في تنفيذ ML حقيقي ، يستغرق التعلم بحد ذاته ربع الجهد. الفصول الثلاثة المتبقية هي إعداد البيانات من خلال الألم والبيروقراطية ، وهو نشر معقد في كثير من الأحيان في حلقة مغلقة دون الوصول إلى الإنترنت ، وإعداد البنية التحتية ، والاختبار والمراقبة. المستندات على مئات الأوراق ، والوضع اليدوي ، وتعارض إصدار النماذج ، والمصدر المفتوح ، والمشاريع القاسية - كل هذا ينتظر عالِم بيانات. لكنه لا يهتم بمثل هذه القضايا التشغيلية "المملة" ؛ فهو يريد تطوير خوارزمية وتحقيق جودة عالية ورد الجميل ولم يعد يتذكر.
ربما ، يتم تنفيذ ML في مكان ما بشكل أسهل وأبسط وأسرع وبزر واحد ، لكننا لم نر مثل هذه الأمثلة. كل ما سبق هو تجربة Front Tier في fintech والاتصالات. تحدث سيرغي فينوغرادوف ، وهو خبير في هندسة النظم المحملة للغاية ، في
المستودعات الكبيرة وتحليل البيانات الثقيلة ، عنه في
HighLoad ++ .

دورة حياة نموذجية
تتكون دورة الحياة في موضوعنا عادةً من ثلاثة أجزاء. في البداية
، تأتي المهمة من العمل . في الثانية ، يقوم
مهندس بيانات و / أو عالم بيانات بإعداد البيانات ، وبناء نموذج. في الجزء الثالث ، تبدأ
الفوضى . في آخر اثنين ، تحدث مواقف مثيرة للاهتمام مختلفة.
جاك لجميع المهن
أول موقف متكرر هو أن عالِم البيانات أو مهندس البيانات يمكنه الوصول إلى المنتجات ، لذلك يقولون له: "لقد فعلت كل هذا ، لقد راهنت عليه.
يأخذ الشخص جهاز
Jupyter Notebook أو مجموعة من دفاتر الملاحظات ، ويعتبرها بشكل حصري بمثابة أداة نشر ، ويبدأ في نسخها بسرور على بعض الخوادم.
كل شيء يبدو على ما يرام ، ولكن ليس دائما. سأخبرك لاحقا لماذا.
استغلال بلا رحمة
القصة الثانية أكثر تعقيدًا ، وعادة ما تحدث في الشركات التي بلغ فيها الاستغلال حالة من الجنون المعتدل. عالم البيانات يجلب حلها للعمل. يفتحون الصندوق الأسود ويرون شيئًا فظيعًا:
- أجهزة الكمبيوتر المحمولة.
- المخلل من إصدارات مختلفة.
- مجموعة من البرامج النصية: من غير الواضح أين ومتى يتم تشغيلها ، وأين يتم حفظ البيانات التي يقومون بإنشائها.
في هذا اللغز ، يواجه الاستغلال عدم توافق الإصدار. على سبيل المثال ، لم يحدد عالم البيانات إصدارًا محددًا من المكتبة ، واستغرقت العملية آخرها. بعد فترة من الوقت ، يلجأ عالم البيانات إلى:
- قمت بتعيين scikit- تعلم للإصدار الخاطئ ، والآن ذهبت جميع المقاييس! تحتاج إلى العودة إلى الإصدار السابق.هذا يكسر تماما همز ، والاستغلال يعاني.
بيروقراطية
في الشركات ذات الشعارات الخضراء ، عندما يبدأ عالم البيانات في العمل ويجلب النموذج ، يتلقى عادةً مستندًا سعة 800 ورقة ردًا: "اتبع هذه التعليمات ، وإلا فلن يشاهد منتجك أبدًا ضوء النهار".
يغادر عالم البيانات المحزن ويلقي كل شيء في منتصف الطريق ثم يستقيل - إنه غير مهتم بالقيام بذلك.
نشر
لنفترض أن عالم البيانات قد مر بجميع الدوائر وفي النهاية تم نشر كل شيء. لكنه لن يكون قادرًا على فهم أن كل شيء يعمل كما ينبغي. في تجربتي ، في نفس البنوك المباركة لا توجد مراقبة لمنتجات علم البيانات.
من الجيد أن يكتب المتخصص نتائج عمله في قاعدة البيانات. بعد فترة ، سوف يستقبلهم ويرى ما يحدث في الداخل. لكن هذا لا يحدث دائما. عندما يعتقد أحد رجال الأعمال وعالم البيانات ببساطة أن كل شيء يعمل بشكل جيد ورائع ، فإنه يترجم إلى حالات غير ناجحة.
