مرحبًا ، أنا أقوم بتطوير تطبيقات لـ
Tarantool DBMS - هذا نظام أساسي طورته مجموعة Mail.ru والذي يجمع بين DBMS عالي الأداء وخادم تطبيقات بلغة Lua. يتم تحقيق السرعة العالية للحلول المستندة إلى Tarantool ، على وجه الخصوص ، من خلال دعم وضع DBMS في الذاكرة والقدرة على تنفيذ منطق تطبيق الأعمال في مساحة عنوان واحدة مع البيانات. هذا يضمن استمرار البيانات باستخدام المعاملات ACID (يتم الاحتفاظ بسجل WAL على القرص). يحتوي Tarantool على دعم النسخ المتماثل والمشاركة المدمج. بدءًا من الإصدار 2.1 ، يتم دعم استعلامات SQL. Tarantool مفتوح المصدر ومرخص بموجب BSD المبسطة. هناك أيضًا إصدار Enterprise تجاري.
 اشعر بالقوة! (... ويعرف أيضا باسم الأداء)
اشعر بالقوة! (... ويعرف أيضا باسم الأداء)كل ما سبق يجعل Tarantool منصة جذابة لإنشاء تطبيقات قواعد البيانات المحملة للغاية. في مثل هذه التطبيقات ، يصبح تكرار البيانات ضروريًا في كثير من الأحيان.
كما ذكر أعلاه ، يحتوي Tarantool على النسخ المتماثل للبيانات المضمّن. مبدأ عملها هو التنفيذ المتسلسل على النسخ المتماثلة لكافة المعاملات الموجودة في سجل المعالج (WAL). عادةً ما يتم استخدام مثل هذا النسخ المتماثل (نسميها
المستوى المنخفض أدناه) لتوفير التسامح مع الخطأ للتطبيق و / أو لتوزيع عبء القراءة بين عقد الكتلة.
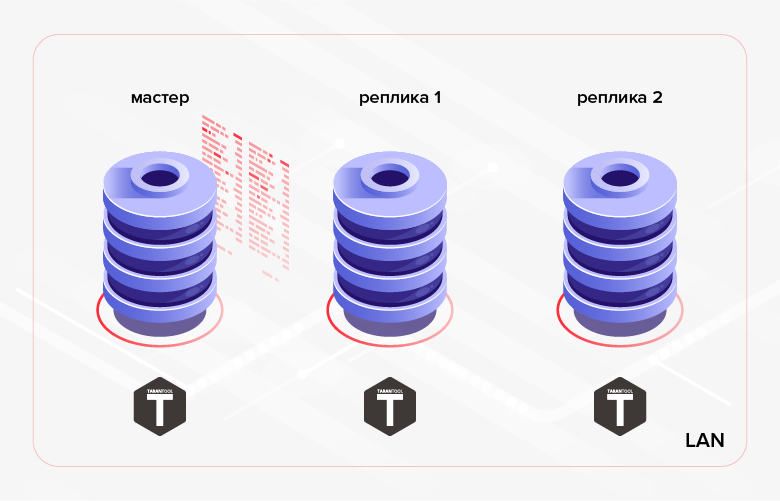 التين. 1. النسخ المتماثل داخل الكتلة
التين. 1. النسخ المتماثل داخل الكتلةمثال على سيناريو بديل هو نقل البيانات التي تم إنشاؤها في قاعدة بيانات واحدة إلى قاعدة بيانات أخرى للمعالجة / الرصد. في الحالة الأخيرة ، قد يكون الحل الأكثر ملاءمة هو استخدام النسخ المتماثل
عالي المستوى - النسخ المتماثل للبيانات على مستوى منطق العمل للتطبيق. أي لا نستخدم حلاً جاهزًا مدمجًا في نظام إدارة قواعد البيانات ، لكننا ننفذ عملية النسخ المتماثل داخل التطبيق الذي نقوم بتطويره. هذا النهج له مزايا وعيوب. نحن قائمة الايجابيات.
