
في 14 مايو ، عندما كان ترامب يستعد لإطلاق جميع الكلاب على Huawei ، جلست بهدوء في Shenzhen على Huawei STW 2019 - مؤتمر كبير لـ 1000 مشارك - تضمن تقارير من
Philip Wong ، نائب رئيس أبحاث TSMC حول آفاق الحوسبة غير فون نيومان الهندسة المعمارية ، وهينغ لياو ، زميل Huawei ، كبير العلماء Huawei 2012 Lab ، حول تطوير بنية جديدة من معالجات التنس والمعالجات العصبية. إن TSMC ، إذا كنت تعرف ، يصنع المعجلات العصبية لشركة Apple و Huawei باستخدام تقنية 7 نانومتر (التي
يمتلكها عدد قليل من الأشخاص ) ، و Huawei مستعدة للتنافس مع Google و NVIDIA للمعالجات العصبية.
تم حظر Google في الصين ، ولم أكن مضطرا لوضع VPN على الجهاز اللوحي ، لذلك استخدمت
وطنيًا Yandex لمعرفة ما هو الوضع مع الشركات المصنعة الأخرى من الحديد المشابه ، وما يحدث عمومًا. بشكل عام ، شاهدت الموقف ، لكن بعد هذه التقارير فقط أدركت مدى استعداد الثورة على نطاق واسع في أحشاء الشركات وصمت الغرف العلمية.
في العام الماضي وحده ، تم استثمار أكثر من 3 مليارات دولار في هذا الموضوع. أعلنت Google منذ فترة طويلة أن الشبكات العصبية مجال استراتيجي ، تعمل بنشاط على دعم دعم الأجهزة والبرامج. تبذل NVIDIA ، التي تشعر أن العرش مذهل ، جهودًا رائعة في مكتبات تسريع الشبكة العصبية والأجهزة الجديدة. أنفقت إنتل في عام 2016 0.8 مليار دولار لشراء شركتين منخرطتين في تسريع أجهزة الشبكات العصبية. وهذا على الرغم من حقيقة أن المشتريات الرئيسية لم تبدأ بعد ، وقد تجاوز عدد اللاعبين خمسين ونموًا سريعًا.
TPU ، VPU ، IPU ، DPU ، NPU ، RPU ، NNP - ماذا يعني كل هذا ومن سيفوز؟ دعنا نحاول معرفة ذلك. من يهتم - مرحبا بكم في القط!
إخلاء المسئولية: اضطر المؤلف إلى إعادة كتابة خوارزميات معالجة الفيديو بالكامل للتنفيذ الفعال على ASIC ، وقام العملاء بعمل نماذج أولية على FPGA ، لذلك هناك فكرة عن عمق الاختلاف في البنى. ومع ذلك ، فإن المؤلف لم يعمل مباشرة مع الحديد مؤخرا. لكنه يتوقع أنه سوف تضطر إلى الخوض في ذلك.
خلفية المشاكل
يتزايد عدد العمليات الحسابية المطلوبة بسرعة ، وسيحب الناس أن يأخذوا المزيد من الطبقات ، والمزيد من خيارات الهندسة المعمارية ، ولعب أكثر نشاطًا باستخدام المعلمات الفائقة ، ولكن ... يعتمد ذلك على الأداء. في الوقت نفسه ، على سبيل المثال ، مع نمو إنتاجية المعالجات القديمة الجيدة - مشاكل كبيرة. انتهت جميع الأشياء الجيدة: قانون مور ، كما تعلم ، ينفد وينخفض معدل نمو أداء المعالج:
حسابات الأداء الحقيقي لعمليات عدد صحيح على SPECint مقارنة مع VAX11-780 ، فيما يلي في كثير من الأحيان مقياس لوغاريتميإذا كان معدل النمو من منتصف الثمانينات إلى منتصف العقد الأول من القرن العشرين - في السنوات المباركة من ذروة أجهزة الكمبيوتر - بمعدل 52 في المائة سنويًا ، فقد انخفض في السنوات الأخيرة إلى 3 في المائة سنويًا. وهذه مشكلة (ترجمة لمقال أخير للبطريرك جون هينيسي حول مشاكل وآفاق العمارة الحديثة
كان على هابري ).
هناك العديد من الأسباب ، على سبيل المثال ، توقف تواتر المعالجات عن النمو:
أصبح من الصعب تقليل حجم الترانزستورات. آخر مصيبة تؤدي إلى انخفاض كبير في الإنتاجية (بما في ذلك أداء وحدات المعالجة المركزية التي تم إصدارها بالفعل) هي (لفة الأسطوانة) ... السلامة والأمان.
الانهيار ،
Specter وغيرها من نقاط الضعف تسبب أضرارا هائلة في معدل نمو الطاقة وحدة المعالجة المركزية (
مثال على تعطيل hyperthreading (!)). أصبح الموضوع شائعًا ، وتوجد نقاط ضعف جديدة من هذا النوع
تقريبًا تقريبًا . وهذا نوع من الكابوس ، لأنه يؤلمني من حيث الأداء.
في الوقت نفسه ، يرتبط تطوير العديد من الخوارزميات ارتباطًا وثيقًا بالنمو المألوف في طاقة المعالج. على سبيل المثال ، لا يشعر الكثير من الباحثين اليوم بالقلق من سرعة الخوارزميات - فهم سيخرجون بشيء ما. وسيكون من الرائع عند التعلم - أن تصبح الشبكات كبيرة و "صعبة" للاستخدام. يتضح هذا بشكل خاص في الفيديو ، حيث لا تنطبق معظم الطرق ، من حيث المبدأ ، على السرعة العالية. وغالبا ما يكون له معنى فقط في الوقت الحقيقي. هذه أيضا مشكلة.
وبالمثل ، يجري تطوير معايير ضغط جديدة تنطوي على زيادة في قدرة فك التشفير. وإذا كانت قوة المعالج لا تنمو؟ يتذكر الجيل الأقدم أنه في عام 2000 كانت هناك مشاكل في تشغيل الفيديو عالي الدقة في جهاز
H.264 الجديد على أجهزة الكمبيوتر القديمة. نعم ، كانت الجودة أفضل مع حجم أصغر ، ولكن في المشاهد السريعة كانت الصورة معلقة أو تمزق الصوت. يجب أن أتواصل مع مطوري
VVC / H.266 الجديدة (من المخطط إصداره في العام المقبل). لن تحسدهم.
لذا ، ما الذي يستعد لنا القرن القادم في ضوء انخفاض معدل نمو أداء المعالج كما هو مطبق على الشبكات العصبية؟
وحدة المعالجة المركزية
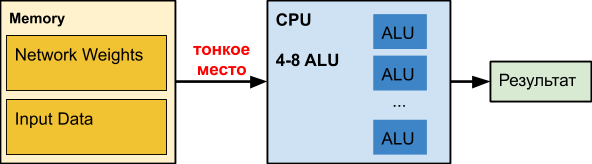 وحدة المعالجة المركزية
وحدة المعالجة المركزية العادية هي محطم رقم كبير تم إتقانه على مدار عقود. للأسف ، لمهام أخرى.
عندما نعمل مع الشبكات العصبية ، خاصة الشبكات العميقة ، يمكن لشبكتنا نفسها أن تحتل مئات الميجابايت. على سبيل المثال ، متطلبات الذاكرة لشبكات
الكشف عن الكائنات هي كما يلي:
في تجربتنا ، يمكن أن تشغل معاملات الشبكة العصبية العميقة لمعالجة
الحدود الشفافة 150-200 ميغابايت. يحدد الزملاء في الشبكة العصبية العمر والجنس لحجم المعاملات البالغة 50 ميجابايت. وخلال التحسين لإصدار الهاتف المحمول من دقة منخفضة - حوالي 25 ميغابايت (float32⇒float16).
