
محركات البحث لا تملك الكثير من المنطق ، هذه حقيقة. لكنهم يحاولون. ويحاول أخصائيو محركات البحث تحسين ذلك - فهم يحاولون تحقيق أقصى درجة من الأهمية للصفحات ، استنادًا إلى التخمين والتجريب.
غوغل سعيدة مؤخرا مع عامل الترتيب الجديد - المطابقة العصبية. نقرأ أن الخبراء يكتبون عن ذلك ، وجمعوا بعض الحيل التي ستساعدك على كتابة المزيد من النصوص ذات الصلة للطلبات.
وبالمناسبة ، NM ليس LSI بالنسبة لك ، إنه أكثر تعقيدًا بقليل.
في سبتمبر 2018 ، قام داني سوليفان بتغريد أنه خلال الأشهر القليلة الماضية ، استخدمت Google طريقة Neural Matching AI لربط الكلمات بالمفاهيم بشكل أفضل. أثرت هذه الخوارزمية على نتائج 30 ٪ من الطلبات في جميع أنحاء العالم.

لم نكن مستعجلين للكتابة عن الخوارزمية الجديدة ، كنا ننتظر الحصول على توضيحات من Google والبحث في هذا المجال. لكن الأمور ما زالت قائمة - يعرض معظم المعلقين لقطات الشاشة نفسها ويتحدثون عن الانتقال من البحث بالكلمات إلى البحث عن قصد. وهي تشير أيضًا إلى نموذج مطابقة الصلة العميقة (DRMM) .
دعونا نحاول معرفة أي نوع من الحيوانات هذه المطابقة العصبية وكيفية تكييف المحتوى على الموقع لذلك.
أمثلة على المطابقة العصبية
داني سوليفان يحدد ما هي المطابقة العصبية. أعطى مثالاً على إصدار الاستعلام "لماذا يبدو التلفزيون الخاص بي غريبًا". يقوم المستخدم بإدخال مثل هذا الاستعلام عندما لا يعرف بعد تأثير أوبرا الصابون. لكن Google ، بفضل الخوارزمية الجديدة ، تعرف بالضبط ما تحتاجه:

باللغة الروسية ، قصة مماثلة:

مثال آخر لقد قابلت حشرة "جميلة" في الشقة وليس لديك أي فكرة عن اسمها:

نذهب إلى Google ، وأدخل مجموعة من الميزات ، وفي الموضع الأول نحصل على الإجابة ذات الصلة:

يرجع تطبيق المطابقة العصبية إلى حقيقة أن المستخدمين لا يعرفون دائمًا ما يبحثون عنه ولا يقومون دائمًا بصياغة الطلبات بشكل صحيح. أظهر داني سوليفان العديد من الاستعلامات "الخاطئة":

تتمثل مهمة المطابقة العصبية في تحديد هدف البحث الحقيقي (النية) وتقديم النتائج الصحيحة.

لتحديد الهدف ، لا يتم استخدام كلمات منفصلة ، ولكن الجوهر والعلاقات بينهما. انظر كيف يعمل - على سبيل المثال من الاستعلامات "ثمل في حالة سكر ما يجب فعله" و "ثمل في الليل".
يحتوي كل طلب على نفس الكيان - "تم سكره". لكن الجمع بينه وبين جوهر "بين عشية وضحاها" يشير إلى محرك البحث أن المستخدم يعني الإفراط في تناول الطعام. وجوهر "ماذا تفعل" على الأرجح يرتبط بالتسمم.

