في الآونة الأخيرة ، تم
إصدار مقال يوضح اتجاهًا جيدًا في التعلم الآلي في السنوات الأخيرة. باختصار: انخفض عدد الشركات الناشئة في مجال التعلم الآلي انخفاضًا حادًا في العامين الماضيين.
حسنا ماذا. دعنا نحلل "ما إذا كانت الفقاعة تنفجر" ، "كيفية الاستمرار في العيش" ونتحدث عن مصدر هذا التمايل.
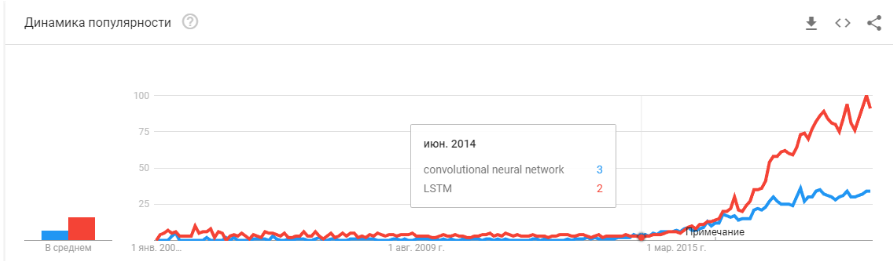
أولاً ، دعنا نتحدث عن ما كان الداعم لهذا المنحنى. من أين أتت؟ ربما يتذكر الجميع
انتصار التعلم الآلي في عام 2012 في مسابقة ImageNet. بعد كل شيء ، هذا هو الحدث العالمي الأول! ولكن في الواقع هذا ليس كذلك. ونمو المنحنى يبدأ قبل ذلك بقليل. وأود أن كسرها إلى عدة نقاط.
- 2008 هو ظهور مصطلح "البيانات الضخمة". بدأت المنتجات الحقيقية في الظهور في عام 2010. البيانات الكبيرة مرتبطة مباشرة بالتعلم الآلي. بدون بيانات كبيرة ، يكون التشغيل المستقر للخوارزميات الموجودة في ذلك الوقت مستحيلًا. وهذه ليست شبكات عصبية. حتى عام 2012 ، كانت الشبكات العصبية هي أقلية هامشية. ولكن بعد ذلك ، بدأت خوارزميات مختلفة تمامًا في العمل ، والتي كانت موجودة منذ سنوات وحتى عقود: SVM (1963 ، 1993) ، Random Forest (1995) ، AdaBoost (2003) ، ... الشركات الناشئة في تلك السنوات مرتبطة أساسًا بالمعالجة التلقائية للبيانات المهيكلة : مكاتب التذاكر والمستخدمين والإعلان ، وأكثر من ذلك بكثير.
مشتق هذه الموجة الأولى هو مجموعة من الأطر مثل XGBoost ، CatBoost ، LightGBM ، إلخ.
- في 2011-2012 ، فازت الشبكات العصبية التلافيفية بسلسلة من مسابقات التعرف على الصور. استخدامها الفعلي تأخر إلى حد ما. أود أن أقول إن الشركات الناشئة ذات الحلول الضخمة والحلول بدأت تظهر في عام 2014. استغرق الأمر عامين لاستيعاب أن الخلايا العصبية لا تزال تعمل ، لإنشاء أطر ملائمة يمكن تثبيتها وتشغيلها في فترة زمنية معقولة ، لتطوير طرق من شأنها أن تعمل على استقرار وتسريع وقت التقارب.
أتاحت الشبكات التلافيفية حل مشاكل رؤية الماكينة: تصنيف الصور والكائنات في صورة ما ، واكتشاف الكائنات ، والتعرف على الأشياء والأشخاص ، وتحسين الصورة ، وما إلى ذلك ، إلخ. - 2015-2017 سنوات. ازدهار الخوارزميات والمشاريع المرتبطة بتكرار الشبكات أو نظائرها (LSTM ، GRU ، TransformerNet ، إلخ). ظهرت خوارزميات تحويل النص إلى نص بشكل جيد وأنظمة الترجمة الآلية. تعتمد جزئيًا على الشبكات التلافيفية لتسليط الضوء على الميزات الأساسية. جزئيًا على حقيقة أنهم تعلموا جمع مجموعات بيانات كبيرة وجيدة حقًا.
