كلما زاد عدد مستخدمي خدمتك ، زاد احتمال احتياجهم إلى المساعدة. تعد الدردشة بالدعم الفني حلاً واضحًا ولكنه مكلف إلى حد ما. ولكن إذا كنت تستخدم تقنية التعلم الآلي ، فيمكنك توفير بعض المال.
يستطيع الروبوت الآن الإجابة على أسئلة بسيطة. علاوة على ذلك ، يمكن تعليم chatbot تحديد نوايا المستخدم والتقاط السياق حتى يتمكن من حل معظم مشكلات المستخدمين دون تدخل بشري. كيف يمكن القيام بذلك ، سيساعد فلاديسلاف بلينوف وفاليري بارانوفا ، مطورو المساعد الشهير أوليغ ، في تحديد الأمر.
بالانتقال من الأساليب البسيطة إلى الأساليب الأكثر تعقيدًا في مهمة تطوير روبوت الدردشة ، سنحلل مشكلات التنفيذ العملية ونرى ما هي مكاسب الجودة التي يمكنك الحصول عليها ومقدار التكلفة.
فلاديسلاف بلينوف هو أحد كبار مطوري أنظمة الحوار في
تينكوف ، وغالبًا ما يلقي الاختصارات: ML ، NLP ، DL ، إلخ. بالإضافة إلى ذلك ، تفحص مدرسة الدراسات العليا نمذجة الفكاهة من خلال التعلم الآلي والشبكات العصبية.
تكتب
فاليريا بارانوفا أشياء رائعة في حقل البرمجة اللغوية العصبية في بيثون لأكثر من 5 سنوات. الآن ، في فريق الأنظمة التفاعلية ، يقوم Tinkoff بإنشاء برامج الدردشة ويقوم بتدريس دورة "التعلم الآلي" للطلاب. وهو يشارك أيضًا في الأبحاث في مجال الفكاهة الحسابية ، أي أنه يعلم منظمة العفو الدولية أن يفهم النكات ويأتي بأخرى جديدة -
سوف تتحدث فاليريا وفلاديسلاف عن هذا الأمر في UseData Conf.
يتم استخدام خدمات Tinkoff Bank بواسطة ملايين الأشخاص. لتوفير دعم على مدار الساعة لمثل هذا العدد من المستخدمين ، هناك حاجة إلى عدد كبير من الموظفين ، مما يؤدي إلى ارتفاع تكلفة الخدمة. يبدو من المنطقي أن الأسئلة الشائعة للمستخدمين يمكن الإجابة عليها تلقائيًا باستخدام روبوت الدردشة.
نية المستخدم أو النية
أول شيء يحتاجه chatbot هو فهم
ما يريده المستخدم . هذه المهمة تسمى تصنيف النوايا أو النوايا. علاوة على ذلك ، سيتم النظر في جميع النماذج والنهج في إطار هذه المهمة.
دعونا نلقي نظرة على مثال لتصنيف النوايا. إذا كتبت: "نقل مئات من Lera" ، فستدرك روبوت الدردشة Oleg أن هذا هو القصد من تحويل الأموال ، أي نية المستخدم لتحويل الأموال. أو بالأحرى ، يحتاج Lera إلى نقل مبلغ 100 روبل.
سنقارن الطرق ونختبر جودة عملهم على عينة اختبار ، والتي تتكون من مربعات حوار حقيقية مع المستخدمين. يحتوي نموذجنا على أكثر من 30000 مثال واضح و 170 نية ، على سبيل المثال: الذهاب إلى السينما ، البحث عن المطاعم ، فتح أو إغلاق إيداع ، إلخ. لدى Oleg أيضًا رأيه الخاص بشأن الكثير ، ويمكنه فقط الدردشة معك.
تصنيف القاموس
أبسط شيء يمكن القيام به في مهمة تصنيف الأهداف هو
استخدام القاموس . على سبيل المثال ، إذا ظهرت كلمة "ترجم" في عبارة المستخدم ، فاعتبر أنه يجب إجراء تحويل الأموال.
دعونا نلقي نظرة على نوعية هذا النهج البسيط.
إذا كان المصنف يعرف ببساطة نية المستخدم على أنها "تحويل الأموال" بكلمة "ترجم" ، فستكون الجودة عالية بالفعل. الدقة - 88 ٪ ، في حين أن اكتمال منخفضة ، أي ما يعادل 23 ٪ فقط. هذا أمر مفهوم: لا تعني كلمة "ترجم" كل الاحتمالات لقول "تحويل الأموال إلى شخص ما".
ومع ذلك ، فإن هذا النهج له مزايا:
- لا حاجة لأخذ العينات المسمى (إذا كنت لا تدرس النموذج ، فلا حاجة لأخذ العينات).
- يمكنك الحصول على دقة عالية إذا قمت بترجمة القواميس جيدًا (لكن ذلك سيستغرق بعض الوقت والموارد).
ومع ذلك ، من المحتمل أن يكون اكتمال مثل هذا الحل منخفضًا ، حيث يصعب وصف جميع الاختلافات في أي فئة.
النظر في مثال مضاد. إذا كان بالإضافة إلى نية تحويل الأموال ، فقد تشمل "التحويل" أيضًا النية الثانية - "التحويل إلى المشغل". عندما نضيف هدفًا جديدًا للترجمة إلى المشغل ، نحصل على نتائج مختلفة.
تنخفض الدقة بمقدار 18 نقطة ، بينما لا ينمو اكتمالها بالطبع. هذا يدل على أن هناك حاجة إلى نهج أكثر تقدما.
تحليل النص
قبل استخدام التعلم الآلي ، تحتاج إلى فهم كيفية تقديم النص كجهة متجهة. واحدة من أسهل الطرق هي
استخدام متجه tf-idf .
يأخذ متجه tf-idf في الاعتبار حدوث كل كلمة في عبارة المستخدم ويأخذ في الاعتبار التواجد الكلي للكلمات في المجموعة. الكلمات التي غالبًا ما توجد في نصوص مختلفة لها وزن أقل في تمثيل المتجهات.
دعونا نلقي نظرة على جودة النموذج الخطي على تمثيلات tf-idf (في حالتنا ، الانحدار اللوجستي).
