يمكن العثور على الدورة الكاملة باللغة الروسية على هذا الرابط .
دورة اللغة الإنجليزية الأصلية متاحة على هذا الرابط .

ومن المقرر محاضرات جديدة كل 2-3 أيام.
محتوى
- مقابلة مع سيباستيان ترون
- مقدمة
- الكلاب والقطط مجموعة البيانات
- صور من مختلف الأحجام
- الصور الملونة. الجزء 1
- الصور الملونة. الجزء 2
- عملية الالتواء على الصور الملونة
- تشغيل أخذ العينات من خلال الحد الأقصى للقيمة في الصور الملونة
- CoLab: القطط والكلاب
- Softmax و السيني
- تفتيش
- تمديد الصورة
- استثناء
- CoLab: الكلاب والقطط. تكرار
- تقنيات أخرى لمنع إعادة التدريب
- التمارين: تصنيف الصور الملونة
- الحل: تصنيف صورة ملونة
- النتائج
مقابلة مع سيباستيان ترون
- لذلك ، نحن هنا اليوم مرة أخرى ، مع سيباستيان وسنتحدث عن إعادة التدريب. هذا الموضوع مثير جدًا لنا ، لا سيما في الأجزاء العملية من الدورة التدريبية الحالية حول العمل مع TensorFlow.
- سيباستيان ، هل سبق لك أن واجهت تحليقًا جيدًا؟ إذا قلت أنك لم تصادف ، فسأقول بالتأكيد أنني لا أصدقك!
- لذا ، فإن سبب إعادة التدريب هو ما يسمى بمفاضلة التباين في الانحياز (حل وسط بين قيم معلمة التحيز وانتشارها). شبكة عصبية فيها عدد قليل من الأوزان غير قادرة على تعلم عدد كاف من الأمثلة ، وتسمى حالة مماثلة في التعلم الآلي التشويه.
- نعم.
- يمكن أن تختار الشبكة العصبية التي تحتوي على الكثير من المعلمات بشكل تعسفي حلًا لا تريده ، وذلك بسبب هذا العدد الكبير من هذه المعلمات. تعتمد نتيجة اختيار حل الشبكة العصبية على تباين البيانات المصدر. وبالتالي ، يمكن صياغة قاعدة بسيطة: فكلما زاد عدد المعلمات في الشبكة فيما يتعلق بحجم (كمية) البيانات ، زاد احتمال الحصول على حل عشوائي بدلاً من الحل الصحيح. على سبيل المثال ، أنت تسأل نفسك ، "من هو الرجل في هذه الغرفة ومن هي المرأة؟" يمكن لشبكة عصبية معقدة أن تخبرك ، على سبيل المثال ، أن جميع الذين تبدأ أسماؤهم بحرف T هم رجال ولا يتراجعون أبدًا. هناك حلان. يستخدم أولها مجموعة بيانات تعليق (مقدار صغير من مجموعة التدريب للتحقق من صحة دقة النموذج). يمكنك أخذ البيانات وتقسيمها إلى جزأين - 90٪ للتدريب ، و 10٪ لاختبار وإجراء ما يسمى التحقق المتبادل ، حيث تتحقق من دقة النموذج على البيانات التي لم تراها الشبكة العصبية - بمجرد أن تبدأ قيمة الخطأ لتنمو بعد دورة تدريبية معينة - حان الوقت للتوقف عن التعلم. الحل الثاني هو إدخال قيود في الشبكة العصبية. على سبيل المثال ، للحد من قيم معلمات النزوح والأوزان ، وجعلها أقرب وأقرب إلى الصفر. كلما كانت الأوزان محدودة ، كان النموذج أقل تدريباً.
- أفهم بشكل صحيح أنه يمكننا الحصول على مجموعات بيانات للتدريب والاختبار والتحقق من الصحة ، أليس كذلك؟
- هذا صحيح. إذا كان لديك مجموعة بيانات للتحقق من الصحة ، فيجب أن يكون لديك مجموعة بيانات لم تلمسها أبدًا أو تظهر على شبكتك العصبية. إذا عرضت النموذج على مجموعة معينة من البيانات عدة مرات ، فعندئذ بالطبع ، ستبدأ عملية إعادة التدريب ، وهو أمر سيء للغاية بالنسبة لنا.
- ربما تتذكر أكثر الحالات إثارة عندما تم إعادة تدريب النموذج الخاص بك؟
"آه ، نعم ... كان هناك مثل هذا الحادث في شبابي الأوائل عندما كنت أقوم بتطوير شبكة عصبية للعب الشطرنج". كان ذلك في عام 1993. وكان الأمر المثير للاهتمام هو أنه من خلال بيانات الشطرنج التي تم تدريب الشبكة العصبية عليها ، حددت الشبكة بسرعة أنه إذا نقل خبير الملكة إلى مركز رقعة الشطرنج ، فستكون هناك فرصة بنسبة 60 ٪ للفوز. ما بدأت تفعله هو فتح "الممر" مع البيدق ونقل الملكة إلى وسط رقعة الشطرنج. لقد كان قرارًا غبيًا لأي لاعب شطرنج ، والذي شهد بوضوح على إعادة تدريب النموذج.
- عظيم! لذلك ، ناقشنا العديد من التقنيات المتعلقة بكيفية تحسين نماذجنا. ما رأيك هو الجانب الأكثر استخفافًا بالتعلم العميق؟
- يتم التقليل من 90 ٪ من عملك ، لأن 90 ٪ من عملك سيتألف من تطهير البيانات.
- أنا هنا أتفق معك تمامًا!
- كما تبين الممارسة ، فإن أي مجموعة بيانات تحتوي على نوع من القمامة. من الصعب للغاية توصيل البيانات بالطريقة الصحيحة ، وجعلها متسقة ، إنها عملية تستغرق وقتًا طويلاً للغاية.
- نعم ، حتى إذا كنت تعمل مع مجموعات البيانات مثل الصور أو مقاطع الفيديو ، حيث يبدو أن جميع المعلومات موجودة بالفعل ، في الداخل ، لا تزال هناك حاجة إلى معالجة الصور مسبقًا.
- الأشخاص الوحيدون الذين تكون البيانات مثالية بالنسبة لهم هم الأساتذة ، لأن لديهم الفرصة للتظاهر في عرض تقديمي في PowerPoint أن كل شيء كما يجب أن يكون وأن كل شيء مثالي! في الواقع ، ستشغل 90 ٪ من وقتك من خلال تطهير البيانات.
- عظيم. لذلك ، دعونا نتعرف أكثر على إعادة التدريب والتقنيات التي ستتيح لنا تحسين نماذج التعلم العميق.
مقدمة
- مرحبا! ومرة أخرى ، مرحبا بكم في الدورة!
"في الدرس الأخير ، قمنا بتطوير شبكة عصبية تلافيفية صغيرة لتصنيف صور عناصر الملابس بظلال رمادية من مجموعة بيانات FASHION MNIST. لقد رأينا في الممارسة العملية أن شبكتنا العصبية الصغيرة يمكنها تصنيف الصور الواردة بدقة عالية إلى حد ما. ومع ذلك ، في العالم الحقيقي علينا أن نعمل مع صور عالية الدقة وأحجام مختلفة. واحدة من المزايا العظيمة لنظام الحسابات القومية هي حقيقة أنها يمكن أن تعمل فقط مع الصور الملونة. لذلك ، سنبدأ درسنا الحالي من خلال استكشاف كيفية عمل SNA مع الصور الملونة.
- في وقت لاحق ، في نفس التردد ، ستقوم ببناء شبكة عصبية تلافيفية يمكنها تصنيف صور القطط والكلاب. في الطريق إلى تنفيذ شبكة عصبية تلافيفية قادرة على تصنيف صور القطط والكلاب ، سوف نتعلم أيضًا كيفية استخدام التقنيات المختلفة لحل واحدة من أكثر المشكلات شيوعًا في الشبكات العصبية - إعادة التدريب. وفي نهاية هذا الدرس ، في الجزء العملي ، ستقوم بتطوير شبكتك العصبية التلافيفية الخاصة لتصنيف الصور الملونة. لنبدأ!
القطط والكلاب Dataset
حتى تلك اللحظة ، عملنا فقط مع الصور ذات الأحجام الرمادية والأحجام 28 × 28 من مجموعة بيانات FASHION MNIST.

في التطبيقات الحقيقية ، نحن مضطرون إلى مواجهة صور بأحجام مختلفة ، على سبيل المثال ، الصور الموضحة أدناه:

كما ذكرنا في بداية هذا الدرس ، سنقوم في هذا الدرس بتطوير شبكة عصبية تلافيفية يمكنها تصنيف الصور الملونة للكلاب والقطط.
لتنفيذ خططنا ، سنستخدم صور القطط والكلاب من مجموعة بيانات Microsoft Asirra. يتم تمييز كل صورة في مجموعة البيانات هذه بالرقم 1 أو 0 إذا كان هناك كلب أو قطة في الصورة ، على التوالي.