MFI
بطريقة ما قمنا بتطوير محرك تسجيل لمؤسسة تمويل أصغر كبيرة. لم يسمحوا لهم بالذهاب إلى المنتج ، لكنهم ببساطة أخذوا سلسلة من النماذج منا وقاموا بتثبيتها وتشغيلها. نتائج اختبار النماذج راض لهم. لكن بعد 6 أشهر عادوا:
- كل شيء سيء. العمل لا يذهب ، نحن تزداد سوءا والأسوأ. يبدو أن الموديلات ممتازة ، لكن النتائج تتراجع والاحتيال والتقصير أكثر فأكثر وأقل من المال. ماذا دفعنا لك؟ هيا بناعلاوة على ذلك ، لا يعطى الوصول إلى النموذج مرة أخرى. تم تفريغ سجلات لمدة شهر ، علاوة على ذلك ، قبل ستة أشهر. لقد درسنا عملية التفريغ لمدة شهر آخر وتوصلنا إلى استنتاج مفاده أنه في مرحلة ما قام قسم تكنولوجيا المعلومات في مؤسسة التمويل الأصغر بتغيير بيانات الإدخال ، وبدلاً من المستندات في json ، بدأوا في إرسال المستندات بتنسيق xml. توقع الطراز json ، ولكنه تلقى xml ، حزينًا واعتقد أنه لا توجد بيانات عند الإدخال.
إذا لم تكن هناك بيانات ، يكون تقييم ما يحدث مختلفًا. بدون مراقبة ، لا يمكن اكتشاف ذلك.
نسخة جديدة ، تتالي والاختبارات
غالبًا ما نواجه حقيقة أن النموذج يعمل بشكل جيد ، ولكن لسبب
ما تم تطوير
نسخة جديدة . يحتاج النموذج مرة أخرى إلى إحضارها بطريقة ما ، ومرة أخرى للذهاب عبر جميع دوائر الجحيم. من الجيد أن تكون إصدارات المكتبة هي نفسها كما في النموذج السابق ، وإذا لم يكن الأمر كذلك ، فسيبدأ النشر من جديد ...
في بعض الأحيان ، قبل وضع إصدار جديد في المعركة ، نريد
اختباره - وضعه على المنتج ، والنظر في نفس تدفق المرور ، والتأكد من أنه جيد. هذا هو مرة أخرى سلسلة النشر الكامل. بالإضافة إلى ذلك ، أنشأنا الأنظمة بحيث وفقًا لهذا النموذج ، لا تحدث نتائج حقيقية ، إذا كان الأمر يتعلق بالتسجيل ، ولكن كان هناك فقط مراقبة وتحليل النتائج لمزيد من التحليل.
هناك حالات عندما
يتم استخدام سلسلة من النماذج. عندما تعتمد نتائج النماذج التالية على النماذج السابقة ، فإنك تحتاج بطريقة ما إلى إقامة تفاعل فيما بينها وفي مكان ما مرة أخرى ، يجب حفظ كل هذا.
كيفية حل مثل هذه المشاكل؟
غالبًا ما يقوم شخص واحد بحل المشكلات
يدويًا ، خاصة في الشركات الصغيرة. إنه يعرف كيف يعمل كل شيء ، ويضع في اعتباره جميع إصدارات النماذج والمكتبات ، ويعرف أين تعمل البرامج النصية ، وأي واجهات المتاجر التي يبنونها. هذا كل شيء رائع. جميلة بشكل خاص هي القصص التي يتركها الوضع اليدوي.
قصة الميراث . رجل طيب يعمل في بنك صغير واحد. ما إن ذهب إلى دولة جنوبية ولم يعد. بعد ذلك ، حصلنا على الميراث: مجموعة من التعليمات البرمجية التي تنشئ واجهات المتاجر التي تعمل عليها النماذج. الشفرة جميلة ، لكنها تعمل ، لكننا لا نعرف الإصدار الدقيق للنص البرمجي الذي ينشئ واجهة العرض هذه أو تلك. في المعركة ، توجد جميع نوافذ المتاجر ، ويتم إطلاقها جميعًا. لقد أمضينا شهرين في محاولة لإيجاد هذا التشابك المعقد وبنيته بطريقة ما.
في مشروع قاسٍ ، لا يريد الناس أن يزعجوا كل أنواع بيثون والمشتريين ، إلخ. يقولون:
- دعنا نشتري IBM SPSS ، التثبيت وكل شيء سيكون رائعا. مشاكل في الإصدار ، مع مصادر البيانات ، مع النشر هناك حل بطريقة أو بأخرى.هذا النهج له الحق في الوجود ، لكن لا يستطيع الجميع تحمله. في أي حال ، هذه إبرة مسننة عالية الجودة. يجلسون عليها ، لكنها لا تعمل من أجل الخروج - الشقوق. وعادة ما يكلف الكثير.
المصدر المفتوح هو عكس النهج السابق. تصفح المطورون الإنترنت ، ووجدوا الكثير من الحلول مفتوحة المصدر التي تحل مهامهم بدرجات متفاوتة. هذه طريقة رائعة ، ولكن لأنفسنا لم نجد حلولًا تلبي متطلباتنا بنسبة 100٪.