1. حفظ حركة المرور:
- لا يمكنك نقل جميع البيانات ، ولكن فقط جزء منها (على سبيل المثال ، يمكنك فقط نقل بعض الجداول ، وبعض الأعمدة أو السجلات التي تفي بمعايير معينة) ؛
- على عكس النسخ المتماثل المنخفض المستوى ، والذي يتم تنفيذه بشكل مستمر في غير متزامن (يتم تنفيذه في الإصدار الحالي من Tarantool - 1.10) أو متزامن (يتم تنفيذه في الإصدارات المستقبلية من Tarantool) ، يمكن إجراء النسخ المتماثل عالي المستوى بواسطة الجلسات (على سبيل المثال ، يقوم التطبيق أولاً بمزامنة البيانات - جلسة التبادل البيانات ، ثم هناك توقف مؤقت في النسخ المتماثل ، وبعدها تحدث جلسة التبادل التالية ، وما إلى ذلك) ؛
- إذا تم تغيير السجل عدة مرات ، فيمكنك نقل الإصدار الأخير فقط (على عكس النسخ المتماثل المنخفض المستوى ، حيث سيتم تشغيل جميع التغييرات التي تم إجراؤها على المعالج بالتسلسل على النسخ المتماثلة).
2. لا توجد صعوبات في تنفيذ التبادل عبر HTTP ، والذي يسمح لك بمزامنة قواعد البيانات عن بعد.
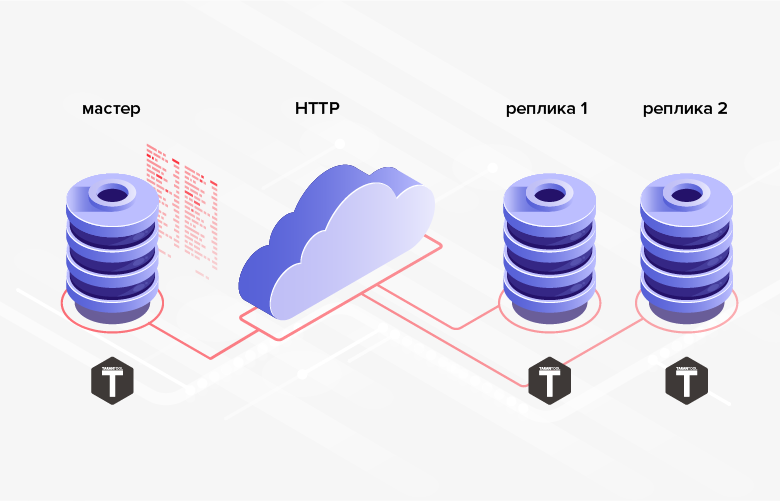 التين. 2. تكرار HTTP
التين. 2. تكرار HTTP3. لا يتعين أن تكون هياكل قواعد البيانات التي يتم نقل البيانات بينها هي نفسها (علاوة على ذلك ، في الحالة العامة ، يمكن حتى استخدام قواعد بيانات قواعد البيانات ولغات البرمجة والأنظمة الأساسية وما إلى ذلك).
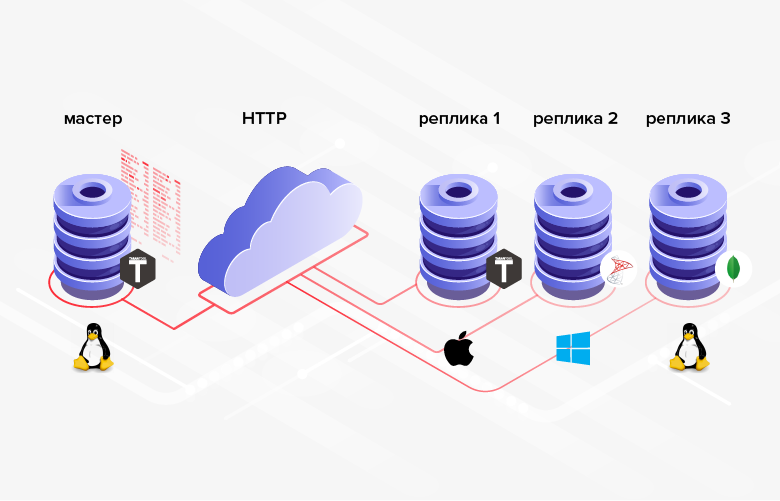 التين. 3. التكرار في النظم غير المتجانسة
التين. 3. التكرار في النظم غير المتجانسةالجانب السلبي هو أن البرمجة في المتوسط أكثر تعقيدًا / أكثر تكلفة من التكوين ، وبدلاً من إعداد الوظيفة المضمنة ، سيتعين عليك تنفيذ عملك.
