يعرف الكثير ممن عملوا مع Spark ML أن بعض الأشياء التي أنجزوها هناك "ليست ناجحة تمامًا".
أو لم تفعل على الإطلاق. يتمثل موقف مطوري Spark في أن SparkML هو النظام الأساسي ، ويجب أن تكون جميع الملحقات حزم منفصلة. لكن هذا ليس مريحًا دائمًا ، لأن Data Scientist والمحللين يريدون العمل باستخدام أدوات مألوفة (Jupter ، Zeppelin) ، حيث يوجد معظم ما هو مطلوب. لا يريدون جمع ملفات JAR 500 ميجابايت مع تجميع maven أو تنزيل التبعيات في أيديهم وإضافتها إلى معلمات بدء تشغيل Spark. قد يتطلب العمل الدقيق مع أنظمة إنشاء مشروع JVM الكثير من الجهود الإضافية من قبل المحللين و DataScientists الذين اعتادوا على Jupyter / Zeppelin. من الواضح أن مطالبة DevOps ومسؤولي الكتلة بوضع مجموعة من الحزم على عقد حساب فكرة سيئة. يعرف أي شخص كتب ملحقات لـ SparkML بمفرده عدد الصعوبات الخفية الموجودة في الفصول والأساليب المهمة (والتي لسبب ما خاصة [ml]) ، والقيود على أنواع المعلمات المخزنة ، إلخ
ويبدو أنه الآن ، مع مكتبة MMLSpark ، ستكون الحياة أسهل قليلاً ، والحد الأدنى لإدخال التعلم الآلي القابل للتطوير باستخدام SparkML و Scala أقل قليلاً.
مقدمة
نظرًا لعدد من الصعوبات ، فضلاً عن مجموعة قليلة من الطرق والحلول الجاهزة في SparkML ، تكتب العديد من الشركات امتداداتها لـ Spark. أحد الأمثلة على ذلك هو PravdaML ، الذي يتم تطويره في Odnoklassniki والذي ، بناءً على تقييم سريع لما هو موجود على GitHub ، يبدو واعداً للغاية. لسوء الحظ ، فإن معظم هذه الحلول إما مغلقة أو مفتوحة بشكل عام ، ولكن ليس لديها القدرة على التثبيت من خلال Maven / sbt ووثائق واجهة برمجة التطبيقات ، مما يجعل من الصعب للغاية العمل معهم.
اليوم ننظر إلى مكتبة MMLSpark .
سننظر ، كالعادة ، في مثال مهمة تصنيف ركاب السفينة تايتانيك. الهدف هو إظهار أكبر عدد ممكن من ميزات مكتبة MMLSpark ، وليس ذلك ضرب سوتا على ImageNet تظهر التعلم آلة باردة. لذلك سوف تيتانيك القيام به.

تحتوي المكتبة نفسها على واجهة برمجة تطبيقات أصلية لـ Scala ( التوثيق ) ، و Python API ( التوثيق ) ، واستناداً إلى بعض الأماكن في مستودع GitHub ، ستتوفر قريبًا واجهة برمجة تطبيقات لـ R.
هناك مثال جيد لأجهزة الكمبيوتر المحمولة في مشروع جيثب (PySpark + Jupyter) ، لكننا سنذهب في الاتجاه الآخر. كما كتب Dmitry Bugaychenko ، إذا قمت بالتطوير لصالح Spark ، فهناك كل الأسباب لاستخدام Scala لهذا ، علاوة على ذلك ، تسمح لك Scala بتعريف محولك ومقدرك على نحو أكثر كفاءة وأكثر مرونة لتضمينهما في SparkML Pipeline ، ولكن كيف تعمل ببطء / pandas code في UDF (تم استدعاؤه الملفات التنفيذية من JVM) قد تمت كتابة الكثير بالفعل.
موجز التثبيت
الكمبيوتر المحمول بأكمله متاح هنا . للعمل مع Titanic ، تكفي صورة Zeppelin Docker التي تعمل محليًا على جهاز كمبيوتر محمول مع الإعدادات الافتراضية للعيون. عامل الميناء يمكن العثور عليها هنا . مكتبة MMLSpark ليست في Maven Central ، ولكن في حزم شرارة ، ولإضافتها إلى Zeppelin ، يجب تشغيل الكتلة التالية في بداية الكمبيوتر المحمول:
%spark.dep z.addRepo("bintray.com").url("http://dl.bintray.com/spark-packages/maven/") z.load("Azure:mmlspark:0.17")
تجدر الإشارة إلى أن المكتبة تتمتع بتوافق خلفي ممتاز: على عكس ، على سبيل المثال ، XGBoost4j-spark ، التي تتطلب ما لا يقل عن Spark 2.3+ ، حصل هذا الشيء على Spark 2.2.1 ، الذي جاء مع صورة Zeppelin Docker ، وأي صعوبات لم ألاحظ.
