تحول العمل العلمي الهام من عام 2012 في مجال برمجيات التعرف على الصور

اليوم ، على سبيل المثال ، يمكنني فتح صور Google ، وكتابة "شاطئ" ، ومشاهدة مجموعة من الصور الخاصة بي من مختلف الشواطئ التي زرتها في العقد الماضي. لم أوقع صوري أبدًا - تتعرف Google على الشواطئ عليها استنادًا إلى محتواها. تعتمد هذه الميزة التي تبدو مملة على تقنية تسمى "الشبكة العصبية التلافيفية العميقة" ، والتي تسمح للبرامج بفهم الصور باستخدام طريقة معقدة ، لا يمكن الوصول إليها بتقنيات الأجيال السابقة.
في السنوات الأخيرة ، وجد الباحثون أن دقة البرامج تصبح أفضل مع قيامهم ببناء شبكات عصبية أعمق (NS) وتدريبهم على مجموعات بيانات أكبر من أي وقت مضى. هذا خلق حاجة نهم لقوة الحوسبة ، ومصنعي GPU المخصب مثل نفيديا وأيه إم دي. قبل بضع سنوات ، طورت Google رقائقها الخاصة للجمعية الوطنية ، بينما تحاول شركات أخرى مواكبة ذلك.
في تسلا ، على سبيل المثال ، تم تعيين Andrei Karpati ، خبير التعلم العميق ، رئيسا لمشروع الطيار الآلي. الآن تقوم شركة صناعة السيارات بتطوير رقاقة خاصة بها لتسريع عمل NS في الإصدارات المستقبلية من الطيار الآلي. أو خذ Apple: تحتوي شرائح A11 و A12 ، المركزية لأحدث أجهزة iPhone ، على "
معالج عصبي " Neural Engine
يعمل على تسريع NS ويسمح لتطبيقات التعرف على الصور والصوت بالعمل بشكل أفضل.
يتعقب الخبراء الذين قابلتهم في هذا المقال بداية الطفرة التعليمية العميقة لوظيفة محددة: AlexNet ، سميت باسم المؤلف الرئيسي ، Alex Krizhevsky. وقال شون جريش ، خبير الدفاع ومؤلف كتاب "
كيف تفكر السيارات الذكية ": "أعتقد أن عام 2012 كان عامًا بارزًا عندما خرج عمل AlexNet".
حتى عام 2012 ، كانت الشبكات العصبية العميقة (GNS) قليلاً من الركود في عالم منطقة موسكو. لكن بعد ذلك شارك كريزيفسكي وزملاؤه من جامعة تورنتو في المسابقة المرموقة للتعرف على الصور ، وتجاوز برنامجهم بشكل كبير كل شيء تم تطويره قبله. على الفور تقريبًا ، أصبحت STS التكنولوجيا الرائدة في التعرف على الصور. سرعان ما أظهر باحثون آخرون يستخدمون هذه التقنية مزيدًا من التحسينات في دقة التعرف.
في هذه المقالة ، سوف نتعمق في التعلم العميق. سأشرح ماهية NS وكيف يتم تدريبهم ولماذا يحتاجون إلى موارد الحوسبة هذه. ثم سأشرح لماذا يفهم نوع معين من شبكات NS - شبكات الالتفاف العميقة - الصور جيدًا. لا تقلق ، سيكون هناك العديد من الصور.
مثال بسيط مع خلية واحدة
قد يبدو مفهوم "الشبكة العصبية" غامضا بالنسبة لك ، لذلك دعونا نبدأ بمثال بسيط. لنفترض أنك تريد أن تقرر الجمعية الوطنية ما إذا كنت ستقود سيارة بناءً على إشارات المرور الخضراء والأصفر والأحمر. NS يمكن أن تحل هذه المشكلة مع خلية واحدة.

تستقبل الخلايا العصبية بيانات الإدخال (1 - على ، 0 - إيقاف) ، تتكاثر بالوزن المناسب ، وتضيف كل قيم الأوزان. ثم تضيف الخلية العصبية تخالفًا يحدد قيمة العتبة لـ "تنشيط" الخلية العصبية. في هذه الحالة ، إذا كان الناتج موجبًا ، فإننا نعتقد أن الخلايا العصبية قد نشطت - والعكس صحيح. الخلايا العصبية تعادل عدم المساواة "الأخضر - الأحمر - 0.5> 0". إذا اتضح أن ذلك صحيح - وهذا يعني أن اللون الأخضر يكون قيد التشغيل وأن اللون الأحمر ليس قيد التشغيل - فيجب أن تستمر السيارة.
في NS الحقيقي ، تتخذ الخلايا العصبية الاصطناعية خطوة أخرى. عن طريق إضافة مدخلات مرجحة وإضافة إزاحة ، تستخدم الخلية العصبية وظيفة تنشيط غير خطية. غالبًا ما يتم استخدام السيني ، وهي دالة على شكل حرف S تعطي دائمًا قيمة من 0 إلى 1.
لن يؤدي استخدام وظيفة التنشيط إلى تغيير نتيجة نموذج إشارة المرور البسيط الخاص بنا (نحتاج فقط إلى استخدام قيمة عتبة قدرها 0.5 وليس 0). لكن عدم خطية وظائف التنشيط ضرورية من أجل قيام NSs بتصميم وظائف أكثر تعقيدًا. بدون وظيفة التنشيط ، يتم تقليل كل NS معقدة بشكل تعسفي إلى مزيج خطي من بيانات الإدخال. لا يمكن للوظيفة الخطية محاكاة الظواهر المعقدة في العالم الحقيقي. تتيح وظيفة التنشيط غير الخطية للـ NS تقريب
أي وظيفة رياضية .
مثال الشبكة
بالطبع ، هناك العديد من الطرق لتقريب الوظيفة. تبرز NS بحقيقة أننا نعرف كيفية "تدريبهم" باستخدام جبر صغير ، ومجموعة من البيانات وبحر من القوة الحاسوبية. بدلاً من توجيه المبرمج لتطوير NS لمهمة محددة ، يمكننا إنشاء برنامج يبدأ بـ NS عامة إلى حد ما ، ويدرس مجموعة من الأمثلة المحددة ، ثم يغير NS بحيث يعطي التسمية الصحيحة لأكبر عدد ممكن من الأمثلة. التوقع هو أن NS النهائية سوف تلخص البيانات وسوف تنتج التسميات الصحيحة للأمثلة التي لم تكن موجودة سابقا في قاعدة البيانات.
بدأت العملية المؤدية إلى هذا الهدف قبل وقت طويل من AlexNet. في عام 1986 ، نشر ثلاثة من الباحثين عملًا
بارزًا بشأن التعرية الخلفية ، وهي تقنية ساعدت على جعل التعلم الرياضي للمراكز الرياضية المعقدة حقيقة واقعة.
لتخيل كيف تعمل backpropagation ، دعونا ننظر إلى NS بسيطة وصفها مايكل نيلسن في كتابه
GO الممتاز
عبر الإنترنت . الغرض من الشبكة هو معالجة صورة رقم مكتوب بخط اليد بدقة 28 × 28 بكسل وتحديد ما إذا كان الرقم 0 و 1 و 2 وما إلى ذلك صحيحًا.
