تذكر أن لعبة The Stack Stack تستند على قاعدة بيانات Elasticsearch غير العلائقية ، وواجهة Kibana على الويب وجامعي البيانات (أشهر Logstash ، و Beats ، و APM ، وغيرها). واحدة من الإضافات اللطيفة إلى مجموعة المنتجات المدرجة بالكامل هي تحليل البيانات باستخدام خوارزميات التعلم الآلي. في المقالة ، نفهم ماهية هذه الخوارزميات. نحن نطلب القط.
يعد "التعلم الآلي" ميزة مدفوعة في برنامج كومبيوتري مرن Stack وهو جزء من X-Pack. لبدء استخدامه ، يكفي تنشيط التنشيط لمدة 30 يومًا بعد التنشيط. بعد انتهاء الفترة التجريبية ، يمكنك طلب الدعم لتمديده أو شراء اشتراك. لا يتم احتساب تكلفة الاشتراك من كمية البيانات ، ولكن من عدد العقد المستخدمة. لا ، يؤثر حجم البيانات ، بالطبع ، على عدد العقد المطلوبة ، ولكن لا يزال هذا النهج في الترخيص أكثر إنسانية فيما يتعلق بميزانية الشركة. إذا لم تكن هناك حاجة للأداء العالي - يمكنك الحفظ.
تمت كتابة ML في Elastic Stack باللغة C ++ ويعمل خارج JVM ، والذي يقوم بتشغيل Elasticsearch نفسه. أي أن العملية (التي ، بالمناسبة ، الكشف التلقائي) تستهلك كل شيء لا يبتلع JVM. في الموقف التجريبي ، لا يعد هذا أمرًا بالغ الأهمية ، ولكن في بيئة إنتاجية من المهم إبراز عقد منفصل لمهام ML.
تنقسم خوارزميات التعلم الآلي إلى فئتين -
مع وبدون معلم . في Elastic Stack ، تكون الخوارزمية من فئة "no teacher". يسمح لك
هذا الرابط برؤية الجهاز الرياضي لخوارزميات التعلم الآلي.
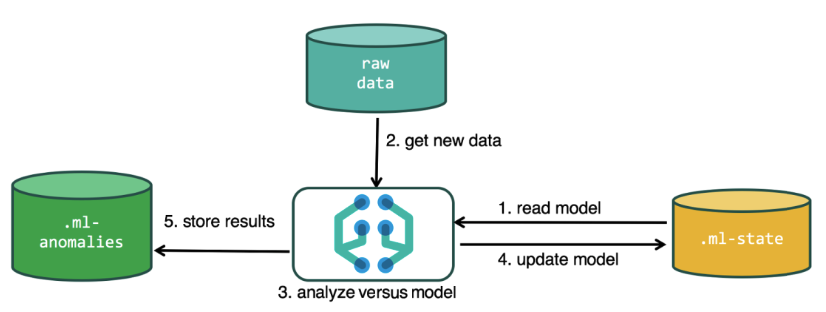
لإجراء التحليل ، تستخدم خوارزمية التعلم الآلي البيانات المخزنة في فهارس Elasticsearch. يمكنك إنشاء مهام للتحليل من واجهة Kibana وعبر واجهة برمجة التطبيقات. إذا قمت بذلك من خلال Kibana ، فإن بعض الأشياء ليست ضرورية لمعرفة. على سبيل المثال ، فهارس إضافية تستخدمها الخوارزمية في العملية.
فهارس إضافية تستخدم في عملية التحليل.ml-state - معلومات حول النماذج الإحصائية (إعدادات التحليل) ؛
.ml-anomalies- * - نتائج عمل خوارزميات ML ؛
.ml-notifications - إعدادات الإخطار بناءً على نتائج التحليل.
يتكون هيكل البيانات في قاعدة بيانات Elasticsearch من فهارس ووثائق مخزنة فيها. إذا ما قورنت بقاعدة بيانات علائقية ، فيمكن مقارنة الفهرس بمخطط قاعدة البيانات ، ووثيقة تحتوي على إدخال في الجدول. هذه المقارنة مشروطة ومقدمة لتبسيط فهم المواد الإضافية لأولئك الذين سمعوا فقط عن Elasticsearch.
تتوفر نفس الوظيفة من خلال واجهة برمجة التطبيقات كما هو الحال من خلال واجهة الويب ، لذلك من أجل توضيح وفهم المفاهيم ، سنبين كيفية التهيئة من خلال Kibana. يوجد قسم "التعلم الآلي" في القائمة على اليسار حيث يمكنك إنشاء وظيفة جديدة. في واجهة Kibana ، تبدو الصورة أدناه. سنقوم الآن بتحليل كل نوع من أنواع المهام وإظهار أنواع التحليل التي يمكن بناؤها هنا.
