HighLoad ++ موجود منذ فترة طويلة ، ونتحدث عن العمل مع PostgreSQL بانتظام. لكن المطورين ما زالوا يواجهون نفس المشكلات من شهر لآخر ، من سنة إلى أخرى. عندما تكون هناك أخطاء في التعامل مع قواعد البيانات في الشركات الصغيرة التي لا تحتوي على قواعد بيانات DBA ، فهذا ليس مفاجئًا. تحتاج الشركات الكبيرة أيضًا إلى قواعد بيانات ، وحتى مع العمليات التي يتم تصحيحها ، لا تزال الأخطاء تحدث وتسقط قواعد البيانات. لا يهم حجم الشركة - لا تزال تحدث أخطاء ، تعطل قواعد البيانات بشكل دوري ، تعطل.

بالطبع ، لن يحدث هذا لك أبدًا ، ولكن التحقق من قائمة التحقق ليس بالأمر الصعب ، وقد يكون من المناسب للغاية إنقاذ الأعصاب المستقبلية. تحت القطة ، سنذكر أهم الأخطاء النموذجية التي يرتكبها المطورين عند العمل مع PostgreSQL ، ونرى لماذا لا نحتاج إلى القيام بذلك ، ومعرفة كيف.
حول المتحدث: بدأ
Alexey Lesovsky كمسؤول لنظام Linux. من مهام المحاكاة الافتراضية ونظم الرصد جاءت تدريجيا إلى PostgreSQL. الآن PostgreSQL DBA في
Data Egret ، وهي شركة استشارية تعمل مع الكثير من المشاريع المختلفة وترى العديد من الأمثلة على المشكلات المتكررة. هذا
رابط لعرض التقرير في HighLoad ++ 2018.
من أين تأتي المشاكل؟
للتدفئة ، بعض القصص حول كيفية حدوث الأخطاء.
التاريخ 1. الميزات
إحدى المشكلات هي الميزات التي تستخدمها الشركة عند العمل مع PostgreSQL. كل شيء يبدأ بسيط: PostgreSQL ، مجموعات البيانات ، استعلامات بسيطة مع JOIN. نحن نأخذ البيانات ، والقيام SELECT - كل شيء بسيط.
ثم نبدأ في استخدام وظيفة PostgreSQL الإضافية ، وإضافة وظائف جديدة ، وملحقات. الميزة تكبر. نحن ربط تدفق النسخ المتماثل ، sharding. تظهر المرافق المختلفة ومجموعات الجسم حول - pgbouncer ، pgpool ، patroni. شيء من هذا القبيل.

كل كلمة رئيسية هي سبب لظهور خطأ.
التاريخ 2. تخزين البيانات
طريقة تخزين البيانات هي أيضًا مصدر للأخطاء.
عندما ظهر المشروع لأول مرة ، كان هناك عدد قليل من البيانات والجداول فيه. استعلامات بسيطة تكفي لتلقي وتسجيل البيانات. ولكن بعد ذلك هناك المزيد والمزيد من الجداول. يتم تحديد البيانات من أماكن مختلفة ، تظهر JOINs. الاستعلامات معقدة وتتضمن تصميمات CTE ، SUBQUERY ، IN IN ، LATERAL. يصبح ارتكاب خطأ وكتابة استعلام منحنى أسهل بكثير.
وهذه هي مجرد قمة جبل الجليد - في مكان ما على الجانب ، يمكن أن يكون هناك 400 جدول ، قسم ، يتم أيضًا من خلالها قراءة البيانات من حين لآخر.
التاريخ 3. دورة الحياة
قصة كيف يتم اتباع المنتج. يجب دائمًا تخزين البيانات في مكان ما ، لذلك هناك دائمًا قاعدة بيانات. كيف تتطور قاعدة البيانات عندما يتطور المنتج؟
من ناحية ، هناك
مطورين مشغولون بلغات البرمجة. يكتبون تطبيقاتهم ويطورون مهارات في مجال تطوير البرمجيات ، دون الاهتمام بالخدمات. غالبًا ما يكونون غير مهتمين بكيفية عمل Kafka أو PostgreSQL - فهم يطورون ميزات جديدة في تطبيقاتهم ، ولا يهتمون بالباقي.
 مدراء ،
مدراء ، من ناحية أخرى. إنها ترفع مثيلات Amazon الجديدة على Bare-metal وتشغلها الأتمتة: فهي تقوم بإعداد عمليات النشر لجعل التخطيط يعمل بشكل جيد ، ويقوم بالتهيئة بحيث تتفاعل الخدمات بشكل جيد مع بعضها البعض.

هناك موقف عندما لا يكون هناك وقت أو رغبة في ضبط المكونات ، وكذلك قاعدة البيانات. تعمل قواعد البيانات مع التكوينات الافتراضية ، ثم ينسونها تمامًا - "لا تعمل ، لا تلمسها".
نتيجة لذلك ، تنتشر الخليعون في أماكن مختلفة ، والتي تطير بين الحين والآخر في مقدمة المطورين. في هذه المقالة ، سنحاول جمع كل هذه المكابس في سقيفة واحدة حتى تعرفها ولا تتخطاها عند العمل مع PostgreSQL.
التخطيط والمراقبة
أولاً ، تخيل أن لدينا مشروعًا جديدًا - إنه دائمًا تطور نشط واختبار الفرضيات وتنفيذ ميزات جديدة. في الوقت الذي ظهر فيه التطبيق للتو وهو قيد التطوير ، فإنه يحتوي على عدد قليل من الزيارات والمستخدمين والعملاء ، ويقومون جميعهم بإنشاء كميات صغيرة من البيانات. تحتوي قاعدة البيانات على استعلامات بسيطة يتم معالجتها بسرعة. لا حاجة لسحب كميات كبيرة من البيانات ، لا توجد مشاكل.
ولكن هناك عدد أكبر من المستخدمين ، وتأتي حركة المرور: تظهر بيانات جديدة ، وتنمو قواعد البيانات وتتوقف الاستعلامات القديمة عن العمل. من الضروري إكمال الفهارس وإعادة كتابة الاستعلامات وتحسينها. هناك مشاكل في الأداء. كل هذا يؤدي إلى التنبيهات في الساعة 4 صباحًا ، والتوتر للمسؤولين وسخط الإدارة.
ما هو الخطأ؟
في تجربتي ، في معظم الأحيان لا توجد أقراص كافية.
المثال الأول . نفتح الجدول الزمني لمراقبة استخدام القرص ، ونرى أن
المساحة الخالية على القرص تنفد .