كل صورة هي 28 * 28 = 784 كميات إدخال ، كل منها عبارة عن رقم حقيقي من 0 إلى 1 ، مما يشير إلى مقدار البيكسل الفاتح أو الغامق. أنشأ نيلسن NA من هذا النوع:
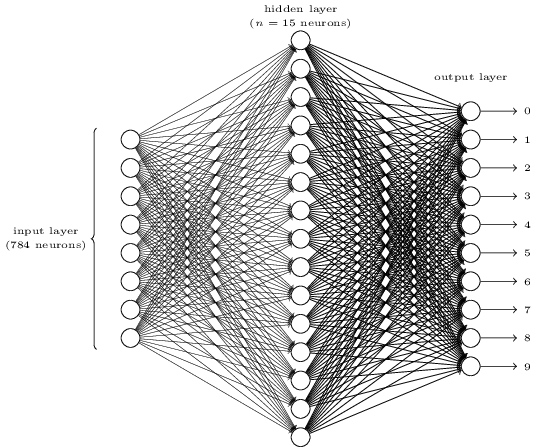
كل دائرة في الوسط وفي العمود الأيمن هي خلية عصبية مماثلة لتلك التي درسناها في القسم السابق. تأخذ كل خلية عصبية متوسط مرجح للمدخلات ، وتضيف إزاحة ، وتطبق وظيفة التنشيط. الدوائر الموجودة على اليسار ليست خلايا عصبية ؛ فهي تمثل بيانات إدخال الشبكة. وعلى الرغم من أن الصورة لا تعرض سوى 8 دوائر إدخال ، إلا أن هناك 784 منها - واحدة لكل بكسل.
يجب على كل خلية من الخلايا العصبية العشرة الموجودة على اليمين "تشغيل" رقمها الخاص: يجب تشغيل الجزء العلوي عندما يتم إدخال 0 مكتوبة بخط اليد (وفقط في هذه الحالة) ، والثانية عندما ترى الشبكة 1 مكتوبة بخط اليد 1 (وفقط) ، وهكذا.
كل خلية عصبية ترى مدخلات من كل خلية عصبية من الطبقة السابقة. لذلك يتلقى كل من الخلايا العصبية الخمسة عشر في الوسط 784 قيمة إدخال. كل من هذه الخلايا العصبية 15 لديه معامل الوزن لكل من قيم إدخال 784. هذا يعني أن هذه الطبقة فقط لديها 15 * 784 = 11 760 معلمات وزن. وبالمثل ، تحتوي طبقة الخرج على 10 خلايا عصبية ، يستقبل كل منها مدخلات من كل 15 خلية عصبية من الطبقة الوسطى ، مما يضيف 15 * 10 = 150 معلمة أخرى للوزن. بالإضافة إلى ذلك ، تحتوي الشبكة على 25 متغير إزاحة - واحد لكل من الخلايا العصبية 25.
تدريب الشبكة العصبية
الهدف من التدريب هو ضبط هذه المعلمات البالغ عددها 11،935 معلمة لزيادة احتمالية تنشيط الخلايا العصبية المرغوبة - وفقط فقط - عندما تعطي الشبكات صورة لرقم مكتوب بخط اليد. يمكننا القيام بذلك من خلال مجموعة الصور المعروفة MNIST ، حيث يوجد 60،000 صورة مميزة بدقة 28 × 28 بكسل.
 160 من أصل 60،000 صورة من مجموعة MNIST
160 من أصل 60،000 صورة من مجموعة MNISTيوضح Nielsen كيفية تدريب شبكة باستخدام 74 سطرًا من رمز python العادي - دون أي مكتبات لـ MO. يبدأ التعلم عن طريق اختيار قيم عشوائية لكل من هذه المعلمات والأوزان والإزاحات البالغ عددها 11،935. ثم يمر البرنامج بأمثلة من الصور ، ويمر على مرحلتين مع كل منها:
- تحسب خطوة الانتشار الأمامية إخراج الشبكة استنادًا إلى صورة المدخلات والمعلمات الحالية.
- تحسب خطوة backpropagation انحراف النتيجة عن بيانات الإخراج الصحيحة وتغيير معلمات الشبكة لتحسين كفاءتها في هذه الصورة بشكل طفيف.
مثال دعنا نقول أن الشبكة تلقت الصورة التالية:
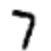
إذا تمت معايرتها جيدًا ، فيجب أن تذهب "7" إلى 1 ، ويجب أن تذهب الاستنتاجات التسعة الأخرى إلى 0. ولكن ، دعنا نقول ذلك بدلاً من ذلك ، تعطي الشبكة عند الإخراج "0" قيمة 0.8. هذا كثير جدا تقوم خوارزمية التدريب بتغيير أوزان المدخلات للخلية العصبية المسؤولة عن "0" بحيث تصبح أقرب إلى الصفر في المرة التالية التي تتم فيها معالجة هذه الصورة.
لهذا ، خوارزمية backpropagation يحسب التدرج خطأ لكل وزن الإدخال. هذا هو مقياس لكيفية تغيير خطأ الإخراج لتغيير معين في وزن الإدخال. ثم تستخدم الخوارزمية التدرج اللوني لتحديد مقدار تغيير كل وزن إدخال - كلما زاد التدرج ، كان التغيير أقوى.
بمعنى آخر ، تقوم عملية التعلم "بتدريب" الخلايا العصبية لطبقة المخرجات على إيلاء اهتمام أقل لتلك المدخلات (الخلايا العصبية في الطبقة الوسطى) التي تدفعها إلى الإجابة الخاطئة ، وأكثر من ذلك إلى تلك المدخلات التي تدفع في الاتجاه الصحيح.
تكرر الخوارزمية هذه الخطوة لجميع الخلايا العصبية الأخرى الناتجة. أنه يقلل من أوزان المدخلات للخلايا العصبية "1" ، "2" ، "3" ، "4" ، "5" ، "6" ، "8" و "9" (ولكن ليس "7") من أجل خفض قيمة هذه الخلايا العصبية الإخراج. كلما زادت قيمة الخرج ، زاد التدرج في خطأ الخرج فيما يتعلق بوزن المدخلات - وزاد وزنه.
والعكس صحيح ، تزيد الخوارزمية من وزن بيانات الإدخال للإخراج "7" ، مما يجعل الخلايا العصبية تنتج قيمة أعلى في المرة التالية التي يتم فيها إعطاء هذه الصورة. مرة أخرى ، فإن المدخلات ذات القيم الأكبر ستزيد الأوزان أكثر ، مما سيجعل الخلايا العصبية الناتجة "7" تولي اهتمامًا أكبر لهذه المدخلات في المرة القادمة.
بعد ذلك ، يجب أن تقوم الخوارزمية بنفس العمليات الحسابية للطبقة الوسطى: قم بتغيير كل وزن إدخال في اتجاه يقلل من أخطاء الشبكة - مرة أخرى ، وبذلك يصبح الناتج "7" أقرب إلى 1 ، والباقي يساوي 0. لكن لكل خلية عصبية متوسطة اتصال مع كل 10 أيام عطلة ، مما يعقد الأمور في جانبين.
أولاً ، لا يعتمد تدرج الخطأ لكل عصبون متوسط على قيمة المدخلات فحسب ، بل يعتمد أيضًا على تدرجات الخطأ في الطبقة التالية. تسمى الخوارزمية بـ backpropagation لأن تدرجات الخطأ للطبقات الأحدث من الشبكة تنتشر في الاتجاه المعاكس وتستخدم لحساب التدرجات في الطبقات السابقة.
أيضا ، كل الخلايا العصبية الوسطى هي مدخلات لجميع الأيام العشرة. لذلك ، يتعين على خوارزمية التدريب حساب تدرج الخطأ ، مما يعكس كيف يؤثر التغيير في وزن إدخال معين على متوسط الخطأ لجميع المخرجات.