نتيجة لذلك ،
زاد اكتمال بحدة ، وبقيت الدقة قابلة للمقارنة مع استخدام القاموس ، وزاد أيضًا مقياس f1 (المتوسط التوافقي الموزون بين الدقة والكمال). وهذا يعني أن النموذج نفسه يفهم بالفعل الكلمات المهمة لأي نية - لا تحتاج إلى اختراع أي شيء بنفسك.
التصور البيانات
يساعد تخيل البيانات على فهم كيف تبدو النوايا ومدى تجميعها في الفضاء. لكن لا يمكننا تصور تمثيلات tf-idf بشكل مباشر بسبب البعد الكبير ، لذلك سوف نستخدم
طريقة ضغط البعد - t-SNE .
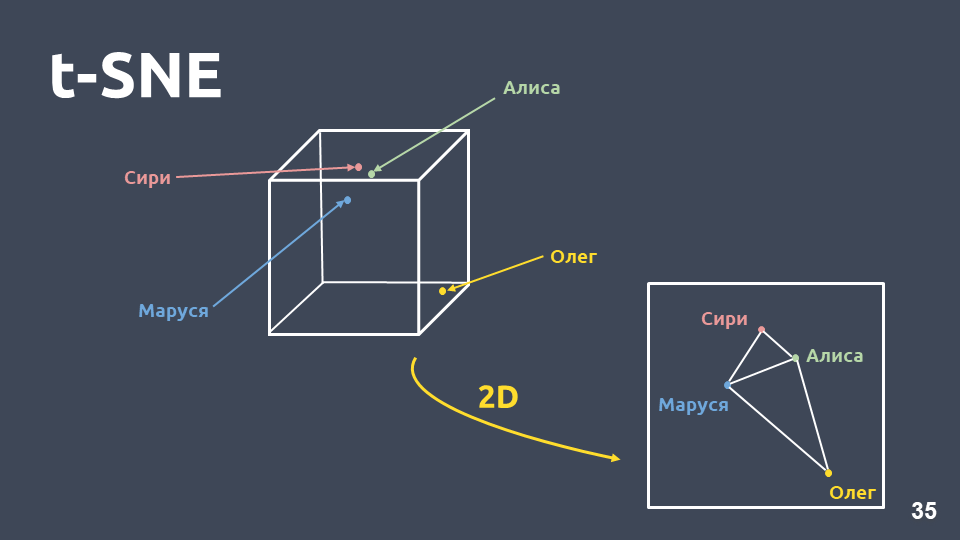
الفرق الرئيسي بين هذه الطريقة و PCA هو أنه عند النقل إلى الفضاء ثنائي الأبعاد ،
يتم الحفاظ على المسافة النسبية بين الكائنات .
t-SNE على tf-idf (أفضل 10 نوايا) ، F1 يسجل 0.92تم عرض أهم 10 نوايا بحدوثها في مجموعتنا أعلاه. هناك نقاط خضراء لا تنتمي إلى أي نية ، و 10 مجموعات تتميز بألوان مختلفة هي نوايا مختلفة. يمكن أن نرى أن بعضهم مصنف جيدًا.
مقياس F1 المرجح
هو 0.92 - وهذا كثير جدًا ، يمكنك بالفعل العمل معه.
لذلك مع المصنف الخطي على tf-idf:
- اكتمال أعلى بكثير من استخدام القاموس ، مع دقة قابلة للمقارنة ؛
- لا حاجة للتفكير في الكلمات التي تتوافق مع أي نية.
ولكن هناك أيضا عيوب:
- المفردات المحدودة ، يمكنك الحصول على وزن فقط لتلك الكلمات الموجودة في نموذج التدريب ؛
- لا تؤخذ إعادة الصياغة بعين الاعتبار ؛
- لا يؤخذ في الاعتبار الترتيب الذي تحدث به الكلمات في النص.
أعاد التنظيم
دعونا نفكر بمزيد من التفصيل في مشكلة إعادة الصياغة.
يمكن أن تكون متجهات Tf-idf قريبة فقط من النصوص التي تتقاطع في الكلمات. يمكن حساب القرب بين المتجهات من خلال جيب تمام الزاوية بينهما. يتم حساب القرب التمامي في تمثيل المتجه tf-idf للحصول على أمثلة محددة.
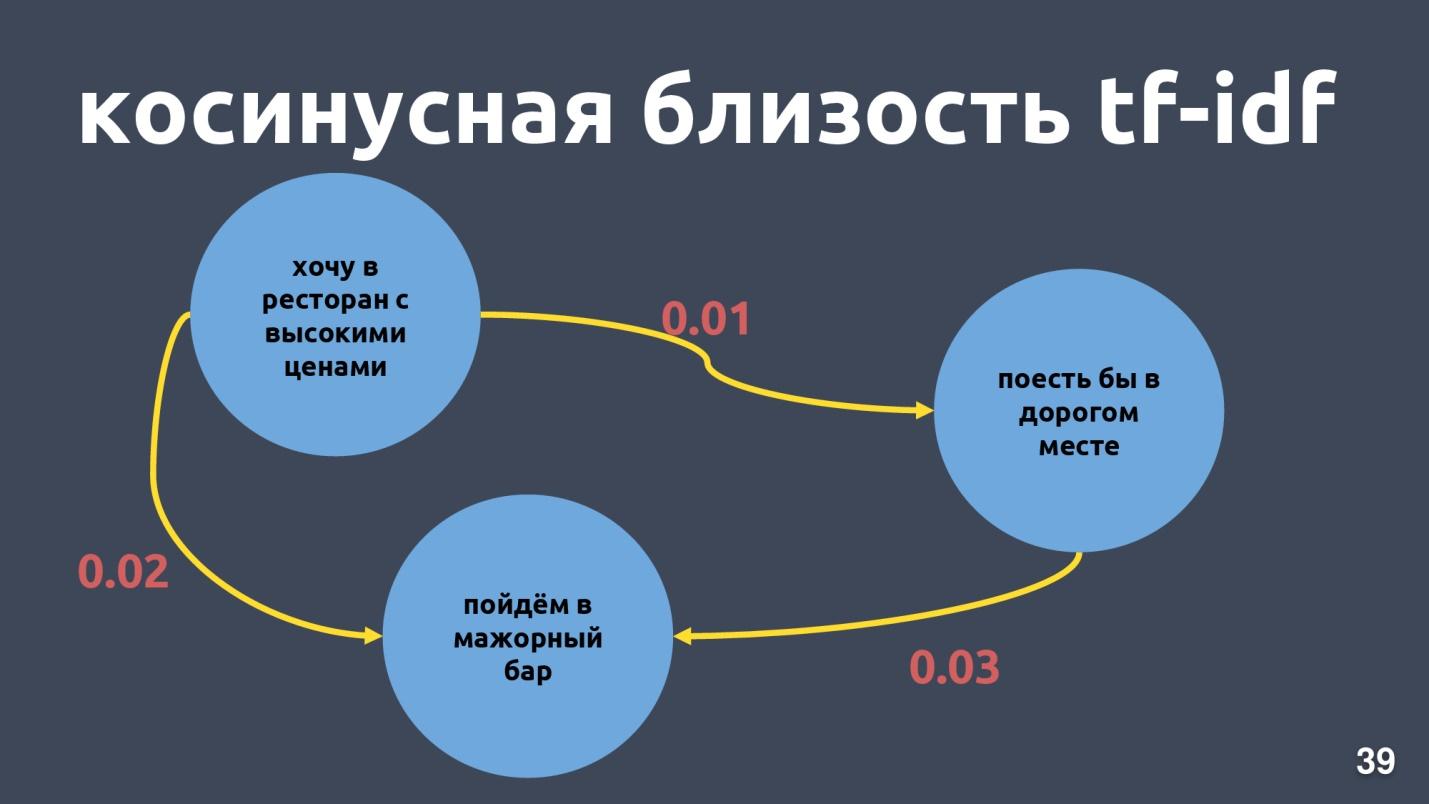
هذه ليست عبارات قريبة جدًا لتمثيل متجه tf-idf ، على الرغم من أنها بالنسبة لنا هي نفس النية ونفس الفئة.