كيف تحدد Google النية - هل الدلالات متشابهة؟ يقارن محرك البحث عدد مرات العثور على الكيانات المدمجة في الطلب جنبًا إلى جنب على الصفحات. بالإضافة إلى ذلك ، يتم أخذ إحصائيات الطلبات في الاعتبار (المستخدمون عند إدخال الطلب "أصبحوا في حالة سكر في الليل" في أكثر الأحيان ينقرون على مقالات حول الإفراط في تناول الطعام).
مثال آخر يدخل المستخدم عبارة "ضع النوافذ". هذا مجرد طلب "خاطئ" يتحدث عنه داني سوليفان. تدرك Google أن أي شخص من خلال "put" يعني شيئًا آخر غير تثبيت بسيط للنوافذ ، ويعرض في الجزء العلوي النتائج الصحيحة من وجهة نظره:
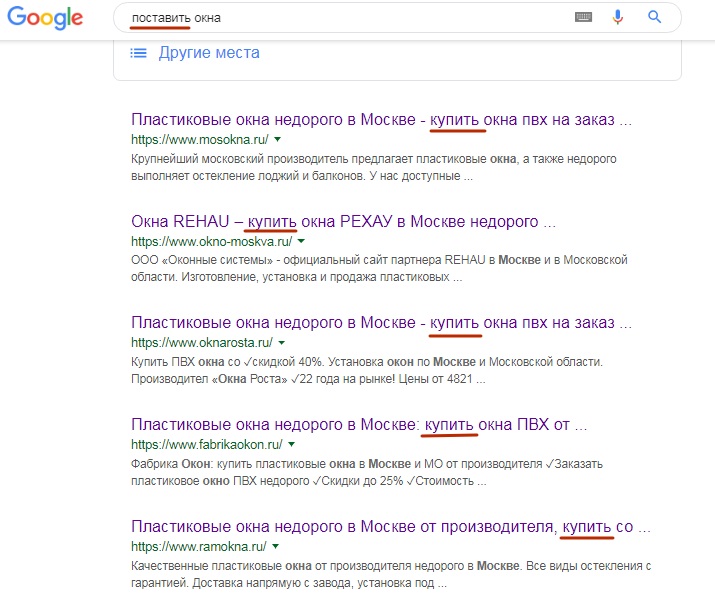
في هذه الحالة ، تحتوي صفحة واحدة فقط من TOP-6 على كلمة "تسليم" (بمعنى "نافذة مزود" ، وليس "تثبيت نوافذ بنفسك"). في الصفحات المتبقية من TOP-6 لا توجد كلمة "ضع" ، ولا حتى كلمات الجذر. على الرغم من أن نتائج مثل "كيفية تثبيت النوافذ بنفسك" ، وما إلى ذلك ، يتم خلطها بالفعل في الأسفل.
هذا يؤدي إلى استنتاج متناقض على ما يبدو: من أجل احتلال المناصب العليا بكلمات عديدة ، ليس من الضروري تشبع النصوص مع دلالات مماثلة لاستعلام البحث. يتم تقييم مدى ملاءمة المحتوى من خلال مجموعة من الكيانات (عبارات التحديد) ، والتي من المحتمل جدًا أن تحقق هدف البحث.
يغير هذا النهج في كتابة نصوص تحسين محركات البحث: في وقت سابق كانت المفاتيح هي النقطة المرجعية ، والآن يحتاج الجمهور.
وثيقة الصلة التصنيف والمطابقة العصبية - كيف سيؤثر هذا سيو؟
اقترح Roger Montti في مقال بمجلة Search Engine Journal أن خوارزمية المطابقة العصبية يمكن أن تعمل وفقًا لطريقة تصنيف صلة الوثيقة (DRR). تم توضيح الطريقة في مقالة " تصنيف الارتباطات العميقة باستخدام تفاعلات محسّنة لاستعلام المستندات " المنشورة على Google AI.
جوهر طريقة DRR هو أنه عند تحديد مدى ملاءمة الوثيقة ، يتم استخدام نصها بشكل حصري. عوامل أخرى - الروابط والمراسيم والإشارات وكبار المسئولين الاقتصاديين على الصفحة - لا يهم.
ما ، لم تعد هناك حاجة الروابط على الإطلاق؟ ليس حقا مثل ذلك. يعد الترتيب وفقًا لطريقة DRR الموصوفة جزءًا من خوارزمية الترتيب العام. في المرحلة الأولى ، يتم إصدار الإصدار مع مراعاة جميع عوامل الترتيب (الروابط ، المفاتيح ، "التنقل" ، تحديد الموقع الجغرافي ، وما إلى ذلك). وبالتالي فإن محرك البحث يلغي المحتوى الأساسي ويحدد المواقع ذات السمعة الطيبة. في المرحلة الثانية ، يدخل DRR العمل - من بين أفضل النتائج ، فإنه يختار الأكثر صلة (مع مراعاة النص فقط).
في الممارسة العملية ، قد يبدو مثل هذا. هناك موقعان: أحدهما حسن السمعة والشباب. يحتوي الموقع الصغير على محتوى فائق لا يحتوي على نظائر في مكانه ، وهو مليء بالتفاصيل والتفاصيل. ولكن نظرًا لوجود المزيد من الروابط إلى موقع موثوق ، فإن صفحته تأخذ الموضع الأول ، بينما تأخذ صفحة الموقع الصغير المرتبة العاشرة. وهنا يبدأ تشغيل DRR - يقوم محرك البحث بمسح النصوص ويدرك أن محتوى الموقع الصغير أكثر أهمية من المحتوى الموثوق. والنتيجة هي انتقال الموقع الشاب إلى منصب أعلى.
كيفية القيام المحتوى تحت المطابقة العصبية
ما إذا كانت المطابقة العصبية تعمل على أساس الحد من مخاطر الكوارث أم لا ، فهي ليست مهمة. من المهم أن يكون هدف البحث "محركات" هنا. ليست طويلة "موطئ قدم" ، وليس كثافة الكلمات الرئيسية ، وليس المرادفة.