Backpropagation هي خوارزمية لتسلق التل: كل ممر يجعل قيم المخرجات أقرب إلى القيم الصحيحة لصورة معينة ، ولكن قليلاً. لمزيد من الأمثلة التي تبحث عنها الخوارزمية ، كلما ارتفعت أعلى التل نحو المجموعة المثلى من المعلمات التي تصنف بشكل صحيح الحد الأقصى لعدد أمثلة التدريب. لتحقيق الدقة العالية ، هناك حاجة إلى آلاف الأمثلة ، وقد تحتاج الخوارزمية إلى التنقل بين كل صورة في هذه المجموعة عشرات المرات قبل توقف فعاليتها عن النمو.
يوضح نيلسن كيفية تنفيذ هذه الأسطر 74 في بيثون. والمثير للدهشة ، أن شبكة مدربة على مثل هذا البرنامج البسيط يمكنها التعرف على أكثر من 95 ٪ من الأرقام المكتوبة بخط اليد من قاعدة بيانات MNIST. مع التحسينات الإضافية ، يمكن لشبكة بسيطة من طبقتين التعرف على أكثر من 98 ٪ من الأرقام.
اختراق AlexNet
قد تظن أنه كان من المفترض أن يتم تطوير موضوع backpropagation في الثمانينيات من القرن الماضي ، وأن يؤدي إلى تقدم سريع في وزارة الدفاع على أساس الجمعية الوطنية - لكن هذا لم يحدث. في التسعينيات وأوائل العقد الأول من القرن العشرين ، عمل بعض الأشخاص على هذه التكنولوجيا ، لكن الاهتمام بالجمعية الوطنية لم يكتسب زخماً حتى أوائل 2010.
يمكن إرجاع هذا إلى
مسابقة ImageNet ، مسابقة MO السنوية التي ينظمها ستانفورد فاي فاي لي ، متخصص تكنولوجيا المعلومات. في كل عام ، يتم إعطاء المنافسين نفس المجموعة التي تضم أكثر من مليون صورة للتدريب ، يتم تمييز كل منها يدويًا في فئات تزيد عن 1000 - من "شاحنة الإطفاء" و "الفطر" إلى "الفهد". يتم تقييم برنامج المشاركين على إمكانية تصنيف الصور الأخرى التي لم تكن في المجموعة. يمكن للبرنامج إعطاء بعض التخمينات ، ويعتبر عمله ناجحًا إذا تطابق واحد على الأقل من التخمينات الخمسة الأولى مع العلامة التي وضعها الشخص.
بدأت المسابقة في عام 2010 ، ولم تلعب NS NS العميقة دورًا كبيرًا فيها في العامين الأولين. استخدمت أفضل الفرق تقنيات مختلفة مختلفة ، وحققت نتائج متوسطة إلى حد ما. في عام 2010 ، فاز الفريق بنسبة أخطاء تساوي 28. في عام 2011 - بنسبة خطأ 25 ٪.
ثم جاء عام 2012. قدم فريق من جامعة تورنتو
عرضًا - أطلق عليه فيما بعد اسم AlexNet تكريماً للمؤلف الرئيسي ، Alex Krizhevsky - وترك المنافسين وراءهم. باستخدام NS العميق ، حقق الفريق معدل خطأ 16 ٪. لأقرب منافس ، كان هذا الرقم 26.
إن NS الموصوفة في المقالة للتعرف على خط اليد لها طبقتان ، 25 خلية عصبية وما يقرب من 12000 معلمة. كان AlexNet أكبر بكثير وأكثر تعقيدًا: ثماني طبقات مدربة و 650.000 خلية عصبية و 60 مليون معلمة.
مطلوب قوة معالجة هائلة لتدريب NS من هذا الحجم ، وتم تصميم AlexNet للاستفادة من التوازي الهائل المتاح مع وحدات معالجة الرسومات الحديثة. اكتشف الباحثون كيفية تقسيم عمل تدريب الشبكة إلى وحدتي معالجة ، مما ضاعف الطاقة. ومع ذلك ، على الرغم من التحسين الدقيق ، استغرق التدريب على الشبكة 5-6 أيام على الأجهزة التي كانت متاحة في عام 2012 (على زوج من Nvidia GTX 580 مع 3 جيجا بايت من الذاكرة).
من المفيد دراسة أمثلة لنتائج AlexNet لفهم مدى خطورة هذا التقدم. فيما يلي صورة من ورقة علمية تعرض أمثلة على الصور والتخمينات الخمسة الأولى للشبكة حسب تصنيفها:

تمكنت AlexNet من التعرف على العلامة في الصورة الأولى ، على الرغم من وجود شكل صغير في الزاوية منها. لم يحدد البرنامج بشكل صحيح الفهد فحسب ، ولكنه أعطى خيارات وثيقة أخرى - جاكوار ، فهد ، نمر ثلج ، ماو مصري. قامت AlexNet بوضع علامة على صورة hornbeam كـ "agaric". مجرد "الفطر" كان الإصدار الثاني من الشبكة.
"الأخطاء" AlexNet مثيرة للإعجاب أيضا. قامت بتمييز الصورة مع الدلماسي يقف وراء مجموعة من الكرز باسم "الدلماسي" ، على الرغم من أن التسمية الرسمية كانت "الكرز". أدركت AlexNet أن هناك نوعًا من التوت في الصورة - من بين الخيارات الخمسة الأولى "العنب" و "العجينة" - إنها ببساطة لم تتعرف على الكرز. في صورة لليمور مدغشقر جالس على شجرة ، أعطت AlexNet قائمة بالثدييات الصغيرة التي تعيش على الأشجار. أعتقد أن العديد من الأشخاص (بمن فيهم أنا) كانوا سيضعون التوقيع الخاطئ هنا.
كانت جودة العمل رائعة ، وأثبتت أن البرنامج قادر على التعرف على الأشياء العادية في مجموعة واسعة من توجهاتها وبيئاتها. سرعان ما أصبح GNS الأسلوب الأكثر شعبية للتعرف على الصور ، ومنذ ذلك الحين لم يتخلَّ العالم عن MO.
وكتبت الجهات الراعية لـ ImageNet: "في أعقاب النجاح الذي تحقق في عام 2012 للأسلوب المستند إلى GO ، تحول معظم المشاركين في مسابقة 2013 إلى الشبكات العصبية التلافيفية العميقة". في السنوات التالية ، استمر هذا الاتجاه ، وبعد ذلك عمل الفائزون على أساس التقنيات الأساسية ، التي طبقها فريق AlexNet لأول مرة. بحلول عام 2017 ، قام المنافسون ، باستخدام NSs أعمق ، بتخفيض معدل الخطأ إلى أقل من ثلاثة. نظرًا لتعقيد المهمة ، فقد تعلمت أجهزة الكمبيوتر إلى حد ما حلها بشكل أفضل من كثير من الناس.