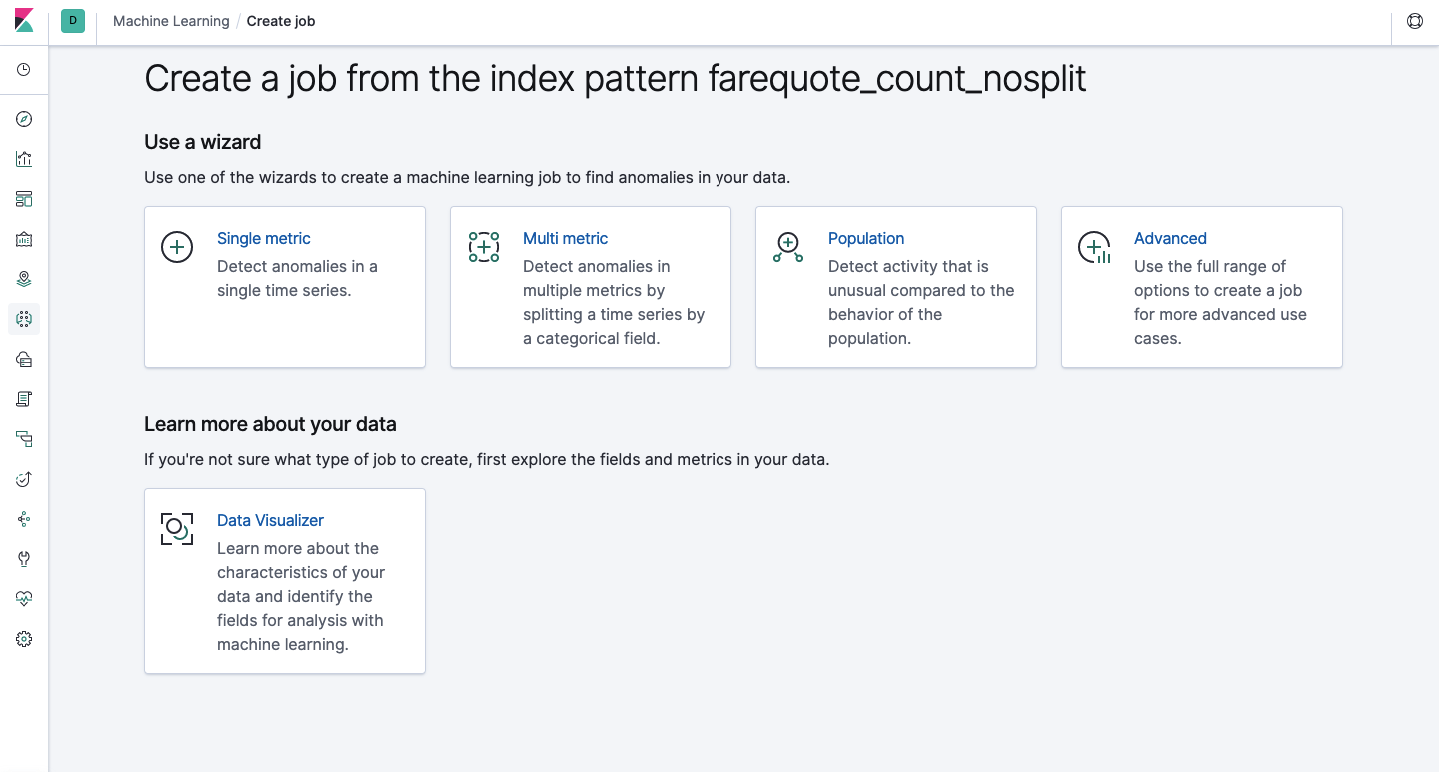
قياس واحد - تحليل لمقياس واحد ، متعدد المقاييس - تحليل لمقاييس أو أكثر. في كلتا الحالتين ، يتم تحليل كل قياس في بيئة معزولة ، أي لا تأخذ الخوارزمية في الاعتبار سلوك المقاييس التي تم تحليلها بالتوازي كما قد يبدو في حالة القياس المتعدد. لتنفيذ الحساب مع مراعاة الارتباط بين المقاييس المختلفة ، يمكنك تطبيق تحليل السكان. و Advanced هو صقل الخوارزميات مع خيارات إضافية لبعض المهام.
متري واحد
تحليل التغييرات في مقياس واحد هو أبسط شيء يمكنك القيام به هنا. بعد النقر فوق "إنشاء وظيفة" ، ستبحث الخوارزمية عن الحالات الشاذة.
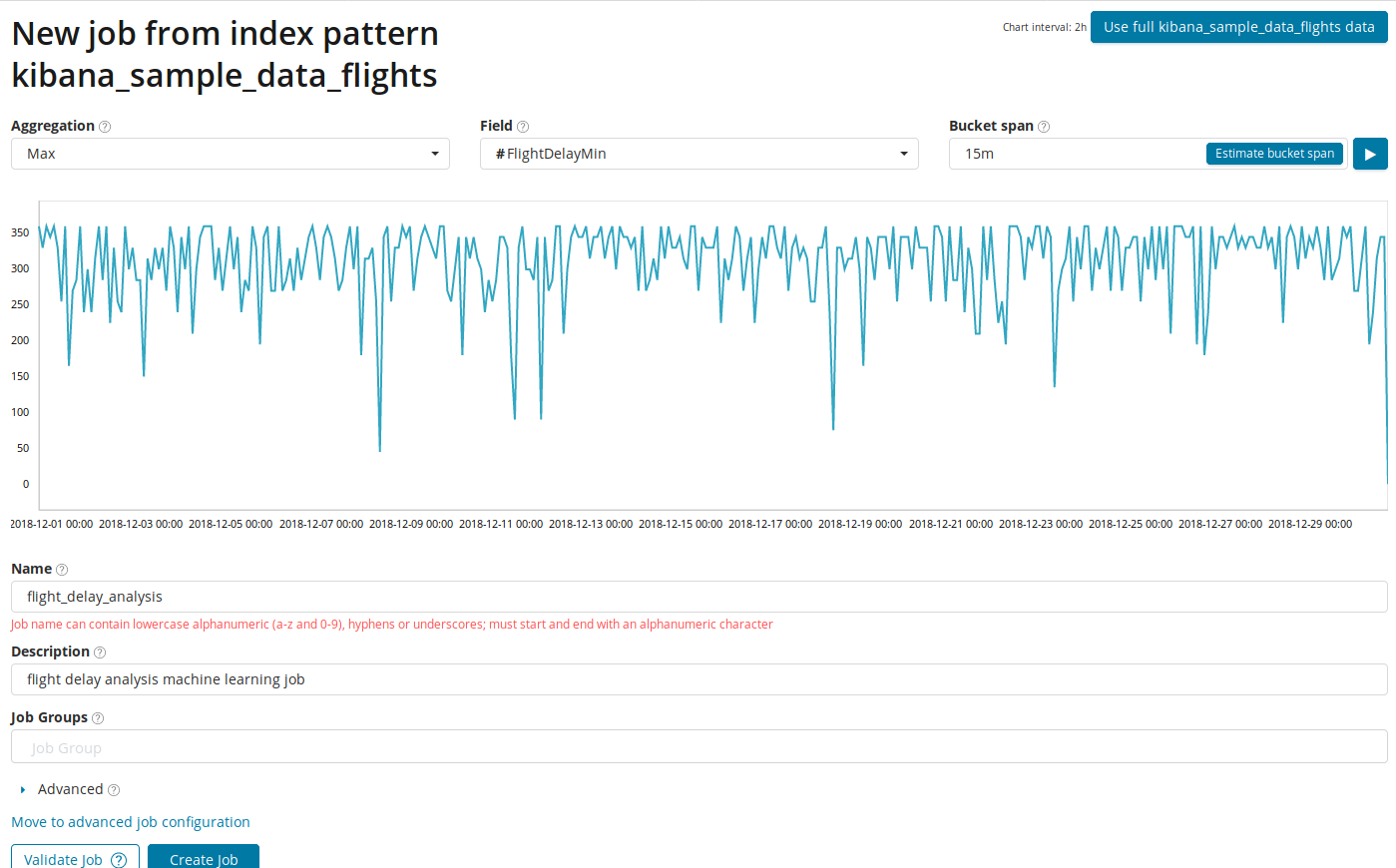
في حقل
التجميع ، يمكنك اختيار طريقة للبحث عن الحالات الشاذة. على سبيل المثال ، مع
Min تعتبر القيم الشاذة أقل من المعتاد. هناك
ماكس ، Hign يعني ، منخفض ، متوسط ، متميز وغيرهم. وصف جميع الوظائف ويمكن الاطلاع
هنا .