على الرغم من حقيقة أن مجموعة بيانات Microsoft Asirra تحتوي على أكثر من 3 ملايين صورة موسومة من القطط والكلاب ، لا يتوفر سوى 25000 صورة للجمهور. تدريب شبكتنا العصبية التلافيفية على هذه الصور 25000 سيستغرق الكثير من الوقت. هذا هو السبب في أننا سوف نستخدم عددًا صغيرًا من الصور لتدريب شبكتنا العصبية التلافيفية من 25000 صورة متوفرة.
لدينا مجموعة فرعية من الصور التدريب يتكون من 2000 جهاز كمبيوتر شخصى و 1000 جهاز كمبيوتر شخصى من الصور للتحقق من صحة النموذج. في مجموعة البيانات التدريبية ، تحتوي 1000 صورة على قطط بينما تحتوي 1000 صورة أخرى على كلاب. سنتحدث عن مجموعة البيانات للتحقق من صحتها لاحقًا في هذا الجزء من الدرس.
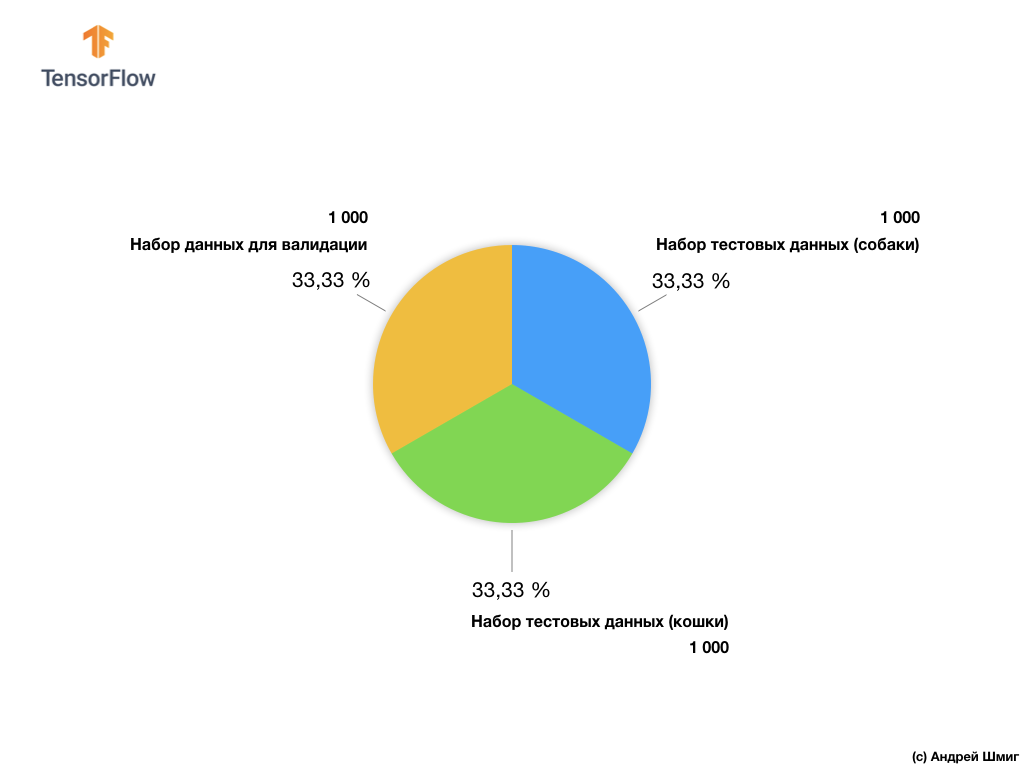
من خلال العمل مع مجموعة البيانات هذه ، سنواجه مشكلتين رئيسيتين - العمل مع الصور ذات الأحجام المختلفة والعمل مع الصور الملونة.
لنبدأ في استكشاف كيفية العمل مع الصور ذات الأحجام المختلفة.
صور من مختلف الأحجام
سيكون أول اختبار لدينا هو حل مشكلة معالجة الصور من مختلف الأحجام. ذلك لأن الشبكة العصبية عند الإدخال تحتاج إلى بيانات ثابتة الحجم.
على سبيل المثال ، يمكنك أن تتذكر من input_shape السابقة باستخدام معلمة input_shape عند إنشاء طبقة Flatten :

قبل نقل صورة عنصر الملابس إلى شبكة عصبية ، قمنا بتحويلها إلى صفيف ثنائي الأبعاد بحجم ثابت - 28 × 28 = 784 عنصرًا (بكسل). نظرًا لأن الصور الموجودة في مجموعة بيانات Fashion MNIST كانت بنفس الحجم ، فإن الصفيف أحادي البعد الناتج كان بنفس الحجم ويتألف من 784 عنصرًا.
ومع ذلك ، من خلال العمل مع الصور ذات الأحجام المختلفة (الطول والعرض) وتحويلها إلى صفائف أحادية البعد ، نحصل على صفائف بأحجام مختلفة.
نظرًا لأن الشبكات العصبية في المدخلات تتطلب بيانات من نفس الحجم ، فلا يكفي مجرد التحول إلى مجموعة أحادية البعد من قيم البيكسل.
لحل مشكلات تصنيف الصور ، نلجأ دائمًا إلى أحد الخيارات لتوحيد بيانات الإدخال - تقليل حجم الصور إلى قيم شائعة (تغيير الحجم).
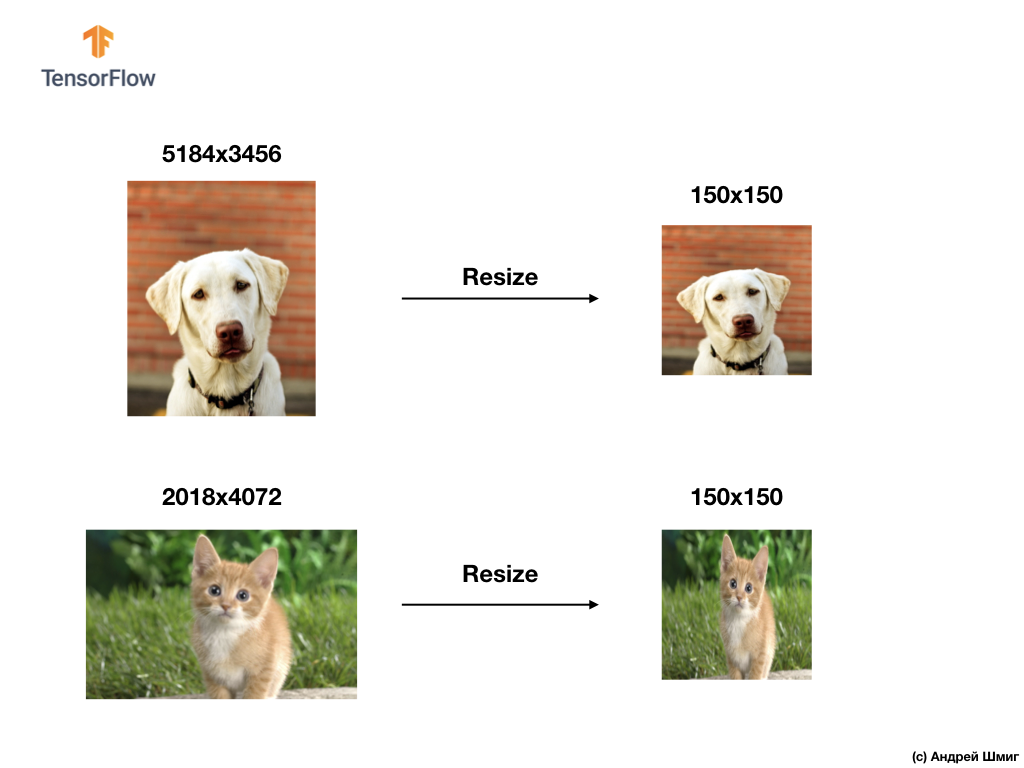
في هذا البرنامج التعليمي ، سوف نلجأ إلى تغيير حجم جميع الصور إلى أحجام تصل إلى 150 بكسل في العرض و 150 بكسل في العرض. تحويل الصور إلى حجم واحد ، فإننا نضمن أن تصل الصورة بالحجم الصحيح إلى مدخلات الشبكة العصبية ، وعند نقلها إلى طبقة مسطحة ، نحصل على مجموعة أحادية البعد من نفس الحجم.
tf.keras.layers.Flatten(input_shape(150,150,1))
نتيجة لذلك ، حصلنا على صفيف أحادي البعد يتكون من 150 × 150 = 22،500 قيمة (بكسل).
المشكلة التالية التي سنواجهها هي مشكلة الصور الملونة. سنتحدث عنها في الجزء التالي.