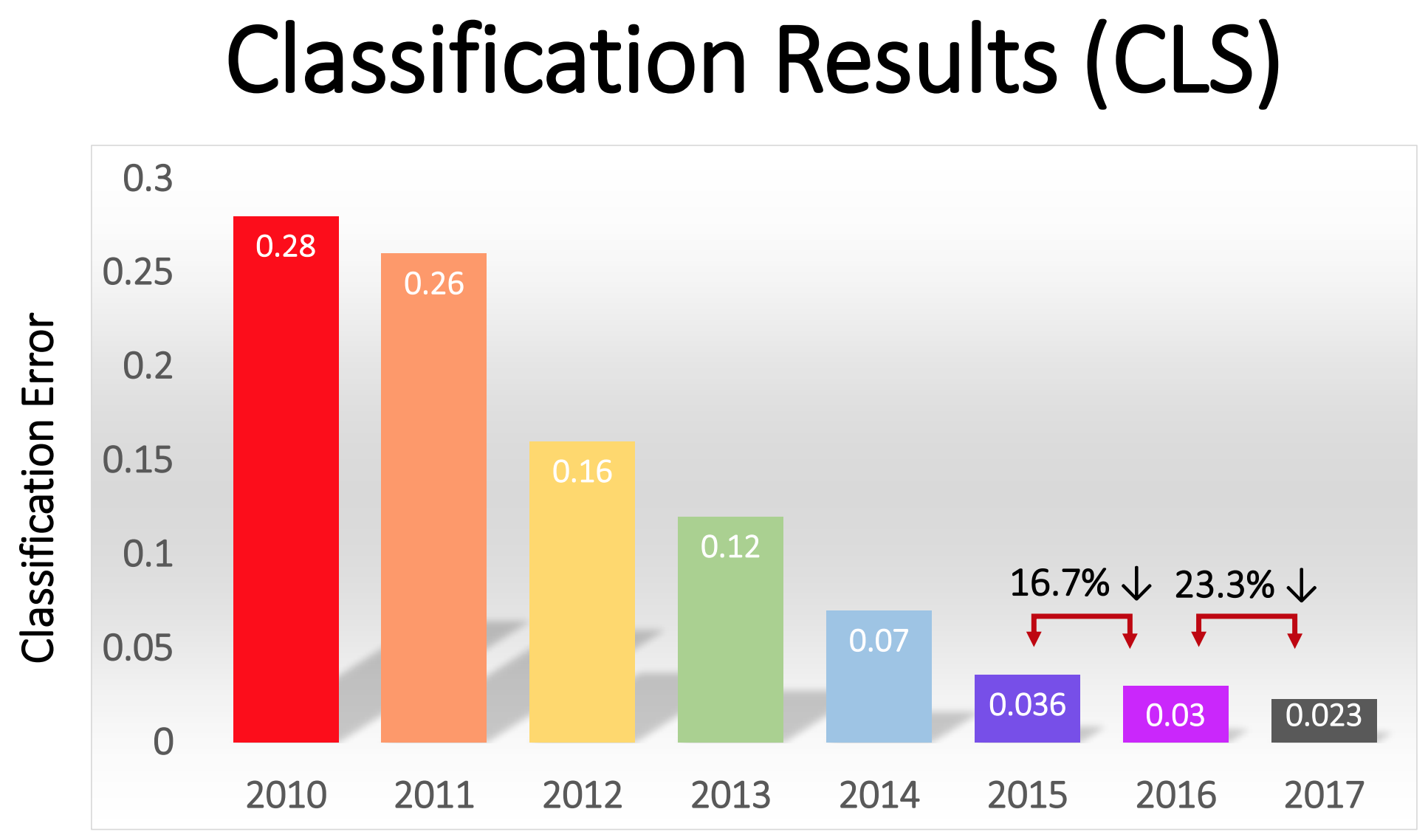 نسبة الأخطاء في تصنيف الصور في سنوات مختلفة
نسبة الأخطاء في تصنيف الصور في سنوات مختلفةشبكات الالتواء: مفهوم
من الناحية الفنية ، كان AlexNet NS NS تلافيفي. في هذا القسم ، سأشرح ما تفعله الشبكة العصبية التلافيفية (SNA) ، ولماذا أصبحت هذه التكنولوجيا مهمة للغاية بالنسبة لخوارزميات التعرف على الأنماط الحديثة.
كانت الشبكة البسيطة التي تمت مناقشتها سابقًا للتعرف على خط اليد متصلة تمامًا: فكل خلية عصبية من الطبقة الأولى كانت مدخلات لكل خلية عصبية من الطبقة الثانية. تعمل هذه البنية بشكل جيد على المهام البسيطة مع التعرف على الأرقام في صور بحجم 28 × 28 بكسل. لكنها لا تتسع بشكل جيد.
في قاعدة بيانات الأرقام المكتوبة بخط اليد MNIST ، يتم توسيط جميع الأحرف. هذا يبسط التعلم إلى حد كبير ، لأنه على سبيل المثال ، سيكون للسبعة دائمًا عدة وحدات بكسل مظلمة في الأعلى واليمين ، وتكون الزاوية اليسرى السفلى بيضاء دائمًا. سيكون للصفر دائمًا بقعة بيضاء في البيكسلات المتوسطة والظلام عند الحواف. يمكن لشبكة بسيطة ومتصلة بشكل كامل التعرف على هذه الأنماط بسهولة تامة.
ولكن لنفترض أنك تريد إنشاء NS قادرًا على التعرف على الأرقام التي يمكن أن توجد في أي مكان على صورة أكبر. لن تعمل الشبكة المتصلة تمامًا بنفس الطريقة مع هذه المهمة ، نظرًا لعدم وجود طريقة فعالة للتعرف على الميزات المماثلة في النماذج الموجودة في أجزاء مختلفة من الصورة. إذا كانت معظم البيانات السبعة موجودة في مجموعة البيانات التدريبية في الركن الأيسر العلوي ، فستكون شبكتك أفضل في التعرف على السبعات الموجودة في الزاوية اليسرى العليا مقارنة بأي جزء آخر من الصورة.
من الناحية النظرية ، يمكن حل هذه المشكلة عن طريق التأكد من أن مجموعتك تحتوي على العديد من الأمثلة لكل رقم في كل من المواضع المحتملة. ولكن في الممارسة العملية سيكون هذا مضيعة هائلة للموارد. مع زيادة حجم الصورة وعمق الشبكة ، سيزداد عدد الروابط - وعدد معلمات الوزن - زيادة هائلة. ستحتاج إلى المزيد من الصور التدريبية (وقوة الحوسبة) لتحقيق الدقة الكافية.
