من تعتقد أنه من الأفضل تهيئة خوارزمية PostgreSQL - DBA أو ML؟ وإذا كانت الثانية ، فهل حان الوقت للتفكير فيما يجب علينا فعله عندما تحل السيارات محلنا. أو لن يتحقق ذلك ، ولا يزال يتعين اتخاذ القرارات المهمة من قبل الناس. ربما ، يجب أن يظل المسؤول عن مستوى العزل ومتطلبات استقرار المعاملة. ولكن يمكن الوثوق بها قريباً فهارس لتحديد الجهاز بنفسك.

تحدث آندي بافلو على
HighLoad ++ عن قواعد بيانات DBMS للمستقبل ، والتي يمكنك "لمسها" الآن. إذا فاتتك هذا الخطاب أو كنت تفضل تلقي المعلومات باللغة الروسية - في ظل الخفض هو ترجمة الخطاب.
سيكون حول مشروع جامعة كارنيجي ميلون حول إنشاء نظم إدارة قواعد البيانات المستقلة. يعني مصطلح "الحكم الذاتي" نظامًا يمكنه تلقائيًا نشر نفسه وتكوينه وتكوينه دون أي تدخل بشري. قد يستغرق الأمر حوالي عشر سنوات لتطوير شيء من هذا القبيل ، ولكن هذا ما يفعله آندي وطلابه. بالطبع ، هناك حاجة إلى خوارزميات التعلم الآلي لإنشاء نظم إدارة قواعد البيانات مستقلة ، ولكن في هذه المقالة سوف نركز فقط على الجانب الهندسي للموضوع. النظر في كيفية تصميم البرمجيات لجعلها قائمة بذاتها.
نبذة عن المتحدث: إندي بافلو ، الأستاذ المشارك في جامعة كارنيجي ميلون ، تحت قيادته ، ينشئ
"DBMS PelotonDB" ذاتي الإدارة ، بالإضافة إلى
ottertune ، مما يساعد على ضبط
إعدادات PostgreSQL و MySQL باستخدام التعلم الآلي. أصبح آندي وفريقه الآن قادة حقيقيين في قواعد بيانات الإدارة الذاتية.
السبب الذي يجعلنا نرغب في إنشاء نظام إدارة قاعدة بيانات مستقل ذاتي. تعد إدارة أدوات قواعد البيانات هذه عملية مكلفة للغاية وتستغرق وقتًا طويلاً. متوسط الراتب DBA في الولايات المتحدة حوالي 89 ألف دولار في السنة. ترجمت إلى روبل ، يتم الحصول على 5.9 مليون روبل في السنة. هذا المبلغ الكبير الذي تدفعه للناس لمجرد مراقبة البرنامج. يتم دفع حوالي 50 ٪ من التكلفة الإجمالية لاستخدام قاعدة البيانات عن طريق عمل هؤلاء المسؤولين والموظفين ذوي الصلة.
عندما يتعلق الأمر بمشروعات كبيرة حقًا ، مثل مناقشتنا على HighLoad ++ والتي تستخدم عشرات الآلاف من قواعد البيانات ، فإن تعقيد هيكلها يتجاوز التصور البشري. الجميع يتعامل مع هذه المشكلة بشكل سطحي ويحاول تحقيق أقصى أداء من خلال استثمار الحد الأدنى من الجهد في ضبط النظام.
يمكنك حفظ مبلغ مستدير إذا قمت بتكوين DBMS على مستوى التطبيق والبيئة لضمان أقصى أداء.
قواعد بيانات ذاتية التكيف ، 1970-1990
ليست فكرة نظم إدارة قواعد البيانات المستقلة ذاتية الحكم جديدة ؛ ويعود تاريخها إلى سبعينيات القرن الماضي ، عندما بدأت إنشاء قواعد البيانات العلائقية لأول مرة. ثم أطلقوا عليها قواعد بيانات التكيف الذاتي (قواعد بيانات التكيف الذاتي) ، وبمساعدتهم حاولوا حل المشاكل الكلاسيكية لتصميم قاعدة البيانات ، والتي لا يزال الناس يكافحون حتى يومنا هذا. هذا هو اختيار الفهارس ، قسم وإنشاء مخطط قاعدة البيانات ، وكذلك وضع البيانات. في ذلك الوقت ، تم تطوير الأدوات التي ساعدت مسؤولي قواعد البيانات على نشر قواعد البيانات. هذه الأدوات ، في الواقع ، عملت تماما مثل عمل نظرائهم الحديثة اليوم.
يتعقب المسؤولون الطلبات التي ينفذها التطبيق. ثم يقومون بتمرير مكدس الاستعلام هذا إلى خوارزمية التوليف ، التي تنشئ نموذجًا داخليًا لكيفية استخدام التطبيق لقاعدة البيانات.
إذا قمت بإنشاء أداة تساعدك في تحديد الفهارس تلقائيًا ، فقم بإنشاء مخططات بيانية يمكنك من خلالها معرفة عدد مرات الوصول إلى كل عمود. بعد ذلك ، قم بتمرير هذه المعلومات إلى خوارزمية البحث ، والتي ستبحث في العديد من المواقع المختلفة - ستحاول تحديد أي من الأعمدة يمكن فهرستها في قاعدة البيانات. ستستخدم الخوارزمية نموذج التكلفة الداخلية لإظهار أن هذا النموذج بعينه سيعطي أداء أفضل مقارنة بالفهارس الأخرى. ثم ستقدم الخوارزمية اقتراحًا بشأن التغييرات التي يجب إجراؤها في المؤشرات. في هذه اللحظة ، حان الوقت للمشاركة في الشخص ، والنظر في هذا الاقتراح وليس فقط تحديد ما إذا كان صحيحًا ، ولكن أيضًا اختيار الوقت المناسب لتنفيذه.

يجب أن تعرف DBAs كيفية استخدام التطبيق عندما يكون هناك انخفاض في نشاط المستخدم. على سبيل المثال ، يوم الأحد الساعة 3:00 صباحًا ، وهو أدنى مستوى من استعلامات قاعدة البيانات ، بحيث يمكنك في الوقت الحالي إعادة تحميل الفهارس.
كما قلت ، عملت جميع أدوات التصميم في الوقت نفسه بنفس الطريقة -
هذه مشكلة قديمة جدًا . كتب المشرف العلمي لمشرفتي العلمية مقالًا عن اختيار الفهرس التلقائي في عام 1976.
قواعد بيانات الضبط الذاتي ، 1990-2000
في التسعينيات ، كان الناس ، في الواقع ، يعملون على نفس المشكلة ، فقط الاسم تغير من قواعد البيانات التكيفية إلى الضبط الذاتي.
حصلت الخوارزميات على نحو أفضل قليلاً ، والأدوات أصبحت أفضل قليلاً ، ولكن على مستوى عالٍ عملت بنفس الطريقة التي كانت عليها من قبل. الشركة الوحيدة في طليعة حركة أنظمة الضبط الذاتي كانت Microsoft Research مع مشروع الإدارة التلقائي الخاص بها. لقد طوروا حلولًا رائعة حقًا ، وفي أواخر التسعينات وأوائل القرن العشرين قدموا مرة أخرى مجموعة من التوصيات لإعداد قاعدة البيانات الخاصة بهم.
