اسمي ماركو
وألقيت حديثًا في
Gophercon Russia هذا العام حول نوع مثير جدًا من الفهارس يسمى "فهارس الصور النقطية". أردت أن أشاركه مع المجتمع ، ليس فقط في تنسيق الفيديو ، ولكن كمقال أيضًا. إنها نسخة باللغة الإنجليزية ويمكنك قراءة الروسية
هنا . من فضلك استمتع!

يمكن الاطلاع على المواد الإضافية والشرائح وكل الكود المصدري هنا:
http://bit.ly/bitmapindexeshttps://github.com/mkevac/gopherconrussia2019تسجيل الفيديو الأصلي:
لنبدأ!
مقدمة

اليوم سأتحدث عنه
- ما هي الفهارس.
- ما هو فهرس الصورة النقطية ؛
- حيث يتم استخدامها. لماذا لا يتم استخدامه حيث لا يتم استخدامه.
- سنرى تطبيقًا بسيطًا في Go ، ثم نذهب إلى المحول البرمجي.
- بعد ذلك ، سننظر إلى تطبيق بسيط إلى حد ما ، ولكنه أسرع بشكل ملحوظ ، في تطبيق التجميع Go.
- وبعد ذلك ، سأقوم بمعالجة "مشاكل" فهارس الصورة النقطية واحداً تلو الآخر.
- وأخيرا ، سوف نرى ما هي الحلول القائمة هناك.
إذن ما هي الفهارس؟
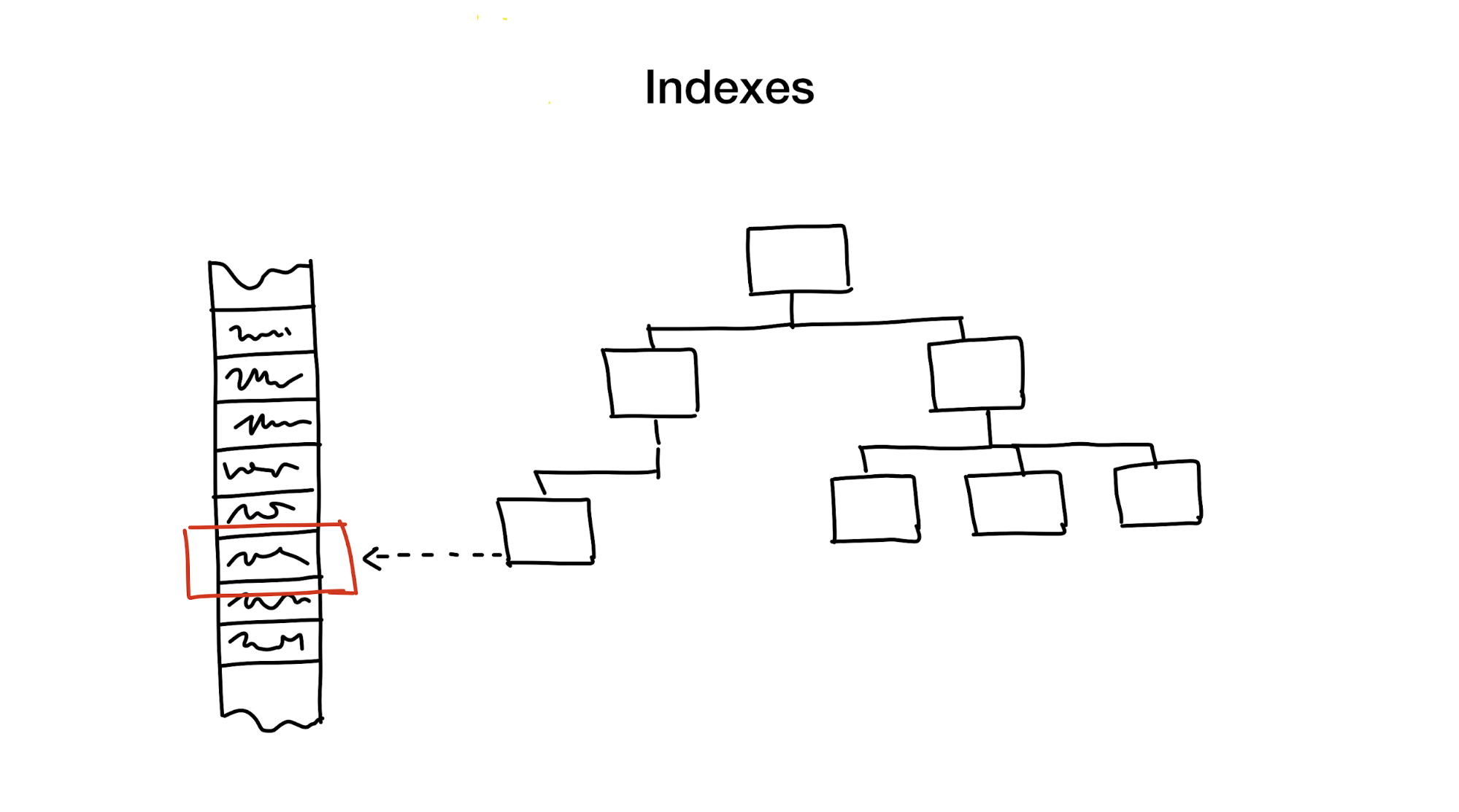
الفهرس هو بنية بيانات مميزة يتم تحديثها بالإضافة إلى البيانات الرئيسية ، وتستخدم لتسريع طلبات البحث. بدون فهارس ، قد يتضمن البحث المرور عبر كافة البيانات (في عملية تُعرف أيضًا باسم "الفحص الكامل") وتتسم هذه العملية بتعقيد حسابي خطي. لكن قواعد البيانات عادة ما تحتوي على كميات هائلة من البيانات ، لذلك التعقيد الخطي بطيء جدًا. من الناحية المثالية ، نود تحقيق سرعات لوغاريتمية أو حتى تعقيد ثابت.
هذا موضوع ضخم ومعقد ينطوي على الكثير من المقايضات ، ولكن بالنظر إلى الوراء على مدى عقود من تطبيقات قواعد البيانات والأبحاث ، أود أن أزعم أنه لا يوجد سوى عدد قليل من الأساليب الشائعة الاستخدام:

أولاً ، تقليل مساحة البحث عن طريق تقطيع المنطقة بأكملها إلى أجزاء أصغر ، بشكل هرمي.
عموما ، يتم تحقيق ذلك باستخدام الأشجار. يشبه وجود صناديق من الصناديق في خزانة الملابس الخاصة بك. يحتوي كل صندوق على مواد يتم فرزها في صناديق أصغر ، كل منها لاستخدام محدد. إذا كنا بحاجة إلى مواد ، فمن الأفضل أن نبحث عن المربع المسمى "مادة" بدلاً من مربع يسمى "ملفات تعريف الارتباط".
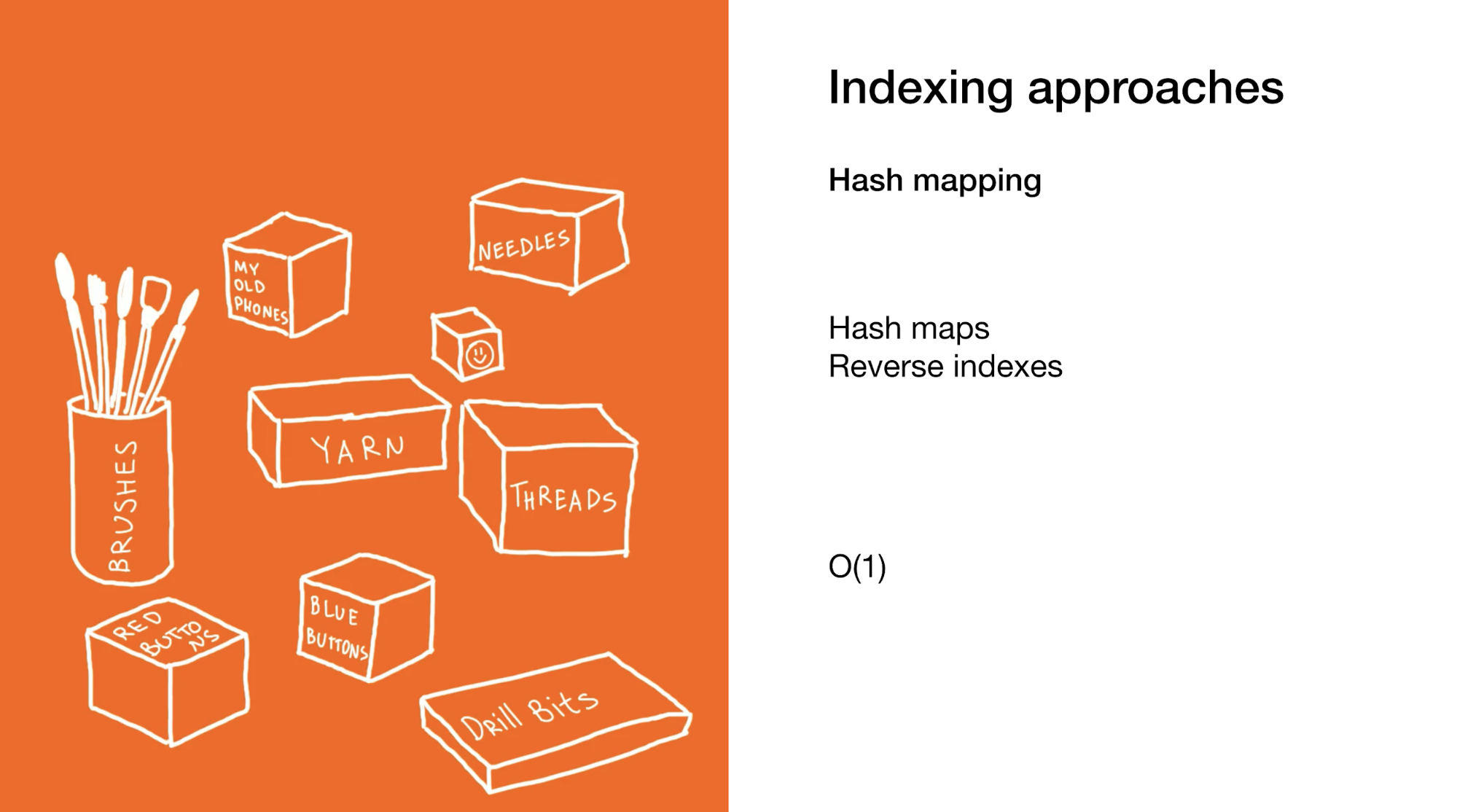
الثاني هو تحديد عنصر أو مجموعة من العناصر على الفور كما هو الحال في خرائط التجزئة أو الفهارس العكسية. استخدام خرائط التجزئة يشبه المثال السابق ، لكنك تستخدم العديد من الصناديق الأصغر التي لا تحتوي على مربعات بنفسها ، بل تستخدم العناصر النهائية.