عندما تتعلم الشبكة العصبية التعرف على شكل موجود في مكان واحد من الصورة ، يجب أن تكون قادرة على تطبيق هذه المعرفة للتعرف على نفس الشكل في أجزاء أخرى من الصورة. يوفر SNA حلاً أنيقًا لهذه المشكلة.قال جاي تنغ الباحث في الذكاء الاصطناعي: "يبدو الأمر كما لو كنت تأخذ استنسلًا وتعلقه على جميع الأماكن في الصورة". - لديك استنسل مع صورة كلب ، وقمت أولاً بإرفاقه في الزاوية اليمنى العليا من الصورة لمعرفة ما إذا كان هناك كلب هناك؟ إذا لم يكن كذلك ، فأنت تغيري الاستنسل قليلاً. وهكذا بالنسبة للصورة بأكملها. لا يهم أين صورة الكلب. سوف الاستنسل تتطابق معها. لا تحتاج إلى كل جزء من الشبكة لمعرفة تصنيفها للكلاب. "تخيل أننا التقطنا صورة كبيرة وقسمناها إلى مربعات بحجم 28 × 28 بكسل. عندها سنكون قادرين على تغذية كل مربع من شبكة متصلة بالكامل تتعرف على خط اليد الذي درسناه من قبل. إذا تم تشغيل الإخراج "7" في واحد على الأقل من المربعات ، فستكون هذه علامة على وجود سبعة في الصورة بأكملها. هذا هو بالضبط ما تفعله الشبكات التلافيفية.كيف عملت الشبكات التلافيفية في AlexNet
في الشبكات التلافيفية ، تُعرف "الستينسلات" مثل كاشفات المعالم ، والمنطقة التي تدرس بها تُعرف باسم الحقل الاستقبالي. تعمل أجهزة الكشف عن الميزات الحقيقية مع حقول أصغر بكثير من مربع مع جانب من 28 بكسل. في AlexNet ، عمل كاشفات المعالم في الطبقة التلافيفية الأولى مع حقل تقريبي بحجم 11 × 11 بكسل. في الطبقات اللاحقة ، كانت الحقول الاستقبالية تتراوح بين 3-5 وحدات.أثناء التقاطع ، يُنتج كاشف علامات صورة الإدخال خريطة علامات: شبكة شعرية ثنائية الأبعاد ، تُلاحظ مدى قوة تنشيط الكاشف في أجزاء مختلفة من الصورة. تحتوي الطبقات التلافيفية عادةً على أكثر من كاشف ، ويقوم كل منهم بمسح الصورة بحثًا عن أنماط مختلفة. كان لدى AlexNet 96 أداة كشف للميزات في الطبقة الأولى ، مما يعطي 96 بطاقة ميزة. لفهم ذلك بشكل أفضل ، ضع في اعتبارك تمثيلًا مرئيًا للأنماط التي درسها كل من كاشفات الطبقة الأولى لـ AlexNet 96 بعد تدريب الشبكة. هناك كاشفات تبحث عن خطوط أفقية أو عمودية ، وانتقالات من الضوء إلى الظلام ، وأنماط الشطرنج والعديد من الأشكال الأخرى.يتم عادةً تمثيل صورة ملونة كخريطة بكسل مع ثلاثة أرقام لكل بكسل: قيمة الأحمر والأخضر والأزرق. تأخذ الطبقة الأولى من AlexNet وجهة النظر هذه وتحولها إلى طريقة عرض باستخدام 96 رقمًا. يحتوي كل "بكسل" في هذه الصورة على 96 قيمة ، واحدة لكل كاشف للميزات.في هذا المثال ، تشير أول 96 قيمة إلى ما إذا كانت نقطة ما في الصورة تتطابق مع هذا النمط:
لفهم ذلك بشكل أفضل ، ضع في اعتبارك تمثيلًا مرئيًا للأنماط التي درسها كل من كاشفات الطبقة الأولى لـ AlexNet 96 بعد تدريب الشبكة. هناك كاشفات تبحث عن خطوط أفقية أو عمودية ، وانتقالات من الضوء إلى الظلام ، وأنماط الشطرنج والعديد من الأشكال الأخرى.يتم عادةً تمثيل صورة ملونة كخريطة بكسل مع ثلاثة أرقام لكل بكسل: قيمة الأحمر والأخضر والأزرق. تأخذ الطبقة الأولى من AlexNet وجهة النظر هذه وتحولها إلى طريقة عرض باستخدام 96 رقمًا. يحتوي كل "بكسل" في هذه الصورة على 96 قيمة ، واحدة لكل كاشف للميزات.في هذا المثال ، تشير أول 96 قيمة إلى ما إذا كانت نقطة ما في الصورة تتطابق مع هذا النمط: تشير القيمة الثانية إلى ما إذا كانت نقطة الصورة تتزامن مع مثل هذا النمط:
تشير القيمة الثانية إلى ما إذا كانت نقطة الصورة تتزامن مع مثل هذا النمط: تشير القيمة الثالثة إلى ما إذا كانت نقطة الصورة تتزامن مع هذا النمط:
تشير القيمة الثالثة إلى ما إذا كانت نقطة الصورة تتزامن مع هذا النمط: وما إلى ذلك بالنسبة لـ 93 كاشف للميزات في طبقة AlexNet الأولى. تنتج الطبقة الأولى تمثيلًا جديدًا للصورة ، حيث يكون كل بكسل متجهًا بأبعاد 96 (وسأوضح لاحقًا أن هذا التمثيل انخفض بمقدار 4 مرات).هذه هي الطبقة الأولى من AlexNet. ثم هناك أربع طبقات تلافيفية أخرى ، تأخذ كل منها إخراج الطبقة السابقة كمدخلات.كما رأينا ، تكشف الطبقة الأولى النقوش الأساسية ، مثل الخطوط الأفقية والعمودية ، والانتقالات من الضوء إلى الظلام والمنحنيات. يستخدمهم المستوى الثاني ككتلة بناء للتعرف على النماذج المعقدة قليلاً. على سبيل المثال ، يمكن أن تحتوي الطبقة الثانية على كاشف للميزات يقوم بإيجاد دوائر تستخدم مجموعة من مخرجات كاشفات الطبقة الأولى التي تعثر على منحنيات. تجد الطبقة الثالثة أشكالًا أكثر تعقيدًا من خلال دمج ميزات من الطبقة الثانية. الرابع والخامس تجد أنماط أكثر تعقيدا.نشر الباحثان ماثيو زيلر وروب فيرجوس عملاً ممتازًا في عام 2014 ، والذي يوفر طرقًا مفيدة للغاية لتصور الأنماط المعترف بها بواسطة شبكة عصبية مكونة من خمسة طبقات تشبه ImageNet.في عرض الشرائح التالي المأخوذ من عملهم ، تحتوي كل صورة ، باستثناء الصورة الأولى ، على نصفين. على اليمين سترى أمثلة على الصور المصغرة التي نشطت بقوة كاشف ميزة معينة. يتم جمعها في تسعة - وكل مجموعة يتوافق مع كاشفها الخاص. على اليسار توجد خريطة تُبيِّن بالضبط وحدات البكسل في هذه الصورة المصغرة الأكثر مسؤولية عن المطابقة. هذا واضح بشكل خاص في الطبقة الخامسة ، نظرًا لوجود مكشافات للميزات تتفاعل بقوة مع الكلاب والشعارات والعجلات وما إلى ذلك.
وما إلى ذلك بالنسبة لـ 93 كاشف للميزات في طبقة AlexNet الأولى. تنتج الطبقة الأولى تمثيلًا جديدًا للصورة ، حيث يكون كل بكسل متجهًا بأبعاد 96 (وسأوضح لاحقًا أن هذا التمثيل انخفض بمقدار 4 مرات).هذه هي الطبقة الأولى من AlexNet. ثم هناك أربع طبقات تلافيفية أخرى ، تأخذ كل منها إخراج الطبقة السابقة كمدخلات.كما رأينا ، تكشف الطبقة الأولى النقوش الأساسية ، مثل الخطوط الأفقية والعمودية ، والانتقالات من الضوء إلى الظلام والمنحنيات. يستخدمهم المستوى الثاني ككتلة بناء للتعرف على النماذج المعقدة قليلاً. على سبيل المثال ، يمكن أن تحتوي الطبقة الثانية على كاشف للميزات يقوم بإيجاد دوائر تستخدم مجموعة من مخرجات كاشفات الطبقة الأولى التي تعثر على منحنيات. تجد الطبقة الثالثة أشكالًا أكثر تعقيدًا من خلال دمج ميزات من الطبقة الثانية. الرابع والخامس تجد أنماط أكثر تعقيدا.نشر الباحثان ماثيو زيلر وروب فيرجوس عملاً ممتازًا في عام 2014 ، والذي يوفر طرقًا مفيدة للغاية لتصور الأنماط المعترف بها بواسطة شبكة عصبية مكونة من خمسة طبقات تشبه ImageNet.في عرض الشرائح التالي المأخوذ من عملهم ، تحتوي كل صورة ، باستثناء الصورة الأولى ، على نصفين. على اليمين سترى أمثلة على الصور المصغرة التي نشطت بقوة كاشف ميزة معينة. يتم جمعها في تسعة - وكل مجموعة يتوافق مع كاشفها الخاص. على اليسار توجد خريطة تُبيِّن بالضبط وحدات البكسل في هذه الصورة المصغرة الأكثر مسؤولية عن المطابقة. هذا واضح بشكل خاص في الطبقة الخامسة ، نظرًا لوجود مكشافات للميزات تتفاعل بقوة مع الكلاب والشعارات والعجلات وما إلى ذلك. الطبقة الأولى - الأنماط والأشكال البسيطة - الطبقة
الطبقة الأولى - الأنماط والأشكال البسيطة - الطبقة الثانية - الهياكل الصغيرة تبدأ في الظهور.يمكن للكشف عن الميزات
الثانية - الهياكل الصغيرة تبدأ في الظهور.يمكن للكشف عن الميزات في الطبقة الثالثة أن يتعرف على الأشكال الأكثر تعقيدًا ، مثل عجلات السيارة ، وأقراص العسل ، وحتى الصور الظلية للأشخاص.
