بدلا من الانضمام
في وقت سابق من مدونتنا ، كتبنا
ما تقوم به IPONWEB - نحن نوفر عرض الإعلانات تلقائيًا على الإنترنت. تتخذ أنظمتنا قرارات ليس فقط على أساس البيانات التاريخية ، ولكن أيضًا تستخدم المعلومات التي يتم الحصول عليها بنشاط في الوقت الفعلي. في حالة DSP (Demand Side Platform - منصة إعلانية للمعلنين) ، يجب على المعلن (أو من يمثله) إنشاء وتحميل لافتة إعلانية (إبداعية) بأحد التنسيقات (صورة ، فيديو ، لافتة تفاعلية ، صورة + نص ، إلخ) ، وحدد جمهور المستخدمين الذين سيتم عرض هذا الشعار عليهم ، وحدد عدد المرات التي يمكن فيها عرض الإعلان لمستخدم واحد ، في أي البلدان ، وعلى أي المواقع ، وعلى أي الأجهزة ، وتعكس هذا (وأكثر من ذلك بكثير) في إعدادات الاستهداف للحملة الإعلانية ، وكذلك توزيع الإعلانات الميزانية الصورة. بالنسبة لـ SSP (منصة العرض الجانبية - منصة إعلانية لأصحاب منصات الإعلانات) ، يجب على مالك الموقع (تطبيقات الهاتف المحمول ، اللوحات الإعلانية ، القنوات التلفزيونية) تحديد نقاط الإعلان على موقعه والإشارة ، على سبيل المثال ، إلى فئات الإعلانات التي يكون مستعدًا للعرض عليها. يتم إجراء جميع هذه الإعدادات يدويًا مقدمًا (وليس في وقت عرض الإعلانات) باستخدام واجهة المستخدم. سأتحدث في هذه المقالة عن أسلوبنا في بناء مثل هذه الواجهات ، شريطة أن يكون هناك الكثير ، فهي متشابهة مع بعضها البعض وفي الوقت نفسه لها خصائص فردية.
كيف بدأ كل شيء
بدأنا الإعلان عن الأعمال في عام 2007 ، لكننا لم نفعل واجهات على الفور ، ولكن فقط في عام 2014. نحن منخرطون بشكل تقليدي في تطوير منصات مخصصة مصممة بالكامل وفقًا لخصائص العمل لكل عميل على حدة - من بين العشرات من المنصات التي أنشأناها ، لا يوجد نظامان متطابقان. ونظرًا لأن منصاتنا الإعلانية قد تم تصميمها دون قيود على إمكانيات التخصيص ، فقد تعين على واجهة المستخدم تلبية نفس المتطلبات.
عندما تلقينا الطلب الأول لواجهة إعلانات لـ DSP قبل خمس سنوات ، وقع اختيارنا على مجموعة التكنولوجيا الشهيرة والمريحة: JavaScript و AngularJS في الواجهة الأمامية ، والخلفية في Python و Django و Django Rest Framework (DRF). من هذا ، تم إجراء أكثر المشاريع العادية ، وكانت مهمتها الرئيسية توفير وظائف CRUD. كانت نتيجة عمله ملف إعدادات للنظام الإعلاني بتنسيق XML. الآن ، قد يبدو بروتوكول التفاعل هذا غريبًا ، ولكن ، كما ناقشنا بالفعل ، بدأنا في إنشاء أنظمة الإعلان الأولى (حتى بدون واجهة المستخدم) في "صفر" ، وقد تم الحفاظ على هذا التنسيق حتى يومنا هذا.
بعد الإطلاق الناجح للمشروع الأول ، لم تستغرق الأمور التالية وقتًا طويلاً. كانت هذه أيضًا واجهة المستخدم لـ DSP والمتطلبات الخاصة بها كانت هي نفسها بالنسبة للمشروع الأول. تقريبا. على الرغم من حقيقة أن كل شيء كان متشابهًا للغاية ، إلا أن الشيطان كان مختبئًا في التفاصيل - هناك تسلسل هرمي مختلف تمامًا للكائنات ، تتم إضافة حقلين هناك ... الطريقة الأكثر وضوحًا للحصول على المشروع الثاني ، تشبه جدًا الأول ، ولكن مع التحسينات ، كانت طريقة النسخ المتماثل ، التي استخدمناها . ويستتبع ذلك مشاكل مألوفة لدى الكثيرين - إلى جانب الكود "الجيد" ، تم نسخ الخلل أيضًا ، وكان من الضروري توزيع التصحيحات يدويًا. حدث الشيء نفسه مع جميع الميزات الجديدة التي تم طرحها في جميع المشاريع النشطة.