ما الذي يمكن عمله حيال ذلك؟ على سبيل المثال ، بدلاً من الرقم ، يمكنك تمثيل كلمة كمتجه كامل - وهذا ما يسمى "تضمين الكلمات".
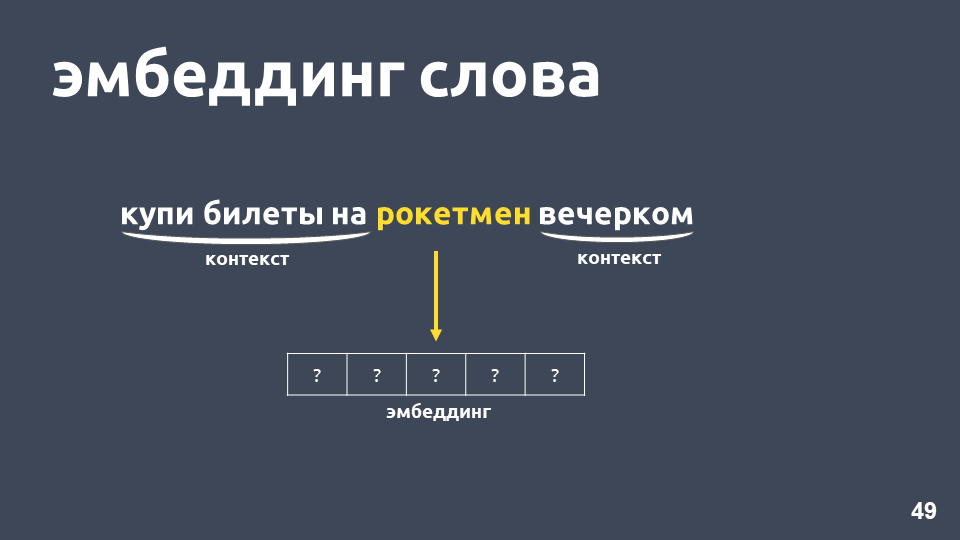
تم اقتراح أحد أشهر النماذج لحل هذه المشكلة في عام 2013. يطلق عليه
word2vec وقد استخدم على نطاق واسع منذ ذلك الحين.
تعمل إحدى طرق تعلم Word2vec تقريبًا على النحو التالي: نحن نأخذ النص ، ونأخذ بعض الكلمات من السياق ونرميه ، ثم نأخذ كلمة عشوائية أخرى من السياق ونقدم كلمتين كنواقل موجزة واحدة. ناقل الموجات الحارة واحد هو متجه وفقًا لبعد القاموس ، حيث يكون للإحداثي المقابل لمؤشر الكلمة في القاموس فقط القيمة 1 ، والباقي 0.
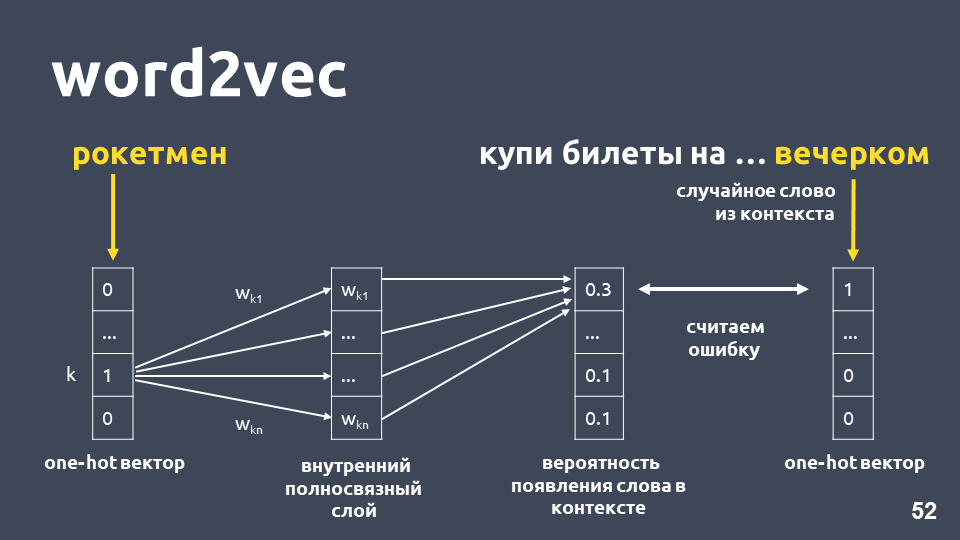
بعد ذلك ، نقوم بتدريب شبكة عصبية بسيطة أحادية الطبقة دون التنشيط على الطبقة الداخلية للتنبؤ بالكلمة التالية في السياق ، أي توقع كلمة "في المساء" باستخدام كلمة "rocketman". في الخرج ، نحصل على توزيع الاحتمالات لجميع الكلمات من القاموس لتكون على النحو التالي. نظرًا لأننا نعرف ما هي الكلمة بالفعل ، فيمكننا حساب الخطأ وتحديث الأوزان وما إلى ذلك.

