في الآونة الأخيرة ، يعمل مصنعو FPGA وشركات الطرف الثالث بنشاط على تطوير أساليب تطوير لـ FPGA التي تختلف عن الأساليب التقليدية باستخدام أدوات التطوير عالية المستوى.
كمطور FPGA ، أستخدم لغة وصف الأجهزة (
HDL ) من
Verilog كأداة رئيسية ، لكن تزايد شعبية الأساليب الجديدة أثارت اهتمامي الكبير ، لذلك قررت في هذه المقالة أن أفهم ما كان يحدث.
هذه المقالة ليست دليلًا أو إرشادات للاستخدام ، فهذه هي مراجعي واستنتاجات حول ما يمكن أن تقدمه أدوات التطوير عالية المستوى لمطور أو مبرمج FPGA الذي يريد الانغماس في عالم FPGA. من أجل مقارنة أدوات التطوير الأكثر إثارة للاهتمام في رأيي ، كتبت العديد من الاختبارات وتحليل النتائج. تحت خفض - ما جاء منه.
لماذا تحتاج إلى أدوات تطوير رفيعة المستوى لـ FPGA؟
- تسريع تطوير المشروع
- بسبب إعادة استخدام الشفرة المكتوبة بالفعل بلغات عالية المستوى ؛
- من خلال استخدام جميع مزايا اللغات عالية المستوى ، عند كتابة الشفرة من نقطة الصفر ؛
- عن طريق تقليل وقت التجميع والتحقق من الشفرة.
- القدرة على إنشاء رمز عالمي يعمل على أي عائلة FPGA.
- تقليل عتبة التطوير لـ FPGAs ، على سبيل المثال ، تجنب مفاهيم "سرعة الساعة" والكيانات الأخرى منخفضة المستوى. القدرة على كتابة كود FPGA لمطور غير مألوف بـ HDL.
من أين تأتي أدوات التطوير رفيعة المستوى؟
الآن تنجذب الكثير من فكرة التنمية رفيعة المستوى.
يشارك كل من المتحمسين ، على سبيل المثال ،
Quokka ومولد كود Python والشركات ، مثل
Mathworks ، ومصنعي FPGA ،
Intel و
Xilinx .
الجميع يستخدم أساليبه وأدواته لتحقيق هدفه. المتحمسون في النضال من أجل عالم مثالي وجميل يستخدمون لغات التطوير المفضلة لديهم ، مثل Python أو C #. الشركات ، التي تحاول إرضاء العميل ، تقدم أدواتها الخاصة أو تكييفها. تقدم Mathworks أداة تشفير HDL الخاصة بها لإنشاء كود HDL من البرامج النصية m وطرز Simulink ، بينما تقدم Intel و Xilinx مترجمين لـ C / C ++ الشائعة.
في الوقت الحالي ، حققت الشركات التي تتمتع بموارد مالية وبشرية كبيرة نجاحًا أكبر ، في حين أن المتحمسين متأخرين بعض الشيء. سيتم تخصيص هذه المقالة للنظر في برنامج تشفير HDL للمنتج من Mathworks و HLS Compiler من Intel.
ماذا عن Xilinxفي هذه المقالة ، لا أعتبر HIL من Xilinx ، نظرًا لوجود بنى مختلفة وأنظمة CAD في Intel و Xilinx ، مما يجعل من المستحيل إجراء مقارنة لا لبس فيها للنتائج. لكنني أريد أن أشير إلى أن Xilinx HLS ، مثل Intel HLS ، يوفر برنامج التحويل البرمجي C / C ++ وهي متشابهة من الناحية النظرية.
دعنا نبدأ بمقارنة المبرمج HDL من Mathworks و Intel HLS Compiler ، بعد أن حل العديد من المشاكل باستخدام طرق مختلفة.
مقارنة بين أدوات التطوير رفيعة المستوى
اختبار واحد. "اثنين من المضاعفات والأفعى"
لا يوجد حل عملي لهذه المشكلة ، ولكنه مناسب تمامًا كاختبار أول. تأخذ الوظيفة 4 معلمات ، تضرب الأولى مع الثانية ، الثالثة مع الرابعة وتضيف نتائج الضرب. لا شيء معقد ، ولكن دعونا نرى كيف تعاملت مواضيعنا مع هذا.
HDL المبرمج بواسطة Mathworks
لحل هذه المشكلة ، يبدو البرنامج النصي m كما يلي:
function [out] = TwoMultAdd(a,b,c,d) out = (a*b)+(c*d); end
دعونا نرى ما تقدمه Mathworks لتحويل الشفرة إلى HDL.
لن أفكر في العمل مع برنامج ترميز HDL بالتفصيل ، وسأتناول فقط الإعدادات التي سوف أقوم بتغييرها في المستقبل للحصول على نتائج مختلفة في FPGA ، وسوف يتعين على مبرمج MATLAB النظر في التغييرات التي سيحتاج إليها لتشغيل شفرته في FPGA.
لذلك ، فإن أول شيء فعله هو تعيين نوع وقيمة قيم الإدخال. لا توجد شار مألوفة ، كثافة العمليات ، تعويم ، مزدوجة في FPGA. يمكن أن يكون عمق البت في أي عدد ، فمن المنطقي اختياره ، استنادًا إلى مجموعة قيم الإدخال التي تخطط لاستخدامها.