في الطبقة الثالثة أن يتعرف على الأشكال الأكثر تعقيدًا ، مثل عجلات السيارة ، وأقراص العسل ، وحتى الصور الظلية للأشخاص. الطبقة الرابعة قادرة على التمييز بين الأشكال المعقدة ، مثل وجوه الكلاب أو أقدام الطيور ،
الطبقة الرابعة قادرة على التمييز بين الأشكال المعقدة ، مثل وجوه الكلاب أو أقدام الطيور ، ويمكن للطبقة الخامسة التعرف على الأشكال المعقدة للغاية ،ومن خلال النظر إلى الصور ، يمكنك أن ترى كيف تستطيع كل طبقة تالية التعرف على أنماط معقدة بشكل متزايد. تتعرف الطبقة الأولى على الأنماط البسيطة التي لا تشبه أي شيء. والثاني يتعرف على القوام والأشكال البسيطة. في الطبقة الثالثة ، تصبح الأشكال التي يمكن التعرف عليها مثل العجلات والمجالات البرتقالية الحمراء (الطماطم ، الخنافس ، شيء آخر) مرئية.في الطبقة الأولى ، يكون جانب الحقل الاستقبالي هو 11 ، وفي الجزء الأخير ، من ثلاثة إلى خمسة. لكن تذكر أن الطبقات اللاحقة تتعرف على خرائط المعالم التي تم إنشاؤها بواسطة الطبقات السابقة ، لذلك تشير كل من "وحدات البكسل" إلى عدة وحدات بكسل للصورة الأصلية. لذلك ، يتضمن حقل الاستلام لكل طبقة جزءًا أكبر من الصورة الأولى من الطبقات السابقة. هذا جزء من السبب في أن الصور المصغرة في الطبقات اللاحقة تبدو أكثر تعقيدًا من الطبقات السابقة.الطبقة الخامسة الأخيرة من الشبكة قادرة على التعرف على مجموعة كبيرة من العناصر المثيرة للإعجاب. على سبيل المثال ، انظر إلى هذه الصورة التي حددتها من الزاوية اليمنى العليا من الصورة المقابلة للطبقة الخامسة:
ويمكن للطبقة الخامسة التعرف على الأشكال المعقدة للغاية ،ومن خلال النظر إلى الصور ، يمكنك أن ترى كيف تستطيع كل طبقة تالية التعرف على أنماط معقدة بشكل متزايد. تتعرف الطبقة الأولى على الأنماط البسيطة التي لا تشبه أي شيء. والثاني يتعرف على القوام والأشكال البسيطة. في الطبقة الثالثة ، تصبح الأشكال التي يمكن التعرف عليها مثل العجلات والمجالات البرتقالية الحمراء (الطماطم ، الخنافس ، شيء آخر) مرئية.في الطبقة الأولى ، يكون جانب الحقل الاستقبالي هو 11 ، وفي الجزء الأخير ، من ثلاثة إلى خمسة. لكن تذكر أن الطبقات اللاحقة تتعرف على خرائط المعالم التي تم إنشاؤها بواسطة الطبقات السابقة ، لذلك تشير كل من "وحدات البكسل" إلى عدة وحدات بكسل للصورة الأصلية. لذلك ، يتضمن حقل الاستلام لكل طبقة جزءًا أكبر من الصورة الأولى من الطبقات السابقة. هذا جزء من السبب في أن الصور المصغرة في الطبقات اللاحقة تبدو أكثر تعقيدًا من الطبقات السابقة.الطبقة الخامسة الأخيرة من الشبكة قادرة على التعرف على مجموعة كبيرة من العناصر المثيرة للإعجاب. على سبيل المثال ، انظر إلى هذه الصورة التي حددتها من الزاوية اليمنى العليا من الصورة المقابلة للطبقة الخامسة: الصور التسعة الموجودة على اليمين قد لا تكون متشابهة. ولكن إذا نظرت إلى تسعة خرائط حرارة على اليسار ، فسترى أن مكشاف الميزة هذا لا يركز على الكائنات الموجودة في مقدمة الصور. بدلاً من ذلك ، يركز على العشب في خلفية كل منهم!من الواضح أن كاشف الحشائش مفيد إذا كانت إحدى الفئات التي تحاول تحديدها هي "عشب" ، لكن يمكن أن يكون مفيدًا للعديد من الفئات الأخرى. بعد خمس طبقات تلافيفية ، لدى AlexNet ثلاث طبقات متصلة تمامًا ، مثل شبكتنا للتعرف على خط اليد. تفحص هذه الطبقات كل من خرائط الميزات الصادرة عن خمس طبقات تلافيفية ، في محاولة لتصنيف الصورة في واحدة من 1000 فئة ممكنة.لذلك إذا كان هناك عشب في الخلفية ، فمع وجود احتمال كبير ، سيكون هناك حيوان بري في الصورة. من ناحية أخرى ، إذا كان هناك عشب في الخلفية ، فمن غير المرجح أن تكون صورة للأثاث في المنزل. توفر هذه وغيرها من كاشفات الطبقة الخامسة طنًا من المعلومات حول المحتوى المحتمل للصورة. تقوم الطبقات الأخيرة من الشبكة بتجميع هذه المعلومات لتوفير تخمين مدعوم بالحقائق حول ما يتم تصويره بشكل عام في الصورة.