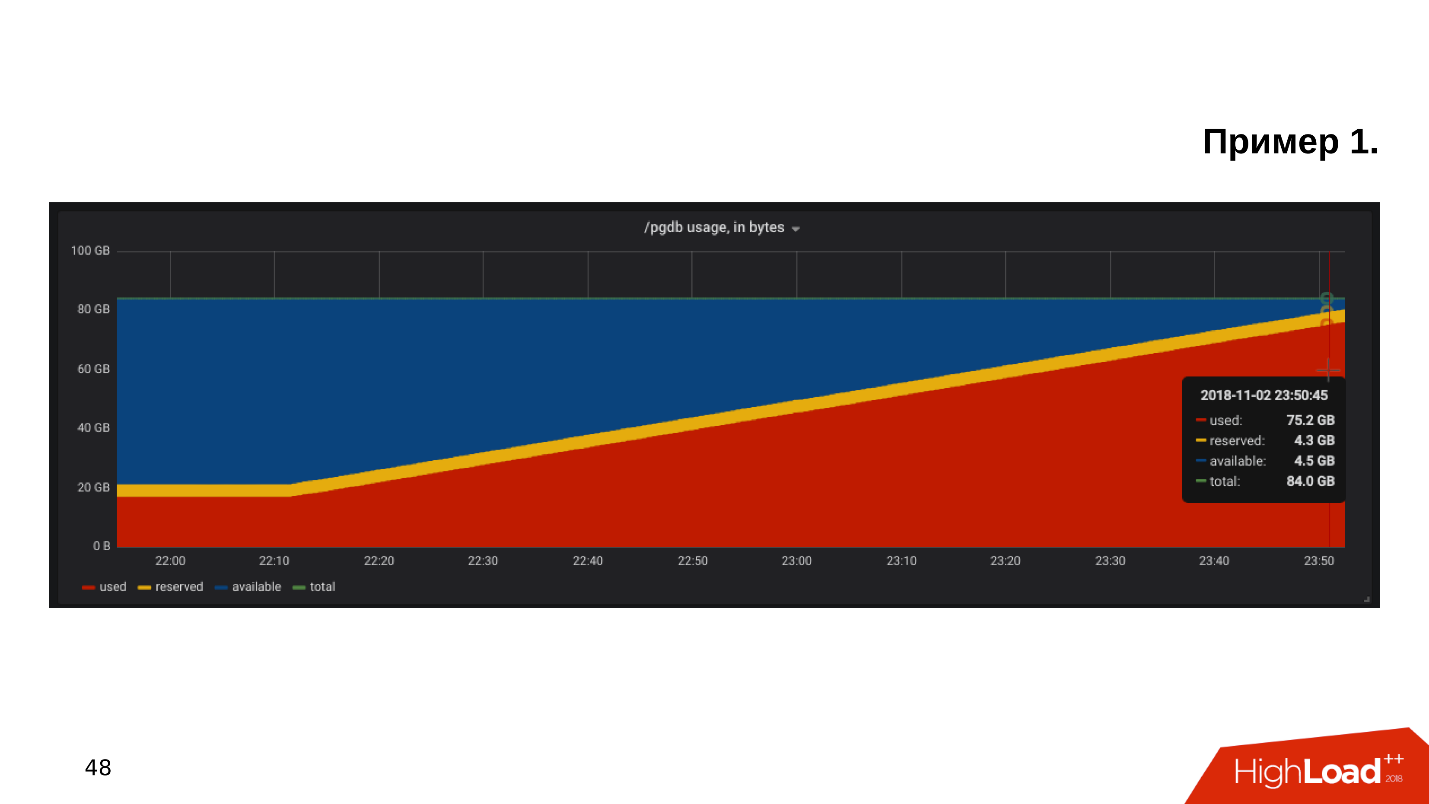
نحن ننظر إلى مقدار المساحة وما يتم تناوله - اتضح أن هناك دليل pg_xlog:
$ du -csh -t 100M /pgdb/9.6/main/* 15G /pgdb/9.6/main/base 58G /pgdb/9.6/main/pg_xlog 72G
يعرف مدراء قواعد البيانات عادةً ما هو هذا الدليل ، ولا يمسونه - إنه موجود وموجود. لكن المطور ، خاصةً إذا نظر إلى التدريج ، يخدش رأسه ويفكر:
- نوع من السجلات ... دعنا نحذف pg_xlog!حذف الدليل ، توقف قاعدة البيانات عن العمل . على الفور ، يتعين عليك google كيفية رفع قاعدة البيانات بعد حذف سجلات المعاملات.
 المثال الثاني
المثال الثاني . مرة أخرى ، نفتح المراقبة ونرى أنه لا توجد مساحة كافية. هذه المرة المكان الذي يشغله نوع من القاعدة.
$ du -csh -t 100M /pgdb/9.6/main/* 70G /pgdb/9.6/main/base 2G /pgdb/9.6/main/pg_xlog 72G
نحن نبحث عن قاعدة البيانات التي تشغل مساحة أكبر ، أي الجداول والفهارس.

اتضح أن هذا هو الجدول مع السجلات التاريخية. لم نحتاج أبدًا إلى سجلات تاريخية. مكتوبة فقط في حالة ، وإذا لم يكن لمشكلة المكان ، فلن ينظر إليها أحد حتى يأتي الثاني:
- دعونا تنظيف كل شيء مم ... أقدم من أكتوبر!قم بتقديم طلب تحديث ، وقم بتشغيله ، وسيعمل على حذف بعض الخطوط.
=# DELETE FROM history_log -# WHERE created_at < «2018-10-01»; DELETE 165517399 Time: 585478.451 ms
يعمل الاستعلام لمدة 10 دقائق ، لكن الجدول لا يزال يشغل نفس المساحة.
PostgreSQL يزيل الصفوف من الجدول - كل شيء على ما يرام ، لكنه لا يعيد المكان إلى نظام التشغيل. سلوك PostgreSQL هذا غير معروف لمعظم المطورين ويمكن أن يكون مفاجئًا للغاية.
المثال الثالث . على سبيل المثال ، قدم ORM طلبًا مثيرًا للاهتمام. عادةً ما يلوم الجميع ORM لإجراء استعلامات "سيئة" تقرأ بعض الجداول.
افترض أن هناك العديد من عمليات JOIN التي تقرأ الجداول بالتوازي في عدة مؤشرات ترابط. يمكن لـ PostgreSQL أن يوازي عمليات البيانات ويمكنه قراءة الجداول في خيوط متعددة. ولكن نظرًا لوجود العديد من خوادم التطبيقات ، يقرأ هذا الاستعلام جميع الجداول عدة آلاف من المرات في الثانية. اتضح أن خادم قاعدة البيانات محمّل بشكل زائد ، ولا يمكن أن تتعامل الأقراص ، وكل هذا يؤدي إلى خطأ
502 Bad Gateway من الواجهة الخلفية - قاعدة البيانات غير متوفرة.
لكن هذا ليس كل شيء. يمكنك استدعاء ميزات أخرى من PostgerSQL.
- الفرامل لعمليات DBMS الخلفية - PostgreSQL لديه جميع أنواع نقاط التفتيش ، والفراغات ، والنسخ المتماثل.
- النفقات العامة الافتراضية . عندما يتم تشغيل قاعدة البيانات على جهاز افتراضي ، على نفس قطعة الحديد ، توجد أيضًا أجهزة افتراضية على الجانب ، ويمكن أن تتعارض حول الموارد.
- يتم التخزين من الشركة المصنعة الصينية NoName ، التي يعتمد أداءها على القمر في الجدي أو موضع زحل ، ولا توجد طريقة لمعرفة سبب عمله بهذه الطريقة. القاعدة تعاني.
- التكوين الافتراضي . هذا هو الموضوع المفضل لدي: يقول العميل أن قاعدة البيانات الخاصة به تتباطأ - أنت تنظر ، ولديه تكوين افتراضي. الحقيقة هي أن تكوين PostgreSQL الافتراضي مصمم للعمل على أقداح إبريق الشاي . تم إطلاق القاعدة ، وهي تعمل ، لكن عندما تعمل بالفعل على أجهزة متوسطة المستوى ، فإن هذا التكوين لا يكفي ، يجب ضبطه.
في معظم الأحيان ، تفتقر PostgreSQL إما إلى مساحة القرص أو أداء القرص. لحسن الحظ ، مع كل من المعالجات والذاكرة والشبكة ، كقاعدة عامة ، كل شيء في ترتيب أكثر أو أقل.
كيف تكون تحتاج الرصد والتخطيط! يبدو الأمر واضحًا ، ولكن لسبب ما ، في معظم الحالات ، لا أحد يخطط لقاعدة ، والرصد لا يغطي كل ما يجب مراقبته أثناء تشغيل PostgreSQL. هناك مجموعة من القواعد الواضحة ، والتي سيعمل بها كل شيء بشكل جيد ، وليس "بشكل عشوائي".
تخطيط
استضافة قاعدة البيانات على SSD دون تردد . سواقات الأقراص الصلبة أصبحت طويلة موثوقة ومستقرة ومثمرة. كانت نماذج SSD للمؤسسات موجودة منذ سنوات.
دائما خطة مخطط البيانات . لا تكتب إلى قاعدة البيانات التي تشك في ما هو مطلوب - مضمونة بعدم الحاجة إليها. مثال بسيط هو جدول تم تعديله قليلاً لأحد عملائنا.