ملاحظة: معظم مكتبة MMLSpark مخصصة لاستدلال الشبكات على الكتلة ، والتي يوجد بها CNTK (والتي ، بناءً على الوثائق ، يجب أن تقرأ طرز cntk الجاهزة) وكتلة OpenCV ضخمة. سنركز على المزيد من المهام الدنيوية ونحاول "محاكاة" الحالة عندما يكون لدينا صفائف ضخمة من البيانات المجدولة الموجودة في HDFS في شكل .csv أو جداول أو بتنسيق آخر. لذلك ، نحتاج إلى معالجتها مسبقًا وبناء نموذج ، في حين أن هذه البيانات لا تنسجم مع ذاكرة جهاز واحد. لذلك ، سوف نقوم بتنفيذ جميع الإجراءات على الكتلة.
قراءة وتحليل الذكاء
بشكل عام ، Spark + Zeppelin ليست سيئة على الإطلاق ويمكنها التعامل مع مهمة EDA ، لكننا سنحاول توسيع قدراتها. أولاً ، نستورد الفئات التي نحتاجها:
- الكل من spark.sql.types لإعلان مخطط وقراءة البيانات بشكل صحيح
- كل ذلك من spark.sql.functions إلى الوصول إلى الأعمدة واستخدام وظائف مدمجة
- com.microsoft.ml.spark.SummarizeData ، والتي يمكن تسميتها تناظرية pandas.DataFrame.describe
import com.microsoft.ml.spark.SummarizeData import org.apache.spark.sql.functions._ import org.apache.spark.sql.types._
نقرأ ملفنا:
val titanicSchema = StructType( StructField("Passanger", ShortType) :: StructField("Survived", ShortType) :: StructField("PClass", ShortType) :: StructField("Name", StringType) :: StructField("Sex", StringType) :: StructField("Age", ShortType) :: StructField("SibSp", ShortType) :: StructField("Parch", ShortType) :: StructField("Ticket", StringType) :: StructField("Fare", FloatType) :: StructField("Cabin", StringType) :: StructField("Embarked", StringType) :: Nil ) val train = spark .read .schema(titanicSchema) .option("header", true) .csv("/mountV/titanic/train.csv")
والآن دعونا نلقي نظرة على البيانات نفسها ، وكذلك حجمها:
println(s"Train shape is: ${train.count} x ${train.columns.length}") train.limit(5).createOrReplaceTempView("trainHead")
ملاحظة: ليست هناك حاجة حقًا لاستخدام createOrReplaceTempView عندما يمكنك فقط كتابة .show (5). لكن العرض لديه مشكلة: عندما تكون البيانات "واسعة" ، فإن التمثيل النصي للوحة "يتحرك" ، ولا يصبح أي شيء واضحًا على الإطلاق.
احصل على حجم بياناتنا: Train shape is: 891 x 12
والآن في الخلية sql يمكننا أن ننظر إلى أول 5 صفوف:
%sql select * from trainHead
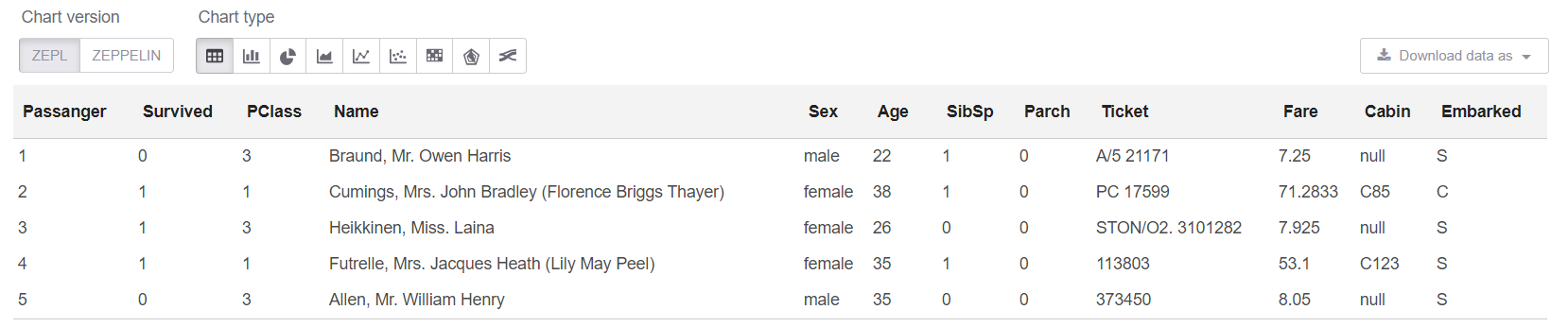
حسنًا ، دعنا نرى الملخص على طاولتنا:
new SummarizeData() .setBasic(true) .setCounts(true) .setPercentiles(false) .setSample(true) .setErrorThreshold(0.25) .transform(train) .createOrReplaceTempView("summary")
تتميز فئة SummarizeData بالعديد من المزايا على Dataset.describe البسيط ، لأنها تتيح لك حساب عدد القيم المفقودة والفريدة ، كما تتيح لك تحديد دقة حساب الكميات. هذا يمكن أن يكون حاسما بالنسبة للبيانات الكبيرة حقا.