إذا لعبت المزايا المذكورة أعلاه في موقفك دورًا حاسمًا (أو شرطًا ضروريًا) ، فمن المنطقي استخدام النسخ المتماثل عالي المستوى. دعنا نفكر في عدة طرق لتطبيق النسخ المتماثل للبيانات على مستوى عالٍ في Tarantool DBMS.
تقليل حركة المرور
لذلك ، واحدة من فوائد النسخ المتماثل رفيع المستوى هو توفير حركة المرور. لكي تظهر هذه الميزة بالكامل ، من الضروري تقليل مقدار البيانات المرسلة خلال كل جلسة تبادل. بالطبع ، لا ينبغي لأحد أن ينسى أنه في نهاية الجلسة يجب مزامنة مستقبِل البيانات مع المصدر (على الأقل بالنسبة لجزء البيانات المتضمنة في النسخ المتماثل).
كيفية تقليل كمية البيانات المنقولة أثناء النسخ المتماثل رفيع المستوى؟ قد يكون الحل "في الجبهة" هو اختيار البيانات حسب وقت التاريخ. للقيام بذلك ، يمكنك استخدام حقل وقت التاريخ الموجود بالفعل في الجدول (إن وجد). على سبيل المثال ، قد يحتوي المستند "ترتيب" على حقل "الوقت المطلوب لتنفيذ الأمر" -
delivery_time . المشكلة في هذا الحل هي أن القيم في هذا الحقل لا يجب أن تكون بالتسلسل المطابق لإنشاء الطلبات. وبالتالي ، لا يمكننا تذكر الحد الأقصى لقيمة حقل
delivery_time المرسلة أثناء جلسة التبادل السابقة ، وفي جلسة التبادل التالية ، حدد جميع السجلات ذات القيمة الأعلى لحقل
delivery_time . في الفترة الفاصلة بين جلسات التبادل ، يمكن إضافة السجلات ذات القيمة الأصغر لحقل
delivery_time . أيضًا ، قد يخضع الأمر للتغييرات ، والتي لم تؤثر على حقل
delivery_time . في كلتا الحالتين ، لن يتم نقل التغييرات من المصدر إلى المتلقي. لحل هذه المشكلات ، سنحتاج إلى نقل البيانات "تداخل". أي أثناء كل جلسة تبادل ، سنقوم بنقل جميع البيانات بقيمة حقل التسليم_تجاوز نقطة في الماضي (على سبيل المثال ، N ساعة من اللحظة الحالية). ومع ذلك ، فمن الواضح أنه بالنسبة للأنظمة الكبيرة ، هذا النهج لا لزوم له للغاية ويمكن أن يقلل من وفورات حركة المرور التي نهدف إليها. بالإضافة إلى ذلك ، قد لا يحتوي الجدول المرسل على حقل وقت للتاريخ.
حل آخر ، أكثر تعقيدًا من حيث التنفيذ ، هو الاعتراف باستلام البيانات. في هذه الحالة ، في كل جلسة تبادل ، يتم إرسال جميع البيانات ، والتي لم يتم تأكيد استلامها من قبل المستلم. للتنفيذ ، تحتاج إلى إضافة عمود منطقي إلى الجدول المصدر (على سبيل المثال ،
is_transferred ). إذا أكد المستلم استلام السجل ، فسيتم تعيين الحقل المقابل على
true ، وبعد ذلك لم يعد السجل مشتركًا في عمليات التبادل. يحتوي خيار التنفيذ هذا على العيوب التالية. أولاً ، لكل سجل يتم نقله ، من الضروري إنشاء تأكيد وإرساله. بمعنى تقريبي ، يمكن أن يكون هذا مشابهًا لمضاعفة كمية البيانات المنقولة مما يؤدي إلى مضاعفة عدد الرحلات ذهابًا وإيابًا. ثانياً ، لا توجد إمكانية لإرسال السجل نفسه إلى عدة أجهزة استقبال (سيؤكد المستقبل الأول الإيصال لأنفسهم ولصالح الجميع).