كانت الفكرة الرئيسية التي طرحتها Microsoft مختلفة عن ما كانت عليه في الماضي - فبدلاً من أن تدعم أدوات التخصيص الطُرز الخاصة بهم ، فقد قاموا في الواقع بإعادة استخدام نموذج تكلفة مُحسِّن الاستعلام للمساعدة في تحديد فوائد فهرس مقابل الآخر. إذا فكرت في الأمر ، فمن المنطقي. عندما تحتاج إلى معرفة ما إذا كان فهرس واحد يمكنه بالفعل تسريع الاستعلامات ، لا يهم حجمها إذا لم يحددها المحسن. لذلك ، يتم استخدام أداة التحسين لمعرفة ما إذا كان سيختار شيئًا بالفعل.

في عام 2007 ، نشرت Microsoft Research
مقالًا يعرض استعاضةً عن الأبحاث على مدى عشر سنوات. وهو يغطي بشكل جيد جميع المهام المعقدة التي نشأت في كل جزء من المسار.
المهمة الأخرى التي تم تسليط الضوء عليها في عصر قواعد الضبط الذاتي هي
كيفية إجراء تعديلات تلقائية على المنظمين. وحدة تحكم قاعدة البيانات هي نوع من معلمات التكوين الذي يغير سلوك نظام قاعدة البيانات في وقت التشغيل. على سبيل المثال ، المعلمة الموجودة في كل قاعدة بيانات تقريبًا هي حجم المخزن المؤقت. أو ، على سبيل المثال ، يمكنك إدارة إعدادات مثل سياسات الحظر وتكرار تنظيف القرص وما شابه. نظرًا للزيادة الكبيرة في تعقيد منظمات إدارة قواعد البيانات في السنوات الأخيرة ، أصبح هذا الموضوع ذا صلة.
لإظهار مدى سوء الأشياء ، سأقدم مراجعة قام بها الطالب بعد دراسة الكثير من إصدارات PostgreSQL و MySQL.
على مدار الخمسة عشر عامًا الماضية ، زاد عدد المنظمين في PostgreSQL 5 مرات ، وبالنسبة لـ MySQL - 7 مرات.
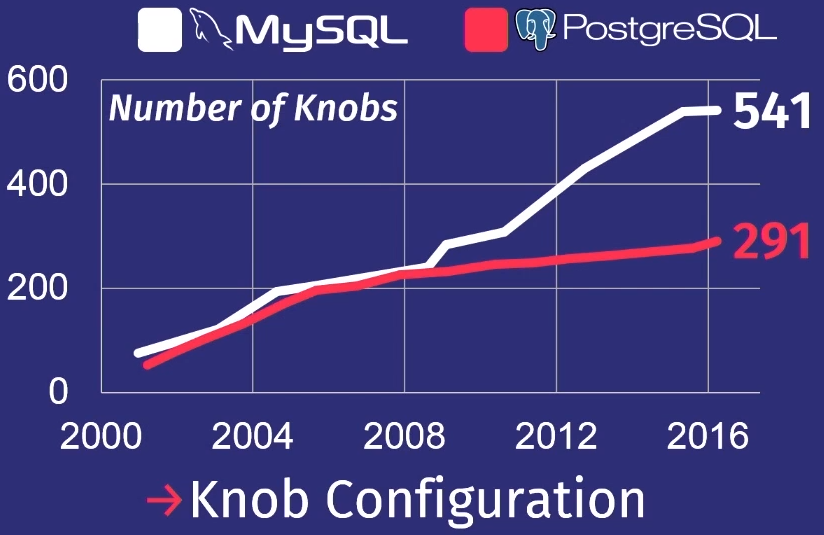
بالطبع ، ليس كل المنظمين يتحكمون فعليًا في عملية تنفيذ المهمة. يحتوي البعض ، على سبيل المثال ، على مسارات ملفات أو عناوين شبكة ، لذلك يمكن للشخص فقط تكوينها. ولكن بضع عشرات منهم يمكن أن تؤثر حقا في الأداء. لا يمكن لأي شخص أن يحمل الكثير في رأسه.
Cloud DB ، 2010– ...
علاوة على ذلك ، نجد أنفسنا في عصر 2010 ، الذي نحن فيه حتى يومنا هذا. أنا أسميها عصر قواعد البيانات السحابية. خلال هذا الوقت ، تم القيام بالكثير من العمل لأتمتة نشر عدد كبير من قواعد البيانات في السحابة.
الشيء الرئيسي الذي يقلق مزودي الخدمات السحابية الرئيسية هو كيفية استضافة مستأجر أو الانتقال من واحد إلى آخر. كيفية تحديد مقدار الموارد التي سيحتاج إليها كل مستأجر ، ثم حاول توزيعها بين الآلات لزيادة الإنتاجية أو مطابقة اتفاقيات مستوى الخدمة بأقل تكلفة.
تعمل أمازون ومايكروسوفت وجوجل على حل هذه المشكلة ، ولكن بشكل أساسي على المستوى التشغيلي. في الآونة الأخيرة فقط ، بدأ مقدمو الخدمات السحابية في التفكير في الحاجة إلى تكوين أنظمة قواعد البيانات الفردية. هذا العمل غير مرئي للمستخدمين العاديين ، ولكنه يحدد المستوى العالي للشركة.
تلخيص البحث الذي استمر 40 عامًا لقواعد البيانات ذات الأنظمة المستقلة وغير المستقلة ، يمكننا أن نستنتج أن هذا العمل لا يزال غير كافٍ.
لماذا اليوم لا يمكن أن يكون لدينا نظام حكم ذاتي حقيقي حقًا؟ هناك ثلاثة أسباب لذلك.

أولاً ، كل هذه الأدوات ، باستثناء توزيع أعباء العمل من موفري الخدمات السحابية ، ليست سوى
استشارية بطبيعتها . وهذا هو ، على أساس الخيار المحسوب ، يجب على الشخص اتخاذ قرار نهائي شخصي بشأن ما إذا كان هذا الاقتراح صحيحًا. علاوة على ذلك ، من الضروري مراقبة تشغيل النظام لبعض الوقت لتحديد ما إذا كان القرار الذي تم اتخاذه لا يزال صحيحًا مع تطور الخدمة. ثم قم بتطبيق المعرفة على نموذج صنع القرار الداخلي الخاص بك في المستقبل. يمكن القيام بذلك لقاعدة بيانات واحدة ، ولكن ليس لعشرات الآلاف.
المشكلة التالية هي أن
أي إجراء هو مجرد رد فعل على شيء ما . في جميع الأمثلة التي درسناها ، يسير العمل مع بيانات حول عبء العمل السابق. هناك مشكلة ، يتم نقل السجلات المتعلقة بها إلى الأداة ، ويقول: "نعم ، أنا أعرف كيفية حل هذه المشكلة". لكن الحل يتعلق فقط بمشكلة حدثت بالفعل. لا تتنبأ الأداة بالأحداث المستقبلية وبالتالي لا تقدم إجراءات تحضيرية. يمكن لأي شخص القيام بذلك ، ويقوم بذلك يدويًا ، لكن الأدوات لا تستطيع ذلك.