الأوزان المحدثة التي تم الحصول عليها نتيجة التدريب على عينة لدينا هي كلمة التضمين.
ميزة استخدام التضمين بدلاً من الرقم هي ، أولاً ،
أخذ هذا السياق في الاعتبار . مثال شائع: ترامب وبوتين قريبان من word2vec لأنهما كلاهما رئيس وكثيرا ما يستخدمان معا في النصوص.
بالنسبة للكلمات التي تم العثور عليها في نموذج التدريب ، يمكنك فقط أخذ مصفوفة التضمين ، واتخاذ متجهها بواسطة فهرس الكلمة ، والحصول على التضمين.
يبدو أن كل شيء على ما يرام ، باستثناء أن بعض الكلمات في المصفوفة قد لا تكون كذلك ، لأن النموذج لم يرها أثناء التدريب. من أجل التعامل مع مشكلة الكلمات غير المألوفة (خارج المفردات) ، توصلوا في عام 2014 إلى تعديل word2vec -
fasttext .
يعمل Fasttext على النحو التالي: إذا لم تكن الكلمة موجودة في القاموس ، فسيتم تقسيمها إلى n-grams رمزية ، حيث يتم أخذ التضمين n-gram لكل مصفوفة من زخارف n-grams (التي يتم تدريبها مثل word2vec) ، ويتم حساب المتوسطات ، ويتم الحصول على المتجهات.
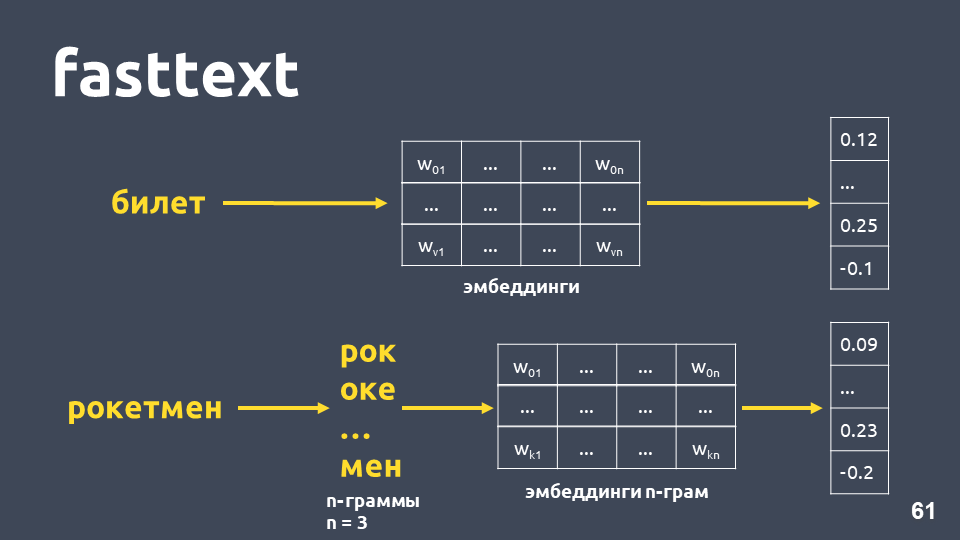
الإجمالي ، نحصل على المتجهات للكلمات التي ليست في قاموسنا. الآن يمكننا
حساب التشابه حتى بالنسبة للكلمات غير المألوفة . والأهم من ذلك ، هناك نماذج مدربة
للروسية والإنجليزية والصينية ، على سبيل المثال ، Facebook و
DeepPavlov ، بحيث يمكنك تضمين هذا بسرعة في خط
أنابيبك .
لكن العيوب تبقى:- لا يتم استخدام النموذج لمتجه النص بأكمله. للحصول على متجه نص عادي ، تحتاج إلى التفكير في شيء ما: متوسط أو متوسط بضرب الأوزان ، ويمكن أن يعمل هذا بشكل مختلف في مهام مختلفة.
- لا يزال ناقل كلمة واحدة واحدًا ، بغض النظر عن السياق. يقوم Word2vec بتدريب متجه كلمة واحدة على أي سياق تحدث فيه الكلمة. بالنسبة للكلمات متعددة القيم (مثل ، على سبيل المثال ، اللغة) ، سيكون هناك متجه واحد.
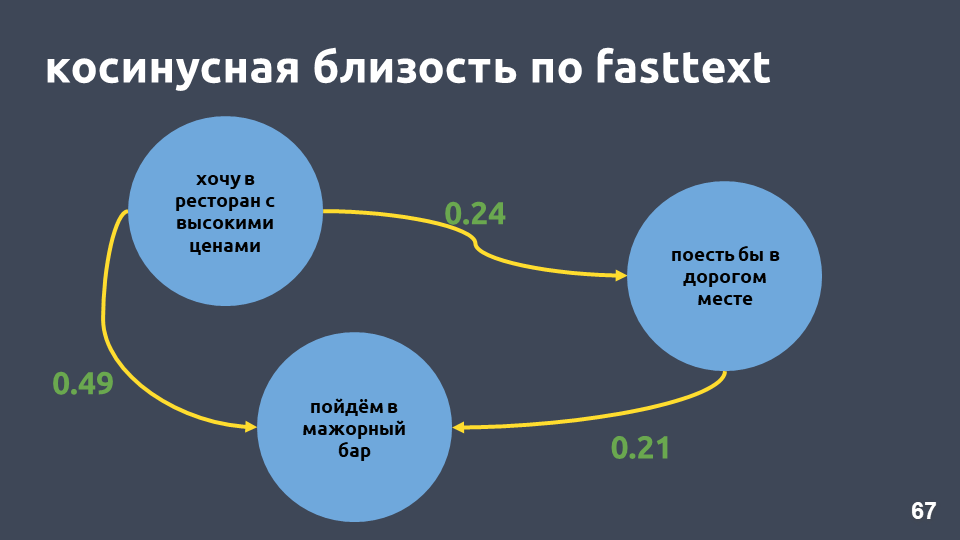
في الواقع ، يكون القرب التمامي في مثالنا في النص السريع أعلى من القرب التمامي في tf-idf ، على الرغم من أن هذه العبارات "تشترك فيها"
t-SNE على fasttext (أفضل 10 نوايا) ، درجة F1: 0.86ومع ذلك ، عند عرض نتائج النص السريع على تحلل t-SNE ، تبرز مجموعات النوايا بشكل أسوأ بكثير من tf-idf. مقياس F1 هنا هو 0.86 بدلاً من 0.92.