يشير حقل الحقل إلى الحقل الرقمي في المستند الذي سنحلل به.
في حقل
فترة الجرافة ، التفاصيل الدقيقة للفترات الزمنية التي سيتم إجراء التحليل عليها. يمكنك الوثوق في الأتمتة أو الاختيار يدويًا. تُظهر الصورة أدناه مثالًا للدقة المنخفضة جدًا - يمكنك تخطي الحالة الشاذة. باستخدام هذا الإعداد ، يمكنك تغيير حساسية الخوارزمية إلى الحالات الشاذة.

مدة البيانات التي تم جمعها هي الشيء الرئيسي الذي يؤثر على فعالية التحليل. في التحليل ، تحدد الخوارزمية الفواصل الزمنية المتكررة ، وتحسب فترة الثقة (خطوط الأساس) وتحدد الحالات الشاذة - الانحرافات غير النمطية عن السلوك المعتاد للقياس. فقط على سبيل المثال:
خطوط الأساس ذات فترة البيانات الصغيرة:
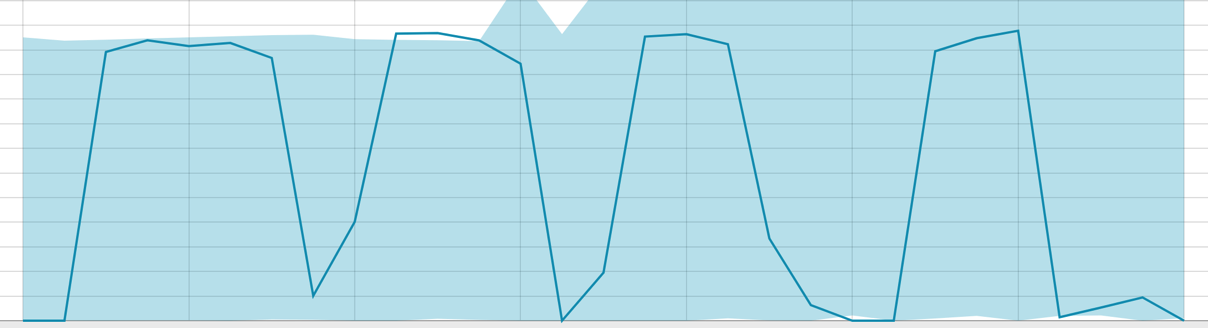
عندما يكون للخوارزمية شيء لتتعلمه ، فإن خط الأساس يبدو كما يلي:
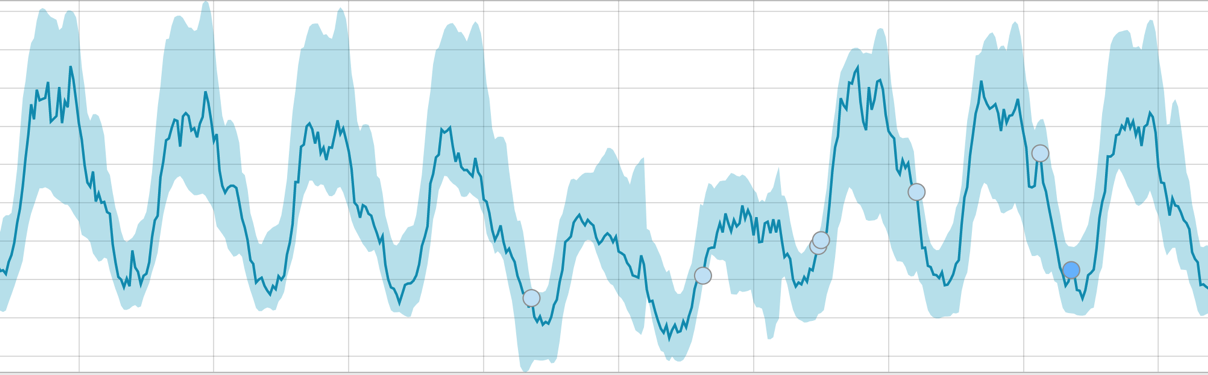
بعد بدء المهمة ، تحدد الخوارزمية الانحرافات الشاذة عن القاعدة وتصنفها على أساس احتمال حدوث الشذوذ (يشار إلى لون الملصق المقابل بين قوسين):
تحذير (سماوي): أقل من 25
قاصر (أصفر): 25-50
التخصص (البرتقالي): 50-75
الحرجة (الأحمر): 75-100
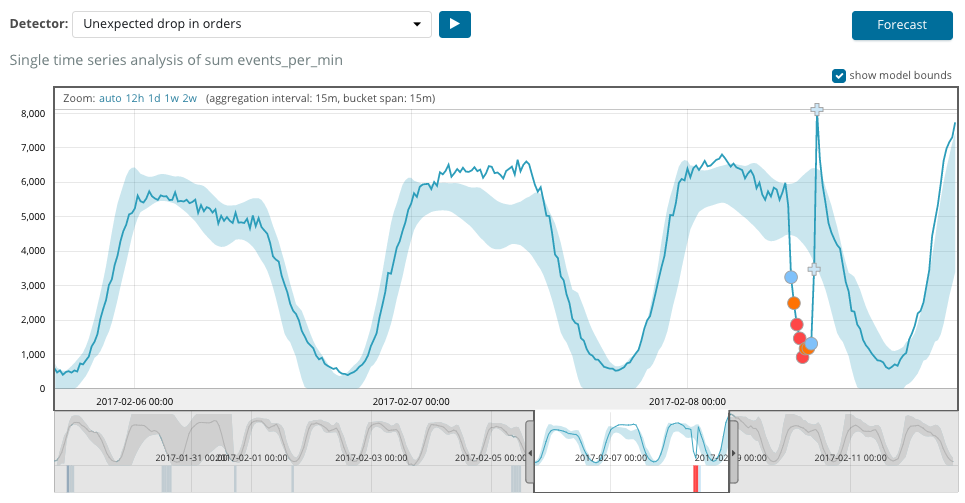
يوضح الرسم البياني أدناه مثالًا على الحالات الشاذة التي تم العثور عليها.