النهج الثالث هو إزالة الحاجة للبحث على الإطلاق كما هو الحال في مرشحات ازهر أو مرشحات الوقواق. يمكن أن توفر لك عوامل تصفية Bloom إجابة على الفور وتوفر لك الوقت الذي تقضيه في البحث.
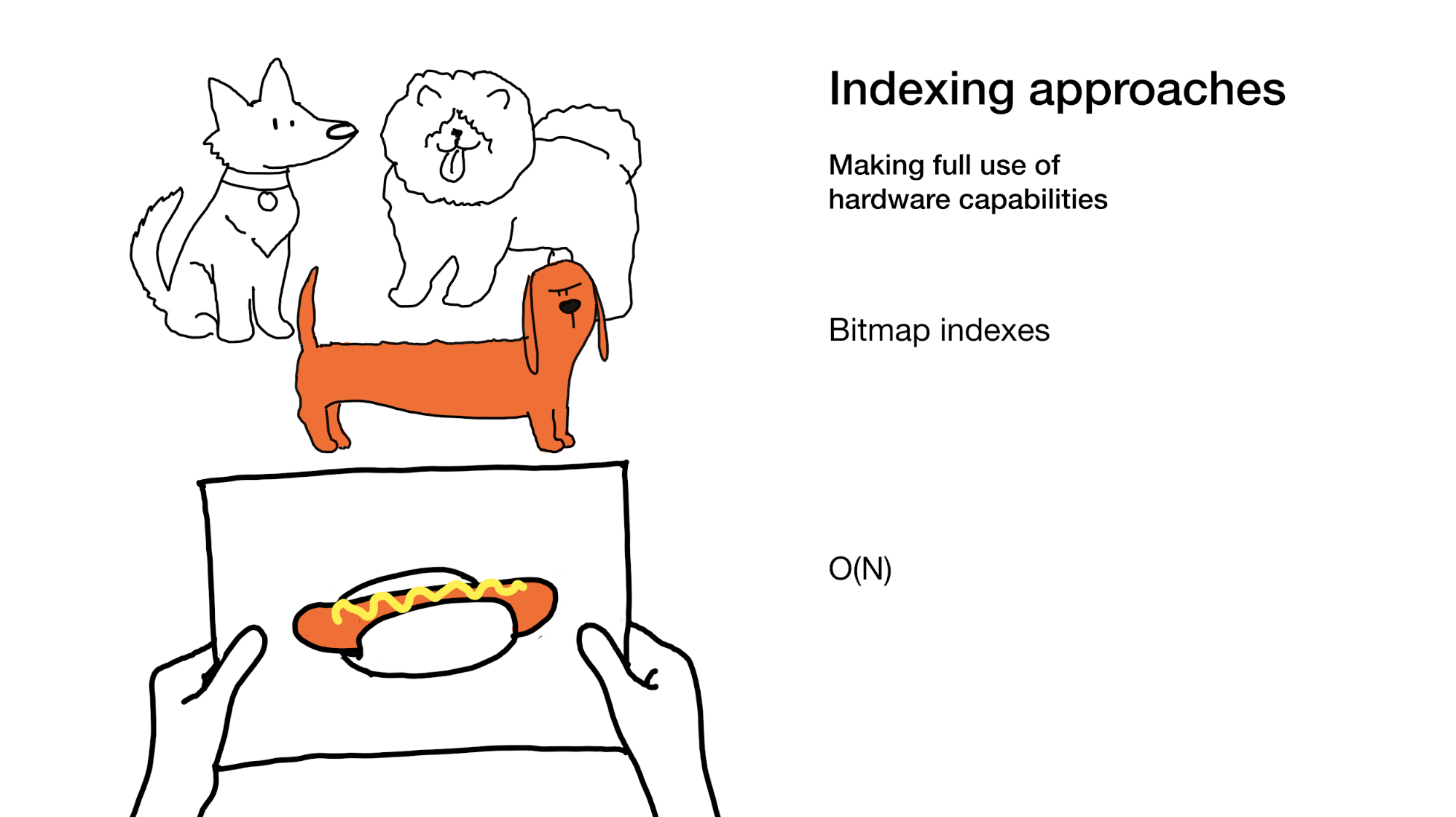
آخر واحد هو تسريع البحث من خلال الاستفادة بشكل أفضل من قدرات الأجهزة لدينا كما هو الحال في فهارس الصورة النقطية. تتضمن مؤشرات الصور النقطية أحيانًا الانتقال إلى الفهرس بالكامل ، نعم ، ولكن يتم ذلك بطريقة فعالة للغاية.
كما قلت سابقًا ، يحتوي البحث على الكثير من المقايضات ، فغالبًا ما نستخدم عدة طرق لتحسين السرعة أكثر أو لتغطية جميع أنواع البحث المحتملة.
أود اليوم أن أتحدث عن أحد هذه الأساليب الأقل شهرة: فهارس الصورة النقطية.
لكن من أنا لأتحدث عن هذا الموضوع؟
أنا فريق قيادي في Badoo (ربما تعرف واحدة أخرى من علاماتنا التجارية: Bumble). لدينا أكثر من 400 مليون مستخدم في جميع أنحاء العالم والكثير من الميزات التي لدينا تشمل البحث عن أفضل تطابق لك! بالنسبة لهذه المهام ، نستخدم الخدمات المخصصة التي تستخدم فهارس الصور النقطية وغيرها.
الآن ، ما هو فهرس الصورة النقطية؟
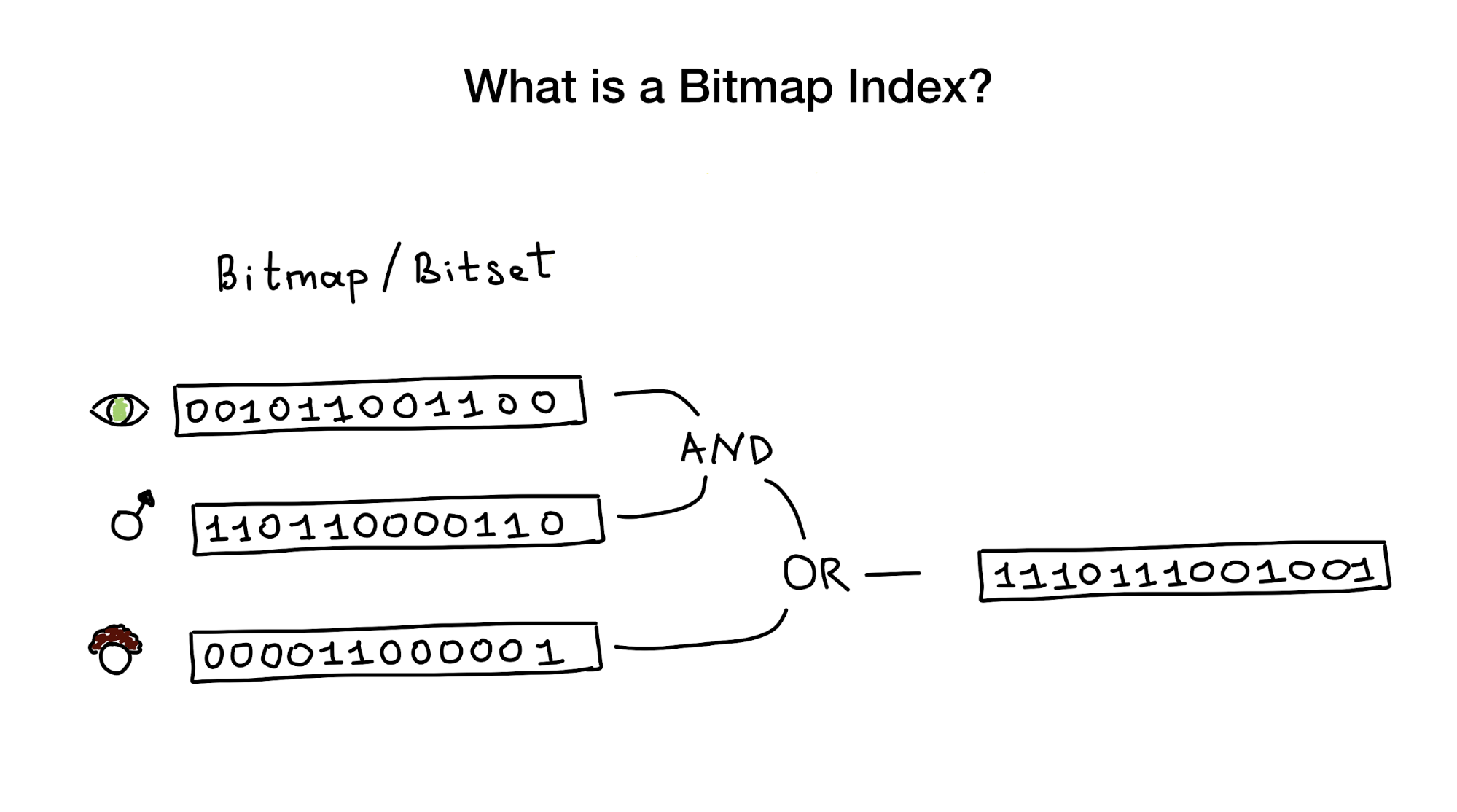
كما يوحي اسمه ، تستخدم فهارس الصور النقطية الصور النقطية ويعرف أيضًا باسم بتات لتطبيق فهرس البحث. من وجهة نظر عين الطير ، يتكون هذا الفهرس من واحدة أو عدة صور نقطية تمثل كيانات (مثل الأشخاص) ومعلماتها (مثل العمر أو لون العين) وخوارزمية للإجابة على استعلامات البحث باستخدام عمليات bitwise مثل AND ، OR ، NOT ، إلخ. .

تُعد فهارس الصور النقطية مفيدة جدًا وعالية الأداء إذا كان لديك عملية بحث يجب أن تجمع بين الاستعلامات من خلال عدة أعمدة ذات أصل منخفض (ربما ، لون العين أو الحالة الزوجية) مقابل شيء مثل المسافة إلى مركز المدينة الذي يحتوي على أصل غير محدود.
ولكن في وقت لاحق من هذه المقالة ، سأظهر أن فهارس الصور النقطية تعمل حتى مع الأعمدة الرئيسية عالية.
دعونا نلقي نظرة على أبسط مثال على فهرس الصورة النقطية ...

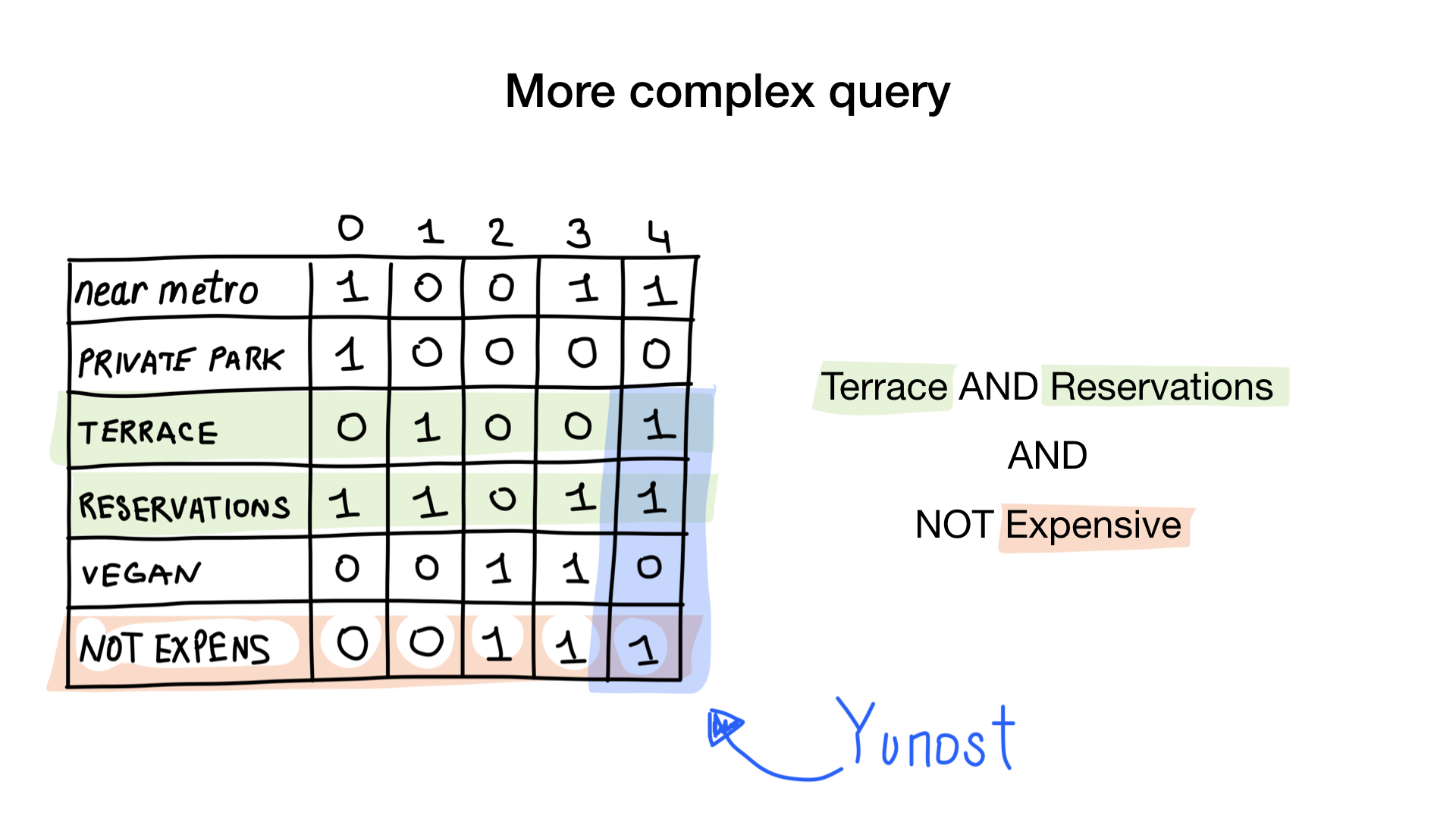
تخيل أن لدينا قائمة بمطاعم موسكو ذات الخصائص الثنائية:
- بالقرب من المترو
- لديها مواقف خاصة للسيارات
- لديه شرفة
- يقبل التحفظات
- نباتي-ودية
- تكلفة
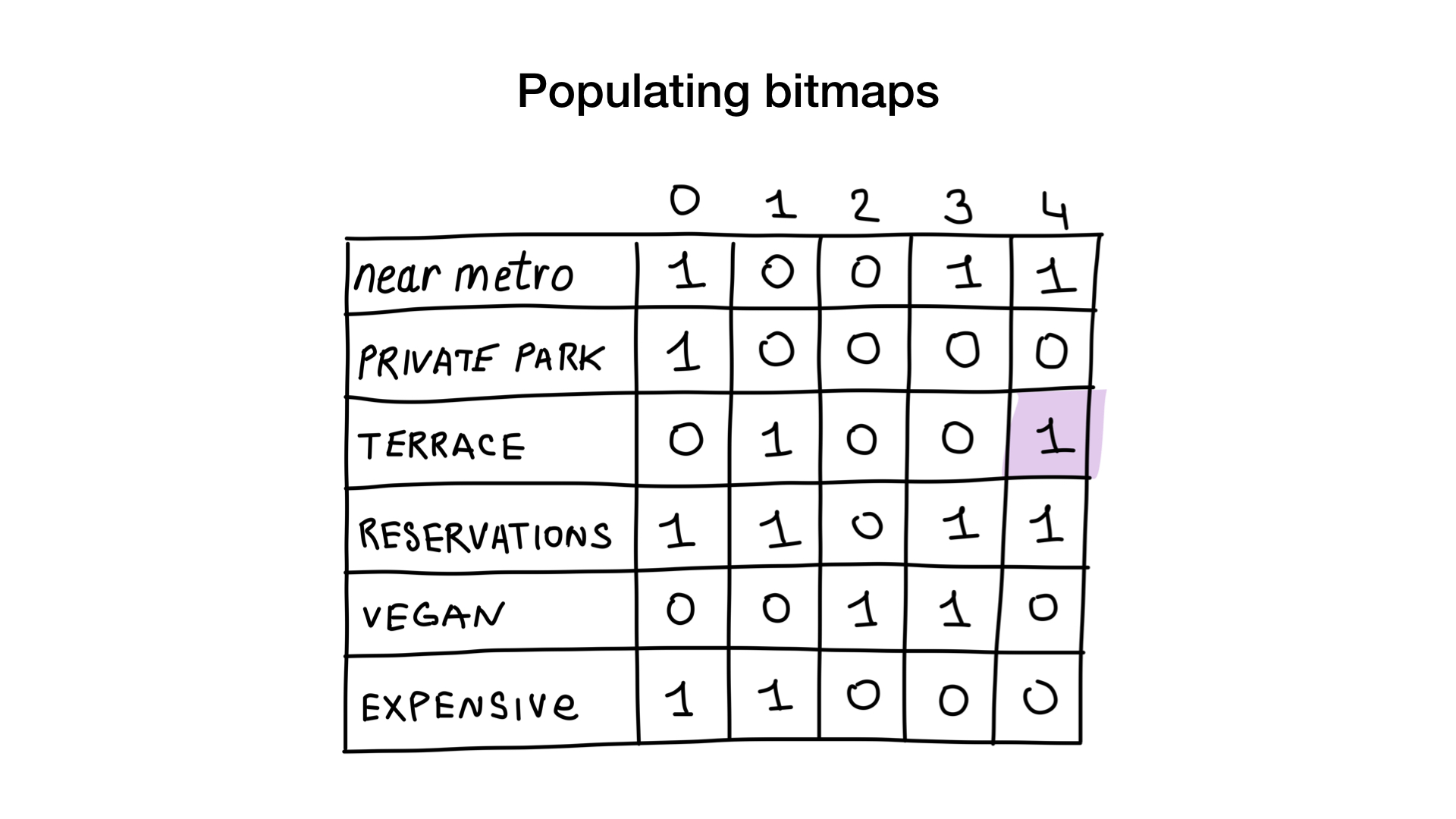
دعنا نعطي كل مطعم فهرسًا يبدأ من 0 وخصص 6 صور نقطية (واحد لكل خاصية). ثم سنقوم بملء هذه الصور النقطية وفقًا لما إذا كان المطعم لديه خاصية محددة أم لا. إذا كان المطعم رقم 4 يحتوي على التراس ، فسيتم تعيين رقم البت 4 في صورة نقطية "التراس" على 1 (0 إن لم يكن).