الصور التسعة الموجودة على اليمين قد لا تكون متشابهة. ولكن إذا نظرت إلى تسعة خرائط حرارة على اليسار ، فسترى أن مكشاف الميزة هذا لا يركز على الكائنات الموجودة في مقدمة الصور. بدلاً من ذلك ، يركز على العشب في خلفية كل منهم!من الواضح أن كاشف الحشائش مفيد إذا كانت إحدى الفئات التي تحاول تحديدها هي "عشب" ، لكن يمكن أن يكون مفيدًا للعديد من الفئات الأخرى. بعد خمس طبقات تلافيفية ، لدى AlexNet ثلاث طبقات متصلة تمامًا ، مثل شبكتنا للتعرف على خط اليد. تفحص هذه الطبقات كل من خرائط الميزات الصادرة عن خمس طبقات تلافيفية ، في محاولة لتصنيف الصورة في واحدة من 1000 فئة ممكنة.لذلك إذا كان هناك عشب في الخلفية ، فمع وجود احتمال كبير ، سيكون هناك حيوان بري في الصورة. من ناحية أخرى ، إذا كان هناك عشب في الخلفية ، فمن غير المرجح أن تكون صورة للأثاث في المنزل. توفر هذه وغيرها من كاشفات الطبقة الخامسة طنًا من المعلومات حول المحتوى المحتمل للصورة. تقوم الطبقات الأخيرة من الشبكة بتجميع هذه المعلومات لتوفير تخمين مدعوم بالحقائق حول ما يتم تصويره بشكل عام في الصورة.ما الذي يجعل الطبقات التلافيفية مختلفة: أوزان المدخلات الشائعة
لقد رأينا أن كاشفات المعالم على الطبقات التلافيفية تُظهر التعرف على الأنماط بشكل مثير للإعجاب ، لكن حتى الآن لم أشرح كيف تعمل الشبكات التلافيفية بالفعل.تتكون الطبقة التلافيفية (SS) من الخلايا العصبية. هم ، مثل أي خلايا عصبية ، يأخذون متوسطًا مرجحًا عند الإدخال ويستخدمون وظيفة التنشيط. يتم تدريب المعلمات باستخدام تقنيات الانتشار الخلفي.ولكن على عكس NS السابق ، فإن SS غير متصل بالكامل. كل خلية عصبية تتلقى مدخلات من جزء صغير من الخلايا العصبية من الطبقة السابقة. والأهم من ذلك أن الخلايا العصبية الشبكية التلافيفية لها أوزان شائعة في المدخلات.لنلقِ نظرة على أول خلية عصبية من أول جهاز AlexNet SS بمزيد من التفاصيل. يبلغ حجم حقل الاستلام لهذه الطبقة 11 × 11 بكسل ، وبالتالي فإن الخلية العصبية الأولى تدرس مربعًا بحجم 11 × 11 بكسل في زاوية واحدة من الصورة. تتلقى هذه الخلية العصبية مدخلات من 121 بكسل ، ولكل بكسل ثلاث قيم - الأحمر والأخضر والأزرق. لذلك ، بشكل عام ، لدى الخلايا العصبية 363 معلمة إدخال. مثل أي خلية عصبية ، يأخذ هذا المتوسط معدل مرجح قدره 363 معلمة ، ويطبق وظيفة التنشيط عليها. وبما أن معلمات الإدخال هي 363 ، فإن معلمات الوزن تحتاج أيضًا إلى 363.الخلايا العصبية الثانية من الطبقة الأولى تشبه الأولى. كما يدرس المربعات التي تبلغ 11 × 11 بكسل ، لكن حقل الاستلام الخاص به قد تم تغييره بأربعة بكسل بالنسبة إلى الأول. يحتوي الحقلان على تراكب يبلغ 7 بكسل ، لذلك لا تغفل الشبكة الأنماط المثيرة للاهتمام التي وقعت في تقاطع المربعين. تأخذ الخلية العصبية الثانية أيضًا 363 معلمة تصف المربع 11 × 11 ، وتضاعف كل منها بالوزن ، وتضيف وظيفة التنشيط وتطبقها.ولكن بدلاً من استخدام مجموعة منفصلة من 363 أوزانًا ، تستخدم الخلية العصبية الثانية نفس الأوزان مثل الأولى. يستخدم البكسل العلوي الأيسر من الخلية العصبية الأولى نفس الأوزان مثل البكسل العلوي الأيسر في الثانية. لذلك ، كلا الخلايا العصبية تبحث عن نفس النمط. يتم تبديل حقولهم الاستقبالية ببساطة 4 بكسل بالنسبة لبعضهم البعض.بطبيعة الحال ، هناك أكثر من خليتين: في الشبكة 55x55 يوجد 3025 خلية عصبية. كل واحد منهم يستخدم نفس المجموعة من 363 أوزان مثل الأولين. تشكل جميع الخلايا العصبية معًا كاشفًا للميزات "يمسح" الصورة للنمط المرغوب ، والذي يمكن تحديد موقعه في أي مكان.تذكر أن طبقة AlexNet الأولى تحتوي على 96 أداة كشف للميزات. الخلايا العصبية 3025 التي ذكرتها للتو تشكل واحدة من هذه 96 كاشفات. كل من 95 المتبقية هي مجموعة منفصلة من 3025 الخلايا العصبية. تستخدم كل مجموعة مؤلفة من 3025 خلية عصبية مجموعة شائعة من 363 أوزانًا - ومع ذلك ، لكل مجموعة من 95 مجموعة لها.يتم تدريب الموجات الديكامترية (HFs) باستخدام نفس المادة الخلفية المستخدمة في الشبكات المتصلة بالكامل ، لكن الهيكل التلافيفي يجعل عملية التعلم أكثر كفاءة وفعالية.وقال شون جريش ، خبير في الدفاع والترخيص: "إن استخدام الإلتواء يساعد حقًا - يمكن إعادة استخدام المعايير". هذا يقلل بشكل كبير من عدد أوزان المدخلات التي يجب أن تتعلمها الشبكة ، مما يسمح لها بتقديم نتائج أفضل مع عدد أقل من أمثلة التدريب.يؤدي التعلم في جزء واحد من الصورة إلى تحسين التعرف على نفس النمط في أجزاء أخرى من الصورة. يتيح ذلك للشبكة تحقيق أداء عالٍ في عدد أقل بكثير من أمثلة التدريب.أدرك الناس بسرعة قوة الشبكات التلافيفية العميقة.
أصبح عمل AlexNet ضجة كبيرة في الأوساط الأكاديمية في منطقة موسكو ، ولكن أهميته سرعان ما فهمت في صناعة تكنولوجيا المعلومات. كانت Google مهتمة بها بشكل خاص.
في عام 2013 ، حصلت Google على شركة ناشئة أسسها مؤلفون AlexNet. استخدمت الشركة هذه التقنية لإضافة ميزة جديدة للبحث عن الصور إلى صور Google. كتب تشاك روزنبرغ من جوجل: "لقد أخذنا البحث المتقدم ونطبقه بعد أكثر من ستة أشهر بقليل".
وفي الوقت نفسه ، في عام 2013 ، تم وصف كيفية استخدام Google لنظام GSS للتعرف على عناوين صور Google Street View. "ساعدنا نظامنا على استخراج ما يقرب من 100 مليون عنوان فعلي من هذه الصور" ، كتب المؤلفون.
وجد الباحثون أن فعالية NS تنمو بعمق متزايد. "لقد وجدنا أن فعالية هذا النهج تزداد مع عمق نظام الحسابات القومية ، وأعمق البنى التي دربناها تظهر أفضل النتائج" ، كتب فريق Google Street View. "تشير تجاربنا إلى أن البنى الأعمق يمكن أن تنتج دقة أكبر ، لكن مع تباطؤ في الكفاءة".
لذلك بعد AlexNet ، بدأت الشبكات تزداد عمقا. قدم فريق Google عرضًا في المسابقة في عام 2014 - بعد عامين فقط من فوز AlexNet في عام 2012. كما كان يستند إلى نظام الحسابات القومية العميق ، لكن Goolge استخدم شبكة أعمق بكثير من 22 طبقة لتحقيق معدل خطأ قدره 6.7 ٪ - كان هذا تحسنا كبيرا مقارنة بـ 16 ٪ من AlexNet.
ولكن في الوقت نفسه ، عملت الشبكات الأعمق بشكل أفضل فقط مع مجموعات أكبر من بيانات التدريب. لذلك ، يقول جريش إن مجموعة البيانات والمنافسة ImageNet لعبت دوراً رئيسياً في نجاح نظام الحسابات القومية. تذكر أنه في مسابقة ImageNet ، يتم إعطاء المشاركين مليون صورة ويطلب منهم فرزها إلى 1000 فئة.
وقال جيريش: "إذا كان لديك مليون صورة للتدريب ، فإن كل فصل يتضمن 1000 صورة". وقال إنه بدون مجموعة البيانات الكبيرة هذه ، "سيكون لديك الكثير من الخيارات لتدريب الشبكة."
في السنوات الأخيرة ، يركز الخبراء بشكل متزايد على جمع كمية هائلة من البيانات لتدريب شبكات أعمق وأكثر دقة. ولهذا السبب تركز الشركات التي تطور سيارات روبوتية على السير على الطرق العامة - يتم إرسال الصور ومقاطع الفيديو الخاصة بهذه الرحلات إلى المقر الرئيسي وتستخدم لتدريب شركات NS.