الصور الملونة. الجزء 1
من أجل فهم وفهم كيفية عمل الشبكات العصبية التلافيفية مع الصور الملونة ، ينبغي لنا أن نتعمق في كيفية عمل نظام الحسابات القومية بالضبط بشكل عام. دعونا تحديث ما نعرفه بالفعل.
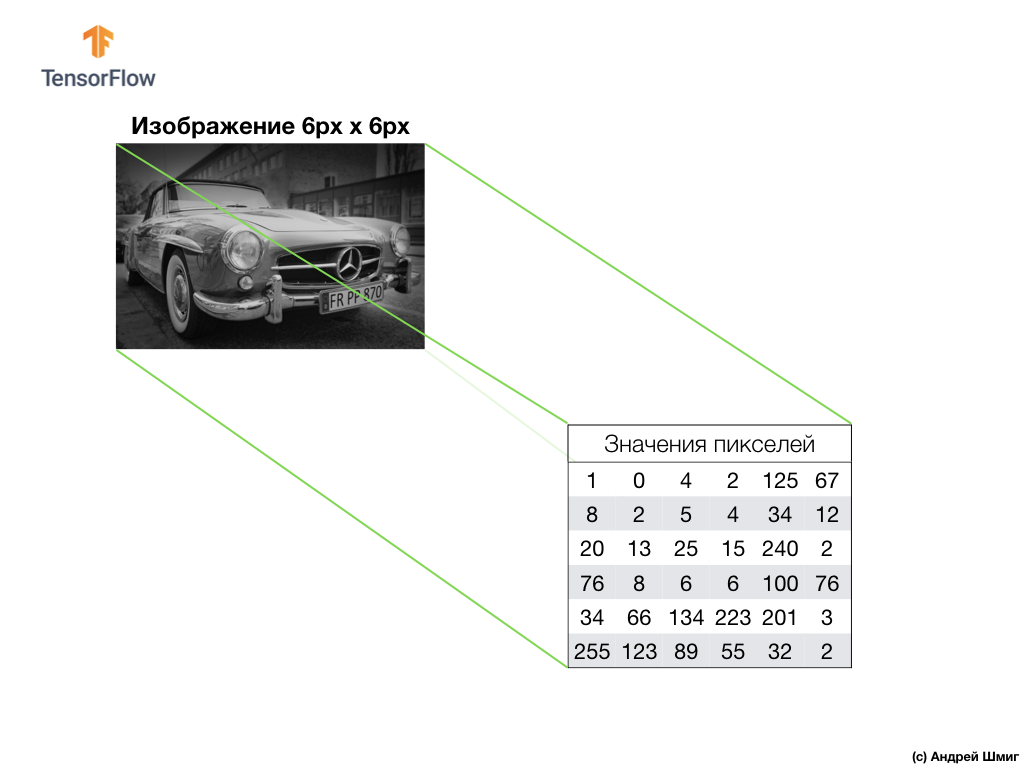
مثال أعلاه هو صورة تدرج الرمادي وكيف يفسرها الكمبيوتر كصفيف ثنائي الأبعاد لقيم البكسل.
مثال أدناه هو صورة ، وهذه المرة لون ، وكيف يفسرها الكمبيوتر كصفيف ثلاثي الأبعاد لقيم البكسل.
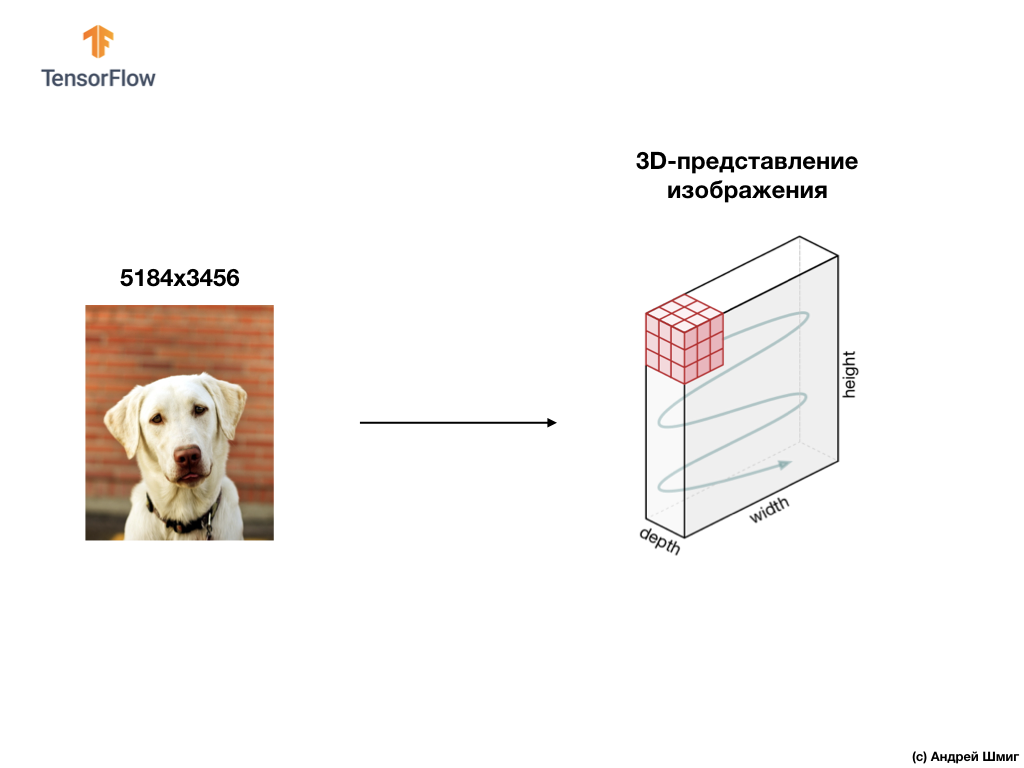
سيتم تحديد ارتفاع وعرض الصفيف ثلاثي الأبعاد حسب ارتفاع وعرض الصورة ، ويحدد العمق (العمق) عدد قنوات الألوان في الصورة.
يمكن تمثيل معظم الصور الملونة بثلاث قنوات ملونة - الأحمر (الأحمر) ، الأخضر (الأخضر) والأزرق (الأزرق).

الصور التي تتكون من قنوات حمراء وخضراء وزرقاء تسمى صور RGB. ينتج عن الجمع بين هذه القنوات الثلاث صورة ملونة. في كل صورة من صور RGB ، يتم تمثيل كل قناة بمصفوفة منفصلة ثنائية الأبعاد من البكسل.
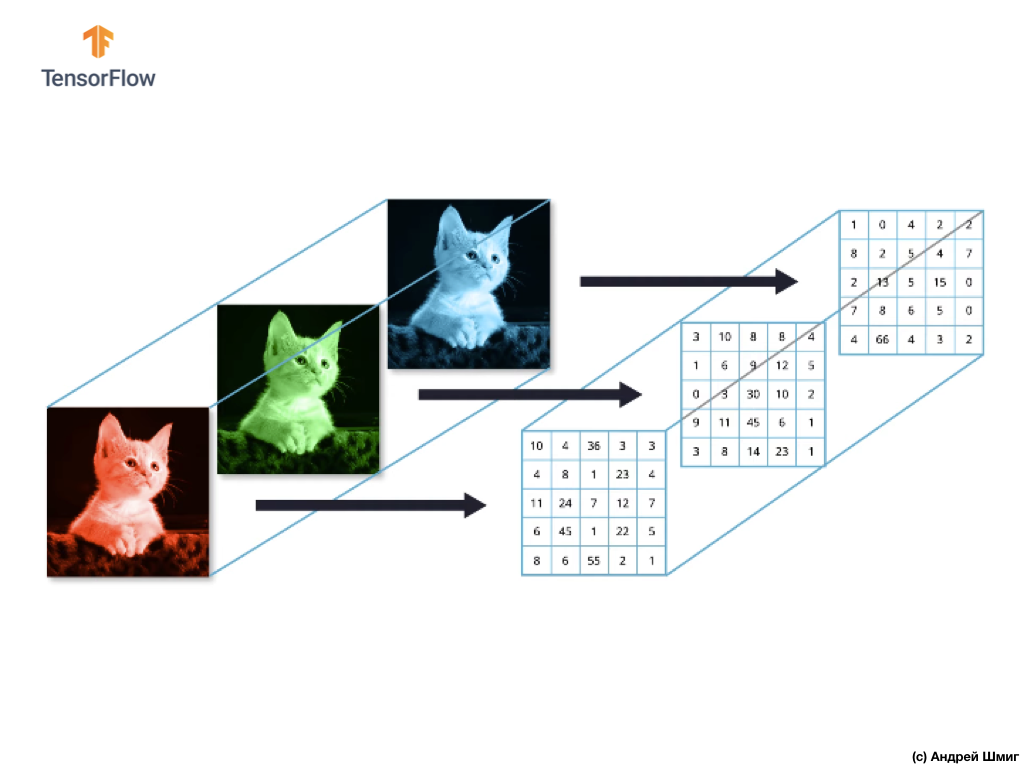
نظرًا لأن عدد القنوات الموجودة لدينا هو ثلاثة ، فنتيجة لذلك ، سيكون لدينا ثلاث صفيفات ثنائية الأبعاد. وبالتالي ، فإن الصورة الملونة التي تتكون من 3 قنوات ملونة سيكون لها التمثيل التالي:

الصور الملونة. الجزء 2
لذا ، نظرًا لأن صورتنا ستتكون الآن من 3 ألوان ، مما يعني أنها ستكون عبارة عن مجموعة ثلاثية الأبعاد لقيم البكسل ، فستحتاج إلى تغيير الرمز الخاص بنا وفقًا لذلك.