أجرينا تجربة: الجمع بين ناقلات tf-idf و fasttext. الجودة هي تماما كما هو الحال عند استخدام tf-idf فقط. هذا ليس صحيحًا بالنسبة لجميع المهام ، فهناك مشاكل تعمل فيها tf-idf المدمجة و fasttext بشكل أفضل من tf-idf فقط ، أو حيث يعمل fasttext بشكل أفضل من tf-idf. تحتاج إلى تجربة ومحاولة.
دعنا نحاول زيادة عدد النوايا (تذكر أن لدينا 170 منها). فيما يلي مجموعات لأهم 30 نية على ناقلات tf-idf.
t-SNE في tf-idf (أفضل 30 نية) ، F1 يسجل 0 ، 85 (في 10 كان 0.92)تنخفض الجودة بمقدار 7 نقاط ، والآن لا نرى بنية كتلة واضحة.
دعونا نلقي نظرة على أمثلة للنصوص التي بدأت تتشوش ، لأنه تمت إضافة المزيد من النوايا التي تتقاطع معانيًا وكلمات.
على سبيل المثال: "وإذا فتحت إيداعًا ، فما الفائدة عليه؟" و "وأريد فتح مساهمة بنسبة 7 في المئة." عبارات مماثلة جدا ، ولكن هذه نوايا مختلفة. في الحالة الأولى ، يريد الشخص معرفة شروط الودائع ، وفي الحالة الثانية ، فتح وديعة. لفصل هذه النصوص في فصول مختلفة ، نحتاج إلى شيء أكثر تعقيدًا -
التعلم العميق .
نموذج اللغة
نريد الحصول على متجه للنص ، وبشكل خاص متجه للكلمة ، والذي يعتمد على سياق الاستخدام. الطريقة القياسية للحصول على مثل هذا المتجه هي
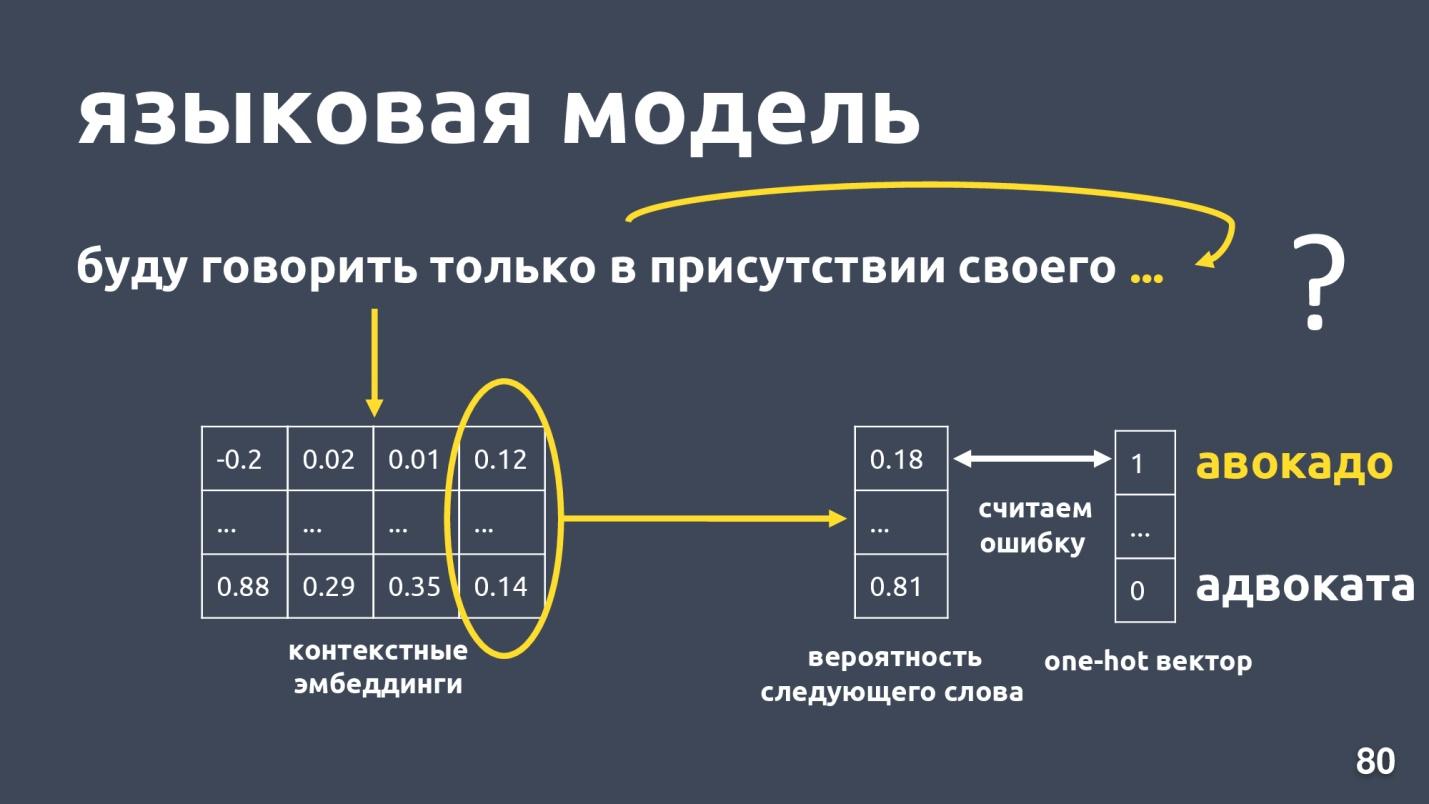
استخدام الزخارف من نموذج اللغة .
نموذج اللغة يحل مشكلة نمذجة اللغة. وما هي هذه المهمة؟ فليكن هناك تسلسل من الكلمات ، على سبيل المثال: "سأتحدث فقط بحضور بلدي ..." ، ونحن نحاول التنبؤ بالكلمة التالية في التسلسل. يوفر نموذج اللغة سياقًا لحفلات الزفاف. بعد الحصول على زخارف وسياقات لكل سياق ، يمكن للمرء التنبؤ باحتمال الكلمة التالية.