السبب الأخير هو أنه لا
يوجد نقل للمعرفة في أي من الحلول. فيما يلي ما أقصده: على سبيل المثال ، لنأخذ أداة عملت في أحد التطبيقات على مثيل قاعدة البيانات الأولى ، إذا وضعت في تطبيق آخر على مثيل آخر لقاعدة البيانات ، فيمكنها ، بناءً على المعرفة المكتسبة عند العمل مع قاعدة البيانات الأولى تساعد البيانات في إعداد قاعدة بيانات ثانية. في الواقع ، كل الأدوات تبدأ العمل من نقطة الصفر ، فهي بحاجة إلى إعادة الحصول على جميع البيانات حول ما يحدث. الرجل يعمل بطريقة مختلفة تماما. إذا كنت أعرف كيفية تكوين تطبيق ما بطريقة معينة ، يمكنني أن أرى نفس الأنماط في تطبيق آخر ، وربما تكوينه بشكل أسرع بكثير. ولكن لا توجد واحدة من هذه الخوارزميات ، ولا تعمل أي من هذه الأدوات بهذه الطريقة.
لماذا أنا متأكد من أن الوقت قد حان للتغيير؟ إن إجابة هذا السؤال هي نفسها عن سبب كون المصفوفات الفائقة للبيانات أو التعلم الآلي أصبحت شائعة.
أصبحت المعدات ذات جودة أفضل : تزداد موارد الإنتاج ، وتنمو سعة التخزين ، وتتزايد سعة الأجهزة ، مما يسرع العمليات الحسابية لتعلم نماذج التعلم الآلي.
أصبحت أدوات البرمجيات المتقدمة متاحة لنا. في السابق ، كنت بحاجة إلى أن تكون خبيرًا في MATLAB أو الجبر الخطي منخفض المستوى لكتابة بعض خوارزميات التعلم الآلي. الآن لدينا Torch و Tenso Flow ، اللذين يوفران ML ، وبالطبع تعلمنا أن نفهم البيانات بشكل أفضل. يعرف الناس نوع البيانات التي قد تكون ضرورية لاتخاذ القرارات في المستقبل ، وبالتالي فهم لا يتجاهلون البيانات التي كانت موجودة من قبل.
الهدف من بحثنا هو إغلاق هذه الدائرة في نظم إدارة قواعد البيانات المستقلة. يمكننا ، مثل الأدوات السابقة ، اقتراح حلول ، ولكن بدلاً من الاعتماد على الشخص - سواء كان القرار صحيحًا عندما تحتاج بالضبط إلى نشره - ستقوم الخوارزمية بذلك تلقائيًا. وبعد ذلك بمساعدة الملاحظات ، سيدرس وسيصبح أفضل بمرور الوقت.
أريد أن أتحدث عن المشاريع التي نعمل عليها حاليًا في جامعة كارنيجي ميلون. في نفوسهم ، نعالج المشكلة بطريقتين مختلفتين.
في البداية - OtterTune - نبحث عن طرق لضبط قاعدة البيانات ، ونتعامل معها كمربعات سوداء. وهذا يعني ، طرق
لضبط نظم إدارة قواعد البيانات الحالية دون التحكم في الجزء الداخلي من النظام ومراقبة الاستجابة فقط.
يدور مشروع Peloton حول
إنشاء قواعد بيانات جديدة من نقطة الصفر ، من نقطة الصفر ، بالنظر إلى حقيقة أن النظام يجب أن يعمل بشكل مستقل. ما هي التعديلات وخوارزميات التحسين التي يجب وضعها - والتي لا يمكن تطبيقها على الأنظمة الحالية.
لننظر في كلا المشروعين بالترتيب.
OtterTune
مشروع تعديل النظام الحالي الذي قمنا بتطويره يسمى OtterTune.
تخيل أنه تم تكوين قاعدة البيانات كخدمة. الفكرة هي أن تقوم بتنزيل مقاييس وقت التشغيل لعمليات قاعدة البيانات الثقيلة التي تستهلك جميع الموارد ، ويأتي التكوين الموصى به للهيئات التنظيمية استجابة ، الأمر الذي في رأينا سيزيد الإنتاجية. يمكن أن يكون وقت تأخير أو نطاق ترددي أو أي خاصية أخرى تحددها - سنحاول إيجاد الخيار الأفضل.

الشيء الرئيسي الجديد في مشروع OtterTune هو
القدرة على استخدام البيانات من جلسات التوليف
السابقة وزيادة كفاءة الجلسات اللاحقة. على سبيل المثال ، خذ تكوين PostgreSQL ، الذي يحتوي على تطبيق لم نره من قبل. ولكن إذا كانت لها خصائص معينة أو تستخدم قاعدة البيانات بنفس طريقة استخدام قواعد البيانات التي رأيناها بالفعل في تطبيقاتنا ، فإننا نعرف بالفعل كيفية تكوين هذا التطبيق بشكل أكثر كفاءة.
في المستوى الأعلى ، تكون خوارزمية العمل كما يلي.
دعنا نقول أن هناك قاعدة بيانات مستهدفة: PostgreSQL أو MySQL أو VectorWise. يجب تثبيت وحدة التحكم في نفس المجال ، والتي ستؤدي مهمتين.
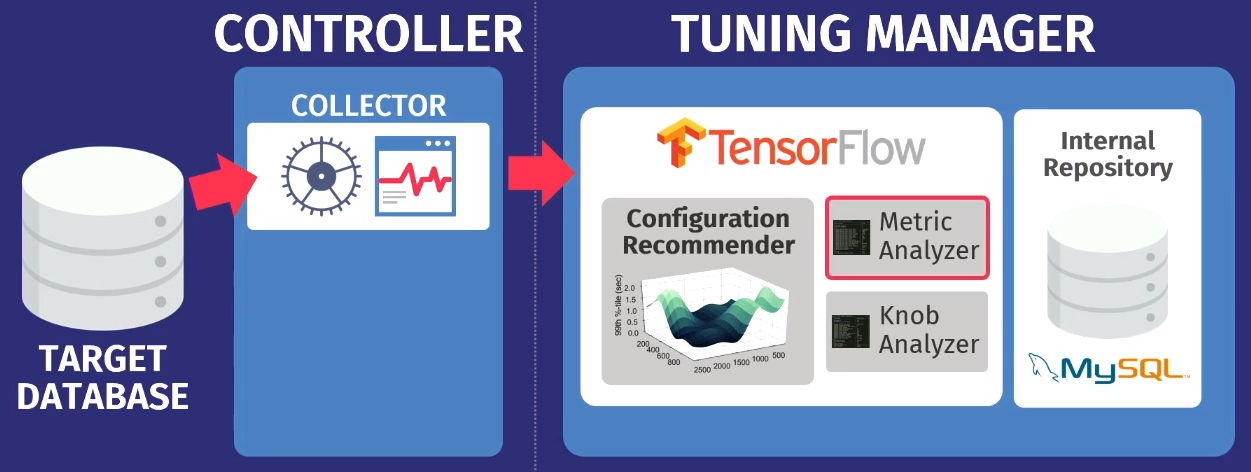
يتم تنفيذ الأول بواسطة ما يسمى المجمّع - وهي أداة تجمع البيانات حول التكوين الحالي ، أي الاستعلام مقاييس وقت التنفيذ من التطبيقات إلى قاعدة البيانات. يتم تحميل البيانات التي يجمعها المجمع في Tuning Manager ، وهي خدمة توليف. لا يهم إذا كانت قاعدة البيانات تعمل محليًا أو في السحابة. بعد التنزيل ، يتم تخزين البيانات في مستودعنا الداخلي ، الذي يخزن جميع جلسات إعداد الاختبار التي تمت على الإطلاق.