هذا هو جدول السجل الذي يوجد فيه عمود بيانات من النوع json. من الناحية النسبية ، يمكنك كتابة أي شيء في هذا العمود. من السجل الأخير من هذا الجدول ، يمكن ملاحظة أن السجلات تشغل 8 ميغابايت. ليس لدى PostgreSQL مشكلة في تخزين السجلات بهذا الطول. يحتوي PostgreSQL على تخزين جيد جدًا يمضغ هذه السجلات.
ولكن المشكلة هي أنه عندما تقرأ خوادم التطبيقات البيانات من هذا الجدول ، فإنها تسد نطاق الشبكة بالكامل بالكامل ، وستعاني الطلبات الأخرى. هذه هي مشكلة تخطيط مخطط البيانات.
استخدم التقسيم لأي تلميح لقصة يحتاج إلى تخزينه لأكثر من عامين . يبدو التقسيم في بعض الأحيان معقدًا - تحتاج إلى عناء مع المشغلات ، مع وظائف من شأنها إنشاء أقسام. في الإصدارات الجديدة من PostgreSQL ، يكون الموقف أفضل وأصبح الآن إعداد التقسيم أبسط بكثير - بمجرد الانتهاء ، ويعمل.
في المثال المدروس لحذف البيانات في 10 دقائق ، يمكن استبدال
DELETE بـ
DROP TABLE - تستغرق هذه العملية في ظروف مماثلة بضع ثوانٍ فقط.
عندما يتم فرز البيانات حسب القسم ، يتم حذف القسم حرفيًا في بضع ميلي ثانية ، ويتولى نظام التشغيل على الفور. إدارة البيانات التاريخية أسهل وأسهل وأكثر أمانًا.
مراقبة
المراقبة موضوع كبير منفصل ، ولكن من وجهة نظر قاعدة البيانات هناك توصيات يمكن أن تنسجم مع قسم واحد من المقال.
بشكل افتراضي ، توفر العديد من أنظمة المراقبة مراقبة المعالجات والذاكرة والشبكة ومساحة القرص ، ولكن كقاعدة عامة ،
لا يوجد التخلص من أجهزة القرص . معلومات حول كيفية تحميل الأقراص ، وعرض النطاق الترددي الموجود حاليًا على الأقراص ، ويجب دائمًا إضافة قيمة زمن الوصول إلى المراقبة. سيساعدك هذا في تقييم كيفية تحميل محركات الأقراص بسرعة.
هناك الكثير من خيارات مراقبة PostgreSQL ، لكل ذوق. وهنا بعض النقاط التي يجب أن تكون موجودة.
- عملاء متصلون . من الضروري مراقبة الحالات التي يعملون معها ، والعثور بسرعة على العملاء "الضارين" الذين يضرون قاعدة البيانات ، ويوقفون تشغيلها.
- خطأ. من الضروري مراقبة الأخطاء من أجل تتبع مدى نجاح قاعدة البيانات: لا توجد أخطاء - كبيرة ، ظهرت أخطاء - سبب للنظر إلى السجلات والبدء في فهم الأخطاء التي تحدث.
- الطلبات (البيانات) . نحن نراقب الخصائص الكمية والنوعية للطلبات من أجل تقييم ما إذا كان لدينا طلبات بطيئة أو طويلة أو كثيفة الاستخدام للموارد.
لمزيد من المعلومات ، راجع تقرير
"أساسيات مراقبة PostgreSQL" مع HighLoad ++ Siberia وصفحة
المراقبة في ويكي PostgreSQL.
عندما خططنا كل شيء و "غطينا أنفسنا" بالرصد ، لا يزال بإمكاننا مواجهة بعض المشاكل.
تدريج
عادةً ما يرى المطور سطر قاعدة البيانات في التكوين. لا يهتم بشكل خاص بكيفية ترتيبها داخليًا - كيف تعمل نقاط التفتيش والنسخ المتماثل وجدولة المواعيد. لدى المطور شيء ما يجب فعله بالفعل - هناك الكثير من الأشياء المثيرة للاهتمام التي يريد تجربتها.
"أعطني عنوان القاعدة ، ثم أنا نفسي." © مطور مجهول.
يؤدي الجهل بالموضوع إلى عواقب مثيرة جدًا عندما يبدأ المطور في كتابة استعلامات تعمل في قاعدة البيانات هذه. التخيلات عند كتابة الاستعلامات في بعض الأحيان تعطي تأثيرات مذهلة.
هناك نوعان من المعاملات.
معاملات OLTP سريعة وقصيرة وخفيفة الوزن تأخذ كسور من الثانية. إنهم ينجحون بسرعة كبيرة ، وهناك الكثير منهم.
OLAP - استعلامات تحليلية - بطيئة وطويلة وثقيلة ، وقراءة صفائف كبيرة من الجداول وقراءة الإحصاءات.
على مدار الأعوام الثلاثة إلى الثلاثة الماضية ، غالبًا ما يبدو اختصار
HTAP - المعالجة
المختلطة للمعالجة / التحليل أو المعالجة
المختلطة للمعاملات التحليلية . إذا لم يكن لديك وقت للتفكير في توسيع نطاق وتنوع طلبات OLAP و OLTP ، يمكنك أن تقول: "لدينا HTAP!" لكن تجربة وألم الأخطاء يُظهر أنه ، بعد كل شيء ، يجب أن تعيش أنواع الطلبات المختلفة بشكل منفصل عن بعضها البعض ، لأن طلبات OLAP الطويلة تمنع طلبات OLTP الخفيفة.
لذلك نأتي إلى مسألة كيفية توسيع نطاق PostgreSQL وذلك لنشر الحمل ، وكان الجميع راضين.
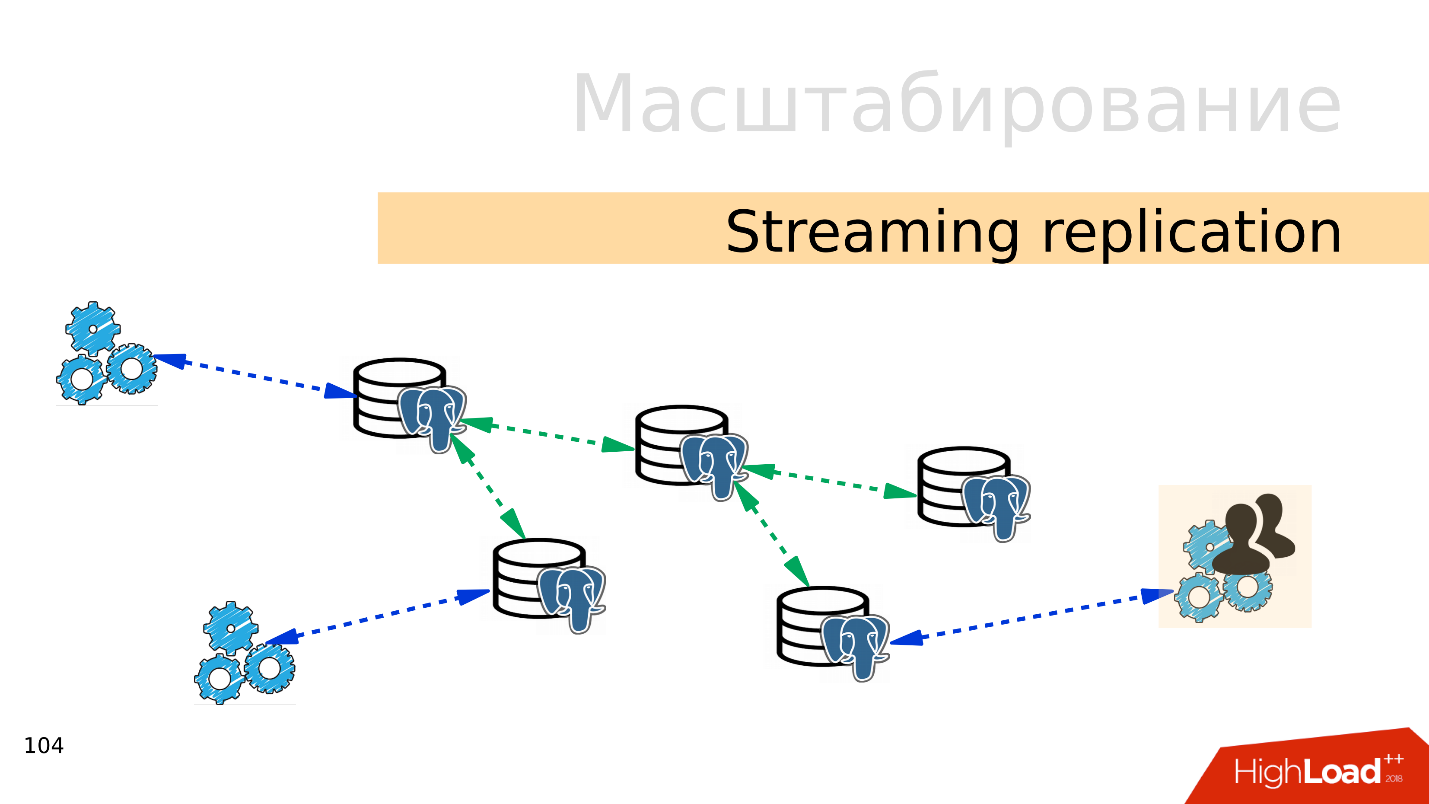
تدفق النسخ المتماثل . الخيار الأسهل هو
دفق النسخ المتماثل . عندما يعمل التطبيق مع قاعدة البيانات ، نقوم بتوصيل العديد من النسخ المتماثلة بقاعدة البيانات هذه وتوزيع الحمل. لا يزال التسجيل يذهب إلى القاعدة الرئيسية ، والقراءة إلى النسخ المتماثلة. هذه الطريقة تسمح لك بتوسيع نطاق واسع جدا.