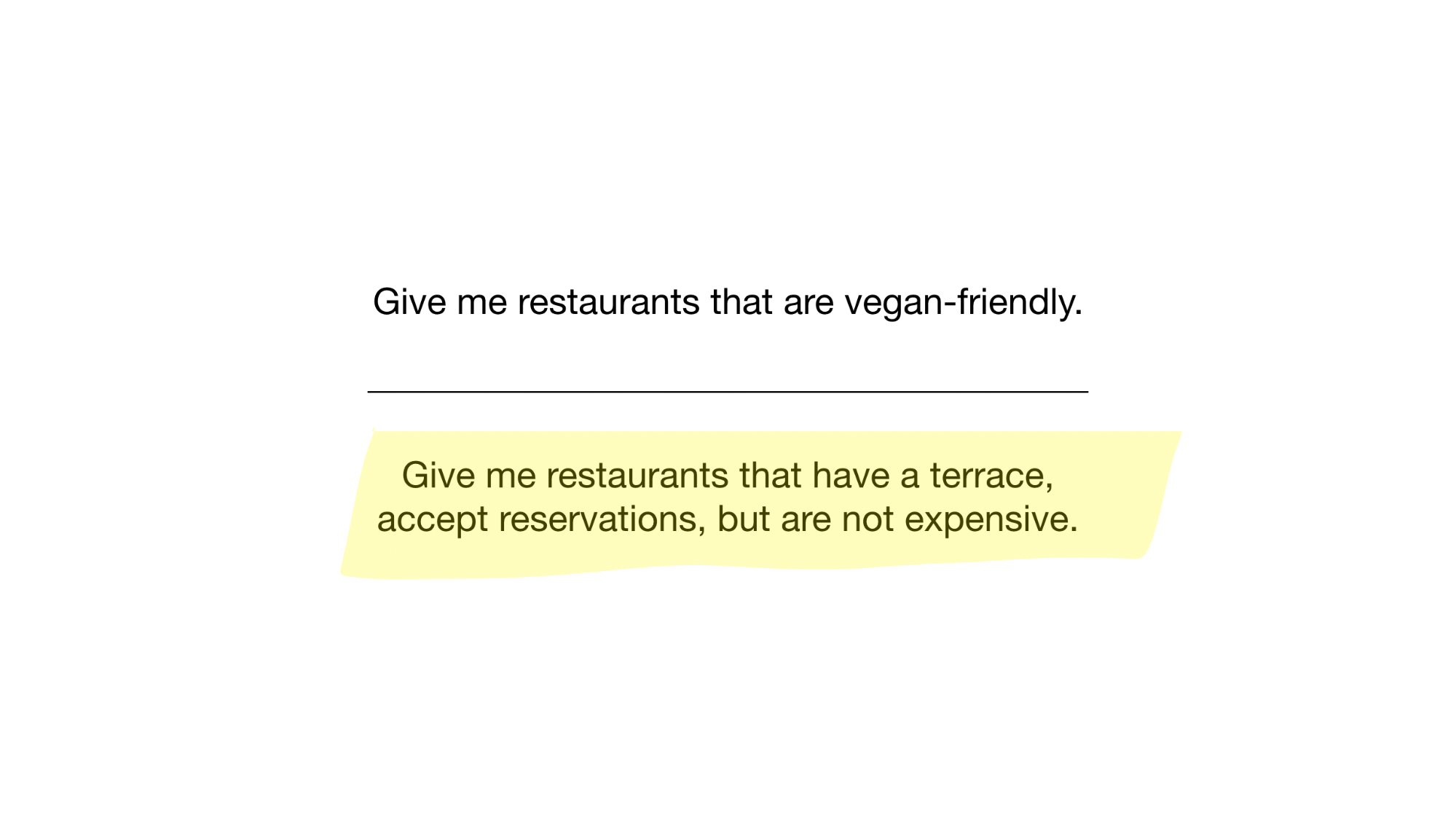
لدينا الآن أبسط فهرس نقطي ممكن يمكننا استخدامه للإجابة على أسئلة مثل
- أعطني المطاعم الصديقة للنباتات
- أعطني المطاعم مع شرفة تقبل الحجوزات ، ولكنها ليست باهظة الثمن


كيف؟ لنرى. السؤال الأول بسيط. نأخذ فقط صورة نقطية "نباتي" ونعيد جميع المؤشرات التي تحتوي على مجموعة بت.

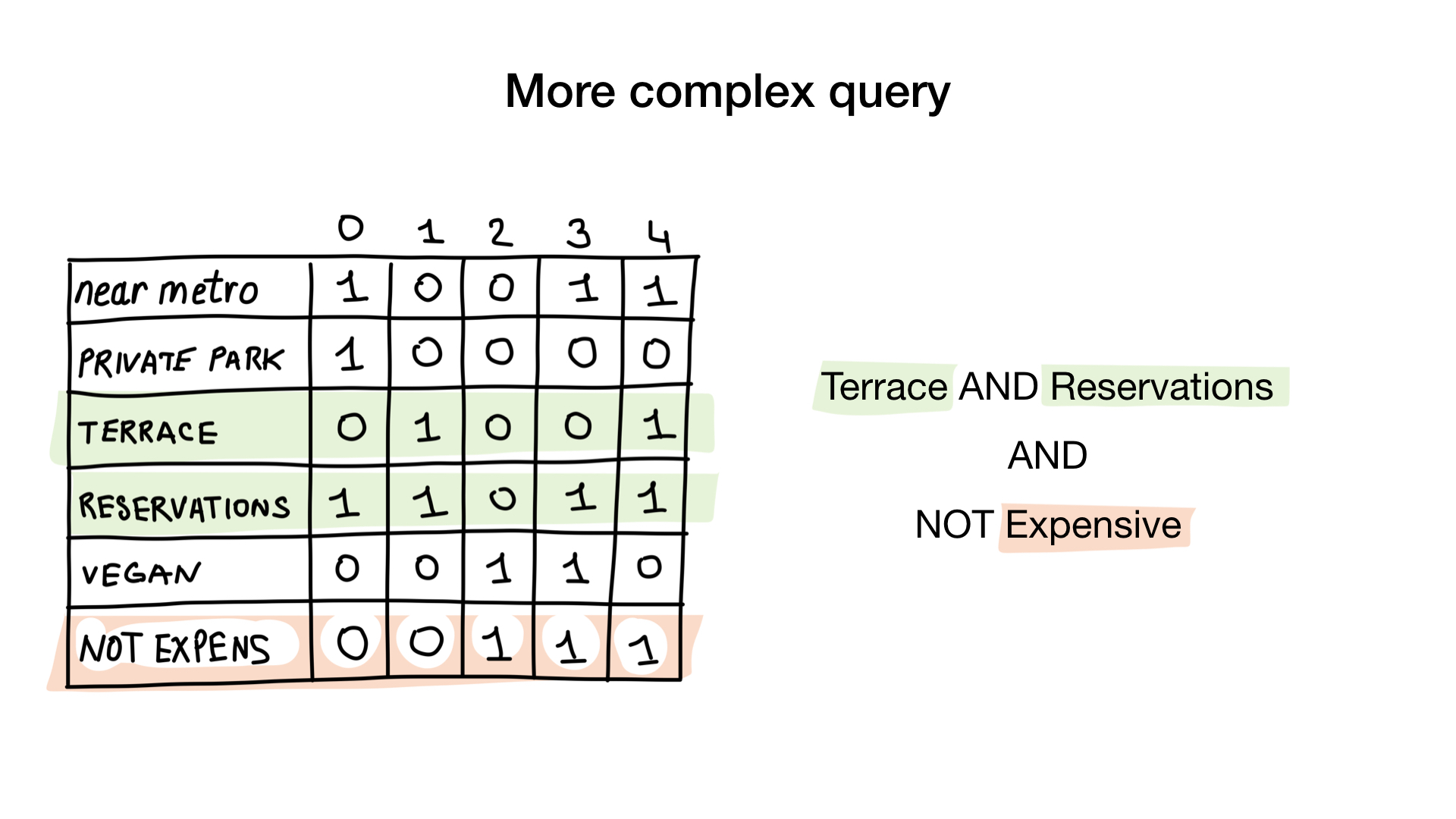
السؤال الثاني هو أكثر تعقيدا قليلا. سنستخدم العملية bitwise NOT على الصورة النقطية "الباهظة الثمن" للحصول على مطاعم غير باهظة الثمن ، مع الصورة النقطية "قبول الحجز" و AND مع "يحتوي على صورة نقطية للشرفة". ستتكون الصورة النقطية الناتجة من المطاعم التي لديها كل هذه الخصائص التي أردناها. هنا نرى أن يونس فقط لديه كل هذه الخصائص.
قد يبدو هذا نظريًا بعض الشيء ولكن لا تقلق ، فسنصل الرمز بعد قليل.
حيث يتم استخدام فهارس الصورة النقطية

إذا كنت google "فهرس الصورة النقطية" ، فستشير 90٪ من النتائج إلى Oracle DB الذي يحتوي على فهارس نقطية أساسية. لكن ، بالتأكيد ، تستخدم DBMS الأخرى فهارس الصور النقطية ، أليس كذلك؟ لا ، في الواقع ، لم يفعلوا. دعنا نذهب من خلال المشتبه بهم المعتادة واحدا تلو الآخر.


- ولكن هناك فتى جديد على الكتلة: بيلوسا. Pilosa هو DBMS جديد مكتوب في Go (لاحظ أنه لا يوجد R ، إنه ليس علائقي) يقوم على كل شيء على فهارس الصورة النقطية. وسوف نتحدث عن بيلوسا في وقت لاحق.
التنفيذ في الذهاب
لكن لماذا؟ لماذا فهارس الصورة النقطية نادرًا ما يتم استخدامه؟ قبل الإجابة على هذا السؤال ، أود توجيهك إلى تطبيق فهرس الصورة النقطية الأساسي في Go.

يتم تمثيل الصورة النقطية كقطعة من الذاكرة. في Go ، دعونا نستخدم شريحة بايت لذلك.
لدينا صورة نقطية واحدة لكل سمة مطعم. يمثل كل بت في صورة نقطية ما إذا كان مطعم معين لديه هذه الخاصية أم لا.

سنحتاج وظيفتين المساعد. يتم استخدام واحد لملء الصورة النقطية بشكل عشوائي ، ولكن مع وجود احتمال محدد بوجود الخاصية. على سبيل المثال ، أعتقد أن هناك عددًا قليلاً جدًا من المطاعم التي لا تقبل الحجوزات وحوالي 20٪ منها صديقة للنباتيين.
وظيفة أخرى سوف تعطينا قائمة المطاعم من صورة نقطية.


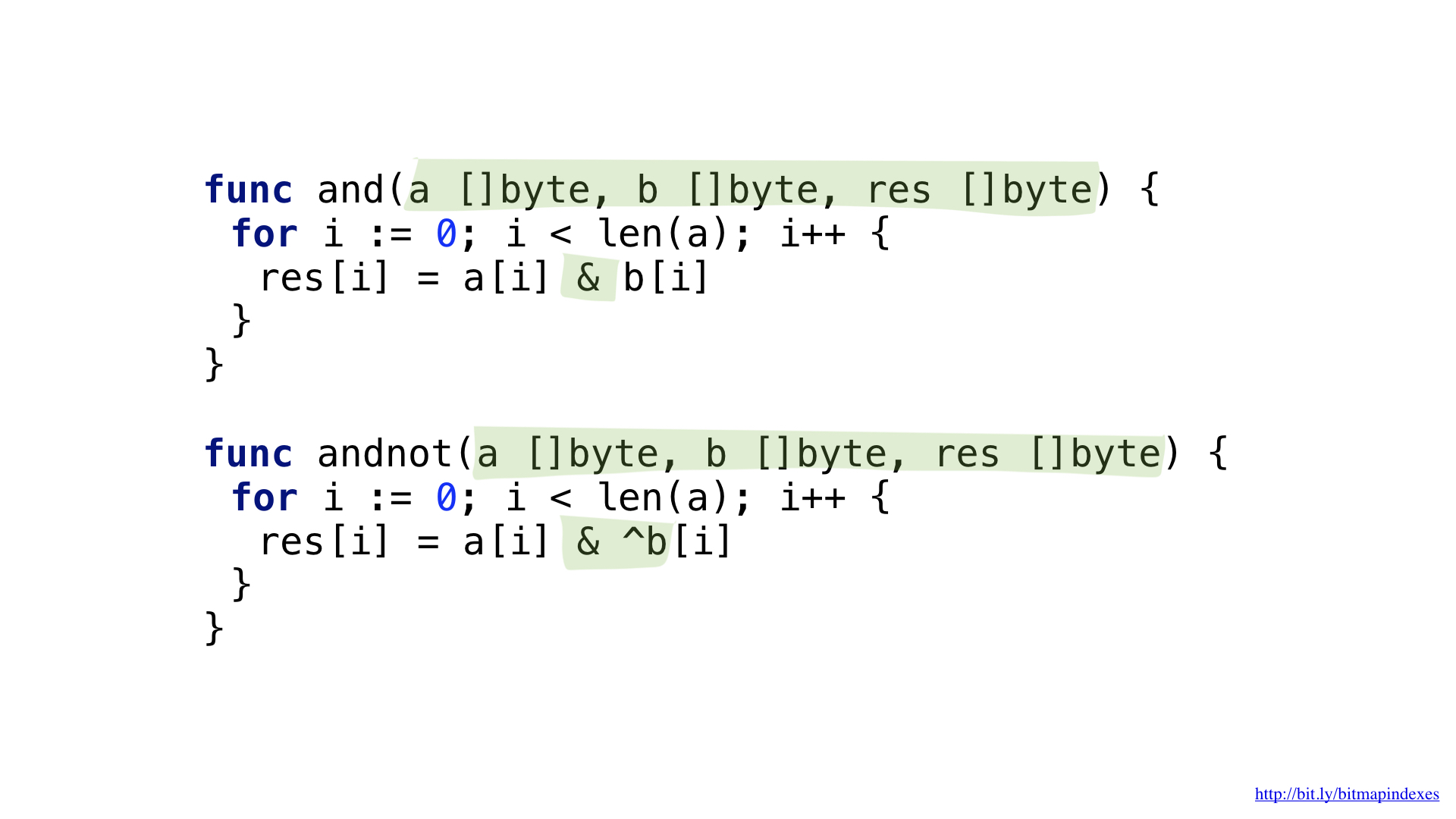
للإجابة على السؤال "أعطني المطاعم مع شرفة تقبل الحجوزات ولكنها ليست باهظة الثمن" ، نحتاج إلى عمليتين: NOT و AND.
يمكننا تبسيط الكود قليلاً من خلال إدخال عملية معقدة و NOT.
لدينا وظائف لكل من هذه. تمر كلتا الوظيفتين من خلال شرائحنا التي تأخذ العناصر المقابلة من كل منهما ، وتجري العملية وتكتب النتيجة إلى الشريحة الناتجة.
والآن يمكننا استخدام الصور النقطية ووظائفنا للحصول على الإجابة.