قبل تقديم التوصيات ، تحتاج إلى تنفيذ خطوتين. أولاً ، تحتاج إلى إلقاء نظرة على مقاييس وقت التشغيل ومعرفة أي المقاييس المهمة بالفعل. يوضح المثال التالي المقاييس التي تم إرجاعها بواسطة MySQL لكن
SHOW_GLOBAL_STATUS على InnoDB. ليس كل منهم مفيدة لتحليلنا. من المعروف أنه في تعلم الآلة ، لا تكون كمية كبيرة من البيانات جيدة دائمًا. لأنه حتى ذلك الحين مطلوب مزيد من البيانات لفصل الحبوب من القشر. كما في هذه الحالة ،
من المهم التخلص من الكيانات التي لا تهم حقًا .
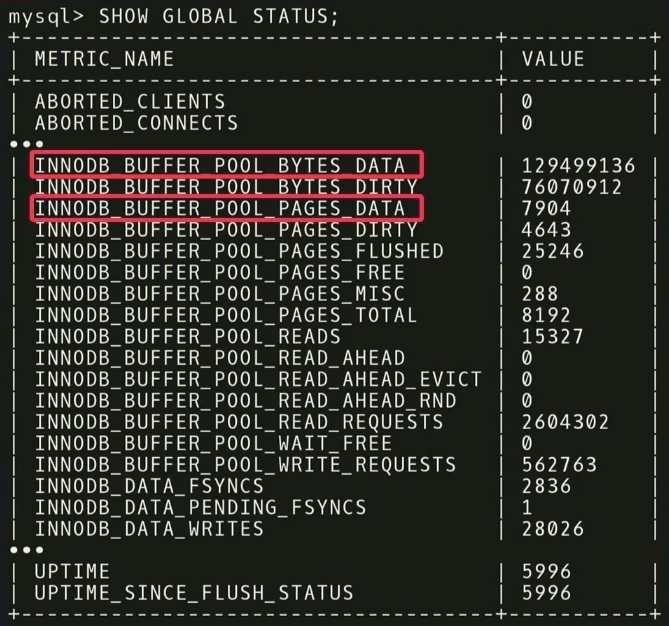
على سبيل المثال ، هناك مقياسين:
INNODB_BUFFER_POOL_BYTES_DATA و
INNODB_BUFFER_POOL_PAGES_DATA . في الواقع ، هذا هو نفس المقياس ، ولكن في وحدات مختلفة. يمكنك إجراء تحليل إحصائي ، ونرى أن المقاييس مترابطة للغاية ، وتخلص إلى أن استخدام كليهما لا لزوم له للتحليل. إذا تجاهلت أحدهم ، فسيقلل بُعد مهمة التعلم وسيتم تقليل وقت تلقي إجابة.
في المرحلة الثانية ، نفعل نفس الشيء ، فقط فيما يتعلق بالمنظمين.
يوجد 500 منظم في MySQL ، وبالطبع ليس كلهم مهمين حقًا ، لكن التطبيقات المختلفة مهمة للتطبيقات المختلفة. من الضروري إجراء تحليل إحصائي آخر لمعرفة الهيئات التنظيمية التي تؤثر فعليًا على الوظيفة المستهدفة.
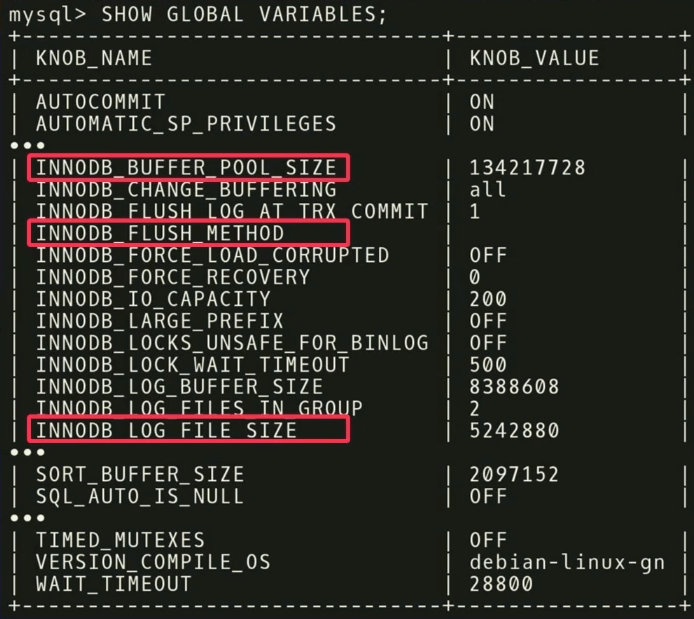
في مثالنا ، وجدنا أن
INNODB_BUFFER_POOL_SIZE الثلاثة
INNODB_BUFFER_POOL_SIZE و
FLUSH_METHOD و
LOG_FILE_SIZE لها أكبر تأثير على الأداء. أنها تقلل من وقت التأخير عن عبء العمل للمعاملات.
هناك نقاط أخرى مثيرة للاهتمام تتعلق بالمنظمين. في لقطة الشاشة يوجد منظم اسمه
TIMED_MUTEXES . إذا كنت تشير إلى وثائق العمل في MySQL ، في القسم 45.7 ، فسيتم الإشارة إلى أن هذا المنظم قديم. لكن
خوارزمية التعلم الآلي غير قادرة على قراءة الوثائق ، لذلك لا تعرف عنها. إنه يعلم أن هناك جهة تنظيمية يمكن تشغيلها أو إيقافها ، وسوف يستغرق الأمر وقتًا طويلاً لفهم أن هذا لا يؤثر على أي شيء. ولكن يمكنك إجراء العمليات الحسابية مقدمًا ومعرفة أن الجهة المنظمة لا تفعل شيئًا ، ولا تضيع الوقت في إعدادها.