في الوقت نفسه ، يتم توزيع الرسم البياني للتأخير عند الوصول إلى الذاكرة وفقًا لحجم البيانات
تقريبًا مثل هذا (المقياس الأفقي لوغاريتمي):
أي مع زيادة حجم البيانات لأكثر من 16 ميغابايت ، يزيد التأخير بمقدار 50 مرة أو أكثر ، مما يؤثر بشكل قاتل على الأداء. في الواقع ، في معظم الأوقات ، وحدة المعالجة المركزية ، عند العمل مع الشبكات العصبية العميقة ، تنتظر
بغباء البيانات.
تعد بيانات Intel حول تسريع مختلف الشبكات مهمة ، حيث ، في الواقع ، لا يحدث التسارع إلا عندما تصبح الشبكة صغيرة (على سبيل المثال ، نتيجة لتقدير الأوزان) ، من أجل البدء على الأقل في إدخال ذاكرة التخزين المؤقت جنبًا إلى جنب مع البيانات المعالجة. لاحظ أن ذاكرة التخزين المؤقت لوحدة المعالجة المركزية الحديثة تستهلك ما يصل إلى نصف طاقة المعالج. في حالة الشبكات العصبية الثقيلة ، فإنه غير فعال ويعمل سخان باهظ الثمن بشكل غير معقول.
لأتباع الشبكات العصبية على وحدة المعالجة المركزيةوفقًا لاختباراتنا الداخلية ، يفقد
Intel OpenVINO تطبيق إطار مصفوفة الضرب + إطار NNPACK على العديد من أبنية الشبكات (خاصة في البُنى البسيطة حيث يكون النطاق الترددي مهمًا لمعالجة البيانات في الوقت الفعلي في وضع ترابط واحد). مثل هذا السيناريو مناسب للعديد من مصنفات الكائنات في الصورة (حيث تحتاج الشبكة العصبية إلى تشغيل عدد كبير من المرات - 50-100 من حيث عدد الكائنات في الصورة) وتصبح النفقات العامة لبدء OpenVINO عالية بشكل غير معقول.
الايجابيات:- "كل شخص لديه" ، وعادة ما يكون خاملاً ، أي سعر دخول منخفض نسبيا للفواتير والتنفيذ.
- هناك شبكات منفصلة غير ذات سير ذاتية تتناسب بشكل جيد مع وحدة المعالجة المركزية ، كما يتصل بها الزملاء ، على سبيل المثال ، Wide & Deep و GNMT.
أقل:- وحدة المعالجة المركزية غير فعالة عند العمل مع الشبكات العصبية العميقة (عندما يكون عدد طبقات الشبكة وحجم بيانات المدخلات كبيرة) ، كل شيء يعمل ببطء شديد.
GPU

الموضوع معروف جيدًا ، لذلك نوجز بإيجاز الشيء الرئيسي. في حالة الشبكات العصبية ، تتمتع
وحدة معالجة الرسومات (GPU) بميزة أداء كبيرة في مهام متوازية بشكل كبير:
انتبه إلى كيفية حل
Xeon Phi 7290 ذي النواة 72 ، بينما "الأزرق" هو أيضًا خادم Xeon ، أي لا تستسلم Intel بهذه السهولة ، والتي ستتم مناقشتها أدناه. ولكن الأهم من ذلك أن ذاكرة بطاقات الفيديو صُممت في الأصل للحصول على أداء أعلى بنحو 5 مرات. في الشبكات العصبية ، الحوسبة مع البيانات بسيطة للغاية. بعض الإجراءات الأولية ، ونحن بحاجة إلى بيانات جديدة. نتيجة لذلك ، تعد سرعة الوصول إلى البيانات أمرًا ضروريًا للتشغيل الفعال لشبكة عصبية. ذاكرة عالية السرعة "على متن" GPU ونظام إدارة ذاكرة التخزين المؤقت أكثر مرونة من على وحدة المعالجة المركزية يمكن أن تحل هذه المشكلة:
منذ عدة سنوات ، كان تيم ديمرز يدعم المراجعة المثيرة للاهتمام
"ما هي GPU (s) التي يجب الحصول عليها من أجل التعلم العميق: تجربتي ومشورة حول استخدام GPUs في التعلم العميق" ("أي GPU أفضل للتعلم العميق ..."). من الواضح أن Tesla و Titans يحكمان التدريب ، على الرغم من أن الاختلاف في البنى يمكن أن يتسبب في فورة مثيرة للاهتمام ، على سبيل المثال ، في حالة الشبكات العصبية المتكررة (والزعيم بشكل عام هو TPU ، ملاحظة للمستقبل):
ومع ذلك ، هناك مخطط أداء مفيد للغاية للدولار ، حيث على حصان
RTX (على الأرجح بسبب
النوى Tensor الخاصة بهم ) ، إذا كان لديك ذاكرة كافية لذلك ، بالطبع:
بالطبع ، تكلفة الحوسبة مهمة. المركز الثاني من التصنيف الأول والأخير من الثانية - يباع
Tesla V100 مقابل 700 ألف روبل ، مثل 10 أجهزة كمبيوتر "عادية" (+ مفتاح Infiniband غالي الثمن ، إذا كنت تريد التدريب على عدة عقد). صحيح V100 ويعمل لمدة عشرة. الناس على استعداد لدفع مبالغ زائدة لتسريع التعلم.
المجموع ، تلخيص!
الايجابيات:- الكاردينال - 10-100 مرات - تسارع مقارنة وحدة المعالجة المركزية.
- فعالة للغاية للتدريب (وأقل فعالية إلى حد ما للاستخدام).
أقل:- تتجاوز تكلفة بطاقات الفيديو الراقية (التي تحتوي على ذاكرة كافية لتدريب الشبكات الكبيرة) تكلفة باقي الكمبيوتر ...
FPGA
 FPGA
FPGA هو بالفعل أكثر إثارة للاهتمام. هذه شبكة تضم عدة ملايين من الكتل القابلة للبرمجة ، ويمكننا أيضًا ربطها برمجياً.
تبدو الشبكة والكتل مثل هذا (عنق الزجاجة هو عنق الزجاجة ، انتبه ، مرة أخرى أمام ذاكرة الشريحة ، ولكن الأمر أسهل ، والذي سيتم وصفه أدناه):
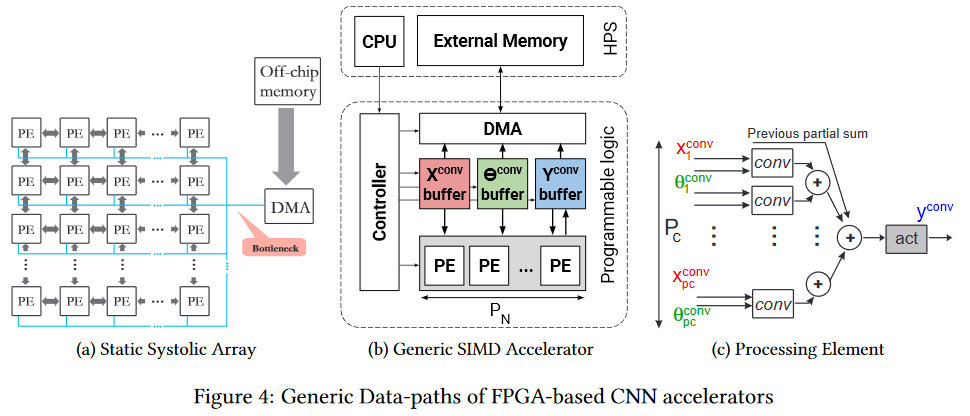
بطبيعة الحال ، من المنطقي استخدام FPGA بالفعل في مرحلة استخدام الشبكة العصبية (في معظم الحالات ، لا توجد ذاكرة كافية للتدريب). علاوة على ذلك ، فإن موضوع التنفيذ على FPGA قد بدأ الآن في التطور بنشاط. على سبيل المثال ، فيما
يلي إطار عمل fpgaConvNet ، والذي يمكنه تسريع استخدام CNN على FPGAs بشكل كبير وتقليل استهلاك الطاقة.