لذلك ، اخترنا الخيار الكلاسيكي -
قرارنا . العكازات ، والدراجات ، وجميع خاصة بهم ، الأم.
ماذا نريد من قرارنا؟
لا تكتب كل شيء بنفسك . نريد أن نأخذ مكونات ، خاصة مكونات البنية التحتية ، التي أثبتت جدارتها جيدًا ولديها دراية بالعمل في المؤسسات التي نعمل معها. نكتب فقط بيئة من شأنها عزل عمل عالم البيانات بسهولة عن عمل DevOps.
معالجة البيانات في وضعين: كلاهما في وضع الدُفعات - الدفعي ، والوقت الحقيقي . تشمل مهامنا كلا أوضاع التشغيل.
سهولة النشر ، وفي محيط مغلق . عند العمل مع البيانات الخاصة الحساسة ، لا يوجد اتصال بالإنترنت. في هذا الوقت ، يجب أن يصل كل شيء بسرعة وبدقة إلى الإنتاج. لذلك ، بدأنا نتطلع إلى Gitlab ، خط أنابيب CI / CD بداخله و Docker.
النموذج ليس غاية في حد ذاته. نحن لا نحل مشكلة بناء نموذج ، نحن نحل مشكلة العمل.
داخل خط الأنابيب ، يجب أن تكون هناك قواعد ومجموعة من النماذج مع دعم
لإصدار جميع مكونات خطوط الأنابيب.
ما المقصود بخط أنابيب؟ في روسيا ، يسري القانون الاتحادي رقم 115 بشأن مكافحة غسل الأموال وتمويل الإرهاب. فقط جدول محتويات توصيات البنك المركزي يحتل 16 شاشة. هذه هي القواعد البسيطة التي يمكن للبنك الوفاء بها إذا كان لديه مثل هذه البيانات ، أو لا يمكن إذا لم يكن لديه بيانات.
يعد تقييم المقترض أو المعاملة المالية أو العمليات التجارية الأخرى مجموعة من البيانات التي نعالجها. يجب أن يمر تيار من خلال هذا النوع من القاعدة. يتم وصف هذه القواعد بطريقة سهلة من قبل المحلل. إنه ليس عالم بيانات ، لكنه يعرف القانون أو التعليمات الأخرى جيدًا. يجلس المحلل ويصف بلغة واضحة الشيكات الخاصة بالبيانات.
بناء مجموعات من النماذج . غالبًا ما ينشأ موقف عندما يستخدم النموذج التالي لعمله القيم التي تم الحصول عليها في النماذج السابقة.
اختبار الفرضيات بسرعة. أكرر الأطروحة السابقة: قام عالم بيانات بعمل نموذج ما ، يدور في المعركة ويعمل بشكل جيد. لسبب ما ، توصل الاختصاصي إلى حل أفضل ، لكنه لا يريد أن يدمر سير العمل الثابت. يقوم عالم البيانات بتعليق نموذج جديد على نفس حركة القتال في نظام القتال. إنها لا تشارك مباشرة في صنع القرار ، لكنها تخدم نفس الحركة ، وتأخذ في الاعتبار بعض الاستنتاجات ويتم تخزين هذه الاستنتاجات في مكان ما.
ميزة سهلة إعادة الاستخدام. تحتوي العديد من المهام على نفس النوع من المكونات ، خاصة تلك المتعلقة باستخراج الميزات أو القواعد. نريد سحب هذه المكونات إلى خطوط أنابيب أخرى.
ماذا قررت أن تفعل؟
أولا نريد الرصد. واثنان من نوعه.
مراقبة
المراقبة الفنية. إذا تم نشر أي مكونات لخطوط الأنابيب ، فعليهم أن يروا ما يحدث للمكون: كيف يستهلك الذاكرة ، وحدة المعالجة المركزية ، القرص.
مراقبة الأعمال. هذه أداة لعالم البيانات تتيح لك الاستخلاص من الفروق التقنية للتنفيذ. على مستوى التصميم ، يساعد الإنشاء في تحديد مقاييس النموذج التي يجب أن تكون متوفرة في المراقبة ، على سبيل المثال ، توزيع ميزة أو نتائج خدمة تسجيل النتائج.
يعرف عالم البيانات المقاييس ويجب ألا يقلق بشأن كيفية دخولهم إلى نظام المراقبة. الشيء الوحيد المهم هو أنه حدد هذه المقاييس ومظهر لوحة القيادة التي سيتم عرض المقاييس عليها. ثم أطلق المتخصص كل شيء على الإنتاج ، ونشر ، وبعد فترة تدفقت المقاييس في المراقبة. لذلك يمكن لعالم البيانات دون الوصول إلى المنتج معرفة ما يحدث داخل النموذج.