"هل انفجرت الفقاعة؟" هل الضجيج المحموم؟ هل ماتوا مثل blockchain؟ "
حسنا اذن! سوف يتوقف Tom Siri عن العمل على هاتفك ، ولن تميز Tesla في اليوم التالي للغد عن الكنغر.
الشبكات العصبية تعمل بالفعل. هم في العشرات من الأجهزة. إنها تسمح لك حقًا بالكسب وتغيير السوق والعالم من حولك. يبدو الضجيج مختلفًا بعض الشيء:
إنه مجرد توقف الشبكات العصبية عن أن تكون شيئًا جديدًا. نعم ، كثير من الناس لديهم توقعات كبيرة. لكن عددًا كبيرًا من الشركات تعلمت استخدام الخلايا العصبية الخاصة بها وصنع منتجات بناءً عليها. توفر الخلايا العصبية وظائف جديدة ، ويمكن أن تقلل الوظائف ، وتقلل من سعر الخدمات:
- شركات التصنيع دمج خوارزميات لتحليل الرفض على الناقل.
- تقوم مزارع المواشي بشراء أنظمة للسيطرة على الأبقار.
- حصادات التلقائي.
- مراكز الاتصال الآلي.
- المرشحات في سناب شات. (
حسنا ، على الأقل شيء معقول! )
لكن الشيء الرئيسي ، وليس الأكثر وضوحًا: "لم تعد هناك أفكار جديدة ، أو أنها لن تجلب رؤوس أموال فورية". الشبكات العصبية قد حلت العشرات من المشاكل. وسوف يقررون أكثر. جميع الأفكار الواضحة التي - ولدت الكثير من الشركات الناشئة. لكن كل ما كان على السطح قد تم جمعه بالفعل. على مدار العامين الماضيين ، لم أقابل فكرة واحدة جديدة لاستخدام الشبكات العصبية. ليست طريقة جديدة واحدة (حسنًا ، حسنًا ، هناك بعض المشكلات مع شبكات GAN).
وكل بدء التشغيل التالي هو أكثر وأكثر تعقيدا. لا يتطلب الأمر وجود شخصين يدربان الخلايا العصبية على البيانات المفتوحة. يتطلب المبرمجين ، خادم ، فريق من المكتبيين ، دعم معقد ، إلخ.
نتيجة لذلك ، هناك عدد أقل من الشركات الناشئة. لكن الإنتاج أكثر. تحتاج إلى إرفاق لوحة الاعتراف الاعتراف؟ هناك المئات من المهنيين ذوي الخبرة ذات الصلة في السوق. يمكنك التوظيف وفي غضون شهرين سيقوم موظفك بإنشاء نظام. أو شراء واحدة النهائي. ولكن القيام بدء التشغيل الجديد؟ .. الجنون!
نحتاج إلى إنشاء نظام لتتبع الزائرين - لماذا ندفع مقابل مجموعة من التراخيص ، عندما يمكنك القيام بذلك لمدة 3 إلى 4 أشهر ، قم بتشديده لعملك.
الآن الشبكات العصبية تسير بنفس الطريقة مثل العشرات من التقنيات الأخرى.
تذكر كيف تغير مفهوم "مطور الموقع" منذ عام 1995؟ في حين أن السوق ليس مشبعًا بالمتخصصين. هناك عدد قليل جدا من المهنيين. لكنني أراهن أنه خلال 5-10 سنوات لن يكون هناك فرق كبير بين مبرمج جافا ومطور الشبكة العصبية. وهؤلاء وهؤلاء المتخصصين سيكون كافيا في السوق.
سيكون هناك ببساطة فئة من المهام التي يتم حلها بواسطة الخلايا العصبية. كان هناك مهمة - استئجار متخصص.
"ثم ماذا؟ أين الذكاء الاصطناعي الموعود؟ "وهنا هناك neponyatchka صغيرة ولكنها مثيرة للاهتمام :)
كومة التقنية الموجودة اليوم ، على ما يبدو ، لن تقودنا إلى الذكاء الاصطناعي. الأفكار ، والجدة ، قد استنفدت إلى حد كبير أنفسهم. دعونا نتحدث عن ما يحمل المستوى الحالي للتنمية.