في هذا الوضع ، كان من الممكن العمل بينما كان هناك عدد قليل من المشاريع ، ولكن عندما تجاوز عددها 20 ، توقف النهج المألوف عن التوسع. لذلك ، قررنا نقل الأجزاء المشتركة للمشروعات إلى المكتبة ، حيث سيقوم المشروع بربط المكونات التي يحتاجها. في حالة اكتشاف خطأ ، يتم إصلاحه مرة واحدة في المكتبة ويتم توزيعه تلقائيًا على المشروعات عند تحديث إصدار المكتبة ، ويحدث نفس الشيء عند إعادة استخدام الميزات الجديدة.
التكوين والمصطلحات
كانت لدينا عدة تكرارات في تنفيذ هذا النهج ، وقد تدفقت جميعها مع بعضها البعض تطوريًا ، بدءًا من مشروعنا المعتاد حول DRF الخالص. في أحدث تنفيذ ، تم وصف مشروعنا باستخدام DSL المستند إلى JSON (انظر الصورة). يصف JSON كلاً من مكونات مكونات المشروع وترابطاتها ، ويمكن لكل من الواجهة الأمامية والخلفية قراءتها.
بعد تهيئة التطبيق الزاوي ، تطلب الواجهة الأمامية تهيئة JSON من الواجهة الخلفية. لا تعطي الواجهة الخلفية ملف تكوين ثابتًا فحسب ، بل تقوم أيضًا بمعالجته ، مع استكماله بمعلومات تعريفية مختلفة أو حذف أجزاء من التكوين تكون مسؤولة عن أجزاء النظام التي يتعذر على المستخدم الوصول إليها. يتيح لك ذلك عرض مختلف المستخدمين على الواجهة بطرق مختلفة ، بما في ذلك النماذج التفاعلية وأنماط CSS للتطبيق بأكمله وعناصر تصميم محددة. هذا الأخير ينطبق بشكل خاص على واجهات المستخدم من الأنظمة الأساسية التي تستخدمها أنواع مختلفة من العملاء مع أدوار مختلفة ومستويات الوصول.

الخلفية ، بخلاف الواجهة الأمامية ، تقرأ التكوين مرة واحدة في مرحلة التهيئة لتطبيق Django. وبالتالي ، يتم تسجيل كامل مقدار الوظائف على الواجهة الخلفية ، ويتم التحقق من الوصول إلى أجزاء مختلفة من النظام أثناء الطيران.