بعد التحليل ، يتم نقل البيانات إلى خوارزمية التكوين الخاصة بنا باستخدام
نموذج عملية Gaussian - وهي طريقة قديمة إلى حد ما. ربما تكون قد سمعت بالتعلم العميق ، فنحن نقوم بشيء مماثل ، لكن بدون شبكات عميقة. نستخدم
GPflow ، حزمة للعمل مع نماذج العمليات Gaussian المطورة في روسيا على أساس TensorFlow. تصدر الخوارزمية توصية من شأنها تحسين الوظيفة الموضوعية ؛ يتم نقل هذه البيانات مرة أخرى إلى عامل التثبيت الذي يعمل داخل وحدة التحكم. يطبق العامل التغييرات عن طريق إجراء إعادة تعيين - لسوء الحظ ، سيتعين عليه إعادة تشغيل قاعدة البيانات - ثم تتكرر العملية مرة أخرى. يتم جمع بعض المزيد من مقاييس وقت التشغيل ، ونقلها إلى الخوارزمية ، ويتم إجراء تحليل لإمكانية تحسين وزيادة الإنتاجية ، ويتم إصدار توصية ، وهكذا ، مرارًا وتكرارًا.
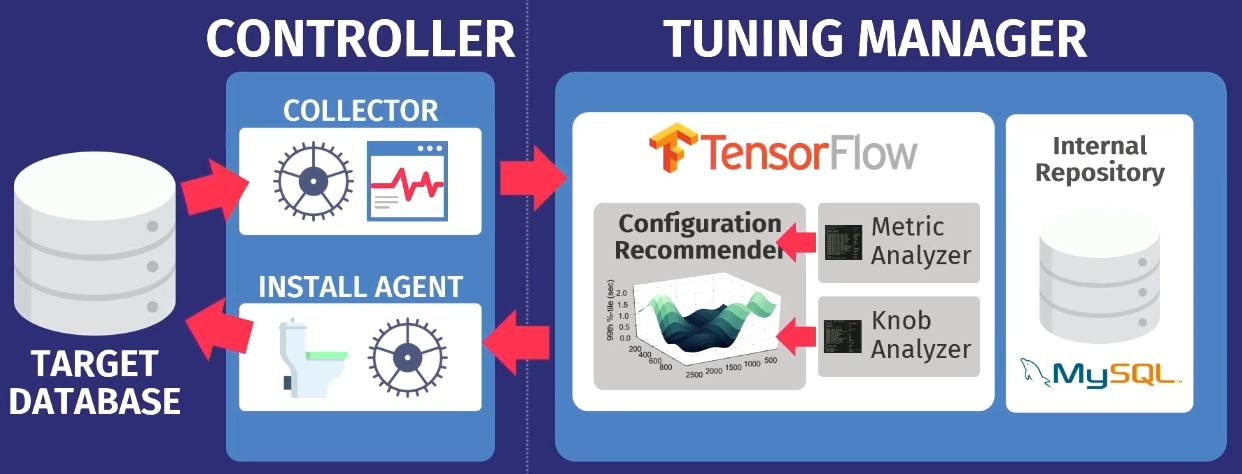
الميزة الرئيسية في OtterTune هي أن الخوارزميات تحتاج فقط إلى معلومات حول مقاييس وقت التشغيل كمدخلات. لسنا بحاجة لرؤية بياناتك وطلبات المستخدم. نحن فقط بحاجة لتتبع عمليات القراءة والكتابة. هذه حجة قوية - لن يتم الكشف عن البيانات الخاصة بك أو لعملائك إلى أطراف ثالثة. لا نحتاج إلى رؤية أي طلبات ، الخوارزمية تعمل فقط على مقاييس وقت التشغيل ، لأنها تقدم توصيات للمنظمين ، وليس للتصميم المادي.
دعونا نلقي نظرة على عرض OtterTune. على موقع المشروع على الويب ، سنقوم بتشغيل Postgres 9.6 وتحميل النظام من خلال اختبار TPC-C. لنبدأ بتهيئة PostgreSQL الأولية ، والتي يتم نشرها عند تثبيتها على Ubuntu.
أولاً ، قم بإجراء اختبار TPC-C لمدة خمس دقائق ، وجمع مقاييس وقت التشغيل الضرورية ، وحملها على خدمة OtterTune ، واحصل على توصيات ، وقم بتطبيق التغييرات ، ثم كرر العملية. سوف نعود إلى هذا لاحقًا. يعمل نظام قاعدة البيانات على جهاز كمبيوتر واحد ، وخدمة Tensor Flow على جهاز آخر ، ويقوم بتحميل البيانات هنا.
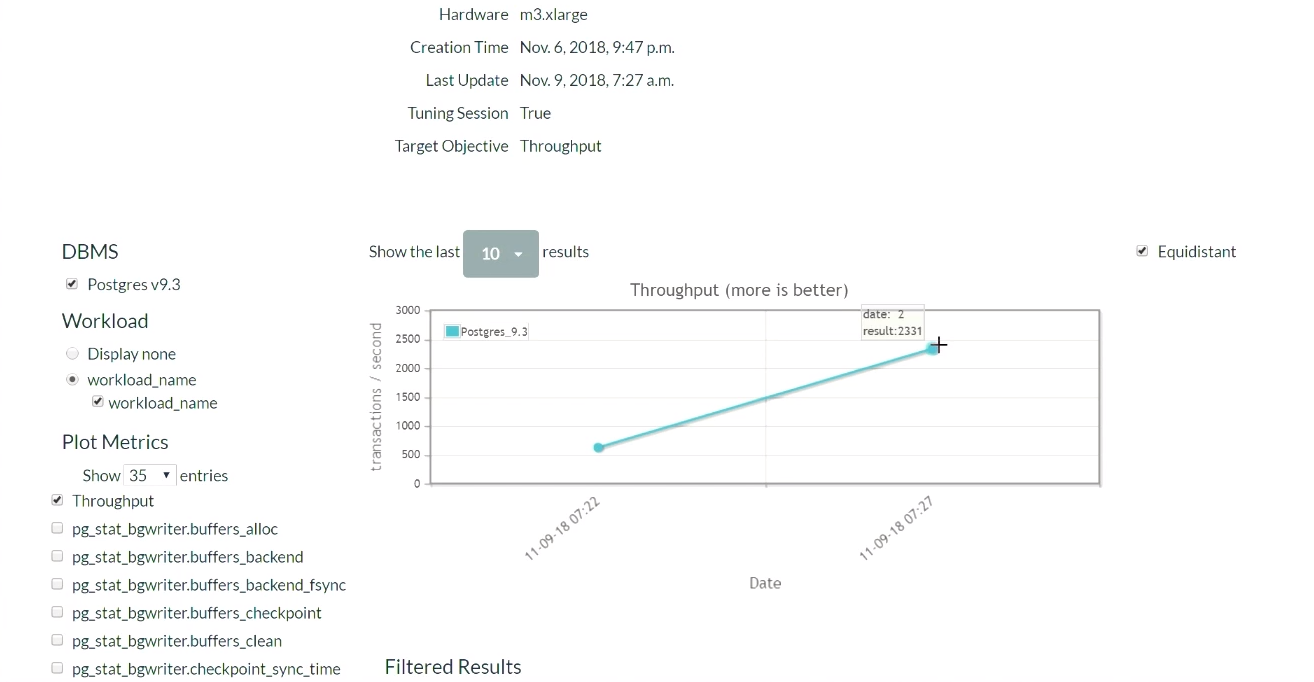
بعد خمس دقائق ، نقوم بتحديث الصفحة (عرض توضيحي لهذا الجزء من النتائج يبدأ في
هذه اللحظة ). عندما بدأنا لأول مرة ، في التكوين الافتراضي لـ PostgreSQL ، كان هناك 623 معاملة في الثانية. ثم ، بعد تلقي التوصية وتطبيق التغييرات مرة واحدة ، ارتفع عدد المعاملات
إلى 2300 في الثانية . تجدر الإشارة إلى أن هذا العرض التوضيحي قد تم إطلاقه بالفعل عدة مرات ، وبالتالي فإن النظام لديه بالفعل مجموعة من البيانات التي تم جمعها مسبقًا. هذا هو السبب في أن الحل سريع للغاية. ماذا سيحدث إذا لم يكن لدى النظام مثل هذه البيانات التي تم جمعها مسبقًا؟ هذه الخوارزمية هي نوع من الوظائف خطوة بخطوة ، وبالتدريج ستصل إلى هذا المستوى.

