من الناحية النظرية ، يساعد استخدام التعلم الآلي (ML) على تقليل مشاركة الإنسان في العمليات والعمليات ، وإعادة تخصيص الموارد ، وخفض التكاليف. كيف يعمل هذا في شركة معينة والصناعة؟ كما تبين تجربتنا ، وأنها تعمل.
في مرحلة معينة من التطوير ، واجهنا في شركة VTB Capital حاجة ملحة لتقليل الوقت المستغرق في معالجة طلبات الدعم الفني. بعد تحليل الخيارات ، تقرر استخدام تقنية ML لتصنيف المكالمات من المستخدمين التجاريين لكاليبسو ، منصة الاستثمار الرئيسية للشركة. تعد المعالجة السريعة لهذه الطلبات أمرًا مهمًا للجودة العالية لخدمة تكنولوجيا المعلومات. طلبنا من شركائنا الرئيسيين ،
EPAM ، المساعدة في حل هذه المشكلة.

لذلك ، يتم تلقي طلبات الدعم عن طريق البريد الإلكتروني وتحويلها إلى تذاكر في جيرا. بعد ذلك ، يقوم اختصاصيو الدعم بتصنيفهم يدويًا ، وتحديد أولوياتهم ، وإدخال بيانات إضافية (على سبيل المثال ، من القسم والمكان الذي تم استلام الطلب فيه ، والوحدة الوظيفية للنظام الذي ينتمي إليه) وتعيين فناني الأداء. في المجموع ، يتم استخدام حوالي 10 فئات من الاستعلامات. على سبيل المثال ، قد يكون هذا طلبًا لتحليل بعض البيانات وتزويد الطالب بمعلومات أو إضافة مستخدم جديد ، إلخ. علاوة على ذلك ، يمكن أن تكون الإجراءات إما قياسية أو غير قياسية ، لذلك من المهم للغاية تحديد نوع الطلب على الفور بشكل صحيح وتعيين التنفيذ إلى المتخصص المناسب.
تجدر الإشارة إلى أن VTB Capital لا ترغب فقط في تطوير حل تكنولوجي مطبق ، ولكن أيضًا لتقييم قدرات الأدوات والتقنيات المختلفة في السوق. مهمة واحدة ، طريقتان مختلفتان ، منصتان تكنولوجيا وثلاثة أسابيع ونصف: ماذا كانت النتيجة؟
النموذج الأولي رقم 1: التقنيات والنماذج
كان أساس تطوير النموذج الأولي هو النهج الذي اقترحه فريق EPAM ، والبيانات التاريخية - حوالي 10000 تذكرة من جيرا. كان التركيز الرئيسي على الحقول الثلاثة المطلوبة التي تتضمنها كل تذكرة: نوع المشكلة (نوع المشكلة) ، الملخص ("رأس" الرسالة أو موضوع الطلب) والوصف (الوصف). في إطار المشروع ، تم التخطيط لحل مشكلة تحليل النص من حقول الملخص والوصف وتحديد نوع الطلب تلقائيًا بناءً على نتائجه.
إن ميزات النص في هذين الحقلين للتذكرة هي الصعوبة التقنية الرئيسية في تحليل البيانات وتطوير نماذج ML. لذلك ، قد يحتوي حقل الملخص على نص "نظيف" تمامًا ، ولكن يتضمن كلمات ومصطلحات محددة (على سبيل المثال ،
تقارير CWS لا تعمل). يتميز حقل الوصف ، على العكس من ذلك ، بنص أكثر "قذرة" مع وفرة من الأحرف الخاصة والرموز والشرطة المائلة للخلف وبقايا العناصر غير النصية:
زملاء ديرا ،
هل يمكن أن توضح لنا ما هو الفرق بين تدابير مخاطر FX_Opt_delta_all و FX_Opt_delta_cash؟
! 01D39C59.62374C90_image001.png! )
بالإضافة إلى ذلك ، غالباً ما يجمع النص بين عدة لغات (بشكل أساسي ، بشكل طبيعي ، الروسية والإنجليزية) ، ويمكن العثور على المصطلحات التجارية ، اللغة العامية والمبرمجية العامية. وبالطبع ، نظرًا لأن الطلبات غالبًا ما تكون مكتوبة على عجل ، في كلتا الحالتين لا يتم استبعاد الأخطاء المطبعية والأخطاء الإملائية.