إذا نظرت إلى الكود الذي استخدمناه في الدرس الأخير عندما كنا نحل مشكلة تصنيف عناصر الملابس في الصور ، يمكننا أن نرى أننا أشرنا إلى بُعد بيانات الإدخال:
model = Sequential() model.add(Conv2D(32, 3, padding='same', activation='relu', input_shape=(28,28,1)))
(28,28,1) من tuple (28,28,1) هما قيم ارتفاع وعرض الصورة. كانت الصور في مجموعة بيانات Fashion MNIST بحجم 28 × 28 بكسل. تشير المعلمة الأخيرة في المجموعة (28,28,1) إلى عدد قنوات الألوان. في مجموعة بيانات Fashion MNIST ، كانت الصور في ظلال قناة اللون الرمادي - 1 فقط.
الآن وقد أصبحت المهمة أكثر تعقيدًا قليلاً ، وأصبحت صورنا للقطط والكلاب بأحجام مختلفة (لكن تم تحويلها إلى واحدة - 150 × 150 بكسل) وتحتوي على 3 قنوات ملونة ، ثم يجب أن تكون مجموعة القيم مختلفة أيضًا:
model = Sequential() model.add(Conv2D(16, 3, padding='same', activation='relu', input_shape=(150,150,3)))
في الجزء التالي ، سنرى كيف يتم حساب الالتواء في وجود ثلاث قنوات ملونة في الصورة.
عملية الالتواء على الصور الملونة
في الدروس السابقة ، تعلمنا كيفية إجراء عملية الالتواء على الصور ذات الدرجات الرمادية. ولكن كيف يمكن إجراء عملية الالتواء على الصور الملونة؟ لنبدأ بتكرار كيفية إجراء عملية الالتواء على الصور ذات التدرج الرمادي.
كل شيء يبدأ مع مرشح (الأساسية) من حجم معين.
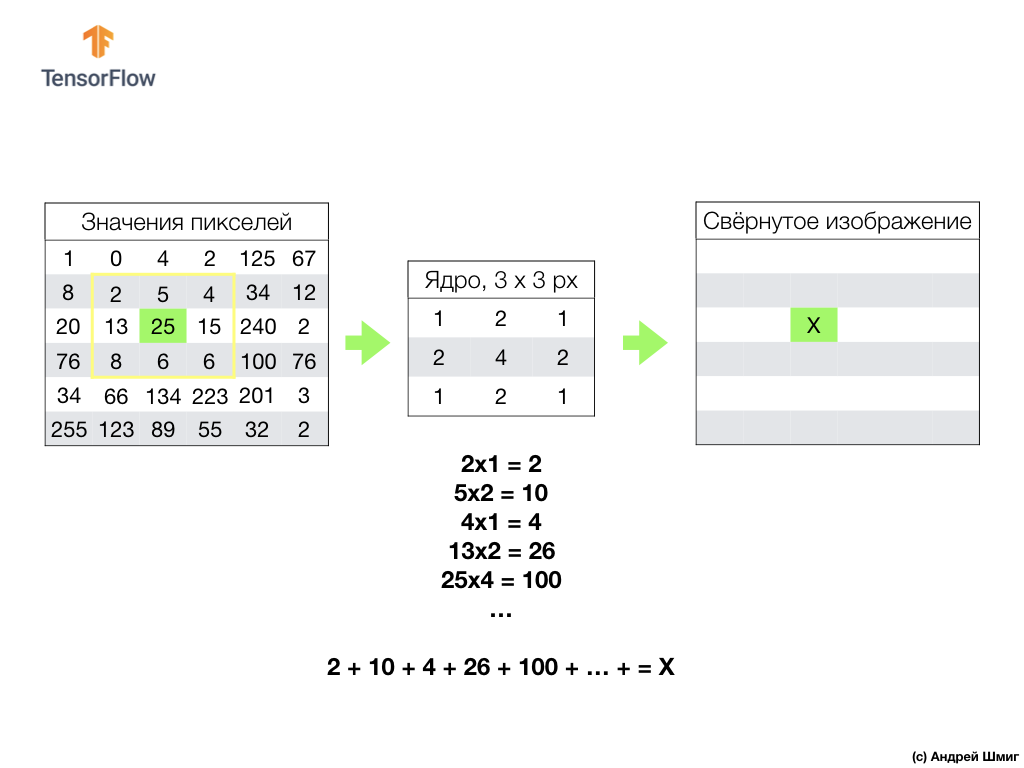
يوجد المرشح على بكسل صورة معين ليتم تحويله ، ثم يتم ضرب كل قيمة مرشح بقيمة بكسل المقابلة في الصورة ويتم جمع كل هذه القيم. يتم تعيين قيمة البيكسل النهائية في الصورة الجديدة في المكان الذي يوجد به البيكسل الأصلي المحول. يتم تكرار العملية لكل بكسل من الصورة الأصلية.
تجدر الإشارة أيضًا إلى أنه أثناء عملية الالتفاف ، حتى لا تفقد المعلومات على حدود الصورة ، يمكننا تطبيق المحاذاة وتثبيت حواف الصورة باستخدام الأصفار:

الآن دعنا نتعرف على كيفية القيام بعملية الالتفاف على الصور الملونة.
تمامًا كما هو الحال عند تحويل صورة بظلال رمادية ، نبدأ باختيار حجم المرشح (الأساسي) بحجم معين.

الفرق الوحيد الآن هو أن المرشح نفسه سيكون ثلاثي الأبعاد ، وقيمة المعلمة العمق ستكون مساوية لقيمة عدد قنوات الألوان في الصورة - 3 (في حالتنا ، RGB). لكل "طبقة" من قناة اللون ، سنقوم أيضًا بتطبيق عملية الالتفاف مع مرشح بالحجم المحدد. دعونا نرى كيف سيكون مثالا.
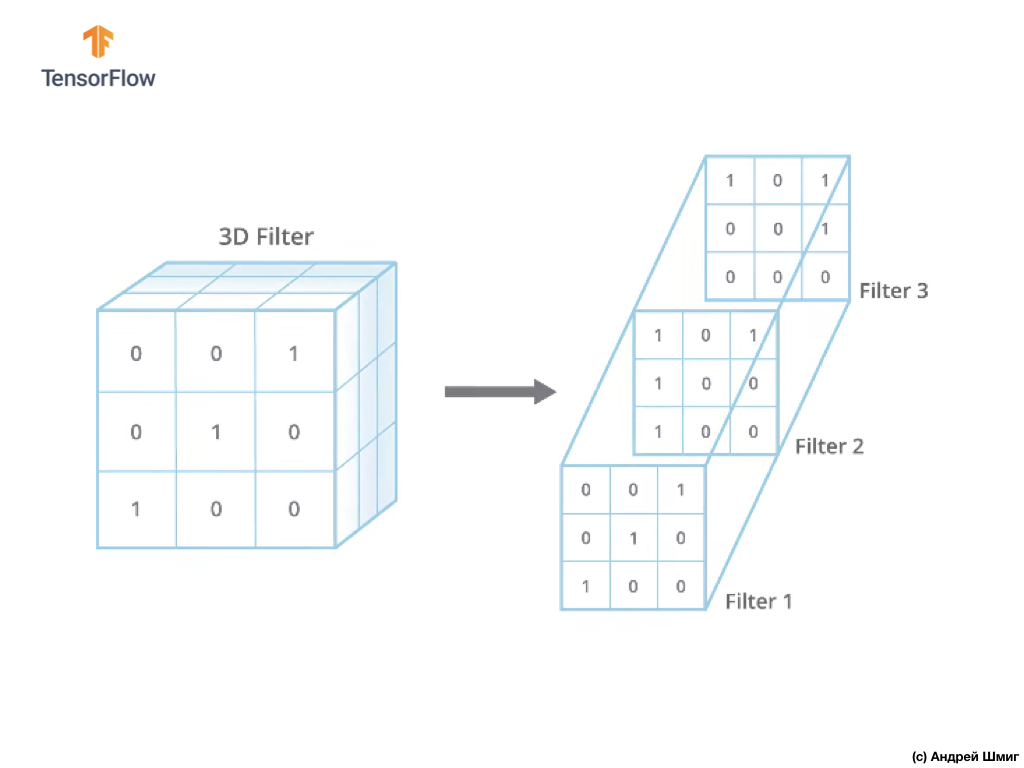
تخيل أن لدينا صورة RGB ونريد تطبيق عملية الالتفاف مع المرشح ثلاثي الأبعاد التالي. يجدر الانتباه إلى حقيقة أن مرشحنا يتكون من 3 مرشحات ثنائية الأبعاد. للبساطة ، دعونا نتخيل أن حجم صورة RGB لدينا هو 5 × 5 بكسل.