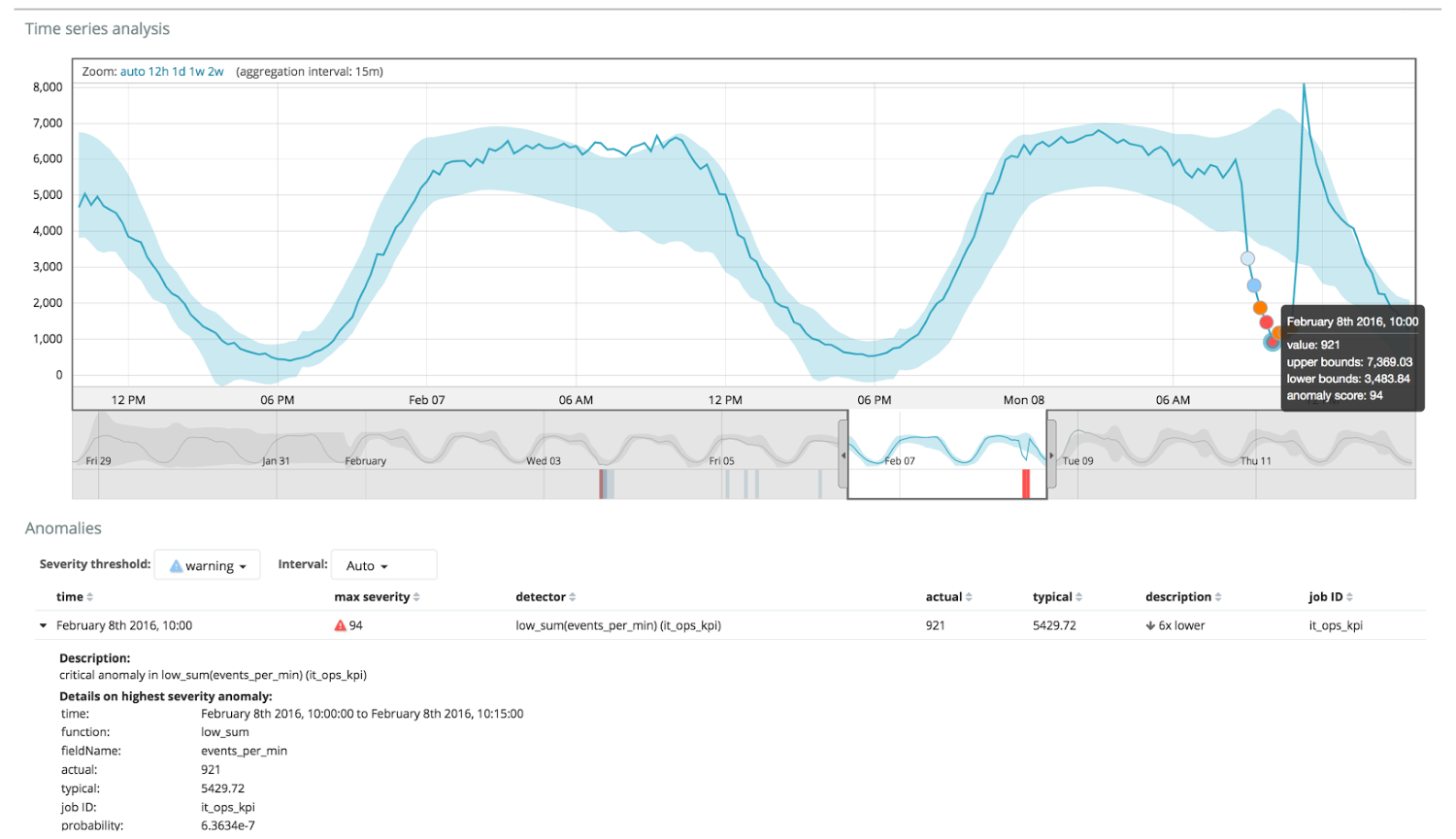
هنا يمكنك رؤية الرقم 94 ، مما يدل على احتمال حدوث حالة شاذة. من الواضح أنه نظرًا لأن القيمة قريبة من 100 ، فهذا يعني وجود حالة شاذة. يُظهر العمود الموجود أسفل الرسم البياني احتمالًا مهينًا قدره 0.000063634٪ من ظهور القيمة المترية هناك.
بالإضافة إلى البحث عن الحالات الشاذة في Kibana ، يمكنك تشغيل التنبؤ. يتم ذلك بطريقة أولية ومن نفس المنظر مع الحالات الشاذة - زر
التوقعات في الزاوية اليمنى العليا.

تستند التوقعات إلى 8 أسابيع بحد أقصى مقدمًا. حتى لو كنت تريد حقًا ، فلم يعد بإمكانك التصميم.