هناك متجه بعد البعد للقاموس ، ويتم تعيين كل كلمة لاحتمال كونها التالية. نحن نعرف مرة أخرى ما هي الكلمة في الواقع ، والنظر في خطأ وتدريب النموذج.
هناك عدد قليل من نماذج اللغة ، هل كان هناك طفرة العام الماضي؟ وقد تم اقتراح العديد من البنى المختلفة. واحد منهم هو
ELMo .
إلمو
تتمثل فكرة نموذج ELMo أولاً في بناء كلمة رمزية تضم كل كلمة في النص ، ثم تطبيق
شبكة LSTM عليها بطريقة تأخذ في الاعتبار
حفلات الزفاف التي تأخذ في الاعتبار السياق الذي تحدث فيه الكلمة.
دعنا ندرس كيفية الحصول على التضمين الرمزي: نقوم بتقسيم الكلمة إلى رموز ، وتطبيق طبقة التضمين لكل رمز والحصول على مصفوفة التضمين. عندما يتعلق الأمر بالرموز فقط ، فإن بُعد هذه المصفوفة صغير. ثم ، يتم تطبيق الالتواء أحادي البعد على مصفوفة التضمين ، كما يحدث عادة في البرمجة اللغوية العصبية (NLP) ، مع تجمع أقصى في النهاية ، يتم الحصول على ناقل واحد. يتم تطبيق
شبكة الطرق السريعة المكونة من طبقتين على هذا المتجه ، والذي يحسب
المتجه العام للكلمة .
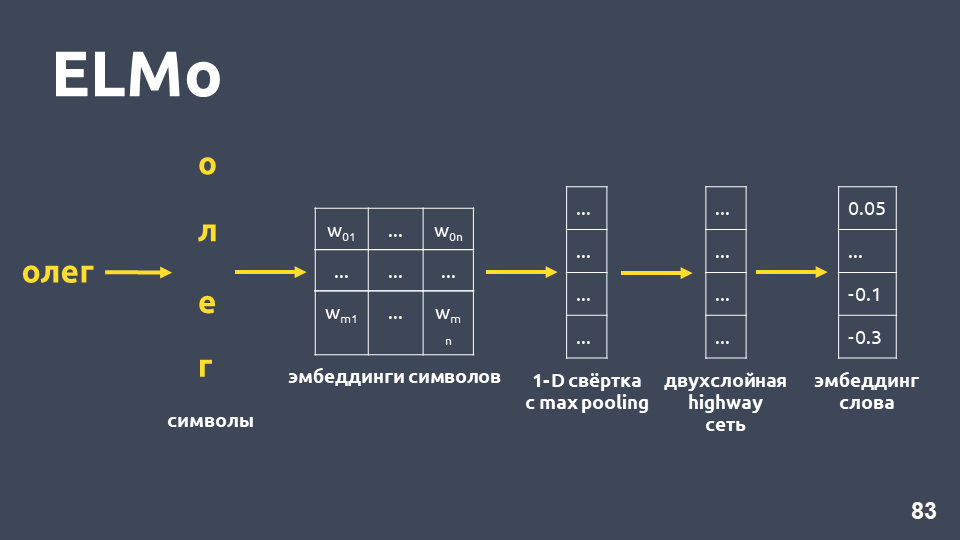
علاوة على ذلك ، سيبني النموذج نوعًا من فرضية التضمين حتى بالنسبة للكلمة التي لم يتم العثور عليها في مجموعة التدريب.
بعد تلقينا حفلات زفاف رمزية لكل كلمة ، نطبق شبكة BiLSTM ثنائية الطبقات عليها.
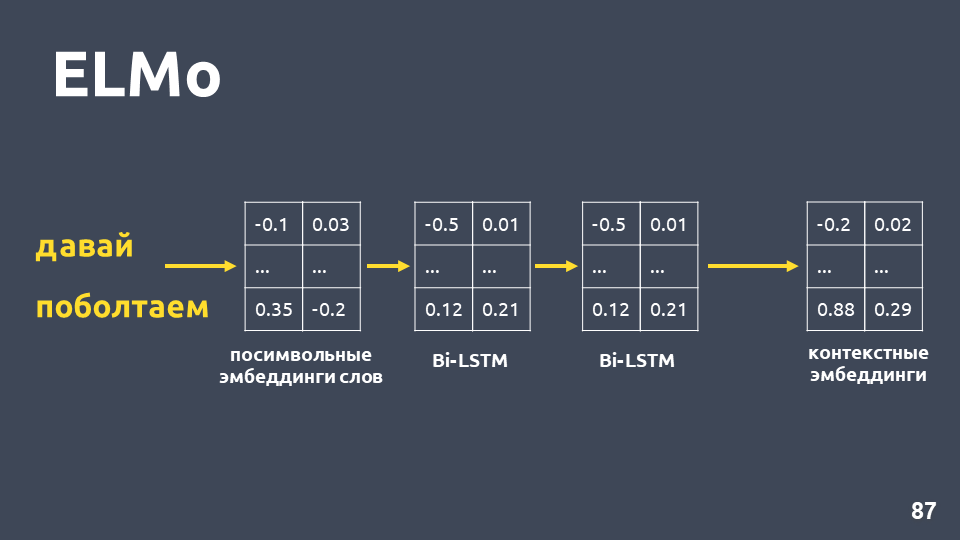
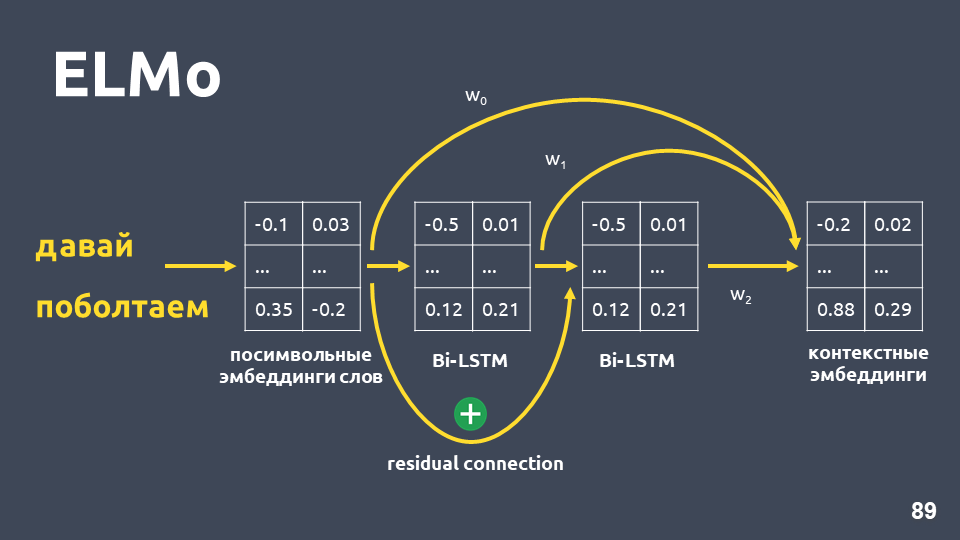
بعد تطبيق شبكة BiLSTM ثنائية الطبقة ، عادةً ما يتم أخذ الحالات المخفية للطبقة الأخيرة ، ويُعتقد أن هذا هو تضمين للسياق. لكن ELMo له ميزتان:
- اتصال المتبقي بين المدخلات من الطبقة الأولى LSTM وإخراجها. تتم إضافة إدخال LSTM إلى الإخراج لتجنب مشكلة التدرجات الخبو.