تتمثل الوظيفة الإضافية لـ FPGA في أنه يمكننا تخزين الشبكة مباشرةً في الخلايا ، أي تختفي نقطة رقيقة في شكل مئات ميغابايت من نفس البيانات يتم نقلها 25 مرة في الثانية (للفيديو) في نفس الاتجاه بطريقة سحرية. هذا يسمح لسرعة أقل على مدار الساعة وعدم وجود مخابئ بدلاً من انخفاض الأداء للحصول على زيادة ملحوظة. نعم ، والحد بشكل كبير من استهلاك الطاقة في
ظاهرة الاحتباس الحراري لكل وحدة حسابية.
انضمت إنتل بنشاط إلى هذه العملية ، حيث
أطلقت مجموعة أدوات OpenVINO في المصدر المفتوح العام الماضي ، والتي تتضمن
مجموعة أدوات التعليم العميق (جزء من
OpenCV ). علاوة على ذلك ، يبدو الأداء على FPGAs على شبكات مختلفة مثيرًا للاهتمام ، وميزة FPGAs مقارنةً بوحدات معالجة الرسومات (على الرغم من وحدات معالجة الرسومات المدمجة Intel) كبيرة جدًا:
ما الذي يسخن بشكل خاص روح المؤلف - تتم مقارنة FPS ، أي الإطارات في الثانية الواحدة هي المقياس الأكثر عملية للفيديو. نظرًا لأن شركة Intel اشترت
Altera ، ثاني أكبر لاعب في سوق FPGA ، في عام 2015 ، فإن المخطط يوفر طعامًا جيدًا للتفكير.
ومن الواضح أن حاجز الدخول إلى مثل هذه البنى أعلى ، لذا يجب مرور بعض الوقت قبل ظهور أدوات ملائمة تأخذ بشكل فعال بنية FPGA المختلفة اختلافًا جوهريًا. ولكن التقليل من إمكانات التكنولوجيا لا يستحق كل هذا العناء. انها مؤلمة العديد من الأماكن رقيقة أنها التطريز.
أخيرًا ، نؤكد أن
برمجة FPGAs هي فن منفصل. على هذا النحو ، لا يتم تنفيذ البرنامج هناك ، ويتم إجراء جميع العمليات الحسابية من حيث تدفقات البيانات ، وتأخير الدفق (الذي يؤثر على الأداء) والبوابات المستخدمة (التي تفتقر دائمًا). لذلك ، من أجل البدء في البرمجة الفعالة ، تحتاج إلى
تغيير البرامج الثابتة الخاصة بك (في الشبكة العصبية الواقعة بين أذنيك). مع كفاءة جيدة ، لا يتم الحصول على هذا على الإطلاق. ومع ذلك ، سوف تخفي الأطر الجديدة قريبا الفرق الخارجي عن الباحثين.
الايجابيات:- تنفيذ شبكة أسرع محتمل.
- انخفاض كبير في استهلاك الطاقة مقارنة بوحدة المعالجة المركزية والجرافيك (وهذا مهم بشكل خاص للحلول النقالة).
سلبيات:- معظمهم يساعدون في تسريع التنفيذ ؛ التدريب عليهم ، على عكس GPU ، أقل ملاءمة بشكل ملحوظ.
- برمجة أكثر تعقيدًا مقارنة بالخيارات السابقة.
- عدد أقل من المتخصصين بشكل ملحوظ.
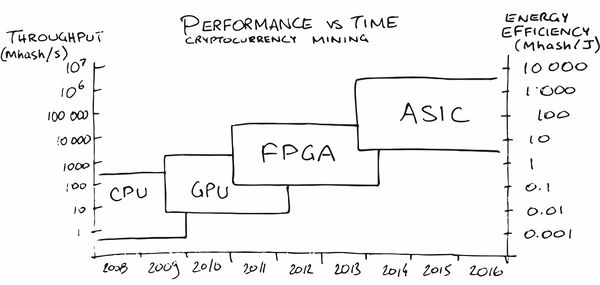
ASIC

التالي هو
ASIC ، وهو اختصار للدوائر المتكاملة الخاصة بالتطبيقات ، أي الدوائر المتكاملة لمهمتنا. على سبيل المثال ، تحقيق شبكة عصبية وضعت في الحديد. ومع ذلك ، يمكن لمعظم العقد الحوسبة العمل بالتوازي. في الواقع ، لا يمكن أن يمنعنا من استخدام جميع وحدات ALU التي تعمل بشكل مستمر إلا تبعيات البيانات والحوسبة غير المتكافئة على مستويات مختلفة من الشبكة.
ربما جعل تعدين العملة المشفرة أكبر إعلان ASIC بين عامة الناس في السنوات الأخيرة. في البداية ، كان التعدين على وحدة المعالجة المركزية مربحًا جدًا ، في وقت لاحق اضطررت إلى شراء وحدة معالجة الرسومات (GPU) ، ثم FPGA ، ثم أسيك المتخصصة ، نظرًا لأن الأشخاص (القراءة - السوق) نضجوا للطلبات التي أصبح إنتاجهم فيها مربحًا.
في منطقتنا ، ظهرت
الخدمات بالفعل (بشكل طبيعي!)
التي تساعد على وضع شبكة عصبية على الحديد مع الخصائص الضرورية لاستهلاك الطاقة و FPS والسعر. بطريقة سحرية ، توافق!
لكن! نحن نفقد التخصيص الشبكة. وبالطبع ، يفكر الناس أيضًا في الأمر. على سبيل المثال ، يوجد هنا مقال يقول: "
هل يمكن للهندسة القابلة
لإعادة التشكيل أن تغلب على ASIC كمسرع CNN؟ " ("هل يمكن للهندسة القابلة للتكوين أن تفوز على ASIC مثل مسرع CNN؟"). هناك ما يكفي من العمل بشأن هذا الموضوع ، لأن السؤال ليس خاملاً. العيب الرئيسي لـ ASIC هو أنه بعد دفعنا الشبكة إلى الأجهزة ، يصبح من الصعب علينا تغييرها. إنها مفيدة للغاية للحالات التي نحتاج فيها بالفعل إلى شبكة تعمل بشكل جيد مع ملايين الرقائق ذات استهلاك الطاقة المنخفض والأداء العالي. وهذا الوضع يتطور تدريجيا في سوق السيارات الطيار الآلي ، على سبيل المثال. أو في كاميرات المراقبة. أو في غرف المكانس الكهربائية الروبوتية. أو في غرف الثلاجة المنزلية. أو في غرفة صانع القهوة.
أو في غرفة الحديد. حسنًا ، أنت تفهم الفكرة
باختصار !
من المهم أن تكون الرقائق رخيصة في الإنتاج الضخم ، وتعمل بسرعة وتستهلك الحد الأدنى من الطاقة.
الايجابيات:- أقل تكلفة رقاقة مقارنة بجميع الحلول السابقة.