تضمنت التقنيات التي اختارها فريق EPAM Python 3.5 لتطوير النموذج الأولي ، و NLTK + Gensim + Re لمعالجة النصوص ، و Pandas + Sklearn لتحليل البيانات وتطوير النماذج ، و Keras + Tensorflow كإطار تعليمي عميق وخلفية.
مع الأخذ في الاعتبار الميزات المحتملة للبيانات الأولية ، تم إنشاء ثلاثة تمثيلات لاستخراج الأحرف من حقل الملخص: على مستوى الرمز ، ومجموعة من الرموز ، والكلمات الفردية. تم استخدام كل تمثيل كمدخل لشبكة عصبية متكررة.
بدوره ، تم اختيار إحصائيات حرف الخدمة (مهمة لمعالجة النص باستخدام علامات التعجب ، الشرطة المائلة ، وما إلى ذلك) ومتوسط قيم السلاسل بعد تصفية أحرف الخدمة والقمامة (للمحافظة المدمجة على بنية النص) كتمثيل لحقل الوصف ؛ وكذلك تمثيل مستوى الكلمة بعد تصفية كلمات التوقف. كان كل تمثيل بمثابة مدخل إلى الشبكة العصبية: إحصاءات في اتصال مترابط بالكامل ، سطراً تلو الآخر وعلى مستوى الكلمات - بشكل متكرر.
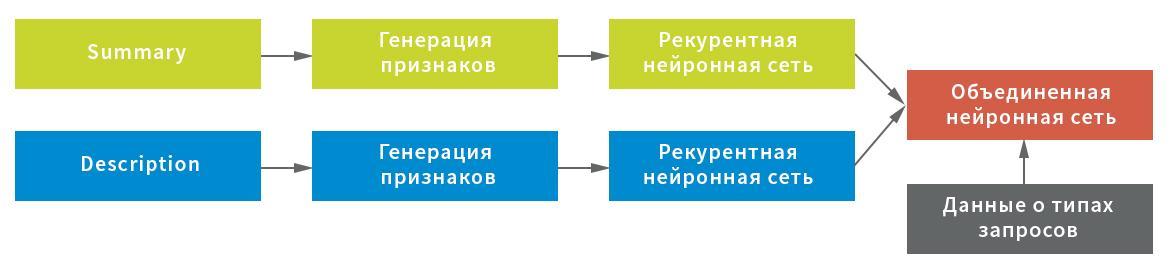
في هذا المخطط ، تم استخدام الشبكة العصبية كشبكة متكررة ، تتكون من طبقة GRU ثنائية الاتجاه مع تسرب متكرر وطبيعي ، ومجموعة من الحالات الخفية للشبكة المتكررة باستخدام طبقة GlobalMaxPool1D وطبقة (كثيفة) متصلة بالكامل مع التسرب. لكل واحد من المدخلات ، تم بناء "رأسها" الخاص بالشبكة العصبية ، ثم تم دمجها من خلال السلاسل وتأمين المتغير المستهدف.
للحصول على النتيجة النهائية ، أرجعت الشبكة العصبية المدمجة احتمالات طلب معين ينتمي إلى كل نوع. تم تقسيم البيانات إلى خمس كتل دون التقاطعات: تم بناء النموذج على أربعة منها واختبارها في الخامس. نظرًا لأن كل طلب يمكن تخصيص نوع واحد فقط من الطلبات ، فإن قاعدة اتخاذ القرار كانت بسيطة - من خلال الحد الأقصى لقيمة الاحتمال.