قبل إنشاء المحتوى ، قرر:
- لمن هو (من الأفضل إجراء البحث ، وصور المستخدمين والكتابة لهم) ؛
- لماذا هو مطلوب (ما المهمة التي تغلقها)؟
- ما هو فيه ما لا يملكه المنافسون (ما القيمة التي يجلبها).
لزيادة أهمية النصوص ، بالإضافة إلى الاستفسارات الأساسية ، استخدم الكيانات ذات الصلة الوثيقة. إذا كان النص مكتوبًا من قِبل خبير ، فمن المرجح أن تكون هذه الكيانات في النص. إنها مسألة أخرى عند منح مؤلف الإعلانات المعارف التقليدية - في هذه الحالة ، من الضروري تحديد الكيانات والإشارة إليها في المهمة.
دعنا نفكر في طرق جمع الكيانات باستخدام مثال فئة من متجر على الإنترنت "مولدات البنزين".
1. ابحث عن أسئلة / إجابات
يمكنك تحديد احتياجات المستخدمين باستخدام المنتديات والتعليقات على مقالات المدونة والمناقشات على الشبكات الاجتماعية. كل شيء يعمل. ولكن من الأسهل الانتقال إلى Answers@Mail.ru (أو النظير الغربي - Quora ) ، وإدخال استعلام بحث ، وتصفح الأسئلة ، وتسليط الضوء على الكيانات المرتبطة بالمفاتيح الرئيسية.
بناء على طلب "مولدات البنزين" mail.ru تصدر 1624 سؤال. نذهب إلى القائمة ونختار الكيانات التي تميز احتياجات الجمهور المستهدف.


بعد اختيار الكيانات ، نفكر في المحتوى المناسب لها. على سبيل المثال ، يجب توضيح استهلاك البنزين لكل ساعة واحدة وطرق استخدام المولد (للحام ، للغلاية ، للإضاءة ، إلخ) في وصف سلع محددة. في وصف نموذج "مولدات البنزين" ، يمكنك أن تصف باختصار كيف تختلف مولدات البنزين عن الغاز ، العاكس ، وما إلى ذلك. ويرد وصف لمشكلة تشغيل المولدات في المقالة الخاصة بالمدونة.
إن معالجة الأسئلة في خدمات ضمان الجودة أمر مرهق ، لكنه يسمح لك بتسليط الضوء على الاحتياجات الحقيقية للجمهور ، والتي ربما لم تخمنها.
يمكنك محاولة تبسيط العمل باستخدام خدمة الاجابة العامة . إنه يجمع الأسئلة والمقارنات والتركيبات المختلفة التي تحدث على الشبكة مع حدوث عبارة معينة.