الأداء ليس رائعًا هنا على الرغم من أن وظائفنا بسيطة حقًا وقد وفرنا الكثير على التخصيصات من خلال عدم إرجاع شريحة جديدة لكل استدعاء دالة.
بعد بعض التنميط باستخدام pprof ، لاحظت أن برنامج التحويل البرمجي go go غاب عن أحد التحسينات الأساسية للغاية: دالة مضمنة.
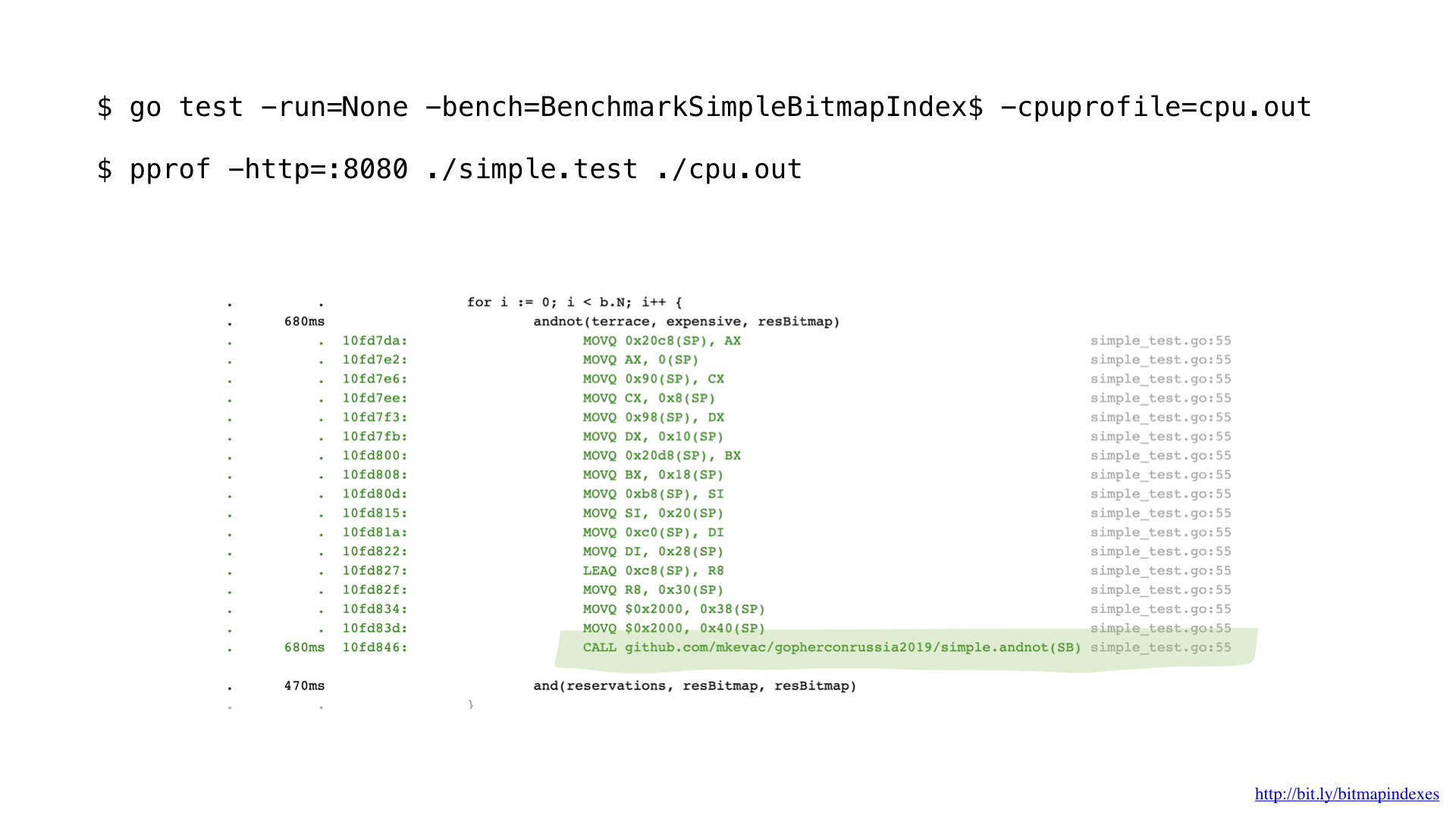
كما ترى ، فإن برنامج Go compiler يخاف من الأمراض من خلال الشرائح ويرفض تضمين أي وظيفة لها تلك الوظائف.
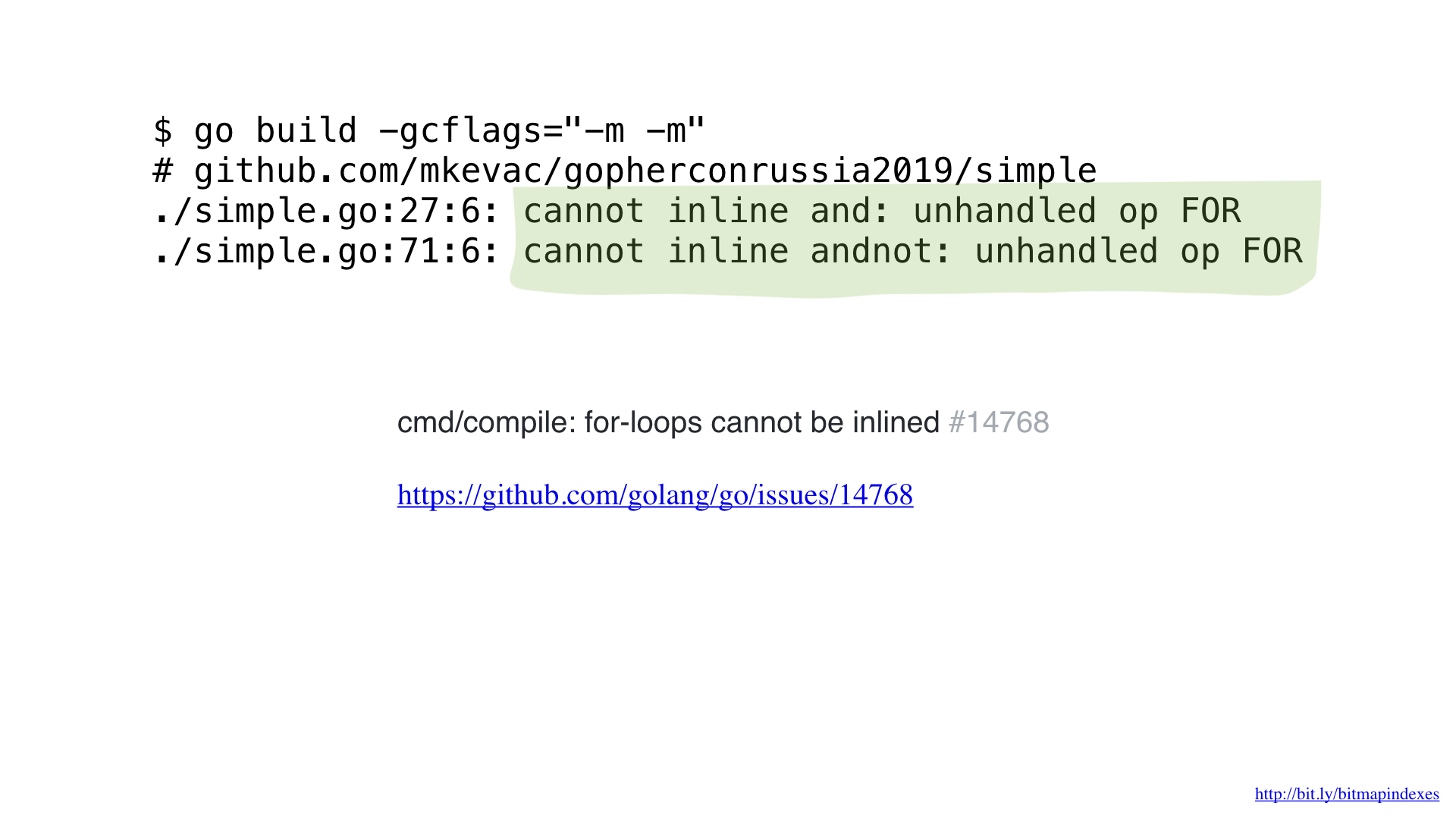
لكنني لست خائفًا منهم ، ويمكنني خداع المترجم باستخدام goto لحلقي.


كما ترون ، أنقذنا المضمّن حوالي 2 ميكروثانية. ليس سيئا!

عنق الزجاجة آخر يسهل اكتشافه عند إلقاء نظرة فاحصة على إخراج التجميع. وشملت الذهاب مترجم الشيكات المدى في حلقة لدينا. Go هي لغة آمنة والمترجم خائف من أن الصور النقطية الثلاثة قد يكون لها أطوال مختلفة وقد يكون هناك تجاوز سعة المخزن المؤقت.
دعونا تهدئة المترجم إلى أسفل وإظهار أن كافة الصور النقطية الخاصة بي هي نفس الطول. للقيام بذلك ، يمكننا إضافة فحص بسيط في بداية الوظيفة.
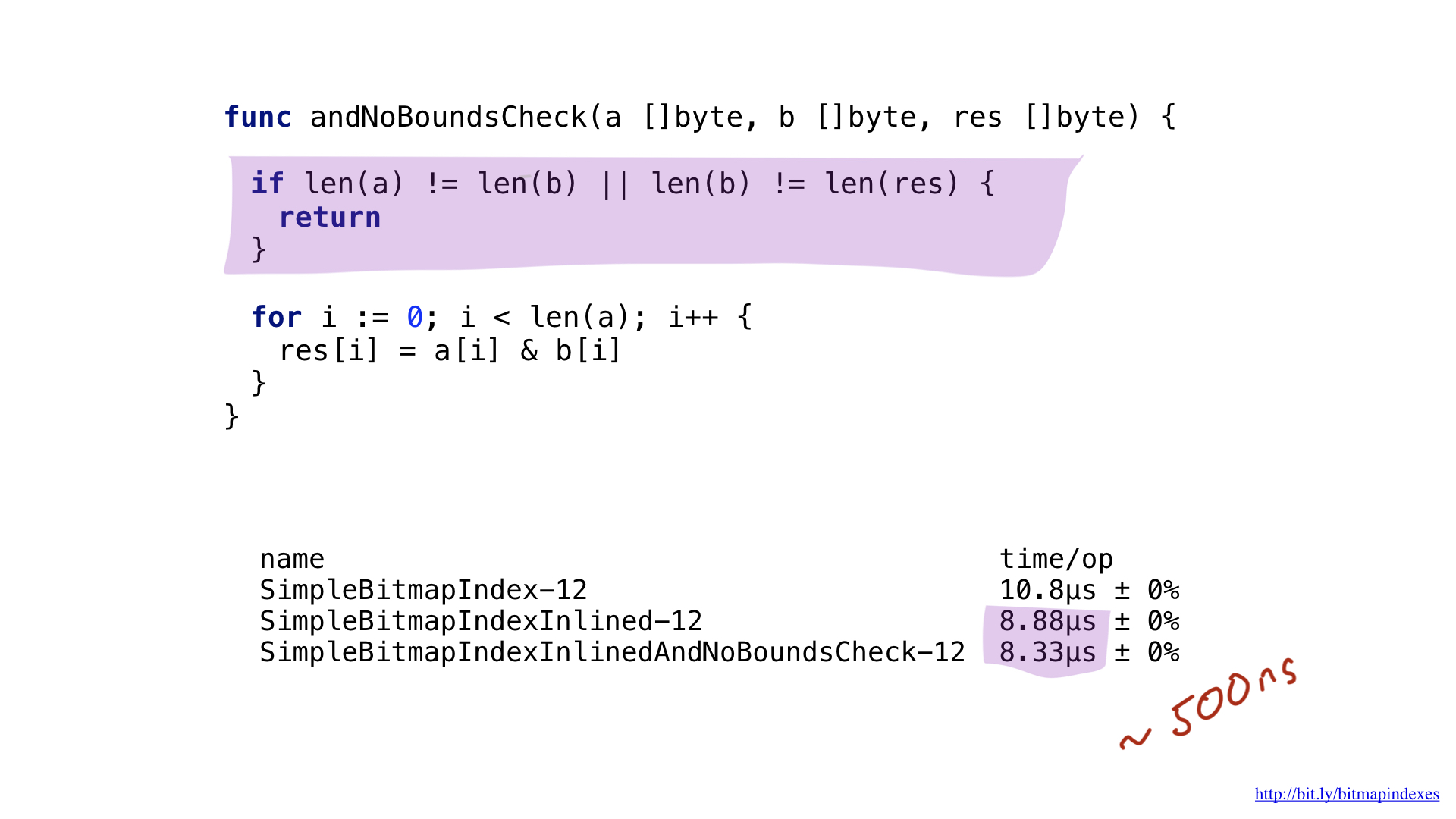
من خلال هذا الاختيار ، سيتخطى برنامج التحويل البرمجي لحسن الحظ عمليات تدقيق النطاق ، وسوف ننقذ بضع نانوثانية.
التنفيذ في التجمع
حسنًا ، لذلك تمكنا من الضغط على أداء أكثر قليلاً من خلال تطبيقنا البسيط ، لكن هذه النتيجة أسوأ بكثير مما هو ممكن في الأجهزة الحالية.
كما ترى ، ما نقوم به هو عمليات bitwise أساسية للغاية ووحدات المعالجة المركزية الخاصة بنا فعالة للغاية مع تلك.
لسوء الحظ ، نحن نقوم بتغذية وحدة المعالجة المركزية لدينا مع قطع صغيرة جدا من العمل. وظيفتنا لا عمليات بايت بايت. يمكننا تعديل تطبيقنا بسهولة للعمل مع قطع 8 بايت باستخدام شرائح uint64.