قيود
لنبدأ مع الطائرات بدون طيار. يبدو أنه من المفهوم أنه من الممكن تصنيع سيارات مستقلة تمامًا باستخدام تقنيات اليوم. ولكن بعد كم سنة سيحدث هذا غير واضح. تعتقد تسلا أن هذا سيحدث في غضون عامين -
هناك العديد من
المتخصصين الآخرين الذين قيموا هذا من 5 إلى 10 سنوات.
على الأرجح ، في رأيي ، بعد 15 عامًا ، ستتغير البنية التحتية للمدن بحد ذاتها بحيث يصبح ظهور السيارات المستقلة أمرًا لا مفر منه ، وسيكون استمراره. لكن هذا لا يمكن اعتباره ذكاء. Modern Tesla عبارة عن خط أنابيب معقد جدًا لتصفية البيانات والبحث عنها وإعادة التدريب. هذه هي القواعد ، والقواعد ، والقواعد ، وجمع البيانات ، والمرشحات فوقها (
هنا كتبت أكثر قليلاً عن ذلك ، أو أنظر من
هذه النقطة).
المشكلة الأولى
وهنا نرى
المشكلة الأساسية الأولى . البيانات الكبيرة. هذا هو بالضبط ما تولد الموجة الحالية من الشبكات العصبية والتعلم الآلي. الآن ، للقيام بشيء معقد وتلقائي ، تحتاج إلى الكثير من البيانات. ليس فقط الكثير ، ولكن كثيرًا جدًا. نحتاج إلى خوارزميات آلية لجمعها وترميزها واستخدامها. نريد أن نجعل السيارة ترى الشاحنات ضد الشمس - يجب أن نجمع أولاً عددًا كافيًا منها. نريد أن لا تصاب السيارة بالجنون بدراجة مثبتة في صندوق السيارة - المزيد من العينات.
علاوة على ذلك ، مثال واحد لا يكفي. مئات؟ الآلاف؟

المشكلة الثانية
المشكلة الثانية هي تصور ما فهمته شبكتنا العصبية. هذه مهمة غير تافهة للغاية. حتى الآن ، قليل من الناس يفهمون كيفية تصور هذا. هذه المقالات حديثة للغاية ، وهذه مجرد أمثلة قليلة ، حتى تلك البعيدة:
التصور من التثبيت على القوام. إنه يظهر جيدًا حول ما تميل الخلايا العصبية إلى الذهاب إليه في دورات + ما تعتبره معلومات أولية.
 تصور
تصور التوهين أثناء
الترجمات . حقًا ، يمكن في الغالب استخدام التوهين بشكل دقيق لإظهار سبب تفاعل الشبكة هذا. لقد قابلت مثل هذه الأشياء لتصحيح الأخطاء ولحلول المنتج. هناك الكثير من المقالات حول هذا الموضوع. لكن كلما زادت تعقيد البيانات ، زاد صعوبة فهم كيفية تحقيق التصور المستدام.

حسنًا ، نعم ، المجموعة القديمة الجيدة من "انظر إلى ما هي الشبكة الموجودة داخل
المرشحات ". كانت هذه الصور شائعة منذ حوالي 3-4 سنوات ، ولكن سرعان ما أدرك الجميع أن الصور جميلة ، لكن ليس هناك شعور كبير بها.

لم أقم بتسمية العشرات من المستحضرات والطرق والخارقة والدراسات الأخرى حول كيفية عرض الدواخل الداخلية للشبكة. هل تعمل هذه الأدوات؟ هل يساعدونك بسرعة على فهم ماهية المشكلة وتصحيح الشبكة؟ .. سحب النسبة المئوية الأخيرة؟ حسنًا ، شيء مثل هذا:

يمكنك مشاهدة أي مسابقة في Kaggle. ووصف كيف يتخذ الناس القرارات النهائية. وصلنا 100-500-800 نموذج مولينوف وعملت!
بالطبع ، أنا أبالغ. لكن هذه الأساليب لا تعطي إجابات سريعة ومباشرة.