تتمثل الطريقة ، الخالية من العيوب المذكورة أعلاه ، في إضافة أعمدة إلى الجدول المطلوب إرسالها لتتبع التغييرات في صفوفها. يمكن أن يكون هذا العمود من نوع التاريخ والوقت ويجب تعيينه / تحديثه من قبل التطبيق للوقت الحالي في كل مرة تقوم بإضافة / تغيير السجلات (تلقائيًا مع إضافة / تغيير). كمثال ، دعنا نسمي العمود
update_time . بعد حفظ الحد الأقصى لقيمة حقل هذا العمود للسجلات المنقولة ، يمكننا بدء جلسة التبادل التالية من هذه القيمة (حدد السجلات التي تزيد قيمة حقل
update_time عن القيمة المحفوظة مسبقًا). المشكلة في الأسلوب الأخير هي أن تغييرات البيانات يمكن أن تحدث في وضع الدُفعات. نتيجةً لذلك ،
update_time لا تكون قيم الحقل في عمود
update_time فريدة. وبالتالي ، لا يمكن استخدام هذا العمود في إخراج بيانات الدُفعات (الصفحة). بالنسبة لإخراج بيانات الصفحة بصفحة ، سيكون من الضروري اختراع آليات إضافية من المحتمل أن تكون ذات كفاءة منخفضة للغاية (على سبيل المثال ، استرجاع جميع السجلات من قاعدة البيانات من خلال
update_time أعلى من القيمة المحددة وإصدار عدد معين من السجلات ، بدءًا من إزاحة معينة من بداية العينة).
يمكنك زيادة كفاءة نقل البيانات عن طريق تحسين النهج السابق بشكل طفيف. للقيام بذلك ، سوف نستخدم نوعًا صحيحًا (عددًا صحيحًا طويلًا) كقيم لحقول العمود لتتبع التغييرات.
row_ver العمود
row_ver . لا يزال يجب تعيين / تحديث قيمة الحقل لهذا العمود في كل مرة يتم فيها إنشاء / تعديل سجل. ولكن في هذه الحالة ، سيتم تخصيص الحقل ليس للوقت الحالي للتاريخ ، ولكن قيمة بعض العدادات تزداد بواحد. نتيجةً لذلك ،
row_ver عمود
row_ver على قيم فريدة ويمكن استخدامه ليس فقط لإخراج بيانات "دلتا" (البيانات المضافة / التي تم تغييرها بعد نهاية جلسة التبادل السابقة) ، ولكن أيضًا بالنسبة لصفحات ترقيم الصفحات البسيطة والفعالة.
يبدو أن الطريقة الأخيرة المقترحة لتقليل كمية البيانات المنقولة كجزء من النسخ المتماثل الرفيع المستوى هي الأكثر مثالية وعالمية. دعونا نتناولها بمزيد من التفاصيل.
نقل البيانات باستخدام صف الإصدار العداد
الخادم / التنفيذ الرئيسي
في MS SQL Server ، لتطبيق هذا النهج ، هناك نوع عمود خاص -
rowversion . تحتوي كل قاعدة بيانات على عداد ، والذي يزيد بمقدار واحد في كل مرة تقوم فيها بإضافة / تغيير سجل في جدول يحتوي على عمود من النوع
rowversion . يتم تعيين قيمة هذا العداد تلقائيًا إلى حقل هذا العمود في السجل المُضاف / المُغيّر. لا يحتوي Tarantool DBMS على آلية مضمنة مشابهة. ومع ذلك ، في Tarantool ، ليس من الصعب تنفيذه يدويًا. النظر في كيفية القيام بذلك.