كما ترون هنا ، لقد اكتسبنا أداءً تقريبًا 8x لحجم دُفعات 8x ، وبالتالي فإن مكاسب الأداء خطية إلى حد كبير.
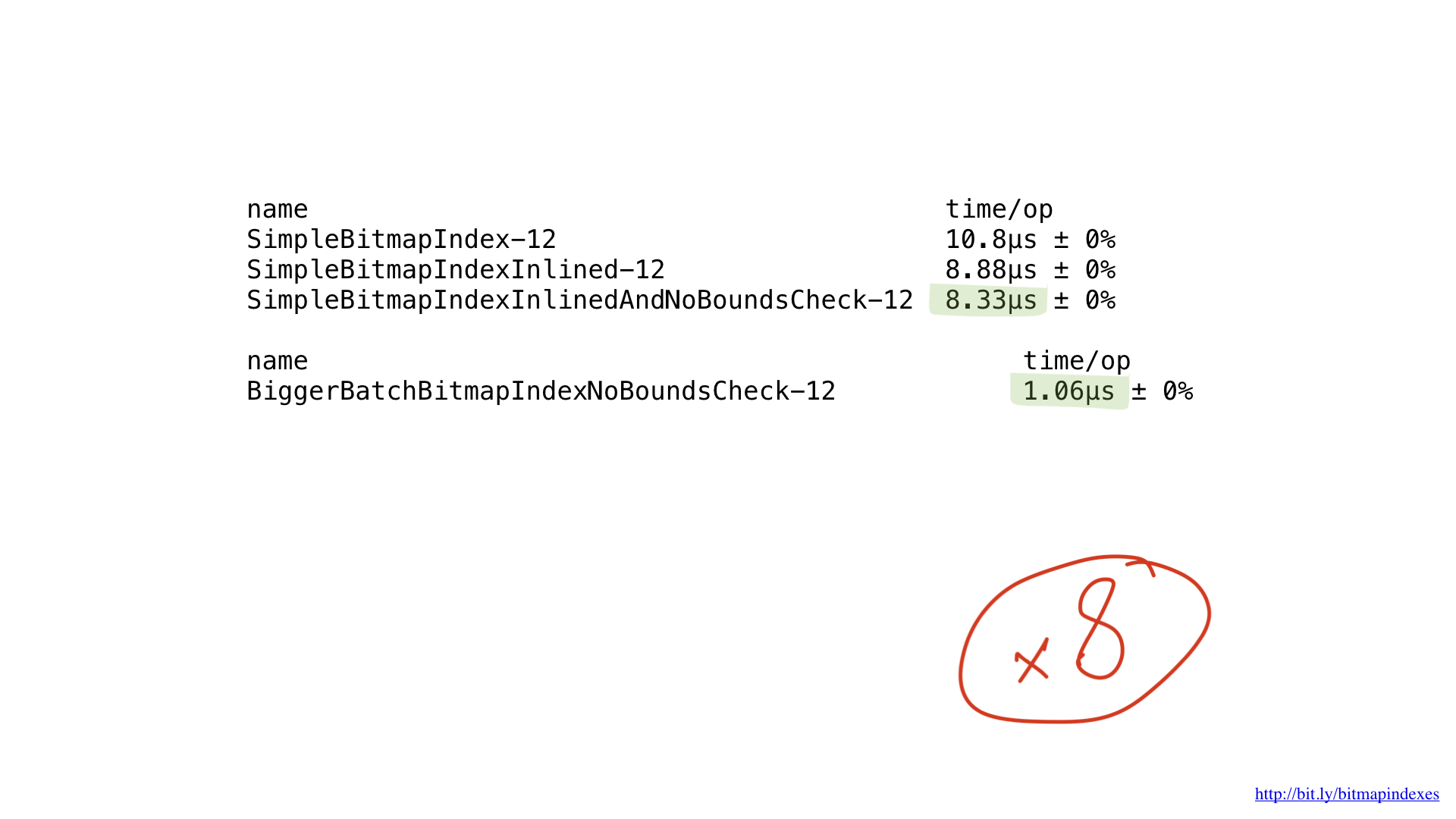

لكن هذه ليست نهاية الطريق. تتمتع وحدات المعالجة المركزية (CPU) الخاصة بنا بالقدرة على العمل مع قطع 16 بايت و 32 بايت وحتى مع قطع 64 بايت. وتسمى هذه العمليات SIMD (Single Instruction Multiple Data) وعملية استخدام مثل هذه العمليات CPU تسمى vectorization.
لسوء الحظ ، فإن برنامج Go compiler ليس جيدًا جدًا مع vectorization. والشيء الوحيد الذي يمكننا القيام به في الوقت الحاضر لتوجيه رمزنا هو استخدام التجميع Go وإضافة هذه التعليمات SIMD بأنفسنا.

الذهاب التجمع هو وحش غريب. كنت تعتقد أن التجميع هو شيء مرتبط بالبنية التي تكتبها من أجلها ، لكن تجميع Go يشبه IRL (لغة التمثيل الوسيطة): إنه مستقل عن النظام الأساسي. أعطى روب بايك حديثًا مدهشًا في هذا الأمر منذ بضع سنوات.
بالإضافة إلى ذلك ، يستخدم Go تنسيق plan9 غير عادي يختلف عن تنسيقي AT&T و Intel.

من الآمن القول إن كتابة رمز التجميع Go ليس متعة.
لحسن الحظ بالنسبة لنا ، هناك بالفعل أداتان من المستوى الأعلى للمساعدة في كتابة مجموعة Go: PeachPy وتجنبها. كلاهما يولد تجميع go من رمز مستوى أعلى مكتوب في Python و Go على التوالي.

تعمل هذه الأدوات على تبسيط بعض الأشياء مثل تخصيص التسجيل والحلقات وتقلل جميعها من تعقيد إدخال مجال برمجة التجميع لـ Go.
سوف نستخدم تجنب هذا المنشور حتى تبدو برامجنا مثل رمز Go العادي.

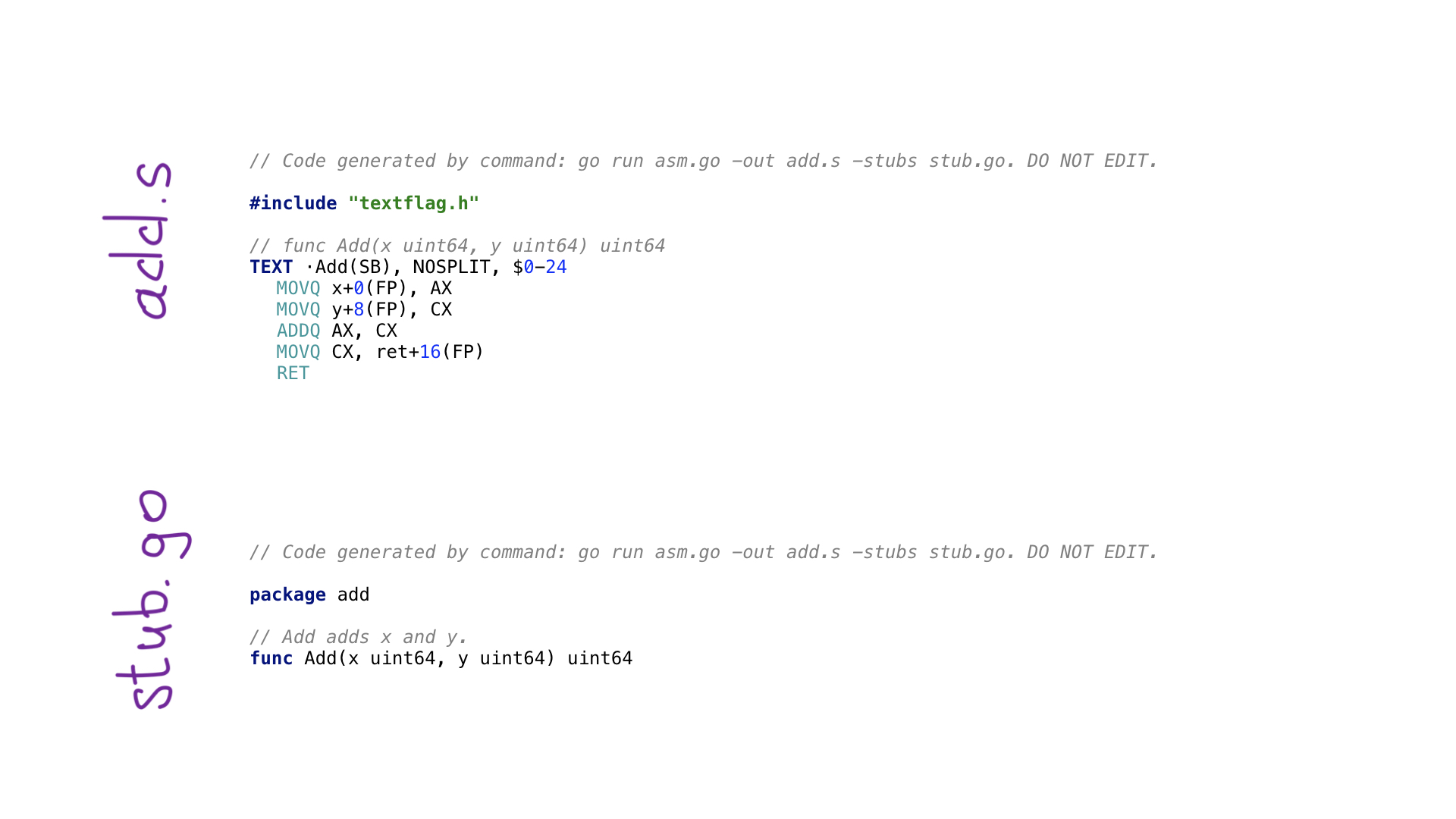
هذا هو أبسط مثال لبرنامج تجنب. لدينا وظيفة رئيسية () تعرّف وظيفة تسمى Add () تضيف رقمين. هناك وظائف المساعد للحصول على المعلمات بالاسم وللحصول على واحدة من السجلات العامة المتاحة. هناك وظائف لكل عملية تجميع مثل ADDQ هنا ، وهناك وظائف مساعد لحفظ النتيجة من سجل إلى القيمة الناتجة.

استدعاء إنشاء توليد سيتم تنفيذ هذا البرنامج تجنب وسيتم إنشاء ملفين
- add.s مع رمز التجميع ولدت
- stub.go مع رؤوس الوظائف اللازمة لربط رمز التجميع والذهاب
الآن بعد أن رأينا ما الذي يتجنبه تجنب ، دعونا ننظر إلى وظائفنا. لقد قمت بتنفيذ كل من الإصدارات العددية و SIMD (المتجهات) لوظائفنا.
لنرى كيف تبدو النسخة العددية أولاً.

كما في المثال السابق ، يمكننا طلب سجل عام وتجنب إعطائنا السجل الصحيح المتاح. لا نحتاج إلى تتبع الإزاحات بالبايت لحججنا ، وتجنب ذلك بالنسبة لنا.

لقد تحولنا سابقًا من الحلقات إلى استخدام goto لأسباب تتعلق بالأداء ولخداع برنامج التحويل البرمجي go. هنا ، نستخدم goto (القفزات) والعلامات مباشرة من البداية لأن الحلقات عبارة عن تصميمات عالية المستوى. في التجمع ليس لدينا سوى يقفز.

يجب أن تكون الشفرة الأخرى واضحة جدًا. نحن نحاكي الحلقة باستخدام القفزات والتسميات ، ونأخذ جزءًا صغيرًا من بياناتنا من الصور النقطية اثنين ، ونجمعها باستخدام إحدى عمليات bitwise ، ونضيف النتيجة في الصورة النقطية الناتجة.