تذكر أيضًا أن كل قناة لون عبارة عن صفيف ثنائي الأبعاد لقيم ألوان البيكسل.
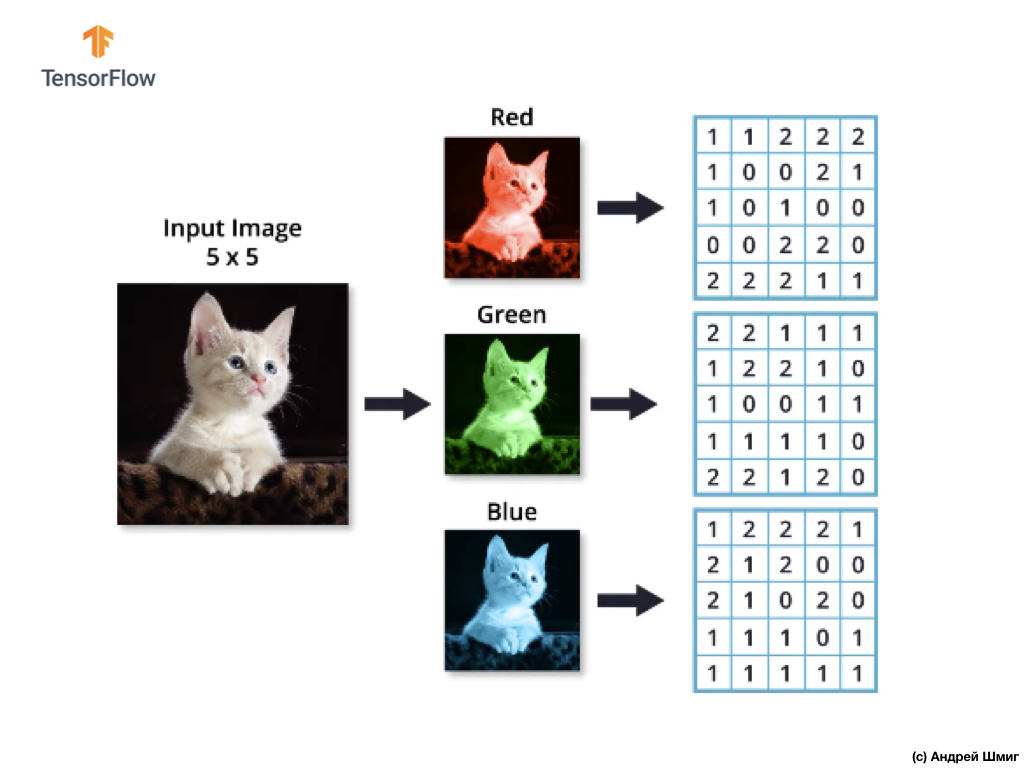
كما هو الحال مع عملية الالتفاف على الصور في ظلال رمادية ، وكذلك مع الصور الملونة - سنقوم بتنفيذ المحاذاة ونكمل الصورة عند الحواف مع الأصفار لمنع فقدان المعلومات على الحدود.
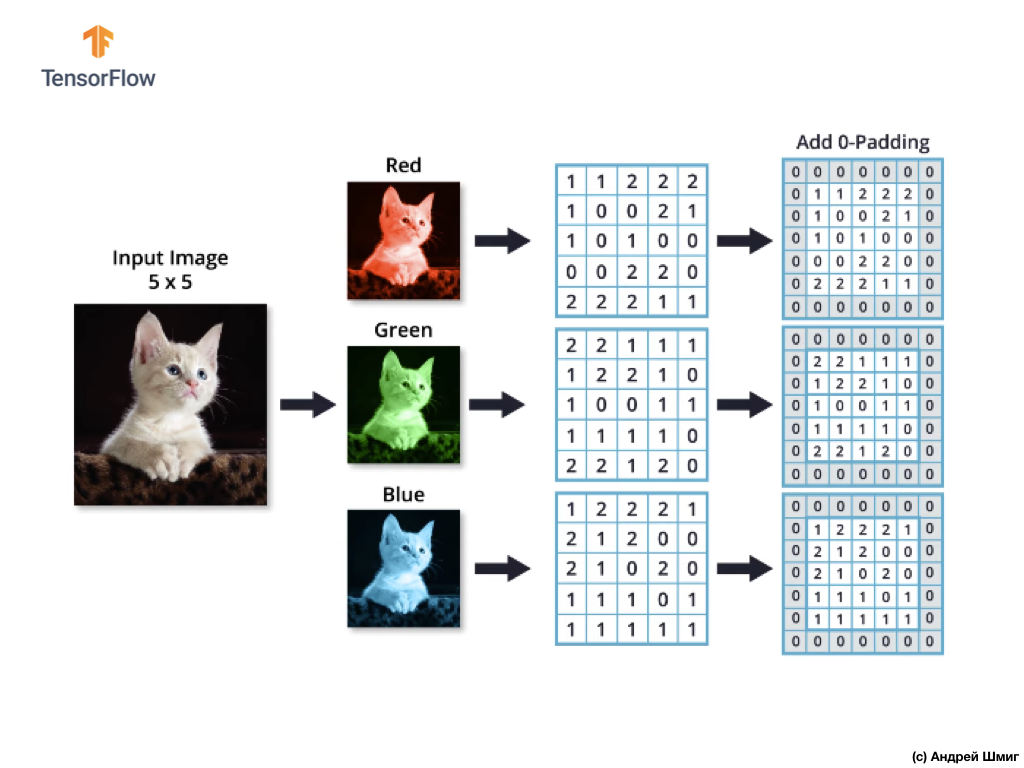
الآن نحن مستعدون لعملية الالتواء!
ستكون آلية الالتفاف الخاصة بالصور الملونة مماثلة للعملية التي قمنا بها باستخدام الصور ذات التدرج الرمادي. الفرق الوحيد بين العمليات المنجزة على الصور ذات التدرج الرمادي والصور الملونة هو أن عملية الالتفاف تحتاج الآن إلى إجراء 3 مرات لكل قناة ملونة.
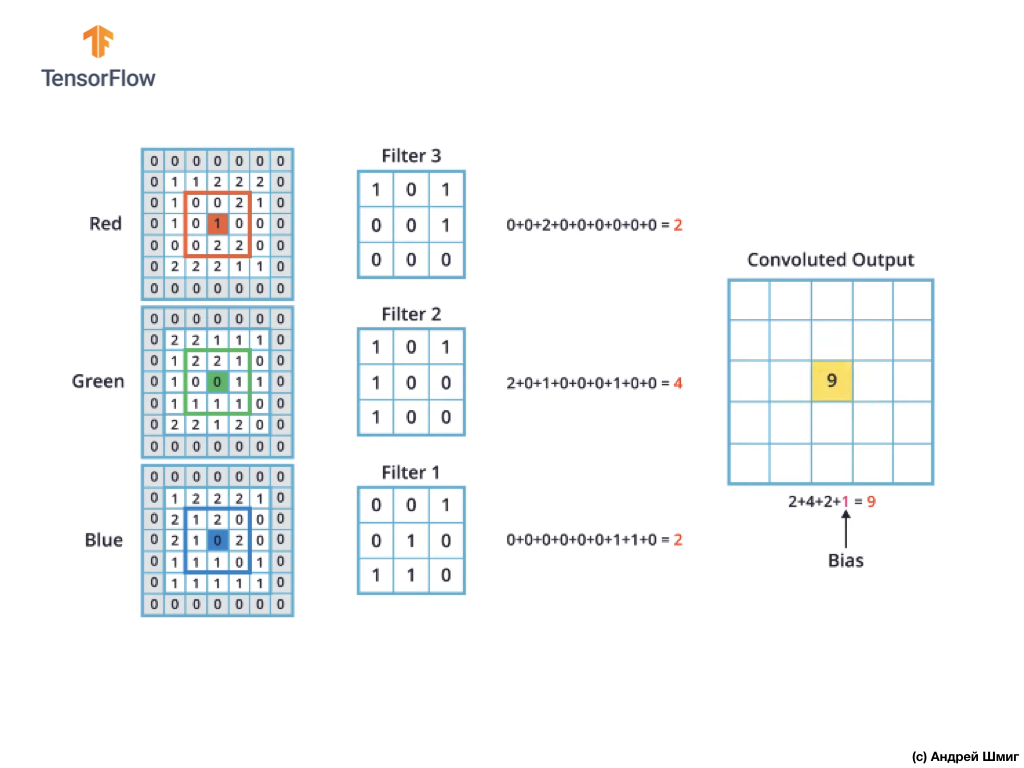
بعد ذلك ، بعد قيامنا بعملية الالتفاف على كل قناة ملونة ، أضف القيم الثلاث التي تم الحصول عليها وأضف 1 إليها (القيمة القياسية المستخدمة عند إجراء عمليات من هذا النوع). يتم إصلاح القيمة الجديدة الناتجة في نفس الموضع في الصورة الجديدة ، في أي موضع كان البيكسل المحول الحالي.