النموذج رقم 2: الخوارزميات ومبادئ العمل
النموذج الأولي الثاني ، الذي تم اعتماد الاقتراح الذي أعده فريق VTB Capital ، هو تطبيق على Microsoft .NET Core مع مكتبات Microsoft.ML لتنفيذ خوارزميات التعلم الآلي و Atlassian.Net SDK للتفاعل مع Jira عبر واجهة برمجة تطبيقات REST. أصبح أساس بناء نماذج ML أيضًا بيانات تاريخية - 50000 تذكرة من Jira. كما في الحالة الأولى ، غطى التعلم الآلي الحقول الملخص والوصف. قبل الاستخدام ، تم تنظيف كلا الحقلين أيضًا. تم حذف التحية والتوقيعات وتاريخ المراسلات والعناصر غير النصية (على سبيل المثال ، الصور) من خطاب المستخدم. بالإضافة إلى ذلك ، باستخدام الوظيفة المضمنة في Microsoft ML ، تم محو الكلمات التي لم تكن ذات صلة بمعالجة النص وتحليله من النص باللغة الإنجليزية.
تم اختيار Aceptaged Perceptron (التصنيف الثنائي) كخوارزمية للتعلم الآلي ، والتي يتم استكمالها باستخدام طريقة One Versus All لتوفير تصنيف متعدد الفئات
تقييم النتائج
لا يوجد نموذج ML يمكن (ربما ، حتى الآن) توفير دقة 100 ٪ من النتيجة.
توفر الخوارزمية النموذج الأولي رقم 1 حصة التصنيف الصحيح (الدقة) ، أي ما يعادل 0.8003 من إجمالي عدد الطلبات ، أو 80 ٪. علاوة على ذلك ، تبلغ قيمة المقياس المماثل في الحالة التي يُفترض فيها أن يتم اختيار الإجابة الصحيحة من قبل الشخص من الاثنين المقدمين بواسطة الحل إلى 0.901 ، أو 90٪. بالطبع ، هناك حالات يكون فيها الحل الذي تم تطويره يعمل بشكل أسوأ أو لا يستطيع إعطاء الإجابة الصحيحة - كقاعدة عامة ، بسبب مجموعة قصيرة جدًا من الكلمات أو خصوصية المعلومات في الطلب نفسه. لا يزال الدور يؤديه عدم كفاية كمية البيانات المستخدمة في عملية التعلم. وفقًا للتقديرات الأولية ، فإن زيادة حجم المعلومات التي تمت معالجتها ستمكن من زيادة دقة التصنيف بمقدار 0.01-0.03 نقطة أخرى.
يتم تقييم نتائج أفضل نموذج في مقاييس الدقة (الدقة) والاكتمال (التذكير) على النحو التالي:

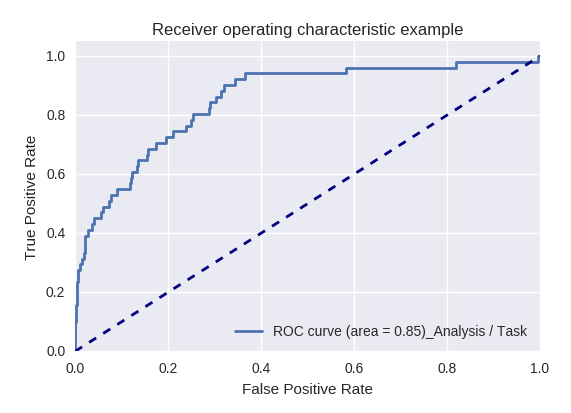
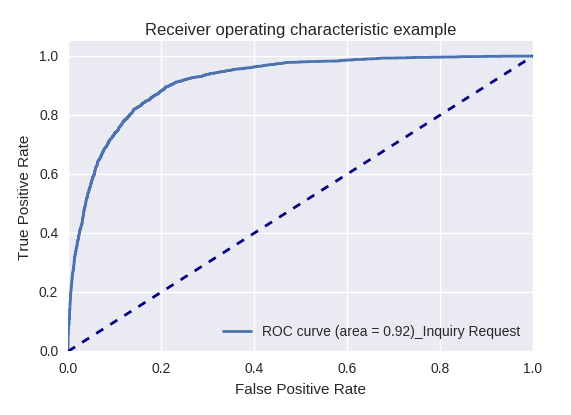
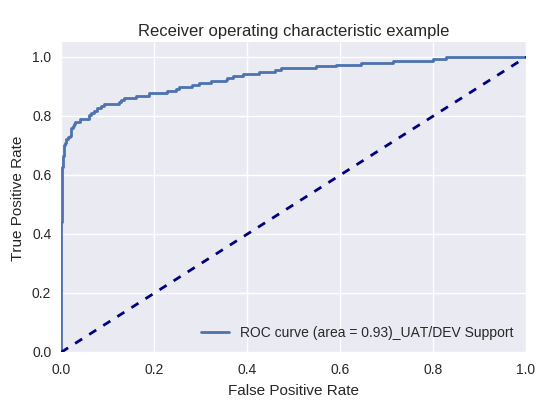
إذا قمنا بتقييم جودة النموذج ككل لأنواع مختلفة من الاستعلامات باستخدام منحنيات ROC-AUC ، فإن النتائج تكون على النحو التالي.