هذا هو رمز asm الناتج الذي نحصل عليه. لم يكن علينا حساب الإزاحات والأحجام (باللون الأخضر) ، ولم يكن علينا التعامل مع سجلات محددة (باللون الأحمر).
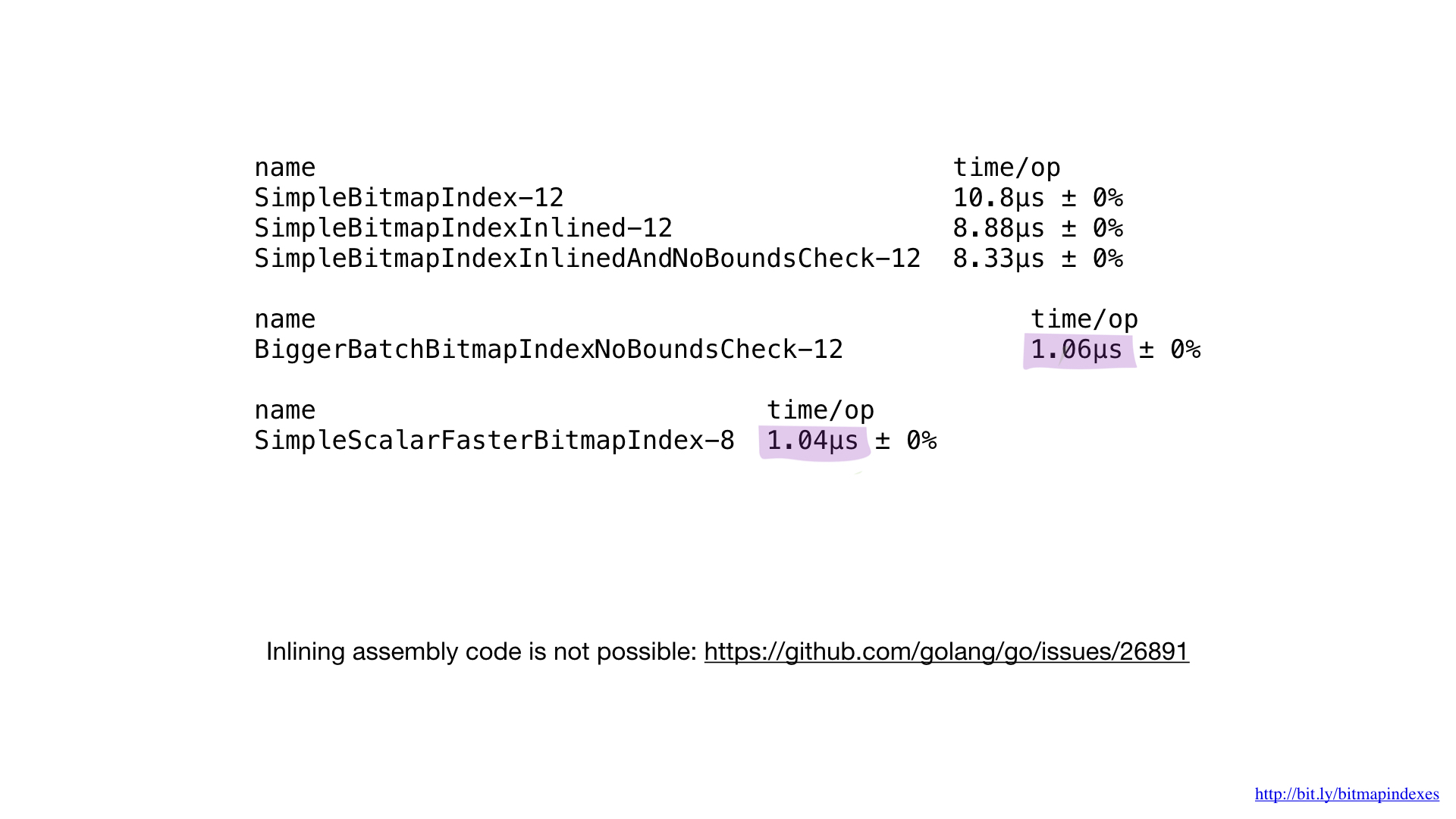
إذا قارنا هذا التطبيق بالتجميع مع أفضل تطبيق سابق مكتوب به ، فسنرى أن الأداء هو نفسه كما هو متوقع. لم نفعل أي شيء بطريقة مختلفة.
لسوء الحظ ، لا يمكننا إجبار Go compiler على تضمين وظائفنا المكتوبة في أسم. إنه يفتقر تمامًا إلى الدعم الخاص به وقد تم العثور على طلب هذه الميزة لبعض الوقت الآن. هذا هو السبب في وظائف ASM الصغيرة في الذهاب لا تعطي أي فائدة. تحتاج إما إلى كتابة وظائف أكبر ، أو استخدام حزمة جديدة للرياضيات / البتات أو تخطي الاسم بالكامل.
دعنا نكتب نسخة متجه من وظائفنا الآن.

اخترت استخدام AVX2 ، لذلك نحن نستخدم قطع 32 بايت. انها تشبه الى حد بعيد العددية في الهيكل. نحن نحمل المعلمات ونطلب السجلات العامة ، إلخ.
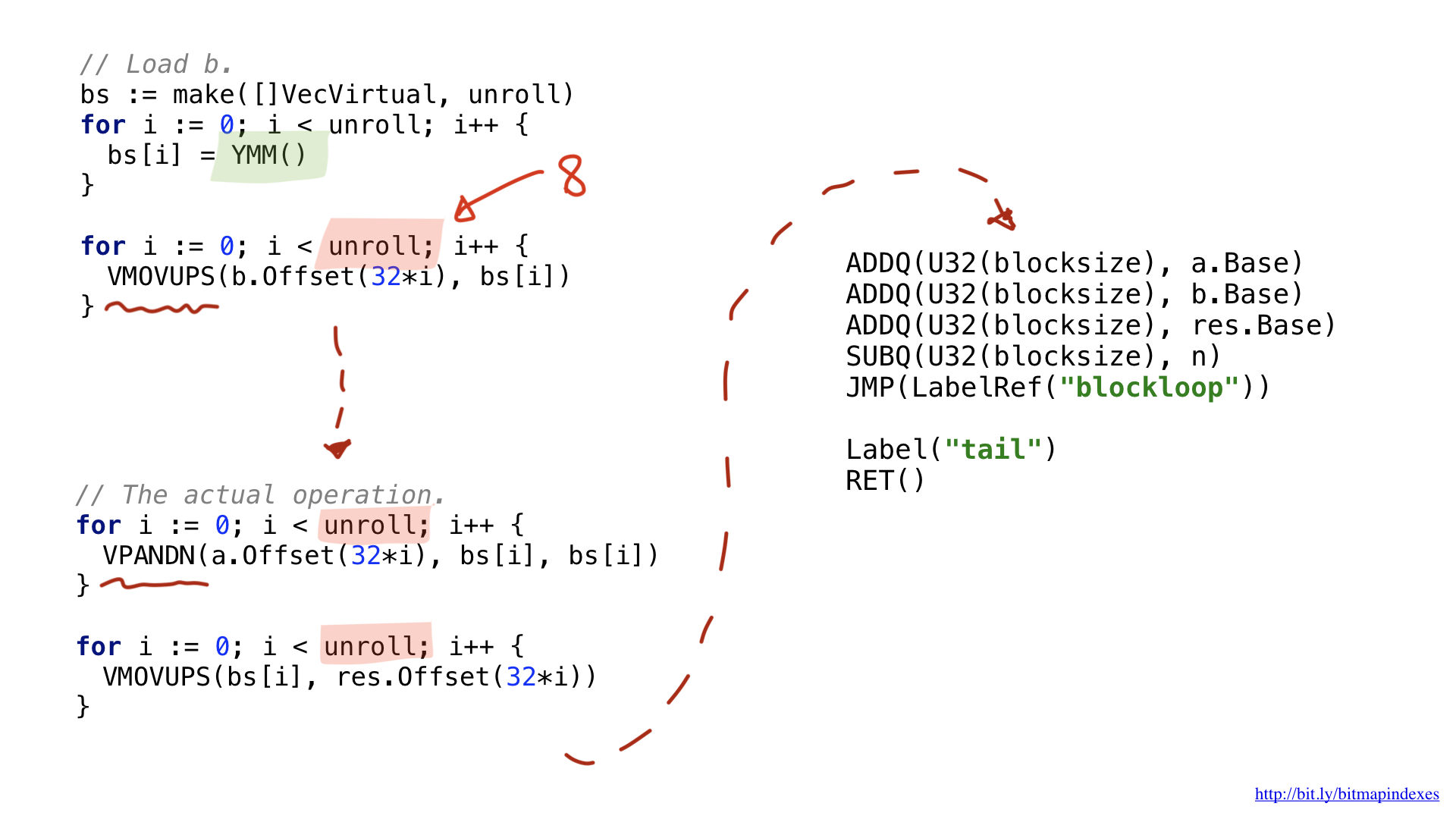
يرتبط أحد التغييرات بحقيقة أن عمليات المتجهات تستخدم سجلات واسعة محددة. لـ 32 بايت لديهم بادئة Y ، وهذا هو السبب في أنك ترى YMM () هناك. ل 64 بايت كان لديهم بادئة Z.
هناك اختلاف آخر يتعلق بالتحسين الذي قمتُ به والذي يُطلق عليه اسم unrolling أو loop unrolling. لقد اخترت إلغاء الحلقة بشكل جزئي والقيام بثمانية عمليات متتالية قبل التسلسل. تعمل هذه التقنية على تسريع الكود عن طريق تقليل الفروع الموجودة لدينا ، وهي محدودة إلى حد كبير بعدد السجلات المتاحة لدينا.
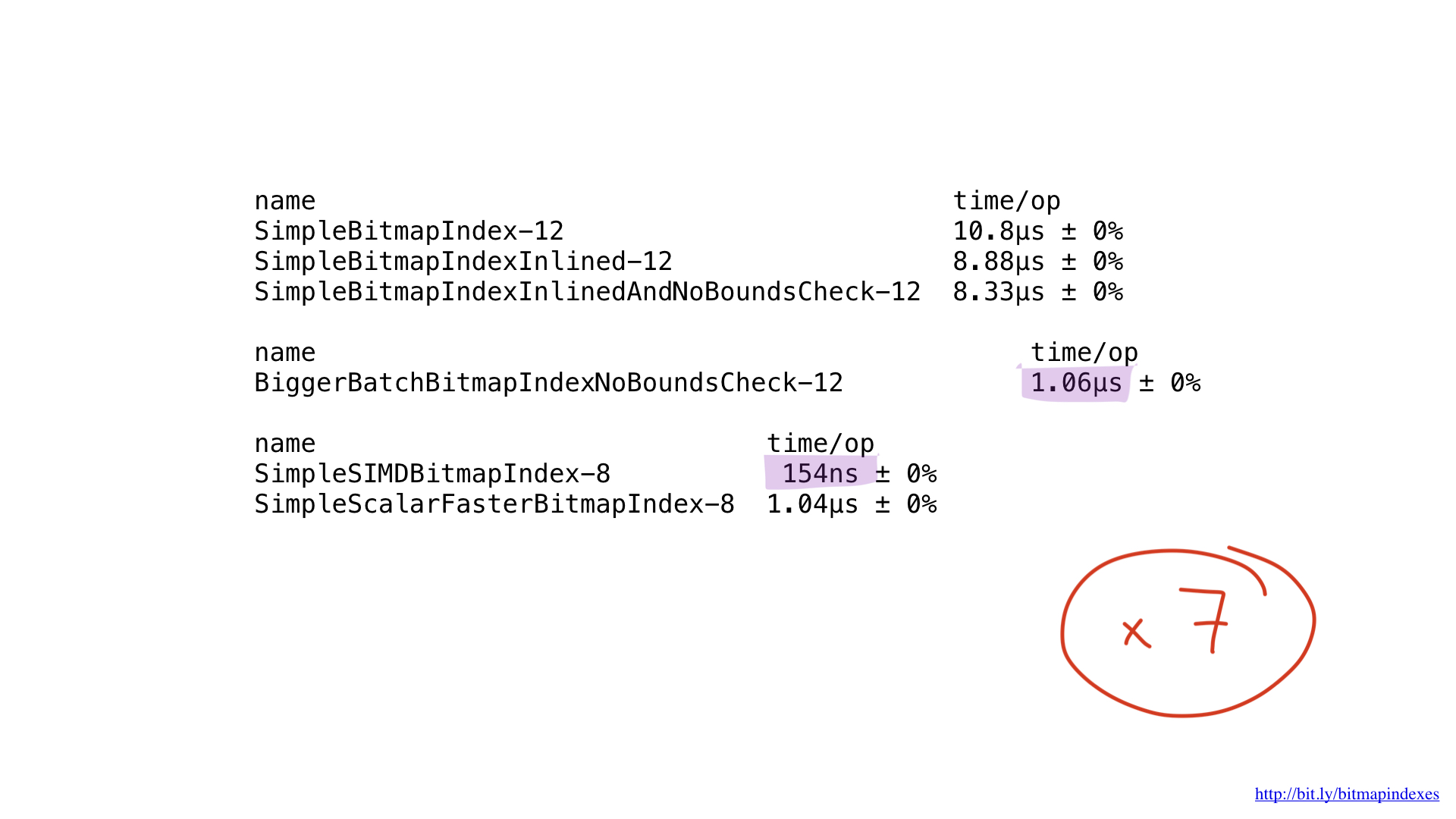
بالنسبة للأداء ... إنه لأمر مدهش. لقد حصلنا على حوالي 7x تحسن مقارنة بالأفضل السابق. مؤثرة جدا ، أليس كذلك؟
يجب أن يكون من الممكن تحسين هذه النتائج أكثر باستخدام AVX512 ، الجلب المسبق ، وربما حتى باستخدام JIT (في الوقت المناسب) التحويل البرمجي بدلاً من منشئ مخطط الاستعلام "اليدوي" ، لكن هذا سيكون موضوعًا لنشر مختلف تمامًا.
مشاكل مؤشر الصورة النقطية
الآن بعد أن رأينا التطبيق الأساسي والسرعة المذهلة للتطبيق asm ، دعنا نتحدث عن حقيقة أن فهارس الصور النقطية غير مستخدمة على نطاق واسع. لماذا هذا؟