بعض الأفكار الشخصيةبشكل عام ، بدا لي شخصيًا أن Odnoklassniki في PravdaML كان لديه تطبيق أفضل للتماثلية SummarizeData. قامت Microsoft بالطريقة السهلة وتستخدم org.apache.spark.sql.functions ، إنها مجرد لف كل شيء بشكل مريح في فصل واحد. بالنسبة إلى Odnoklassniki ، يتم تطبيق ذلك من خلال VectorStatCollector ، والذي يتطلب تعليمة برمجية أكثر تعقيدًا عند الاتصال (يجب عليك أولاً إضافة جميع الميزات إلى متجه) وقد يتطلب عمليات إضافية (على سبيل المثال ، يرفض DecimalType هضم DecimalType ). لكن لدي افتراض ، بناءً على تجربتي مع Spark ، أن SummarizeData من MMLSpark قد تتعطل مع أخطاء مثل StackOverflow في org.apache.spark.sql.catalyst إذا كان هناك العديد من الأعمدة بالفعل ، والرسم البياني للحساب ليس صغيراً بحلول وقت الإطلاق ( على الرغم من أن هؤلاء المشجعين من "المتطرفة" في Spark 2.4 ، إلا أنهم أضافوا القدرة على خفض مُحسِّن الرسم البياني Catalyst ). حسنًا ، يبدو أنه مع وجود عدد كبير من الأعمدة ، سيكون إصدار Microsoft أبطأ. ولكن هذا ، بالطبع ، يجب أن يتم التحقق بشكل منفصل.
تطهير البيانات
في تيتانيك ، كل شيء كالمعتاد - مجموعة من أعمدة السلسلة تفتقد القيم. ونوع من غير قادر في البيانات (يبدو أن هذا الإصدار معين من البيانات ليست محددة للغاية) - 25 أسطر من القيم المفقودة. أولاً ، قم بإصلاح هذا:
val trainFiltered = train.filter(!(isnan(col("Survived")) || isnull(col("Survived"))))
سلسلة معالجة البيانات
بقدر ما أتذكر ، كانت السمات التي تم الحصول عليها من حقول Name and Cabin هي الأفضل في Titanic. يمكنك توفيرها كثيرًا ، لكننا سنقتصر على عدد قليل ، حتى لا نعطي أمثلة على نفس الكود تقريبًا.
عادة ما يكون من المناسب استخدام التعبيرات العادية لمثل هذه الأشياء.
لكننا نريد في هذه الحالة:
- تم توزيع كل شيء ، وتمت معالجة البيانات في نفس المكان الذي كانت فيه ؛
- تم تصميم كل شيء على أنه فئات SpakrML Transformer أو Spark ML Estimator ، بحيث يمكن تجميعها لاحقًا في Pipeline.
ملاحظة: أولاً ، يضمن لنا خط الأنابيب أننا نطبق دائمًا نفس التحويلات على كل من القطار والاختبار ، كما يتيح لنا أيضًا اكتشاف خطأ "البحث في المستقبل" في التحقق من الصحة. كما أنه يوفر لنا إمكانات بسيطة لتوفير وتحميل ، والتنبؤ باستخدام خط أنابيب لدينا.
