النهاية ، وبالتالي فإن حصة الفئة الإيجابية في المعاملات تبلغ 65٪. تم تقييم جودة الخوارزمية باستخدام مجموعة فرعية من 50 ألف مستخدم من العينة المقدمة.
تصنيف الكلي
بدأ قرار المنافسة بتجميع جميع تفاعلات المستخدم مع المحتوى في مقياس تصنيف واحد. كان من المفترض أنه إذا اشترى المستخدم المحتوى ، فإن هذا يعني أقصى فائدة. الفيلم أقصر من المسلسل ، لذلك لمشاهدة المسلسل ككل تحتاج إلى إعطاء المزيد من النقاط. نتيجة لذلك ، تم تكوين التصنيف الكلي وفقًا للقواعد التالية:
- حصة الفيلم * 5
- برنامج تلفزيوني Share * 10
- [إشارة مرجعية الفيلم] * 0.5
- [إشارة مرجعية السلسلة] * 1.5
- [شراء / استئجار محتوى] * 15
- التقييم + 2
نموذج المستوى الأول
قدم المنظمون حلاً أساسًا يعتمد على التصفية التعاونية باستخدام مقاييس Tf-IDF. إضافة جميع أنواع التفاعلات إلى التصنيف الكلي ، مما زاد عدد أقرب الجيران من 20 إلى 150 واستبدال Tf-IDF بأوزان BM25 التي خرجت عن 0.03 على LB (لوحة المتصدرين).
مستوحاة من وظيفة الفريق الذي احتل المركز الثالث في تحدي RecSys 2018 ، اخترت طراز LightFM مع خسارة WARP كنموذج أساسي ثانٍ. أعطت LightFM مع معلمات فرط مختارة: learning_rate ، no_components ، item_alpha ، user_alpha ، max_sampled 0.033 على LB.

تم إجراء التحقق من صحة النموذج في الوقت المحدد: وقع أول 80٪ من التفاعلات في القطار ، بينما تم التحقق من 20٪ المتبقية. لتقديم طلب على LB ، تم تدريب نموذج على مجموعة البيانات بأكملها مع تحديد المعلمات للتحقق من صحتها.
مزج النموذج
في المرحلة السابقة ، اتضح أن بناء خطين أساسيين قويين ، علاوة على ذلك ، تتقاطع توصياتهما في المتوسط مع 60 في المائة من المحتوى الموصى به. إذا كان هناك نموذجان قويان وفي نفس الوقت مترابطان بشكل ضعيف ، فإن مزجهما يعد خطوة معقولة.
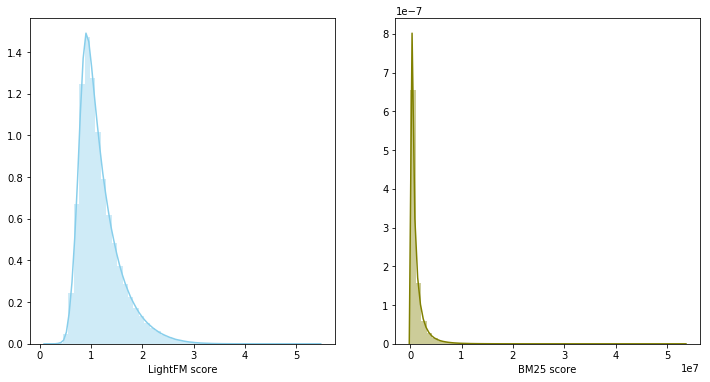
في هذه الحالة ، تنتمي درجات النموذج إلى توزيعات مختلفة ولديها مقاييس مختلفة ، لذلك تقرر استخدام مجموع الرتب لدمج النموذجين. حقق مزج النموذج 0.0347 على LB.

نموذج المستوى الثاني
غالبًا ما تستخدم الأنظمة الموصى بها مقاربة من مستويين لبناء النماذج: أولاً ، يتم اختيار المرشحين الأوائل بواسطة نموذج بسيط من المستوى الأول ، ثم يتم إعادة ترتيب القمة المحددة بنموذج أكثر تعقيدًا مع إضافة عدد كبير من الميزات.