بالإضافة إلى ذلك ، يمكنك توصيل المزيد من النسخ المتماثلة
للنسخ المتماثلة الفردية والحصول على
النسخ المتماثل المتتالي . يمكن فصل مجموعات المستخدمين أو التطبيقات ، على سبيل المثال ، قراءة التحليلات ، إلى نسخة متماثلة منفصلة.
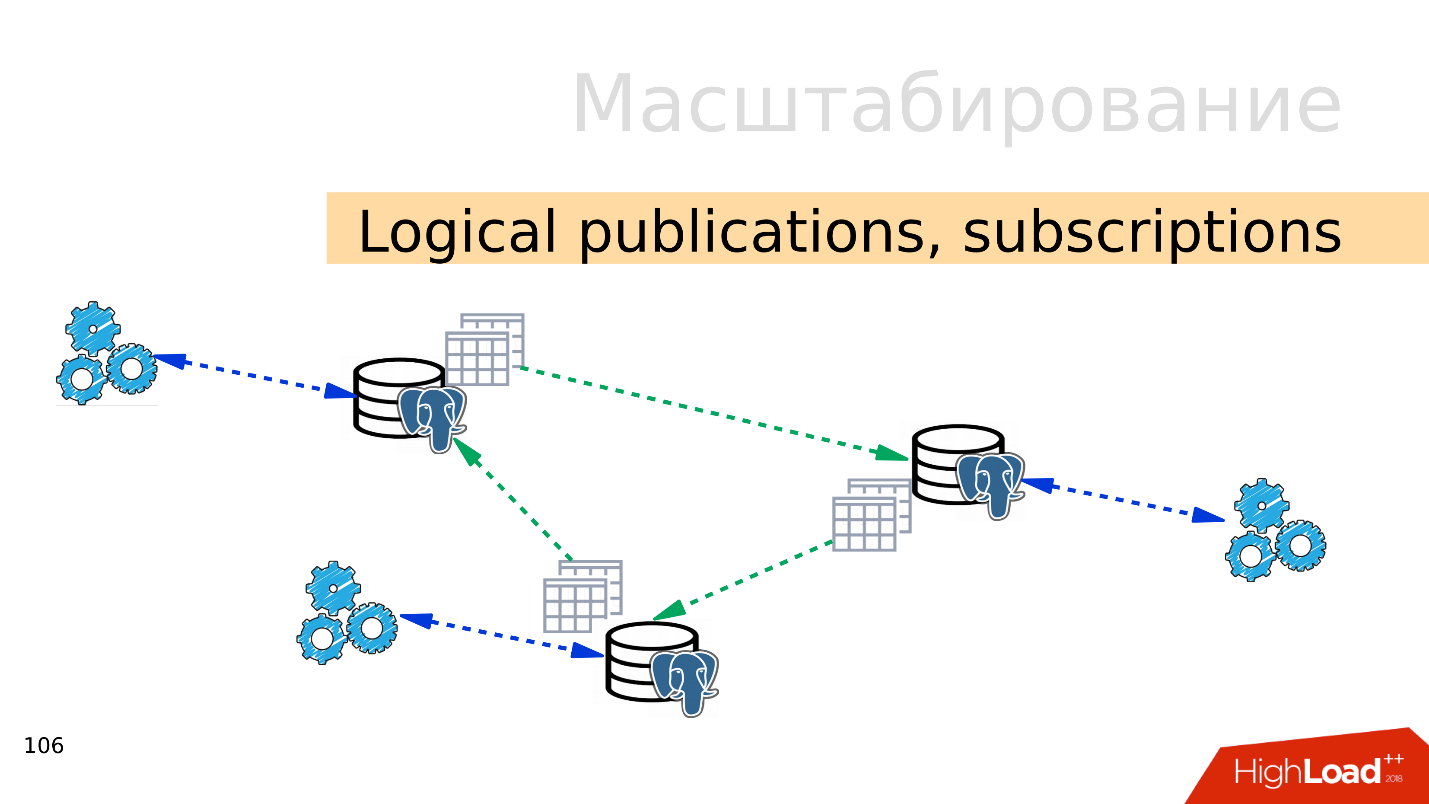
 المنشورات المنطقية والاشتراكات
المنشورات المنطقية والاشتراكات - تتضمن آلية المنشورات والاشتراكات المنطقية وجود العديد من خوادم PostgreSQL المستقلة مع قواعد بيانات منفصلة ومجموعات من الجداول. يمكن توصيل مجموعات الجداول هذه بقواعد البيانات المجاورة ، وستكون مرئية للتطبيقات التي يمكن استخدامها بشكل طبيعي. بمعنى ، يتم نسخ كافة التغييرات التي تحدث في المصدر إلى قاعدة الوجهة وتكون مرئية هناك. يعمل بشكل رائع مع PostgreSQL 10.
 الجداول الخارجية ، التقسيم التعريفي - التقسيم التعريفي والجداول الخارجية
الجداول الخارجية ، التقسيم التعريفي - التقسيم التعريفي والجداول الخارجية . يمكنك أن تأخذ عدة PostgreSQL وإنشاء مجموعات متعددة من الجداول التي تخزن نطاقات البيانات المطلوبة. يمكن أن تكون هذه بيانات لسنة محددة أو بيانات تم جمعها عبر أي نطاق.