- أقل استهلاك للطاقة لكل وحدة من العمليات.
- سرعة عالية جدا (بما في ذلك ، إذا لزم الأمر ، رقما قياسيا).
سلبيات:- قدرة محدودة للغاية لتحديث الشبكة والمنطق.
- أعلى تكلفة تطوير مقارنة بجميع الحلول السابقة.
- استخدام أسيك هو فعالة من حيث التكلفة أساسا ليعمل كبيرة.
TPU
تذكر أنه عند العمل مع الشبكات ، هناك مهمتان - التدريب والتنفيذ (الاستدلال). إذا كانت FPGA / ASICs تركز أساسًا على تسريع التنفيذ (بما في ذلك بعض الشبكات الثابتة) ، فإن TPU (وحدة معالجة Tensor أو معالجات tensor) إما تسريع التعلم القائم على الأجهزة أو تسريع عالمي نسبيًا لشبكة تعسفية. الاسم جميل ، توافق ، على الرغم من أنه في الحقيقة ، لا يزال يتم استخدام المرتبة الثانية مع وحدة الضرب المختلط (MXU) المتصلة بذاكرة النطاق الترددي العالي (HBM). في ما يلي الرسم البياني للعمارة من TPU Google الإصدار الثاني والثالث:
TPU جوجل
بشكل عام ، أصدرت Google إعلانًا عن اسم TPU ، لتكشف عن التطورات الداخلية في عام 2017:
بدأوا العمل التمهيدي على المعالجات المتخصصة للشبكات العصبية بعباراتهم في عام 2006 ، وأنشأوا في عام 2013 مشروعًا بتمويل جيد ، وفي عام 2015 بدأوا العمل مع الرقائق الأولى التي ساعدت كثيرًا مع الشبكات العصبية لخدمة السحابية من Google Translate والمزيد. وهذا كان ، نؤكد ، تسريع الشبكة. هناك ميزة مهمة لمراكز البيانات تتمثل في طلبيتي كفاءة استخدام الطاقة أعلى من حيث الحجم مقارنةً بوحدات المعالجة المركزية (الرسم البياني لـ TPU v1):
أيضًا ، كقاعدة عامة ، مقارنةً بـ GPU ، يكون
أداء الشبكة أفضل من 10 إلى 30 مرة للأفضل:
الفرق هو حتى 10 مرات كبيرة. من الواضح أن الفرق مع GPU في 20-30 مرة يحدد تطور هذا الاتجاه.
ولحسن الحظ ، فإن Google ليست وحدها.
TPU هواوي
اليوم ، بدأت شركة Huawei التي طالت معاناتها في تطوير TPU منذ عدة سنوات تحت اسم Huawei Ascend ، وفي نسختين في آن واحد - لمراكز البيانات (مثل Google) وللأجهزة المحمولة (التي بدأت Google أيضًا القيام بها مؤخرًا). إذا كنت تعتقد أن مواد Huawei ، فقد تفوقت على Google TPU v3 الجديد بـ FP16 2.5 مرة و NVIDIA V100 مرتين:

كالعادة ، سؤال جيد: كيف ستتصرف هذه الشريحة في مهام حقيقية. على الرسم البياني ، كما ترون ، ذروة الأداء. بالإضافة إلى ذلك ، يعد Google TPU v3 جيدًا بعدة طرق لأنه يمكن أن يعمل بفعالية في مجموعات من 1024 معالج. أعلنت Huawei أيضًا عن مجموعات خوادم لـ Ascend 910 ، لكن لا توجد تفاصيل. بشكل عام ، أظهر مهندسو Huawei أنفسهم على درجة عالية من الكفاءة على مدار السنوات العشر الماضية ، وهناك كل فرصة لاستخدام أداء قمة أعلى بمقدار 2.8 مرة مقارنةً بـ Google TPU v3 ، إلى جانب أحدث تكنولوجيا عملية تبلغ 7 نانومتر ، في هذه الحالة.
يعد ناقل البيانات والذاكرة حاسمين بالنسبة للأداء ، وتوضح الشريحة أنه تم إيلاء اهتمام كبير لهذه المكونات (بما في ذلك سرعة الاتصال بالذاكرة بشكل أسرع بكثير من وحدة معالجة الرسومات):
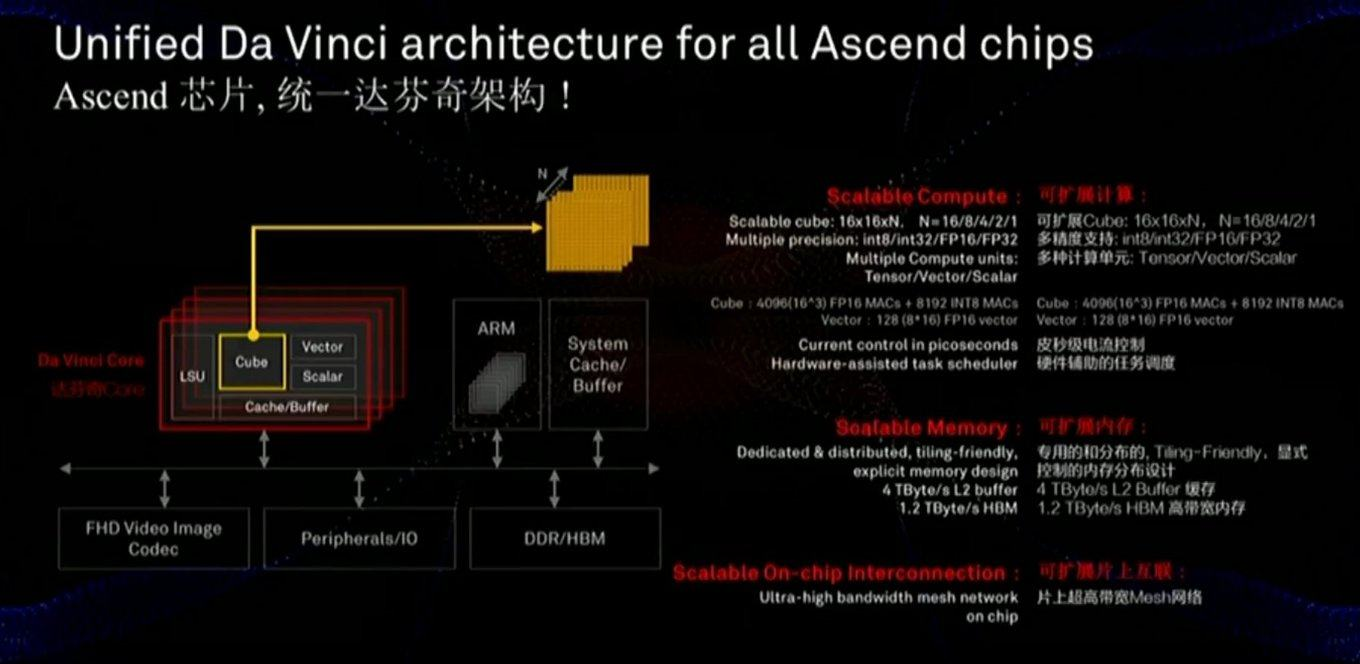 تستخدم الرقاقة أيضًا مقاربة مختلفة قليلاً - ليست مقاييس MXU 128x128 ثنائية الأبعاد ، ولكن الحسابات في مكعب ثلاثي الأبعاد بحجم أصغر 16x16xN ، حيث N = {16.8،4،2،1}. لذلك ، فإن السؤال الأساسي هو مدى تكمن في التسارع الحقيقي لشبكات محددة (على سبيل المثال ، الحسابات في المكعب مناسبة للصور). أيضًا ، تظهر دراسة متأنية للشريحة أنه ، على عكس Google ، تدمج الرقاقة على الفور العمل مع فيديو FullHD المضغوط. للمؤلف ، وهذا يبدو مشجعا للغاية !كما ذكر أعلاه ، في نفس السطر ، يتم تطوير معالجات للأجهزة المحمولة التي تعد كفاءة استخدام الطاقة فيها أمرًا بالغ الأهمية ، والتي سيتم تشغيل الشبكة عليها بشكل رئيسي (أي بشكل منفصل - معالجات للتعلم السحابي ومنفصل - للتنفيذ):