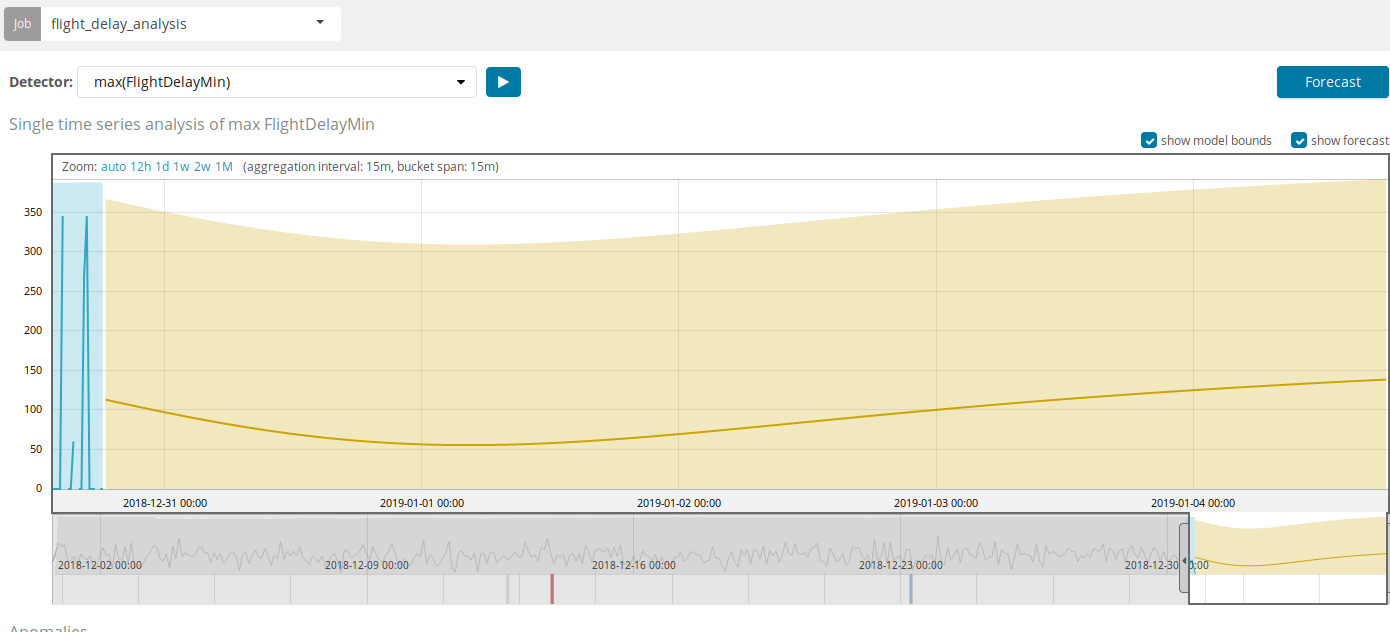
في بعض الحالات ، ستكون التنبؤات مفيدة للغاية ، على سبيل المثال ، عندما تتم مراقبة تحميل المستخدم للبنية التحتية.
متعدد متري
ننتقل إلى ميزة ML التالية في Elastic Stack - تحليل العديد من المقاييس في حزمة واحدة. ولكن هذا لا يعني أنه سيتم تحليل اعتماد أحد المقاييس على الآخر. هذا هو نفس المقياس الفردي الذي يحتوي على الكثير من المقاييس على شاشة واحدة فقط لسهولة مقارنة تأثيرات أحدهما على الآخر. سنتحدث عن تحليل اعتماد أحد المقاييس على الآخر في الجزء "السكان".
بعد النقر على المربع باستخدام Multi Metric ، ستظهر لك نافذة الإعدادات. سوف نتناولها بمزيد من التفصيل.
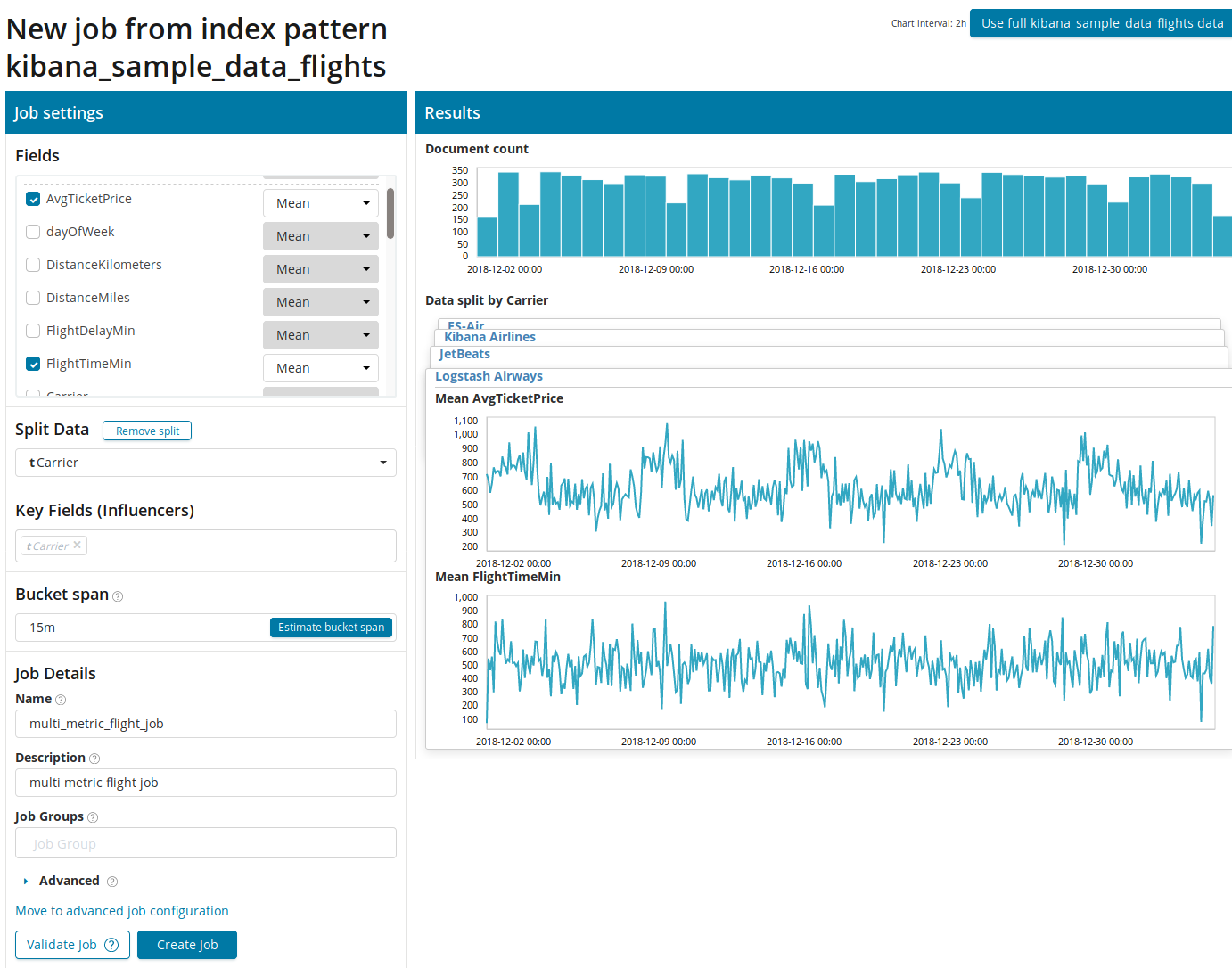
تحتاج أولاً إلى تحديد الحقول لتحليل وتجميع البيانات عليها. خيارات التجميع هنا هي نفسها لخيارات القياس الأحادي (
Max ، Hign Mean ، Low ، Mean ، Distinct ، وغيرها). علاوة على ذلك ، يتم تقسيم البيانات اختيارياً إلى أحد الحقول (الحقل
Split Data ). في المثال ، قمنا بهذا باستخدام حقل
OriginAirportID . لاحظ أن الرسم البياني للمقاييس على اليمين يتم تقديمه الآن كرسوم بيانية متعددة.