أولاً ، مصطلحات صغيرة: تسمى الجداول في Tarantool المساحة ، وتسمى السجلات tuple. في Tarantool ، يمكنك إنشاء تسلسلات. التسلسلات ليست أكثر من المولدات المسماة للقيم الصحيحة للأعداد الصحيحة. أي هذا هو بالضبط ما نحتاجه لأغراضنا. أدناه سنقوم بإنشاء مثل هذا التسلسل.
قبل تنفيذ أي عملية قاعدة بيانات في Tarantool ، يجب تشغيل الأمر التالي:
box.cfg{}
نتيجة لذلك ، سيبدأ Tarantool في كتابة اللقطات وسجل المعاملات إلى الدليل الحالي.
إنشاء تسلسل
row_version :
box.schema.sequence.create('row_version', { if_not_exists = true })
يتيح
if_not_exists الخيار
if_not_exists تشغيل البرنامج النصي
if_not_exists عدة مرات: إذا كان الكائن موجودًا ، فلن يحاول Tarantool إعادة إنشائه. سيتم استخدام هذا الخيار في جميع أوامر DDL اللاحقة.
لنقم بإنشاء مساحة كمثال.
box.schema.space.create('goods', { format = { { name = 'id', type = 'unsigned' }, { name = 'name', type = 'string' }, { name = 'code', type = 'unsigned' }, { name = 'row_ver', type = 'unsigned' } }, if_not_exists = true })
هنا نقوم بتعيين اسم المسافة (
goods ) ، أسماء الحقول وأنواعها.
يتم إنشاء حقول زيادة تلقائية Tarantool أيضًا باستخدام تسلسلات. قم بإنشاء مفتاح أساسي تلقائي الزيادة في حقل
id :
box.schema.sequence.create('goods_id', { if_not_exists = true }) box.space.goods:create_index('primary', { parts = { 'id' }, sequence = 'goods_id', unique = true, type = 'HASH', if_not_exists = true })
يدعم Tarantool عدة أنواع من الفهارس. في معظم الأحيان ، يتم استخدام فهارس من أنواع TREE و HASH ، والتي تستند إلى الهياكل المقابلة للاسم. TREE هو نوع الفهرس الأكثر تنوعًا. انها تسمح لك لاستعادة البيانات بطريقة مرتبة. ولكن لاختيار المساواة ، HASH هو أكثر ملاءمة. وفقًا لذلك ، من المستحسن استخدام HASH للمفتاح الأساسي (وهو ما فعلناه).
لاستخدام عمود
row_ver لنقل البيانات التي تم تغييرها ، يجب عليك ربط قيم تسلسل
row_ver بالحقول في هذا العمود. ولكن على عكس المفتاح الأساسي ، يجب زيادة قيمة الحقل في عمود
row_ver بواحد ، ليس فقط عند إضافة سجلات جديدة ، ولكن أيضًا عند تغيير السجلات الحالية. للقيام بذلك ، يمكنك استخدام المشغلات. يحتوي Tarantool على نوعين من المشغّلات للمسافات:
before_replace و
on_replace . يتم تشغيل المشغّلات في كل مرة يتم فيها تغيير البيانات الموجودة في المساحة (لكل وظيفة تتأثر بالتغييرات ، يتم تشغيل وظيفة المشغل). على عكس
on_replace ، تتيح لك المشغلات
before_replace تعديل بيانات المجموعة التي تم تنفيذ المشغل من أجلها. وفقا لذلك ، فإن النوع الأخير من المشغلات يناسبنا.
box.space.goods:before_replace(function(old, new) return box.tuple.new({new[1], new[2], new[3], box.sequence.row_version:next()}) end)
يستبدل هذا المشغل قيمة الحقل
row_ver من tuple المخزنة
row_version تسلسل
row_version التالي.