يحتوي SparkML على فئة "شبه عالمية" لمثل هذه المهام - SQLTranformer ، لكن من الواضح أن الكتابة في SQL أسوأ من الكتابة في Scala ، إذا كان ذلك بسبب إمكانية اكتشاف بناء جملة أو أخطاء نموذجية أثناء التحويل البرمجي وتمييز بناء الجملة في Idea. وهنا تأتي MMLSpark لمساعدتنا ، حيث يتم تطبيق محول UDFT عالمي حقيقي:
import com.microsoft.ml.spark.UDFTransformer
بادئ ذي بدء ، سنقوم بإنشاء وظيفة التحويل لدينا ، والتي هي بسيطة للغاية إلى الحد الأقصى ، ولكن هدفنا الآن هو إظهار عملية إنشاء UDFTransformer. من حيث المبدأ ، بناءً على مثل هذه الأمثلة البسيطة ، يمكن لأي شخص إضافة منطق إلى أي مستوى من التعقيد.
val miss = ".*miss\\..*".r val mr = ".*mr\\..*".r val mrs = ".*mrs\\..*".r val master = ".*master.*".r def convertNames(input: String): Option[String] = { Option(input).map(x => { x.toLowerCase match { case miss() => "Miss" case mr() => "Mr" case mrs() => "Mrs" case master() => "Master" case _ => "Unknown" } }) }
(يمكنك أن ترى على الفور مدى ملاءمة سكالا للعمل مع القيم المفقودة ، والتي ، بالمناسبة ، ليست فقط null ، ولكن أيضًا Double.NaN ، ولكن هناك هذه مزحة شيء نادر مثل الإغفالات في متغيرات BooleanType ، إلخ.)
أعلن الآن لدينا UserDefinedFunction وإنشاء Transformer على الفور على أساس ذلك:
val nameTransformUDF = udf(convertNames _) val nameTransformer = new UDFTransformer() .setUDF(nameTransformUDF) .setInputCol("Name") .setOutputCol("NameType")
ملاحظة: في جهاز الكمبيوتر المحمول Zeppelin ، يتشابه الأمر تمامًا ، ولكن عندما يتم تجميعه معًا لاحقًا في رمز الإنتاج ، من المهم أن تكون جميع UDF في فئات أو كائنات extends Serializable . الشيء الواضح الذي يمكنك نسيانه في بعض الأحيان ثم الدخول فيه لفترة طويلة هو الخطأ في قراءة آثار المكدس الطويلة من أخطاء Spark.
الآن لا يزال لدينا مجال Cabin . دعونا نلقي نظرة فاحصة على ذلك:

نرى أن هناك العديد من القيم المفقودة ، وهناك حروف وأرقام ومجموعات مختلفة ، إلخ. دعنا نأخذ عدد الحجرات (إذا كان هناك أكثر من كابينة) ، وكذلك الأرقام - ربما يكون لديهم نوع من المنطق ، على سبيل المثال ، إذا كان الترقيم من إحدى نهايات السفينة ، فكانت فرص كابينة في القوس أقل. سنقوم أيضًا بإنشاء وظائف ، ثم بناءً عليها UDFTransformer :