امتلاك الخبرة الكافية ، بعد اختيار خيارات مختلفة ، يمكنك إصدار حكم حول سبب اتخاذ نظامك لهذا القرار. لكن تصحيح سلوك النظام سيكون صعباً. ضع عكازاً ، انقل العتبة ، أضف مجموعة بيانات ، خذ شبكة خلفية أخرى.
المشكلة الثالثة
المشكلة الأساسية الثالثة هي أن الشبكات لا تعلم المنطق ، ولكن الإحصائيات. إحصائيا هذا
الشخص :

منطقيا - ليست مشابهة جدا. الشبكات العصبية لا تتعلم شيئًا معقدًا إذا لم تكن مجبرة. يتعلمون دائما أبسط الأعراض. هل لديك عيون ، أنف ، رأس؟ لذلك هذا الوجه! أو إعطاء مثال حيث العينين لن يعني الوجه. ومرة أخرى ، ملايين الأمثلة.
هناك الكثير من الغرفة في القاع
أود أن أقول إن هذه المشكلات العالمية الثلاثة هي التي تحد اليوم من تطور الشبكات العصبية والتعلم الآلي. وحيث لا تقتصر هذه المشاكل على استخدامها بالفعل بنشاط.
هل هذه هي النهاية؟ نهض الشبكات العصبية؟غير معروف. لكن ، بالطبع ، الكل لا يأمل.
هناك العديد من الطرق والتوجيهات لحل تلك المشكلات الأساسية التي تناولتها أعلاه. لكن حتى الآن ، لم يسمح لنا أي من هذه الأساليب بعمل شيء جديد بشكل أساسي ، لحل شيء لم يتم حله بعد. حتى الآن ، تتم جميع المشاريع الأساسية على أساس نهج مستقرة (تسلا) ، أو تظل مشاريع اختبار للمعاهد أو الشركات (Google Brain ، OpenAI).
بمعنى تقريبي ، الاتجاه الرئيسي هو إنشاء تمثيل رفيع المستوى لبيانات الإدخال. بمعنى ما ، "الذاكرة". أبسط مثال على الذاكرة هو تمثيلات "تضمين" الصور المختلفة. حسنًا ، على سبيل المثال ، جميع أنظمة التعرف على الوجوه. تتعلم الشبكة الحصول على فكرة ثابتة معينة من الوجه لا تعتمد على الدوران والإضاءة والدقة. في الواقع ، تقلل الشبكة مقياس "الوجوه المختلفة - البعيدة" و "المتطابقة - الإغلاق".

مثل هذا التدريب يتطلب عشرات ومئات الآلاف من الأمثلة. لكن النتيجة تجلب بعض أساسيات "التعلم بنقرة واحدة". الآن نحن لسنا بحاجة إلى مئات الوجوه لتذكر شخص. وجه واحد فقط ، وهذا كل شيء -
سنكتشف !
هنا فقط المشكلة ... يمكن أن تتعلم الشبكة فقط كائنات بسيطة إلى حد ما. عند محاولة التمييز بين الوجوه ، ولكن ، على سبيل المثال ، "أشخاص يرتدون ملابس" (مهمة
إعادة التوضيح ) ، تفشل الجودة بعدة أوامر. ولم تعد الشبكة قادرة على تعلم تغييرات زاوية واضحة.
والتعلم من الملايين من الأمثلة هو الترفيه بطريقة أو بأخرى.
هناك عمل للحد من الانتخابات بشكل كبير. على سبيل المثال ، يمكنك أن تتذكر على الفور أحد أول أعمال
Google OneShot Learning :
هناك العديد من هذه الأعمال ، على سبيل المثال
1 أو
2 أو
3 .
هناك ناقص واحد - عادة ما يعمل التدريب بشكل جيد على بعض "أمثلة MNIST'ovskie البسيطة". وفي الانتقال إلى المهام المعقدة - تحتاج إلى قاعدة كبيرة أو نموذج من الكائنات أو نوع من السحر.
بشكل عام ، يعد العمل على تدريب One-Shot موضوعًا مثيرًا للاهتمام. تجد الكثير من الأفكار. لكن بالنسبة للجزء الأكبر ، فإن المشكلتين اللتين قمت بإدراجهما (التدريب المسبق على مجموعة بيانات ضخمة / عدم الاستقرار على البيانات المعقدة) تعيقان التعلم.