تم تقسيم مجموعة البيانات في الوقت المناسب إلى أجزاء التدريب والتحقق من الصحة. تم جمع مجموعة مختارة من التوصيات لجزء التحقق من الصحة لكل مستخدم ، والذي يتكون من الجمع بين توقعات top200 لنماذج المستوى الأول باستثناء الأفلام التي تمت مشاهدتها بالفعل. علاوة على ذلك ، كان مطلوبًا لتعليم النموذج إعادة ترتيب الجزء العلوي الناتج لكل مستخدم. تمت صياغة المشكلة من حيث التصنيف الثنائي. ينتمي زوج (مستخدم ، محتوى) إلى الفئة الإيجابية فقط إذا كان المستخدم يستهلك المحتوى خلال فترة التحقق من الصحة. كنموذج من المستوى الثاني ، تم استخدام تعزيز التدرج ، وهي حزمة LightGBM.
دليل
تقوم نماذج المستوى الأول للأزواج (المستخدم ، المحتوى) بتقييم الأهمية في شكل سرعة ، وتصنيفًا يمكنك ترتيبه بترتيب تنازلي. توقف النموذج المدرب على علامات الرتبة والسرعة ، إلى جانب علامات من كتالوج المحتوى ، 0.0359 على LB.
من نموذج توزيع أول الميزات المجهولة الهوية ، استنتج أنه هو تاريخ ظهور الفيلم في الكتالوج ، لذلك ، تم إعادة تدريب النموذج بشدة لهذه الميزة باستخدام نظام التحقق المحدد. أعطت إزالة سمة من العينة زيادة في LB إلى 0.0367
يقوم نموذج LightFM ، بالإضافة إلى التنبؤ بأهمية المحتوى للمستخدم ، بإرجاع متجهين: تحيز العناصر وتحيز المستخدم ، والتي ترتبط بدرجة شعبية المحتوى وعدد الأفلام التي شاهدها المستخدم ، على التوالي. رفع علامات إضافة السرعة على LB إلى 0.0388 .
يمكنك تعيين تصنيف لزوج (مستخدم ، محتوى) إما قبل أو بعد حذف الأفلام التي تمت مشاهدتها بالفعل. قدمت التغييرات في الطريقة إلى زيادة في LB إلى 0.0395 .
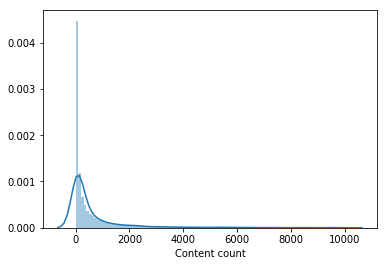
لم يشاهد أحد تقريبًا جزءًا كبيرًا من كتالوج الأفلام. تمت إزالة المحتوى الذي تمت مشاهدته بواسطة أقل من 100 مستخدم من العينة لتدريب نموذج المستوى الثاني ، مما قلل الفهرس بمقدار النصف. جعل إزالة المحتوى الذي لا يحظى بشعبية الاختيار من نماذج المستوى الأول أكثر ملاءمة وفقط بعد ذلك قام متجه المستخدمين من LightFM بتحسين سرعة التحقق من الصحة وقدم زيادة على LB إلى 0.0429 .
علاوة على ذلك ، تمت إضافة علامة - أضاف المستخدم الإشارة المرجعية إلى الكتاب ، لكنه لم يطلع على فترة القطار ، مما رفع السرعة على LB إلى 0.0447 . بالإضافة إلى ذلك ، تمت إضافة علامات حول تاريخ أول معاملات الماضي ، رفعوا السرعة إلى 0.0457 على LB.

سوف ننظر في هذا النموذج النهائي. وكانت أهمها علامات من نماذج المستوى الأول وعلامات مجهولة المصدر من كتالوج المحتوى.
لم تزد الميزات التالية إلى النموذج النهائي:
- عدد الإشارات المرجعية + مشاركة المحتوى المعروض من الإشارات المرجعية - 0.0453 LB
- عدد الأفلام المشتراة 0.0451 رطل
ولكن عند المزج مع النموذج النهائي ، خرجوا 0.0465 على LB. مستوحاة من نتائج المزج ، تم تدريب النماذج التالية بشكل منفصل:
- مع الكسور المختلفة من عينة التدريب لنموذج المستوى الأول. أعطى الانقسام بنسبة 90 ٪ / 10 ٪ زيادة ، على عكس الانقسام بنسبة 95 ٪ / 5 ٪ و 70 ٪ / 30 ٪.
- مع طريقة تجميع تصنيف المعدل.
- مع إضافة الأفلام التي لا تحظى بشعبية إلى مجموعة التدريب لنموذج المستوى الثاني. لكل وحدة محتوى ، تم تجميع مجموعة من 1000 مستخدم.
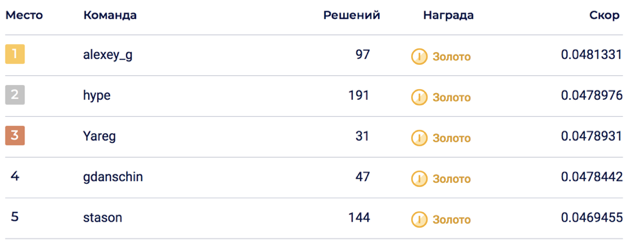
سمح المزج النهائي من 6 نماذج لتحقيق 0.0469678 على LB ، والتي تتوافق مع المركز الخامس.