العيب الوحيد هو خدمة اللغة الإنجليزية. ترجمة العبارة المطلوبة تحل المشكلة جزئيًا. ولكن في القطاع التجاري ، تجدر الإشارة إلى خصائص الأسواق (ما يقلق الهنود قد يكون عديم الفائدة بالنسبة للروس).
2. تحليل عبارات الجمعيات
ضمن نتائج البحث ، يتم عرض مجموعة "معًا ... التي يتم البحث عنها كثيرًا" - يتم جمع العبارات التي يربطها محرك البحث نفسه مع العبارة الأصلية ("مولدات البنزين") هنا.

يسمح لك تحليل عبارات الارتباط بتحديد الكيانات ذات الصلة: 5 كيلوواط ، 3 كيلوواط ، 10 كيلوواط ، العاكس ، 1 كيلوواط.
يبقى التفكير في كيفية تضمينها في المحتوى. على سبيل المثال ، في وصف عمود "المولدات التي تعمل بالبنزين" ، تجدر الإشارة إلى أسباب استخدام المولدات ذات القدرة المختلفة (1 ، 3 ، 5 ، 10 كيلو واط) والنوع (العاكس ، التقليدي ، إلخ).
إذا كان لديك الكثير من الطلبات الأولية ، فقم بجمع الارتباطات يدويًا لفترة طويلة - استخدم المحلل اللغوي .
3. تحليل تلميحات البحث
تلميحات مصدر آخر لمطابقة الكيانات ذات الصلة.

نحن تجديد قائمة الكيانات التي تم جمعها من الجمعيات: مع التشغيل التلقائي ، الديزل ، 380 فولت ، صامت. هذه هي الكلمات التي تميز مشاكل المستخدم بشكل جيد.
يوجد أيضًا محلل لجمع التلميحات.
من حيث المبدأ ، الأساليب التي تمت مناقشتها كافية للحصول على فكرة عن احتياجات الجمهور. ولكن إذا كنت ترغب في ممارسة الدلالات الأعمق ، فهناك طريقتان اختياريتان.
4. اختيار شبه المرادفات
شبه المرادفات (الجمعيات الدلالية) هي كلمات قريبة من المعنى ، ولكنها غير قابلة للتبادل في سياقات مختلفة. على سبيل المثال ، عبارة "المولد" و "المولد التلقائي" هي مرادفات في النص الخاص بقطع غيار السيارات ، لكنها لن تكون كذلك في النص الخاص بأنواع المولدات.
يتم تحديد المرادفات شبه بناءً على عدد مرات حدوثها في النصوص. لحل هذه المشكلة ، هناك خدمة RusVectōrēs (قسم "كلمات مماثلة"). أدخل كلمة الاهتمام ، وحدد جميع الطرز وأجزاء الكلام المتاحة ، وابدأ البحث.