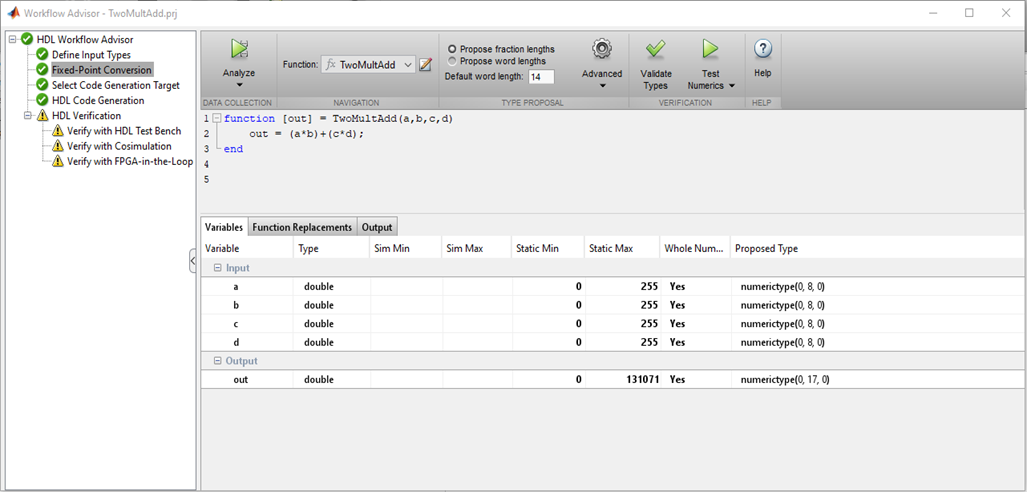 الشكل 1
الشكل 1يقوم MATLAB بفحص أنواع المتغيرات وقيمها وتحديد أحجام البت الصحيحة للحافلات والسجلات ، وهو أمر مناسب حقًا. إذا لم تكن هناك مشاكل في عمق البت والكتابة ، يمكنك المتابعة إلى النقاط التالية.
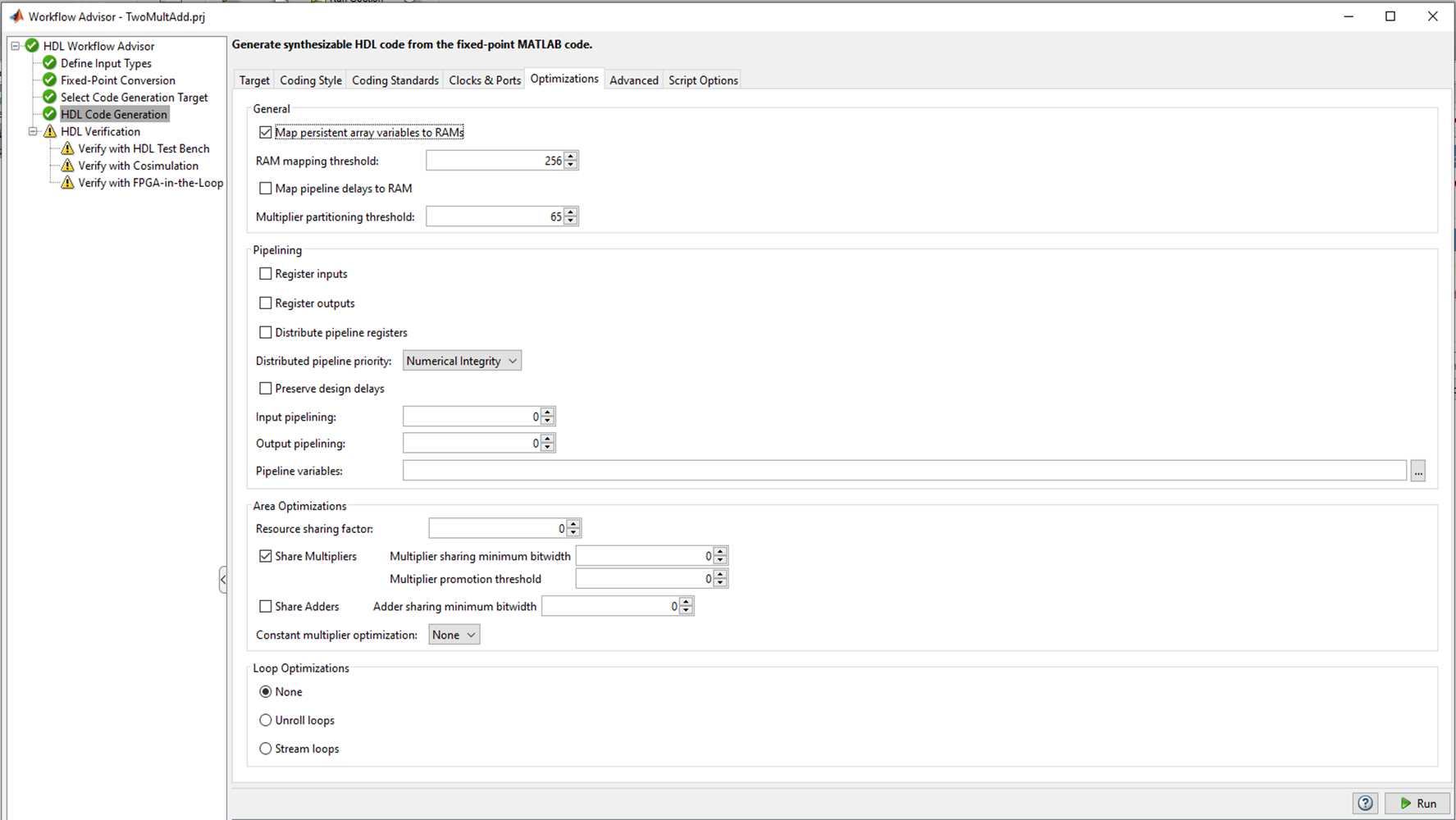 الشكل 2
الشكل 2هناك العديد من علامات التبويب في HDL Code Generation حيث يمكنك اختيار اللغة المطلوب تحويلها إلى (Verilog أو VHDL) ؛ نمط الرمز أسماء الإشارات. علامة التبويب الأكثر إثارة للاهتمام ، في رأيي ، هي Optimization ، وسأقوم بتجربتها ، ولكن في وقت لاحق ، دعونا الآن نترك جميع الإعدادات الافتراضية ونرى ما يحدث مع مشفر HDL "خارج الصندوق".