من ناحية أخرى ، تقترب GAN - الشبكات التنافسية بشكل عام - من التضمين. ربما قرأت مجموعة من المقالات حول هذا الموضوع على حبري. (
1 ،
2 ،
3 )
تتمثل إحدى ميزات GAN في تكوين بعض مساحة الحالة الداخلية (بشكل أساسي نفس التضمين) ، والذي يسمح لك برسم صورة. يمكن أن يكون
الأشخاص ، يمكن أن يكون هناك
إجراءات .
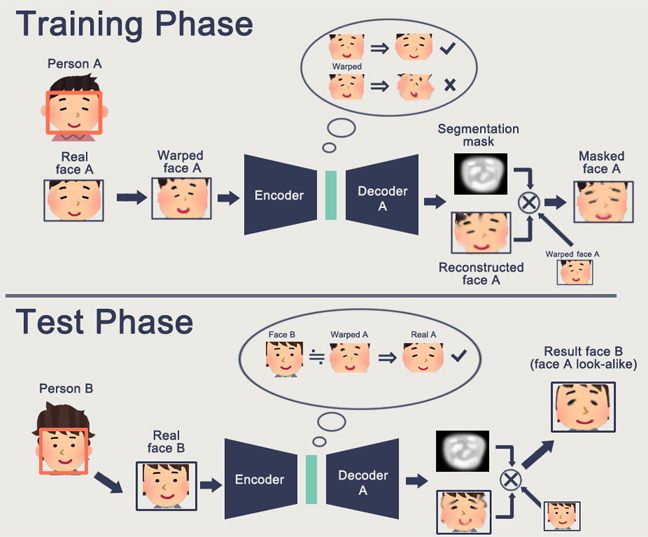
تتمثل مشكلة GAN في أنه كلما زاد تعقيد الكائن الذي تم إنشاؤه ، زاد صعوبة وصفه في منطق "المولد المولد". نتيجة لذلك ، من التطبيقات الحقيقية لشبكة GAN ، والتي تُسمع فقط DeepFake ، والتي ، مرة أخرى ، تتعامل مع تمثيلات الأفراد (التي توجد لها قاعدة ضخمة).
لقد واجهت عدد قليل جدا من التطبيقات المفيدة الأخرى. عادة نوع من الصافرة وهمية مع رسم الصور.
ومرة أخرى لا أحد لديه فهم كيف سيسمح لنا ذلك بالتقدم نحو مستقبل أكثر إشراقا. تمثيل المنطق / الفضاء في الشبكة العصبية أمر جيد. لكننا نحتاج إلى عدد كبير من الأمثلة ، نحن لا نفهم كيف تمثل هذه الخلايا العصبية في حد ذاتها ، ونحن لا نفهم كيفية جعل الخلايا العصبية تتذكر فكرة معقدة حقًا.
التعلم التعزيز هو نهج مختلف تماما. بالتأكيد تتذكر كيف تغلب Google على الجميع في Go. الانتصارات الأخيرة في ستاركرافت ودوتا. لكن هنا كل شيء بعيد عن أن يكون وردياً وواعداً. أفضل شيء عن RL وتعقيده هو
هذا المقال .
لتلخيص ما كتبه المؤلف لفترة وجيزة:
- النماذج من خارج الصندوق لا تناسب / تعمل بشكل سيء في معظم الحالات
- المهام العملية أسهل في حلها بطرق أخرى. لا تستخدم Boston Dynamics RL نظرًا لتعقيدها / عدم القدرة على التنبؤ / التعقيد الحسابي
- لكي تعمل RL ، فأنت بحاجة إلى وظيفة معقدة. غالبا ما يكون من الصعب إنشاء / الكتابة.
- من الصعب تدريب الموديلات. يتعين علينا قضاء الكثير من الوقت للتأرجح والخروج من أوبتيما المحلي
- ونتيجة لذلك ، من الصعب تكرار النموذج ، وعدم استقرار النموذج في أدنى تغيير
- غالبًا ما يملأ على بعض الأنماط اليسرى ، حتى مولد الأرقام العشوائية
النقطة الأساسية هي أن RL لا يعمل بعد في الإنتاج. لدى Google نوعًا من التجارب (
1 ،
2 ). لكنني لم أر نظام بقالة واحد.