طلبات اتخاذ إجراء (طلب إجراء) وتحليل المعلومات (تحليل / طلب مهمة)
 طلبات التغييرات في بيانات الأعمال (طلب بيانات الأعمال) وللتغييرات (تغيير طلب)
طلبات التغييرات في بيانات الأعمال (طلب بيانات الأعمال) وللتغييرات (تغيير طلب)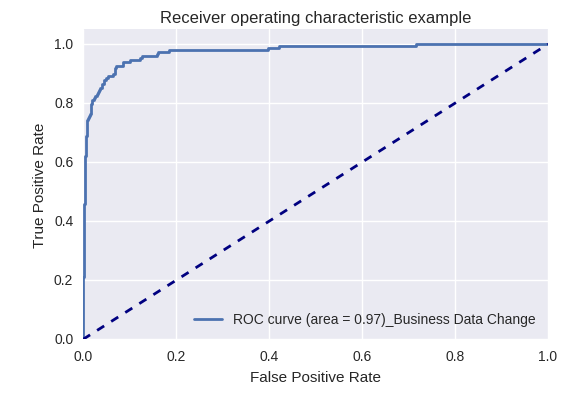
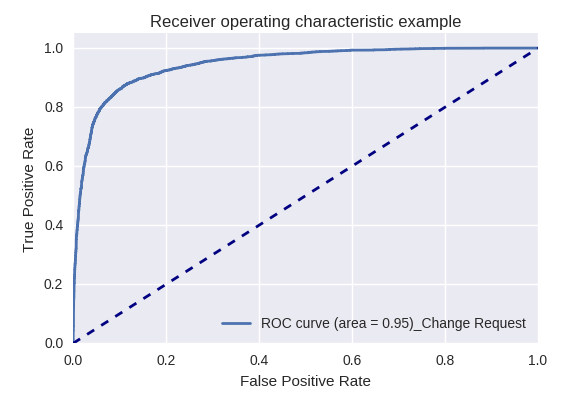 طلب تطوير وطلب استفسار
طلب تطوير وطلب استفسار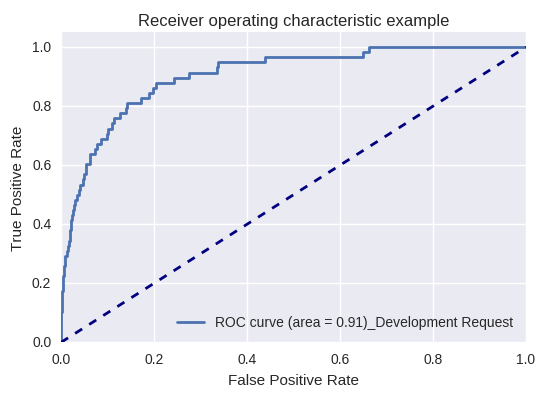
 طلبات إنشاء كائن جديد (طلب كائن جديد) وإضافة مستخدم جديد (طلب مستخدم جديد)
طلبات إنشاء كائن جديد (طلب كائن جديد) وإضافة مستخدم جديد (طلب مستخدم جديد)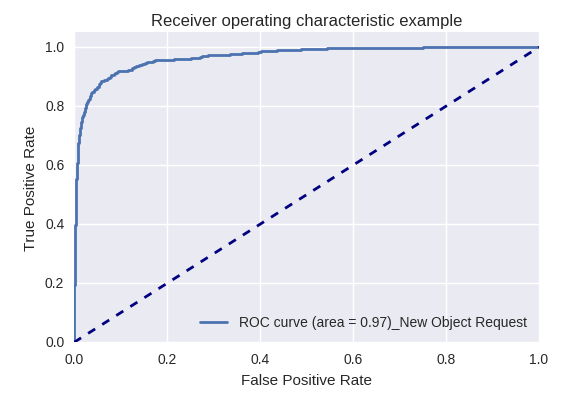
 طلب الإنتاج وطلب دعم UAT / DEV (طلب دعم UAT / Dev)
طلب الإنتاج وطلب دعم UAT / DEV (طلب دعم UAT / Dev)
فيما يلي أمثلة للتصنيف الصحيح وغير الصحيح لبعض أنواع الاستعلامات:
طلب استفسار
تغيير الطلب
التصنيف الصحيح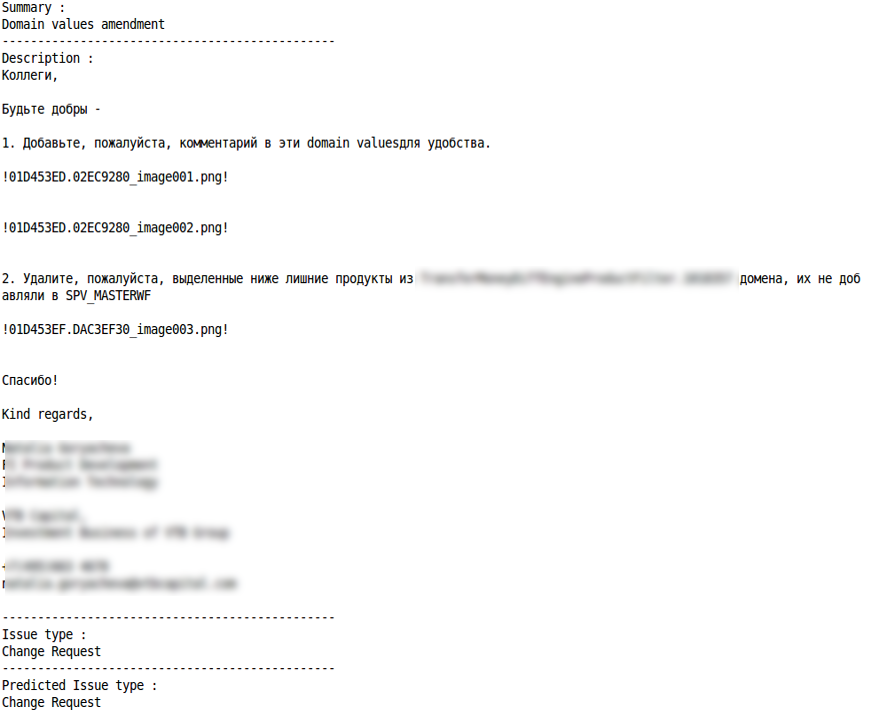 الخطأ في التصنيف
الخطأ في التصنيف طلب العملالتصنيف الصحيح
طلب العملالتصنيف الصحيح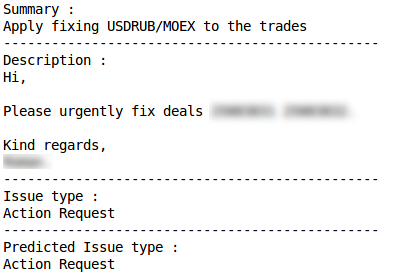 الخطأ في التصنيفقضية الإنتاجالتصنيف الصحيح
الخطأ في التصنيفقضية الإنتاجالتصنيف الصحيح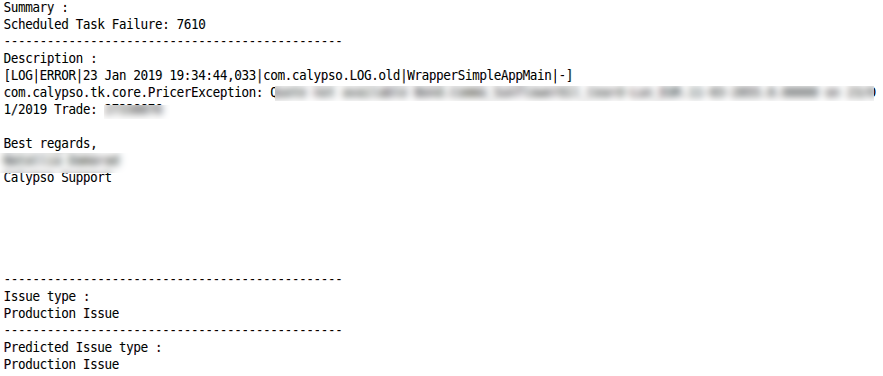 الخطأ في التصنيف
الخطأ في التصنيف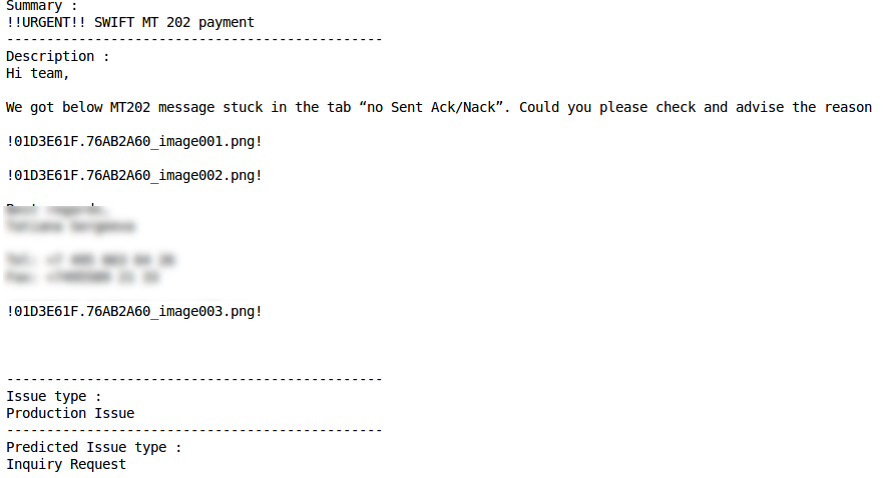
أظهر النموذج الأولي الثاني أيضًا نتائج جيدة: في حوالي 75٪ من الحالات ، يحدد ML بشكل صحيح نوع الاستعلام (قياس الدقة). ترتبط فرصة تحسين المؤشر بتحسين جودة البيانات المصدر ، ولا سيما إزالة الحالات التي تم فيها تعيين نفس الاستعلامات لأنواع مختلفة.
لتلخيص
لقد أظهر كل نموذج من النماذج المطبقة فعاليته ، والآن تم إطلاق مجموعة من نموذجين تم تطويرهما في الإنتاج التجريبي في VTB Capital. أتاحت تجربة صغيرة باستخدام ML في أقل من شهر وبأقل تكلفة ممكنة للشركة التعرف على أدوات التعلم الآلي وحل مشكلة تطبيق مهمة لتصنيف طلبات المستخدمين.
يمكن إعادة استخدام الخبرة التي اكتسبها مطورو EPAM و VTB Capital - بالإضافة إلى استخدام الخوارزميات المنفذة لمعالجة طلبات المستخدمين لمزيد من التطوير - في حل مجموعة متنوعة من المشكلات المتعلقة بمعالجة دفق المعلومات. تتيح لك الحركة في التكرارات الصغيرة وتغطية العملية الواحدة تلو الأخرى إتقان الأدوات والجمع بين الأدوات والتقنيات المختلفة ، واختيار الخيارات المثبتة جيدًا والتخلي عن الخيارات الأقل فعالية. هذا مثير للاهتمام لفريق تكنولوجيا المعلومات ويساعد في الوقت نفسه على الحصول على نتائج مهمة للإدارة والأعمال.