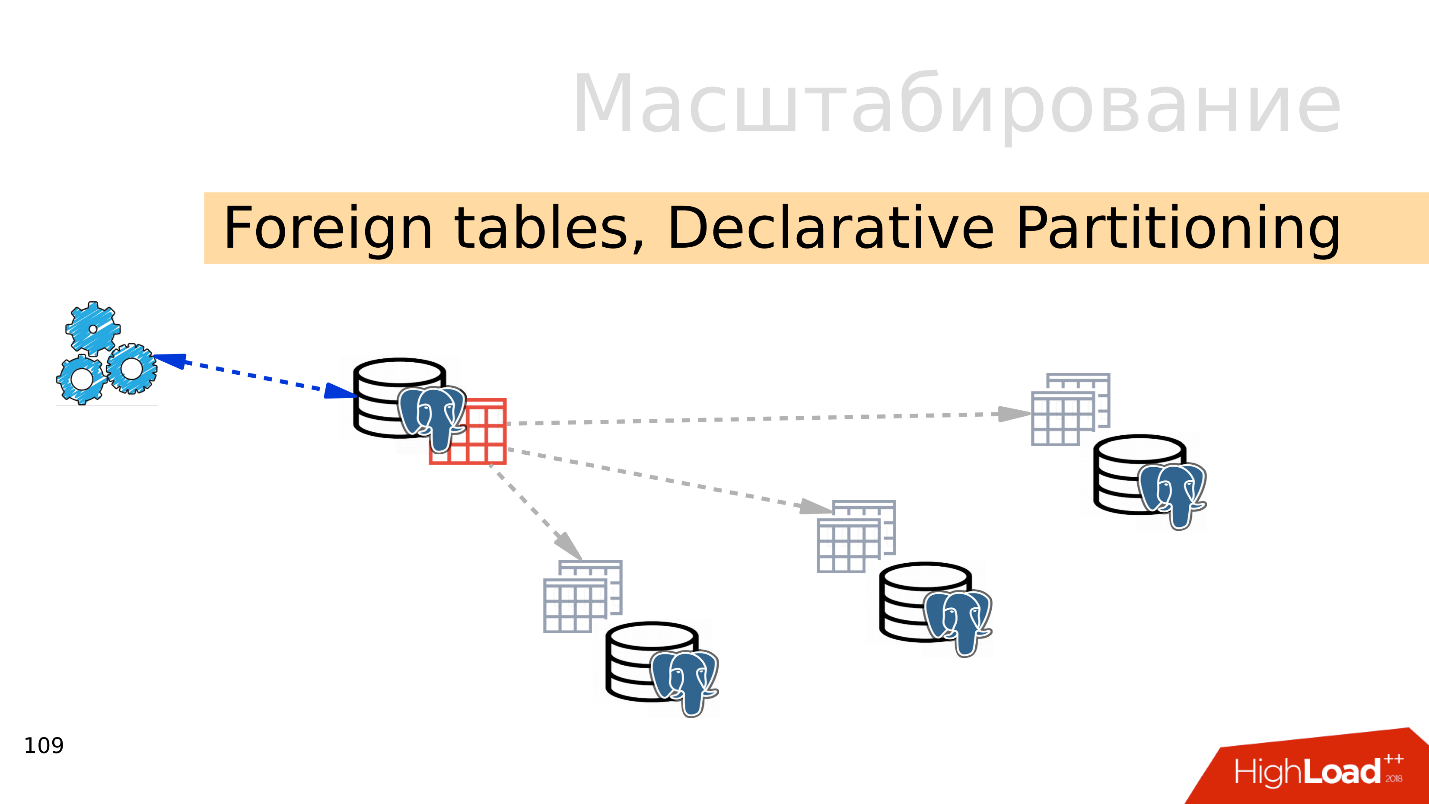
باستخدام آلية الجداول الخارجية ، يمكنك دمج كل قواعد البيانات هذه في شكل جدول مقسم في PostgreSQL منفصل. قد يعمل التطبيق بالفعل مع هذا الجدول المقسم ، ولكنه في الواقع سوف يقرأ البيانات من الأقسام البعيدة. عندما تكون وحدات تخزين البيانات أكثر من إمكانات خادم واحد ، فإن هذا أمر يتقاسم.

يمكن دمج كل هذا في نشر التوصيفات ، للتوصل إلى طبولوجيا نسخ متماثل مختلفة لـ PostgreSQL ، ولكن كيف يعمل كل شيء وكيفية إدارته هو موضوع تقرير منفصل.
من أين تبدأ؟
الخيار الأسهل هو
مع النسخ المتماثل . الخطوة الأولى هي نشر العبء على القراءة والكتابة. وهذا هو ، والكتابة إلى السيد ، وقراءة من النسخ المتماثلة. لذلك نحن زيادة حجم الحمل وتنفيذ القراءة من المعالج. بالإضافة إلى ذلك ، لا ننسى المحللين. تعمل الاستعلامات التحليلية لفترة طويلة ، فهي تحتاج إلى نسخة متماثلة منفصلة مع إعدادات منفصلة بحيث لا يمكن أن تتداخل الاستعلامات التحليلية الطويلة مع الباقي.
والخطوة التالية هي
تحقيق التوازن . لا يزال لدينا نفس السطر في التكوين الذي يعمل عليه المطور. إنه يحتاج إلى مكان حيث سيكتب ويقرأ. هناك العديد من الخيارات هنا.
المثالي هو تطبيق الموازنة
على مستوى التطبيق ، عندما يعرف التطبيق نفسه من أين يقرأ البيانات ، ويعرف كيفية اختيار نسخة متماثلة. افترض أن هناك حاجة دائمًا إلى تحديث رصيد الحساب ويحتاج إلى قراءته من الرئيسي ، ويمكن قراءة صورة المنتج أو المعلومات المتعلقة به مع بعض التأخير ويتم ذلك من نسخة متماثلة.
- في رأيي ، ليس DNS Round Robin تطبيقًا ملائمًا للغاية ، لأنه يعمل أحيانًا لفترة طويلة ولا يعطي الوقت اللازم عند تبديل أدوار المعالج بين الخوادم في حالات الفشل.
- خيار أكثر إثارة للاهتمام هو استخدام Keepalived و HAProxy . يتم طرح عناوين افتراضية للسيد ومجموعة النسخ المتماثلة بين خوادم HAProxy ، ويقوم HAProxy بالفعل بموازنة حركة المرور.
- Patroni ، DCS بالتزامن مع شيء مثل ZooKeeper ، وغيرها ، القنصل - الخيار الأكثر إثارة للاهتمام ، في رأيي. بمعنى أن اكتشاف الخدمة هو المسؤول عن المعلومات التي هي الرئيسية الآن ومن هو النسخة المتماثلة. يدير Patroni مجموعة من PostgreSQL's ، وينفذ التبديل - إذا تم تغيير الهيكل ، ستظهر هذه المعلومات في اكتشاف الخدمة ، ويمكن للتطبيقات اكتشاف الطبولوجيا الحالية بسرعة.
وهناك فروق دقيقة في النسخ المتماثل ، وأكثرها شيوعًا هي
تأخر النسخ المتماثل . يمكنك القيام بذلك مثل GitLab ، وعندما تتراكم الفجوة ، ما عليك سوى إسقاط القاعدة. لكن لدينا مراقبة شاملة - نحن ننظر إليها ونرى المعاملات الطويلة.