اضغط على الزر "تشغيل" واحصل على الكود التالي:
`timescale 1 ns / 1 ns module TwoMultAdd_fixpt (a, b, c, d, out); input [7:0] a; // ufix8 input [7:0] b; // ufix8 input [7:0] c; // ufix8 input [7:0] d; // ufix8 output [16:0] out; // ufix17 wire [15:0] TwoMultAdd_fixpt_mul_temp; // ufix16 wire [16:0] TwoMultAdd_fixpt_2; // ufix17 wire [15:0] TwoMultAdd_fixpt_mul_temp_1; // ufix16 wire [16:0] TwoMultAdd_fixpt_3; // ufix17 //HDL code generation from MATLAB function: TwoMultAdd_fixpt //%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% // % // Generated by MATLAB 9.2 and Fixed-Point Designer 5.4 % // % //%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% assign TwoMultAdd_fixpt_mul_temp = a * b; assign TwoMultAdd_fixpt_2 = {1'b0, TwoMultAdd_fixpt_mul_temp}; assign TwoMultAdd_fixpt_mul_temp_1 = c * d; assign TwoMultAdd_fixpt_3 = {1'b0, TwoMultAdd_fixpt_mul_temp_1}; assign out = TwoMultAdd_fixpt_2 + TwoMultAdd_fixpt_3; endmodule // TwoMultAdd_fixpt
رمز تبدو جيدة. يفهم MATLAB أن كتابة التعبير بالكامل على سطر واحد على Verilog هي ممارسة سيئة. يخلق
أسلاك منفصلة للمضاعف والأفعى ، لا يوجد شيء للشكوى منه.
من المثير للقلق أن وصف السجلات مفقود. حدث هذا لأننا لم نسأل HDL-coder عن هذا الأمر ، وترك جميع الحقول في الإعدادات لقيمها الافتراضية.
هنا هو ما Quartus توليفها من هذا الرمز.
 الشكل 3
الشكل 3لا مشاكل ، كان كل شيء كما هو مخطط لها.
في FPGA ننفذ الدوائر المتزامنة ، وما زلت أود أن أرى السجلات. يقدم HDL-coder آلية لوضع السجلات ، ولكن أين يضعها متروك للمطور. يمكننا وضع السجلات عند إدخال المضاعفات ، أو عند إخراج المضاعفات أمام الإعلان ، أو عند إخراج الإعلان.
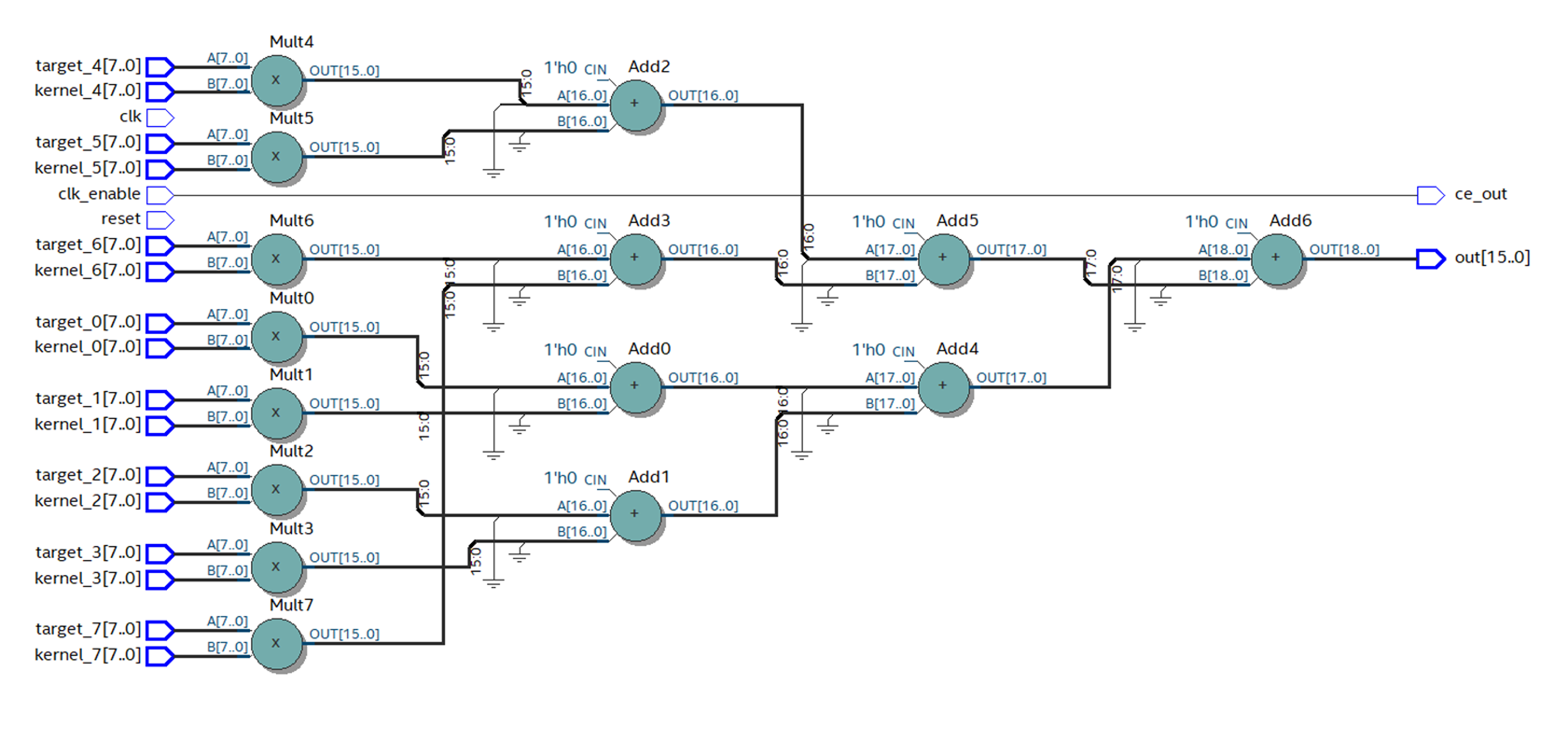
لتجميع الأمثلة ، اخترت عائلة FPGA Cyclone V ، حيث يتم استخدام كتل DSP خاصة مع إضافات ومضاعفات مدمجة لتنفيذ العمليات الحسابية. كتلة DSP يشبه هذا:
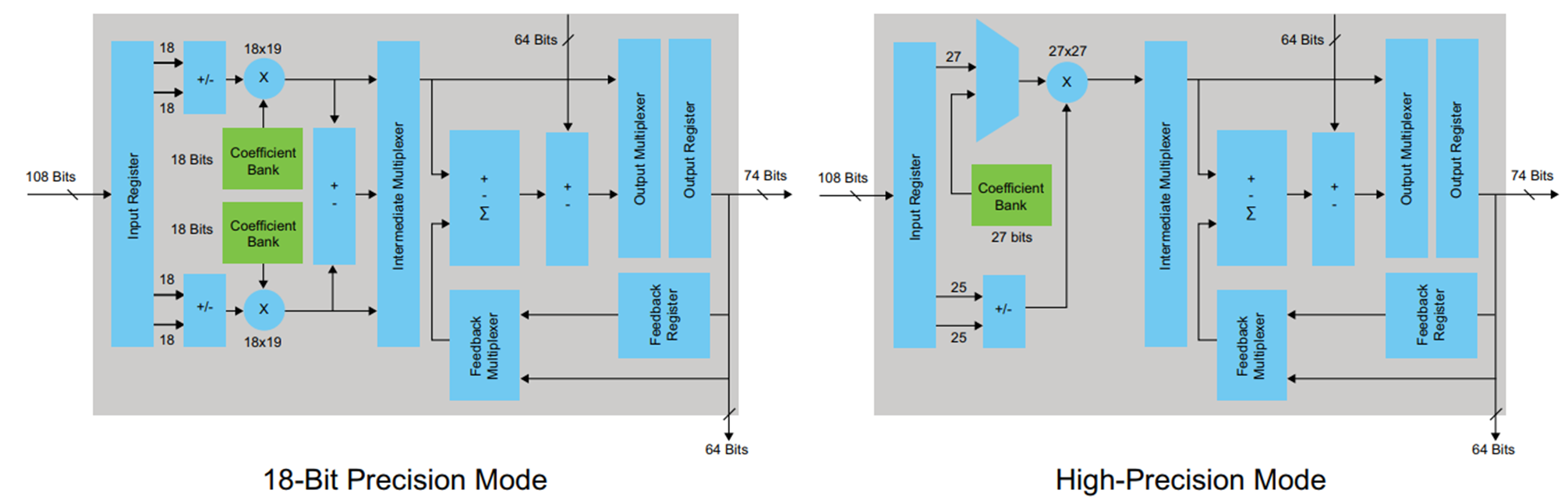 الشكل 4