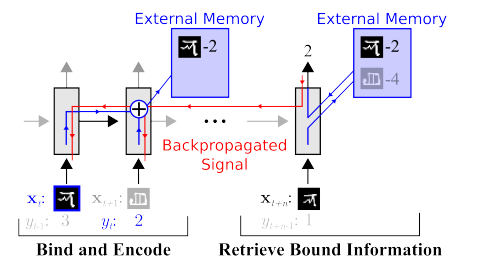
الذاكرة. الجانب السلبي من كل ما هو موضح أعلاه غير منظم. أحد الأساليب لمحاولة تنظيم كل هذا هو توفير الشبكة العصبية مع الوصول إلى ذاكرة منفصلة. حتى تتمكن من تسجيل وإعادة كتابة نتائج خطواتها هناك. ثم يمكن تحديد الشبكة العصبية حسب الحالة الحالية للذاكرة. هذا يشبه إلى حد كبير المعالجات الكلاسيكية وأجهزة الكمبيوتر.
المقال الأكثر شهرة وشعبية هو من DeepMind:
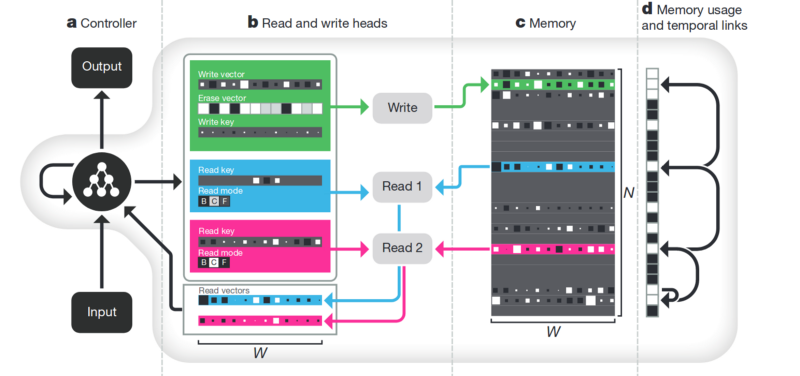
يبدو أنه هنا ، هو مفتاح فهم الذكاء؟ لكن بدلاً من ذلك ، لا. لا يزال النظام بحاجة إلى كمية هائلة من البيانات للتدريب. ويعمل بشكل رئيسي مع بيانات جدولية منظمة. في الوقت نفسه ، عندما
حل Facebook مشكلة مماثلة ، ذهبوا بالطريقة "رؤية الذاكرة ، وجعل الخلايا العصبية أكثر تعقيدًا ، ولكن المزيد من الأمثلة ، وسوف تتعلم نفسها".
الانفصال . هناك طريقة أخرى لإنشاء ذاكرة ذات معنى وهي أخذ نفس الزخارف ، ولكن عند تعلم إدخال معايير إضافية من شأنها أن تسمح لهم بتسليط الضوء على "المعاني" فيها. على سبيل المثال ، نريد تدريب شبكة عصبية للتمييز بين سلوك الشخص في المتجر. إذا اتبعنا المسار القياسي ، فسيتعين علينا إنشاء أكثر من عشرة شبكات. واحد يبحث عن شخص ، والثاني يحدد ما يفعله ، والثالث هو عمره ، والرابع هو الجنس. ينظر المنطق المنفصل إلى جزء المتجر حيث يقوم / يتعلم من أجله. الثالث يحدد مساره ، إلخ.
أو ، إذا كان هناك عدد لا نهائي من البيانات ، فسيكون من الممكن تدريب شبكة واحدة على جميع أنواع النتائج (من الواضح أنه لا يمكن كتابة هذه المجموعة من البيانات).
يخبرنا نهج الاستنباط - ودعنا ندرب الشبكة حتى تتمكن من التمييز بين المفاهيم. حتى تتمكن من تكوين تضمين في الفيديو ، حيث تحدد منطقة ما الإجراء ، أحدهما - الموضع على الأرض في الوقت المناسب ، واحد - ارتفاع الشخص ، والآخر - جنسه. في الوقت نفسه ، أثناء التدريب ، أود تقريبًا ألا أقترح أبدًا مثل هذه المفاهيم الأساسية على الشبكة ، ولكن حتى تحدد نفسها وتجمع المجالات. هناك القليل من هذه المقالات (بعضها
1 و
2 و
3 ) وبشكل عام فهي نظرية.