نقوم بإجراء عملية تحويل مماثلة (عملية تحويل) لكل بكسل في صورتنا الأصلية ولكل قناة ملونة.
في هذا المثال بالذات ، تكون الصورة الناتجة بنفس حجم الطول والعرض مثل صورة RGB الأصلية.
كما ترى ، فإن تطبيق عملية الالتفاف باستخدام مرشح ثلاثي الأبعاد واحد ينتج عنه قيمة إخراج واحدة.
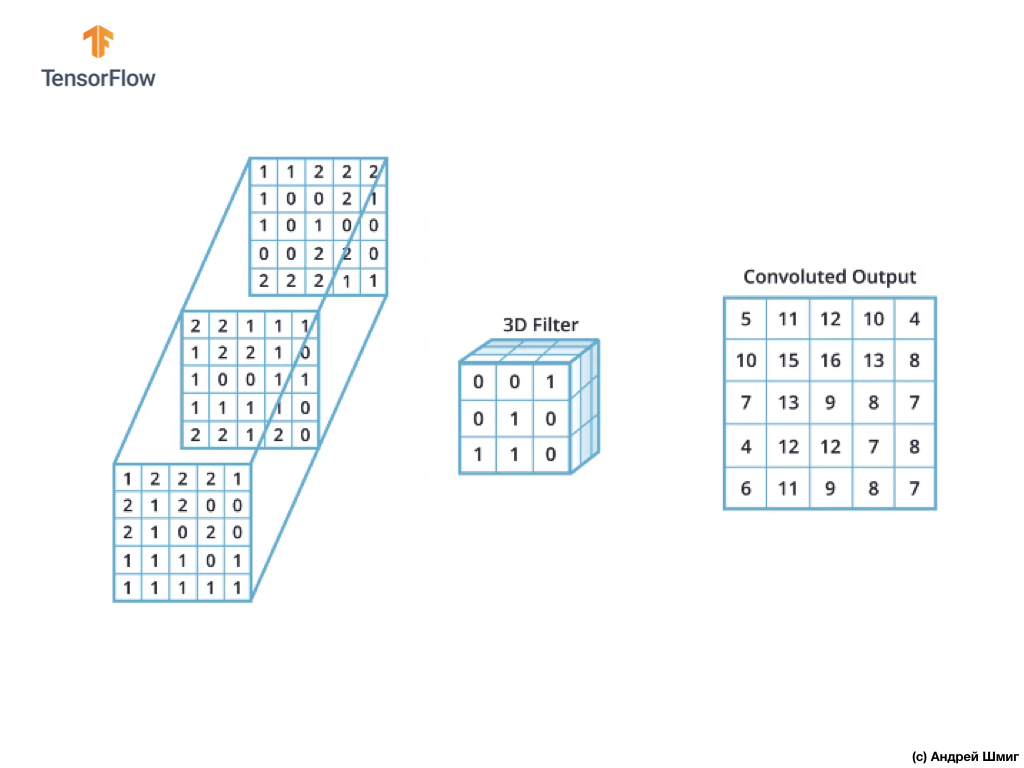
ومع ذلك ، عند العمل مع الشبكات العصبية التلافيفية ، من الشائع استخدام أكثر من فلتر ثلاثي الأبعاد. إذا استخدمنا أكثر من فلتر ثلاثي الأبعاد ، فستكون النتيجة عدة قيم مخرجات - كل قيمة هي نتيجة مرشح واحد.
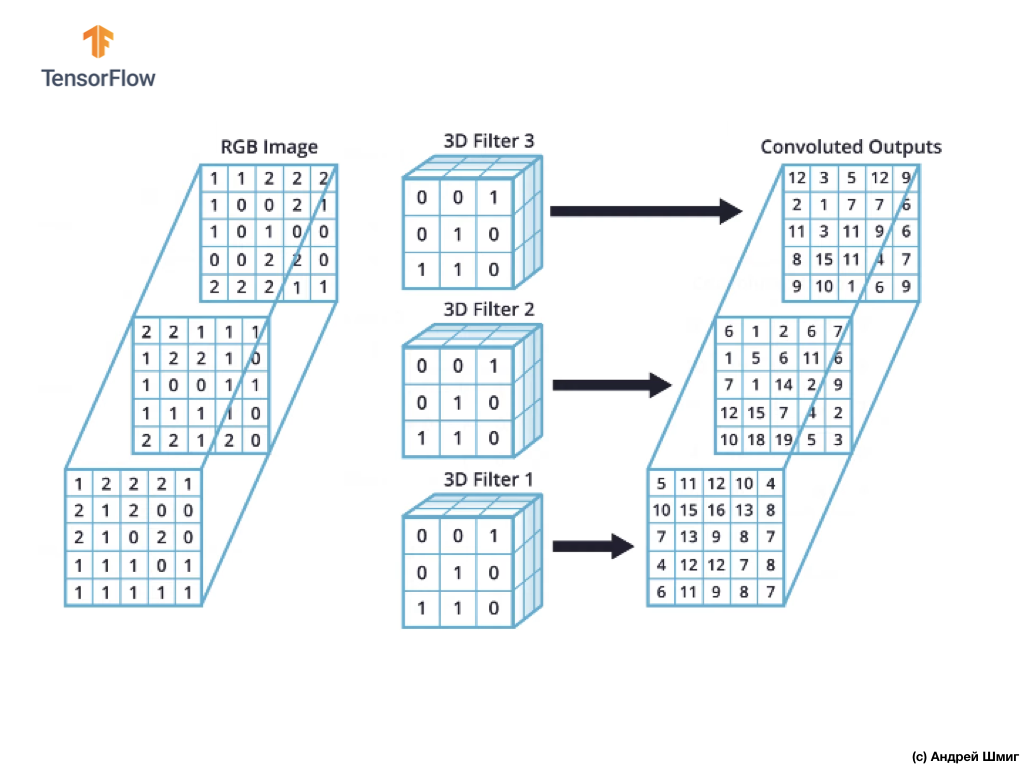
في مثالنا أعلاه ، بما أننا نستخدم 3 مرشحات ، فإن التمثيل ثلاثي الأبعاد الناتج سيكون له عمق 3 - كل طبقة سوف تتوافق مع قيمة مخرجات تحويل مرشح واحد فوق الصورة مع جميع قنوات الألوان الخاصة به.
على سبيل المثال ، إذا بدلاً من 3 مرشحات ، قررنا استخدام 16 ، ثم التمثيل ثلاثي الأبعاد للمخرجات سيحتوي على 16 طبقة عمق.
في الرمز ، يمكننا التحكم في عدد المرشحات التي تم إنشاؤها عن طريق تمرير القيمة المناسبة لمعلمة filters :
tf.keras.layers.Conv2D(filters, kernel_size, ...)
يمكننا أيضًا تحديد حجم المرشح من خلال المعلمة kernel_size . على سبيل المثال ، لإنشاء 3 عوامل تصفية بحجم 3x3 ، كما كان الحال في مثالنا أعلاه ، يمكننا كتابة الرمز على النحو التالي:
tf.keras.layers.Conv2D(3, (3,3), ...)
تذكر أنه أثناء تدريب الشبكة العصبية التلافيفية ، سيتم تحديث القيم في المرشحات ثلاثية الأبعاد لتقليل قيمة وظيفة الخسارة.
الآن بعد أن عرفنا كيفية إجراء عملية الالتفاف على الصور الملونة ، فقد حان الوقت لمعرفة كيفية تطبيق عملية العينة الفرعية على النتيجة القصوى بالقيمة القصوى (نفس الحد الأقصى للتجمع).
تشغيل أخذ العينات من خلال الحد الأقصى للقيمة في الصور الملونة
دعونا الآن نتعلم كيفية إجراء عملية العينة الفرعية بأقصى قيمة في الصور الملونة. في الواقع ، تعمل عملية أخذ العينات الفرعية بالقيمة القصوى بنفس الطريقة التي تعمل بها مع الصور ذات الظلال الرمادية مع اختلاف طفيف - يجب تطبيق عملية أخذ العينات الفرعية الآن على كل تمثيل ناتج تلقيناه نتيجة لتطبيق المرشحات. لنلقِ نظرة على مثال.