بعد مرور بعض الوقت والخمس مرات ، كانت أفضل نتيجة هي 2600. ذهبنا من 600 معاملة في الثانية ، وتمكنا من الوصول إلى قيمة 2600. ظهر انخفاض صغير لأن الخوارزمية قررت تجربة طريقة مختلفة لضبط الهيئات التنظيمية بعد أن حققت نتائج جيدة. كانت النتيجة هامشًا ، لذلك لم يحدث انخفاض كبير في الأداء. بعد الحصول على نتيجة سلبية ، أعيد تكوين الخوارزمية وبدأت في البحث عن طرق أخرى للتنظيم.
نستنتج أنه لا ينبغي أن تخاف من بدء استراتيجية سيئة في العمل ، لأن الخوارزمية سوف تستكشف مساحة الحل وستحاول تكوينات مختلفة لتحقيق شروط اتفاقية SLA. على الرغم من أنه يمكنك دائمًا تكوين الخدمة بحيث تختار الخوارزمية حلول التحسين فقط. ومع مرور الوقت ، سوف تتلقى كل خير وأفضل النتائج.
عد الآن إلى موضوع حديثنا. سوف أخبركم بالنتائج الحالية
لمقال نشر في سيجمود. قمنا بتكوين MySQL و PostgreSQL لـ TPC-C باستخدام OtterTune ، من أجل زيادة الإنتاجية.
قارن تكوينات قواعد البيانات هذه ، التي يتم نشرها افتراضيًا أثناء التثبيت الأول على أوبونتو. بعد ذلك ، قم بتشغيل بعض البرامج النصية لتكوين المصدر المفتوح التي يمكنك الحصول عليها من Percona وبعض الشركات الاستشارية الأخرى التي تعمل مع PostgreSQL. تستخدم هذه البرامج النصية إجراءات إرشادية ، مثل القاعدة التي يجب عليك تعيين حجم مخزن مؤقت معين لجهازك فيها. لدينا أيضًا تهيئة من Amazon RDS ، والتي لديها بالفعل إعدادات مسبقة لـ Amazon للمعدات التي تعمل عليها. ثم قارن هذا بنتيجة إعداد DBAs باهظة الثمن يدويًا ، ولكن بشرط أن يكون لديهم 20 دقيقة والقدرة على ضبط أي معلمات تريدها. والخطوة الأخيرة هي إطلاق OtterTune.
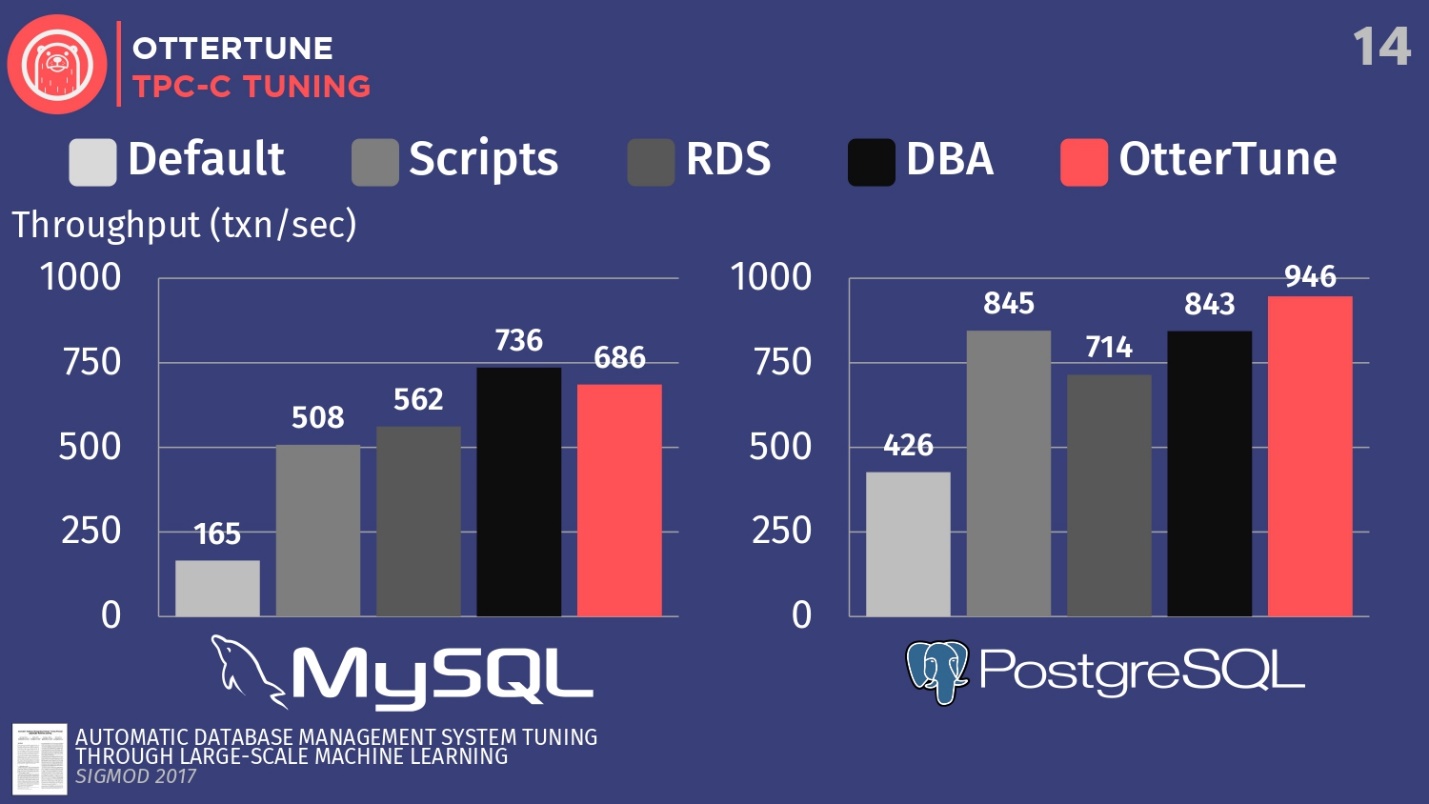
بالنسبة إلى MySQL ، يمكنك أن ترى أن التكوين الافتراضي متأخر جدًا ، وأن البرامج النصية تعمل بشكل أفضل قليلاً ، وأن RDS أفضل قليلاً. في هذه الحالة ، تم عرض أفضل نتيجة من قِبل مسؤول قاعدة البيانات - مسؤول MySQL الرائد من Facebook.