قبل الانتقال إلى الجزء الأكثر إثارة للاهتمام - بنية قاعدة البيانات - أريد تقديم العديد من المفاهيم التي نستخدمها عندما نتحدث عن بنية مشاريعنا من أجل أن نكون على نفس الطول الموجي مع القارئ.
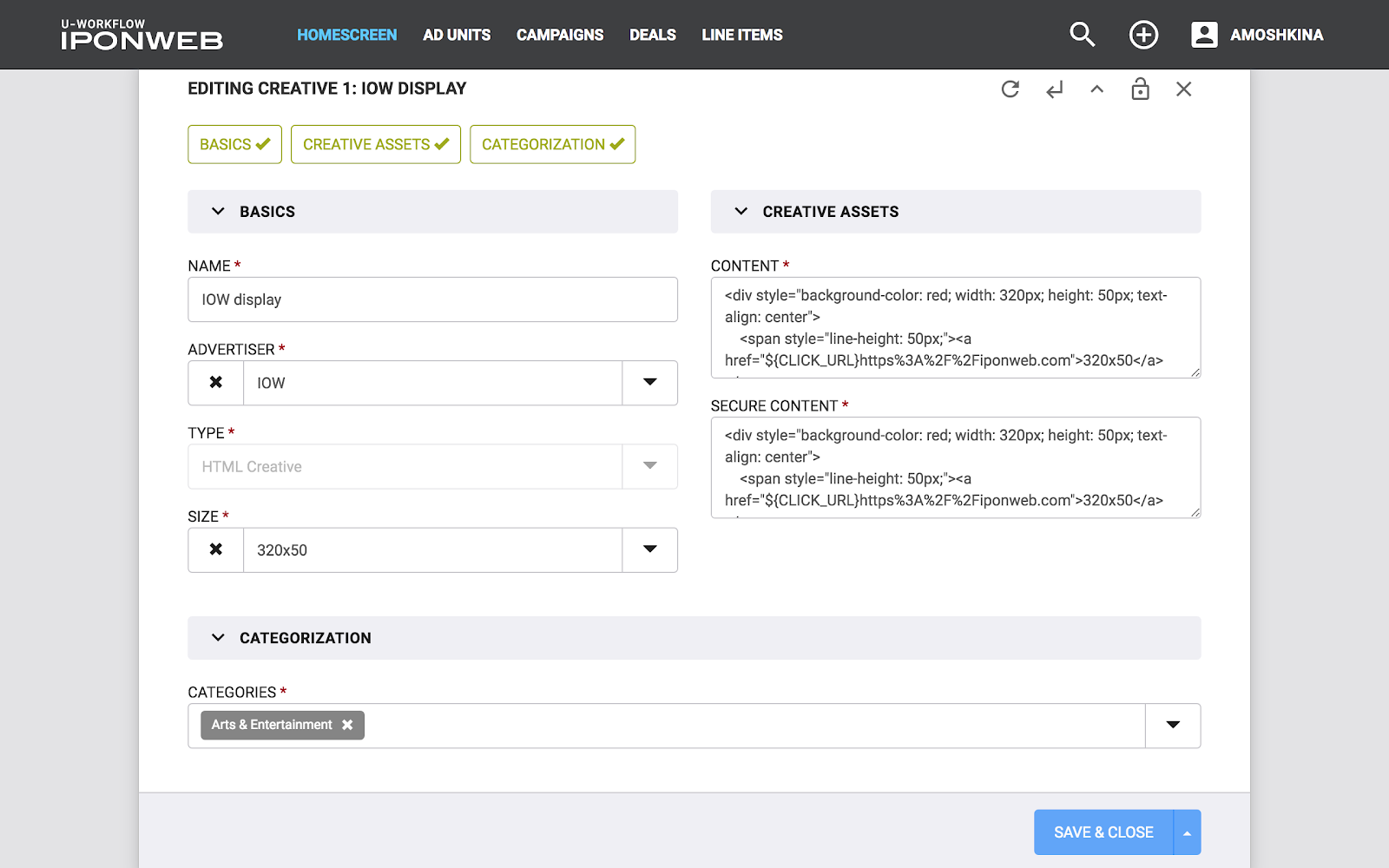
هذه المفاهيم - الكيان والميزة - موضحة جيدًا في نموذج إدخال البيانات (انظر الصورة). النموذج بالكامل هو الكيان ، والحقول الفردية الموجودة فيه هي ميزة. تظهر الصورة أيضًا نقطة النهاية (فقط في حالة). لذلك ، يعد Entity كائنًا مستقلًا في النظام يمكن إجراء عمليات CRUD عليه ، في حين أن الميزة ليست سوى جزء من "شيء أكثر" ، جزء من الكيان. باستخدام الميزة ، لا يمكنك إجراء عمليات CRUD دون ربطها بأي كيان. على سبيل المثال: ميزانية الحملة الإعلانية دون الرجوع إلى الحملة نفسها هي مجرد رقم لا يمكن استخدامه بدون معلومات عن الحملة الأم.
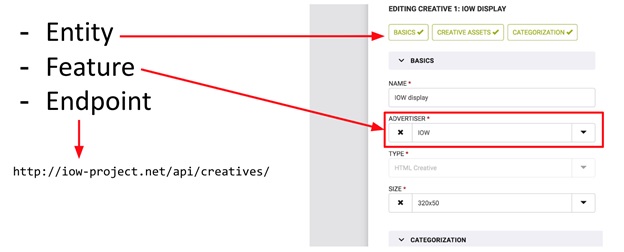
يمكن العثور على نفس المفاهيم في تكوين JSON للمشروع (انظر الصورة).

هيكل قاعدة البيانات
الجزء الأكثر إثارة للاهتمام من مشاريعنا هو هيكل قاعدة البيانات والميكانيكا التي تدعمها. بعد أن بدأت في استخدام PostgreSQL للإصدارات الأولى من مشاريعنا ، ما زلنا مع هذه التكنولوجيا اليوم. جنبا إلى جنب مع هذا ، نحن نستخدم بنشاط Django ORM. في عمليات التنفيذ المبكرة ، استخدمنا النموذج القياسي للعلاقات بين الكائنات (الكيانات) على المفتاح الخارجي ، ومع ذلك ، تسبب هذا النهج في صعوبات عندما كان من الضروري تغيير التسلسل الهرمي للعلاقات. لذلك ، على سبيل المثال ، في التسلسل الهرمي القياسي لوحدة عمل DSP -> المعلن -> الحملة ، يحتاج بعض العملاء إلى إدخال مستوى الوكالة (وحدة الأعمال -> الوكالة -> المعلن -> ...). لذلك ، تخلينا تدريجياً عن استخدام المفتاح الخارجي وننظم روابط بين الكائنات باستخدام روابط من كثير إلى كثير من خلال جدول منفصل ، نسميه "LinkRegistry".