لتتمكن من استخراج البيانات من مساحة
goods في عمود
row_ver ، قم بإنشاء فهرس:
box.space.goods:create_index('row_ver', { parts = { 'row_ver' }, unique = true, type = 'TREE', if_not_exists = true })
نوع الفهرس هو شجرة (
TREE ) ، لأن نحتاج إلى استرداد البيانات بترتيب تصاعدي للقيم في العمود
row_ver .
أضف بعض البيانات إلى الفضاء:
box.space.goods:insert{nil, 'pen', 123} box.space.goods:insert{nil, 'pencil', 321} box.space.goods:insert{nil, 'brush', 100} box.space.goods:insert{nil, 'watercolour', 456} box.space.goods:insert{nil, 'album', 101} box.space.goods:insert{nil, 'notebook', 800} box.space.goods:insert{nil, 'rubber', 531} box.space.goods:insert{nil, 'ruler', 135}
لأن الحقل الأول عبارة عن عداد زيادة تلقائية ، نمرّر صفراً بدلاً من ذلك. سيقوم Tarantool باستبدال القيمة التالية تلقائيًا. وبالمثل ، يمكنك تمرير قيمة nil كقيمة للحقول في العمود
row_ver - أو عدم تحديد القيمة على الإطلاق ، لأن هذا العمود يأخذ الموضع الأخير في الفضاء.
تحقق من نتيجة الإدراج:
tarantool> box.space.goods:select()
كما ترون ، تم ملء الحقل الأول والأخير تلقائيًا. الآن سيكون من السهل كتابة وظيفة لترحيل تفريغ
goods :
local page_size = 5 local function get_goods(row_ver) local index = box.space.goods.index.row_ver local goods = {} local counter = 0 for _, tuple in index:pairs(row_ver, { iterator = 'GT' }) do local obj = tuple:tomap({ names_only = true }) table.insert(goods, obj) counter = counter + 1 if counter >= page_size then break end end return goods end
تأخذ الوظيفة كمعلمة قيمة
row_ver للسجل الأخير المستلم (0 للمكالمة الأولى) وتُرجع المجموعة التالية من البيانات التي تم تغييرها (إذا كان هناك واحدًا ، وإلا صفيف فارغ).
يتم استرداد البيانات في Tarantool من خلال الفهارس. تستخدم الدالة
row_ver فهرس
row_ver لاسترداد البيانات التي تم تغييرها. نوع التكرار هو GT (أكبر من ، أكثر من). هذا يعني أن التكرار سوف يجتاز قيم الفهرس بالتتابع بدءًا من القيمة التالية بعد المفتاح الذي تم تمريره.
إرجاع التكرار tuples. لكي تتمكن لاحقًا من نقل البيانات عبر HTTP ، من الضروري تحويل المجموعات إلى هيكل مناسب للتسلسل اللاحق. في المثال ، يتم استخدام وظيفة
tomap القياسية لهذا الغرض. بدلا من استخدام
tomap يمكنك كتابة
tomap الخاصة. على سبيل المثال ، قد نرغب في إعادة تسمية حقل
name ، وليس اجتياز حقل
code ، وإضافة حقل
comment :
local function unflatten_goods(tuple) local obj = {} obj.id = tuple.id obj.goods_name = tuple.name obj.comment = 'some comment' obj.row_ver = tuple.row_ver return obj end
يتم تحديد حجم صفحة بيانات المخرجات (عدد السجلات في جزء واحد) بواسطة متغير
page_size . في المثال ، قيمة
page_size هي 5. في البرنامج الحقيقي ، يكون حجم الصفحة عادةً أكثر أهمية. ذلك يعتمد على متوسط حجم tuple الفضاء. يمكن تحديد حجم الصفحة الأمثل بشكل تجريبي عن طريق قياس وقت نقل البيانات. كلما زاد حجم الصفحة ، قل عدد الرحلات ذهابًا وإيابًا بين جانبي الإرسال والاستقبال. حتى تتمكن من تقليل الوقت الإجمالي لتحميل التغييرات. ومع ذلك ، إذا كان حجم الصفحة كبيرًا جدًا ، فسنأخذ الخادم وقتًا أطول من اللازم لإجراء تسلسل التحديد. نتيجة لذلك ، قد يكون هناك تأخير في معالجة الطلبات الأخرى التي تأتي إلى الخادم. يمكن تحميل المعلمة
page_size من ملف التكوين. لكل مساحة مرسلة ، يمكنك ضبط القيمة الخاصة بك. ومع ذلك ، بالنسبة لمعظم المسافات ، قد تكون القيمة الافتراضية (على سبيل المثال ، 100) مناسبة.