خسر OtterTune للإنسان . ولكن الحقيقة هي أن هناك منظم معين يعطل تزامن تنظيف السجل ، وهذا ليس مهمًا على Facebook. ومع ذلك ، فقد رفضنا الوصول إلى منظم OtterTune هذا لأن الخوارزميات لا تعرف ما إذا كنت توافق على فقد آخر خمسة ميلي ثانية من البيانات. في رأينا ، ينبغي اتخاذ هذا القرار من قبل شخص. ربما يوافق Facebook على مثل هذه الخسائر ، نحن لا نعرف هذا. إذا قمنا بضبط هذا المنظم بنفس الطريقة ، فيمكننا التنافس مع الشخص.
يوضح هذا المثال كيف نحاول أن نكون محافظين حيث يجب أن يتخذ الشخص القرار النهائي. نظرًا لوجود بعض جوانب قواعد البيانات التي لا تعرفها خوارزمية ML.
في حالة PostgreSQL ، تعمل نصوص التكوين بشكل جيد. RDS يفعل أسوأ قليلا. ولكن ، تجدر الإشارة إلى أن مؤشرات OtterTune في هذا تجاوزت الشخص. يوضح الرسم البياني النتائج التي تم الحصول عليها بعد إعداد قاعدة البيانات من قِبل مستشار ويسكونسن لكبار مستشاري PostgreSQL. في هذا المثال ، تمكن OtterTune من إيجاد التوازن الأمثل بين حجم ملف السجل وحجم تجمع المخزن المؤقت ، وتحقيق التوازن بين مقدار الذاكرة المستخدمة من قبل هذين المكونين وضمان أفضل أداء.
الاستنتاج الرئيسي هو أن خدمة OtterTune تستخدم مثل هذه الخوارزميات والتعلم الآلي حتى نتمكن من تحقيق الأداء نفسه أو أفضل مقارنةً بـ DBAs باهظة الثمن للغاية. وهذا لا ينطبق فقط على مثيل واحد من قاعدة البيانات ، بل يمكننا توسيع نطاق العمل إلى عشرات الآلاف من النسخ ، لأنه مجرد برامج ، مجرد بيانات.
بلوتون
المشروع الثاني الذي أود التحدث عنه يسمى بيلوتون. هذا نظام بيانات جديد تمامًا نقوم ببنائه من نقطة الصفر في جامعة كارنيجي ميلون. نحن نسميها DBMS إدارة ذاتية.
تتمثل الفكرة في معرفة التغييرات التي يمكن إجراؤها على نحو أفضل إذا كنت تتحكم في رصة البرنامج بالكامل. كيفية جعل الإعدادات أفضل من OtterTune ، نظرًا للمعرفة حول كل جزء من النظام ، حول دورة البرنامج بالكامل.

كيف ستعمل: قمنا بدمج
مكونات التعلم الآلي مع التعزيز في نظام قاعدة البيانات ، ويمكننا ملاحظة جميع جوانب سلوكها في وقت التشغيل ، ومن ثم تقديم توصيات. ونحن لا نقتصر على التوصيات المتعلقة بضبط الهيئات التنظيمية ، كما يحدث في خدمة OtterTune ، نود أن ننفذ مجموعة الإجراءات القياسية الكاملة التي تحدثت عنها سابقًا: اختيار الفهارس ، واختيار مخططات التقسيم ، والتحجيم الرأسي والأفقي ، إلخ.
من المرجح أن يتغير اسم نظام بيلوتون. لا أعرف كيف في روسيا ، ولكن في الولايات المتحدة الأمريكية ، فإن مصطلح " بيلوتون" يعني "بلا خوف" و "إنهاء" ، وبالفرنسية تعني "فصيلة". لكن في الولايات المتحدة ، توجد شركة بيلوتون لتمرينات الدراجات تمتلك الكثير من المال. في كل مرة يظهر فيها ذكر لها ، على سبيل المثال ، فتح متجر جديد ، أو إعلان جديد على التلفزيون ، يكتب لي جميع أصدقائي: "انظر ، لقد سرقوا فكرتك ، سرقوا اسمك". تُظهر الإعلانات أشخاصًا جميلين يركبون دراجات تمريناتهم ، ولا يمكننا منافسة ذلك. ومؤخراً ، أعلن Uber عن مخطط موارد جديد يسمى Peloton ، لذلك لم يعد بإمكاننا تسميته نظامنا. لكن ليس لدينا اسم جديد بعد ، لذلك في هذه القصة سأظل أستخدم الإصدار الحالي من الاسم.النظر في كيفية عمل هذا النظام على مستوى عال. على سبيل المثال ، خذ قاعدة البيانات الهدف ، وأكرر ، هذا هو برنامجنا ، وهذا ما نعمل معه. نحن نجمع نفس سجل عبء العمل الذي عرضته سابقًا. الفرق هو أننا سنقوم بإنشاء نماذج للتنبؤ تتيح لنا التنبؤ بدورات عبء العمل في المستقبل ، وما متطلبات عبء العمل المستقبلية. هذا هو السبب في أننا نسمي هذا النظام إدارة قواعد البيانات ذاتي الإدارة.
الفكرة الأساسية لإدارة قواعد البيانات ذاتي الإدارة تشبه فكرة السيارة مع التحكم التلقائي.
تبدو مركبة غير مأهولة أمامها وتستطيع رؤية ما يوجد أمامها على الطريق ، ويمكنها التنبؤ بكيفية الوصول إلى وجهتها. يعمل نظام قاعدة بيانات مستقل بنفس الطريقة. يجب أن تكون قادرًا على التطلع إلى المستقبل والتوصل إلى استنتاج حول شكل عبء العمل في غضون أسبوع أو ساعة. ثم نقوم بتمرير هذه البيانات المتوقعة إلى عنصر التخطيط - نسميها الدماغ - التي تعمل على Tensor Flow.
تعكس هذه العملية عمل AlphaGo من لندن كجزء من مشروع Google Deep Mind ، على المستوى الأعلى ، تعمل جميعها في سيناريو مشابه: يبحث مونت كارلو في الشجرة ، ونتيجة البحث هي إجراءات مختلفة يجب تنفيذها لتحقيق الهدف المنشود.
تحدد الخوارزمية التالية مخطط التشغيل تقريبًا:
- البيانات المصدر عبارة عن مجموعة من الإجراءات المطلوبة ، على سبيل المثال ، حذف فهرس ، وإضافة فهرس ، والتدرج الرأسي والأفقي ، وما شابه ذلك.