المنشورات الأقدم تعطينا هذه الأسباب الثلاثة. لكن الأخيرة ، وأنا أزعم أن هذه "ثابتة" أو التعامل معها الآن. لن أخوض في الكثير من التفاصيل حول هذا الموضوع هنا لأنه ليس لدينا الكثير من الوقت ، لكن الأمر يستحق بالتأكيد نظرة سريعة.
مشكلة كاردينال عالية
لذلك ، لقد قيل لنا أن فهارس الصور النقطية ممكنة فقط لحقول منخفضة الأهمية. أي الحقول التي تحتوي على عدد قليل من القيم المتميزة ، مثل الجنس أو لون العين. والسبب في ذلك هو أن التمثيل المشترك (بت واحد لكل قيمة مميزة) يمكن أن يكون كبيرًا جدًا بالنسبة للقيم العالية. ونتيجة لذلك ، يمكن أن تصبح الصورة النقطية ضخمة حتى لو كانت قليلة الكثافة.
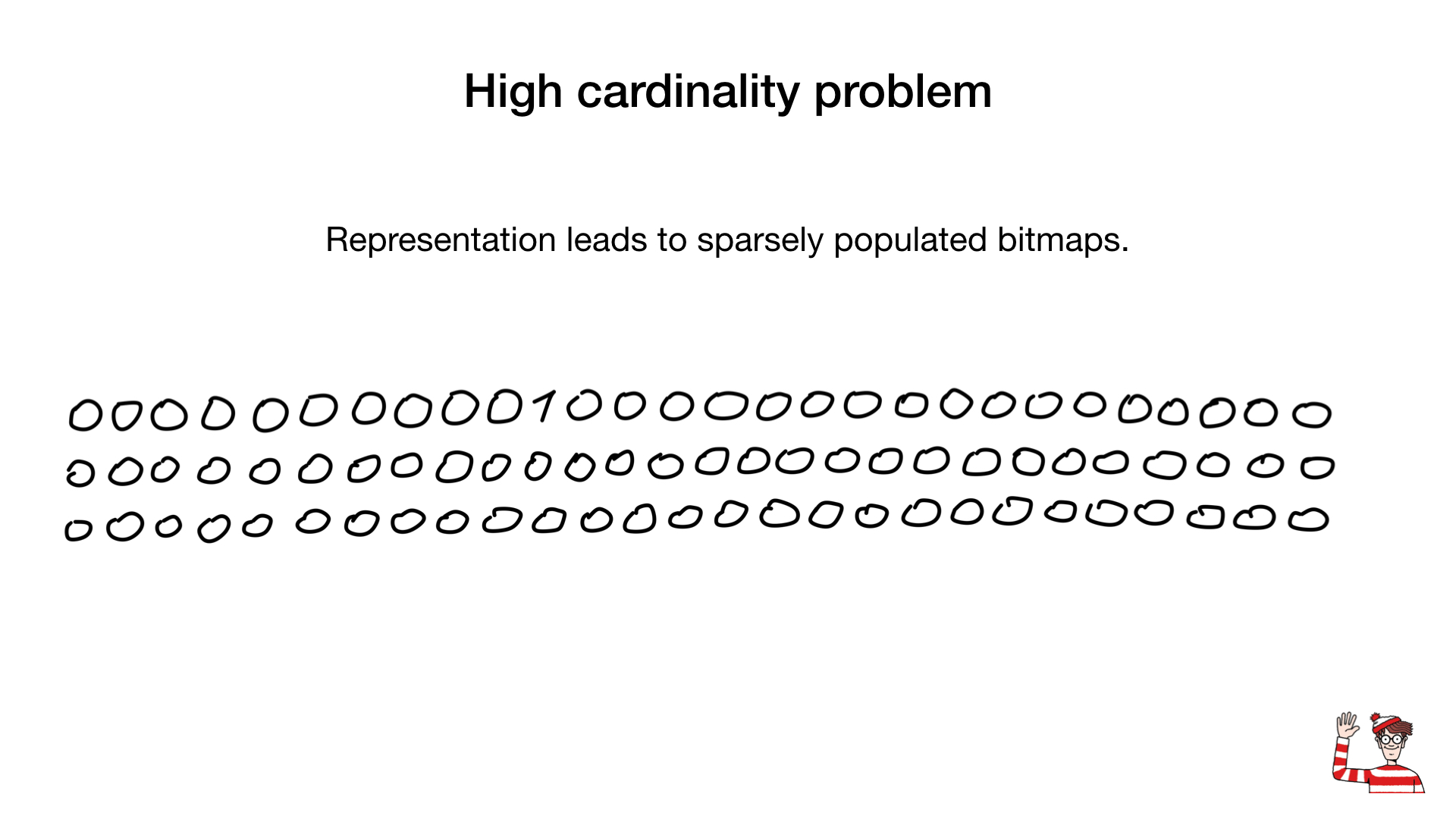
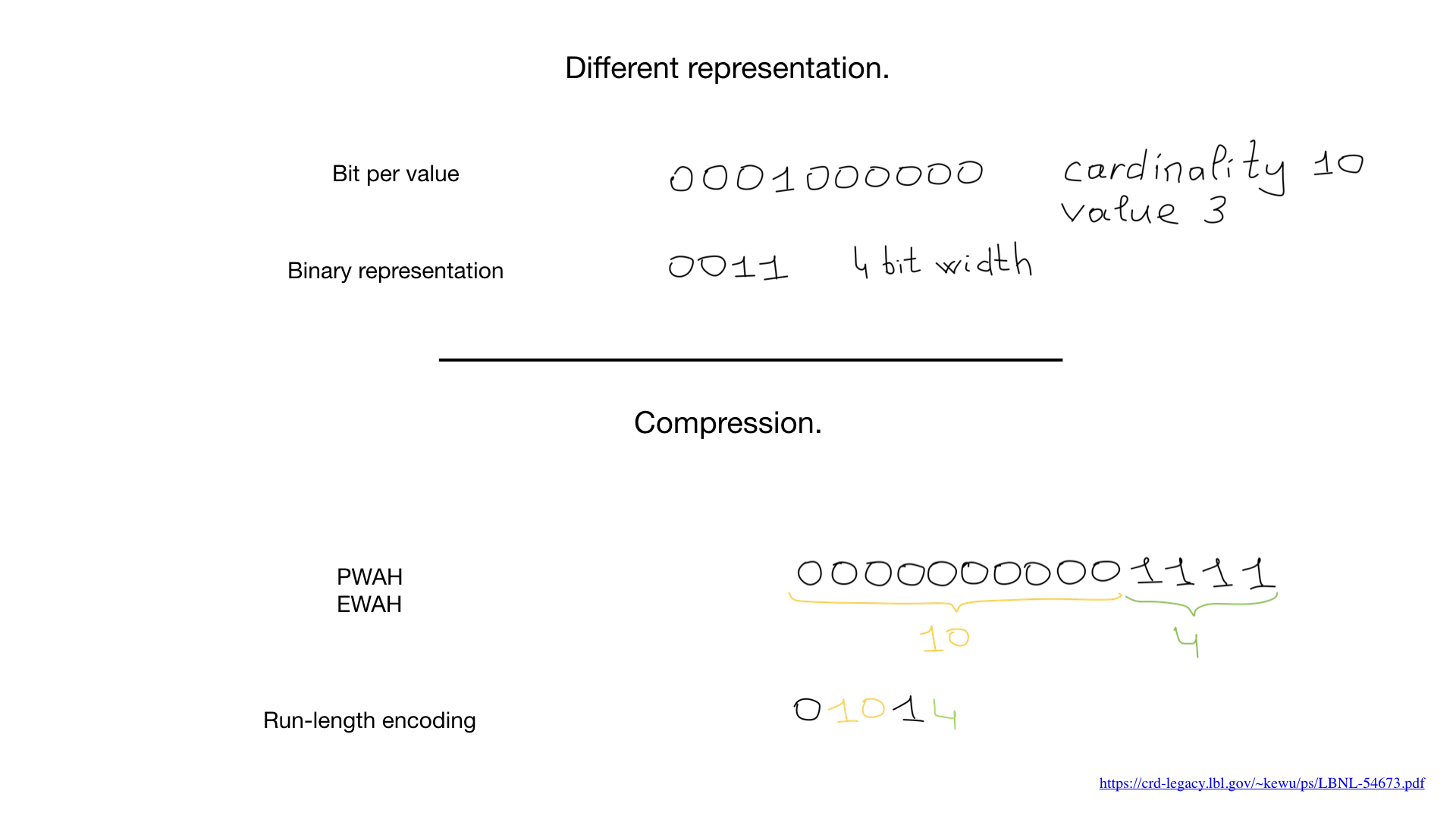
في بعض الأحيان ، يمكن استخدام تمثيل مختلف لهذه الحقول مثل تمثيل الأرقام الثنائية كما هو موضح هنا ، ولكن أكبر مبدل للألعاب هو الضغط. لقد توصل العلماء إلى خوارزميات ضغط مذهلة. تعتمد جميعها تقريبًا على خوارزميات طويلة المدى ، ولكن الأمر الأكثر إثارة للدهشة هو أننا لسنا بحاجة إلى إلغاء ضغط الصور النقطية من أجل القيام بعمليات bitwise عليها. تعمل عمليات bitwise العادية على الصور النقطية المضغوطة.

في الآونة الأخيرة ، رأينا الأساليب المختلطة تظهر مثل "الصور النقطية الهادرة". تستخدم الصور النقطية الهادرة ثلاثة تمثيلات منفصلة للصور النقطية: الصور النقطية والمصفوفات و "عمليات التشغيل الجزئي" وتوازن بين استخدام هذه العروض الثلاثة لزيادة السرعة وتقليل استخدام الذاكرة.
يمكن العثور على الصور النقطية الهادرة في بعض التطبيقات الأكثر استخدامًا على نطاق واسع وهناك تطبيقات للعديد من اللغات ، بما في ذلك العديد من التطبيقات لـ Go.
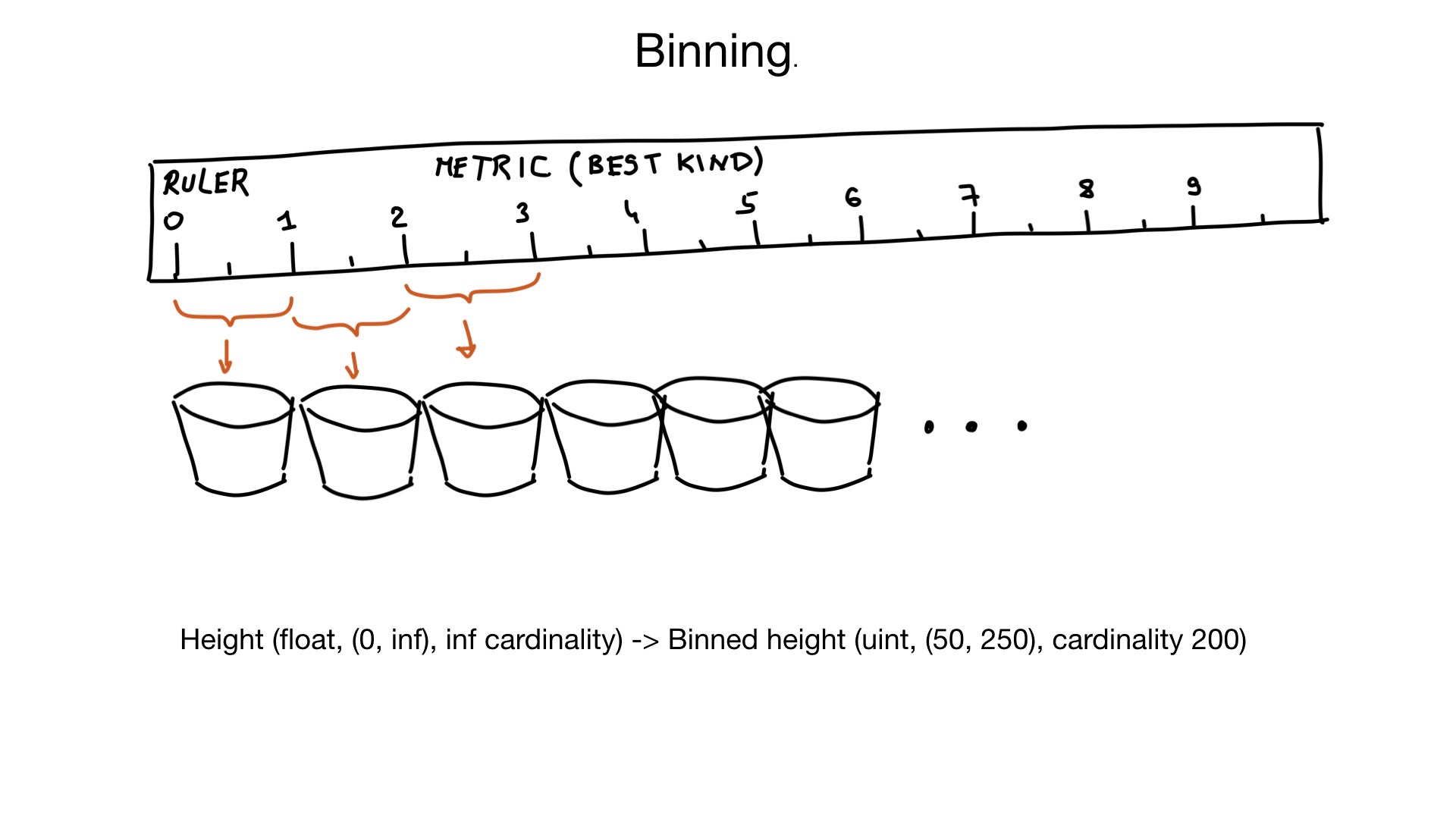
طريقة أخرى يمكن أن تساعد في حقول أصل عالية تسمى binning. تخيل أن لدينا حقل يمثل ارتفاع الشخص. الارتفاع تعويم ، لكننا لا نفكر في الأمر بهذه الطريقة. لا أحد يهتم إذا كان طولك 185.2 أو 185.3 سم. حتى نتمكن من استخدام "صناديق افتراضية" للضغط على ارتفاعات مماثلة في نفس الصندوق: صندوق 1 سم ، في هذه الحالة. وإذا افترضت أن هناك عددًا قليلًا جدًا من الأشخاص الذين يبلغ ارتفاعهم أقل من 50 سم ، أو أكثر من 250 سم ، يمكننا تحويل ارتفاعنا إلى الحقل بحوالي 200 عنصر أساسي ، بدلاً من أصل غير محدود تقريبًا. إذا لزم الأمر ، يمكننا أن نفعل تصفية إضافية على النتائج في وقت لاحق.
مشكلة الإنتاجية العالية
سبب آخر لسوء الفهرسة النقطية هو أنه قد يكون من المكلف تحديث الصور النقطية.
تقوم قواعد البيانات بالتحديثات وعمليات البحث بشكل متوازٍ ، لذلك يجب أن تكون قادرًا على تحديث البيانات بينما قد يكون هناك مئات مؤشرات الترابط تمر عبر الصور النقطية التي تقوم بالبحث. ستكون هناك حاجة إلى أقفال من أجل منع سباقات البيانات أو مشاكل تناسق البيانات. وحيث يوجد قفل كبير واحد ، يوجد خلاف في القفل.
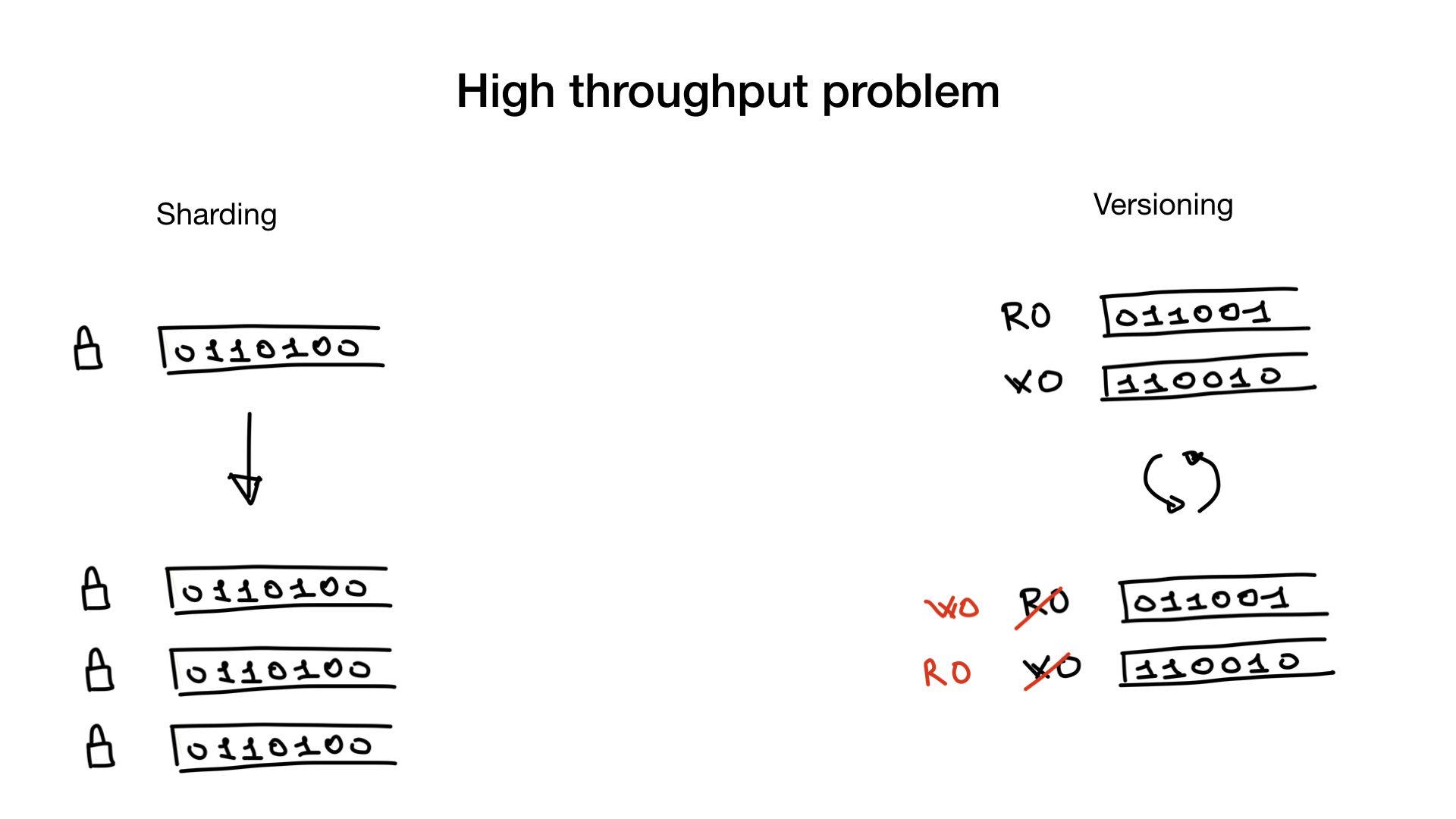
يمكن حل هذه المشكلة ، إذا كان لديك ، عن طريق مشاركة الفهارس أو عن طريق الحصول على إصدارات الفهرس ، إذا كان ذلك مناسبًا.
المشاركة واضحة. يمكنك مشاركتها كما تفعل مع مستخدمين في قاعدة بيانات والآن ، بدلاً من قفل واحد ، لديك أقفال متعددة تقلل إلى حد كبير من تنافسك على القفل.
هناك طريقة أخرى ممكنة في بعض الأحيان وهي وجود فهارس مُصدرة. لديك الفهرس الذي تستخدمه للبحث ولديك فهرس تستخدمه للكتابة والتحديثات. وقمت بنسخها وتبديلها بتردد منخفض ، على سبيل المثال 100 أو 500 مللي ثانية.
ولكن هذا النهج ممكن فقط إذا كان تطبيقك قادرًا على تحمل فهارس البحث التي لا معنى لها والتي لا معنى لها قليلاً.
بالطبع ، يمكن أيضًا استخدام هذين النهجين معًا. يمكن أن يكون لديك فهارس الإصدارات المظللة.
استفسارات غير تافهة
مشكلة أخرى في فهرس الصورة النقطية لها علاقة باستخدام مؤشرات الصور النقطية مع استعلامات النطاق. للوهلة الأولى ، لا يبدو أن عمليات bitwise مثل AND و OR مفيدة للغاية لاستفسارات النطاق مثل "أعطني غرف فندقية بتكلفة تتراوح من 200 إلى 300 دولار في الليلة".