- يقترح مؤلفو ELMo الجمع بين التضمين الرمزي لكل كلمة ، وإخراج الطبقة الأولى من LSTM وإخراج طبقة LSTM الثانية مع بعض الأوزان المحددة لكل مهمة. يعد ذلك ضروريًا لمراعاة ميزات المستوى المنخفض والميزات ذات المستوى الأعلى التي تعطي الطبقتين الأولى والثانية من LSTM.
في مشكلتنا ، استخدمنا متوسطًا بسيطًا لهذه الزخارف الثلاثة ، وبالتالي حصلنا على تضمين سياق لكل كلمة.
يوفر نموذج اللغة الفوائد التالية:
- يعتمد متجه الكلمة على السياق الذي تستخدم فيه الكلمة. هذا هو ، على سبيل المثال ، بالنسبة لكلمة "اللغة" في معنى الجزء الأساسي والمصطلح اللغوي ، نحصل على متجهات مختلفة.
- كما في حالة word2vec و fasttext ، هناك العديد من النماذج المدربة ، على سبيل المثال ، من مشروع DeepPavlov . يمكنك أن تأخذ النموذج النهائي ومحاولة التقدم في مهمتك.
- لم تعد بحاجة إلى التفكير في كيفية قياس متجهات الكلمة. نموذج ELMo ينتج على الفور متجه لجميع النص.
- يمكنك إعادة تدريب نموذج اللغة لمهمتك ، فهناك عدة طرق لذلك ، على سبيل المثال ، ULMFiT.
تبقى ناقص الوحيد -
نموذج اللغة لا يضمن أن النصوص التي تنتمي إلى نفس الفئة ، أي إلى نية واحدة ، ستكون قريبة في مساحة المتجه.
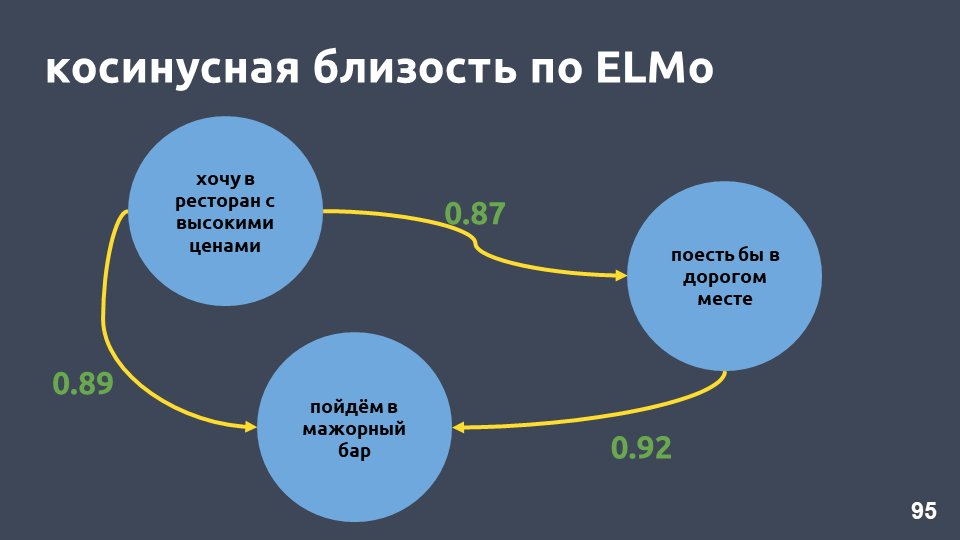
في مثال مطعمنا ، أصبحت قيم جيب التمام وفقًا لنموذج ELMo أعلى حقًا.
t-SNE على ELMo (أفضل 10 نوايا) ، النتيجة F1 0.93 (0.92 بواسطة tf-idf)المجموعات ذات النوايا العشرة الأولى هي أيضًا أكثر وضوحًا. في الشكل أعلاه ، كل المجموعات العشر مرئية بوضوح ، بينما زادت الدقة قليلاً.
t-SNE على ELMo (أفضل 30 نوايا) F1 يسجل 0.86 (0.85 بواسطة tf-idf)بالنسبة إلى أفضل 30 نية ، لا يزال يتم الحفاظ على بنية المجموعة ، وهناك أيضًا زيادة في الجودة بمقدار نقطة واحدة.
ولكن في مثل هذا النموذج لا يوجد ما يضمن أن المقترحات "وإذا قمت بفتح الودائع ، ما هي الفائدة عليها؟" و "وأريد فتح مساهمة بنسبة 7 في المائة" ستكون بعيدة عن بعضها البعض ، على الرغم من أنها تقع في فصول مختلفة. مع ELMo ، نحن ببساطة نتعلم نموذج اللغة ، وإذا كانت النصوص متشابهة لغوياً ، فستكون قريبة.
لا يعرف ELMo أي شيء عن الفصول الدراسية لدينا ، ولكن يمكنك تجميع متجهات نصية لنفس الغرض في الفضاء باستخدام تسميات
الفصول الدراسية .