الشكل 4كتلة DSP لديها سجلات المدخلات والمخرجات. ليست هناك حاجة لمحاولة التقاط نتائج الضرب في السجل قبل الإضافة ، فهذا سوف ينتهك الهيكل فقط (في بعض الحالات ، يكون هذا الخيار ممكنًا وحتى مطلوبًا). الأمر متروك للمطور لتحديد كيفية التعامل مع سجل المدخلات والمخرجات بناءً على متطلبات الكمون والحد الأقصى للتردد المطلوب. قررت استخدام سجل الإخراج فقط. لكي يتم توضيح هذا السجل في الكود الذي تم إنشاؤه بواسطة برنامج تشفير HDL ، في علامة التبويب "خيارات" في برنامج تشفير HDL ، تحتاج إلى التحقق من خانة الاختيار تسجيل الإخراج وإعادة تشغيل التحويل.
اتضح الكود التالي:
`timescale 1 ns / 1 ns module TwoMultAdd_fixpt (clk, reset, clke_ena_i, a, b, c, d, clke_ena_o, out); input clk; input reset; input clke_ena_i; input [7:0] a; // ufix8 input [7:0] b; // ufix8 input [7:0] c; // ufix8 input [7:0] d; // ufix8 output clke_ena_o; output [16:0] out; // ufix17 wire enb; wire [16:0] out_1; // ufix17 wire [15:0] TwoMultAdd_fixpt_mul_temp; // ufix16 wire [16:0] TwoMultAdd_fixpt_2; // ufix17 wire [15:0] TwoMultAdd_fixpt_mul_temp_1; // ufix16 wire [16:0] TwoMultAdd_fixpt_3; // ufix17 reg [16:0] out_2; // ufix17 //HDL code generation from MATLAB function: TwoMultAdd_fixpt //%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% // % // Generated by MATLAB 9.2 and Fixed-Point Designer 5.4 % // % //%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% assign TwoMultAdd_fixpt_mul_temp = a * b; assign TwoMultAdd_fixpt_2 = {1'b0, TwoMultAdd_fixpt_mul_temp}; assign TwoMultAdd_fixpt_mul_temp_1 = c * d; assign TwoMultAdd_fixpt_3 = {1'b0, TwoMultAdd_fixpt_mul_temp_1}; assign out_1 = TwoMultAdd_fixpt_2 + TwoMultAdd_fixpt_3; assign enb = clke_ena_i; always @(posedge clk or posedge reset) begin : out_reg_process if (reset == 1'b1) begin out_2 <= 17'b00000000000000000; end else begin if (enb) begin out_2 <= out_1; end end end assign clke_ena_o = clke_ena_i; assign out = out_2; endmodule // TwoMultAdd_fixpt
كما ترون ، الكود لديه اختلافات أساسية مقارنة بالإصدار السابق. ظهرت دائمًا الكتلة ، وهي وصف للسجل (فقط ما أردنا). لتشغيل الكتلة دائمًا ، ظهرت أيضًا مدخلات وحدة clk (تردد الساعة) وإعادة الضبط (إعادة الضبط). يمكن ملاحظة أن ناتج الأفعى مغلق في المشغل الموصوف دائمًا. هناك أيضًا بعض إشارات إذن ena ، لكنها ليست مثيرة للاهتمام بالنسبة لنا.
لنلقِ نظرة على المخطط الذي يصنعه Quartus الآن.