تجريب
اختبار
خط أنابيب لتحقيق الاتساق . بالنظر إلى تفاصيل خط الأنابيب ، هذا هو نوع من الرسم البياني للحوسبة. نريد أن نفهم أننا نطبق رسمًا بيانيًا ، يمكننا تجاوزه وإيجاد طريقة للخروج منه.
الرسم البياني يحتوي على مكونات - وحدات. يجب على جميع الوحدات اجتياز اختبار الوحدة والتكامل. يجب أن تكون العملية شفافة وسهلة لعالم البيانات.
يصف المطور النموذج والاختبارات من تلقاء نفسه أو بمساعدة شخص آخر. يضع كل شيء في Gitlab ، خط الأنابيب الذي تم تكوينه بواسطة التكامل المستمر يثير ويختبر ويرى النتائج. إذا كان كل شيء جيدًا - فقد ذهب أبعد من ذلك ، لا - يبدأ من جديد.
يركز عالم البيانات على النموذج ولا يعرف ما هو تحت الغطاء. لهذا ، أعطيت له عدة أشياء.
- واجهة برمجة تطبيقات للتكامل مع جوهر النظام نفسه عبر ناقل البيانات - ناقل الرسالة. في هذه الحالة ، يحتاج المختص إلى وصف ما يجري وما يخرج من نموذجه ونقطة الدخول والتقاطع مع المكونات المختلفة داخل خط الأنابيب.
- بعد تدريب النموذج ، يظهر قطعة أثرية - ملف XGBoost أو ملف مخلل . يمتلك عالم البيانات منفذاً للعمل مع القطع الأثرية - يجب عليه دمج مكونات خطوط الأنابيب في الداخل.
- واجهة برمجة تطبيقات سهلة وشفافة لعالم البيانات لمراقبة تشغيل مكونات خطوط الأنابيب - المراقبة الفنية والتجارية.
- بنية أساسية بسيطة وشفافة للتكامل مع مصادر البيانات والحفاظ على نتائج العمل.
غالبًا ما تعمل النماذج لصالحنا ، وبعد فترة تصل عملية التدقيق التي تريد رفع تاريخ الخدمة بالكامل. التدقيق يريد التحقق من صحة العمل ، وعدم وجود احتيال من جانبنا. هناك حاجة إلى أدوات بسيطة حتى يتمكن أي مدقق يعرف SQL من الدخول إلى مستودع خاص ومعرفة كيفية عمل كل شيء ، وما هي القرارات التي اتخذت ولماذا.
وضعنا الأساس لقصتين مهمتين بالنسبة لنا.
رحلة العملاء. هذه فرصة لاستخدام آليات الحفاظ على تاريخ العميل بالكامل - ما حدث للعميل كجزء من العمليات التجارية التي يتم تنفيذها على هذا النظام.
قد يكون لدينا مصادر بيانات خارجية ، على سبيل المثال ، منصات DMP. من بينهم نحصل على معلومات حول السلوك البشري على الشبكة وفي الأجهزة المحمولة. هذا قد يكون له تأثير على نموذجه LTV ونماذج التهديف. إذا تأخر المقترض في السداد ، يمكننا أن نتوقع أن هذه ليست نية خبيثة - فهناك ببساطة مشاكل. في هذه الحالة ، نطبق طرقًا لينة للتعرض للمقترض. عندما يتم حل المشكلات ، يقوم العميل بإغلاق القرض. عندما يأتي في المرة القادمة ، سوف نعرف قصته كلها. سيحصل عالم البيانات على سجل مرئي من النموذج وإجراء تسجيل في وضع الضوء.
تحديد الحالات الشاذة . نحن نواجه باستمرار عالم معقد للغاية. على سبيل المثال ، يمكن أن تكون النقاط الضعيفة ضمن التقييم المتسارع لمؤسسات التمويل الأصغر مصدراً للاحتيال التلقائي.
رحلة العملاء هي مفهوم الوصول السريع والسهل إلى دفق البيانات الذي يمر عبر النموذج. يسهل النموذج اكتشاف الحالات الشاذة التي تميز الغش في وقت حدوثها الجماعي.
كيف يتم ترتيب كل شيء؟
وبدون تردد ، اتخذنا تطبيق
كافكا كتصحيح للرسالة. هذا هو الحل الجيد الذي يستخدمه العديد من عملائنا ، العملية قادرة على العمل معها.