بالإضافة إلى ذلك ، تخلينا تدريجياً عن القرص الصلب لملء الكيانات وبدأنا في تخزين معظم الحقول في جداول منفصلة ، وربطها أيضًا من خلال "LinkRegistry" (انظر الصورة). لماذا كان هذا مطلوبا؟ لكل عميل ، قد يختلف محتوى الكيان - سيتم إضافة بعض الحقول أو حذفها. اتضح أنه سيتعين علينا تخزين مجموعة من الحقول في كل كيان لجميع عملائنا. في الوقت نفسه ، يجب أن تكون جميعها اختيارية ، بحيث لا تتداخل الحقول الإلزامية "الغريبة" مع العمل.

النظر في المثال في الصورة: هنا يتم وصف هيكل قاعدة البيانات للإبداع مع حقل إضافي واحد - `image_url`. يتم تخزين معرفه فقط في الجدول الإبداعي ، ويتم تخزين image_url في جدول منفصل ، ويتم وصف العلاقة بينهما عن طريق إدخال آخر في الجدول LinkRegistry. وبالتالي ، سيتم وصف هذا التصميم من خلال ثلاثة إدخالات ، واحدة في كل جدول. وفقًا لذلك ، من أجل حفظ مثل هذا التصميم ، تحتاج إلى إنشاء إدخال في كل منها ، وقراءته بنفس الطريقة ، قم بزيارة 3 جداول. سيكون من غير المريح أن تكتب مثل هذه المعالجة في كل مرة من الصفر ، لذلك تستخلص مكتبتنا كل هذه التفاصيل من المبرمج. للعمل مع البيانات ، يستخدم Django و DRF الطرز والمسلسلات الموصوفة بواسطة الكود. في مشاريعنا ، يتم تحديد مجموعة الحقول في النماذج والمتسلسلات في وقت التشغيل من خلال تكوين JSON ، ويتم إنشاء فئات النماذج بشكل حيوي (باستخدام وظيفة الكتابة) وتخزينها في سجل خاص ، من حيث تكون متاحة أثناء تشغيل التطبيق. كما نستخدم فئات أساسية خاصة لهذه الطرز والمسلسلات ، والتي تساعد في العمل مع هيكل أساسي غير قياسي.
عند حفظ كائن جديد (أو تحديث كائن موجود) ، تدخل البيانات الواردة من الواجهة الأمامية إلى المتسلسل ، حيث يتم التحقق من صحتها - لا يوجد شيء غير عادي ، تعمل آليات DRF القياسية. ولكن يتم إعادة تعريف الادخار والتحديث هنا. يعرف المتسلسل دائمًا النموذج الذي يعمل به ، ووفقًا للتمثيل الداخلي لنموذجنا الديناميكي ، يمكنه فهم الجدول الذي يجب وضع بيانات الحقل التالي فيه. نقوم بتشفير هذه المعلومات في حقول النموذج المخصص (تذكر كيف يتم وصف "ForeignKey" في جانغو - يتم تمرير النموذج ذي الصلة داخل الحقل ، ونفعل نفس الشيء). في هذه الحقول الخاصة ، نلخص أيضًا الحاجة إلى إضافة سجل ربط ثالث إلى LinkRegistry باستخدام آلية الواصف - في الرمز الذي تكتبه {creative.image_url = 'http: // foo.bar' '، وفي الطريقة التي تم تجاوزها ، سجلناها في inset__` `LinkRegistry`.
وهذا ينطبق على الكتابة إلى قاعدة البيانات. والآن دعونا نتعامل مع القراءة. كيف يتم سحب tuple من قاعدة البيانات إلى مثيل طراز Django؟ في نموذج Django الأساسي ، هناك طريقة "from_db" ، والتي تسمى لكل مجموعة يتم تلقيها عند تنفيذ استعلام في `queryset`. عند الإدخال ، يتلقى tuple ويعيد مثيل نموذج Django. لقد قمنا بإعادة تعريف هذه الطريقة في نموذجنا الأساسي ، حيث وفقًا لنموذج النموذج الرئيسي (حيث يأتي فقط "المعرف") ، نحصل على البيانات من الجداول الأخرى ذات الصلة ، وبعد الحصول على هذه المجموعة الكاملة ، نقوم بتفعيل النموذج. بالطبع ، عملنا أيضًا على تحسين آلية الجلب المسبق لحالة الاستخدام غير القياسية لدينا.