تستخدم الرقاقة أيضًا مقاربة مختلفة قليلاً - ليست مقاييس MXU 128x128 ثنائية الأبعاد ، ولكن الحسابات في مكعب ثلاثي الأبعاد بحجم أصغر 16x16xN ، حيث N = {16.8،4،2،1}. لذلك ، فإن السؤال الأساسي هو مدى تكمن في التسارع الحقيقي لشبكات محددة (على سبيل المثال ، الحسابات في المكعب مناسبة للصور). أيضًا ، تظهر دراسة متأنية للشريحة أنه ، على عكس Google ، تدمج الرقاقة على الفور العمل مع فيديو FullHD المضغوط. للمؤلف ، وهذا يبدو مشجعا للغاية !كما ذكر أعلاه ، في نفس السطر ، يتم تطوير معالجات للأجهزة المحمولة التي تعد كفاءة استخدام الطاقة فيها أمرًا بالغ الأهمية ، والتي سيتم تشغيل الشبكة عليها بشكل رئيسي (أي بشكل منفصل - معالجات للتعلم السحابي ومنفصل - للتنفيذ): ومع هذه المعلمة ، يبدو كل شيء جيدًا مقارنة بـ NVIDIA على الأقل (لاحظ أنهم لم يحققوا مقارنة مع Google ، ومع ذلك ، فإن Google لا تمنح أجهزة TPU السحابية أيديها). وستتنافس رقائق الهواتف المحمولة الخاصة بهم مع معالجات من Apple و Google وشركات أخرى ، لكن من السابق لأوانه تقييمها هنا.من الواضح أن رقائق Nano و Tiny و Lite الجديدة يجب أن تكون أفضل. يصبح من الواضح
ومع هذه المعلمة ، يبدو كل شيء جيدًا مقارنة بـ NVIDIA على الأقل (لاحظ أنهم لم يحققوا مقارنة مع Google ، ومع ذلك ، فإن Google لا تمنح أجهزة TPU السحابية أيديها). وستتنافس رقائق الهواتف المحمولة الخاصة بهم مع معالجات من Apple و Google وشركات أخرى ، لكن من السابق لأوانه تقييمها هنا.من الواضح أن رقائق Nano و Tiny و Lite الجديدة يجب أن تكون أفضل. يصبح من الواضح لماذا كان ترامب مرعوبًا بسبب قيام العديد من الشركات المصنعة بدراسة بعناية لنجاحات Huawei (التي تفوقت على جميع شركات الحديد الأمريكية في الإيرادات ، بما في ذلك Intel في 2018).الشبكات العميقة التناظرية
— , .
. , , , - (, — — 90-)? : , ? :
مع هذا النهج ، يتم حساب DNN (الشبكة العصبية العميقة) بسرعة وكفاءة في استخدام الطاقة. ولكن هناك مشكلة - وهي DAC / ADCs (DAC / ADC) - محولات من رقمية إلى تمثيلية والعكس صحيح ، مما يقلل من كفاءة الطاقة ودقة العملية.ومع ذلك ، في عام 2017 ، اقترحت IBM Research CMOS تمثيلية لوحدات المعالجة RPU ( وحدات المعالجة المقاومة ) ، والتي تسمح لك بتخزين البيانات المعالجة أيضًا في شكل تمثيلي وتزيد بشكل كبير من الكفاءة الكلية للمنهج:, — RPU, , . IBM , 2- ( ), 100 (!) GPU:
, :
ومع ذلك ، فإن الاتجاه المحتمل للحوسبة التناظرية تبدو مثيرة للاهتمام
للغاية .
الشيء الوحيد الذي يربك هو أنه IBM ،
الذي قدم بالفعل عشرات براءات الاختراع حول هذا الموضوع . وفقًا للتجربة ، نظرًا لخصائص ثقافة الشركات ، فإنهم يتعاونون بشكل ضعيف نسبيًا مع الشركات الأخرى ، وامتلاكهم بعض التكنولوجيا ، من المرجح أن يبطئوا تطورها من بين أمور أخرى بدلاً من مشاركتها بفعالية. على سبيل المثال ، رفضت شركة IBM في وقت واحد ترخيص الضغط الحسابي لـ JPEG إلى لجنة
ISO ، على الرغم من أن مشروع المعيار كان خيارًا مع الضغط الحسابي. ونتيجة لذلك ، ظهرت الحياة السياسية في فرنسا مع ضغط Huffman ولسعة 10-15 ٪ أسوأ مما يمكن. كان الوضع نفسه مع معايير ضغط الفيديو. وتحولت الصناعة بشكل كبير إلى ضغط حسابي في برامج الترميز فقط عندما تنتهي صلاحية 5 براءات اختراع لـ IBM بعد 12 عامًا ... دعنا نأمل أن يكون IBM أكثر ميلًا إلى التعاون هذه المرة ، وبالتالي ،
نتمنى أقصى قدر من النجاح في هذا المجال لأي شخص غير مرتبط بـ IBM ، يستفيد
مثل هؤلاء الأشخاص والشركات كثيرًا .
إذا نجحت ،
ستكون ثورة في استخدام الشبكات العصبية وثورة في العديد من مجالات علوم الكمبيوتر.رسائل أخرى متنوعة
بشكل عام ، أصبح موضوع تسريع الشبكات العصبية عصريًا ، وتشارك فيه جميع الشركات الكبرى وعشرات الشركات الناشئة ،
وقد اجتذبت 5 منها على الأقل أكثر من 100 مليون دولار من الاستثمارات بحلول بداية عام 2018. في المجموع ، في عام 2017 ، تم استثمار 1.5 مليار دولار في الشركات الناشئة المتعلقة بتطوير الرقائق. على الرغم من حقيقة أن المستثمرين لم يلاحظوا صناع الرقائق لمدة 15 عامًا جيدًا (لأنه لم يكن هناك شيء يصطادونه على خلفية الشركات العملاقة). بشكل عام - الآن هناك فرصة حقيقية لثورة حديدية صغيرة. علاوة على ذلك ، من الصعب للغاية التنبؤ بالهيكل الذي سيفوز به ، وقد نضجت الحاجة إلى الثورة ، وإمكانيات زيادة الإنتاجية كبيرة. نضج الموقف الثوري الكلاسيكي: لم يعد
مور قادرًا على ذلك ، ولم يعد
دين جاهزًا بعد.
حسنًا ، نظرًا لأن قانون السوق الأكثر أهمية - كن مختلفًا ، فهناك الكثير من الرسائل الجديدة ، على سبيل المثال:
- وحدة المعالجة العصبية ( NPU ) - المعالج العصبي ، وأحيانًا بشكل جميل - شريحة عصبية الشكل - بشكل عام ، الاسم العام لمسرع الشبكات العصبية ، والتي تسمى رقائق Samsung و Huawei والمزيد في القائمة ...