شبكة سيامي
خذ بنية الشبكة العصبية المفضلة لديك لتوجيه النص ومثالين للنوايا. لكل من الأمثلة التي نحصل عليها حفلات الزفاف ، ثم نقوم بحساب مسافة جيب التمام بينهما.
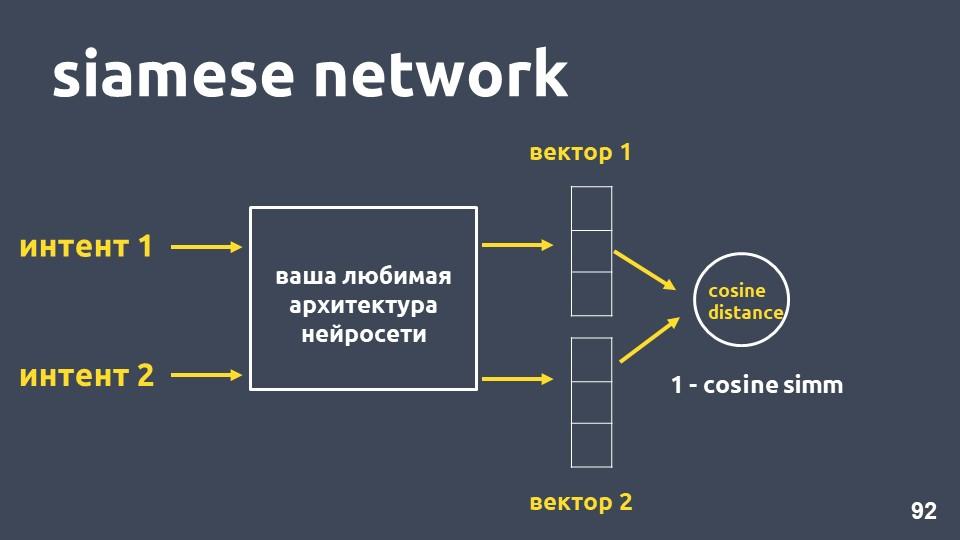
المسافة جيب التمام تساوي واحد ناقص القرب التمام الذي التقينا في وقت سابق.
هذا النهج يسمى
شبكة سيامي .
نريد نصوص من نفس الفصل ، على سبيل المثال ، "إجراء تحويل" و "رمي الأموال" ، لتقع في الفضاء. وهذا يعني أن مسافة جيب التمام بين متجهاتها يجب أن تكون صغيرة قدر الإمكان ، وتكون صفرية بشكل مثالي وينبغي أن تكون النصوص المتعلقة بالنوايا المختلفة متباعدة بقدر الإمكان.
لكن في الممارسة العملية ، فإن طريقة التدريب هذه لا تعمل بشكل جيد ، نظرًا لأن كائنات الفئات المختلفة لا تحصل على مسافة كافية عن بعضها البعض. وظيفة الخسارة المسماة
"الخسارة الثلاثية" تعمل بشكل أفضل. ويستخدم ثلاثة أضعاف كائنات تسمى ثلاثة توائم.
يوضح الرسم التوضيحي ثلاثيًا: كائن مرساة في دائرة زرقاء ، كائنًا إيجابيًا باللون الأخضر وكائن سلبي في دائرة حمراء. الكائن السلبي والمرساة موجودان في فئات مختلفة ، والموجبة والمرساة موجودة في فئة واحدة.

نريد أن نضمن أنه بعد التدريب يكون الكائن الإيجابي أقرب إلى المرسى من السالب. للقيام بذلك ، فإننا نعتبر مسافة جيب التمام بين أزواج الكائنات وأدخل مقياس التشعب - "الهامش" - المسافة التي نتوقع أن تكون بين الأجسام الموجبة والسالبة.

تبدو وظيفة الخسارة كما يلي:
بمعنى آخر ، أثناء التدريب ، نحقق أن الكائن الإيجابي أقرب إلى المرسى من الهامش السلبي ، على الأقل. إذا كانت وظيفة الفقد هي صفر ، فستعمل ، وننهي التدريب ، وإلا فإننا نواصل تقليل الوظيفة الهدف.
بعد أن قمنا بتدريب النموذج ، ما زلنا لا نحصل على مصنف ، إنها مجرد طريقة للحصول على مثل هذه الزخارف التي من المحتمل أن يكون لها كائنات متقاربة في نفس القصد.
عندما نحصل على النموذج ، يمكننا استخدام طريقة تصنيف مختلفة في أعلى الزخارف.
KNN مناسب ، حيث حققنا بالفعل أن لحفلات الزفاف بنية عنقودية مميزة.
تذكر كيف يعمل kNN للنصوص: خذ عنصرًا من النص ، واحصل على التضمين له ، وقم بترجمته إلى فراغ متجه ، ثم انظر من هو جاره. بين الجيران ، نعتبر الفئة الأكثر شيوعًا ونستنتج أن الكائن الجديد ينتمي إلى هذه الفئة.
البعد من حفلات الزفاف التي نستخدمها هو 300 ، وفي عينة التدريب هناك حوالي 500000 كائن. الأساليب القياسية للعثور على أقرب الجيران لا تناسبنا من حيث الأداء. استخدمنا طريقة
HNSW -
التسلسل الهرمي للملاحة الصغيرة في العالم .
Navigable Small World هو رسم بياني متصل حيث توجد حواف قليلة بين القمم التي تقع على مسافة كبيرة ، والعديد من الحواف بين القمم القريبة. في حالتنا ، سيتم تحديد طول الحافة من خلال مسافة جيب التمام ، أي بالنسبة لعينة التدريب ، نحسب المسافة بين جميع أمثلة النوايا ، ثم نرمي مسافات كبيرة بشكل عشوائي بحيث لا يزال الرسم البياني متصلًا.
, Hierarchical. , , , . .
, , , , .
, , , , , . , , ,
— 0,95-0,99 , .
, , , ,
. .
, . , . .
t-SNE siamese (-10 ), F1 score 0,95 (0,93 ELMo)t-SNE siamese (-30 ), F1 score 0,87 (0,86 ELMo)10 ELMo, 30 — , .
النتائج
, , , 2-5, . , , , 20-30 . , .
, , , tf-idf . , , , .
, word2vec fasttext. , , . , , , .
, , ELMo. , , , , , .
ELMo, , .
, - . . , . , , . , , .. , .
:— «Deep Learning vs common sense» — UseData Conf . , - , 18 , , .
, , , , 16 UseData Conf .