للبساطة ، دعونا نتخيل أن وجهة نظرنا الإخراج تبدو مثل هذا:
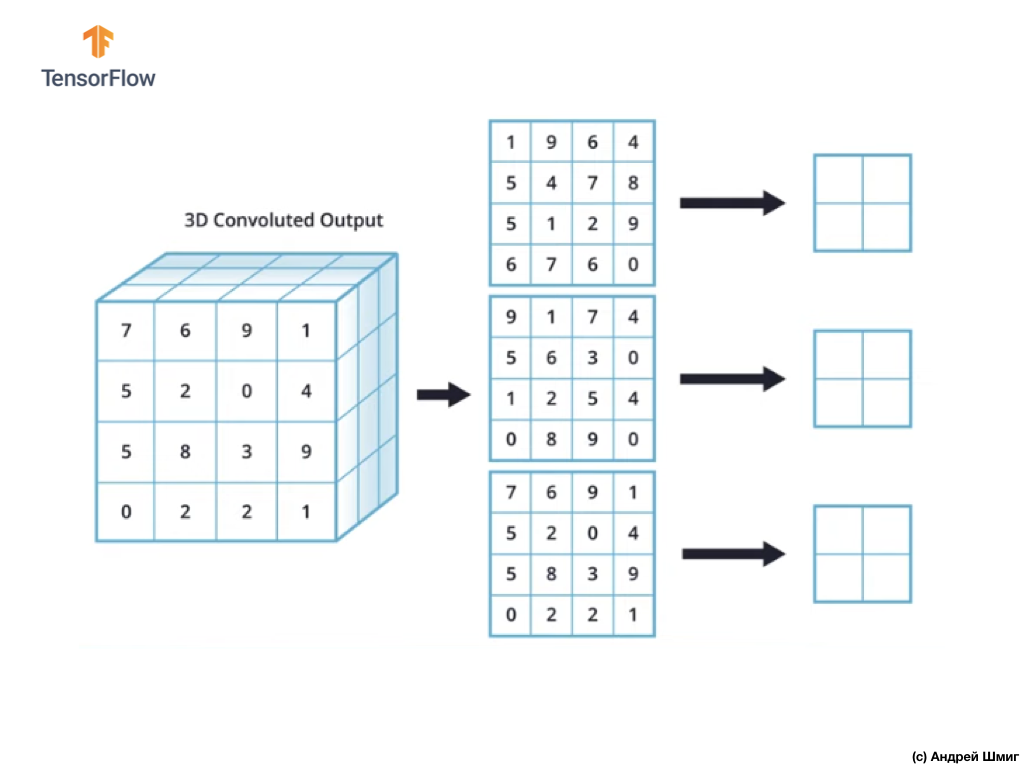
كما كان من قبل ، سوف نستخدم نواة 2 × 2 والخطوة 2 لإجراء عملية أخذ العينات بالقيمة القصوى. تبدأ عملية العينة الجزئية بالقيمة القصوى بـ "تثبيت" نواة 2 × 2 في الزاوية اليسرى العليا من كل تمثيل للمخرجات (التمثيل الذي تم الحصول عليه بعد تطبيق عملية الالتفاف).

الآن يمكننا أن نبدأ عملية أخذ العينات بالقيمة القصوى. على سبيل المثال ، في أول تمثيل للناتج لدينا ، تندرج القيم التالية في النواة 2 × 2 - 1 ، 9 ، 5 ، 4. نظرًا لأن الحد الأقصى للقيمة في هذا النواة هو 9 ، فإنه يتم إرسالها إلى تمثيل المخرجات الجديد. يتم تكرار عملية مماثلة لكل تمثيل الإدخال.
نتيجة لذلك ، يجب أن نحصل على النتيجة التالية:

بعد إجراء عملية العينة الفرعية بالقيمة القصوى ، تكون النتيجة صفائف ثنائية الأبعاد ، كل منها أصغر مرتين من تمثيل الإدخال الأصلي.
وبالتالي ، في هذه الحالة بالذات ، عند إجراء عملية أخذ العينات الجزئية بالقيمة القصوى على تمثيل المدخلات ثلاثي الأبعاد ، نحصل على تمثيل مخرجات ثلاثي الأبعاد بنفس العمق ، ولكن مع قيم الطول والعرض نصف القيم الأولية.
لذلك ، هذه هي النظرية الكاملة التي سنحتاجها لمزيد من العمل. الآن دعنا نرى كيف يعمل هذا في الكود!
CoLab: القطط والكلاب
CoLab الأصلي باللغة الإنجليزية متاح على هذا الرابط .
CoLab باللغة الروسية متاح على هذا الرابط .
في هذا البرنامج التعليمي ، سنناقش كيفية تصنيف صور القطط والكلاب. سنقوم بتطوير مصنف الصورة باستخدام نموذج tf.keras.Sequential ، ونستخدم tf.keras.Sequential لتحميل البيانات.
الأفكار المراد تغطيتها في هذا الجزء:
سنكتسب خبرة عملية في تطوير مصنف ونطور فهمًا بديهيًا للمفاهيم التالية:
- بناء نموذج لتدفق البيانات ( خطوط إدخال البيانات ) باستخدام
tf.keras.preprocessing.image.ImageDataGenerator (كيفية العمل بكفاءة مع البيانات الموجودة على القرص المتفاعل مع النموذج؟) - إعادة التدريب - ما هو وكيفية تحديد ذلك؟
قبل أن نبدأ ...
قبل بدء تشغيل الشفرة في المحرر ، نوصي بإعادة تعيين جميع الإعدادات في Runtime -> إعادة تعيين الكل في القائمة العلوية. سيساعد مثل هذا الإجراء على تجنب مشاكل نقص الذاكرة ، إذا كنت تعمل بشكل متوازٍ أو تعمل مع العديد من المحررين.
استيراد الحزم
لنبدأ باستيراد الحزم التي تحتاجها:
os - قراءة الملفات وهياكل الدليل؛numpy - بالنسبة لبعض عمليات المصفوفة خارج TensorFlow ؛matplotlib.pyplot - التخطيط وعرض الصور من مجموعة بيانات الاختبار والتحقق.
from __future__ import absolute_import, division, print_function, unicode_literals import os import matplotlib.pyplot as plt import numpy as np
استيراد TensorFlow :
import tensorflow as tf from tensorflow.keras.preprocessing.image import ImageDataGenerator
import logging logger = tf.get_logger() logger.setLevel(logging.ERROR)
تحميل البيانات
نبدأ في تطوير مصنفنا عن طريق تحميل مجموعة بيانات. مجموعة البيانات التي نستخدمها هي نسخة مُفلترة من مجموعة بيانات Dogs vs Cats من خدمة Kaggle (في النهاية ، يتم توفير مجموعة البيانات هذه بواسطة Microsoft Research).
في الماضي ، استخدمت CoLab وأنا مجموعة بيانات من وحدة TensorFlow Dataset نفسها ، وهي ملائمة للغاية للعمل والاختبار. ومع ذلك ، في tf.keras.preprocessing.image.ImageDataGenerator ، tf.keras.preprocessing.image.ImageDataGenerator فئة tf.keras.preprocessing.image.ImageDataGenerator لقراءة البيانات من القرص. لذلك ، نحتاج أولاً إلى تنزيل مجموعة بيانات Dog VS Cats وفك ضغطها.
_URL = 'https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip' zip_dir = tf.keras.utils.get_file('cats_and_dogs_filterted.zip', origin=_URL, extract=True)
تحتوي مجموعة البيانات التي قمنا بتنزيلها على البنية التالية:
cats_and_dogs_filtered |__ train |______ cats: [cat.0.jpg, cat.1.jpg, cat.2.jpg ...] |______ dogs: [dog.0.jpg, dog.1.jpg, dog.2.jpg ...] |__ validation |______ cats: [cat.2000.jpg, cat.2001.jpg, cat.2002.jpg ...] |______ dogs: [dog.2000.jpg, dog.2001.jpg, dog.2002.jpg ...]