 الشكل 5
الشكل 5ومرة أخرى ، النتائج جيدة ومتوقعة.
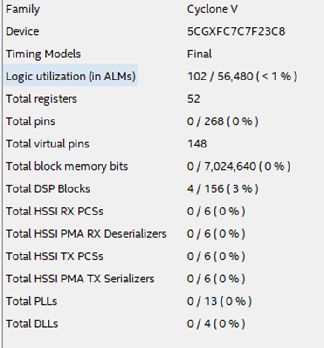
يعرض الجدول أدناه جدول الموارد المستخدمة - نضعها في الاعتبار.
 الشكل 6
الشكل 6لهذا المسعى الأول ، تتلقى Mathworks رصيدًا. كل شيء غير معقد ، يمكن التنبؤ به ومع النتيجة المرجوة.
وصفت بالتفصيل مثالًا بسيطًا ، قدمت مخططًا لكتلة DSP ، ووصفت إمكانيات استخدام إعدادات استخدام السجل في HDL-coder ، والتي تختلف عن الإعدادات "الافتراضية". يتم ذلك لسبب ما. بهذا أود التأكيد على أنه حتى في هذا المثال البسيط ، عند استخدام HDL-coder ، فإن معرفة بنية FPGA وأساسيات الدارات الرقمية ضرورية ، ويجب تغيير الإعدادات بوعي.
إنتل HLS مترجم
دعنا نحاول ترجمة التعليمات البرمجية بنفس الوظيفة المكتوبة بلغة C ++ ونرى ما يتم تصنيعه في النهاية في FPGA باستخدام برنامج التحويل البرمجي HLS.
حتى رمز C ++
component unsigned int TwoMultAdd(unsigned char a, unsigned char b, unsigned char c, unsigned char d) { return (a*b)+(c*d); }
لقد اخترت أنواع البيانات لتجنب الفائض المتغيرات.
هناك طرق متقدمة لإعداد أعماق البت ، لكن هدفنا هو اختبار القدرة على تجميع الوظائف المكتوبة بنمط C / C ++ تحت FPGA دون إجراء أي تغييرات ، كل ذلك خارج المربع.
نظرًا لأن برنامج التحويل البرمجي HLS هو أداة أصلية من Intel ، فإننا نجمع الشفرة مع مترجم خاص ونفحص النتيجة على الفور في Quartus.
دعونا ننظر إلى الدائرة التي توليفها Quartus.
 الشكل 7
الشكل 7قام المحول البرمجي بإنشاء سجلات عند المدخلات والمخرجات ، لكن الجوهر مخفي في وحدة المجمع. نبدأ في نشر برنامج التجميع و ... رؤية المزيد والمزيد من الوحدات المتداخلة.
هيكل المشروع يشبه هذا.
 الشكل 8
الشكل 8تلميح واضح من إنتل هو "لا تضع يديك على ذلك!". ولكن سنحاول ، وخاصة وظيفة ليست معقدة.
في أحشاء شجرة المشروع | quartus_compile | TwoMultAdd: TwoMultAdd_inst | TwoMultAdd_internal: twomultadd_internal_inst | TwoMultAdd_fu
nction_wrapper: TwoMultAdd_internal | TwoMultAdd_function: theTwoMultAdd_function | bb_TwoMultAdd_B1_start:
thebb_TwoMultAdd_B1_start | bb_TwoMultAdd_B1_start_stall_region: thebb_TwoMultAdd_B1_start_stall_region | i
_sfc_c1_wt_entry_twomultadd_c1_enter_twomultadd: thei_sfc_c1_wt_entry_twomultadd_c1_enter_twomultad
d_aunroll_x | i_sfc_logic_c1_wt_entry_twomultadd_c1_enter_twomultadd13: thei_sfc_logic_c1_wt_entry_twom
ultadd_c1_enter_twomultadd13_aunroll_x | Mult1 هي الوحدة التي تبحث عنها.
يمكننا إلقاء نظرة على الرسم البياني للوحدة المرغوبة التي تم تصنيعها بواسطة Quartus.
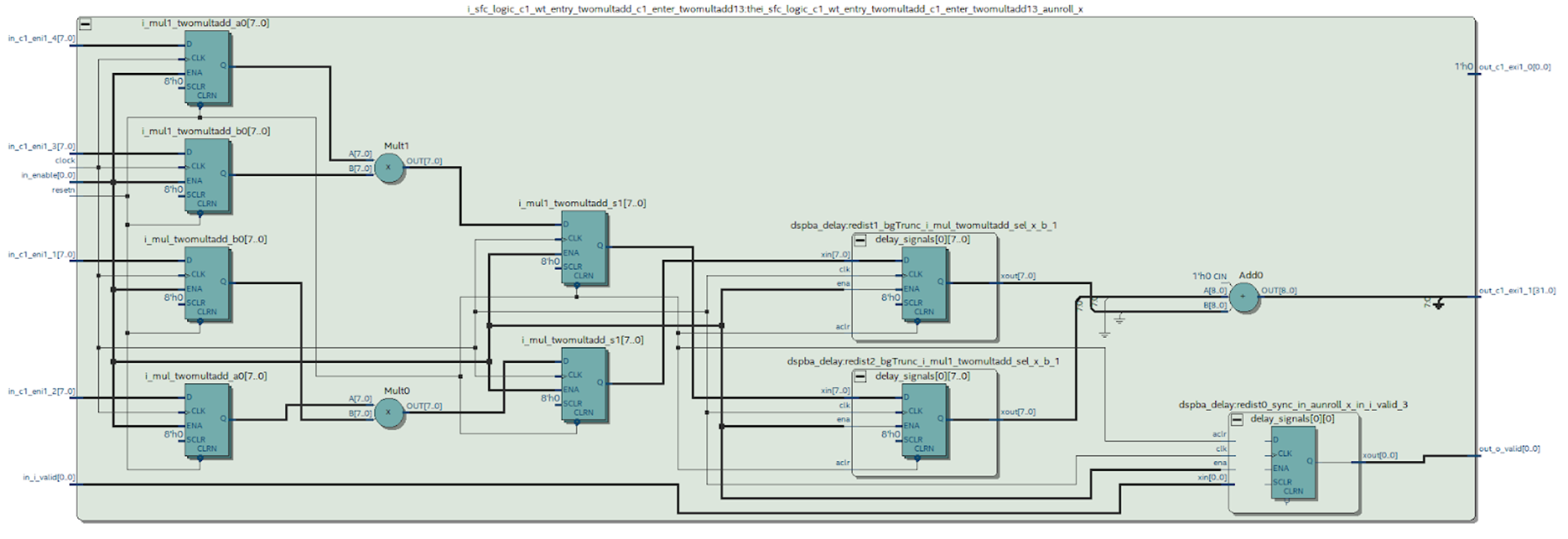 الشكل 9
الشكل 9ما هي الاستنتاجات التي يمكن استخلاصها من هذا المخطط.