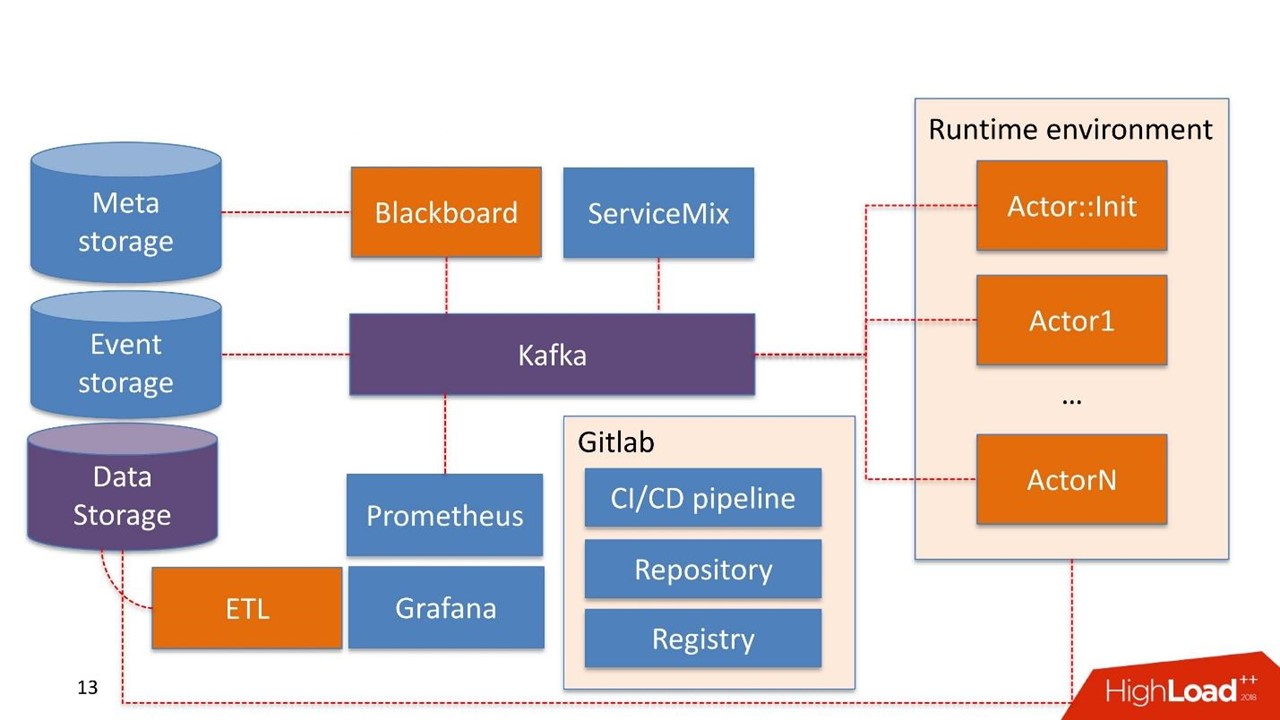
قد يتم بالفعل استخدام بعض مكونات النظام في الشركة نفسها. نحن لا نبني النظام مرة أخرى ، ولكننا نعيد استخدام ما لديهم بالفعل.
تخزين البيانات في هذه الحالة هو وحدة التخزين التي عادة ما يكون لدى العميل بالفعل. يمكن أن يكون Hadoop ، قواعد البيانات العلائقية وغير العلائقية. يمكننا العمل أصلاً خارج نطاق اللعبة مع HDFS و Hive و Impala و Greenplum و PostgreSQL. نعتبر هذه المخازن مصدرًا لنوافذ المتاجر.
تصل البيانات إلى المستودع ، وتمر عبر ETL أو ETL للعميل ، إذا كان لديه واحد. نحن نبني نوافذ المتاجر التي يتم استخدامها داخل النماذج. يتم استخدام تخزين البيانات في وضع القراءة فقط.
تطوراتنا
السبورة. الاسم مأخوذ من ممارسة غريبة نوعا ما لعلماء الرياضيات من 30-40. هذا هو مدير خطوط الأنابيب الذين يعيشون في نظام المسؤول. يحتوي Blackboard على نوع من التخزين الفوقية. يخزن خطوط الأنابيب نفسها والتكوينات اللازمة لتهيئة جميع المكونات.
كل عمل النظام يبدأ بـ Blackboard. بعض المعجزة ، انتهى خط الأنابيب في Meta Storage ، Blackboard بعد حين يفهم ذلك ، يسحب الإصدار الحالي من خط الأنابيب ، ويهيئه ويرسل إشارة داخل Kafka.
هناك
بيئة وقت التشغيل . إنه مبني على Dockers ويمكن نسخه على خوادم ، بما في ذلك في السحابة الخاصة بالعميل.
خارج الصندوق يأتي
الممثل الرئيسي
:: التهيئة - هذا هو المُهيئ. هذا هو الجني الذي يمكن أن يفعل شيئين فقط:
بناء وتدمير المكونات . يتلقى أمرًا من Blackboard: "هنا هو خط الأنابيب ، يجب تشغيله على مثل هذه الخوادم ومثل هذه الموارد ومثل هذه الكميات ومثل هذه الكميات - العمل!" ثم الممثل يبدأ كل شيء.
من الناحية الرياضية ، يمثل الفاعل وظيفة تأخذ كائنًا واحدًا أو أكثر كمدخلات ، أو تغير حالة الكائنات باستخدام خوارزمية في الداخل ، أو ينشئ كائنًا جديدًا في الإخراج ، أو يغير حالة كائن موجود.