فيما يلي في هذا القسم ، سيتم تقديم شرائح عروض الشركات بشكل أساسي كأمثلة على الأسماء الذاتية للتكنولوجيا
من الواضح أن المقارنة المباشرة تمثل مشكلة ، ولكن فيما يلي بعض البيانات المثيرة للاهتمام التي تقارن الرقائق بالمعالجات العصبية من Apple و Huawei ، والتي تنتجها شركة TSMC المذكورة في البداية. يمكن ملاحظة أن المنافسة صعبة ، حيث يظهر الجيل الجديد زيادة في الإنتاجية تبلغ من 2 إلى 8 مرات وتعقيد العمليات التكنولوجية:
- معالج الشبكة العصبية (NNP) - معالج الشبكة العصبية.
هذا هو اسم عائلة شرائحها ، على سبيل المثال Intel (كانت في الأصل شركة Nervana Systems ، التي اشترتها Intel في عام 2016 مقابل 400 مليون دولار). ومع ذلك ، في المقالات والكتب ، فإن اسم NNP شائع جدًا أيضًا.
- وحدة معالجة الذكاء (IPU) - معالج ذكي - اسم الرقائق التي يروج لها Graphcore (بالمناسبة ، التي تلقت بالفعل استثمارات بقيمة 310 مليون دولار).
إنها تنتج بطاقات خاصة لأجهزة الكمبيوتر ، ولكنها موجهة نحو تدريب الشبكات العصبية ، مع أداء تدريب RNN أعلى بمعدل 180 إلى 240 مرة من أداء NVIDIA P100.
- وحدة معالجة تدفق البيانات (DPU) - معالج معالجة البيانات - يتم الترويج لها بواسطة WAVE Computing ، التي تلقت بالفعل استثمارًا بقيمة 203 ملايين دولار. ينتج عن نفس المعجلات مثل Graphcore:
نظرًا لأنهم تلقوا أقل من 100 مليون ، فإنهم يعلنون أن التدريب أسرع بـ 25 مرة فقط من GPU (على الرغم من أنهم يعدون أنه سيكون 1000 مرة في وقت قريب). لنرى ...
- وحدة معالجة الرؤية ( VPU ) - معالج رؤية الكمبيوتر:
يستخدم المصطلح في منتجات العديد من الشركات ، على سبيل المثال ، Myriad X VPU من Movidius ( اشترتها أيضًا Intel في عام 2016).
- يقوم أحد المنافسين لـ IBM (والذي ، كما نذكر ، باستخدام مصطلح RPU ) - Mythic - بتحريك Analog DNN ، الذي يقوم أيضًا بتخزين الشبكة في الشريحة وتنفيذ سريع نسبيًا. حتى الآن ليس لديهم سوى وعود ، رغم أنها جادة :
وهذا يسرد فقط أكبر المناطق في التنمية التي تم استثمار مئات الملايين منها (وهذا مهم في تطوير الحديد).
بشكل عام ، كما نرى ، كل الزهور تتفتح بسرعة. تدريجيا ، سوف تستوعب الشركات مليارات الدولارات من الاستثمارات (عادة ما يستغرق الأمر من 1.5 إلى 3 سنوات لتصنيع الرقائق) ، وسوف يستقر الغبار ، وسيصبح القائد واضحًا ، وسوف يكتب الفائزون ، كالعادة ، قصة ، وسيصبح اسم التكنولوجيا الأكثر نجاحًا مقبولًا بشكل عام. لقد حدث هذا بالفعل أكثر من مرة ("IBM PC" ، "Smartphone" ، "Xerox" ، إلخ).
بضع كلمات عن المقارنة الصحيحة
كما ذكرنا أعلاه ، فإن المقارنة الصحيحة لأداء الشبكات العصبية ليست سهلة. هذا هو بالضبط السبب الذي يجعل Google تنشر رسمًا بيانيًا يجعل TPU v1 يجعله NVIDIA V100. تقوم NVIDIA ، التي ترى مثل هذا الخزي ، بنشر جدول حيث يفقد Google TPU v1 جهاز V100. (هكذا!) تنشر Google المخطط التالي ، حيث يخسر V100 في Google TPU v2 & v3. وأخيرًا ، يعتبر Huawei هو الجدول الزمني الذي يخسر فيه الجميع على Huawei Ascend ، لكن V100 أفضل من TPU v3. السيرك ، باختصار. ما هو المميز -
كل مخطط
له حقيقة
خاصة به !
الأسباب الجذرية للحالة واضحة:
- يمكنك قياس سرعة التعلم أو سرعة التنفيذ (أيهما أكثر ملاءمة).
- من الممكن قياس الشبكات العصبية المختلفة ، لأن سرعة تنفيذ / تدريب الشبكات العصبية المختلفة على أبنية محددة يمكن أن تختلف اختلافًا كبيرًا بسبب بنية الشبكة وكمية البيانات المطلوبة.
- ويمكنك قياس الأداء الأقصى للمسرع (ربما الأكثر تجريدًا من كل ما سبق).
كمحاولة لترتيب الأشياء في حديقة الحيوان هذه ،
ظهر اختبار
MLPerf ، الذي أصبح الآن الإصدار 0.5 متاحًا ، أي إنه بصدد تطوير منهجية مقارنة ، والتي من المقرر أن يتم طرحها في الإصدار الأول في
الربع الثالث من هذا العام :
نظرًا لأن المؤلفين هناك أحد المساهمين الرئيسيين في TensorFlow ، فهناك كل فرصة لاكتشاف أفضل طريقة للتدريب وربما استخدامها (لأن النسخة المحمولة من TF ستضم على الأرجح أيضًا في هذا الاختبار مع مرور الوقت).
في الآونة الأخيرة ،
منعت المنظمة الدولية
IEEE ، التي تنشر الجزء الثالث من الأدبيات الفنية العالمية في مجال الإلكترونيات الراديوية وأجهزة الكمبيوتر والهندسة الكهربائية ،
شركة Huawei من مواجهة طفل ، إلا أنها
ألغت الحظر قريبًا. لم تدخل Huawei في الترتيب
الحالي لـ MLPerf ، في حين أن Huawei TPU منافس جاد لبطاقات Google TPUs و NVIDIA (على سبيل المثال ، إلى جانب البطاقات السياسية ، هناك أسباب اقتصادية لتجاهل Huawei ، بصراحة). مع الاهتمام غير المقنع سوف نتابع تطور الأحداث!
كل شيء إلى الجنة! أقرب إلى الغيوم!
وبما أنه كان يتعلق بالتدريب ، يجدر بنا أن نقول بضع كلمات عن تفاصيله:
- مع رحيل البحث على نطاق واسع إلى الشبكات العصبية العميقة (مع عشرات ومئات الطبقات التي تمزق الجميع بالفعل) ، كان من الضروري طحن مئات ميغابايت من المعاملات ، الأمر الذي جعل على الفور جميع مخابئ المعالج للأجيال السابقة غير فعالة. في الوقت نفسه ، تناقش ImageNet الكلاسيكية وجود ارتباط صارم بين حجم الشبكة ودقتها (كلما كان الأفضل ، اليمين ، أكبر شبكة ، المحور الأفقي لوغاريتمي):
- تتبع عملية الحساب داخل الشبكة العصبية مخططًا ثابتًا ، أي حيث كل "المتفرعة" و "التحولات" (من حيث القرن الماضي) ستحدث في الغالبية العظمى من الحالات معروفة بدقة مقدما ، مما يترك تنفيذ المضاربة من التعليمات دون عمل ، مما سبق زيادة الإنتاجية بشكل كبير:
وهذا ما يجعل آليات التنبؤ الفائق التكدس المتراكم للعمليات المتفرعة وعمليات التقييم المسبق للعقود السابقة من تحسين المعالج غير فعالة (لسوء الحظ ، يسهم هذا الجزء من الرقاقة أيضًا في الاحتباس الحراري بدلاً من DNN على ذاكرة التخزين المؤقت لـ DNN).