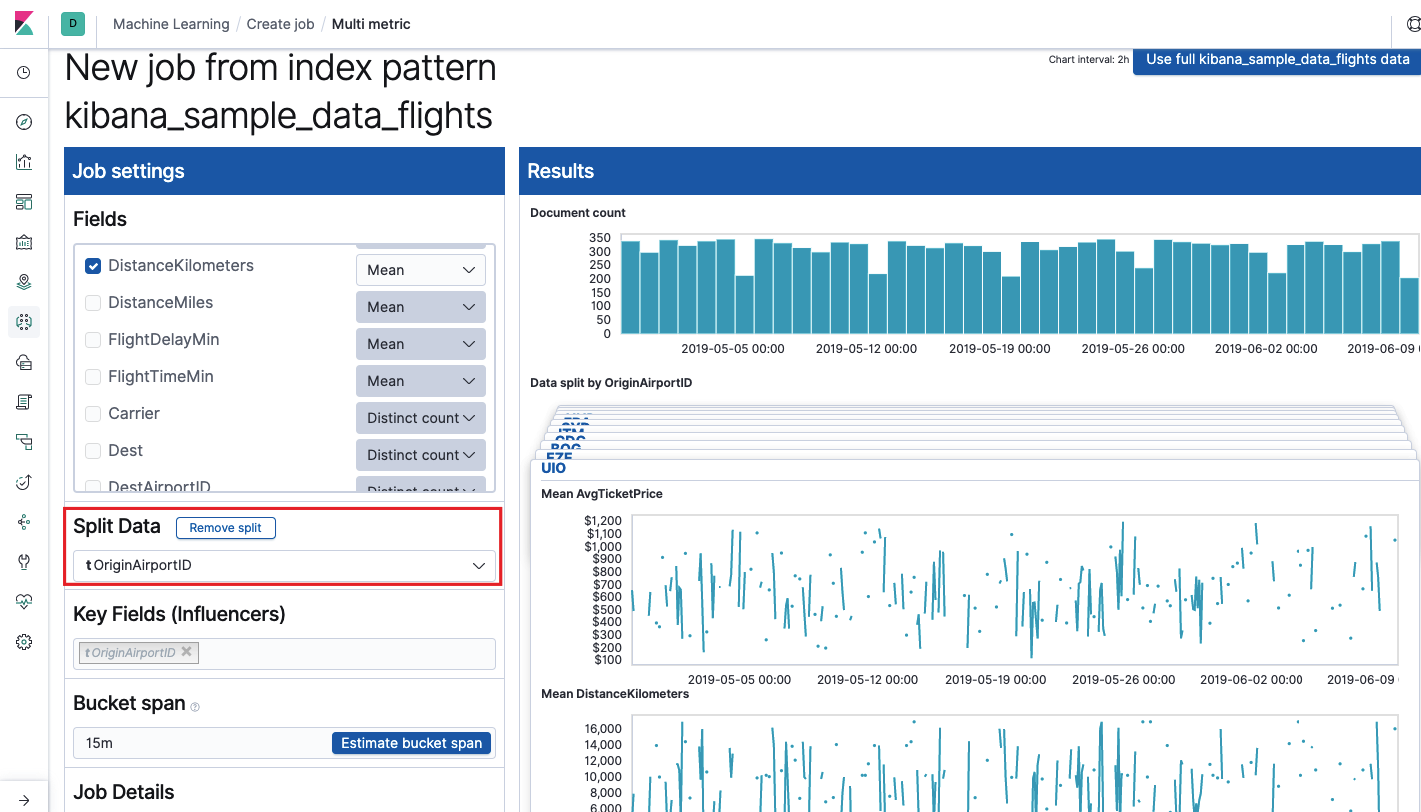 يؤثر
يؤثر حقل
الحقول الرئيسية (المؤثرون) بشكل مباشر على الحالات الشاذة الموجودة. بشكل افتراضي ، ستكون هناك دائمًا قيمة واحدة على الأقل ، ويمكنك إضافة قيم إضافية. ستأخذ الخوارزمية في الاعتبار تأثير هذه الحقول في التحليل وإظهار أكثر القيم "تأثيرًا".
بعد الإطلاق ، ستظهر الصورة التالية في واجهة Kibana.