من الناحية الفنية ، الممثل هو برنامج بيثون. يعمل في حاوية Docker مع بيئته.
الممثل لا يعرف عن وجود جهات فاعلة أخرى. الكيان الوحيد الذي يعرف أنه بالإضافة إلى الفاعل موجود كامل خط أنابيب ككل - وهذا هو السبورة. يراقب حالة تنفيذ جميع الجهات الفاعلة داخل النظام ويحافظ على الحالة الراهنة ، والتي يتم التعبير عنها في المراقبة كصورة لعملية الأعمال بأكملها ككل.
ممثل :: Init يولد العديد من حاويات دوكر. بالإضافة إلى ذلك ، يمكن للجهات الفاعلة العمل مع تخزين البيانات.
يحتوي النظام نفسه على مكون "
تخزين الأحداث" . كما تخزين الأحداث نستخدم
ClickHouse . مهمتها بسيطة: يتم تخزين جميع المعلومات المتبادلة بين الممثل من خلال كافكا في ClickHouse. يتم ذلك
لمزيد من التدقيق . هذا هو سجل تشغيل خط الأنابيب.
يمكن أيضًا تطوير الممثلين
لرحلة العملاء . يرون تغييرات في سجل خط الأنابيب ، ويمكنهم على الفور إعادة إنشاء النوافذ اللازمة للنماذج أو المكونات للعمل مع القواعد ، بالفعل داخل خط الأنابيب. هذه عملية مستمرة لتغيير البيانات.
المراقبة مبنية بشكل
أساسي على
بروميثيوس . يحصل الممثل على واجهة برمجة تطبيقات أساسية ، وفي وضع مغلق ، ولكنه شفاف بما يكفي للمطور ، يرسل رسائل مع المقاييس إلى كافكا. تقوم بروميثيوس بقراءة المقاييس من كافكا وحفظها في مستودعها.
للتصور نستخدم
Grafana .
نقطتين للتكامل
الأول هو نقطة التكامل مع مصادر البيانات التي تمر عبر ETLs إلى مستودع البيانات. النقطة الثانية للتكامل عندما يتم استخدام خدمة بالفعل من قبل مستهلك البيانات ، على سبيل المثال ، خدمة تسجيل.
أخذنا
اباتشي ServiceMix. من التجربة ، تكون نقاط التكامل هذه من نفس النوع مع نفس النوع من البروتوكولات: SOAP ، RESTful ، وقوائم الانتظار الأقل تكرارًا. في كل مرة لا نريد تطوير مُنشئنا أو خدمتنا من أجل إنشاء خدمة SOAP التالية. لذلك ، نأخذ ServiceMix ، صفه في SDL ، حيث يتم إنشاء نماذج البيانات لهذه الخدمة والأساليب الموجودة فيها. ثم ندفع من خلال جهاز التوجيه داخل ServiceMix ، ويقوم بإنشاء الخدمة نفسها.
من أنفسنا ، أضفنا تحويل صعبة متزامن غير متزامن. جميع الطلبات التي تعيش داخل النظام غير متزامنة وتذهب عبر Message Bus.
معظم خدمات التسجيل متزامنة. تأتي طلبات ServiceMix عبر REST أو SOAP. في هذه المرحلة ، يمر عبر بوابتنا ، التي تحتفظ بمعرفة جلسة HTTP. ثم يرسل رسالة إلى كافكا ، يمر عبر بعض خطوط الأنابيب ، ويتم إنشاء حل.
ومع ذلك ، قد لا يزال هناك حل. على سبيل المثال ، حدث شيء ما ، أو كان هناك جيش تحرير السودان صعب لاتخاذ قرار ، ومراقبو Gateway: "حسنًا ، لقد تلقيت طلبًا ، أوصلني إلى موضوع كافكا آخر ، أو لم يصلني شيء ، لكن تم تشغيل برنامج المهلة." ثم مرة أخرى ، يذهب تحويل متزامن إلى غير متزامن ، وفي نفس جلسة HTTP ، هناك استجابة للمستهلك نتيجة العمل. قد يكون هذا خطأ أو توقعات طبيعية.
في هذا المكان ، بالمناسبة ، أكلنا كلبًا لا طعم له بفضل المصدر المفتوح الكبير والقوي. استخدمنا ServiceMix من واحد من أحدث الإصدارات ، و كافكا من الإصدارات السابقة وعملت كل شيء تماما. لقد كتبنا في هذه البوابة ، بناءً على تلك المكعبات التي كانت موجودة بالفعل في ServiceMix. عندما خرجت النسخة الجديدة من كافكا ، استحوذنا عليها بسعادة ، لكن اتضح أن دعم الرؤوس الموجودة في الرسالة الموجودة في كافكا قد تغير. العبارة داخل ServiceMix لم تعد قادرة على العمل معهم. لفهم هذا ، قضينا الكثير من الوقت. نتيجة لذلك ، قمنا ببناء بوابتنا ، والتي يمكن أن تعمل مع الإصدارات الجديدة من كافكا. لقد كتبنا عن المشكلة إلى مطوري ServiceMix وتلقينا الإجابة: "شكرًا لك ، سنساعدك بالتأكيد في الإصدارات القادمة!"