- علاوة على ذلك ، يتم تدريب الشبكات العصبية بشكل ضعيف نسبياً أفقياً . أي لا يمكننا أخذ 1000 جهاز كمبيوتر قوي والحصول على تسريع التعلم 1000 مرة. وحتى في 100 لا يمكننا (على الأقل حتى يتم حل المشكلة النظرية المتمثلة في تدهور جودة التدريب على حجم كبير من الدفعة). بشكل عام ، يصعب علينا توزيع شيء ما على العديد من أجهزة الكمبيوتر ، لأنه بمجرد انخفاض سرعة الوصول إلى الذاكرة الموحدة التي تقع فيها الشبكة ، تنخفض سرعة تعلمها بشكل كارثي. لذلك ، إذا كان لدى الباحث الوصول إلى 1000 جهاز كمبيوتر قوي
مجانًا ، فسوف يأخذها بكل تأكيد قريبًا ، ولكن على الأرجح (إذا لم يكن هناك infiniband + RDMA) ، فستكون هناك العديد من الشبكات العصبية ذات معلمات فرط مختلفة. أي سيكون وقت التدريب الإجمالي أقل بعدة مرات فقط من جهاز كمبيوتر واحد. من الممكن اللعب بأحجام الدُفعة والتعليم الإضافي والتكنولوجيات العصرية الأخرى ، لكن الاستنتاج الرئيسي هو نعم ، مع زيادة عدد أجهزة الكمبيوتر ، ستزداد كفاءة العمل واحتمال تحقيق النتيجة ، ولكن ليس بشكل خطي. واليوم ، يعد وقت باحث علوم البيانات مكلفًا وفي كثير من الأحيان إذا كنت تستطيع إنفاق الكثير من السيارات (وإن كان ذلك غير معقول) ، ولكن الحصول على تسارع - يتم ذلك (انظر المثال مع 1 و 2 و 4 V100s باهظة الثمن في السحب أدناه).
بالضبط هذه النقاط تفسر لماذا اندفع الكثير من الناس نحو تطوير الحديد المتخصص للشبكات العصبية العميقة. ولماذا حصلوا على مليارات. هناك بالفعل ضوء مرئي في نهاية النفق وليس فقط Graphcore (والذي ، أذكر ، تسارع تدريب RNN 240 مرة).
على سبيل المثال ، فإن السادة من IBM Research
متفائلون بتطوير شرائح خاصة من شأنها أن تزيد من كفاءة العمليات الحسابية بترتيب كبير بعد 5 سنوات (وبعد 10 سنوات بمقدار طلبيين من حيث الحجم ، تصل إلى 1000 مرة مقارنة بمستوى 2016 على هذا المخطط ، على الرغم من ، في الكفاءة لكل واط ، ولكن الطاقة الأساسية ستزيد أيضا):
كل هذا يعني ظهور قطع من الحديد ، والتي سيكون التدريب فيها سريعًا نسبيًا ، ولكنه سيكون مكلفًا ، مما يؤدي بطبيعة الحال إلى فكرة مشاركة وقت استخدام قطعة الحديد الباهظة هذه بين الباحثين. وهذه الفكرة اليوم لا تقودنا بشكل طبيعي إلى الحوسبة السحابية. والانتقال من التعلم إلى الغيوم منذ فترة طويلة بنشاط.
لاحظ أنه الآن قد يختلف تدريب نفس النماذج في الوقت المناسب حسب حجم الخدمات السحابية المختلفة. تتصدر Amazon موقع الصدارة ، ويأتي Colab المجاني من Google في المرتبة الأخيرة. يرجى ملاحظة كيف تتغير نتيجة عدد V100 بين الزعماء - زيادة عدد البطاقات بمقدار 4 مرات (!) زيادة الإنتاجية بأقل من الثلث (!!!) من اللون الأزرق إلى اللون الأرجواني ، كما أن Google لديها عدد أقل:
يبدو أنه في السنوات المقبلة ، سينمو الفرق إلى حجمين. الرب! طبخ المال! سنقوم بإعادة الودائع بمليارات الاستثمارات إلى أنجح المستثمرين ...
باختصار
دعنا نحاول تلخيص النقاط الرئيسية في الجهاز اللوحي:
بضع كلمات عن تسريع البرنامج
في الإنصاف ، نذكر أن الموضوع الكبير اليوم هو تسريع برمجيات تنفيذ وتدريب الشبكات العصبية العميقة. يمكن تسريع التنفيذ بشكل كبير في المقام الأول بسبب ما يسمى بالكمي للشبكة. ربما يكون هذا ، أولاً ، نظرًا لأن نطاق الأوزان المستخدمة ليس كبيرًا جدًا وغالبًا ما يكون من الممكن تحجيم الأوزان من قيمة الفاصلة العائمة ذات 4 بايت إلى عدد صحيح واحد بايت (وتذكر نجاحات IBM ، أقوى). ثانياً ، الشبكة المدربة ككل مقاومة تمامًا للضوضاء الحسابية ودقة الانتقال إلى
int8 تنخفض قليلاً. في الوقت نفسه ، على الرغم من حقيقة أن عدد العمليات يمكن أن يزداد (بسبب القياس عند الحساب) ، فإن حقيقة أن حجم الشبكة يقل بمقدار 4 مرات ويمكن اعتبارها عمليات متجهة سريعة تزيد بشكل كبير من السرعة الكلية للتنفيذ. هذا مهم بشكل خاص للتطبيقات المحمولة ، لكنه يعمل في السحب أيضًا (مثال على التنفيذ المتسارع في غيوم الأمازون):
هناك طرق أخرى
لتسريع تنفيذ الخوارزميات والمزيد من الطرق
لتسريع عملية التعلم . ومع ذلك ، فهذه مواضيع كبيرة منفصلة وليس هذه المرة.
بدلا من الاستنتاج
في المحاضرات التي قدمها ، يقدم المستثمر والمؤلف
توني سيبا مثالاً رائعًا: في عام 2000 ، احتل الحاسوب العملاق رقم 1 بسعة 1 ترافلوبس مساحة 150 مترًا مربعًا ، بتكلفة 46 مليون دولار واستهلك 850 كيلوواط:
بعد 15 عامًا ، تتوافق وحدة معالجة الرسومات NVIDIA مع أداء يصل إلى 2.3 ترافلوبس (مرتين أكثر) في اليد ، بتكلفة 59 دولارًا (بزيادة تبلغ نحو مليون مرة) وتستهلك 15 واط (بزيادة 56 ألف مرة):
في آذار (مارس) من هذا العام ،
قدمت Google "TPU Pods" ، وهي في الواقع حواسيب عملاقة مبردة بالسوائل تعتمد على TPU v3 ، الميزة الرئيسية هي أنها يمكن أن تعمل معًا في أنظمة 1024 TPU. تبدو رائعة جدا:
لا يتم تقديم البيانات الدقيقة ، ولكن يقال إن النظام يشبه الحواسيب الفائقة الأولى في العالم. TPU Pod يمكن أن تزيد بشكل كبير من سرعة تعلم الشبكات العصبية. لزيادة سرعة التفاعل ، يتم توصيل TPUs بواسطة خطوط عالية السرعة في بنية حلقية:

يبدو أنه بعد 15 عامًا ، سيتمكّن هذا
المعالج العصبي القوي أيضًا من احتوائه في يدك ، مثل
معالج Skynet (
يجب عليك الاعتراف ، إنه شيء مشابه):
لقطة من الإصدار المخرج لفيلم "Terminator 2"بالنظر إلى المعدل الحالي لتحسين مسرعات أجهزة الشبكات العصبية العميقة والمثال أعلاه ، فإن هذا حقيقي تمامًا. هناك كل فرصة في بضع سنوات لالتقاط شريحة مع أداء مثل TPU اليوم.