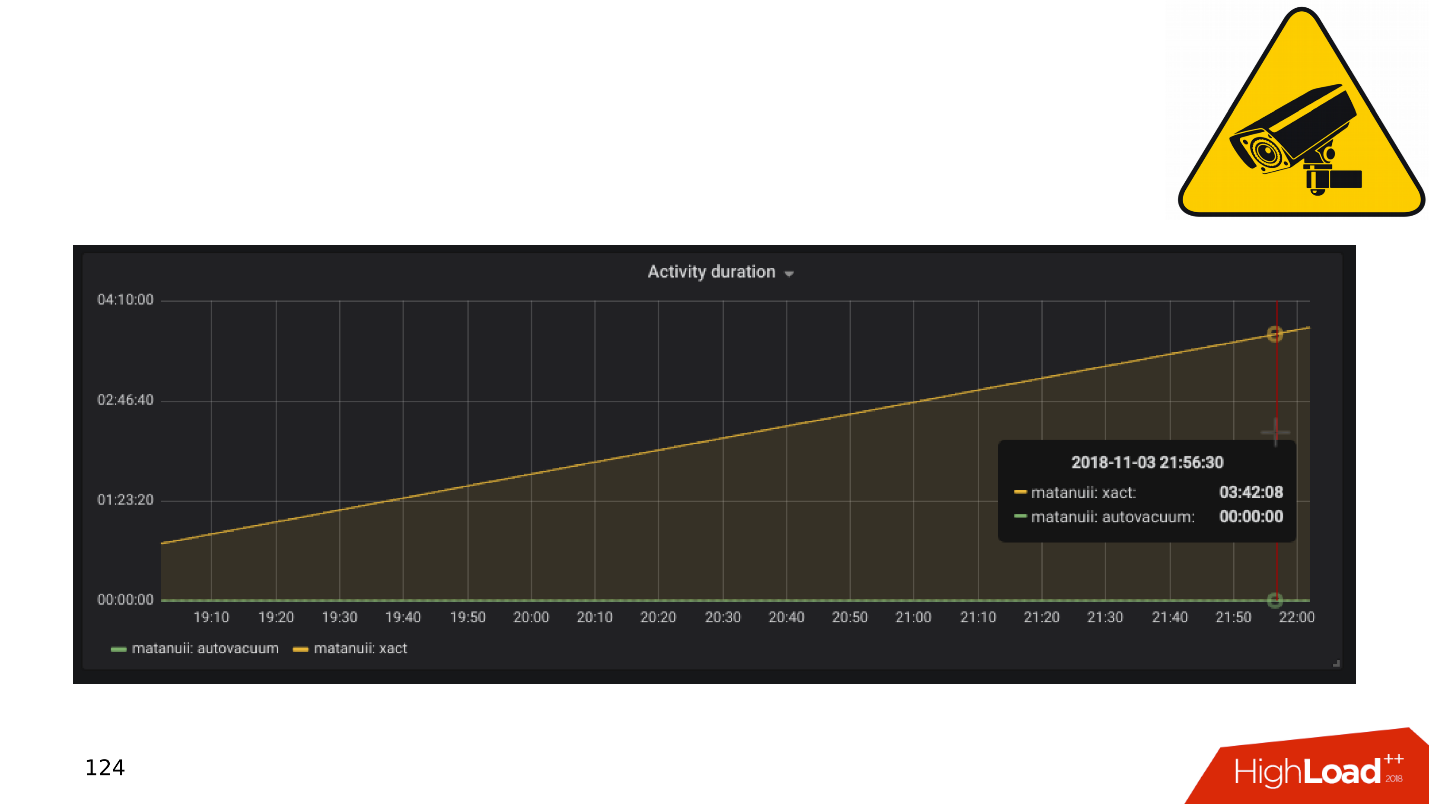
التطبيقات والمعاملات DBMS
بشكل عام ، تؤدي المعاملات البطيئة والخاملة إلى:
- انخفاض في الإنتاجية - ليس إلى تشنج حاد ، ولكن على نحو سلس ؛
- الأقفال والجمود ، لأن المعاملات الطويلة تمسك بالأقفال وتمنع المعاملات الأخرى من العمل ؛
- 50 * أخطاء HTTP على الواجهة الخلفية أو أخطاء الواجهة أو أي مكان آخر.
دعونا نلقي نظرة على نظرية صغيرة حول كيفية ظهور هذه المشاكل ، ولماذا آلية المعاملات الطويلة والخاملة ضارة.
PostgreSQL لديه MVCC - نسبيا ، محرك قاعدة بيانات. إنها تتيح للعملاء العمل على نحو تنافسي مع البيانات دون التداخل مع بعضهم البعض: القراء لا يتعارضون مع القراء ، والكتاب لا يتعارضون مع الكتاب. بالطبع ، هناك بعض الاستثناءات ، لكنها في هذه الحالة ليست مهمة.
اتضح أنه في قاعدة البيانات لصف واحد يمكن أن يكون هناك عدة إصدارات لمعاملات مختلفة. يتصل العملاء ، وتوفر لهم قاعدة البيانات لقطات من البيانات ، وداخل هذه اللقطات ، قد توجد إصدارات مختلفة من نفس السطر. وفقًا لذلك ، في دورة حياة قاعدة البيانات ، يتم نقل المعاملات واستبدال بعضها البعض ، وتظهر إصدارات الصفوف التي لا يحتاجها أحد.
لذلك هناك
حاجة لجمع القمامة - فراغ السيارات . توجد معاملات طويلة وتمنع الفراغ التلقائي من تنظيف إصدارات الصف غير الضرورية. تبدأ هذه البيانات غير المهمة في التجول من الذاكرة إلى القرص ومن القرص إلى الذاكرة. لتخزين هذه البيانات المهملة ، يتم إهدار موارد وحدة المعالجة المركزية والذاكرة.
كلما طالت المعاملة ، زاد الأداء غير الهام والأدنى.
من وجهة نظر "من يقع اللوم؟" ، التطبيق هو المسؤول عن ظهور المعاملات الطويلة. إذا كانت قاعدة البيانات موجودة لوحدها ، فلن تؤخذ معاملات طويلة لا تفعل شيئًا من أي مكان. في الممارسة العملية ، هناك الخيارات التالية لظهور المعاملات الخاملة.
"دعنا نذهب إلى مصدر خارجي .
" يفتح التطبيق معاملة ، ويفعل شيئًا في قاعدة البيانات ، ثم يقرر الانتقال إلى مصدر خارجي ، على سبيل المثال ، Memcached أو Redis ، على أمل أن يعود بعد ذلك إلى قاعدة البيانات ، ومتابعة العمل وإغلاق المعاملة. ولكن في حالة حدوث خطأ في المصدر الخارجي ، تعطل التطبيق وتظل المعاملة مغلقة حتى يلاحظها شخص ما ويقتلها.
لا خطأ معالجة . من ناحية أخرى ، قد يكون هناك مشكلة في معالجة الأخطاء. عندما ، مرة أخرى ، فتح التطبيق معاملة ، وحل بعض المشاكل في قاعدة البيانات ، وعاد إلى تنفيذ التعليمات البرمجية ، وأداء بعض الوظائف والحسابات ، من أجل مواصلة العمل في الصفقة وإغلاقه. عندما تمت مقاطعة عملية التطبيق بسبب خطأ ما ، عاد الرمز إلى بداية الدورة ، وبقيت المعاملة مغلقة مرة أخرى.
العامل البشري . على سبيل المثال ، يعمل مسؤول أو مطور أو محلل في بعض صفحات pgAdmin أو في DBeaver - فتح معاملة ، ويفعل شيئًا فيها. ثم انصرف الشخص ، وانتقل إلى مهمة أخرى ، ثم إلى المهمة الثالثة ، ونسي المعاملة ، وغادر لعطلة نهاية الأسبوع ، وتستمر الصفقة في التعطل. أداء قاعدة يعاني.
دعونا نرى ما يجب القيام به في هذه الحالات.
- لدينا مراقبة ؛ وبالتالي ، نحتاج إلى تنبيهات في المراقبة . أي معاملة معلقة لأكثر من ساعة ولا تفعل شيئًا هي مناسبة لمعرفة من أين جاءت وفهم الخطأ.
- والخطوة التالية هي إطلاق هذه المعاملات من خلال المهمة في التاج (pg_terminate_backend (pid)) أو التهيئة في تهيئة PostgreSQL. هناك حاجة إلى عتبة 10-30 دقيقة ، وبعد ذلك يتم الانتهاء من المعاملات تلقائيا.
- إعادة بناء التطبيق . بالطبع ، تحتاج إلى معرفة من أين تأتي المعاملات الخاملة ، ولماذا تحدث وتخلص من هذه الأماكن.
تجنب المعاملات الطويلة بأي ثمن ، لأنها تؤثر بشكل كبير على أداء قاعدة البيانات.
يصبح كل شيء أكثر إثارة للاهتمام عندما تظهر المهام المعلقة ، على سبيل المثال ، تحتاج إلى حساب الوحدات بعناية. ونحن نأتي إلى مسألة بناء الدراجات.
بناء الدراجات
قرحة الموضوع. يحتاج العمل على جانب التطبيق إلى إجراء معالجة خلفية للأحداث. على سبيل المثال ، لحساب المجاميع: الحد الأدنى والحد الأقصى ومتوسط القيمة ، وإرسال الإشعارات إلى المستخدمين ، وإصدار الفواتير للعملاء ، وإعداد حساب مستخدم بعد التسجيل أو التسجيل في الخدمات المجاورة - تأخر المعالجة.