def getCabinsCount(input: String): Int = { Option(input) match { case Some(x) => x.split(" ").length case None => -1 } } val numPattern = "([az])([0-9]+)".r def getNumbersFromCabin(input: String): Int = { Option(input) match { case Some(x) => { x.split(" ")(0).toLowerCase match { case numPattern(sym, num) => Integer.parseInt(num) case _ => -1 } } case None => -2 } } val cabinsCountUDF = udf(getCabinsCount _) val numbersFromCabinUDF = udf(getNumbersFromCabin _) val cabinsCountTransformer = new UDFTransformer() .setInputCol("Cabin") .setOutputCol("CabinCount") .setUDF(cabinsCountUDF) val numbersFromCabinTransformer = new UDFTransformer() .setInputCol("Cabin") .setOutputCol("CabinNumber") .setUDF(numbersFromCabinUDF)
الآن لنبدأ بالقيم المفقودة ، وهي العمر. أولاً ، دعنا نستفيد من إمكانات التصور في زيبلين:
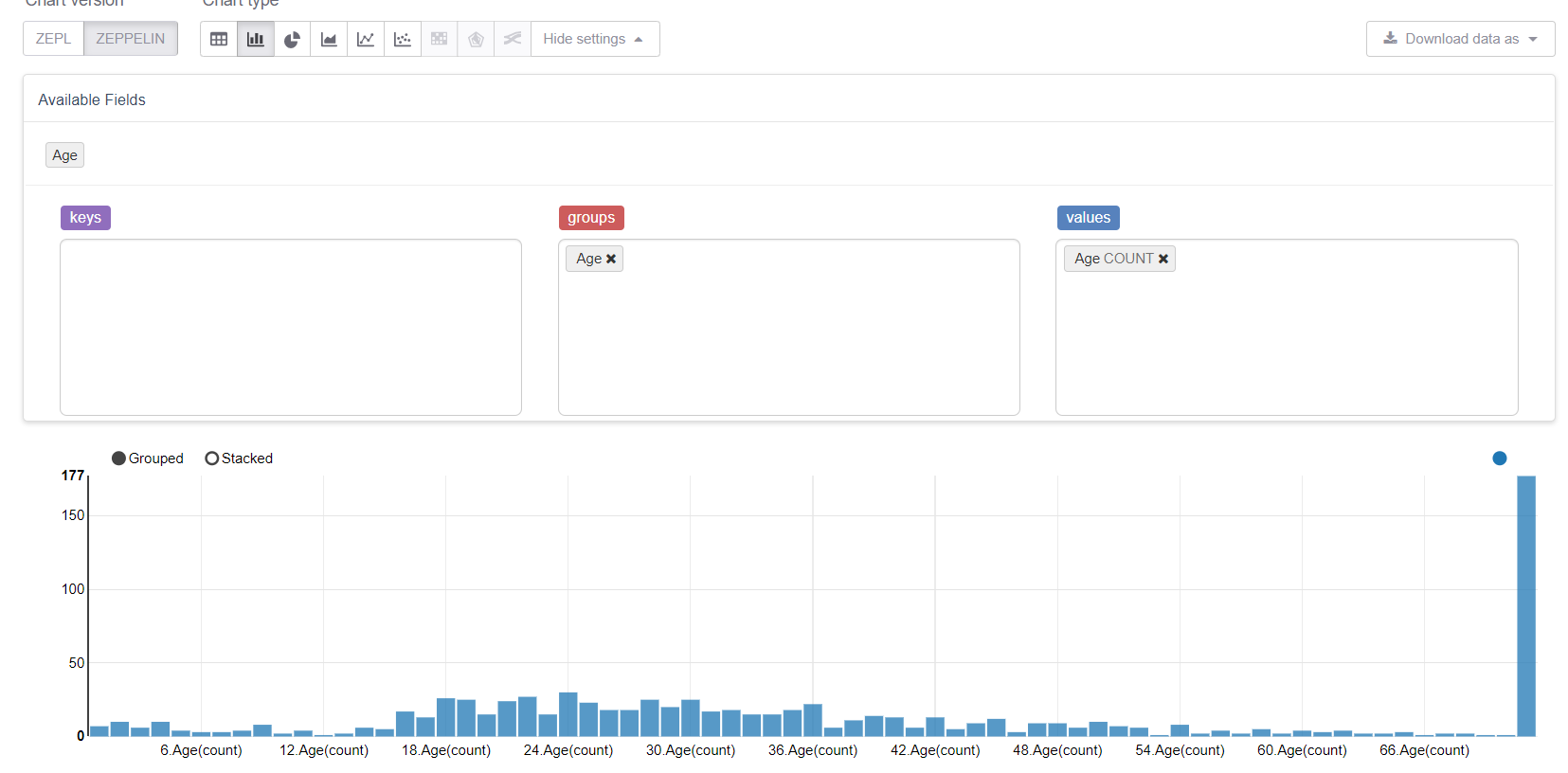
وانظر كيف تفسد القيم المفقودة كل شيء. سيكون من المنطقي استبدالها بوسط (أو وسيط) ، ولكن هدفنا هو النظر في جميع ميزات مكتبة MMLSpark. لذلك ، سوف نكتب Estimator الخاص ، والذي سينظر في مجموعة / متوسطات في عينة التدريب واستبدالها بالفجوات المقابلة.
سنحتاج:
import org.apache.spark.sql.{Dataset, DataFrame} import org.apache.spark.ml.{Estimator, Model} import org.apache.spark.ml.param.{Param, ParamMap} import org.apache.spark.ml.util.Identifiable import org.apache.spark.ml.util.DefaultParamsWritable import com.microsoft.ml.spark.{HasInputCol, HasOutputCol} import com.microsoft.ml.spark.ConstructorWritable import com.microsoft.ml.spark.ConstructorReadable import com.microsoft.ml.spark.Wrappable
دعونا نلاحظ ConstructorWritable ، مما يبسط الحياة إلى حد كبير. إذا كان Model بنا Model "مدربًا" fit(), طريقة fit(), ، والذي يتم تحديده بالكامل بواسطة مُنشئه (وربما يكون هذا 99٪ من الحالات) ، فلا يمكننا كتابة التسلسل بأيدينا على الإطلاق. يعمل هذا بالفعل على تبسيط عملية التطوير وتسريعها وإزالة الأخطاء وتقليل عتبة الدخول إلى DataScientist والمحللين الذين ليسوا عادة مبرمجين محترفين.