للحصول على قائمة كاملة من الدلائل ، يمكنك استخدام الأمر التالي:
zip_dir_base = os.path.dirname(zip_dir) !find $zip_dir_base -type d -print
نتيجة لذلك ، حصلنا على شيء مشابه:
/root/.keras/datasets /root/.keras/datasets/cats_and_dogs_filtered /root/.keras/datasets/cats_and_dogs_filtered/train /root/.keras/datasets/cats_and_dogs_filtered/train/dogs /root/.keras/datasets/cats_and_dogs_filtered/train/cats /root/.keras/datasets/cats_and_dogs_filtered/validation /root/.keras/datasets/cats_and_dogs_filtered/validation/dogs /root/.keras/datasets/cats_and_dogs_filtered/validation/cats
الآن تعيين المسارات الصحيحة إلى الدلائل مع مجموعات البيانات للتدريب والتحقق من صحة للمتغيرات:
base_dir = os.path.join(os.path.dirname(zip_dir), 'cats_and_dogs_filtered') train_dir = os.path.join(base_dir, 'train') validation_dir = os.path.join(base_dir, 'validation') train_cats_dir = os.path.join(train_dir, 'cats') train_dogs_dir = os.path.join(train_dir, 'dogs') validation_cats_dir = os.path.join(validation_dir, 'cats') validation_dogs_dir = os.path.join(validation_dir, 'dogs')
فهم البيانات وهيكلها
دعونا نرى عدد الصور من القطط والكلاب لدينا في مجموعات بيانات الاختبار والتحقق (الدلائل).
num_cats_tr = len(os.listdir(train_cats_dir)) num_dogs_tr = len(os.listdir(train_dogs_dir)) num_cats_val = len(os.listdir(validation_cats_dir)) num_dogs_val = len(os.listdir(validation_dogs_dir)) total_train = num_cats_tr + num_dogs_tr total_val = num_cats_val + num_dogs_val
print(' : ', num_cats_tr) print(' : ', num_dogs_tr) print(' : ', num_cats_val) print(' : ', num_dogs_val) print('--') print(' : ', total_train) print(' : ', total_val)
سيكون إخراج الكتلة الأخيرة كما يلي:
: 1000 : 1000 : 500 : 500 -- : 2000 : 1000
تحديد معلمات النموذج
للراحة ، سنضع تثبيت المتغيرات التي نحتاجها لمزيد من معالجة البيانات والتدريب النموذجي في إعلان منفصل:
BATCH_SIZE = 100
إعداد البيانات
قبل أن يمكن استخدام الصور كمدخلات لشبكتنا ، يجب تحويلها إلى التنسورات مع قيم الفاصلة العائمة. قائمة الخطوات الواجب اتخاذها للقيام بذلك:
- قراءة الصور من القرص
- فك شفرة محتوى الصورة وتحويلها إلى التنسيق المطلوب مع مراعاة ملف تعريف RGB
- تحويل إلى التنسورات مع القيم الفاصلة العائمة
- لتطبيع قيم الموتر من الفاصل الزمني من 0 إلى 255 إلى الفاصل من 0 إلى 1 ، لأن الشبكات العصبية تعمل بشكل أفضل مع قيم الإدخال الصغيرة.
لحسن الحظ ، يمكن تنفيذ كل هذه العمليات باستخدام فئة tf.keras.preprocessing.image.ImageDataGenerator .
يمكننا القيام بكل هذا باستخدام عدة سطور من التعليمات البرمجية:
train_image_generator = ImageDataGenerator(rescale=1./255) validation_image_generator = ImageDataGenerator(rescale=1./255)
بعد تعريف المولدات لمجموعة من بيانات الاختبار والتحقق من الصحة ، ستقوم طريقة التدفق_الحملي بتحميل الصور من القرص وتطبيع البيانات وتغيير حجم الصور باستخدام سطر واحد فقط من التعليمات البرمجية:
train_data_gen = train_image_generator.flow_from_directory(batch_size=BATCH_SIZE, directory=train_dir, shuffle=True, target_size=(IMG_SHAPE,IMG_SHAPE), class_mode='binary')
الاستنتاج:
Found 2000 images belonging to 2 classes.
مولد بيانات التحقق من الصحة:
val_data_gen = validation_image_generator.flow_from_directory(batch_size=BATCH_SIZE, directory=validation_dir, shuffle=False, target_size=(IMG_SHAPE,IMG_SHAPE), class_mode='binary')
الاستنتاج:
Found 1000 images belonging to 2 classes.
تصور الصور من مجموعة التدريب.
يمكننا تصور الصور من مجموعة بيانات التدريب باستخدام matplotlib :
sample_training_images, _ = next(train_data_gen)
تقوم الوظيفة next بإرجاع كتلة من الصور من مجموعة البيانات. كتلة واحدة هي مجموعة من (العديد من الصور ، العديد من التسميات) . في الوقت الحالي ، سنقوم بإسقاط الملصقات ، حيث أننا لسنا بحاجة إليها - نحن مهتمون بالصور نفسها.
plotImages(sample_training_images[:5])
مثال الإخراج (2 صور بدلا من كل 5):

خلق نموذج
نحن تصف النموذج
يتكون النموذج من 4 كتل ملتفة ، بعد كل منها كتلة تحتوي على طبقة فرعية. بعد ذلك ، لدينا طبقة متصلة بالكامل مع 512 خلية عصبية relu تنشيط relu . سيعطي النموذج توزيع الاحتمال لفئتين - الكلاب والقطط - باستخدام softmax .
model = tf.keras.models.Sequential([ tf.keras.layers.Conv2D(32, (3,3), activation='relu', input_shape=(IMG_SHAPE, IMG_SHAPE, 3)), tf.keras.layers.MaxPooling2D(2, 2), tf.keras.layers.Conv2D(64, (3, 3), activation='relu'), tf.keras.layers.MaxPooling2D(2, 2), tf.keras.layers.Conv2D(128, (3, 3), activation='relu'), tf.keras.layers.MaxPooling2D(2, 2), tf.keras.layers.Conv2D(128, (3, 3), activation='relu'), tf.keras.layers.MaxPooling2D(2, 2), tf.keras.layers.Flatten(), tf.keras.layers.Dense(512, activation='relu'), tf.keras.layers.Dense(2, activation='softmax') ])
تجميع النموذج
كما كان من قبل ، سوف نستخدم محسن adam . نستخدم sparse_categorical_crossentropy خسارة. نريد أيضًا مراقبة دقة النموذج في كل تكرار تدريب ، لذلك نقوم بتمرير قيمة accuracy إلى معلمة metrics :
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
عرض النموذج
دعونا نلقي نظرة على هيكل نموذجنا من خلال المستويات باستخدام طريقة الملخص :
model.summary()
الاستنتاج:
Model: "sequential" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= conv2d (Conv2D) (None, 148, 148, 32) 896 _________________________________________________________________ max_pooling2d (MaxPooling2D) (None, 74, 74, 32) 0 _________________________________________________________________ conv2d_1 (Conv2D) (None, 72, 72, 64) 18496 _________________________________________________________________ max_pooling2d_1 (MaxPooling2 (None, 36, 36, 64) 0 _________________________________________________________________ conv2d_2 (Conv2D) (None, 34, 34, 128) 73856 _________________________________________________________________ max_pooling2d_2 (MaxPooling2 (None, 17, 17, 128) 0 _________________________________________________________________ conv2d_3 (Conv2D) (None, 15, 15, 128) 147584 _________________________________________________________________ max_pooling2d_3 (MaxPooling2 (None, 7, 7, 128) 0 _________________________________________________________________ flatten (Flatten) (None, 6272) 0 _________________________________________________________________ dense (Dense) (None, 512) 3211776 _________________________________________________________________ dense_1 (Dense) (None, 2) 1026 ================================================================= Total params: 3,453,634 Trainable params: 3,453,634 Non-trainable params: 0
!
( ImageDataGenerator ) fit_generator fit :
EPOCHS = 100 history = model.fit_generator( train_data_gen, steps_per_epoch=int(np.ceil(total_train / float(BATCH_SIZE))), epochs=EPOCHS, validation_data=val_data_gen, validation_steps=int(np.ceil(total_val / float(BATCH_SIZE))) )
:
acc = history.history['acc'] val_acc = history.history['val_acc'] loss = history.history['loss'] val_loss = history.history['val_loss'] epochs_range = range(EPOCHS) plt.figure(figsize=(8,8)) plt.subplot(1, 2, 1) plt.plot(epochs_range, acc, label=' ') plt.plot(epochs_range, val_acc, label=' ') plt.legend(loc='lower right') plt.title(' ') plt.subplot(1, 2, 2) plt.plot(epochs_range, loss, label=' ') plt.plot(epochs_range, val_loss, label=' ') plt.legend(loc='upper right') plt.title(' ') plt.savefig('./foo.png') plt.show()
الاستنتاج:
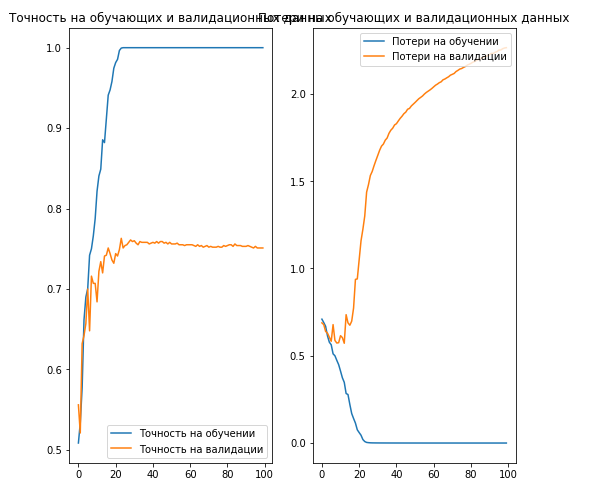
, 70% ( ).
. , .
… .
... ومكالمة تحث على اتخاذ إجراء - اشترك ، ضع علامة زائد وشاركه :)
يوتيوب
برقية
فكونتاكتي