get_goods وظيفة
get_goods في الوحدة النمطية. قم بإنشاء ملف repl.lua يحتوي على وصف متغير
get_goods ووظيفة
get_goods . في نهاية الملف ، أضف وظيفة التصدير:
return { get_goods = get_goods }
لتحميل الوحدة ، قم بتنفيذ:
tarantool> repl = require('repl')
دعنا ننفذ وظيفة
get_goods :
tarantool> repl.get_goods(0)
خذ قيمة الحقل
row_ver من الصف الأخير
row_ver بالوظيفة مرة أخرى:
tarantool> repl.get_goods(5)
ومرة أخرى:
tarantool> repl.get_goods(8)
كما ترى ، بهذا الاستخدام ، تقوم الدالة صفحة تلو الأخرى بإرجاع كافة سجلات مساحة
goods . يتبع الصفحة الأخيرة تحديد فارغ.
سنقوم بإجراء تغييرات على الفضاء:
box.space.goods:update(4, {{'=', 6, 'copybook'}}) box.space.goods:insert{nil, 'clip', 234} box.space.goods:insert{nil, 'folder', 432}
قمنا بتغيير قيمة حقل
name لسجل واحد وقمنا بإضافة سجلين جديدين.
كرر استدعاء الوظيفة الأخيرة:
tarantool> repl.get_goods(8)
أرجعت الدالة السجلات التي تم تغييرها وإضافتها. وبالتالي ، تتيح
get_goods وظيفة
get_goods الحصول على البيانات التي تغيرت منذ آخر مكالمة لها ، والتي هي أساس طريقة النسخ المتماثل قيد النظر.
نترك نتائج النتائج عبر HTTP في شكل JSON خارج نطاق هذه المقالة. يمكنك أن تقرأ عنها هنا:
https://habr.com/ru/company/mailru/blog/272141/تنفيذ جزء العميل / العبد
النظر في ما يبدو تنفيذ الجانب المتلقي. قم بإنشاء مساحة على جانب الاستقبال لتخزين البيانات التي تم تنزيلها:
box.schema.space.create('goods', { format = { { name = 'id', type = 'unsigned' }, { name = 'name', type = 'string' }, { name = 'code', type = 'unsigned' } }, if_not_exists = true }) box.space.goods:create_index('primary', { parts = { 'id' }, sequence = 'goods_id', unique = true, type = 'HASH', if_not_exists = true })
تشبه بنية المساحة بنية المساحة في المصدر. ولكن نظرًا لأننا لن ننقل البيانات المستلمة في مكان آخر ، فإن عمود
row_ver في مساحة جهاز الاستقبال. في حقل
id سيتم كتابة معرفات المصدر. لذلك ، على جانب المتلقي ، ليست هناك حاجة لجعله زيادة تلقائية.
بالإضافة إلى ذلك ، نحتاج إلى مساحة لحفظ قيم
row_ver :
box.schema.space.create('row_ver', { format = { { name = 'space_name', type = 'string' }, { name = 'value', type = 'string' } }, if_not_exists = true }) box.space.row_ver:create_index('primary', { parts = { 'space_name' }, unique = true, type = 'HASH', if_not_exists = true })
لكل مساحة محملة (field
space_name ) ، سنوفر هنا
row_ver آخر قيمة محملة (
value الحقل). المفتاح الأساسي هو عمود
space_name .