نتيجة لذلك ، ستحصل على أهم 10 شركاء في كل نموذج بحث. استخدامهم العمياء في تكوين المعارف التقليدية لا يستحق كل هذا العناء - سيكون هناك الكثير من "القمامة" هنا (تحليل الارتباطات استنادًا إلى بيانات من محركات البحث لا يزال الأفضل). ومع ذلك ، يمكنك تحديد كلمات مثيرة للاهتمام. على سبيل المثال ، نرى أن الكلمات "مولد الغاز" ، و "العاكس" ، و "مولد الغاز" ، و "الموصل" ، وما إلى ذلك ترتبط بكلمة "المولد".
5. تحليل النصوص المنافس
لتحديد احتياجات الجمهور ، هذه الطريقة ليست هي الأفضل. أولاً ، لا يُعرف متى تم إنشاء المحتوى على مواقع الويب الخاصة بالمنافسين (خلال هذا الوقت ، قد تتغير تفضيلات البحث). ثانياً ، ليس هناك ما يضمن أن المنافسين قد حللوا بعناية مشاكل الجمهور وصمموا نصوصًا تستند إليهم.
من ناحية أخرى ، إذا استخدمت هذه الطريقة كمساعد ، فهناك فرصة لتحديد الكيانات التي قد تفوتها.
لذلك ، ندخل الاستعلام الرئيسي "مولدات البنزين" في البحث ، وانسخ النصوص ذات الصلة من المواقع إلى TOP-10 واختر الدلالات باستخدام Advego :

نحن نستكمل قائمة الكيانات ذات الصلة: 4 السكتة الدماغية ، الطوارئ ، الحكم الذاتي ، دون انقطاع ، للمنزل الصيفي ، للطبيعة ، الخ
وضع كل ذلك معًا والحصول على المعارف التقليدية الأمثل للمطابقة العصبية.
المعارف التقليدية للكلمات: اصنع التطابق العصبي ، وليس LSI
بعد جمع الكيانات ذات الصلة ، يجب عليك كتابة النص. ولكن لا يكفي فقط تحديد المفاتيح وقائمة المرادفات والكلمات ذات الصلة في TOR ، كما يحدث عادةً عند طلب نصوص LSI .

مثال على المعارف التقليدية لنص LSI
على أساس هذه المعارف التقليدية - ببساطة مع قائمة من الكلمات - يتم الحصول على نصوص غريبة في بعض الأحيان.
من الممارسات الشائعة بين مؤلفي الكتب كتابة نص ، وعندئذٍ فقط إدخال الكلمات المحددة فيه. هذا أسهل ، حيث لا تحتاج إلى مقاطعة اختيار الكلمات وإدراجها في عملية كتابة النص. لكن مثل هذه الإدخالات بأثر رجعي يمكن أن تكسر - وغالبًا ما تنهار - منطق وأسلوب النص.
النص الموجود تحت المطابقة العصبية يدور حول المستخدمين واحتياجاتهم ، وليس حول المفاتيح وكلمات زائد. لذلك ، تظهر ميزات تسويقية بحتة في المعارف التقليدية: أوصاف المستهلك ودوافعها. المفاتيح والكلمات الإضافية تتلاشى في الخلفية - يتم استخدامها كعلامات ، وليس كعناصر إلزامية. يحتل مكانهم احتياجات المعلومات للجمهور.

مثال المعارف التقليدية تحت المطابقة العصبية
تسمح هذه المعارف التقليدية للمؤلف أن يفهم بوضوح من هو النص ولماذا وتحت أي ظروف سيتم قراءته. إن هذه المعارف التقليدية لا توضح الكلمات المراد استخدامها فحسب ، بل تعطي توجيهات - ماذا تكتب من أجل استخدام هذه الكلمات.
المطابقة العصبية ، عندما تقوم بتحسين الصفحات للبحث ، فإنها تحول التركيز من ميكانيكا محسنات محركات البحث إلى التسويق. في الواقع ، وقد لوحظ هذا الاتجاه لعدة سنوات. المطابقة العصبية هي مجرد خطوة أخرى نحو تحسين محرك البحث مع الوجه الإنساني.
يستغرق تحسين محتوى المطابقة العصبية وقتًا ورأس عمل. من الأسهل بكثير إسقاط المفاتيح من AX إلى المعارف التقليدية ، وتحليل الكلمات الزائدة وقول مؤلف الإعلانات: "الكتابة للأشخاص". ولكن مع تطور بحث الذكاء الاصطناعى ، فإن هذا النهج سيكون أقل وأقل فعالية.