جوهر هذه المهام هو نفسه - تم تأجيلها لوقت لاحق. تظهر الجداول في قاعدة البيانات التي تقوم فقط بتنفيذ قوائم الانتظار.

في ما يلي معرّف المهمة ، وقت إنشاء المهمة ، وعندما يتم تحديثها ، والمعالج الذي أخذها ، وعدد محاولات الإكمال. إذا كان لديك جدول يشبه هذا الجدول عن بُعد ، عندئذ يكون لديك
طوابير مكتوبة ذاتيًا .
كل هذا يعمل بشكل جيد حتى تظهر المعاملات الطويلة. بعد ذلك ،
تنتفخ الجداول التي تعمل مع قوائم الانتظار . تتم إضافة وظائف جديدة في كل وقت ، يتم حذف الوظائف القديمة ، تحدث التحديثات - يتم الحصول على جدول مع تسجيل مكثف. يجب تنظيفه بانتظام من الإصدارات القديمة من السلاسل بحيث لا يعاني الأداء.
يزداد وقت المعالجة - الصفقة الطويلة تحمل قفلًا على الإصدارات القديمة من الصفوف أو تمنع الفراغ من تنظيفها. عندما يزداد حجم الجدول ، يزداد أيضًا وقت المعالجة ، نظرًا لأنك تحتاج إلى قراءة العديد من الصفحات بالقمامة. يزيد الوقت ،
وتتوقف قائمة الانتظار في مرحلة ما عن العمل .
فيما يلي مثال على الجزء العلوي لأحد عملائنا الذين لديهم قائمة انتظار. جميع الطلبات مرتبطة فقط بقائمة الانتظار.

انتبه إلى وقت تنفيذ هذه الطلبات - جميعها عدا واحدة تعمل لأكثر من عشرين ثانية.
لحل هذه المشكلات ، تم
اختراع Skytools PgQ ، مدير قائمة انتظار PostgreSQL ، منذ فترة طويلة. لا تقم بإعادة اختراع دراجتك - خذ PgQ ، وقم بإعداده مرة واحدة ونسيان الخطوط.
صحيح ، لديه أيضا الميزات. Skytools PgQ لديه
القليل من الوثائق . بعد قراءة الصفحة الرسمية ، يشعر المرء بأنه لم يفهم شيئًا. ينمو الشعور عند محاولة القيام بشيء ما. كل شيء يعمل ، ولكن
كيف يعمل غير واضح . نوع من السحر جدي. ولكن يمكن العثور على الكثير من المعلومات في
القوائم البريدية . هذا ليس تنسيقًا مناسبًا للغاية ، ولكن هناك الكثير من الأشياء المثيرة للاهتمام ، وسيتعين عليك قراءة هذه الأوراق.
على الرغم من السلبيات ، يعمل Skytools PgQ على مبدأ "الإعداد والنسيان". , , , . PgQ , . PgQ , .
, - — , . .
PgQ. , PostgreSQL, , , PgQ . , .
, . , , , - , , , . , , , alter.
auto-failover — PostgreSQL - , , . , auto-failover.
Split-brain . PostgreSQL , , — . , . PostgreSQL fencing, Kubernets . - , . Split-brain.

. GitHub Split-brain, .
Cascade failover . , . , .
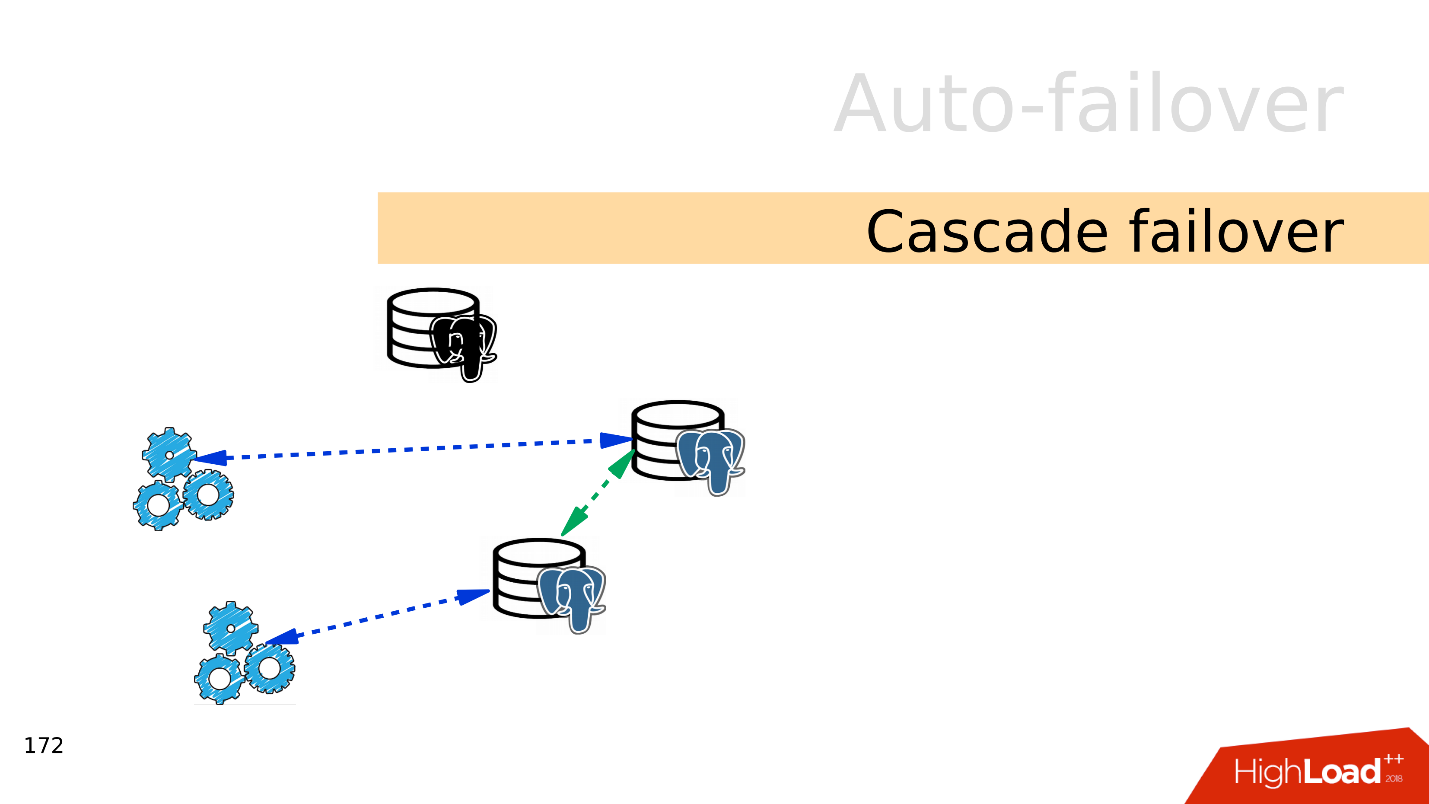
, . , .