من الواضح أن شيئًا ما حدث حاولنا تجنبه عند العمل في MATLAB: تم تجميع الحالة عند إخراج المضاعف - وهذا ليس جيدًا. يمكن أن نرى من مخطط كتلة DSP (الشكل 4) أنه لا يوجد سوى سجل واحد في مخرجاته ، مما يعني أنه يجب إجراء كل عملية ضرب في كتلة منفصلة.
يوضح جدول الموارد المستخدمة ما الذي يؤدي إليه هذا.
 الشكل 10
الشكل 10مقارنة النتائج مع جدول المبرمج HDL (الشكل 6).
إذا كنت تستخدم عددًا أكبر من السجلات التي يمكنك تحملها ، فإن إنفاق كتل DSP الثمينة على هذه الوظيفة البسيطة أمر غير سارة للغاية.
ولكن هناك زيادة كبيرة في إنتل HLS مقارنة مع المبرمج HDL. باستخدام الإعدادات الافتراضية ، قام برنامج التحويل البرمجي HLS بتطوير تصميم متزامن في FPGA ، على الرغم من أنه أنفق المزيد من الموارد. مثل هذه البنية ممكنة ، فمن الواضح أن إنتل HLS تم تكوينه لتحقيق أقصى قدر من الأداء ، وليس لتوفير الموارد.
دعونا نرى كيف تتصرف مواضيعنا مع مشاريع أكثر تعقيدا.
الاختبار الثاني. "الضرب الحكيم للمصفوفات مع جمع النتيجة"
تستخدم هذه الوظيفة على نطاق واسع في معالجة الصور: ما يسمى
"مصفوفة المصفوفة" . نبيعه باستخدام أدوات عالية المستوى.
HDL المبرمج بواسطة Mathwork
العمل يبدأ على الفور مع وجود قيود. لا يمكن لـ HDL Coder قبول وظائف المصفوفة ثنائية الأبعاد كمدخلات. بالنظر إلى أن MATLAB هي أداة للعمل مع المصفوفات ، فإن هذه ضربة خطيرة لكود كامل الموروثة ، والتي يمكن أن تصبح مشكلة خطيرة. إذا تم كتابة الكود من الصفر ، فهذه ميزة غير سارة يجب مراعاتها. لذلك عليك نشر جميع المصفوفات في المتجه وتنفيذ الوظائف مع مراعاة متجهات الإدخال.
رمز الوظيفة في MATLAB هو كما يلي
function [out] = mhls_conv2_manually(target,kernel) len = length(kernel); mult = target.*kernel; summ = sum(mult); out = summ/len; end
لقد تبين أن كود HDL الذي تم إنشاؤه منتفخ للغاية ويحتوي على مئات الأسطر ، لذا لن أعطيها هنا. دعونا نرى ما مخطط Quartus توليفها من هذا الرمز.
 الشكل 11
الشكل 11هذا المخطط يبدو غير ناجح. إنه يعمل بشكل رسمي ، لكنني أفترض أنه سيعمل بتردد منخفض جدًا ، ولا يمكن استخدامه في أجهزة حقيقية. ولكن يجب التحقق من أي افتراض. للقيام بذلك ، سنضع السجلات في مدخلات ومخرجات هذه الدائرة وبمساعدة Timing Analyzer ، سنقوم بتقييم الوضع الحقيقي. لإجراء التحليل ، يجب عليك تحديد تردد التشغيل المطلوب للدائرة حتى يعلم Quartus بما يجب السعي إليه عند تقديم الأسلاك ، وفي حالة حدوث عطل ، يقدم تقارير عن الانتهاكات.
لقد حددنا التردد على 100 ميجاهرتز ، لنرى ما يمكن للرباعية إخراجه من الدائرة المقترحة.
 الشكل 12
الشكل 12يمكن أن نرى أنه اتضح قليلاً: 33 ميغاهيرتز تبدو تافهة. التأخير في سلسلة المضاعفات والإضافات حوالي 30 نانوثانية. للتخلص من هذا "عنق الزجاجة" ، تحتاج إلى استخدام الناقل: إدراج السجلات بعد العمليات الحسابية ، وبالتالي تقليل المسار الحرج.
HDL المبرمج يعطينا هذه الفرصة. في علامة التبويب "خيارات" ، يمكنك تعيين متغيرات خطوط الأنابيب. نظرًا لأن الشفرة المعنية تتم كتابتها بأسلوب MATLAB ، فلا توجد طريقة لمتغيرات خطوط الأنابيب (باستثناء متغيرات mult و summ) ، والتي لا تناسبنا. من الضروري إدخال السجلات في الدوائر الوسيطة المخفية في رمز HDL الخاص بنا.
علاوة على ذلك ، يمكن أن يكون الوضع مع التحسين أسوأ. على سبيل المثال ، لا شيء يمنعنا من كتابة التعليمات البرمجية
out = (sum(target.*kernel))/len;
إنه مناسب تمامًا لـ MATLAB ، ولكنه يحرمنا تمامًا من إمكانية تحسين HDL.