تجريب
إطارنا معقد للغاية ، لذلك نكتب الكثير من الاختبارات. لدينا اختبارات لكل من الواجهة الأمامية والخلفية. سوف أسهب في اختبارات الخلفية بالتفصيل.
لتشغيل الاختبارات ، نستخدم pytest. في الخلفية ، لدينا فئتان كبيرتان من الاختبارات: اختبارات إطارنا (نسميها أيضًا "الأساسية") واختبارات المشروع.
في النواة ، نكتب اختبارات وحدة معزولة واختبارات وظيفية لاختبار نقاط النهاية باستخدام البرنامج المساعد pytest-django. بشكل عام ، يتم اختبار كل العمل مع قاعدة البيانات بشكل أساسي من خلال الطلبات إلى API - كما يحدث في الإنتاج.
يمكن للاختبارات الوظيفية تحديد تكوين JSON. حتى لا يتم ربطنا بمصطلحات المشروع ، نستخدم أسماء "وهمية" للكيانات التي نختبر بها ميزاتنا في النواة ("إيما" ، "آلا" ، "كارل" ، "ماريا" ، إلخ). نظرًا لكتابة ميزة image_url ، لا نريد قصر وعي المطور على أنه يمكن استخدامه فقط مع الكيان الإبداعي - الميزات والكيانات عالمية ، ويمكن ربطها ببعضها البعض في أي مجموعات ذات صلة بعميل معين.
بالنسبة إلى اختبار المشروعات ، يتم تشغيل جميع حالات الاختبار باستخدام تكوين الإنتاج ، بدون كيانات وهمية ، نظرًا لأنه من المهم بالنسبة لنا أن نتحقق بشكل دقيق مما سيعمل العميل معه. في المشروع ، يمكنك كتابة أي اختبارات تغطي ميزات المنطق التجاري للمشروع. في الوقت نفسه ، يمكن توصيل اختبارات CRUD الأساسية بالمشروع من النواة. يتم كتابتها بطريقة عامة ، ويمكن أن تكون مرتبطة بأي مشروع: يمكن لاختبار اختبار قراءة تكوين JSON للمشروع ، وتحديد الكيانات التي تتصل بها هذه الميزة ، وتشغيل الاختبارات فقط للكيانات اللازمة. من أجل راحة إعداد بيانات الاختبار ، قمنا بتطوير نظام من المساعدين القادرين أيضًا على إعداد مجموعات بيانات الاختبار بناءً على تكوين JSON. تحتل اختبارات E2E مكانًا خاصًا في اختبار المشروع على المنقلة ، والذي يختبر جميع الوظائف الأساسية للمشروع. يتم وصف هذه الاختبارات أيضًا باستخدام JSON ، حيث يتم كتابتها ودعمها بواسطة مطوري الواجهة الأمامية.
خاتمة
في هذه المقالة ، درسنا نهج التصميم المعياري الذي طورته IPONWEB في قسم واجهة المستخدم. يعمل هذا الحل بنجاح في الإنتاج منذ ثلاث سنوات. ومع ذلك ، لا يزال لهذا الحل عدد من القيود التي لا تسمح لنا بالراحة على أمجادنا. أولاً ، قاعدة الكود الخاصة بنا لا تزال معقدة للغاية. ثانياً ، يرتبط الكود الأساسي الذي يدعم النماذج الديناميكية بمكونات مهمة مثل البحث والتحميل بالجملة للكائنات وحقوق الوصول وغيرها. لهذا السبب ، يمكن أن تؤثر التغييرات في أحد المكونات بشكل كبير على المكونات الأخرى. في محاولة للتخلص من هذه القيود ، نواصل معالجة مكتبتنا بنشاط ، وتقسيمها إلى أجزاء مستقلة كثيرة وتقليل تعقيد التعليمات البرمجية. سنخبرك بالنتائج في المقالات التالية.
هذه المقالة هي نسخة موسعة من عرضي التقديمي في MoscowPythonConf ++ 2019 ، لذلك أشارك روابط
لمقاطع فيديو وشرائح .