تحديد فئة Estimator لدينا. في الواقع ، أهم شيء هنا هو الأسلوب fit ، والباقي نقاط تقنية:
class GroupImputerEstimator(override val uid: String) extends Estimator[GroupImputerModel] with HasInputCol with HasOutputCol with Wrappable with DefaultParamsWritable { def this() = this(Identifiable.randomUID("GroupImputer")) val groupCol: Param[String] = new Param[String]( this, "groupCol", "Groupping column" ) def setGroupCol(v: String): this.type = super.set(groupCol, v) def getGroupCol: String = $(groupCol) override def fit(dataset: Dataset[_]): GroupImputerModel = { val meanDF = dataset .toDF .groupBy($(groupCol)) .agg(mean(col($(inputCol))).alias("groupMean")) .select(col($(groupCol)), col("groupMean")) new GroupImputerModel( uid, meanDF, getInputCol, getOutputCol, getGroupCol ) } override def transformSchema(schema: StructType): StructType = schema .add( StructField( $(outputCol), schema.filter(x => x.name == $(inputCol))(0).dataType ) ) override def copy(extra: ParamMap): Estimator[GroupImputerModel] = { val to = new GroupImputerEstimator(this.uid) copyValues(to, extra).asInstanceOf[GroupImputerEstimator] } }
ملاحظة: لم أستخدم defaultCopy ، لأنه عندما اتصلت ، لسبب ما ، أقسم أنني لم يكن لدي مُنشئ. \ <init> (java.lang.String) ، على الرغم من أنه يبدو أنه لا ينبغي أن يحدث هذا. حسنًا ، على أي حال ، فإن تنفيذ copy سهل.
تحتاج الآن إلى تطبيق Model - فصل يصف النموذج المدرب ويقوم بتنفيذ طريقة transform . سننشئها بناءً على وظيفة org.apache.spark.sql.functions المدمجة في org.apache.spark.sql.functions :
class GroupImputerModel( val uid: String, val meanDF: DataFrame, val inputCol: String, val outputCol: String, val groupCol: String ) extends Model[GroupImputerModel] with ConstructorWritable[GroupImputerModel] { val ttag: TypeTag[GroupImputerModel] = typeTag[GroupImputerModel] def objectsToSave: List[Any] = List(uid, meanDF, inputCol, outputCol, groupCol) override def copy(extra: ParamMap): GroupImputerModel = new GroupImputerModel(uid, meanDF, inputCol, outputCol, groupCol) override def transform(dataset: Dataset[_]): DataFrame = { dataset .toDF .join(meanDF, Seq(groupCol), "left") .withColumn( outputCol, coalesce(col(inputCol), col("groupMean")) .cast(IntegerType)) .drop("groupMean") } override def transformSchema (schema: StructType): StructType = schema .add( StructField(outputCol, schema.filter(x => x.name == inputCol)(0).dataType) ) }
آخر كائن نحتاج إلى إعلانه هو Reader ، والذي نطبقه باستخدام فئة MMLSpark ConstructorReadable :
object GroupImputerModel extends ConstructorReadable[GroupImputerModel]
إنشاء خطوط الأنابيب
في Pipeline ، أود أن أعرض كلاً من فصول SparkML المعتادة والشيء المريح بشكل لا يصدق من MMLSpark - MultiColumnAdapter ، والذي يسمح لك بتطبيق محولات SparkML على العديد من الأعمدة في وقت واحد (كمرجع ، على سبيل المثال ، StringIndexer و OneHotEncoder يأخذان عمودًا واحدًا بالضبط إلى الإدخال ، الأمر الذي يحولهما إعلان في الألم):
import org.apache.spark.ml.feature.{StringIndexer, VectorAssembler} import org.apache.spark.ml.Pipeline import com.microsoft.ml.spark.{MultiColumnAdapter, LightGBMClassifier}
أولاً ، سنعلن عن الأعمدة التي لدينا:
val catCols = Array("Sex", "Embarked", "NameType") val numCols = Array("PClass", "AgeNoMissings", "SibSp", "Parch", "CabinCount", "CabinNumber")
الآن قم بإنشاء تشفير السلسلة:
val stringEncoder = new MultiColumnAdapter() .setBaseStage(new StringIndexer().setHandleInvalid("keep")) .setInputCols(catCols) .setOutputCols(catCols.map(x => x + "_freqEncoded"))
ملاحظة: بخلاف scikit-Learn في SparkML ، تعمل StringIndexer على مبدأ تشفير التردد ، ويمكن استخدامه لتحديد علاقة الطلب (على سبيل المثال الفئة 0 <الفئة 1 ، وهذا منطقي في كثير من الأحيان) أشجار حاسمة.