الحوسبة التعلم العميق بوم
إن اكتشاف حقيقة أن الشبكات الأعمق ومجموعات البيانات الأكبر يمكنها تحسين أداء NS قد أحدث تعطشًا لا يشبع لإطالة قوة الحوسبة. كان أحد المكونات الرئيسية لنجاح AlexNet هو فكرة استخدام تدريب المصفوفات في تدريب NS ، والذي يمكن تنفيذه بكفاءة على وحدات معالجة الرسومات المتوازية.
قال جاي تين ، باحث في وزارة التربية: "إن NSs متوازنة بشكل جيد". أثبتت بطاقات الرسومات - التي توفر قوة معالجة متوازية هائلة لألعاب الفيديو - أنها مفيدة لأجهزة NS.
وقال تين: "الجزء المركزي من عمل وحدة معالجة الرسومات (GPU) ، الضرب السريع للغاية للمصفوفة ، اتضح أنه الجزء الرئيسي من عمل الجمعية الوطنية".
كل هذا كان ناجحًا بالنسبة لمصنعي GPU و Nvidia و AMD الرائدين. طورت كلتا الشركتين رقائق جديدة مصممة خصيصًا لتلبية احتياجات تطبيق MO ، والآن أصبحت تطبيقات AI مسؤولة عن جزء كبير من مبيعات GPU لهذه الشركات.
في عام 2016 ، أعلنت Google عن إنشاء شريحة خاصة ، هي وحدة معالجة Tensor (TPU) ، المصممة للعمل في الجمعية الوطنية.
كتب متحدث باسم الشركة في العام الماضي: "على الرغم من أن Google كانت تفكر في إنشاء دوائر متكاملة ذات أغراض خاصة (ASICs) في عام 2006 ، إلا أن هذا الموقف أصبح عاجلاً في عام 2013". "لقد أدركنا حينها أن المتطلبات السريعة النمو للجمعية الوطنية للطاقة الحاسوبية قد تتطلب منا مضاعفة عدد مراكز البيانات المتوفرة لدينا."
في البداية ، كانت خدمات Google الخاصة هي فقط التي يمكنها الوصول إلى TPUs ، لكن الشركة سمحت لاحقًا للجميع باستخدام هذه التقنية من خلال منصة الحوسبة السحابية.
بالطبع ، Google ليست الشركة الوحيدة التي تعمل على رقائق AI. مجرد أمثلة قليلة: في أحدث إصدارات شرائح iPhone
هناك "جوهر عصبي" الأمثل للعمليات مع NS. تقوم Intel
بتطوير مجموعة رقائق خاصة بها ل GO.
أعلنت شركة Tesla مؤخرًا رفض الرقائق من شركة Nvidia لصالح رقائق NS الخاصة بها. يشاع أيضا أن الأمازون
تعمل على رقائق AI.
لماذا يصعب فهم الشبكات العصبية العميقة
شرحت كيفية عمل الشبكات العصبية ، لكنني لم أوضح سبب عملها بشكل جيد. ليس من الواضح كيف بالضبط كمية هائلة من حسابات المصفوفة يسمح لنظام الكمبيوتر لتمييز جاكوار من الفهد ، و Eldberry من الكشمش.
ولعل أبرز ما في الجمعية الوطنية هو أنها لا تفعل ذلك. يسمح الإلتفاف NS لفهم الواصلة - يمكنهم معرفة ما إذا كانت الصورة من الزاوية اليمنى العليا من الصورة تشبه الصورة الموجودة في الزاوية اليسرى العليا من صورة أخرى.
لكن في الوقت نفسه ، ليس لدى SNA فكرة عن الهندسة. لا يمكنهم التعرف على تشابه الصورتين إذا تم تدويرهما بزاوية 45 درجة أو الضعف. SNA لا يحاول فهم بنية ثلاثية الأبعاد للكائنات ، ولا يمكن أن تأخذ في الاعتبار ظروف الإضاءة المختلفة.
ولكن في الوقت نفسه ، يمكن أن تتعرف NS على صور للكلاب التي تم التقاطها من الأمام ومن الجانب ، ولا يهم ما إذا كان الكلب يشغل جزءًا صغيرًا من الصورة أو جزءًا كبيرًا. كيف يفعلون ذلك؟ اتضح أنه إذا كانت هناك بيانات كافية ، فإن النهج الإحصائي مع التعداد المباشر يمكنه التعامل مع المهمة. لم يتم تصميم نظام الحسابات القومية بحيث يمكنه "تخيل" كيف ستبدو صورة معينة من زاوية مختلفة أو في ظروف مختلفة ، ولكن مع وجود عدد كاف من الأمثلة المصنفة ، يمكنه تعلم جميع الأشكال الممكنة للصورة عن طريق التكرار البسيط.
هناك دليل على أن النظام البصري للأشخاص يعمل بطريقة مماثلة. انظر إلى بضع صور - أولاً قم أولاً بدراسة الأول بعناية ، ثم افتح الثانية.
 الصورة الأولى
الصورة الأولىالتقط مُبدع الصورة صورة شخص ما وقلب عينيه وفمه رأسًا على عقب. تبدو الصورة طبيعية نسبيًا عندما تنظر إليها رأسًا على عقب ، لأن النظام البصري البشري يستخدم لرؤية العينين والفم في هذا الموضع. ولكن إذا نظرت إلى الصورة في الاتجاه الصحيح ، يمكنك أن ترى على الفور أن الوجه مشوه بشكل غريب.
هذا يشير إلى أن النظام البصري البشري يعتمد على نفس تقنيات التعرف على الأنماط الخام مثل NS. إذا نظرنا إلى شيء مرئي دائمًا في اتجاه واحد - العين البشرية - يمكننا التعرف عليه بشكل أفضل في اتجاهه الطبيعي.
NSs تتعرف بشكل جيد على الصور باستخدام كل السياق المتاح عليها. على سبيل المثال ، عادة ما تقود السيارات على الطرق. عادة ما تلبس الفساتين على جسم المرأة أو تتدلى في خزانة. وعادة ما يتم إطلاق النار على الطائرات أو السماء التي تحكم على المدرج. لا أحد يعلم على وجه التحديد NS هذه الارتباطات ، ولكن مع عدد كاف من الأمثلة المسمى ، يمكن أن تتعلم الشبكة نفسها.
في عام 2015 ، حاول باحثون من Google فهم NS بشكل أفضل "تشغيلهم للخلف". بدلاً من استخدام الصور للتدريب NS ، استخدموا NS تدريب لتغيير الصور. على سبيل المثال ، بدأوا مع صورة تحتوي على ضوضاء عشوائية ، ثم قاموا بتغييرها تدريجياً بحيث نشطت بقوة أحد الخلايا العصبية في NS - في الواقع ، طلبوا من NS "رسم" إحدى الفئات التي تم تعليمها للتعرف عليها. في حالة واحدة مثيرة للاهتمام ، أجبروا NS على إنشاء الصور التي تنشط NS ، والمدربين على التعرف على الدمبل.

"بالطبع ، هناك دمبل هنا ، لكن ليست هناك صورة واحدة من الدمبل تبدو كاملة دون وجود لفافة العضلات العضلية التي ترفعها" ، كتب باحثو Google.
للوهلة الأولى يبدو غريباً ، لكنه في الواقع لا يختلف كثيراً عما يفعله الناس. إذا رأينا كائنًا صغيرًا أو غير واضح في الصورة ، فإننا نبحث عن فكرة في محيطها لفهم ما يمكن أن يحدث هناك. من الواضح أن الناس يتحدثون عن الصور بشكل مختلف ، مستخدمين فهمًا مفاهيميًا معقدًا للعالم من حولهم. لكن في النهاية ، تتعرف STS على الصور جيدًا ، لأنها تستفيد استفادة كاملة من السياق بأكمله المرسوم عليها ، وهذا لا يختلف كثيرًا عن كيفية قيام الناس بذلك.