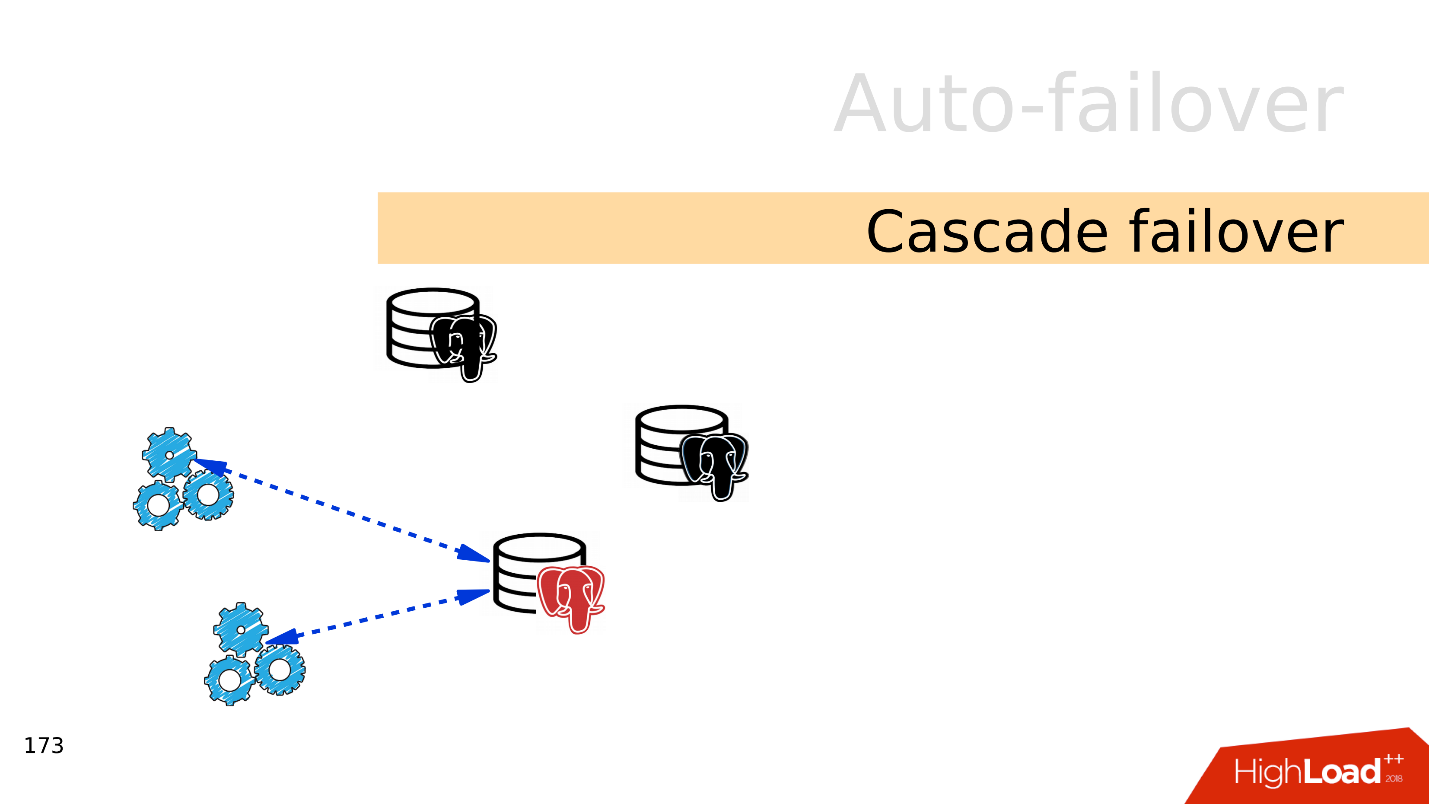
— failover.
auto-failover, .
Bash — , . , , . - , , . .
Ansible playbooks — bash- . , , .
Patroni — , , auto-failover, , service discovery.
PAF —
Pacemaker . auto-failover PostgreSQL, Pacemaker.
Stolon . Kubernetes, . Stolon Patroni, .
Docker Kubernetes . , .
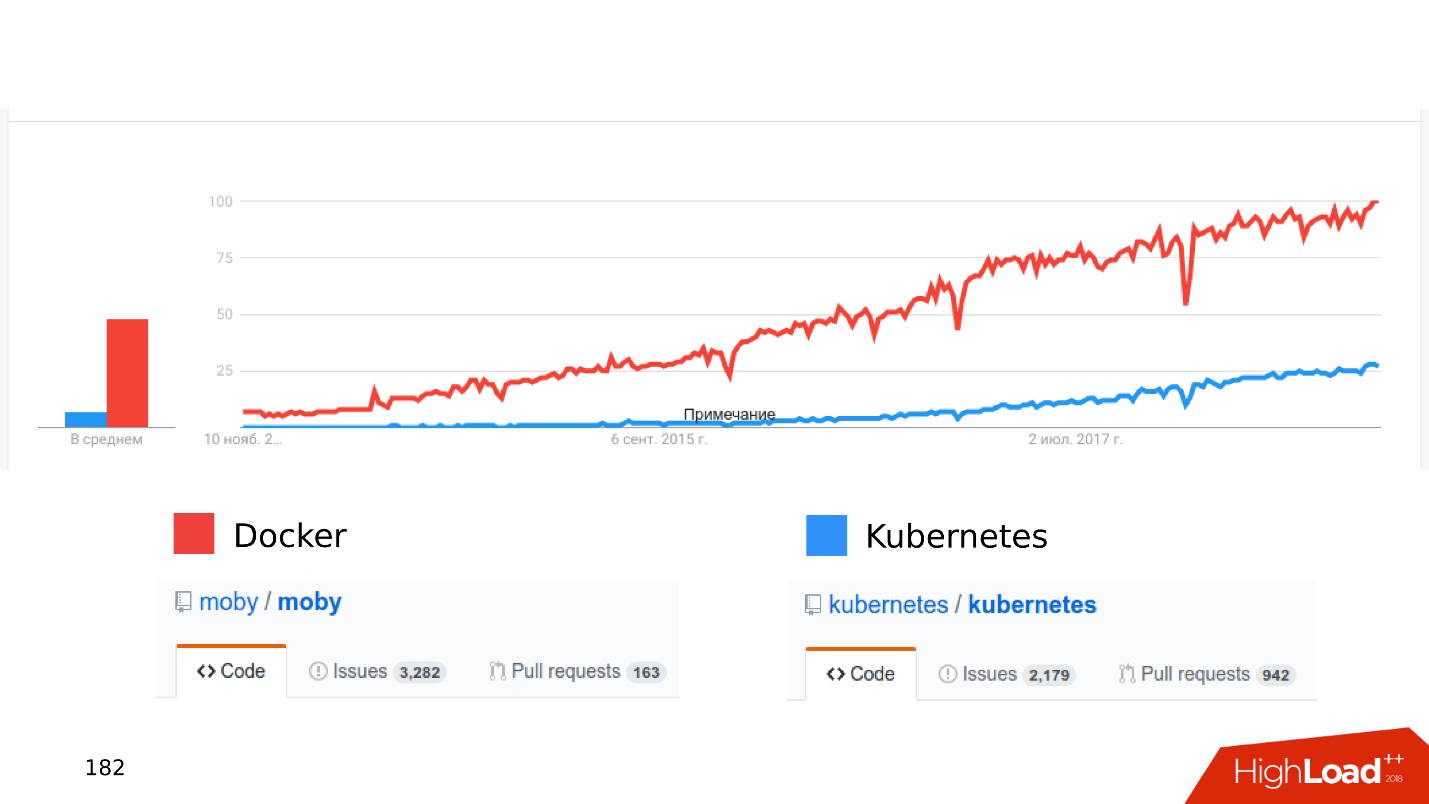
, .
« Kubernetes...» .
— stateful , - . إلى أين؟ . Open Source: CEPH, GlusterFS, LinStor DRBD. , , , .
—
. , Kubernetes, CEPH. — . , .
- , .
- latency . latency — .
- . Kubernetes , - . , shared storage Kubernetes, . - .
, Kubernetes Docker staging dev- . , , Kubernetes .
,
local volumes — ,
streaming replication — ,
PostgreSQL- , — , . :
Zalando Crunchy .
, . issues pull requests. , , .
النتائج
SSD — , .
. JSON 8 — , .
, . PostgreSQL, .
— Postgres is ready . . PostgreSQL , . :
streaming replication; publications, subscriptions; foreign Tables; declarative partitioning .
. , .
-, , —
. . , Skytools PgQ!
Kubernetes, local volumes, streaming replication PostgreSQL . - , , .
. , 24 25 HighLoad++ Siberia , , . 38 — !