Imputer لدينا Imputer :
val missingImputer = new GroupImputerEstimator() .setInputCol("Age") .setOutputCol("AgeNoMissings") .setGroupCol("Sex")
و VectorAssembler ، نظرًا لأن مصنفات SparkML أكثر راحة في العمل مع VectorType :
val assembler = new VectorAssembler() .setInputCols(stringEncoder.getOutputCols ++ numCols) .setOutputCol("features")
الآن سوف نستخدم تعزيز التدرج المزود بـ MMLSpark - LightGBM ، والذي تم تضمينه في "الثلاثة الكبار" من أفضل تطبيقات هذه الخوارزمية إلى جانب XGBoost و CatBoost. إنه يعمل عدة مرات بشكل أسرع وأفضل وأكثر استقرارًا من تطبيق GBM الذي لدى SparkML (حتى مع مراعاة أن منفذ JVM لا يزال قيد التطوير النشط):
val catColIndices = Array(0, 1, 2) val lgbClf = new LightGBMClassifier() .setFeaturesCol("features") .setLabelCol("Survived") .setProbabilityCol("predictedProb") .setPredictionCol("predictedLabel") .setRawPredictionCol("rawPrediction") .setIsUnbalance(true) .setCategoricalSlotIndexes(catColIndices) .setObjective("binary")
ملاحظة: يدعم LightGBM العمل مع المتغيرات الفئوية (مثل تقريبًا catboost) ، لذلك أشرنا إليها مقدمًا حيث توجد سمات الفئة في متجهنا ، وسيقوم هو بنفسه بمعرفة ما يجب فعله بها وكيفية تشفيرها.
المزيد عن ميزات LightGBM لـ Spark- على العقد التي تشغل RadHat LightGBM ، فإن أي إصدار باستثناء أحدث إصدار سوف يتعطل بسبب حقيقة أنه لا يحب إصدار
glibc . تم إصلاح هذا مؤخرًا ، عند التثبيت عبر Maven ، تقوم MMLSpark بسحب الإصدار قبل الأخير من LightGBM عند التثبيت عبر Maven ، لذلك تحتاج إلى إضافة تبعية أحدث إصدار على RadHat بيديك. - تقوم LightGBM في عملها بإنشاء مقبس على برنامج التشغيل للتواصل مع المديرين التنفيذيين ، ويقوم بذلك باستخدام
new java.net.ServerSocket(0) ، وبالتالي يتم استخدام منفذ عشوائي من المنافذ المؤقتة لنظام التشغيل. إذا كان نطاق المنافذ المؤقتة يختلف عن نطاق المنافذ المفتوحة بواسطة جدار الحماية ، إذن يمكن أن يحرق الكثير يمكنك الحصول على تأثير مثير للاهتمام عندما يعمل LightGBM أحيانًا (عندما اخترت منفذًا جيدًا) وفي بعض الأحيان لا. وستكون هناك أخطاء مثل ConnectionTimeOut ، والتي يمكن أن تشير أيضًا ، على سبيل المثال ، إلى الخيار عند تعليق GC على المديرين التنفيذيين أو شيء من هذا القبيل. بشكل عام ، لا تكرر أخطائي.
حسنًا ، أخيرًا ، أعلن خط أنابيبنا:
val pipeline = new Pipeline() .setStages( Array( missingImputer, nameTransformer, cabinsCountTransformer, numbersFromCabinTransformer, stringEncoder, assembler, lgbClf ) )
تدريب
سنقوم بتقسيم مجموعة التدريب الخاصة بنا إلى قطار واختبار والتحقق من خط أنابيبنا. هنا يمكنك فقط تقييم راحة خط الأنابيب ، لأنه مستقل تمامًا عن القسم ويضمن أننا سنطبق نفس التحويلات على التدريب والاختبار ، وسيتم تعلم جميع معلمات التحول في القطار:
val Array(trainDF, testDF) = trainFiltered.randomSplit(Array(0.8, 0.2)) println(s"Train rows: ${trainDF.count}\nTest rows: ${testDF.count}")
من أجل حساب مناسب للمقاييس ، سوف نستخدم فئة أخرى من MMLSpark - ComputeModelStatistics :
import com.microsoft.ml.spark.ComputeModelStatistics import com.microsoft.ml.spark.metrics.MetricConstants val modelEvaluator = new ComputeModelStatistics() .setLabelCol("Survived") .setScoresCol("predictedProb") .setScoredLabelsCol("predictedLabel") .setEvaluationMetric(MetricConstants.ClassificationMetrics)
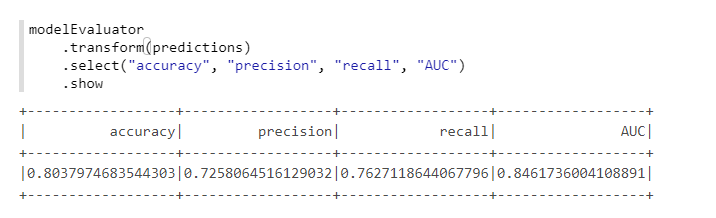
ليس سيئًا ، نظرًا لأننا لم نغير الإعدادات الافتراضية.