المخرج التالي هو تحرير الكود باليد. هذه نقطة مهمة جدًا ، حيث أننا نرفض أن نرث ونبدأ في إعادة كتابة النص m ، وليس بنمط MATLAB.
الرمز الجديد هو على النحو التالي
function [out] = mhls_conv2_manually(target,kernel) len = length(kernel); mult = target.*kernel; summ_1 = zeros([1,(len/2)]); summ_2 = zeros([1,(len/4)]); summ_3 = zeros([1,(len/8)]); for i=0:1:(len/2)-1 summ_1(i+1) = (mult(i*2+1)+mult(i*2+2)); end for i=0:1:(len/4)-1 summ_2(i+1) = (summ_1(i*2+1)+summ_1(i*2+2)); end for i=0:1:(len/8)-1 summ_3(i+1) = (summ_2(i*2+1)+summ_2(i*2+2)); end out = summ_3/len; end
في Quartus ، نجمع الشفرة التي تم إنشاؤها بواسطة HDL Coder. يمكن ملاحظة أن عدد الطبقات ذات العناصر البدائية قد انخفض ، ويبدو المخطط أفضل بكثير.
 الشكل 12
الشكل 12مع التصميم الصحيح للبدائل ، ينمو التردد 3 مرات تقريبًا ، ويصل إلى 88 ميجاهرتز.
 الشكل 13
الشكل 13الآن اللمسة الأخيرة: في إعدادات التحسين ، حدد summ_1 و summ_2 و summ_3 كعناصر في خط الأنابيب. نقوم بجمع الكود الناتج في Quartus. يتغير المخطط كما يلي:
 الشكل 14
الشكل 14يزيد الحد الأقصى للتردد مرة أخرى والآن تبلغ قيمته حوالي 195 ميغاهيرتز.
 الشكل 15
الشكل 15كم عدد الموارد على الشريحة سوف تتخذ مثل هذا التصميم؟ يوضح الشكل 16 جدول الموارد المستخدمة للحالة الموصوفة.
 الشكل 16
الشكل 16ما هي الاستنتاجات التي يمكن استخلاصها بعد النظر في هذا المثال؟
العيب الرئيسي لمشفرات HDL هو أنه من غير المرجح أن تستخدم كود MATLAB في شكله النقي.
لا يوجد دعم للمصفوفات كمدخلات للدالة ، ويكون تخطيط الكود في نمط MATLAB دون المتوسط.
الخطر الرئيسي هو عدم وجود سجلات في الكود الذي تم إنشاؤه دون إعدادات إضافية. بدون هذه السجلات ، وحتى بعد تلقي كود HDL العامل رسميًا دون أخطاء في بناء الجملة ، فإن استخدام هذا الرمز في الواقع والتطورات الحديثة أمر غير مرغوب فيه.
من المستحسن أن يكتب على الفور شفرة شحذ لتحويل HDL. في هذه الحالة ، يمكنك الحصول على نتائج مقبولة تمامًا من حيث السرعة وكثافة الموارد.
إذا كنت من مطوري MATLAB ، فلا تتعجل في النقر فوق الزر "تشغيل" وتجميع التعليمات البرمجية الخاصة بك ضمن FPGA ، تذكر أن التعليمات البرمجية الخاصة بك سيتم توليفها في دائرة حقيقية. =)
إنتل HLS مترجم
لنفس الوظيفة ، كتبت رمز C / C ++ التالي
component unsigned int conv(unsigned char *data, unsigned char *kernel) { unsigned int mult_res[16]; unsigned int summl; summl = 0; for (int i = 0; i < 16; i++) { mult_res[i] = data[i] * kernel[i]; summl = summl+mult_res[i]; } return summl/16; }
أول ما يلفت انتباهك هو مقدار الموارد المستخدمة.
 الشكل 17
الشكل 17يمكن أن نرى من الجدول أنه تم استخدام كتلة DSP واحدة فقط ، لذلك حدث خطأ ما ، ولا يتم إجراء الضرب بشكل متوازٍ. عدد السجلات المستخدمة أمر مفاجئ أيضًا ، وحتى الذاكرة متورطة ، لكننا سنترك هذا لضمير برنامج التحويل البرمجي HLS.
تجدر الإشارة إلى أن برنامج التحويل البرمجي HLS قد طور دون المستوى الأمثل ، باستخدام كمية هائلة من الموارد الإضافية ، ولكن لا يزال يعمل دائرة ، وفقا لتقارير Quartus ، ستعمل على تردد مقبول ، وهذا الفشل لن يعمل المبرمج HDL.
 الشكل 18
الشكل 18دعونا نحاول تحسين الوضع. ما هو المطلوب لهذا؟ هذا صحيح ، تغمض عينيك عن الميراث والزحف إلى رمز ، ولكن حتى الآن ليس كثيرا.
HLS لديه توجيهات خاصة لتحسين رمز FPGA. ندرج التوجيه unroll ، والذي يجب أن يوسع حلقة لدينا بالتوازي:
#pragma unroll for (int i = 0; i < 16; i++) { mult_res[i] = data[i] * kernel[i]; }
دعونا نرى كيف كان رد فعل Quartus لذلك
 الشكل 19
الشكل 19بادئ ذي بدء ، انتبه إلى عدد كتل DSP - هناك 16 منها ، مما يعني أنه يتم إجراء الضرب بشكل متوازٍ.
الصيحة! إفتح الأعمال! لكن من الصعب بالفعل تحمل مقدار نمو استخدام الموارد الأخرى. أصبحت الدائرة غير قابلة للقراءة تماما.
 الشكل 20
الشكل 20أعتقد أن هذا يرجع إلى حقيقة أنه لم يشر أحد إلى المترجم إلى أن الحسابات بأرقام النقاط الثابتة مناسبة تمامًا لنا ، وقد طبق بصدق جميع رياضيات الفاصلة العائمة على المنطق والسجلات. نحتاج أن نوضح للمترجم ما هو مطلوب منه ، ولهذا فإننا نغرق مرة أخرى في الكود.
لغرض استخدام النقطة الثابتة ، يتم تنفيذ فئات القوالب.