لذلك ، نحن مضطرون لمراقبة التحديثات وتغيير شيء بانتظام.
البنية التحتية هي Gitlab. نحن نستخدم كل شيء تقريبا فيه.
- مستودع الكود.
- تواصل التكامل / تواصل خط أنابيب التسليم.
- سجل للحفاظ على سجل حاويات دوكر.
المكونات
لقد قمنا بتطوير 5 مكونات:
- السبورة - إدارة دورة حياة خط الأنابيب. أين وماذا ومع ما المعلمات لتشغيل من خط الأنابيب.
- يعمل مستخرج الميزات ببساطة - نعلم مستخرج الميزات أننا نحصل على مثل هذا النموذج البيانات عند الإدخال ، وحدد الحقول اللازمة من البيانات ، وقم بتعيينها على قيم معينة. على سبيل المثال ، نحصل على تاريخ ميلاد العميل ، ونحوله إلى عصر ، ونستخدمه كميزة في نموذجنا. مستخرج الميزات هو المسؤول عن تخصيب البيانات.
- المحرك القائم على القاعدة - التحقق من البيانات وفقا للقواعد. هذه لغة وصف بسيطة تتيح لشخص مطلع على بناء <code> إذا ، كتل <code /> أخرى لوصف قواعد التدقيق داخل النظام.
- محرك التعلم الآلي - يتيح لك تشغيل المنفذ ، وتهيئة النموذج المدربين وإرساله إلى بيانات الإدخال. في الإخراج ، يأخذ النموذج البيانات.
- محرك القرار - محرك القرار ، والخروج من الرسم البياني. بوجود سلسلة من النماذج ، على سبيل المثال ، فروع مختلفة من تقييم المقترض ، عليك أن تقرر مسألة المال في مكان ما. يجب أن تكون مجموعة قواعد الحل بسيطة. , LTV- — , , .
. — , . — , .
pipeline .
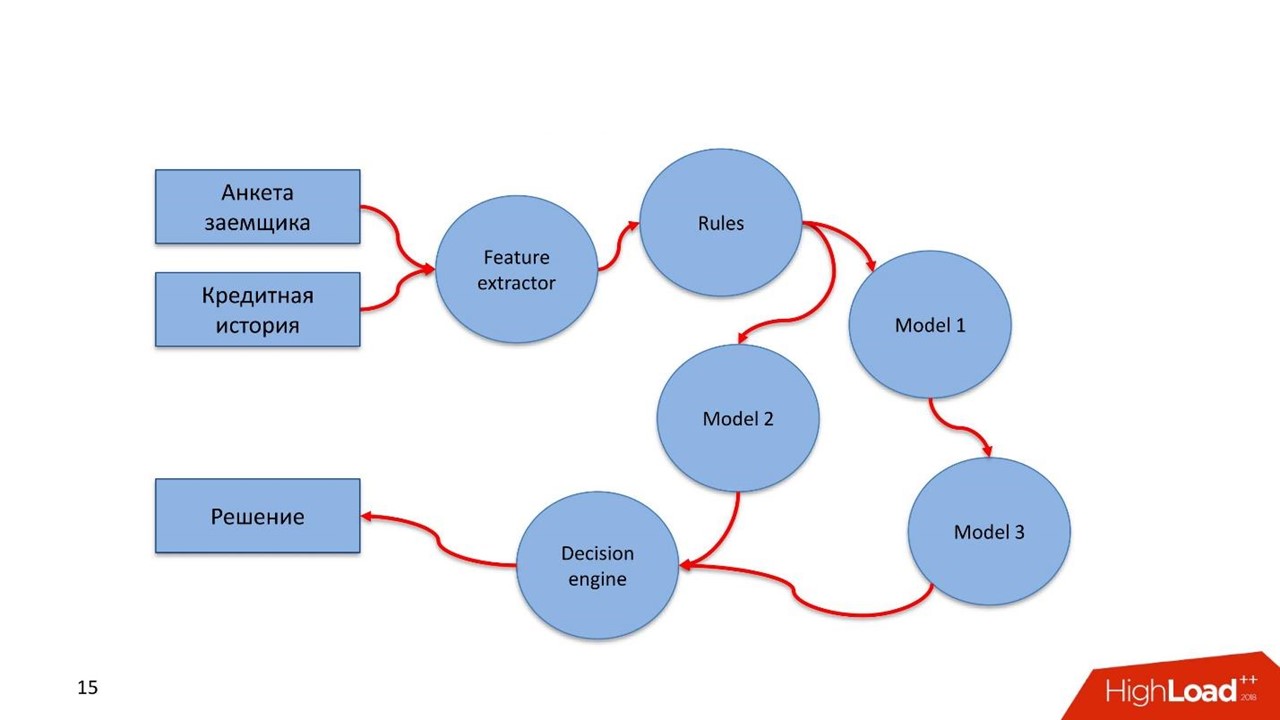
- Feature extractor : , , .