لكن هذا الاتجاه ، على الأقل من الناحية النظرية ، ينبغي أن يغطي المشاكل المدرجة في البداية.
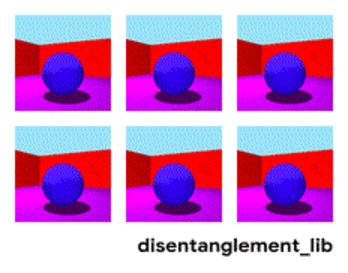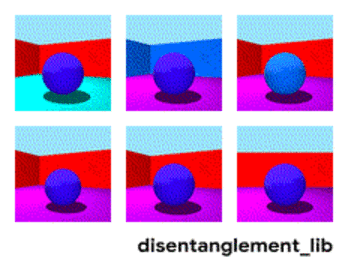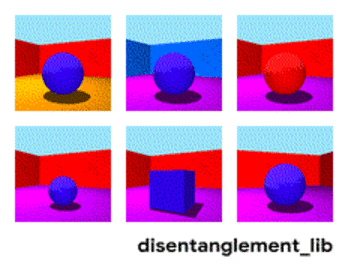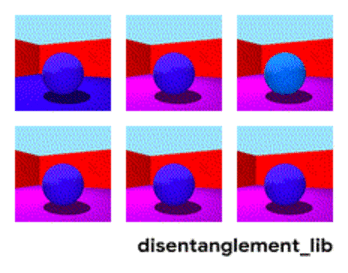
تحلل الصورة وفقًا لمعايير "لون الجدار / لون الأرض / شكل الكائن / لون الكائن / إلخ"

تحلل الوجه وفقًا لمعايير "الحجم ، الحواجب ، الاتجاه ، لون البشرة ، إلخ."
آخر
هناك العديد من الاتجاهات الأخرى غير العالمية التي تسمح لنا بتقليل القاعدة بطريقة أو بأخرى ، والعمل باستخدام المزيد من البيانات غير المتجانسة ، إلخ.
الانتباه . ربما لا يكون من المنطقي عزل هذا كطريقة منفصلة. مجرد نهج يعزز الآخرين. تم تخصيص العديد من المقالات له (
1 ،
2 ،
3 ). معنى الاهتمام هو تعزيز استجابة الشبكة للكائنات المهمة أثناء التدريب. غالبًا بواسطة بعض التعيينات المستهدفة الخارجية أو شبكة خارجية صغيرة.
محاكاة ثلاثية الأبعاد . إذا قمت بإنشاء محرك ثلاثي الأبعاد جيد ، فيمكنك غالبًا إغلاق 90٪ من بيانات التدريب به (حتى أنني رأيت مثالًا حيث تم إغلاق حوالي 99٪ من البيانات باستخدام محرك جيد). هناك العديد من الأفكار والاختراقات حول كيفية جعل شبكة مدربة على محرك ثلاثي الأبعاد يعمل على بيانات حقيقية (الضبط الدقيق ، نقل النمط ، إلخ). ولكن غالبًا ما يكون إنشاء محرك جيد أمرًا أكثر صعوبة من جمع البيانات. أمثلة عند صنع المحركات:
تدريب الروبوت (
google ،
braingarden )
تعلم كيفية
التعرف على البضائع في متجر (ولكن في مشروعين فعلناهما ، استغنينا عن هذا بهدوء)
التدريب في تسلا (مرة أخرى ، الفيديو الذي كان أعلاه).
النتائج
المادة كلها في الاستنتاجات بمعنى ما. ربما كانت الرسالة الرئيسية التي أردت القيام بها هي "أن الهدية الترويجية قد انتهت ، والخلايا العصبية لا تقدم حلولًا أكثر بساطة." الآن علينا أن نعمل بجد لبناء حلول معقدة. أو العمل بجد في عمل التقارير العلمية المعقدة.
بشكل عام ، الموضوع قابل للنقاش. ربما القراء لديهم أمثلة أكثر إثارة للاهتمام؟