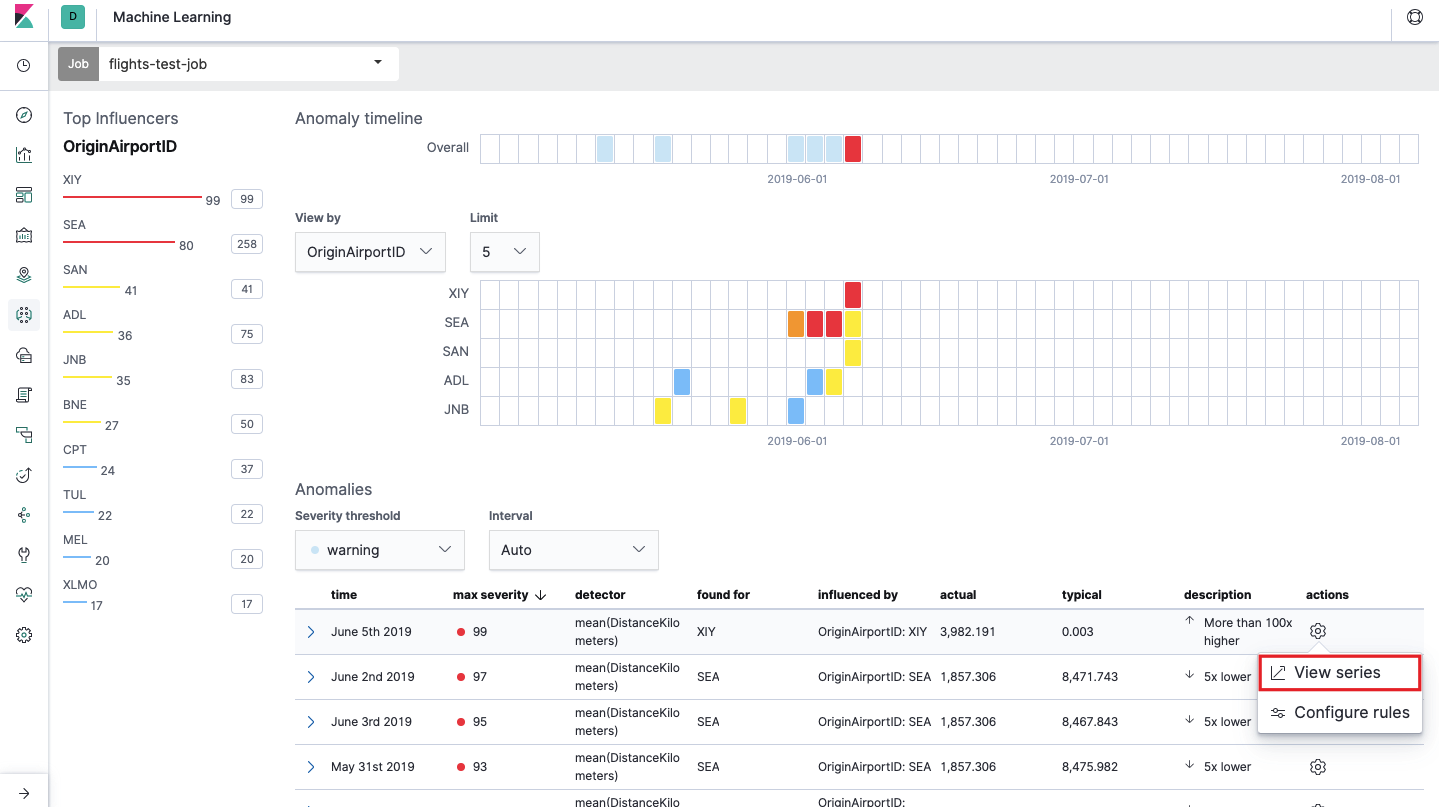
هذا هو ما يسمى خريطة الحرارة من الحالات الشاذة لكل قيمة من حقل
OriginAirportID التي حددناها في
تقسيم البيانات . كما هو الحال مع القياس الفردي ، يشير اللون إلى مستوى الانحراف غير الطبيعي. من المناسب إجراء تحليل مشابه ، على سبيل المثال ، على محطات العمل لتعقب تلك التي يوجد فيها الكثير من التراخيص المشبوهة ، إلخ. لقد كتبنا بالفعل
عن الأحداث المشبوهة في EventLog Windows ، والتي يمكن أيضًا جمعها وتحليلها هنا.
أسفل خريطة الحرارة توجد قائمة من الحالات الشاذة ، من كل واحدة يمكنك الذهاب إلى طريقة العرض "مقياس واحد" لإجراء تحليل تفصيلي.
سكان
للبحث عن الحالات الشاذة بين الارتباطات بين المقاييس المختلفة ، يحتوي تطبيق Flex Stack على تحليل سكاني متخصص. وبمساعدة ذلك ، يمكنك البحث عن القيم الشاذة في أداء الخادم مقارنة بالآخرين ، على سبيل المثال ، زيادة في عدد الطلبات إلى النظام المستهدف.