- . , -: , , 18.
- . , . , , pipeline.
- Decision engine . .
- .
yaml. . , , . yaml.
pipeline, , : feature extractor, rules, models, decision engine, . —
Docker- . Registry, Docker-. -, , . , , Docker- .
خط أنابيب
,
Python — . Feature extractor, , decision engine Python.
Pipeline
yaml. meta storage —
.
Runtime environment 10 , Blackboard , pipeline 10 . , : , , IP- Kafka, , . .
GitLab. Ansible. , . , 50 000 Ansible .
?
GitLab pipeline. GitLab. CI , , , .
GitLab Runner , Docker- , pipeline. — Registry.
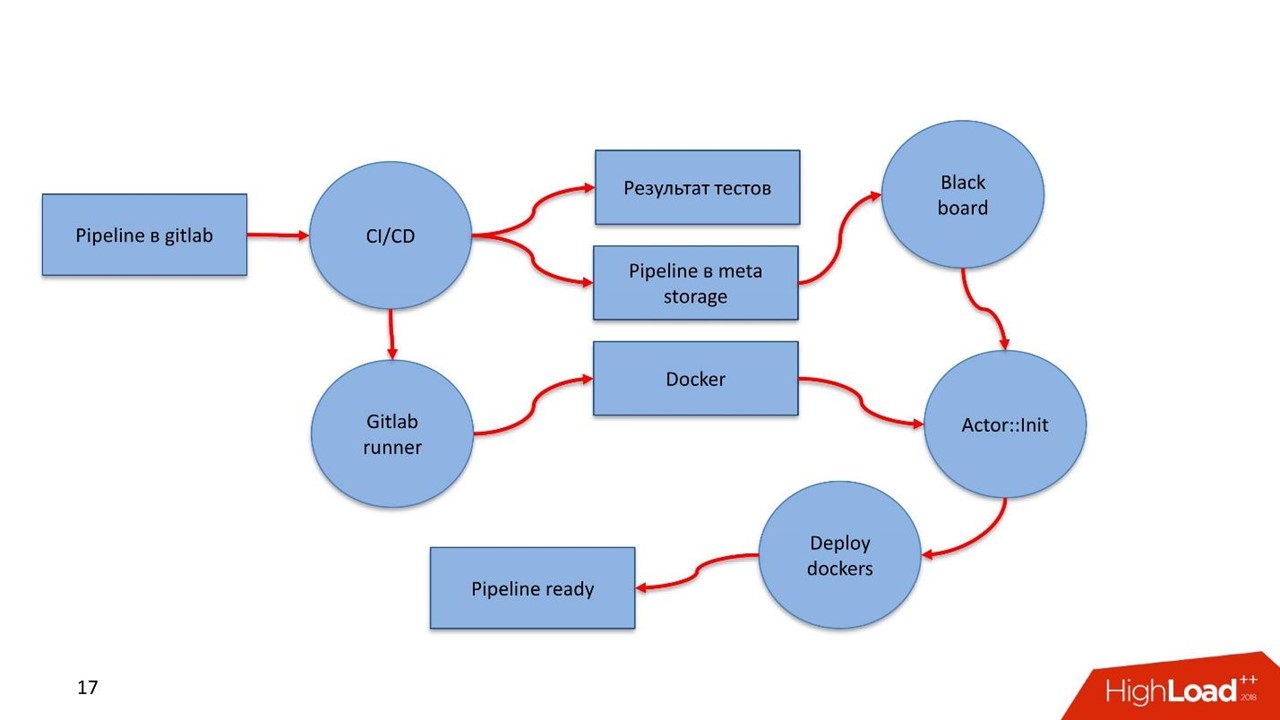
Docker , . Docker- . CI pipeline pipeline - Meta Storage, Blackboard.
Blackboard Meta Storage — , , , -. Docker- , , .
- Blackboard Meta Storage : , Kafka, . , , Docker- , .
, Docker-, — pipeline !
DigitalOcean. AWS Scaleway, .
, . pipeline . , .
?
— . , pipeline, real-time .
- 2 Feature extractor . 1 , .. json .
- 8 — 8 ML engine. XGBoost.
- 18 RB engine (115 ). 1000 .
- 1 decision engine.
200 . 2 Feature extractor, 8 , 18 1 decision engine 1,2 .
Discovery . , - . , , . . Meta Storage.
pipeline . ,
BPM . yaml , , .
. Java, Scala, R. Python, , . API , pipeline .
ما هي النتيجة؟
— . — .
, . , . — 2018 .
, . — , , .
, . , , notebook , .
, - , , . , , UseData Conf . , , , 16 .