بالمناسبة ، من المضحك أنه في الفيلم قام صانعو الرقائق (على ما يبدو ، تخيل أين قد تقود شبكة التدريب الذاتي) بإيقاف التدريب بشكل افتراضي. من الناحية المميزة ، لم يتمكن
T-800 نفسه من تمكين وضع التدريب وعمل في وضع الاستدلال (انظر
الإصدار التوجيهي الأطول). علاوة على ذلك ، كان
معالج الشبكة العصبية الخاص به متقدمًا وعند تشغيل إعادة التدريب ، يمكنه استخدام البيانات المتراكمة مسبقًا لتحديث النموذج. ليس سيئا لعام 1991.
بدأ هذا النص في شنتشن 13 مليون الساخنة. جلست في واحدة من سيارات الأجرة الكهربائية في المدينة البالغ عددها 27000 ونظرت إلى الشاشات الكريستالية الأربعة السائلة للسيارة باهتمام كبير. واحدة صغيرة - من بين الأجهزة الموجودة أمام السائق ، وجهازي - في المركز في لوحة القيادة والأخرى - شفافة - في مرآة الرؤية الخلفية ، بالإضافة إلى DVR ، وكاميرا مراقبة فيديو وجهاز Android على متن الطائرة (إذا حكمنا على الخط العلوي بمستوى الشحن والتواصل مع الشبكة). عرض بيانات برنامج التشغيل (من يشكو ، إذا كان ذلك) ، وتوقعات الطقس جديدة ، ويبدو أن هناك اتصال مع أسطول سيارات الأجرة. لم يكن السائق يعرف اللغة الإنجليزية ، ولم ينجح في سؤاله عن انطباعاته عن الآلة الكهربائية. لذلك ، ضغط على الدواسة بتكاسل ، وحرك السيارة قليلاً في ازدحام مروري. وشاهدت النافذة بنظرة مستقبلية باهتمام - كان الصينيون الذين يرتدون ستراتهم يقودون من العمل على الدراجات البخارية الكهربائية والأحواض ... وتساءلت كيف سيبدو كل شيء في غضون 15 عامًا ...
في الواقع ، بالفعل اليوم ، فإن مرآة الرؤية الخلفية ، التي تستخدم البيانات من كاميرا DVR
وتسريع أجهزة الشبكات العصبية ، قادرة تمامًا على التحكم في السيارة أثناء السير ووضع المسار. في فترة ما بعد الظهر ، على الأقل). بعد 15 عامًا ، من الواضح أن النظام لن يكون قادراً على قيادة السيارة فحسب ، بل سيسعده أيضًا أن يزودني بخصائص السيارات الكهربائية الصينية الجديدة. باللغة الروسية ، بشكل طبيعي (كخيار: الإنجليزية ، الصينية ... الألبانية ، أخيرًا). السائق هنا لا لزوم له ، سيئة التدريب ، وصلة.
الرب!
مثيرة للاهتمام للغاية 15 سنة ينتظرون منا!
ترقبوا!
سأعود! )))
 محدث:
محدث: التعليقات الأكثر إثارة للاهتمام:
حول الكمي وتسريع العمليات الحسابية على FPGA
التعليقاتMirn
في FPGA ، لا يتوفر حساب الدقة التعسفية فقط ، ولكن أيضًا جحيم القدرة الهامة على حفظ ومعالجة بيانات البتات التعسفية. على سبيل المثال ، هناك الكثير من المعاملات في MobileNetV2 W و B المزعجة ويمكنك قياسها دون فقدان الكثير من الدقة إلى 16 بت فقط ، أو سيتعين عليك إعادة التدريب. لكن إذا نظرت إلى الداخل وجمعت إحصائيات حول القنوات والطبقات ، يمكنك أن ترى أن جميع الـ 16 بت يتم استخدامها فقط عند إدخال معاملات 1000 واط الأولى ، أما الباقي فيتم بنقطة 8 إلى 11 بت ، منها فقط 2-3 بت وتوقيع مهمان للغاية ، وإحصائيات حول استخدام القنوات بحيث يكون هناك العديد من القنوات التي تكون فيها الأصفار عمومًا ، أو القيم الصغيرة ، أو القنوات التي تكون فيها جميع القيم تقريبًا 8-11 بت ، أي من الممكن تظليل العارض بالأظافر في وقت تجميع وعدم تخزين أي في الواقع ، من الممكن تخزين ذاكرة ROM ليس 16 بت ولكن قيم 4 بت ، ويمكنك حتى تخزين الشبكة العصبية بأكملها على FPGAs رخيصة دون فقدان الكثير من الدقة (أقل من 1 ٪) ، وكذلك معالجة بسرعات تصل إلى عشرات الآلاف من FPS مع الكمون بحيث نحصل على استجابة الشبكة العصبية على الفور كيف استقبال نهاية الإطار.
حول القياس الكمي: فكرتي هي أنه في عدد من مراحل الحوسبة W ، تتغير معاملات القناة رقم 0 فقط من +50 إلى -50 ، ثم يكون من المنطقي ضغط الشاهد على 7 ، وإذا كان من -123 إلى +124 على سبيل المثال ، ثم إلى 8 (بما في ذلك علامة ). FPGA , 7, 8 ROM . , .
(, , ), RTL , , . GCC AVX256 bitperfect ( FPGA ) FPS ( W B, ).
W fc , .. -100 +100 +10000 255 9 ( ).
! ل dephwise .
u-law ( ! ).
, , 6, , .
( ). — , FixedPoint dot product — Fractional part, — , , fc .
GPU, FPGA, ASIC
@BigPack
- TVM ( tvm.ai/about), ( Keras) . , — «»- (bare metal, ISA, FPGA .) edge computing. TVM HLS TVM FPGA. HLS FPGA «» , ( ) FPGA , GPU/TPU .
PS FPGA transparent hardware ( — open-source hardware), , ( «» ) . -. , FPGA —
FPGA, FPGA Microsoft
@Brak0delFPGA, 2019 , . — . / dsp-
Xilinx Achronix , DDR.
, , , FPGA ASIC-. FPGA : , ASIC , FPGA - . أي - . , ASIC-, , . , FPGA , ASIC.
, CPU, FPGA , , .
, GPU , FPGA , : , - , GPU , , , - ( , , , , FPGA , GPU ,
). , FPGA , , , ASIC-.
Microsoft (
Catapult v.2 ), FPGA-. , FPGA. () .
FPGA
Ristretto Deephi , , Deephi FPGA. , , , .
FPGA .
حول اقتصاديات التنمية FPGA مقابل أسيكتعليقMirn
, FPGA :
, ASIC.
:
FPGA
( ), ( , , IP 30-50 5 ).
, 10 ( ), 5*(N+1)
, , — 10 , , 120*N
( , — )
: (120+50+5)*N, 5 880
ASIC
( 2 )
(3-4 )
ASIC « » — : ,
, ( ), , — , .
: — , , .
( MiT — , , , )
, , 10 3-5 , ( — , , — , — ) , : .
! ! . NEC SONY (c , 10-15 , )
: FPGA ASIC.
شكر:
- . .. ,
- , , ,
- , , ,
- , , , , , , , , , , , , !