يتمثل الحل الساذج وغير الفعال للغاية في الحصول على نتائج لكل نقطة سعر من 200 إلى 300 وإلى نتائج أو.

هناك طريقة أفضل قليلاً تتمثل في استخدام binning ووضع فنادقنا في نطاقات أسعار بعرض يتراوح من 50 دولارًا. سيؤدي هذا النهج إلى تقليل نفقات البحث بحوالي 50 مرة.
ولكن يمكن أيضًا حل هذه المشكلة بسهولة شديدة باستخدام ترميز خاص يجعل استعلامات النطاق ممكنة وسريعة. في الأدب ، تسمى الصور النقطية هذه الصور النقطية المشفرة بالنطاق.

في الصور النقطية المشفرة بالنطاق ، لا نضع فقط بتات محددة ، دعنا نقول ، القيمة 200 ، لكن نضبط كل البتات على 200 وأعلى. الشيء نفسه لمدة 300.
لذلك ، باستخدام هذا الاستعلام نطاق تمثيل الصورة النقطية المشفرة يمكن الرد عليها بتمريرين فقط خلال الصورة النقطية. نحصل على جميع الفنادق التي تكلف أقل من أو تساوي 300 دولار ، ونحذف من جميع الفنادق التي تكلف أقل من أو تساوي 199 دولار. القيام به.

ستكون مندهشًا ولكن حتى الاستعلامات الجغرافية ممكنة باستخدام الصور النقطية. تتمثل الحيلة في استخدام تمثيل مثل Google S2 أو ما شابه ذلك يرفق بإحداثيات في شكل هندسي يمكن تمثيله بثلاثة أو أكثر من الخطوط المفهرسة. إذا كنت تستخدم هذا التمثيل ، فيمكنك حينئذٍ تمثيل الاستعلام الجغرافي على هيئة العديد من استعلامات النطاق في فهارس الخطوط.
حلول جاهزة
حسنًا ، أتمنى أن أثير اهتمامك قليلاً. لديك الآن أداة أخرى تحت حزامك وإذا كنت بحاجة إلى تنفيذ شيء مثل هذا في خدمتك ، فستعرف المكان الذي تبحث عنه.
كل هذا جيد وجيد ، لكن ليس لدى الجميع الوقت والصبر والموارد لتنفيذ فهرس الصور النقطية خاصةً عندما يتعلق الأمر بأشياء أكثر تقدماً مثل تعليمات SIMD.
لا تخف ، فهناك منتجان مفتوحان المصدر يمكن أن يساعدك في مساعيك.

طافوا
أولاً ، هناك مكتبة ذكرتها بالفعل تسمى "الصور النقطية الهادرة". تطبق هذه المكتبة "حاوية" طافرة وجميع عمليات bitwise التي ستحتاج إليها إذا كنت ستقوم بتطبيق فهرس نقطي كامل.
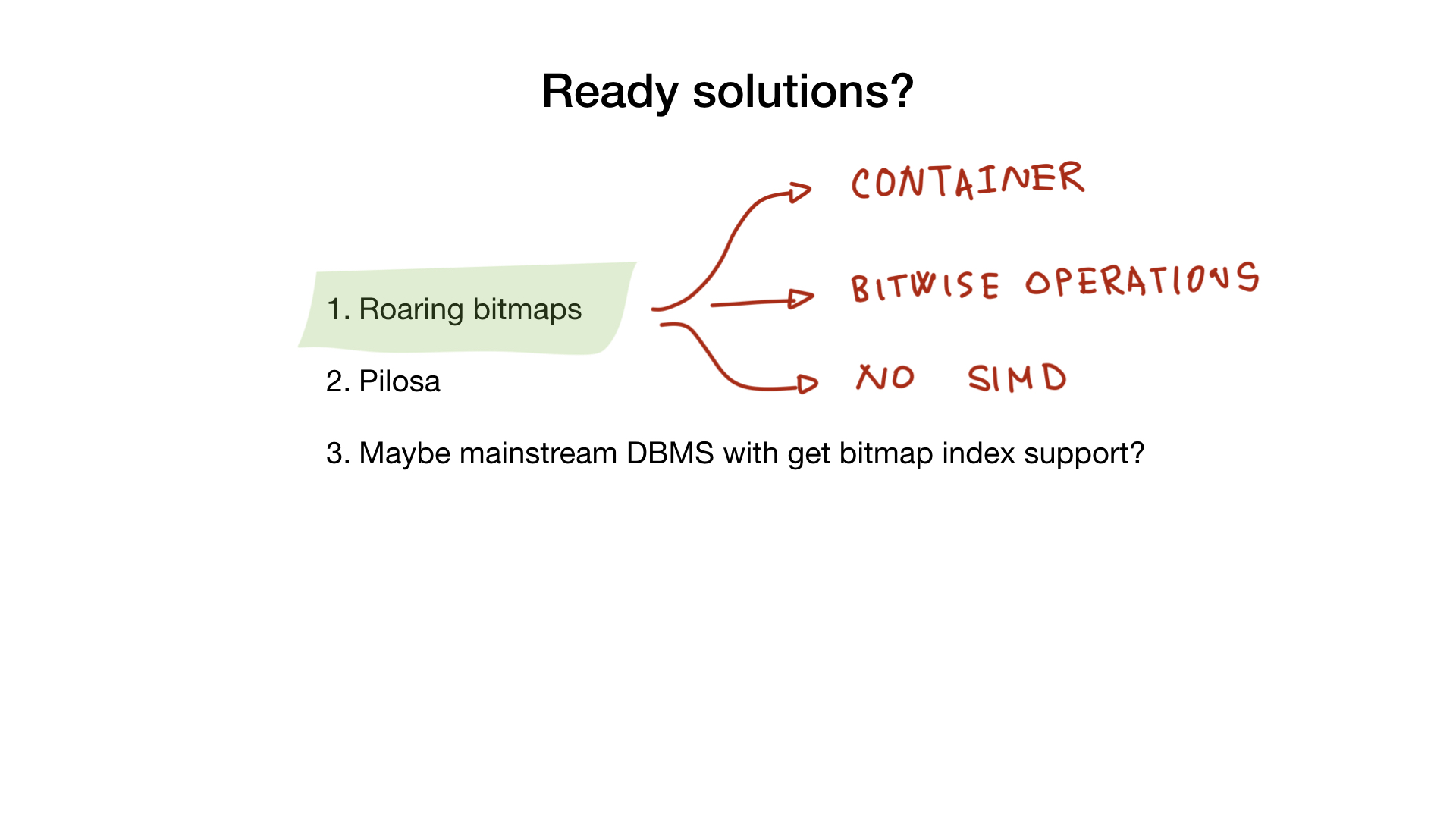
لسوء الحظ ، لا تستخدم تطبيقات go SIMD ، لذا فهي توفر أداء أقل إلى حد ما من تطبيق C ، على سبيل المثال.
ثدييات مشعرة
منتج آخر هو DBMS يسمى Pilosa يحتوي على فهارس الصورة النقطية فقط. إنه مشروع حديث ، لكنه اكتسب الكثير من الجر مؤخرًا.
E-d3BCvTn1CSSDr5Vj6W_9e5_GC1syQ9qSrwdS0 ">
يستخدم Pilosa الصور النقطية الهادرة أسفل ويعطي كل الأشياء التي كنت أخبرك بها أو يبسطها أو يفسرها تقريبًا: الصور النقطية المشفرة بنطاق النطاق ومفهوم الحقول وما إلى ذلك.
دعونا ننظر بإيجاز إلى مثال على Pilosa قيد الاستخدام ...

يشبه المثال الذي تراه تمامًا ما رأيناه سابقًا. نقوم بإنشاء عميل لخادم pilosa ، وإنشاء فهرس وحقول لخصائصنا. نحن نملأ الحقول ببيانات عشوائية مع بعض الاحتمالات كما فعلنا في وقت سابق ، ثم ننفذ استعلام البحث الخاص بنا.
ترى نفس النمط الأساسي هنا. غير مكلفة تتقاطع أو AND- إد مع شرفة وتتقاطع مع التحفظات.
والنتيجة كما هو متوقع.

وأخيرًا ، آمل أنه في وقت ما في المستقبل ، ستحصل قواعد البيانات مثل mysql و postgresql على نوع فهرس جديد: فهرس الصورة النقطية.

الكلمات الختامية

وإذا كنت لا تزال مستيقظًا ، أشكرك على ذلك. يعني قلة الوقت أنه كان علي أن أقوم بالكثير من الأشياء في هذا المنشور ، لكنني آمل أن يكون مفيدًا وربما ملهمًا.
تعد فهارس الصور النقطية شيئًا مفيدًا للتعرف عليها وفهمها حتى إذا لم تكن بحاجة إليها في الوقت الحالي. احتفظ بها كأداة أخرى في محفظتك.
خلال حديثي ، رأينا العديد من حيل الأداء التي يمكننا استخدامها والأشياء التي يصارعها Go في الوقت الحالي. هذه بالتأكيد أشياء يحتاج كل مبرمج Go إلى معرفتها.
وهذا هو كل ما لدي بالنسبة لك الآن. شكرا جزيلا لك