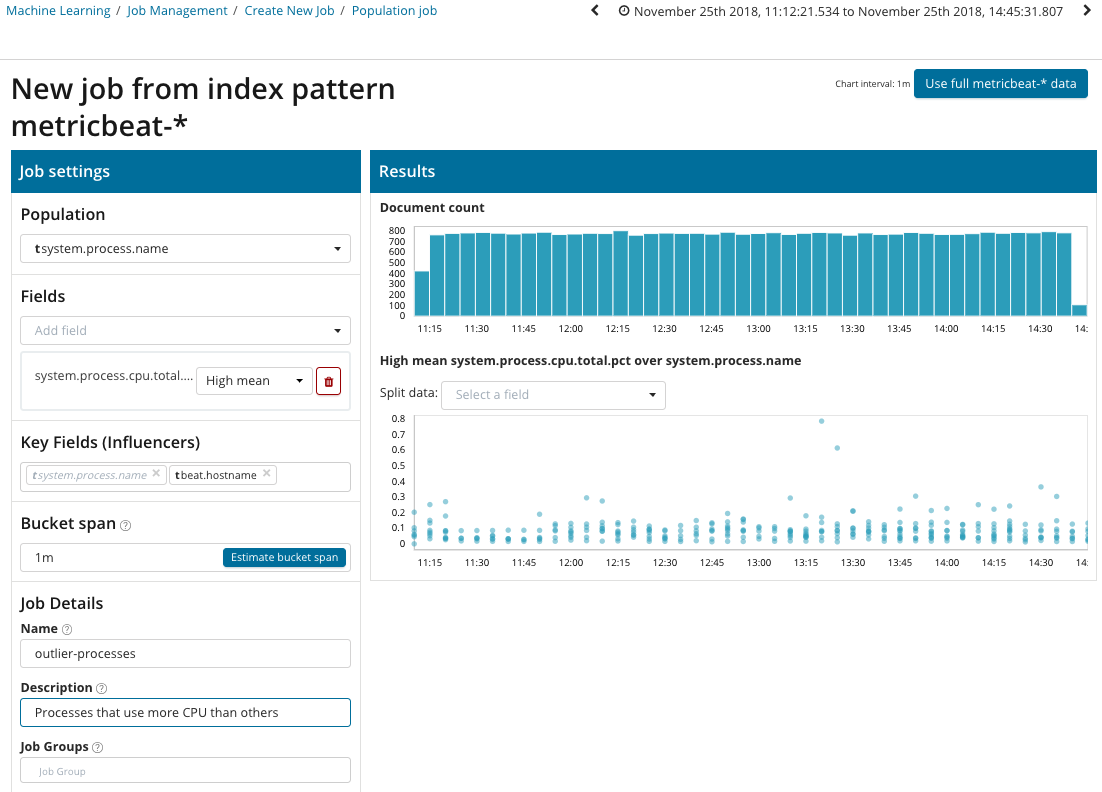
في هذا الرسم التوضيحي ، يشير الحقل "السكان" إلى القيمة التي تتعلق بها المقاييس التي تم تحليلها. هذا هو اسم العملية. نتيجة لذلك ، سنرى كيف أثر تحميل المعالج لكل عملية على بعضها البعض.
يرجى ملاحظة أن الرسم البياني للبيانات التي تم تحليلها يختلف عن الحالات ذات المقياس الفردي والمتري المتعدد. يتم ذلك في Kibana حسب التصميم لتحسين الإدراك لتوزيع قيم البيانات التي تم تحليلها.

يوضح الرسم البياني أن عملية
الإجهاد (بالمناسبة ، الناتجة عن أداة خاصة) على خادم
poipu تصرفت بشكل غير طبيعي ، مما أثر (أو اتضح أنه مؤثر) على حدوث هذه الحالة الشاذة.
متقدم
تحليلات دقيقة. مع التحليل المتقدم ، تظهر إعدادات إضافية في Kibana. بعد النقر فوق قائمة "إنشاء" في التجانب المتقدم ، تظهر نافذة مبوبة. تم تخطي علامة تبويب "
تفاصيل الوظيفة" عمداً ، ولا ترتبط الإعدادات الأساسية مباشرة بإعدادات التحليل.
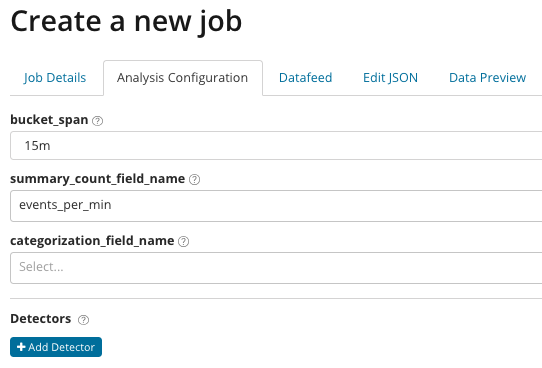
في
summary_count_field_name ، يمكنك اختيارياً اختيار اسم الحقل من المستندات التي تحتوي على قيم مجمعة. في هذا المثال ، عدد الأحداث في الدقيقة. يشير
categorization_field_name إلى اسم قيمة الحقل من المستند ، والذي يحتوي على نوع من قيمة المتغير. عن طريق قناع في هذا الحقل ، يمكنك تقسيم البيانات التي تم تحليلها إلى مجموعات فرعية. انتبه إلى زر
إضافة الكاشف في الرسم التوضيحي السابق. أدناه هو نتيجة النقر على هذا الزر.

فيما يلي كتلة إعدادات إضافية لإعداد كاشف الشذوذ لمهمة محددة. نحن نخطط لتحليل حالات استخدام محددة (خاصة للأمان) في المقالات التالية. على سبيل المثال ،
انظر إلى إحدى الحالات المفككة. يرتبط بالبحث عن قيم نادراً ما تظهر ويتم تنفيذه
بواسطة الدالة النادرة .
في حقل
الوظيفة ، يمكنك تحديد وظيفة محددة للبحث عن الحالات الشاذة. بالإضافة إلى
النادر ، هناك بعض الوظائف المثيرة للاهتمام -
time_of_day و time_of_week . وهي تحدد الحالات الشاذة في سلوك المقاييس طوال اليوم أو الأسبوع ، على التوالي. توجد بقية وظائف التحليل
في الوثائق .
يشير اسم الحقل إلى حقل المستند الذي سيتم تحليله. يمكن استخدام
By_field_name لفصل نتائج التحليل لكل قيمة فردية لحقل المستند المحدد هنا. إذا قمت بملء
over_field_name ، فستحصل على تحليل السكان ، الذي
درسناه أعلاه. إذا حددت قيمة في
partition_field_name ، فسيتم حساب الأسس الفردية لكل قيمة في هذا المستند (على سبيل المثال ، يمكن أن يكون اسم الخادم أو العملية على الخادم بمثابة القيمة). في
exclude_frequent ، يمكنك تحديد
الكل أو
لا شيء ، مما يعني استبعاد (أو التضمين) قيم حقل الوثيقة التي يتم مواجهتها بشكل متكرر.
في المقالة التي حاولنا تقديمها لأفضل فكرة موجزة حول إمكانيات التعلم الآلي في لعبة Flex Stack ، لا يزال هناك الكثير من التفاصيل وراء الكواليس. أخبرنا في التعليقات عن الحالات التي تمكنت من حلها بمساعدة التطبيق المرن والمكدس للمهام التي تستخدمها. للاتصال بنا ، يمكنك استخدام الرسائل الشخصية على Habré أو
نموذج الملاحظات على الموقع .