لنقم بإنشاء وظيفة لتحميل بيانات مساحة
goods عبر HTTP. للقيام بذلك ، نحتاج إلى مكتبة تنفذ عميل HTTP. يحمّل السطر التالي المكتبة وينشئ عميل HTTP:
local http_client = require('http.client').new()
نحتاج أيضًا إلى مكتبة لإلغاء تسلسل json:
local json = require('json')
هذا يكفي لإنشاء وظيفة تحميل البيانات:
local function load_data(url, row_ver) local url = ('%s?rowVer=%s'):format(url, tostring(row_ver)) local body = nil local data = http_client:request('GET', url, body, { keepalive_idle = 1, keepalive_interval = 1 }) return json.decode(data.body) end
تقوم الدالة بتنفيذ طلب HTTP على عنوان url ، وتمرر
row_ver فيه كمعلمة ، وتُرجع النتيجة
row_ver من الطلب.
وظيفة حفظ البيانات المستلمة هي كما يلي:
local function save_goods(goods) local n = #goods box.atomic(function() for i = 1, n do local obj = goods[i] box.space.goods:put( obj.id, obj.name, obj.code) end end) end
يتم وضع دورة تخزين البيانات في مساحة
goods في المعاملات (يتم استخدام الدالة
box.atomic لهذا) لتقليل عدد عمليات القرص.
أخيرًا ، يمكن تنفيذ وظيفة تزامن
goods الفضائية المحلية مع المصدر على النحو التالي:
local function sync_goods() local tuple = box.space.row_ver:get('goods') local row_ver = tuple and tuple.value or 0
أولاً ، نقرأ قيمة
row_ver المحفوظة مسبقًا
row_ver goods . إذا كانت غائبة (جلسة التبادل الأولى) ،
row_ver الصفر كـ
row_ver . بعد ذلك ، في الحلقة ، نقوم بترقيم الصفحات المعدلة من المصدر إلى عنوان url المحدد. في كل تكرار ، نقوم بحفظ البيانات المستلمة في المساحة المحلية المقابلة وتحديث قيمة
row_ver (في
row_ver row_ver وفي متغير
row_ver ) - نأخذ قيمة
row_ver من الصف الأخير من البيانات المحملة.
للحماية من الحلقات العرضية (في حالة حدوث خطأ في البرنامج) ، يمكن استبدال
while بـ:
for _ = 1, max_req do ...
نتيجة لوظيفة
sync_goods ،
sync_goods goods في المستقبل على أحدث إصدارات جميع سجلات مساحة
goods في المصدر.
من الواضح أن حذف البيانات لا يمكن بثه بهذه الطريقة. في حالة وجود هذه الحاجة ، يمكنك استخدام علامة الحذف.
is_deleted الحقل المنطقي
is_deleted مساحة
goods وبدلاً من حذف السجل فعليًا ، استخدم الحذف المنطقي -
is_deleted قيمة الحقل
is_deleted إلى
true . في بعض الأحيان ، بدلاً من الحقل المنطقي
is_deleted ،
is_deleted أكثر ملاءمة لاستخدام الحقل
deleted ، الذي يخزن وقت تاريخ الحذف المنطقي للسجل. بعد إجراء الحذف المنطقي ، سيتم نقل السجل المحدد للحذف من المصدر إلى جهاز الاستقبال (وفقًا للمنطق الذي تمت مناقشته أعلاه).
يمكن استخدام تسلسل
row_ver لنقل البيانات من مسافات أخرى: ليست هناك حاجة لإنشاء تسلسل منفصل لكل مساحة مرسلة.
درسنا طريقة فعالة لتكرار البيانات عالية المستوى في التطبيقات التي تستخدم Tarantool DBMS.
النتائج
- يعتبر Tarantool DBMS منتجًا جذابًا واعدًا لإنشاء تطبيقات محملة للغاية.
- يوفر النسخ المتماثل عالي المستوى طريقة أكثر مرونة لنقل البيانات مقارنة بالنسخ المتماثل المنخفض المستوى.
- تسمح طريقة النسخ المتماثل عالية المستوى التي تم بحثها في المقالة لأحد تقليل كمية البيانات المرسلة عن طريق نقل السجلات التي تغيرت فقط منذ آخر جلسة تبادل.