 الشكل 21
الشكل 21عند التحدث بكلماتنا الخاصة ، يمكننا استخدام المتغيرات التي يتم ضبط عمق البت فيها يدويًا إلى حد ما. بالنسبة لأولئك الذين يكتبون HDL ، لا يمكنك التعود على ذلك ، ولكن من المحتمل أن يقوم مبرمجو C / C ++ برؤوس رؤوسهم. أعماق البت ، كما في MATLAB ، في هذه الحالة ، لن يخبر أحد ، ويجب على المطور نفسه حساب عدد البتات.
دعونا نرى كيف يبدو في الممارسة العملية.
نقوم بتحرير الكود كما يلي:
component ac_fixed<16,16,false> conv(ac_fixed<8,8,false> *data, ac_fixed<8,8,false> *kernel) { ac_fixed<16,16,false>mult_res[16]; ac_fixed<32,32,false>summl; #pragma unroll for (int i = 0; i < 16; i++) { mult_res[i] = data[i] * kernel[i]; } for (int i = 0; i < 16; i++) { summl = summl+mult_res[i]; } return summl/16; }
وبدلاً من المعكرونة المخيفة من الشكل 20 ، نحصل على هذا الجمال:
 الشكل 22
الشكل 22لسوء الحظ ، لا يزال هناك شيء غريب يحدث مع الموارد المستخدمة.
 الشكل 23
الشكل 23لكن مراجعة مفصلة للتقارير تظهر أن الوحدة التي تهمنا مباشرة تبدو أكثر من كافية:
 الشكل 24
الشكل 24يرتبط الاستهلاك الضخم للسجلات وذاكرة الكتلة بعدد كبير من الوحدات الطرفية. ما زلت لا أفهم تمامًا المعنى العميق لوجودهم ، وسيحتاج الأمر إلى حل ، لكن المشكلة تم حلها. في الحالة القصوى ، يمكنك استبعاد وحدة واحدة من اهتماماتنا عن البنية العامة للمشروع ، والتي ستوفر لنا من الوحدات الطرفية التي تلتهم الموارد.
الاختبار الثالث. "الانتقال من RGB إلى HSV"
بدأت في كتابة هذا المقال ، لم أكن أتوقع أن تكون ضخمة للغاية. لكن لا يمكنني رفض المثال الثالث والأخير في إطار هذه المقالة ، على سبيل المثال.
أولاً ، هذا مثال حقيقي من ممارستي ، ولهذا السبب بدأت في البحث عن أدوات تطوير رفيعة المستوى.
ثانياً ، من المثالين الأولين ، يمكننا أن نفترض أنه كلما كان التصميم أكثر تعقيدًا ، ازدادت سوءًا مواجهة الأدوات الرفيعة المستوى للمهمة.
أريد أن أوضح أن هذا الحكم خاطئ ، وفي الواقع ، كلما زادت المهمة تعقيدًا ، تجلت مزايا أدوات التطوير عالية المستوى.
في العام الماضي ، عندما كنت أعمل في أحد المشاريع ، لم أحب الكاميرا التي تم شراؤها في Aliexpress ، أي أن الألوان لم تكن مشبعة بما فيه الكفاية. تتمثل إحدى الطرق الشائعة لتغيير تشبع اللون في التبديل من مساحة ألوان RGB إلى مساحة HSV ، حيث تكون إحدى المعلمات هي التشبع. أتذكر كيف فتحت الصيغة الانتقالية وأخذت نفسًا عميقًا ... تطبيق هذه الحسابات في FPGA ليس شيئًا غير عادي ، لكن بالطبع سوف يستغرق الأمر وقتًا لكتابة التعليمات البرمجية. لذلك ، فإن الصيغة للتبديل من RGB إلى HSV هي كما يلي:
 الشكل 25
الشكل 25لن يستغرق تنفيذ مثل هذه الخوارزمية في FPGA أيامًا ، بل ساعات ، وكل هذا يجب أن يتم بعناية فائقة بسبب تفاصيل HDL ، والتنفيذ في C ++ أو في MATLAB سيستغرق ، على ما أعتقد ، دقائق.
في C ++ ، يمكنك كتابة التعليمات البرمجية مباشرة في الجبهة ولا تزال تحصل على نتيجة عملية.
كتبت الخيار التالي في C ++
struct color_space{ unsigned char rh; unsigned char gs; unsigned char bv; }; component color_space rgb2hsv(color_space rgb_0) { color_space hsv; float h,s,v,r,g,b; float max_col, min_col; r = static_cast<float>(rgb_0.rh)/255; g = static_cast<float>(rgb_0.gs)/255; b = static_cast<float>(rgb_0.bv)/255; max_col = std::max(std::max(r,g),b); min_col = std::min(std::min(r,g),b);
ونفذت Quartus النتيجة بنجاح ، كما يتبين من جدول الموارد المستخدمة.
 الشكل 26
الشكل 26التردد جيد جدا
 الشكل 27
الشكل 27مع HDL المبرمج ، الأمور معقدة بعض الشيء.
من أجل عدم تضخيم المقالة ، لن أقدم نصًا m لهذه المهمة ، فلا ينبغي أن يسبب صعوبات. بالكاد يمكن استخدام برنامج نصي m مكتوب في الجبهة بنجاح ، ولكن إذا قمت بتحرير الكود وتحديد أماكن خطوط الأنابيب بشكل صحيح ، فسنحصل على نتيجة عملية. هذا ، بالطبع ، سوف يستغرق عدة دقائق ، ولكن ليس ساعات.
C++ , .
, , , , — , FPGA , HDL.
استنتاج
.
, , , .
, , . , , HDL, .
, FPGA FPGA . .
, — FPGA.
HLS compiler : , , , “best practices” .. MATLAB, , GUI , , , , , .
? — Intel HLS compiler. . HDL coder . , HDL coder , , . HLS, , , FPGA , .
Xilinx , — FPGA. , , Verilog/VHDL , . ( ), .
? , , , HDL .
, , , , .