على الجانب الخاص ، حدث هزة ، الأمر الذي أدى إلى حل المركز الثاني. أعتقد أن الحل تحول إلى استدامة بفضل المزج بين عدد كبير من النماذج.
لم تدخل
في عملية حل المنافسة ، تم إنشاء العديد من الإشارات التي بدا أنها بالتأكيد تدخل ، ولكن للأسف. العلامات والمناهج الأكثر ثقة:
- سمات محتوى مجهولة. لم يكن معروفًا على وجه اليقين ما تحتويه ، ولكن اعتقد جميع المشاركين في المسابقة أنهم احتووا على معلومات حول الممثلين والمخرجين والملحنين ... في قراري حاولت إضافتهم بتنسيقات متعددة: الأكثر شهرة كأحرف ثنائية ، وضع مصفوفة من المحتوى السمات التي تستخدم LightFM و BigARTM ، ثم اسحب المتجهات وإضافتها إلى طراز المستوى الثاني.
- متجهات المحتوى من نموذج LigthFM في نموذج المستوى الثاني.
- سمات الأجهزة التي شاهد المستخدم منها المحتوى.
- خفض وزن المحتوى الشعبي لنموذج المستوى الثاني.
- نسبة الأفلام / العروض التليفزيونية بالنسبة إلى العدد الإجمالي للمحتوى الذي تمت مشاهدته.
- ترتيب المقاييس من CatBoost.
حقائق مثيرة للاهتمام حول المنافسة
- تبين أن حل Top1 أسوأ من طراز منتج okko 0.048 مقابل 0.062. يجب أن يؤخذ في الاعتبار أن طراز المنتج قد تم إطلاقه بالفعل في وقت أخذ العينات.
- بعد حوالي أسبوع من بدء المسابقة ، تم تغيير مجموعة البيانات ، لأولئك الذين شاركوا منذ البداية قاموا بإضافة 30 طلبًا ، والتي تم إحراقها بشكل غير متوقع بعد دمج الفرق.
- لا يرتبط التحقق من الصحة دائمًا بـ LB ، مما يشير إلى حدوث هزة محتملة.
رمز القرار
الحل متاح على github في شكل جهازي كمبيوتر محمول من نوع jupyter: تصنيف التجميع ، ونماذج التدريب في المستويين الأول والثاني.
حل المركز الثالث متاح أيضًا على جيثب .
قرار المنظمين
بدلاً من ألف كلمة ، أرفق أهم ميزات المنظمين.
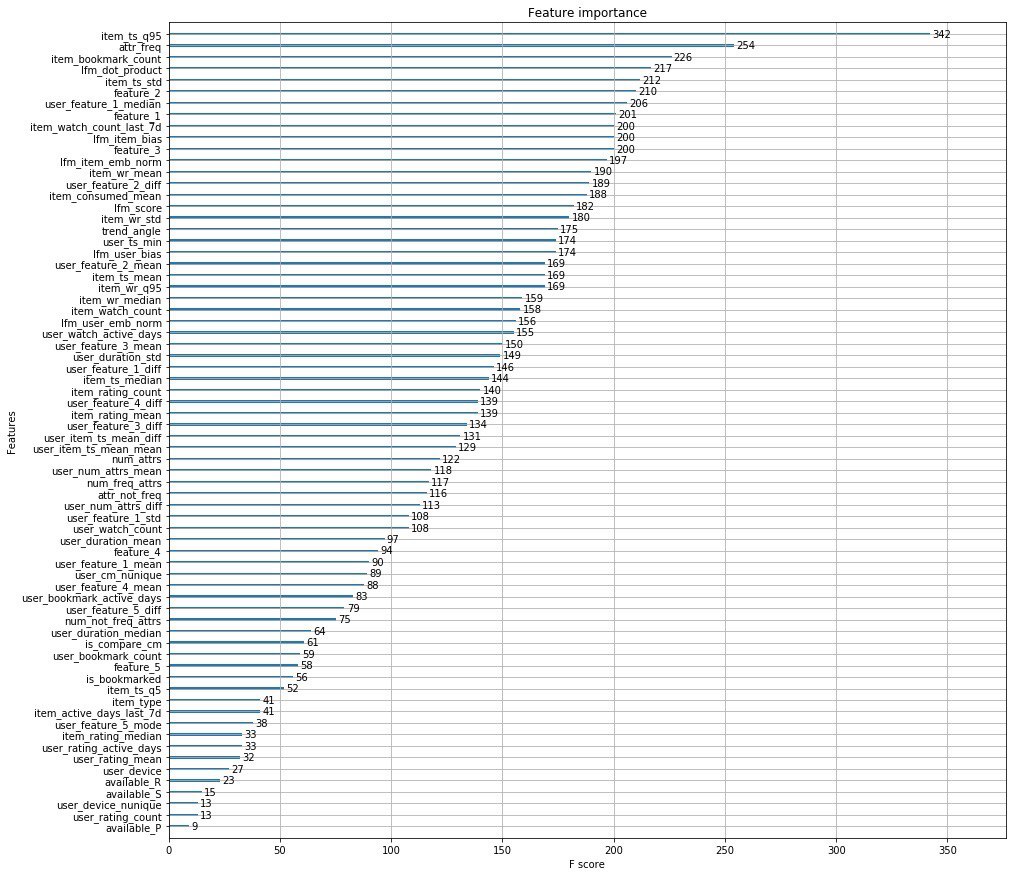
بالإضافة إلى ذلك ، أصدر شباب Okko مقالاً يتحدثون فيه عن مراحل تطور محرك توصياتهم.
ملاحظة هنا يمكنك رؤية الأداء في Data Fest 6 حول هذا الحل للمشكلة.