اختيار hyperparameters
لتحديد معلمات تشعبية في MMLSpark ، يوجد TuneHyperparameters باردة منفصلة ، والتي تنفذ عملية بحث عشوائية على الشبكة. ومع ذلك ، لسوء الحظ ، لا يدعم Pipeline حتى الآن ، لذلك سنستخدم CrossValidator CrossValidator المعتاد:
import org.apache.spark.ml.tuning.{ParamGridBuilder, CrossValidator} import org.apache.spark.ml.evaluation.BinaryClassificationEvaluator val paramSpace = new ParamGridBuilder() .addGrid(lgbClf.maxDepth, Array(3, 5)) .addGrid(lgbClf.learningRate, Array(0.05, 0.1)) .addGrid(lgbClf.numIterations, Array(100, 300)) .build println(s"Size of ParamsGrid: ${paramSpace.size}")
لسوء الحظ ، لم أجد طريقة مناسبة لكيفية رؤية النتائج مع تلك المعايير التي تم الحصول عليها عليها. لذلك ، من الضروري استخدام التصميمات "الوحشية":
crossValidator .getEstimatorParamMaps .zip(bestModel.avgMetrics) .foreach(x => { println( "\n" + x._1 .toSeq .foldLeft(new StringBuilder())( (a, b) => a .append(s"\n\t${b.param.name} : ${b.value}")) .toString + s"\n\tMetric: ${x._2}" ) })
الذي يعطينا شيء مثل هذا:
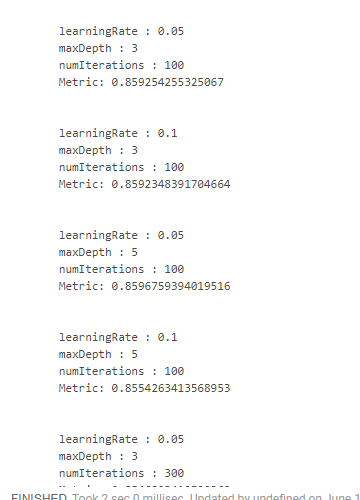
حصلنا على أفضل نتيجة عن طريق تقليل سرعة التعلم وزيادة عمق الأشجار. على هذا الأساس ، سيكون من الممكن ضبط مساحة البحث والتوصل إلى نتيجة أفضل ، لكن ببساطة ليس لدينا مثل هذا الهدف.
استنتاج
في الواقع ، في حين أن MMLSpark لديه الإصدار 0.17 ولا يزال يحتوي على أخطاء منفصلة. ولكن من بين جميع امتدادات Spark التي رأيتها ، فإن MMLSpark في رأيي لديه أكثر المستندات شمولاً وعملية التثبيت والتنفيذ الأكثر قابلية للفهم. لم تقم Microsoft بالترويج له بالفعل ، لم يكن هناك سوى تقرير حول Databricks ، ولكن كان هناك المزيد حول DeepLearning ، وليس حول هذه الأشياء الروتينية التي كتبت عنها.
شخصيًا ، في مهامنا ، ساعدت هذه المكتبة كثيرًا ، حيث سمحت لي بالوصول إلى القليل من غابة مصادر Spark وعدم استخدام المنعكس للوصول إلى طرق [ml] خاصة ، ووجد أحد الزملاء المكتبة عن طريق الصدفة تقريبًا. في الوقت نفسه ، ويرجع ذلك إلى حقيقة أن المكتبة قيد التطوير النشط ، بنية الملف المصدر عصيدة كاملة مربكة إلى حد ما. حسنًا ، نظرًا لحقيقة عدم وجود أمثلة خاصة أو مستندات أخرى (باستثناء scaladoc العارية) ، فقد اضطررنا في البداية إلى الزحف إلى شفرة المصدر باستمرار.
لذلك ، آمل حقًا أن يكون هذا البرنامج التعليمي المصغر (على الرغم من وضوحه وبساطته) مفيدًا لشخص ما وسيساعد في توفير الكثير من الوقت والجهد!