- يتم إنشاء سلسلة من الإجراءات ، الأمر الذي يؤدي في النهاية إلى تحقيق أقصى وظيفة موضوعية.
- يتم تجاهل جميع المعايير باستثناء الأول ، ويتم تطبيق التغييرات.
- ينظر النظام إلى التأثير الناتج ، ثم تتكرر العملية مرارًا وتكرارًا.

لا تلجأ دائمًا إلى استعارة سيارة بدون طيار ، ولكن هكذا تعمل. وهذا ما يسمى أفق التخطيط.
بعد النظر إلى الأفق على الطريق ، وضعنا أنفسنا في نقطة وهمية للوصول ، ثم نبدأ في تخطيط سلسلة من الإجراءات للوصول إلى هذه النقطة في الأفق: تسريع ، إبطاء ، انعطاف يسار ، انعطف يمينًا ، إلخ. ثم نتجاهل جميع الإجراءات عقليا باستثناء الإجراء الأول الذي يجب تنفيذه ، وننفذه ، ثم نكرر العملية مرة أخرى. الطائرات بدون طيار تشغيل مثل هذه الخوارزمية 30 مرة في الثانية الواحدة. بالنسبة لقواعد البيانات ، تكون هذه العملية أبطأ قليلاً ، لكن الفكرة تظل كما هي.
لقد قررنا إنشاء نظام قاعدة بيانات خاص بنا
من نقطة الصفر ، بدلاً من بناء شيء فوق PostgreSQL أو MySQL ، لأن نكون صادقين ، فهي بطيئة جدًا مقارنة بما نود القيام به. PostgreSQL جميل ، وأنا أحبه وأستخدمه في الدورات الجامعية ، لكن الأمر يتطلب الكثير من الوقت لإنشاء فهارس ، لأن جميع البيانات تأتي من الأقراص.
في القياس مع السيارات ، يمكن مقارنة نظام إدارة قواعد البيانات المستقل على PostgreSQL مع عربة بدون طيار. ستكون الشاحنة قادرة على التعرف على الكلب أمام الطريق والالتفاف حوله ، ولكن ليس إذا كانت السيارة قد خرجت من الطريق مباشرة أمام السيارة. عندئذ يكون التصادم أمرًا لا مفر منه ، لأن الشاحنة غير قابلة للمناورة بما فيه الكفاية. قررنا إنشاء نظام من البداية حتى نتمكن من تطبيق التغييرات في أسرع وقت ممكن ومعرفة التكوين الصحيح.
الآن قمنا بحل المشكلة الأولى ونشرنا
مقالًا عن مزيج من التعلم العميق والانحدار الخطي الكلاسيكي للاختيار التلقائي والتنبؤ بأعباء العمل.
ولكن هناك مشكلة أكبر ليس لدينا حل جيد لها -
كتالوجات الإجراءات . ليس السؤال هو كيفية اختيار الإجراءات ، لأن الرجال من Microsoft قاموا بهذا بالفعل. والسؤال هو كيفية تحديد ما إذا كان أحد الإجراءات أفضل من الآخر ، من حيث ما يحدث قبل النشر وبعد النشر. كيفية عكس إجراء ما إذا لم يكن الفهرس الذي تم إنشاؤه بواسطة أمر الشخص هو الأمثل ، وكيف يمكنك إلغاء هذا الإجراء والإشارة إلى سبب الإلغاء. بالإضافة إلى ذلك ، هناك عدد من المهام الأخرى من حيث تفاعل نظامنا الخاص مع العالم الخارجي ، والتي ليس لدينا حل لها بعد ، لكننا نعمل عليها.
بالمناسبة ، سأحكي قصة مسلية عن شركة قاعدة بيانات معروفة. كان لدى هذه الشركة أداة اختيار فهرس تلقائية ، وكانت هناك مشكلة. قام عميل واحد بإلغاء جميع الفهارس التي أوصت بها الأداة وتطبيقها باستمرار. حدث هذا الإلغاء في كثير من الأحيان أن الأداة معلقة. لم يكن يعلم ما هي إستراتيجية السلوك الإضافية ، لأن أي حل يتم تقديمه لشخص ما قد حصل على تقييم سلبي. عندما تحول المطورون إلى العميل وسألوه: "لماذا تلغي جميع التوصيات والاقتراحات بشأن المؤشرات؟" ، أجاب العميل أنه ببساطة لا يحب أسمائهم. الناس أغبياء ، لكن عليك أن تتعامل معهم. ولهذه المشكلة ، ليس لدي أي حل.تصميم نظم إدارة قواعد البيانات المستقلة
بالنظر إلى طريقتين مختلفتين لإنشاء أنظمة قاعدة بيانات مستقلة ، فلنتحدث الآن عن كيفية تصميم نظام إدارة قواعد البيانات (DBMS) بحيث يكون مستقلاً.
دعونا نتناول ثلاثة مواضيع:
- كيفية ضبط المنظمين ،
- كيفية جمع المقاييس الداخلية ،
- كيفية تصميم الإجراءات.
مرة أخرى ، عد إلى النقاط الأساسية: يجب أن يوفر نظام قاعدة البيانات المعلومات الصحيحة لخوارزميات التعلم الآلي من أجل اعتماد قرارات أفضل لاحقًا. يجب تقليل كمية البيانات عديمة الفائدة التي نرسلها من أجل زيادة سرعة تلقي الردود.
, , , .
PG_SETTINGS , .
, , , .. , .
, , , , .
, , , .
:
- . , , .
- . , , -1 0, .
- , . , . 64- , 0 2 64 . , .
, . , 10 , , 10 . , .
- , . , , . , , , .
, , , . , . , , , — . , .
, , , . , .
, , . , : , , , , . - Oracle, , .

, , .
, , . , , , . - , , , . : PostgreSQL , .

, , , .
- , , , . , , . RocksDB, MyRocks MySQL.
RocksDB . , . , , , . RocksDB, .

, , , , . MyRocks . — :
ROCKSDB_BITES_READ, ROCKSDB_BITES_WRITTEN . , , . , . , .

, , , .
, , open source. , .
, ,
. MySQL , . , . 5 , 10 , , . 5 , — .
, . — PostgreSQL .
— . , . , , , , .
. , — SLA. , .
, . , . , . , .

, - , . , , - , . , , , — , -, , .
, , , .
, . , , , , 5- . downtime, .
, , , , , . , , , , .
Oracle autonomous database
Oracle . 2017 Oracle , . , Oracle, , « , Oracle 20 ».
. , , , , , . CIDR , . , : «, , , . , , , Oracle ?» , — ., , , Oracle. , .
,
— , , , - .
—
, . , , , 2000- . , Oracle , . , : , — - .
, . , , .
—
. , . : JOIN. . . , . .
Oracle. Microsoft 2017 SQL Server, . IBM DB2 00- , «LEO» — . , 1970-, Ingres. , JOIN, , . .
, , .
, , . , , . , , .
, , — , , , . , , , . , , .., .
HighLoad++ , HighLoad++ Siberia . , 39 , , highload- - .
HighLoad++ , . , UseData Conf — 16 , . , .